
基于数据增强深度学习的苹果花检测方法研究*
2022-05-17 14:48:38陈国防陈兆英王玉亮王金星范国强李汉卿
中国农机化学报 2022年5期
陈国防,陈兆英,王玉亮,王金星,范国强,李汉卿
(1. 山东农业大学机械与电子工程学院,山东泰安,271018;2. 山东省园艺机械与装备重点实验室,山东泰安,271018)
0 引言
苹果产业,是我国极为重要的果业品种之一,对我国的果业经济、进出口创汇等有着重要影响。苹果花的开花强度(生长早期果园的花朵数量)与果实数量和果实品质之间有着很大的关系[1],适当的疏花可提升果实的产量和品质。但目前在自动疏花方面的研究进展还有限,通常是随机选取果园内的果树,通过人工观察进行开花强度估值。因此,将现在较为先进的计算机视觉技术应用于苹果花的检测,不仅对促进疏花机器人的发展具有重要意义,而且可以提高疏花效率和果农的经济效益[2-3]。
近年来,随着深度学习技术的深入研究,卷积神经网络在农业领域图像识别中的应用不断深入。Kapach等[4]研究分析了在水果采摘机器人视觉领域的各种方法的优劣性。张星等[5]研究了基于YOLOv3的菠萝拾捡识别方法。李龙等[6]研究了基于纹理和梯度特征的苹果伤痕与果梗/花萼在线识别方法。Dias等[7]提出一种称为CNN+SVM的苹果花识别检测方法。王丹丹等[8]研究了基于R-FCN深度卷积神经网络的机器人蔬果前苹果目标检测方法。Yu等[9]使用Mask R-CNN进行草莓检测以及成熟度估计。熊俊涛等[10]提出了一种Des-YOLOv3算法,可实现夜间成熟柑橘的识别与检测。
以上研究大部分都集中在成熟水果的检测与识别上,但很少有针对结果之前苹果花检测的研究应用。针对这些问题,深度学习可以更好的提取苹果花的识别特征,结合数据增强的方法,能有效解决苹果花识别困难的问题。基于此本研究提出基于数据增强深度学习的苹果花识别检测方法,使用在线数据增强与离线数据增强等方式,针对YOLOv4网络模型进行研究和提升,为果园的化学疏花与机械疏花提供有益的理论基础与参考。
1 材料与方法
1.1 数据采集
试验所用的苹果花图像在(国家苹果工程技术研究中心)山东省果树研究所天平湖试验示范基地苹果园采集。试验区中心经度和纬度分别为东经117°1′33″和北纬36°13′1″。该试验区主要种植富士与王林两个品种的苹果,种植方式均为矮砧密植型。
图像采集设备为佳能CanonEOS80D相机,相机有效像素为2 420万。拍摄试验数据为盛开的苹果花的正面、侧面和遮挡等图像,拍摄于2021年3月29日—4月13日。为了取得更全面的苹果花图像,选取拍摄时间为每天的8:30~9:30、11:00~12:00、15:00~16:00三个时间段,连续随机拍摄试验区内的苹果花。拍摄时分为远景和近景,远景、近景相机镜头分别距离苹果花拍摄目标100~150 cm和30~50 cm,按行间两侧不同方向进行拍摄。
1.2 试验平台
为验证本文提出方法的有效性,本试验基于Windows10x64操作系统,深度学习库采用Tensorflow搭建,编程语言使用Python,软件平台为Windows10+tensorflow2.4.1+CUDA11.0+ cuDNN8.0.5 + VS2019+PyCharm。硬件平台为Intel(R)Core(TM)i7-10700F2.9 GHzCPU+32 GB内存+一个NVIDIAGeForceRTX3060 12 GB GPU和1.5 TB的存储容量。数据集标注软件使用LabelImg。
1.3 建立数据集
试验中,由于果园中每棵苹果树所包含的苹果花图像的特征信息不一致,因此在果园中随机选取了60棵树,通过在行间两侧拍摄与远近景拍摄的方式,实地拍摄苹果花图像共974幅,如图1所示。




(a) 近景苹果花图像1 (b) 近景苹果花图像2 (c) 远景苹果花图像1 (d) 远景苹果花图像2图1 苹果花图像示例Fig. 1 Apple flower image example
然后对苹果花图像进行人工标注,图像标记使用LabelImg软件完成。通过包含苹果花的最小矩形框进行标注,标记为XML文件存储格式,并以PASCAL VOC数据集格式进行存储。
2 苹果花识别检测
2.1 苹果花检测模型
2.1.1 YOLOv3网络模型
YOLOv3[11]是YOLO的第3个版本,它通过结合浅层和深层特征来提取有利的特征。随着输出特征图的数量和比例的变化,边界框的比例也会相应调整。YOLOv3采用多个scale融合的方式做预测,使用K-means聚类算法来获得9个尺度的Bounding Box,为每个向下扩展的尺度设置3个Bounding Box预测。13×13的featuremap(特征图)具有最大的感受野,相应的最大预测框适用于检测较大的物体。26×26的featuremap具有中等感受野,相应的中等预测框适用于检测中等大小的物体。52×52的featuremap感受野最小,对应的最小预测框适用于检测最小尺寸的物体。YOLOv3的网络结构,如图2所示。
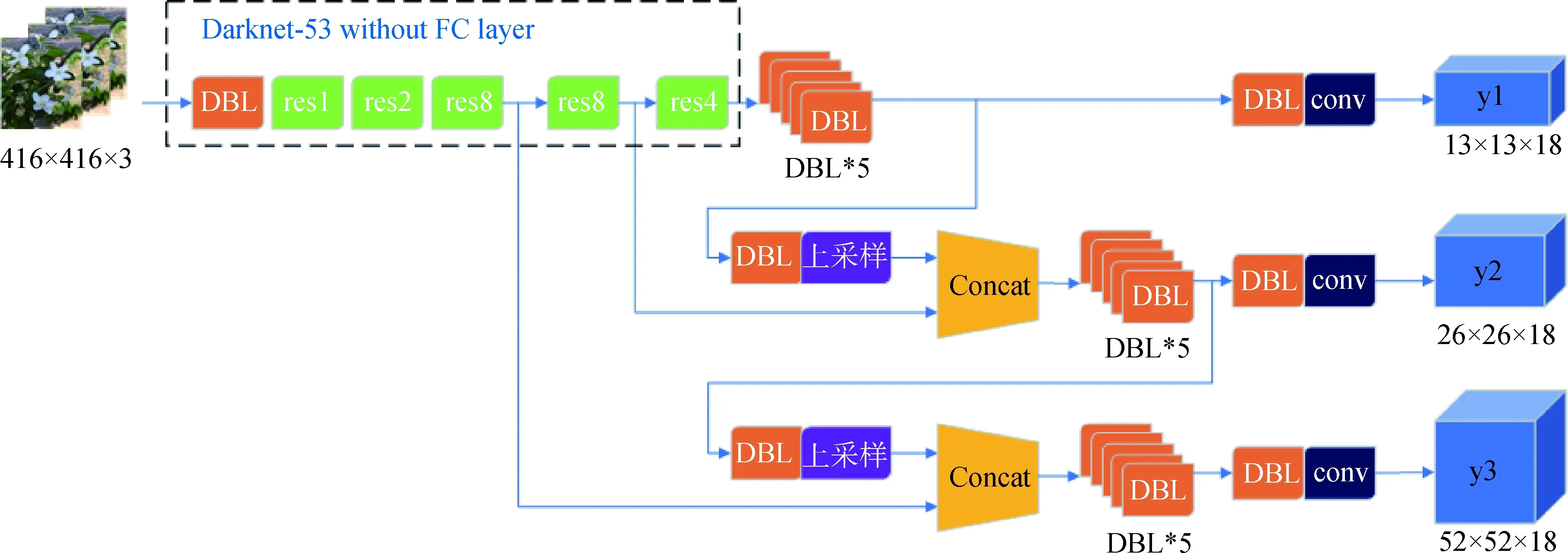
图2 YOLOv3网络结构Fig. 2 YOLOv3 network structure
2.1.2 YOLOv4网络模型
在本研究中,采用的YOLOv4网络与YOLOv3网络相比,本方法在数据处理中引入了Mosaic数据增强。同时,在骨干网络中加入了CSP[12]网络,在Darknet53的残差单元上均加入了CSP,以提高网络的深度学习能力。此外,对网络训练、激活函数和损失函数进行了优化,使YOLOv4更快,实现了准确性和速度之间的最佳平衡。YOLOv4网络结构如图3所示,YOLOv4网络利用神经网络框架CSPDarknet53作为训练和提取图像特征的主干网络,然后将PANet(路径聚合网络)用在三个有效特征层上,实现对提取特征的更好融合[12]。

图3 YOLOv4网络结构Fig. 3 YOLOv4 network structure
本算法使用CSPDarknet53作为其骨干网络,主要由DBM模块和CSPResNet模块构成,DBM模块由卷积层(Conv)、批归一化层(Batch Normolization,BN)和Mish激活功能组成。本算法将以往残差块的堆叠拆分成两部分,为CSP Net结构形式:主干部分进行传统的残差块堆叠操作,另一部分几乎不经过计算,像一个残差边一样与主干部分计算后的结果进行拼接[12]。通过对两部分的跨级拼接与通道整合,增强卷积神经网络的学习能力。CSP结构如图4所示,其中part1部分与YOLOv3的网络结构相同,part2部分则几乎不经过计算与part1计算后的结果进行拼接。CSPResnet相比Resnet提高了计算速度。

图4 CSPResNe(X)t网络结构图Fig. 4 CSPResNe(X)t network structure diagram
另外,本算法在检测部分使用了空间金字塔池化层SPP模块,解决输入图像尺寸不统一的问题。在边界框的预测方式上利用K-means聚类生成不同尺度的先验框,并在不同层级的特征图上进行预测,同时采用PANet对不同层级的特征进行融合。
2.2 优化YOLOv4网络模型
2.2.1 优化边框回归损失函数
在YOLOv4网络模型的基础上,选用损失函数CIOU代替MSE,改进损失函数,提高目标框回归的稳定性。损失函数主要分为三大部分:边框回归损失、置信度损失以及分类损失,YOLOv3的损失函数[13]如式(1)所示。
(1)
式中:λobj——当前网格是否存在物体,取值为0或1;
tω——真实框的宽度;
th——真实框的高度;
tr——真实坐标损失;
pr——预测坐标损失;
tclass——真实分类;
pclassr——预测分类;
tconf——真实置信度;
pconf——预测置信度。
YOLOv3目标检测模型进行边框回归时,MSE(均方误差)损失函数直接根据预测框和真实框的中心点坐标和宽度、高度信息进行设置。本试验中选用损失函数CIOU代替MSE,其他两个部分不做实质改变。几种典型的损失函数分别定义如下。
1)IOU损失。IOU[14]损失定义为1与预测框A和真实框B之间交并比的差值。
LIOU=1-IOU(A,B)
(2)
IOU损失函数在bounding box没有重叠时不提供滑动梯度,只在它们重叠的时候才有效。
2)GIOU损失。GIOU[15]在原来的IOU损失的基础上增加一个惩罚项,以缓解IOU损失在检测框不重叠时出现的梯度问题,如式(3)所示。
(3)
式中:A——预测框;
B——真实框;
C——A和B的最小包围框。
A,B,C的关系,如图5(a)所示,惩罚项的含义为图5(b)中黄色区域与C的面积的比值。

(a) bounding box关系图

(b) 惩罚项图5 GIOU边框回归损失Fig. 5 GIOU loss for bounding box regression
3)DIOU损失函数。DIOU在GIOU的基础上考虑了中心点的距离。GIOU是通过增大和移动预测框,直到预测框与真实框有重叠然后才能进行式(3)中IOU(A,B)的计算。这将消耗大量的时间在预测框尝试与真实框接触上,影响损失的收敛速度。为此DIOU损失也多出一个惩罚项,增加了对中心点距离的考虑,如式(4)所示。
RDIOU=ρ2(Actr,Bctr)/c2
(4)
式中:Actr——预测框中心点坐标;
Bctr——真实框中心点坐标;
ρ——欧式距离;
c——A,B最小包围框的对角线长度。
所以两个框距离越远,DIOU越接近2;距离越近,DIOU越接近0。
4)CIOU损失函数。本文使用CIOU作为边框回归损失函数,CIOU考虑到anchor之间的重叠面积、中心点距离、长宽比三个几何因素,使得目标框回归变得更加稳定。CIOU的公式如式(5)、式(6)所示。
(5)
(6)
式中:α——权重系数;
υ——长宽相似比衡量参数。
CIOU边框回归损失示意图如图6所示,d=ρ(Actr,Bctr)为中心点坐标的欧氏距离,c为最小包围框的对角线距离。

图6 CIOU边框回归损失Fig. 6 CIOU loss for bounding box regression
α和υ的公式如式(7)、式(8)。
(7)
(8)
式中:ω——预测边界框的宽;
h——预测边界框的高;
ωgt——真实边界框的宽;
hgt——真实边界框的高。
1-CIOU即为对应的Loss函数,如式(9)所示。
(9)
当ω和ωgt、h和hgt一致时,惩罚项便不发挥作用,此时υ为0。所以CIOU的惩罚项可以使ω和ωgt、h和hgt快速拟合。
2.2.2 改进数据增强
为丰富和平衡苹果花图像的训练集数据,以更好的提取苹果花的特征,泛化模型,同时可以减少人工标注的工作量,进行离线和在线数据增强的YOLOv4方法。
本文使用Python程序对标注好的苹果花图像数据集进行离线数据增强。由于受光照影响,拍摄的图像差别较大,使得苹果花图像数据不均衡。所以对图像增强处理,进行旋转图像、裁剪图像、平移图像、镜像图像和加噪声等预处理方式扩充数据集,增强到2 458张数据集图像,并按8∶2划分训练集和测试集。数据增强示例如图7所示。
图7中,右侧为原数据集图像,图7(a)对原图进行水平或垂直镜像;图7(b)对原图进行角度变换;图7(c)为平移图像;图7(d)对原图进行随机裁剪;图7(a)~图7(d)并未改变图像内部信息。图7(e)对原图添加噪声;图7(f)对原图进行亮度增加或降低;图7(e)、图7(f)需要改变图像内部信息。同时对各种增强方式进行了随机叠加以增强数据集的泛化性,且进行裁剪、平移、镜像和旋转时,同时要对bbox进行对应调整。

图7 苹果花数据增强示例Fig. 7 Apple flower data enhancement example
同时,在训练过程中使用在线的Mosaic数据增强,代替传统的CutMix[16]数据增强方式。CutMix数据增强方法是将两张图片拼接,选择一张苹果花数据集图像剪切掉一部分像素,然后再随机选择另一张图片的同样大小部分的像素,将第二张图像的部分区域添加到第一张图像中,如图8所示。

图8 CutMix数据增强结果Fig. 8 CutMix data enhancement results
Mosaic数据增强方式利用4张图片,用来丰富检测苹果花图像的背景,在BN计算时,一次性计算4张图片的数据。Mosaic数据增强方式,每次读取4张图片,然后分别对4张图片进行翻转、平移、缩放、裁剪和色域变化等,并且按照4个方向位置摆好,如图9所示。

(a) 位置1

(b) 位置2

(c) 位置3

(d) 位置4图9 Mosaic数据增强示例Fig. 9 Mosaic data enhancement example
最后,将4张图片按照各自的位置,进行随机裁剪,最终进行图片的组合和框的组合,拼接成一个图像,如图10所示。

图10 Mosaic数据增强结果Fig. 10 Mosaic data enhancement results
3 网络训练与结果分析
3.1 评价标准
为了检验模型的检测性能,本文采用Precision(准确率,P)、Recall(召回率,R)和Average Precision(平均精确度,AP)三个指标[17]作为评价标准对模型进行评估。
准确率P表示模型分类器认为是正类且事实上是正类的部分,占所有分类器是正类的比例,计算公式
(10)
召回率R表示模型分类器认为是正类且事实上是正类的部分,占所有事实上是正类的比例,计算公式
(11)
式中:TP——检测结果为正类且事实上是正类的数量;
FP——检测结果为正类而事实上为负类的数量;
FN——检测结果为负类且事实上是负类的数量。
通过对Precision和Recall各点的组合,最终形成的曲线下面的面积为平均精确度

(12)
式中:P(R)——PR曲线上R对应P的值。
3.2 结果分析
使用YOLOv4网络,并采用2.2.2中的式(9)所示的CIOU回归损失函数,对增强后数据集中的1 996幅训练集苹果花图像进行训练,全局损失函数值的训练误差曲线,如图11所示。可看出,前100次迭代模型快速拟合,进行到350个迭代次数以后曲线趋于平稳,训练模型收敛。

图11 训练误差曲线Fig. 11 Training error curve
为验证该方法的有效性,对数据集图像中的492幅测试集的苹果花图像进行测试,结果如表1所示,本文提出的识别检测方法的准确率为98.07%;召回率为97.56%;平均精确度为99.76%。

表1 本试验模型测试参数表Tab. 1 Test parameter list of this experimental model
微调卷积神经网络各训练参数,多次试验达到所需试验标准。模型对不同苹果花图片实现智能识别,并给出该图片对应的苹果花概率值如图12所示。可以看出本文提出的方法对于不同品种苹果花的聚焦图像和普通图像、近景图像和远景图像均有较好的识别准确性,从图12(d)~图12(f)可看出本文提出的方法对于遮挡、倾斜、重叠、顺光和逆光的苹果花的识别也有效,图12(d)和图12(f)可看出该方法对于完全绽放的苹果花均能准确识别,对于未开放的花苞或者未完全开放的苹果花也会有漏识别出现。
结果表明,尽管存在漏识别的情况,但该方法对苹果花的检测精度较高,满足果园苹果花开花强度识别检测要求,可对苹果园的产量预估和疏花机械的研发提供技术参考,为苹果花的化学疏花决策奠定基础。

(a) 王林近景图像

(b) 富士近景图像

(c) 王林聚焦图像

(d) 富士聚焦图像

(e) 王林远景图像

(f) 富士远景图像图12 苹果花识别检测效果Fig. 12 Apple flower recognition and detection effect
3.3 不同方法识别效果对比试验
本文为进一步验证提出的数据增强YOLOv4苹果花识别检测方法,对果园苹果花目标检测的优势与有效性,在改进模型各项参数的同时,将该方法与目前具有代表性的目标检测模型YOLOv3、YOLOv4和Faster R-CNN在相同数据集下作对比试验[18]。不同算法对苹果花识别检测效果如图13所示,各个识别方法的识别结果的准确率、召回率和平均精确度,如表2所示。

(a) 原图

(b) Faster R-CNN

(c) YOLOv3

(d) YOLOv4

(e) 本文方法图13 不同算法苹果花识别检测效果对比Fig. 13 Comparison of apple blossom recognition and detection results with different algorithms
由表2可知,本文所提出的识别检测方法的AP值最高,相较于Faster R-CNN提高了2.53%;相较于YOLOv3提高了14.56%;相较于YOLOv4提高了5.08%;表明了采用本文所提出的方法进行苹果花识别检测的结果最优。Faster R-CNN在测试集上的平均准确率虽为97.23%,但准确率为74.42%过低,作为较复杂的网络结构,运行时间较长,虽能够提取较深的苹果花特征,但可能会出现过拟合,对图像的泛化能力仍有不足。YOLOv3和YOLOv4在测试集上的平均准确率分别为85.20%和94.68%,在没有改进数据增强的情况下,导致识别准确率仍较低。本文的算法在测试集上的检测时间为105 ms,检测速度虽不是最快,但准确率可达99.76%,相较于Faster R-CNN、YOLOv3和YOLOv4有更高的识别精确度。经上述分析,可得出本文提出的方法实现了精确度和速度之间的最佳平衡。
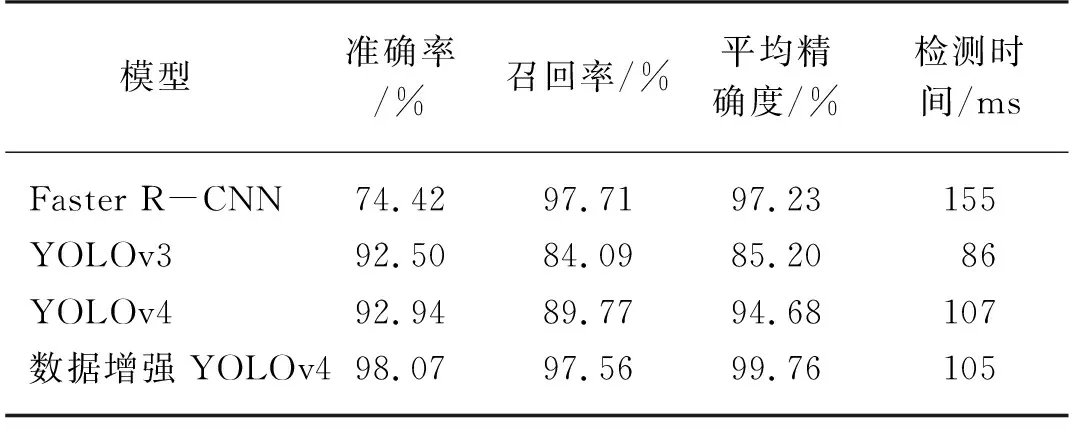
表2 各模型测试参数对比Tab. 2 Comparison of test parameters of each model
4 结论
本文提出了一种基于数据增强YOLOv4的苹果花识别检测方法。
1) 通过构建苹果花数据集,搭建YOLOv4网络框架,在骨干网络中加入CSP网络和PANet结构提高特征提取融合能力,选用损失函数CIOU代替MSE,改进损失函数,并通过离线与在线Mosaic数据增强优化数据增强手段,实现对苹果花的识别检测。对苹果园的产量预估和自动疏花机械的研发提供了技术保证,为苹果花的化学疏花决策奠定了基础。
2) 通过本文提出的方法识别检测苹果花,识别准确率为98.07%,召回率97.56%,平均精确度为99.76%,对苹果花具有较好的识别精准度和识别效果。将本方法对比了Faster R-CNN、YOLOv3和YOLOv4主流网络模型识别方法,对苹果花的平均识别精确度分别提高了2.53%、14.56%和5.08%。
猜你喜欢
科学导报(2023年23期)2023-04-17 19:30:19
幼儿教育·父母孩子版(2023年3期)2023-04-07 20:34:12
农业与技术(2022年24期)2023-01-03 06:08:48
江西教育·职教版(2022年9期)2022-04-29 00:44:03
中国果业信息(2021年7期)2021-12-01 20:20:32
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
作文周刊·小学三年级版(2020年24期)2020-07-17 16:17:45
诗潮(2019年10期)2019-11-19 13:58:55
今日农业(2019年15期)2019-01-03 12:11:33
农家参谋(2017年4期)2017-08-13 10:41:45
