
基于YOLOV3改进的虹膜定位算法
2022-05-18 13:11:22于哲舟刘元宁
东北大学学报(自然科学版) 2022年4期
于哲舟, 刘 岩, 刘元宁
(1. 吉林大学 计算机科学与技术学院, 吉林 长春 130012; 2. 吉林大学 软件学院, 吉林 长春 130012;3. 吉林大学 符号计算与知识工程教育部重点实验室, 吉林 长春 130012)
当今最受欢迎的生物特征识别方式是虹膜识别[1-3],在整个虹膜识别系统流程中,虹膜定位环节处于核心位置,虹膜定位的准确率对系统后期的识别产生重大影响.传统的虹膜定位方法容易受到噪声、睫毛遮挡等影响,导致定位不准确,所提取到的信息很难在后期的特征识别中使用.YOLOV3模型在目标检测方面效果较好,采用这种基础模型对虹膜两个内外边界进行定位,提高了定位准确性.由于原始特征提取网络DarkNet-53层数较少,不能提取到高质量的虹膜特征.虽然能够大大提高检测速度,但准确率很低;随卷积神经网络中卷积层数的不断加深,提取到的特征也会更为丰富,随网络层数不断加深,导致网络模型出现退化.退化主要是由于梯度消失导致网络性能退化,同时由于虹膜图像在采集时虹膜的大小也不尽相同.卷积神经网络经过多次卷积之后,特征图的尺寸会变得很小,所以检测小目标更加困难,无法更好利用虹膜图片学习到虹膜语义特征,因此本文针对这些问题对虹膜定位模型作出改进[4-8].
1 改进的YOLOV3结构
1.1 Densenet-121网络模型
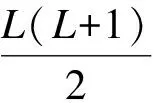
xl=Hl([x0,x1,…,xl-1]) .
(1)
式中:xl表示第l层的输出;[x0,x1,…,xl-1]表示网络的0,1,…,l-1层所输出的特征图级联在一起.Densenet网络结构如图1所示.

图1 Densenet网络结构
1.2 Non-local注意力机制
Non-local注意力机制的作用主要是用来对虹膜图像重点区域进行加强,增强虹膜图片学习到的语义特征,Non-local操作相当于构造了一个和特征图谱尺寸一样大的卷积核,从而可以维持更多信息. Non-local操作能够直接从任意两点间获取到长距离的依赖信息,同时它也是一个易于集成的网络模块,虹膜特征信息提取是一种比较优良的注意力机制实现.Non-local的通用式为
(2)
式中:yi表示输出;c(x)为归一化因子;f(xi,xj)为计算i和j间的相似性;g(xj)为计算特征图在j位置上的表示.Non-local注意力机制结构[9-11]如图2所示.
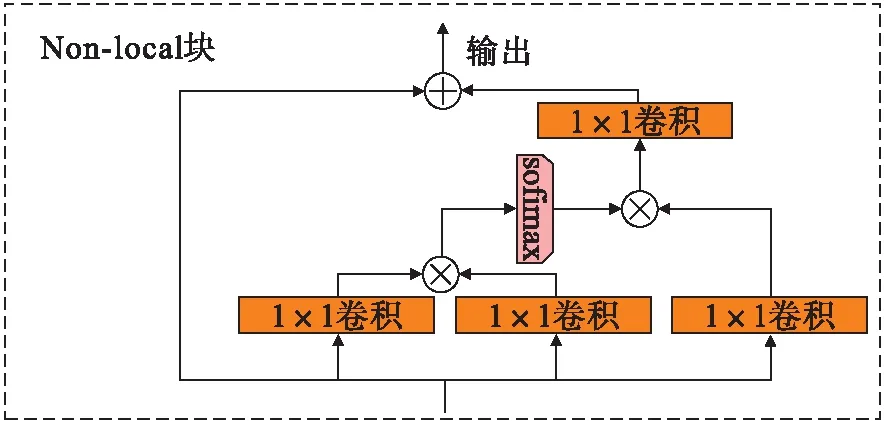
图2 Non-local注意力机制结构
1.3 辅助网络
为进一步增强小目标虹膜学习到的语义特征,在改进的YOLOV3虹膜定位算法中,使用复制残余模块的方式获得辅助结构,扩展整个特征提取网络,进而优化骨干网络.辅助网络的规模要比骨干网络小,与原始的YOLOV3剩余模块相比,增加了辅助网络的剩余模块.在辅助网络中使用较大的接收场,辅助网络会将收集到的特征位置信息传输到骨干网络上,骨干网络能够更加准确地学习目标特征信息.在网络中添加辅助网络使整个网络结构与高级或低级语义特征密切联系,能够有效提高网络性能.辅助网络结构图如图3所示[12-13].
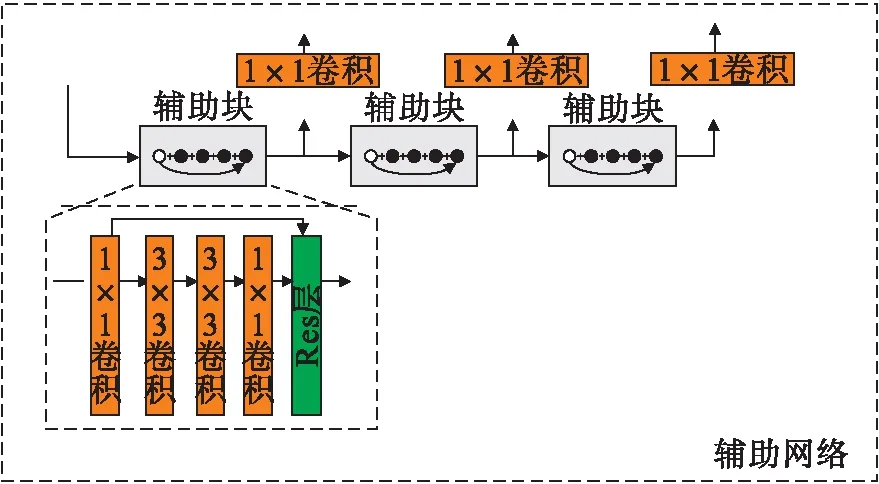
图3 辅助网络结构图
2 实验设计
实验数据使用的是吉林大学自主采集的JLUIRIS-v6和JLUIRIS-v7两代虹膜图像,在虹膜库中选择2 238张经过质量评价挑选后的虹膜图像作为本次实验的训练集和测试集.在进行虹膜定位前要对虹膜图像进行预处理及标注处理.本文所用的工具是labelImg,标注过的每张图片都生成关于虹膜的内外圆目标框的标签及其坐标值的xml文件.经过标注的虹膜图像如图4所示.

图4 虹膜图像预处理
本文改进实验的batchsize为8,一共训练80个epoch,图片输入大小为640×480.Densenet的权重在Imagenet上预训练完成.采用Adam优化器,由于主干网络已经在Imagenet上预训练,因此,Densenet的学习率设置为0.000 1,网络中其他模块的学习率设置成0.001,学习率每30个epoch下降为原来的1/10.在进行了40个epoch后,采用多尺度的训练方式,随机将图片的尺度放大或者缩小来增强模型的尺度不变性.本文采用了随机亮度、随机对比度、图片翻转及图片模糊等数据增强的方式.激活层使用leakey relu激活函数.所有的实验都是在一个单独的1 080 ti上完成,训练时间为6 h.对于每一个锚点,根据实际数据设置了9个锚点框,大小为 [(10,13),(16,30),(33,23),(30,61),(62,45),(59,119),(116,90),(156,198),(373,326)],对于与真实框的IOU大于0.7的锚点框,将其设置成正样本,IOU小于0.3的锚点框设置成负样本,IOU在0.3~0.7之间的样本不作计算.在Non-local模块中,放缩系数r设置为2.测试时,NMS非极大值抑制的阈值设置为0.4,物体的置信度阈值设置为0.75[14-15].
改进的模型结构图如图5所示.

图5 改进模型的结构图
改进模型的参数如表1所示.
3 实验结果分析
可视化结果如图6所示.使用Densenet特征提取网络的矩形可视化结果如图6a所示,使用Darknet特征提取模型的可视化结果如图6b所示.

图6 可视化结果

表1 改进模型的参数
由于目标检测模型中的标定框和得到的预测框都是基于直角坐标系下的矩形框体,根据虹膜内圆、外圆的几何特征,虹膜定位要求输出的是椭圆形的定位框.根据得到的矩形框体输出椭圆形的标注框,最终本文系统得到的虹膜内外圆定位结果的可视化图像如图7所示.可知本文模型的内外圆定位效果.
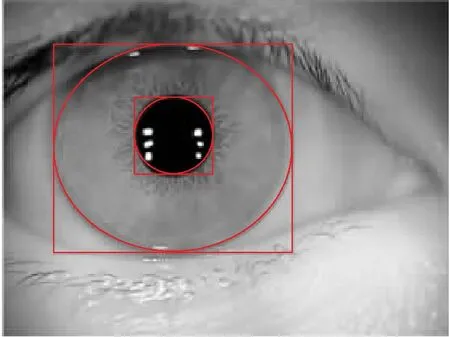
图7 模型最终可视化图像
与未改进的算法相比,本文模型训练效果有了显著提升,同时loss曲线下降的趋势更加平缓,本文改进网络结构训练集的损失函数图像如图8所示.由各层loss曲线可知,本文模型能很快逼近曲线中损失函数的最小值,收敛速度快,所以能更好更快地拟合虹膜数据集.
YOLOV3虹膜图像只需要定位出2种类别的物体,即虹膜的内圆和外圆边界.在传统Daugman模型中,虹膜定位精确率为95.6%,Wilde模型定位精确率为95.3%,基于Darknet的YOLOV3模型定位精确率为92.4%,本文中通过优化的模型精确率为97.1%.PR曲线如图9所示,各模型评价指标对比如表2所示.

图8 损失函数图

图9 PR曲线图
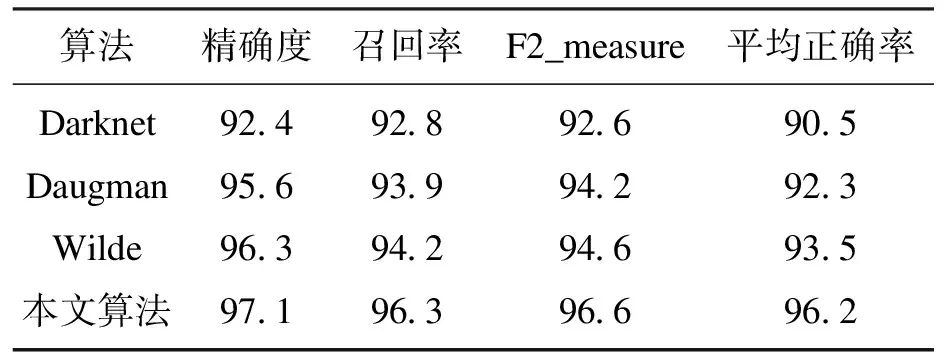
表2 各模型评价指标对比
4 结 论
1) Darknet本身所特有的优势是速率较快,但它的特征提取能力差,容易出现退化现象.经过改进的YOLOV3网络将特征提取模块换成优良的特征提取模型Densenet-121,并添加了复制网络及Non-local注意力机制增强学习到的语义特征,着重感兴趣区域,即使是小目标虹膜也能够学习到大量的特征信息,测试结果的精确率达到97.1%.
2) 本文模型在虹膜定位上超越了传统虹膜定位算法精确率方面的各项评价指标.
猜你喜欢
世界科学技术-中医药现代化(2022年3期)2022-08-22 00:32:50
中国典型病例大全(2022年11期)2022-05-13 17:54:50
云南化工(2021年8期)2021-12-21 06:37:54
海洋信息技术与应用(2020年1期)2020-06-11 12:43:56
传媒评论(2019年4期)2019-07-13 05:49:14
电子制作(2018年19期)2018-11-14 02:37:08
文萃报·周二版(2018年51期)2018-08-04 06:05:18
自动化学报(2017年11期)2017-04-04 02:52:58
警察技术(2015年3期)2015-02-27 15:37:15
噪声与振动控制(2015年4期)2015-01-01 07:08:21
