
一种基于BERT-Stacking的钓鱼网站检测方法
2022-05-17 00:38:28周杭霞
中国计量大学学报 2022年1期
胡 强,周杭霞,刘 倩
(中国计量大学 信息工程学院,浙江 杭州 310018)
钓鱼网站通过伪装成正常合法的网站诱导用户,从而获取用户的账户密码等隐私信息,盗取用户的钱财或个人信息。目前的钓鱼网站检测方法主要基于黑白名单、视觉相似性、机器学习三个方向。基于黑白名单过滤的钓鱼检测方法,作为各大浏览器最常用的检测钓鱼网站的技术,其有效性取决于其大小、范围、更新速度和频率、准确性以及其他特征[1],所以具有一定的滞后性。基于白名单的钓鱼检测方法主要通过业务白名单动态模型实现对未知钓鱼威胁的主动防御[2]。
基于颜色直方图的小波哈希机制[3]和基于量化网页元素对CSS元素的影响[4]是近几年利用视觉相似性检测钓鱼网站使用较多的方法,Rao等[5]在此引入了Simhash和Perceptual hash两种模糊相似性指标来评估页面与钓鱼网站的相似性。基于视觉相似性的检测方法需要对网页进行大量的图形分析,因此检测的计算开销较大。
针对以上两种方法的局限性,更多的钓鱼网站检测方法开始使用机器学习算法。改进的随机森林算法[6]和在线序列极限学习机[7]均被证明可以有效的提高检测钓鱼网站的准确率,但当URL中特征噪声较大时,出现过拟合。卜佑军等[8]使用CNN提取网站URL特征,并利用双向LSTM算法分析其双向长距离依赖特征,避免了人工提取特征的局限性,但是只使用了网站的URL特征,没有利用其HTML特征进一步挖掘。Liu等[9]设计了一种CASE框架来构建钓鱼网站的特征空间,分多阶段使用不同的机器学习算法来检测钓鱼网站,但由于使用了线性的多阶段检测,大幅增加了钓鱼网站的检测时间。毕青松等[10]提出利用mRMR和RF算法对网站特征排序,并利用极端梯度提升(XGBoost)算法构建钓鱼网站检测模型,取得较好的检测结果。文献[11]提出一种Nmap-RF集成学习的方法,结合规则匹配和随机森林两种算法分析网页URL特征以检测钓鱼网站。以上两种方法由于只是使用两种算法简单叠加,并没有发挥集成学习的真正优势。
本文设计了基于BERT提取的网站HTML字符串嵌入特征,结合URL字符串特征检测钓鱼网站。此外,我们使用从公开的钓鱼检测网站Alexa和Phishtank获取的数据集,结合DF、GBDT、XGBoost和LightGBM设计了一种Stacking算法来检测钓鱼网站。本文的主要贡献主要有以下几个方面。
1)从公开数据集中筛选出两个分别为5万级和10万级钓鱼网站数据集,其中合法网站从Alexa网站收集,占数据集48%,非法钓鱼网站从Phishtank网站收集,占数据集52%。
2)在特征提取方面,我们设计了一种基于BERT提取的网站HTML字符串嵌入特征来替换常用的HTML人工特征。
3)通过实验选取了四个分类器作为基学习器,设计了一种Stacking算法,并将DF、XGBoost和LightGBM作为Stacking的第一层,GBDT作为第二层。
1 基于BERT-Stacking的钓鱼网站检测算法
1.1 钓鱼网站特征提取
1.1.1 提取HTML特征
考虑到人工提取HTML特征需要对HTML源码进行大量分析,并且特征需要不断补充更新,我们提出一种使用BERT(Bidirectional Encoder Representations from Transformers)[12]提取HTML字符串嵌入特征的方法,将HTML文档转化为词嵌入向量。
作为一种预训练的语言表征模型,与产生静态词向量的Word2Vec[13]不同,BERT通过双向注意力机制可以学习上下文信息,使用Transformer提取特征[14]。通过训练BERT模型,我们可以得到它从HTML文档中提取的字符串嵌入特征。具体来说,BERT会根据HTML文档内容的空间距离提取HTML字符串,将其映射到单词文本来学习多维HTML字符串嵌入信息,最终得到一个多维向量来表示HTML文档。
1.1.2 提取URL特征
对于网页的URL特征,我们使用基于数学统计的计算词频和基于领域知识的人工选择等方法进行特征统计,舍弃对于检测钓鱼网站不重要的特征,最终筛选出9维特征用于对分类器的训练。
1)IP地址。网络钓鱼网页的域名有很大比例包含IP地址。本文用二值‘0’和‘1’表示URL的域名是否包含IP地址,例如‘1’表示URL包含IP地址。
2)URL长度信息。长度信息包括URL中的字符数及其域名。
3)可疑符号。钓鱼网址通常会出现一些很少使用的符号,包括‘@’和‘_’等等。本文用二值表示URL的域名是否包含特殊字符,‘1’表示URL包含特殊字符。
4)重定向。URL重定向跳转中最常见的跳转到登陆口、支付口。本文用二值表示URL的域名是否包含重定向,‘1’表示包含重定向。
5)相似的域名标签。钓鱼网站通常会仿冒目标网站的URL,以此来迷惑用户。
6)URL的子域名数。通常合法网站的URL中只包含一个子域名。
7)URL的子域名长度。类似整个URL长度信息,子域名的长度信息也同样可以作为判别网站是否合法的有效特征。
8)活跃时间。钓鱼网站的存活时间普遍很短,根据此可以用来训练模型。
9)域名中点的个数。网络钓鱼网页倾向于在其URL中使用更多的‘.’。
1.2 搭建检测钓鱼网站的Stacking模型
Stacking是一种用于最小化一个或多个学习器的泛化误差的方案[15],通过形成不同预测变量的线性组合以提高预测准确性[16]。其基本思想是将模型分为一、二两级学习器,使用原始数据集训练第一级学习器,将其输出作为第二级学习器的输入特征,并将原始对应标签作为新标签,以此训练第二级学习器,并将得到的输出结果作为最终的模型输出,其算法过程如算法1所示。

算法1.Stacking过程输入:训练集D={(x1,y1),(x2,y2),…,(xm,ym)}初级学习算法1,2,…,T次级学习算法过程:1:训练一级学习器2:FOR t=1,2,…,T DO3:ht=t(D)4:END FOR5:生成新的数据集6:D′=Ø7:FOR i=1,2,…,m DO8:FOR t=1,2,…,T DO9:zit=ht(xi)10:END FOR11:D′=D′∪((zi1,zi2,…,ziT),yi)12:END FOR13:在新的数据集D′上训练二级学习器h′=(D′)输出:H(x)=h′(h1(x),h2(x),…,hT(x))
本文设计的Stacking算法由两层组成,使用深度森林(Deep Forest, DF)[17]、极限梯度提升树(Extreme Gradient Boosting, XGBoost)[18]和轻量级梯度提升机(Light Gradient Boosting Machine, LightGBM)[19]三个基学习器作为第一级学习器,使用梯度提升决策树(Gradient Boosting Decision Tree, GBDT)[20]作为第二级学习器。同时,为了增强模型的泛化性能,我们采用5-折交叉验证训练Stacking第一级学习器。
2 实验分析
2.1 评价指标
本文使用精确率(Accuracy,A)、查准率(Precision,P)、召回率(Recall,R)和F1值(F-Measure)四个指标[21]来评估此模型的性能,首先引入如表1所示的混淆矩阵。

表1 混淆矩阵Table 1 Confusion matrix
其中,TP表示预测的钓鱼网页实际为钓鱼网页的数量,FP表示预测的钓鱼网页实际为合法网页的数量,TN表示预测的合法网页实际为合法网页的数量,FN表示预测的合法网页实际为钓鱼网页的数量。各评价指标的计算公式如下:
(1)
(2)
(3)
(4)
2.2 选定Stacking第一级基学习器
集成学习的模型效果通常要优于使用单一模型[22],但是为了取得最优的集成效果,我们需要对基学习器进行筛选。在筛选两两组合模型时,通常会使用Kappa统计量,其值越接近1,则所选组合模型越优,由于Kappa统计量与分类器的精确率和准确率呈正相关[23],我们使用精确率来代替Kappa统计量。
我们从AdaBoost、k近邻(k-Nearest Neighbors, KNN)、支持向量机(Support Vector Machine, SVM)、GBDT、LightGBM、XGBoost、DF中选择Stacking第一级的基学习器,通过在本文收集的5万级数据集上进行实验,得出如表2所示的结果。

表2 各基学习器在5万级数据集上精确率统计
由表2可以看出,DF、XGBoost、LightGBM三个基学习器的精确率相对较高,因此我们选择此三个基学习器作为Stacking第一级,选择GBDT作为第二级。为进一步说明选择三个基学习器的优势,我们分别对其中不同的两个基学习器进行Stacking组合实验,如表3。

表3 不同基学习器组成Stacking第一级精确率比较
由表3可以看出,使用三个基学习器作为Stacking第一级效果要优于只使用其中两个基学习器,因此我们最终选择DF、XGBoost、LightGBM作为Stacking的第一级。
2.3 分析特征重要性
为证明我们提出的基于BERT提取的HTML字符串嵌入特征的有效性,我们首先使用XGBoost算法的特征排名功能对所有特征做重要性排名可视化,并且将1.1节中提取的特征依次简称为F1-F10,其可视化结果如图1。
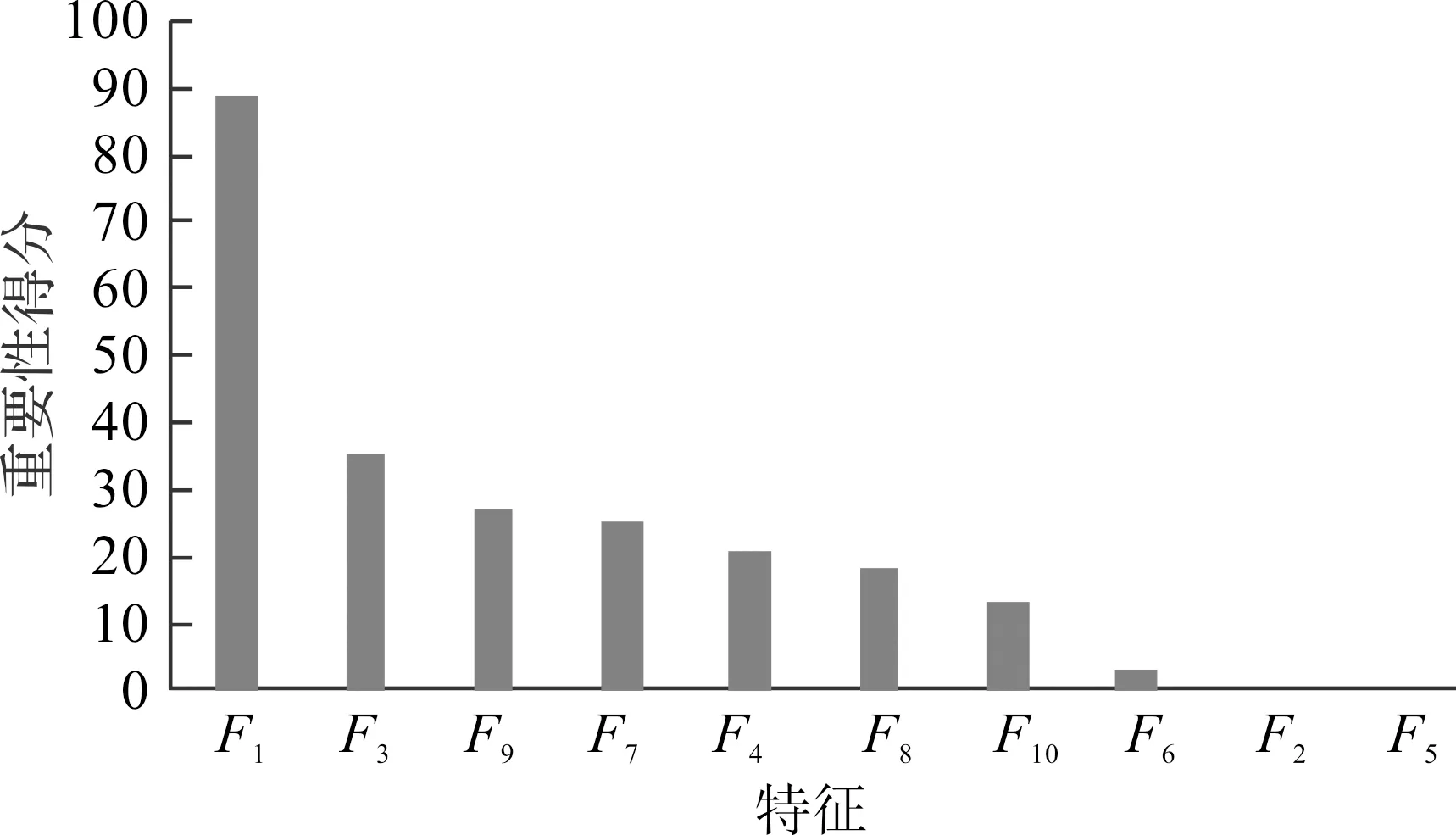
图1 特征重要性排名Figure 1 Ranking of feature importance
由图1可以看出,基于BERT提取的HTML字符串嵌入特征在所有特征中重要性得分最高,而且超过排名第二的“URL长度信息”两倍,说明在模型训练过程中,HTML字符串嵌入特征在判别网站类型时价值最高。
另外,我们对引入HTML字符串嵌入特征前后的模型性能进行对比分析,在相同的数据集上分别进行实验,如表4。

表4 引入HTML字符串嵌入特征前后精确率比较
2.4 与单个基学习器的检测效果比较分析
为证明本文提出的Stacking算法在钓鱼网站检测领域相较单个基学习器的优越性,我们对2.2节中提到的基学习器以及本文提出的BERT-Stacking模型在相同数据集上进行实验对比,实验结果如表5。

表5 BERT-Stacking模型与单模型性能比较
由表5可以看出,本文提出的BERT-Stacking模型在精确率、查准率、召回率、F1值四个指标上均优于单个基学习器。尤其值得注意的是,相较其Stacking第一级所用的DF、XGBoost、LightGBM三个基学习器,Stacking模型在四个指标上均有三个百分点左右的提升,漏报率也大大降低。
2.5 与其他模型的检测效果比较分析
为证明本文的模型相较其他检测钓鱼网站的机器学习模型也具有一定优势,我们选取4种机器学习方法进行实验比较,其中两种为第2节中提到的文献[8]的CNN-BiLSTM和文献[11]的Nmap-RF。另外,我们选取了近两年的两种优秀检测算法:文献[24]提出一种Texception架构并使用FastText来构建字符嵌入特征,并为单词生成嵌入矢量,从而提高对特征的利用率;文献[25]提出一种并行联结神经网络(PNJ),通过提取URL的词汇特征和字符特征,并转换为词嵌入向量和字符嵌入向量,结合胶囊网络和独立递归神经网络的并行联结神经网络分析语义信息,以提高检测准确率。本文的BERT-Stacking算法与以上四种模型的对比实验结果如表6。

表6 BERT-stacking模型与其他模型性能比较
以上实验均在同一数据集上进行,具有较好的可比性。由表6的实验结果可以看出,本文提出的BERT-Stacking在各指标上均优于其他模型,尤其是高于文献[25]的提取URL字符串嵌入的方法,进一步说明了本文提出的基于BERT提取的HTML字符串嵌入特征的有效性和优势。
2.6 比较不同量级数据集上模型的性能
为进一步证明本文提出的BERT-Stacking模型在大规模网站上的检测性能,我们通过sklearn库中的数据集分割功能,随机的从本文使用的数据集Dataset-10中筛选出一个5万级的数据集Dataset-5。我们首先在Dataset-5的训练集上训练本文的模型,并在Dataset-5上验证其精度,另外,我们将Dataset-5的测试集与Dataset-10剩余的数据集合并,将其作为Dataset-10数据集的测试集,并在该测试集上验证模型精度,实验结果如表7。

表7 BERT-stacking模型在不同规模数据集的性能表现
由表7可以看出,模型在5万级数据集的测试集上已经取得较好的检测结果,当测试集扩大到10万级后依旧可以保持较高的检测精度,说明本文提出的模型具有较好的泛化能力,可以在大规模网站中检测钓鱼网站。
3 结 语
本文基于BERT设计了一种HTML字符串嵌入特征,将网站HTML文档转化为多维向量,并结合网站URL特征共同表征网站特征。另外,经过实验筛选,将DF、XGBoost、LightGBM、GBDT通过集成学习组成一个Stacking模型,利用HTML字符串嵌入特征和URL特征深度挖掘网站特征从而检测钓鱼网站。实验结果显示,本文提出的Stacking相较于单个基学习器在各指标上均有明显提升。另外,本文基于BERT本文设计的HTML字符串嵌入特征对于检测钓鱼网站具有很高的检测精度。在未来的工作中,我们将使用相似的方法进一步提取URL特征,进一步优化设计特征的流程。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
计算机与网络(2018年10期)2018-02-15 09:06:37
数学物理学报(2017年5期)2017-11-23 07:51:31
中国知识产权(2015年9期)2015-05-30 10:48:04
燕山大学学报(2014年1期)2014-03-11 15:28:11
新课程学习·中(2013年3期)2013-06-14 05:55:20
测绘科学与工程(2013年6期)2013-03-11 15:07:57
互联网天地(2012年6期)2012-03-24 07:52:48
网络安全与数据管理(2011年17期)2011-07-25 00:33:50
