
由形状结构和位姿特征学习的稠密点云重建
2022-05-17 06:01杨永兆张玉金张立军
计算机与生活 2022年5期
杨永兆,张玉金,张立军
上海工程技术大学 电子电气工程学院,上海201620
随着深度学习技术深入发展,3D 感知作为计算机视觉的热门研究方向,吸引着越来越多研究人员。点云作为3D 目标表示形式之一,一直被用于目标三维重建,如自动驾驶、AR/VR、工业控制、医学诊断等。生活中,不仅能从单视角图像预测目标三维形状,而且还能捕捉它的细节信息,但对计算机来说,从单视角图像重建目标的高分辨率三维结构形状是一项较有意义且极具挑战的工作。
基于体素的重建方法是将图像映射到几何模型。在3D-CNNs 的帮助下,从一张2D 图像通过神经网络生成具有规律性、顺序性的3D 体素化占据网格结构。然而,体素在表示3D 结构时,存在着大量物体表面结构性数据,并且3D-CNNs 运算量很大,这给网络训练和预测推理时增加了额外的开销。相比于体素重建方法,点云是一个更加有效的选择。当点云在目标物体表面被采样时,点云中每个点包含着丰富的位置信息。此外,点云还能够有效地捕捉更加详细的目标表面信息,不需要重建目标内部结构形状。但点云的固有属性无序性也给网络在处理点云时带来了挑战,传统CNNs(convolutional neural networks)是用于相对有序的数据分析和处理上,如图像、体素等。最近在这方面的研究工作主要通过设计网络结构和损失函数等方法来处理3D 点云和重建。
然而,现有工作在使用点云作为图像三维重建的描述方法时仍面临些问题。一方面,在重建稀疏点云时,大多方法都是在做2D 特征提取,忽略图像中目标在不同方向视角下的内容特征是不同的,并且网络训练样本数据量较大和输入图像中的每个通道值也具有不一样的特征。因此在稀疏重建后,模型的形状相对有所破损。而重建稠密点云是在稀疏点云基础上完成的,这也在另一方面影响最终稠密重建后的3D 点云模型并没有达到理想状态。
本文围绕上述问题提出一个两阶段重建稠密点云的网络模型。首先在三维重建网络模型阶段,基于双注意力机制构建了提取目标形状特征的2D 图像编码网络,同时构建了基于PointNet++的位姿特征网络学习潜在式3D 点云位姿特征,接着特征融合网络模块对形状和位姿特征融合,通过反卷积的解码网络将融合特征解码为1 024 个稀疏点云模型。在网络模型的第二阶段,本文把第一阶段输出的稀疏点云模型作为稠密点云处理网络的输入,根据PUNet工作思想,本文按照上采样因子为4 的原理生成16 384 个点的稠密点云。最后,在预训练这两个阶段的模型之后,组合这两个模型形成端到端的网络,并且运用深度学习方法微调这个模型获得最终的稠密点云。算法流程如图1 所示。

图1 不同阶段重建点云Fig.1 Reconstruction of point cloud at different stages
1 相关工作
1.1 3D 重建
近年来,越来越多的研究者开始着手研究3D 视觉中基于单张图像的三维重建任务。之前一段时间,在3D-CNNs 的帮助下,研究者们围绕用3D 体素输出去描述重建结果的工作而展开研究。Yang 等人提出一种新的基于生成对抗网络(generative adversarial networks,GAN)的3D-RecGAN,它能够从一张深度图恢复3D 结构。文献[7]探索基于自动编码器网络学习潜在的特征。3D-R2N2是一个令人记忆深刻的方法之一,因为它通过使用3D 长短时记忆网络(LSTM)学习体素数据潜在的描述,然后把单个或者多个2D 图像投影到3D 体素中。
最近,Fan 等人介绍通过使用多层感知器的变体来预测无序点云和一种有效度量两个点集之间损失的方法,其网络最终重建的结果比体素方法要优胜。文献[9]和文献[10]提出从单个图像学习三维重建的自由形式的变形方法。Mandikal 等人提出了一种将图像编码与点云编码相结合的潜在空间学习网络。该方法把图像映射到三维空间并学习三维点云潜在式特征,以提高点云重建精度。Zhang 等人先通过在合成数据集中检索与输入图像相似匹配的点云模型,然后组合点云特征和具有复杂背景的单张图像特征以重建点云。Lin 等人把输入图像合成新的深度图以优化网络并获得更稠密的点云。一些其他工作是用投影、深度图和变形网络等2D 监督方法对部分点云或深度图补全的3D 点云重建。
1.2 点云处理
在无规则空间中,根据点云的无序性和稀疏性原则,在2D 图像中使用的卷积神经网络不能直接处理点云。PointNet首先是在空间转换网络里将无序点云对齐到相应的点云特征中,然后运用了多层感知机模块和全局池化层提取点云全局特征。而PointNet++是在此基础上使用具有层次性特征学习网络结构提取点云全局特征和局部特征。Wang 等人提出了边缘卷积网络结构,通过在点和特征空间中寻找邻近区域去提取局部特征。Wu 等人提出PointConv 和PointDeconv,两种卷积是对2D 空间卷积的一种延伸,使它应用到3D 空间中点云。Yu 等人的PU-Net是对点云做上采样操作的网络。
在前人的工作中,Mandikal等人和Lu 等人分别通过深度金字塔网络和稠密点云生成网络分阶段逐级对稀疏点云稠密重建。首先两个网络在第一阶段重建出稀疏点云模型,然后作为输入送入第二阶段网络,最后在第二阶段网络中分两次增加其稠密化重建,其中每次4 倍的密度,最后生成16 倍稠密点云。然而,本文模型与其有几点不同。首先在三维重建这个阶段,所提出的模型有两个并行输入,且这两个并行输入的网络结构也不相同,每个输入网络是由各自网络结构的特点和其提取什么样的特征而决定。其次在网络结构组成上,文献[19]和文献[20]分别是基于VGGNet编码网络和基于残差注意力编码网络。而本文模型是由基于Dual-Attention图像形状编码网络、基于PointNet++点云姿态编码网络和特征融合网络结构组成的编码网络,同时基于PU-Net的解码网络生成稀疏点云。最后,DensePCR需要训练两次稠密重建网络,一次是从1重建出4点云,接着从4重建出16点云。因此,网络在时空复杂度上比较大,中间需要提供两次Ground Truth。相反,本文网络在稠密点云处理这个阶段只需要一次输入,不需要额外的输入或者输出,因此本文第二阶段的点云处理网络能够直接预测一个16稠密点云(=1 024)。
2 方法
本文目标是要重建高分辨率稠密点云。因此提议模型要从单张RGB 图像中使用稠密点云方法预测密实的几何体形状表面。算法网络结构如图2 所示。从图中可以看出,为了重建出稠密3D 点云并且是从一张单视角RGB 图像,算法需要先重建出稀疏点云,然后在此基础上重建出稠密3D 点云。因而这要求算法模型不仅能从输入图像中学习2D 形状特征内容,还要能感知3D 姿态特征信息。为此把模型分为两个阶段,首先在3D 重建网络阶段生成稀疏点云,接着将稀疏点云作为输入经过点云处理网络产生稠密点云。下面详细描述每个模型组件。
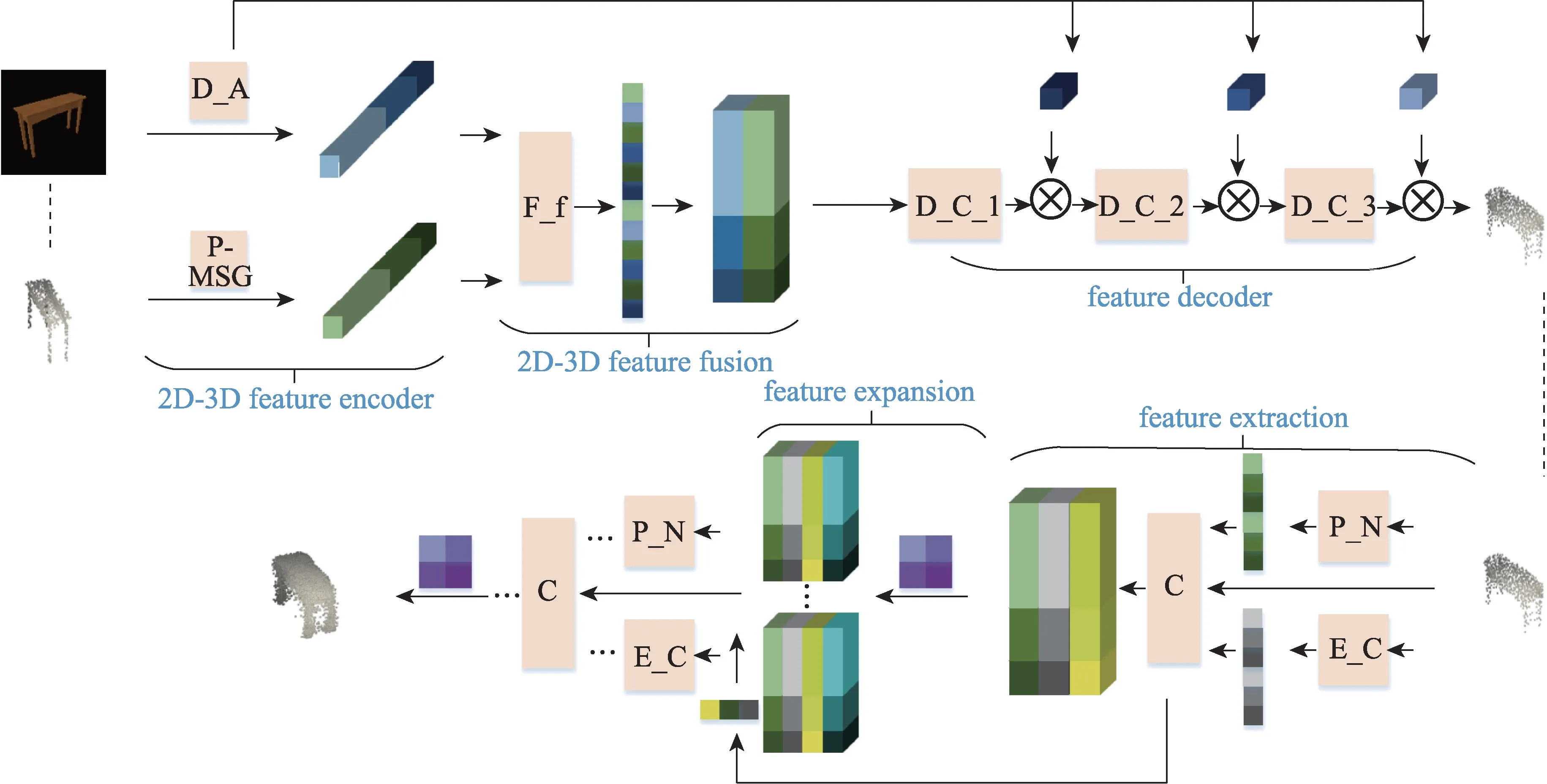
图2 网络整体结构图Fig.2 Overall network structure diagram
2.1 基于图像的3D 点云重建网络
在本文算法第一阶段,稀疏点云产生是基于预训练3D 点云编码网络和残差双注意力机制网络。其中点云编码网络是基于PointNet++模块的编码网络,而基于双注意力机制的残差网络是叠加3 个双注意力机制模块。在3D 点云编码网络结构中,编码器主要学习某个视角下3D 点云中关于图像目标的潜在式3D 姿态特征。而以图像作为输入的残差双注意力网络是学习图像目标的2D 形状特征,通过融合这两种特征形成新的多样性潜在特征。最后由反卷积层和卷积层的相互交替解码网络重建出稀疏点云。详细结构如图3 所示。
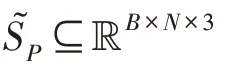
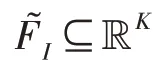
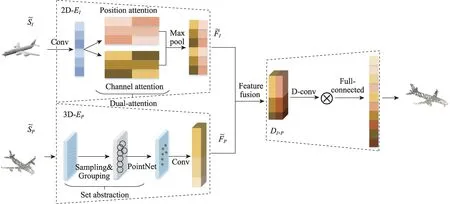
图3 3D 点云重建网络Fig.3 3D point cloud reconstruction network
双注意力机制网络模型由图3 中空间注意力和通道注意力两部分组成。因为实验输入是RGB 图像,如果只对图像单通道特征分析而忽略其他通道特征,那么图像中的一些隐含信息可能被忽略。借鉴隐写术思想,本文基于双注意力网络模型构建残差双注意力模块,不仅可以关注去除背景后图像目标的形状特征,还可以自适应包含不同通道之间特征依赖性,其相关必要性分析也可在实验3.4 节中可见。图3 中Position attention 是空间注意力网络,其主要对卷积后新特征和计算相应矩阵乘法获得空间注意力特征图,然后特征图和第三分支卷积特征再做乘法运算,最后与原始特征加权求和。上述过程可以用公式表示如下:
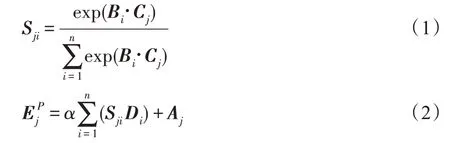
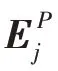
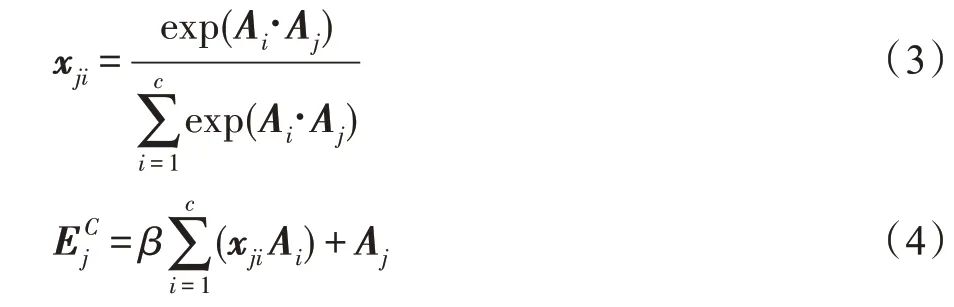
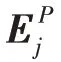
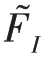
基于U-Net结构,算法的解码器(D)由卷积、反卷积和全连接层组成。以往的方法中使用全连接层作为解码器的组成部分,但是与全连接层相比,基于U-Net 的反卷积解码器和编码器相结合,从而增强特征。并且反卷积与卷积是对称操作,将编码网络的特征信息加入解码网络中,这样通过它可以逐级恢复不同尺寸细节信息特征。例如,图像编码网络中2D 形状特征是图像目标部分结构信息,而点云编码网络中3D 姿态特征是目标的三维结构特征,这样不同成分特征都是重建稀疏点云的重要组成部分,相应每个细节特征都不能缺少。最后通过全连接层输出重建稀疏点云的尺寸1 024×3,其张量形式是(,1 024,3)。
2.2 稠密点云生成网络
算法第二阶段是当给定稀疏点云时,模型可以有效生成稠密点云。因此本文在前人的基础上重新引入稠密点云生成网络。图2 和图4 中,3D 重建网络的输出被送入稠密点云处理网络后,首先对其特征提取,在获得点的全局特征和局部特征融合后,算法把相关点特征送到采样因子为4 的上采样网络中,然后对融合点云特征做上采样处理操作,同时引入网格变换使得生成点能够均匀分布形成4 倍稠密点云。然后重复执行上述网络生成16 倍稠密点云。
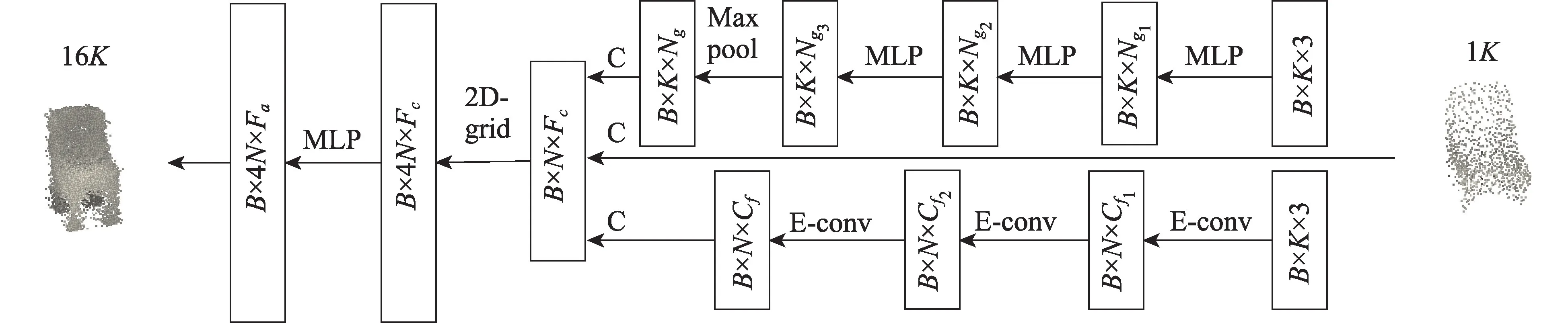
图4 稠密点云生成网络Fig.4 Dense point cloud generation network
为了能让稠密点云表面均匀,模型对稀疏点云提取全局特征和局部特征。如图2,图中P_N 网络是基于PointNet网络模块,采用类似MLP 结构处理点云上每个点的特征。并且该结构是由一个共享MLP操作集组成,然后对称式最大池化层应用在最后一层将特征平铺。当输入1×3(=1 024)稀疏点云时,一组共享MLP 卷积是对点云中每个点做卷积计算,最后逐点式池化层获得了全局特征向量,其特征维度为(,,N),而每个点维度为1×N。 N是MLP 最后一层的卷积核数量,是点的数量,是batch_size。然而PointNet++是通过FPS(最远点采样)对点云中独立区域点采样,这对于计算全局特征复杂度高,并且点与点之间相关性没有考虑。本文根据文献[17]和文献[20],在特征空间中通过KNN 算法计算采样点距离建立局部相邻区域,接着边缘卷积学习其局部特征。与FPS 不同,KNN 简单易用且适用于数量多的点,同时文献[20]和本文实验也说明,在特征空间中采用KNN 计算局部相邻的方法与采用FPS 计算局部特征的DensePCR相比是有效的。当输入给定点云形状是×3 或者×F,通过对输入点云中每个点的局部相邻域使用一组边缘卷积,获得了包含全部特征的张量,其形状为×C。其中,F是输入点云中点的特征维度,C是最后一组边缘卷积的卷积核数量。最后把全局特征、局部特征和输入点云的原始特征通过级联的方式获得级联特征,其特征向量形状为×F。最后把这个特征送入点云上采样网络。
点云稠密化采样是在上采样因子为4 的网络中对先前特征向量重建出维度是4×F的新特征向量,其中F=3+C+N。同时为了防止点在稠密化过程中出现簇拥在一起,算法把个2D 坐标网格应用到上采样点和重叠点。通过改变2D 网格从2×2到4×1,让其维度与现有的tensor 维度一致。这样,网络可以在不使用排斥损失的情况下,学习拟合稠密点云,并且引导重建稠密的点分布在目标曲面周围,而效果可视化分析可见实验3.5 节描述。在2D 网格帮助下,每个点获得了4×1 的网格特征。最终输入的级联特征向量在一组共享MLP 稠密处理后生成4×F稠密点云,其中F=3+C+N+1。
3 实验
本文从定量和定性两方面评估提议方法。除了与先前工作比较外,本文也分析了算法模型中各个组成成分的重要性。
3.1 数据准备
ShapeNet 数据集被用于训练和评估本文算法性能。它是由ShapeNet和WordNet组织的三维CAD模型集合。ShapeNet 包含来自13 个目标类44 000 个模型,每个模型从24 个不同方向角度预渲染成24 张2D 图像。作者将图像裁剪到128×128 分辨率,然后作为输入再通过网络传输。在本次实验中,所有训练测试数量按5∶5 比例进行。为了产生Ground Truth点云,使用最远点采样算法对模型表面均匀地采样成1、4和16点云,其中=1 024。
3.2 评价指标
近年来,在3D 重建领域,CD(Chamfer distance)和EMD(earth move's distance)已经成为两个重要广泛使用的评估方法。因此,本文记录CD 和EMD度量值作为模型定量评估结果。CD 作为损失函数表达为:
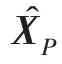
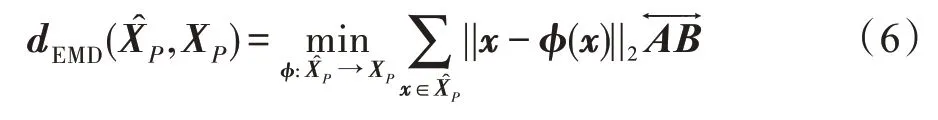
3.3 对比实验
本文考虑DensePCR和AttentionDPCR作为本次对比实验,对于稠密点云重建生成。复现它们在相同数据集和5∶5 训练、测试比例,这样为了公平对比。由于这两个实验方法与本文算法类似,它们也是由两个阶段的网络组成稠密点云重建网络,因此本文也考虑稀疏点云重建阶段各自网络模型的不同,把本文算法在稀疏点云重建的实验结果和DensePCR、AttentionDPCR 进行对比。这样可以验证形状和位姿特征学习对于稠密点云重建的有效性。
3.4 消融实验
为了分析网络模型中不同组件重要性,本节进行了消融实验。考虑到实验复杂性,实验在稀疏点云重建下进行。图5 是在3D 重建模型基础上把双注意力网络换成单注意力机制和在此基础上去除位姿特征网络模块、特征融合网络结构后绘制不同网络结构的CD/EMD 结果图。3D 重建模型主要包括形状特征网络模块、位姿特征网络模块和特征融合网络结构。具体的“d_a+p”是完整模型,“d_a”是只有双注意力的形状特征网络,“a+p”是单注意力的形状特征网络、位姿特征网络和特征融合结构的组合,“a”是只有单注意力形状特征网络。对于本文方法引入双注意力机制的必要性分析,由图5 可以看到,“d_a+p”的平均CD/EMD 值低于“a+p”,说明双注意力网络模型比单注意力机制的效果较好;其次,在去除位姿特征和融合网络结构后,由图5 结果可以说明位姿特征网络和特征融合网络结构能更好地提升点云重建效果。
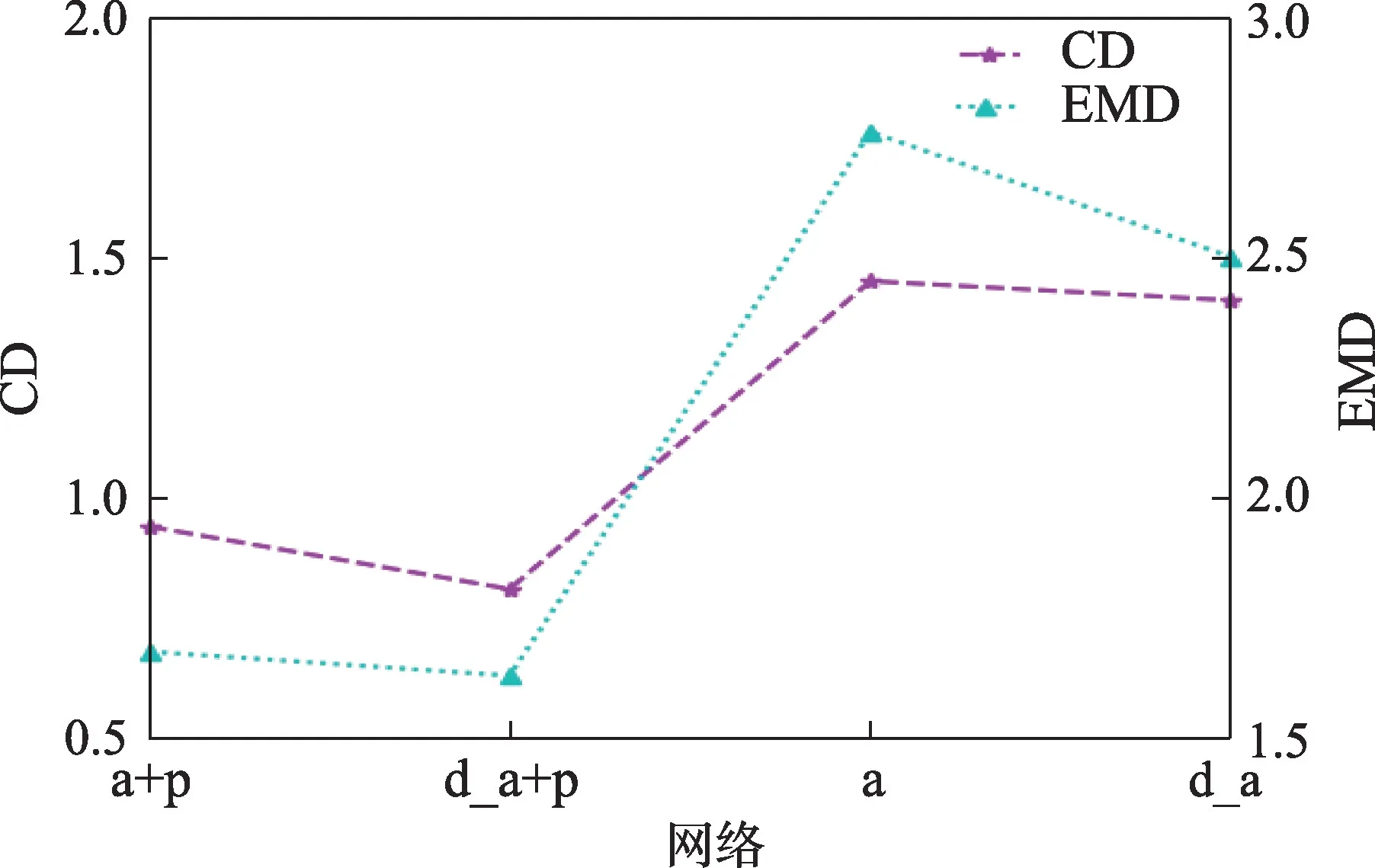
图5 3D 重建网络的消融研究Fig.5 Ablation of 3D reconstruction network
3.5 在ShapeNet数据集上评测
本文在ShapeNet 数据集上评估算法有效性。把单个RGB 图像作为输入,然后在稀疏点云重建网络作用下生成1(=1 024)点云,接着经过稠密点云处理网络生成一个16稠密点云。为了与DensePCR、AttentionDPCR 相比较,和其在第一阶段相比较的结果详见表1。在表1 中本文记录了3 个模型对稀疏点云重建的结果,并且本文也给出提议算法在重建稀疏点云时部分定性结果,如图6 中可视化图片。从定量和定性结果中可以验证本文算法要胜过另外两个重建稀疏点云方法。虽然本文方法在稀疏重建定性结果方面有些不完整的地方,但结果中整体形状和中间Ground Truth 相比还是较接近。对比实验数据都是在相同的epoch 条件下得出。相反地,根据之前文献呈现数据和对比仿真实验数据观察,DensePCR和AttentionDPCR 在与原先8∶2 比例的实验数据结果相比有明显下降现象。本文推测DensePCR可能对于样本的依赖程度比较高,而AttentionDPCR 与原先结果有相反的变化,可能归因于引用了注意力机制。表2 是在预训练稀疏点云重建网络和稠密点云处理网络上最终Finetune 的结果。从表中看到在13 个类中,提议方法除其中4 个类的CD 值比AttentionDPCR对应类的CD 值高0.002 外,其余类的CD 值和所有EMD 值都低于DensePCR 和AttentionDPCR。同时为验证提议模型稠密重建效果和对其可视化分析,本文对重建结果进行可视化,并和DensePCR、Attention-DPCR 在如图7 中做重建效果定性对比。从图7 可以看到,相比其他两种对于目标结构形状和表面细节重建方法,提议模型获得了不错效果。双注意力编码结构使得网络更加关注目标形状结构,例如椅子、台灯和长椅的整体主干形状;而通过位姿特征学习使网络加强对椅子的腿、扶手和台灯底座等一些细节预测的描述。并且从图7 也可以看出模型重建点云效果与表2 中定量结果的CD/EMD 值成正相关。另外,也从点云Ground Truth(G.T)和Predicted(Pre.)的可视化图像做相似性度量分析。具体是用图7 中G.T 的可视化二值图像与不同方法预测的可视化二值图像分别做均方误差值计算,其计算相应度量值如图8 所示。如果均值低可以说明两个图像相似度高,从而相应点云之间的相似度也比较接近。从图8可以看出,本文提议方法的度量值比其他两个方法的度量值较低,因此可侧面反映出本文方法引导重建点云效果要稍优于前两者方法。DensePCR 在重建稠密点云时,过多的噪点和没有聚集性的点分布在模型周围,使得三维模型变形或者重建不出完整模型。AttentionDPCR 在重建效果图中也并没有表现出其模型相关性,在表2 中虽有几个类的CD 值低于本文方法中相应类的CD 值0.002,但其模型生成的稠密点云与之CD 值成相反关系。在5∶5 比例样本下,本文算法模型结果都胜过前两者,从结果可以验证由形状和位姿特征学习对重建点云是有效的,并且也从侧面反映出本文算法对于小样本数据训练的鲁棒性较好。另外,本文也探索了方向角度对模型性能影响。按照官方给定24 个渲染角度扩充采样实验数据中Ground Truth 内容,同时设置每个G.T 和其对应图像角度一致的训练、测试实验方式。因考虑到实验复杂性,这部分实验是在稀疏点云重建阶段进行。度量结果可见表3。观察表3 发现,本文模型在方向角度对齐的条件下,CD/EMD 值相比没有方向角度对齐的条件各提升0.2 左右。其次,实验数据也可说明方向角度对于点云重建有些影响,同时本文方法在方向角度条件下对于点云重建性能有点提升。除了上述模型外,本文方法也有失败案例,分析认为模型从预测稀疏点云时与Ground Truth 有些距离,接着在进行稠密处理时,稠密重建网络对于稀疏点云的特征无法从输入中获得,即使在后面2D 网格作用下也无法使得点与点之间相关性得到很好的联系。

图6 稀疏点云重建结果Fig.6 Reconstruction results of sparse point cloud

图7 各种算法在ShapeNet上定性结果比较Fig.7 Comparison of qualitative results of various algorithms on ShapeNet
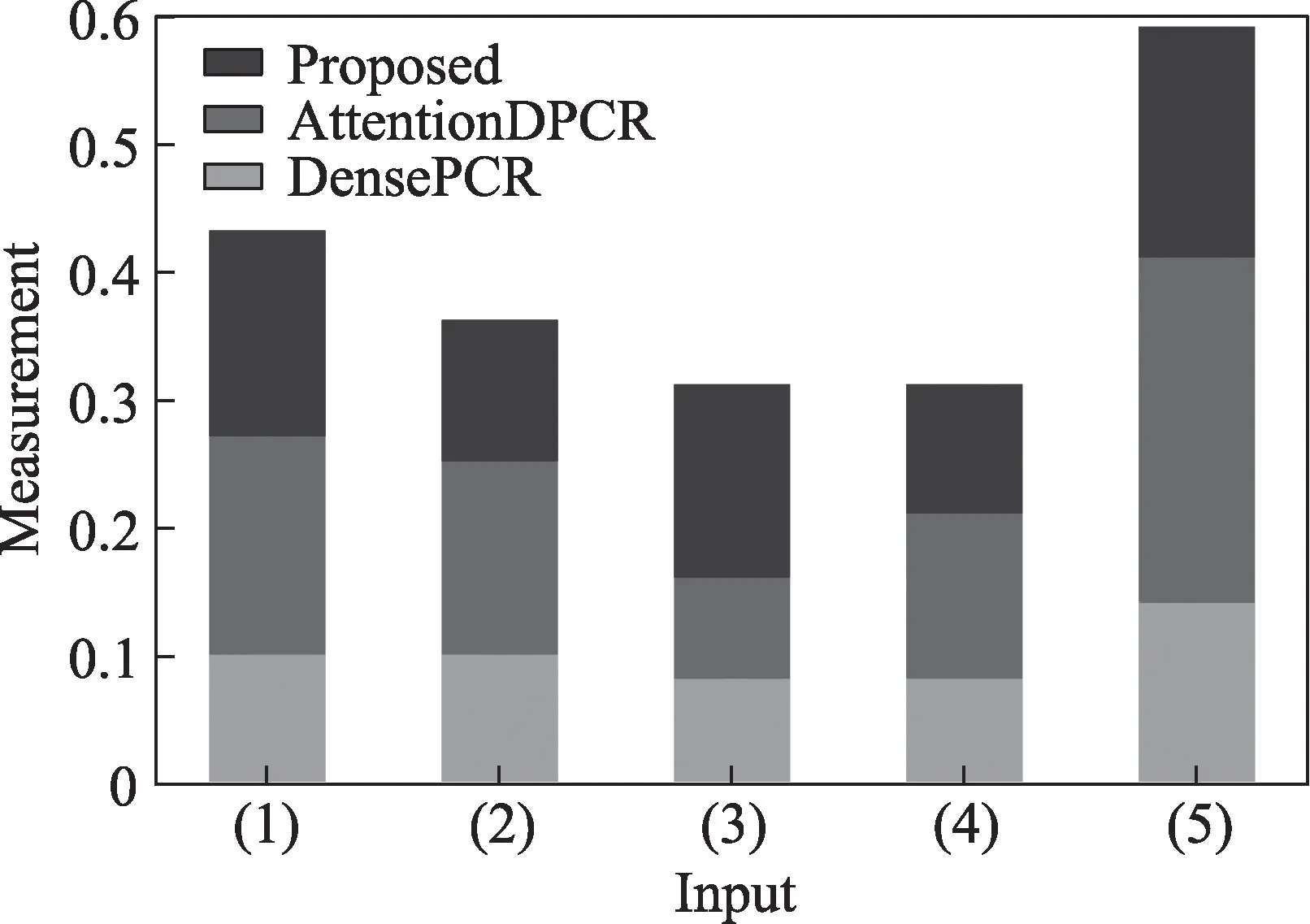
图8 各种算法与Ground Truth 相似性度量结果比较Fig.8 Comparison of similarity measurement results between various algorithms and Ground Truth
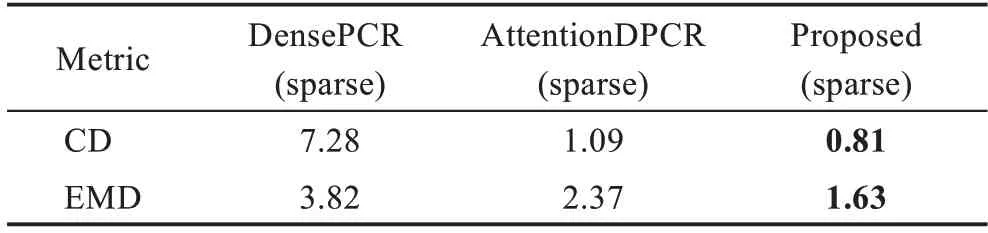
表1 与DensePCR、AttentionDPCR 在sparse阶段的比较Table 1 Comparison with DensePCR and AttentionDPCR in sparse phase
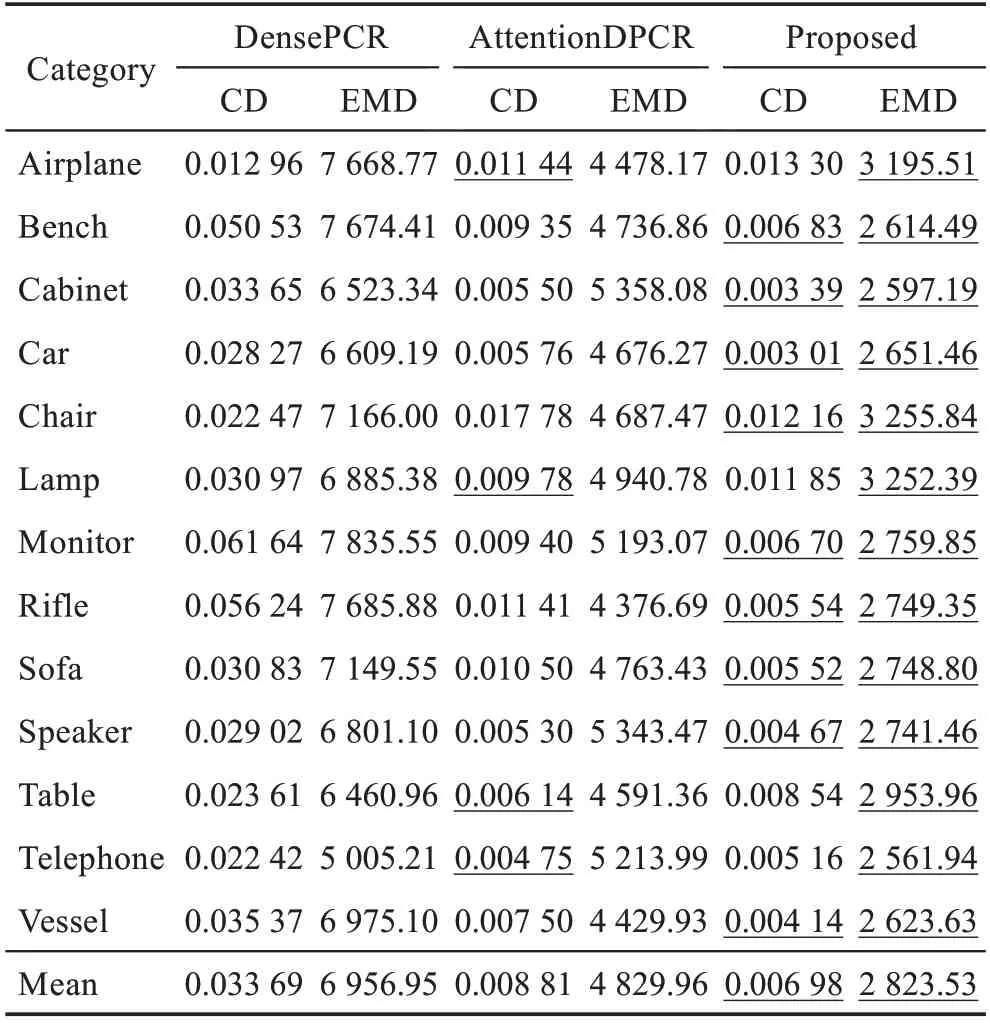
表2 各算法在ShapeNet上定量结果比较Table 2 Comparison of quantitative results of various algorithms on ShapeNet

表3 提议模型在有无方向角度下定量结果比较Table 3 Comparison of quantitative results of proposed model with or without angle
3.6 在Pix3D 数据集上评测
为了验证模型算法在真实图像Pix3D数据集上泛化能力和鲁棒性表现,在Pix3D 数据集上评估本文方法性能。Pix3D 数据集由大量的现实图像、相关的mask 图像和3D Ground Truth 模型组成。在Shape-Net 数据集上训练提议模型,然后直接在Pix3D 数据集的chair、sofa 和table 这3 个类上做测试。因为这3个类也都重复出现在ShapeNet 数据集上。在测试之前,排除这3 个类中有遮挡、截断的图像,然后用它提供的mask 掩盖住每张关联图像的背景,最后裁剪至128×128 分辨率大小的形状作为网络输入。表4 包含本文方法和对比方法在Pix3D 上CD 值和EMD 值的测评结果。从结果看出,本文除了在chair、table 两个类中CD 值稍低0.01 以外,其余CD 与EMD 值都胜过DensePCR、AttentionDPCR。而从图9 定性结果得知,本文模型对于单张真实图像的点云重建效果和模型泛化能力与DensePCR、AttentionDPCR 相比稍优胜,而且也可以看出本文模型的定量结果与定性结果成正相关。DensePCR 对于样本量的依赖性可能比较大,其CD 和EMD 值都比较大,且从定性结果同时得出模型对于目标的三维轮廓、形状结构重建不够完整。AttentionDPCR 在定量结果中虽有两个类的CD 值稍高0.01,但是其模型对于点云重建的定性结果与之成相反关系。

表4 各算法在Pix3D 数据集上定量结果比较Table 4 Comparison of quantitative results of various algorithms on Pix3D dataset

图9 各种算法在Pix3D 数据集上定性结果比较Fig.9 Comparison of qualitative results of various algorithms on Pix3D dataset
4 结束语
本文提出一个将目标2D 形状特征与3D 位姿特征融合分阶段重建稠密点云的网络模型。在这个模型中,首先基于双特征提取构建点云重建编解码网络和重新引入稠密点云生成网络,然后分别预训练这两个模型,最后finetune 这两个模型形成端到端的网络。本文在公开数据集ShapeNet 和Pix3D 上将本文算法和现有工作进行对比,定量和定性两方面结果显示本文算法的性能优于一些现有工作。从实验结果也可以看出,本文与现有工作的不足,即对目标重建的分辨率还不够高,目标中纹理信息还不能够完全表示出,且模型在训练过程中易受到光照、方向角度、模型表面复杂程度等因素的影响。在今后的工作中,将提高本文算法对目标内容的学习,减少其他因素的影响,提高模型的鲁棒性。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
甘肃教育(2020年22期)2020-04-13
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
小天使·五年级语数英综合(2016年12期)2016-12-09
第二课堂(课外活动版)(2016年2期)2016-10-21
小朋友·聪明学堂(2015年7期)2015-11-30
中学生英语·中考指导版(2008年6期)2008-12-19
