
结合信息论和范数的并行随机森林算法
2022-05-17 06:01毛伊敏耿俊豪
计算机与生活 2022年5期
毛伊敏,耿俊豪
江西理工大学 信息工程学院,江西 赣州341000
分类算法是一种有监督的学习算法,它能够根据有标记的信息发现分类规则、构造分类模型,从而预测未含标记的数据属性特征。在分类算法中,随机森林(random forest,RF)以其具有稳定性强、对噪声和异常值有较好容忍性等特点,近年来已被应用于文本分类、环境预测、信用评估、生物信息、医疗诊断等领域,受到人们的广泛关注。
随着信息技术和网络技术的发展,大数据成为研究热点,相较于传统数据,大数据具有4V 特性——Volume(数量大)、Variety(种类多)、Velocity(速度快)、Value(价值密度低),这使得传统随机森林算法在处理大数据时所需运行时间较长,内存容量较多,且通过提升计算机硬件水平来满足人们对大数据分析与处理的需求,显得尤为困难。此时并行化的计算思想变得非常重要,通过改进传统的随机森林算法并与分布式计算模型相结合成为当前研究的主要方向。
近年来在大数据处理方面,Google 开发的Map-Reduce 并行编程模型由于操作简单、自动容错、扩展性强等优点深受广大学者和企业的青睐。同时,以Hadoop、Spark 为代表的分布式计算架构也受到了越来越多的关注。目前许多基于MapReduce 计算模型的随机森林算法已成功应用到大数据的分析与处理领域中。其中,基于MapReduce 的并行化随机森林算法MR_RF,采用分而治之的思想,调用Map-Reduce 模型将数据分区后传递给多个计算节点构建基分类器,汇聚每个计算节点输出的基分类器得到随机森林模型。接着,再次调用MapReduce 模型,利用构建好的随机森林对测试集进行预测得到分类准确度,实现了随机森林算法的并行化,但该算法前后调用两次并行化框架,中间结果多次的读出和写入,消耗了大量的时间。为了降低MR_RF 算法的时间复杂度,钱雪忠等人提出了一种改进的MR_RF算法,利用袋外数据直接计算出分类模型的泛化误差,以此判断随机森林的分类准确率,减少了调用并行框架的次数。然而在大数据环境下,数据集中大量的冗余以及不相关特征降低了构建随机森林模型时决策树所选特征的质量,进而影响了随机森林模型整体的分类准确度。
为降低大数据集中的冗余与不相关特征对模型的影响,Chen 等人提出了一种并行随机森林算法(parallel random forest,PRF),通过计算特征信息增益率的方式,选出最优的个训练特征与其余训练特征随机搭配,对训练特征降维,并利用袋外数据作为训练集计算出每棵决策树对应的分类准确度作为权重,用于模型预测阶段。虽然PRF 算法优化了训练特征,提升了随机森林的分类准确度,但没有减少数据集本身冗余与不相关特征的个数,故生成的训练特征集依然还有较多的冗余与不相关特征;针对以上情况,Hu 等人提出了一种基于最大信息系数的并行随机森林算法PRFMIC,通过计算最大信息系数将特征分为三个区间,删除低相关区间的特征,选取高相关区间和中相关区间内的特征组成特征子集,并行构建随机森林模型,算法虽然考虑到了不相关特征对随机森林模型的影响,但数据中存在的冗余特征在随机森林建模阶段非但不能提供有效的信息,而且增加了决策树与决策树之间相关性,影响随机森林模型整体的准确度;此外,上述算法在生成训练特征集时未考虑到训练特征的信息量,由低信息量的训练特征集训练出的决策树影响了随机森林整体的准确度;同时,算法在预测分类阶段,由于负载不平衡造成该阶段所需时间过多,影响了随机森林整体的并行化效率。如何减少大数据集中冗余与不相关特征,如何提高训练特征信息量以及如何提升算法的并行效率等仍然是目前亟待解决的问题。针对这些问题,本文提出了基于信息论和范数的并行随机森林算法(parallel random forest algorithm based on information theory and norm,PRFITN)。首先,该算法基于信息增益和Frobenius 范数设计了一种混合降维策略DRIGFN(dimension reduction based on information gain and Frobenius norm),获得降维后的数据集,有效减少了冗余及不相关特征数;此外,算法提出了一种基于信息论的特征分组策略(feature grouping strategy based on information theory,FGSIT),根据FGSIT 策略将特征分组,采用分层抽样方法,保证了随机森林中决策树构建时特征子集的信息量,提高了分类结果的准确度;最后,考虑到集群负载对并行算法效率的影响,在Reduce 阶段提出了一种键值对重分配策略(redistribution of key-value pairs,RSKP),获取全局的分类结果,实现了键值对的快速均匀分配,从而提高了集群的并行效率。实验结果表明,该算法在大数据环境下,尤其是针对特征数较多的数据集有更好的分类效果。
1 算法及相关概念介绍
1.1 相关概念介绍
(信息增益)已知离散变量和其对应的类别,则信息增益(;)由下式计算:

其中,()为关于类别的信息熵,(|)为关于变量和类别的条件熵。
(互信息)已知离散变量、,则互信息(;)由下式计算:
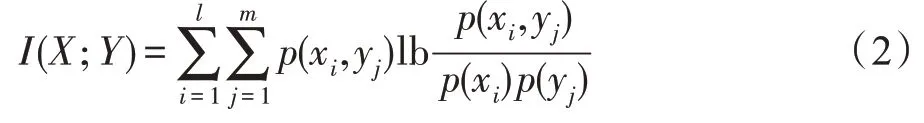
(条件互信息)已知离散变量、以及它们对应的类别,则条件互信息(;|)由下式计算:
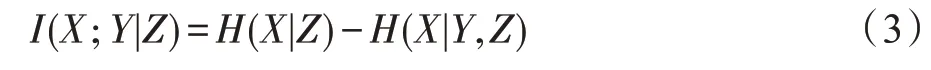
其中,(|) 为关于变量和类别的条件熵,(|,)为关于变量、和类别的条件熵。
(Frobenius 范数)已知=(a)∈R为一个×维的矩阵,a为矩阵中的元素,则Frobenius范数||||可以由下式计算:

1.2 相关算法介绍
主成分分析算法(principal component analysis,PCA)是一种降维的多元统计方法,其主要目的是在保持最大变异条件下,寻找到一个转换矩阵,降低数据集的维度。PCA算法主要分为4个步骤:(1)建立数据矩阵,对原始数据集进行标准化处理;(2)建立相关系数矩阵并计算各主成分的特征值与对应的特征向量个数;(3)依据特征值和累计贡献率,确定所需主成分的个数;(4)组合主成分对应的特征向量,得到转换矩阵对原数据集降维。
支持向量机算法(support vector machine,SVM)是建立在统计学理论基础上的数据挖掘算法,主要通过选择一个满足分类要求的最优分类超平面,使得该超平面在保证分类精度的同时,能够使超平面两侧的空白区域最大化。SVM 算法主要分为3 个步骤:(1)构建分类超平面()=,其中是超平面的权值,是数据向量矩阵;(2)利用核函数求解分类超平面,得到超平面权值;(3)利用超平面权值预测数据分类。
2 PRFITN 算法
PRFITN 算法主要包括三个阶段:数据降维、特征分组和并行构建随机森林。(1)在数据降维阶段,提出DRIGFN 策略,准确地识别和删除数据集中的冗余和不相关特征,获得降维后的数据集DB;(2)在特征分组阶段,提出FGSIT 策略用于度量特征的重要性,并在此基础上循环分配特征,以此获得两组特征子集、;(3)在并行构建随机森林阶段,提出RSKP策略用于优化MapReduce 计算模型,提升其并行化效率,并利用优化后的MapReduce模型并行构建随机森林、预测数据集分类,得到随机森林的准确度。
2.1 数据降维
目前,降维算法主要包括特征选择和特征提取两个方向,然而在大数据环境下,由于数据集中存在大量冗余与不相关特征,故单独使用特征选择或特征提取方法,都无法获得较优的特征集合。针对这一问题,本文提出DRIGFN 策略用于识别和过滤大数据环境下的冗余和不相关数据。首先结合MapReduce模型,并行计算特征信息增益值,以此删除不相关特征;接着利用Frobenius 范数评估信息损失量、分类误差以及控制分类器过拟合,并在此基础上提出全局优化函数用于迭代优化降维参数。假设=[,,…,x]∈R表示原始数据集DB 的维特征空间中的个样本,数据集DB 包含个不同类别,∈R表示特征矩阵所对应的标签,则DRIGFN 策略如下:
对于数据集DB,特征选择的主要目的是减少不相关特征的数量。其具体过程为:首先,使用Hadoop中默认的文件块策略,将原始数据集的特征空间划分成大小相同的文件块Block;接着,文件块Block 作为输入数据,根据定义1,Mapper 节点通过调用Map函数以键值对<,>的形式统计出每个特征的信息增益(为特征名称,为对应特征的信息增益),组合每个键值对得到特征信息增益集合={<,>,<,>,…,<key,value>};最后,根据特征对应的信息增益值对集合中元素降序排列,移除集合中排序较为靠后的特征,重新组合得到新的特征矩阵′=[,,…,x]∈R(1 ≤≤),并将处理后得到的特征矩阵′与标签向量按列合并后得到的数据集DB′传入到下一阶段。特征选择的执行过程如下所示:
特征选择


在特征提取阶段,为进一步优化特征选择后的数据集DB′,首先,利用主成分分析以及支持向量机算法获取初始参数,并利用得到的参数对特征矩阵进行重构;其次,采用Frobenius 范数对信息损失量、分类误差以及分类器过拟合程度进行估计;最后,为了使信息损失量、分类误差以及过拟合程度总和达到最小,提出了全局优化函数对转换矩阵和分类矩阵进行优化。特征提取的具体过程描述如下:
(1)参数的初始化与特征矩阵的重构
已知特征矩阵′和数据集DB′,首先采用主成分分析(PCA)获取初始的转换矩阵∈R(1 ≤≤),即:

其中,″是由PCA 降维后得到的特征矩阵,与标签按列合并后得到转换后的数据集DB″。
其次,采用支持向量机(SVM)算法以数据集DB″中所有样本作为训练集获得关于″的分类矩阵∈R,据此可以计算出″的预测标签为:

接着,为了评估在特征提取过程时信息的损失量,采用转换矩阵对特征矩阵″进行重构,″的重构矩阵X可以表示为:
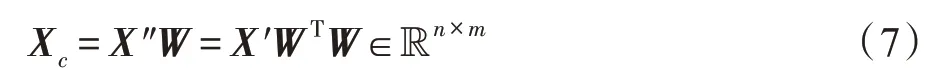
(2)信息损失量、分类误差以及分类器过拟合程度的估计
根据上一步中得到的转换矩阵、分类矩阵以及重构矩阵X,该部分将采用Frobenius 范数对信息损失量、分类误差以及分类器过拟合程度进行估计。
因重构矩阵X由特征矩阵′通过矩阵转换得到,故与′的元素间会存在或多或少的差异,从而利用Frobenius 范数对两矩阵中各个元素的差异处理后求和,得到的结果便可反映出降维后矩阵″与矩阵′相比的信息损失量,具体定义如下:
(信息损失量)已知特征矩阵′和重构矩阵X,则根据定义4,信息损失量可以表示为:

同理,预测标签(″)与标签之间的差异也可利用Frobenius范数对其度量,具体定义如下:
(分类误差)已知为特征矩阵所对应的标签,(″)是由支持向量机预测得到的预测标签,则根据定义4,分类误差可以表示为:

最后,根据Frobenius 范数,设计,通过值控制分类的过拟合程度,具体定义如下:
(过拟合程度)已知为特征矩阵″的分类矩阵,则根据定义4,过拟合程度可以表示为:

根据Frobenius 范数的定义可以推断出,的元素分布越均匀,的值越小;反之,中个别元素值越大,的值越大。
(3)全局优化函数
为了获取全局最优转换函数,需要同时满足、以及总体最小化,故结合式(8)~(10)三式提出关于转换矩阵和分类矩阵的全局优化函数(,)的定义,如下所示:
(全局优化函数(,))已知特征矩阵′和标签,对应的转换矩阵和分类矩阵分别为和,由此可得到关于′的信息损失量、分类误差以及过拟合程度为、和,则全局优化函数(,)可表示为:
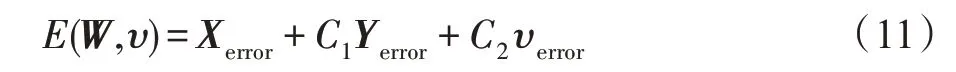
其中,和分别为和的权重参数。
考虑到全局优化函数(,)中分类矩阵受到转换矩阵的影响,故在利用梯度求解函数最小值时将其分为两步:(1)将分类矩阵视为常数求解转换矩阵;(2)将转换矩阵代入求解分类矩阵。根据、和的相关定义,对函数(,)求关于的梯度为∇(,),令∇(,)=0,可求解出转换矩阵′,且对于∀∈(={|∈R,≠′}) 都有(,)≥(′,),故′为 使(,) 最小的局部最优转换矩阵;同理,将′代入(,),对(′,)关于的梯度为∇(′,),令∇(′,)=0,可求得分类矩阵′,且对于∀∈(={|∈R,≠′})都有(′,)≥(′,′),故′为使(′,)最小的局部最优分类矩阵。
根据定义8 及其求解过程可以得到局部最优转换矩阵′以及分类矩阵′。为获取全局最优转换矩阵,将求解得到的局部最优转换矩阵′以及分类矩阵′依次代入函数(,)对转换矩阵以及分类矩阵迭代求解直到其收敛,此时返回得到的转换矩阵即为全局最优转换矩阵。最后将全局最优转换矩阵代入式(5)便可得到经特征提取后的特征矩阵=[,,…,x]∈R,并与标签按列合并后即可得到降维数据集DB。特征提取的执行过程如下所示:
特征提取

2.2 特征分组
目前大数据环境下的并行随机森林算法中,训练特征的形成是通过随机选取数据集的特征获得的,虽然DRIGFN 策略通过数据降维的方式减少了数据集中存在的冗余和不相关特征,但仍存在大量低信息量特征,由于它们的存在,导致生成的训练特征所含信息量低。为了解决上述问题,提出基于信息论的特征分组策略FGSIT,该策略首先利用信息论的相关知识衡量特征-标签、特征-特征间的影响程度;其次,在获取特征-标签、特征-特征影响程度的基础上提出特征评判函数;最后,以迭代的方式将特征划分为两组。特征分组的具体过程描述如下:
(1)特征-标签、特征-特征间的影响程度
已知特征x是特征矩阵中的任一特征,是特征矩阵对应的标签,根据定义1 得到特征x的信息增益(x;)如下所示:

然而,信息增益只衡量了特征-标签间的影响,忽略掉了特征-特征间的影响,考虑到特征分组过程中,备选特征对已选特征的影响,提出了一种计算特征-特征间影响程度的函数(),其定义如下所示:
(特征-特征影响函数())已知为标签,为已选特征集,x是中的元素,则根据定义2和定义3,备选特征x对中特征的影响程度()可表示为:
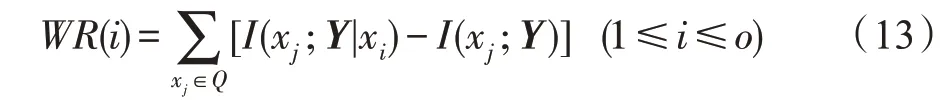
根据定义2 和定义3 可知,互信息(x;)表示已选特征x与标签之间的相关性,条件互信息(x;|x)则表示在特征x的条件下特征x与标签之间的相关性,因此利用条件互信息(x;|x)与互信息(x;)之差可表示特征x对特征x与标签的影响,故在()函数中利用特征x对中所有特征的影响之和便可表示特征x对的整体影响程度。
(2)特征评判函数
为了在特征分组过程中同时考虑到特征-标签、特征-特征间的影响程度,结合以上两点,提出特征评判函数(),其定义如下所示:
(特征评判函数())已知备选特征x、标签向量以及已选特征集,则关于特征x的评判函数()可表示为:

其中,为函数(x;)的权重参数。
因信息增益可以用来衡量特征-标签间的影响,函数()可以衡量特征-特征间的影响,故结合式(12)、式(13)得到的特征评判函数()可同时衡量特征-标签、特征-特征间的影响程度。
(3)特征分组
由定义10 提出的特征评判函数()可将特征分组过程分为三步:
①将中信息增益值最大的特征放入中;
②依次计算备选特征的()值,将()最大值对应的特征放入中;
③迭代执行步骤②,直到中特征个数达到阈值时为止,其余特征自行组成特征集。
根据随机森林的性质可以推断出随机森林的分类效果与森林中决策树间的相关性以及每棵决策树的分类能力两个因素有关,相关性越强,随机森林分类效果越差;决策树分类能力越强,随机森林分类效果越好。然而,阈值的选择影响到了特征的分组,进而同时影响到决策树的相关性以及决策树的分类能力。因此,阈值的选择尤为重要,故提出阈值函数()用来确定阈值,其定义如下所示:
(阈值函数())假设随机森林中有棵决策树,中包含个特征,中包含个特征,按比例从中随机抽取个特征作为高信息量特征,从中随机抽取个特征与组合作为构建决策树的训练特征,则阈值函数()可表示为:
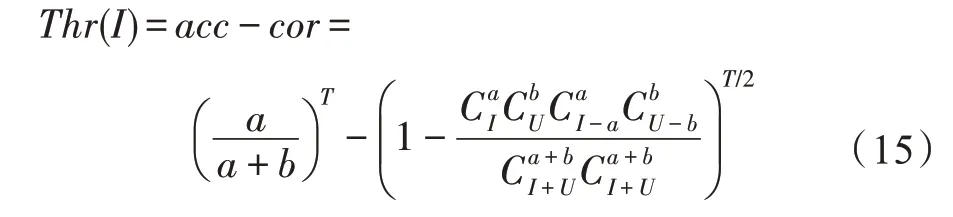
其中,是利用中特征占比反映出随机森林中决策树的整体分类能力,是利用两棵决策树所选特征的相似程度反映出随机森林中决策树的相关性。
根据定义11 可知可用来衡量随机森林中决策树整体的分类能力,可用来衡量随机森林中决策树间的相关性。因此,根据随机森林的性质,随机森林的分类效果可以利用-衡量,通过观察式子可以发现当特征全部属于时,/(+)=1,此时=1 且≈0,可取到其最大值,但此时失去了分组的意义故而舍去;当/(+)<1,由于在大数据环境 下≫/2,故≈0,此时可以得到当=,=,即=(+)/2 时,的取值最小,-可达到最大值。
FGSIT 策略的执行过程如下所示:
FGSIT 策略

2.3 并行构建随机森林
在数据降维和特征分组之后,需要根据降维后的数据集DB以及特征集、并行化训练分类器。目前大数据环境下的并行随机森林算法大多根据训练数据和训练特征构建多棵决策树作为输出结果,并在此基础上对样本进行预测,获得模型准确度。然而,此类方法在预测阶段时,由于各个计算节点中决策树的不同,进而对数据集得到的预测键值对也有所不同,故在合并之后,每个Mapper 节点上键值对的数量会有所差异,通常会导致下一阶段中Reducer节点负载不平衡,影响算法的并行化效率。为了应对上述问题,本节首先提出RSKP 策略优化MapReduce计算模型,平衡Reducer 节点负载;然后,利用优化后的MapReduce 模型并行构建随机森林,预测数据集分类,得到随机森林的准确度。并行构建随机森林的具体过程描述如下:
(1)RSKP 策略
给定每个Mapper 节点中合并后得到的键值对集合,,…,P,RSKP 策略的过程描述如图1 所示。
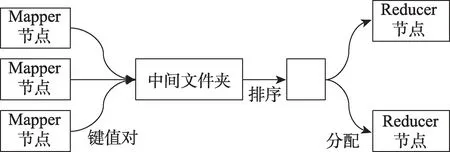
图1 RSKP 策略Fig.1 RSKP strategy
①将所有的键值对集合,,…,P汇总到中间文件中,并根据键值对中的键对它们进行排序;
②根据键值对的数量以及Reducer 节点的个数将中间文件夹中的键值对均匀分配到各个节点。
(2)并行构建随机森林、预测数据集分类
通过RSKP 策略得到了优化后的MapReduce 模型,结合该模型,并行构建随机森林具体分为四步,由图2 所示。

图2 并行构建随机森林Fig.2 Construct random forests in parallel
①调用Hadoop 默认的数据块策略,将数据集DB划分成大小相同的数据块Block 并将其作为输入数据传输到Mapper节点中。
②根据主节点分配给每个Mapper 节点的任务,调用Map 函数通过bootstrap 自主抽样方式抽取决策树的训练集,并从特征子集、中按比例随机抽取特征作为训练特征,基于训练集和训练特征以键值对<key,value>的形式构建决策树(key为决策树模型编号,value为该决策树模型),所有Mapper 节点执行完毕,解析出所有决策树合并得到随机森林模型。
③利用Mapper 节点中的决策树对数据集DB进行预测并形成新的键值对<′,′>(′为样本ID 与对应类别的组合数组,′=1 表示该键值对出现的次数),合并具有相同′值的键值对(如本 地有三个′都为的键值对<:1 >、<:1 >、<:1 >,则它们将会合并为一个键值对<:3 >)。
④将Mapper 节点中预测得到的键值对由主节点分配后传入相应的Reducer 节点再次合并,得到全局分类结果,并与标签比较得到模型的准确度。
至此,并行构建随机森林的执行过程如下所示:
并行构建随机森林


2.4 PRFITN 算法步骤
PRFITN 算法的具体实现步骤如下:
通过Hadoop 默认的文件块策略,将原始数据集划分成大小相同的文件块Block,调用一次MapReduce 任务并行计算原始数据特征的信息增益,在此基础上对特征进行选择。
调用FEKFN 策略以迭代的方式对特征选择后的数据集进行新特征的提取。
调用FGSIT 策略对降维后的数据集进行特征分组。
启动新的MapReduce 任务,调用Map 函数,采用bootstrap 和分层抽样的方法抽取建模所用的训练样本及特征,构建决策树,汇总所有决策树得到随机森林;采用RSKP 策略均匀分配Reducer 节点任务,调用Reduce 函数得到全局分类结果,并评估模型分类准确率。
2.5 算法时间复杂度分析
PRFITN 算法主要包括三个阶段:数据降维、特征分组和并行构建随机森林。因此,该算法的时间复杂度主要由三部分组成,分别记为、和。
在数据降维的特征选择阶段,时间复杂度主要取决于计算每个特征的信息增益值,它需要遍历数据集中的每个特征对应的样本下的每条数据。已知数据集的样本数目为,特征数目为,且执行MapReduce 任务时对应的Mapper 节点个数为,则该阶段的时间复杂度为:

在数据降维的特征提取阶段,时间复杂度主要取决于迭代优化转换矩阵以及分类矩阵的过程,已知为×阶矩阵,为×1 阶矩阵,假设该阶段需要迭代计算次,则时间复杂度为:
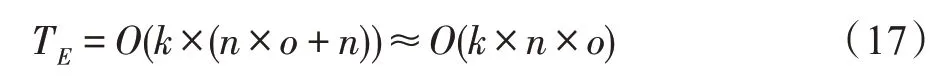
因此,数据预处理的时间复杂度为:
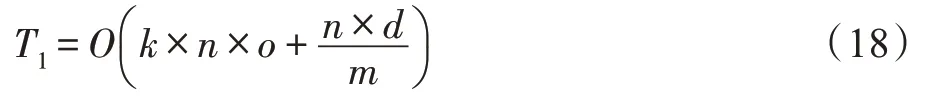
在特征分组阶段,主要采用FGSIT 策略划分特征,每次筛选特征时都需要计算每个备选特征与已选特征之间的特征评判函数()。已知处理过后的特征个数为,样本数为,则该阶段的时间复杂度为:

在并行构建随机森林阶段,主要调用MapReduce任务并行构建随机森林模型以及预测全部数据的分类从而评估准确率。假设随机森林模型包含棵决策树,且执行MapReduce 任务时对应的Mapper 节点个数为,Reduce 节点个数为,则该阶段的时间复杂度为:
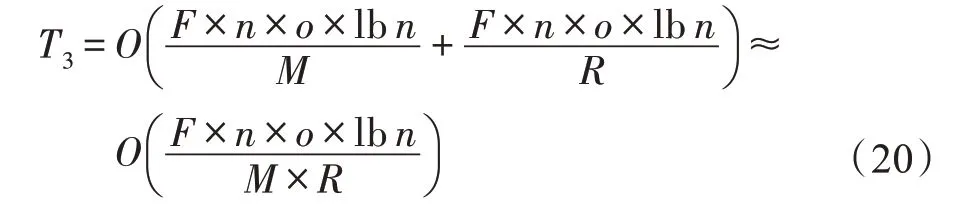
因此,PRFITN 算法的时间复杂度为:

3 实验结果及比较
3.1 实验环境
为了验证PRFITN 算法的性能,本文设计了相关实验。在硬件方面,实验包括4 个计算节点,其中1个Master 节点,3 个Slaver 节点。所有节点的CPU 均为AMD Ryzen 7,每个CPU 都拥有8 个处理单元,其内存均为16 GB。实验环境中的4 个节点处于同一个局域网中,通过200 Mbit/s 以太网相连。在软件方面,每个节点安装的Hadoop 版本为2.7.4,Java 版本为1.8.0,操作系统均为Ubuntu 16.04。各个节点的具体配置如表1 所示。
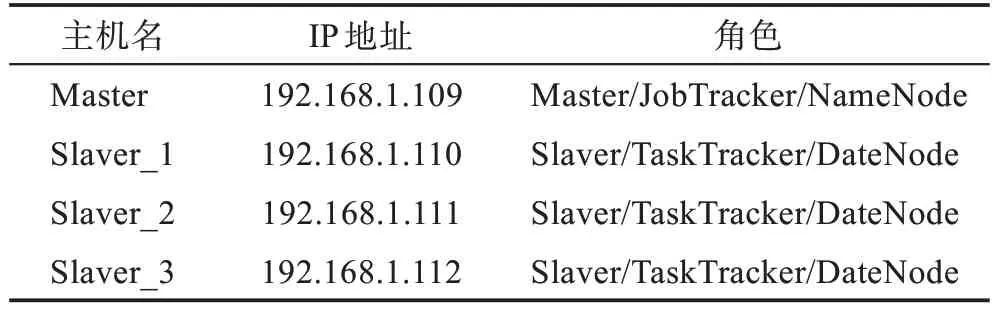
表1 实验中节点的配置Table 1 Configuration of nodes in experiment
3.2 实验数据
PRFITN 算法所使用的实验数据为3 个来自UCI公共数据库(https://archive.ics.uci.edu/ml/index.php)的真实数据集,分别为Farm Ads、Susy 和APS Failure at Scania Trucks。Farm Ads数据集是从12个网站上的文字广告中收集的各种与农场动物相关的数据集,该数据集包含了4 143 条样本,共有54 877 种属性,具有样本量少、属性数多的特点;Susy 是一个记录使用粒子加速器探测粒子的数据集,该数据集包含5 000 000 条样本,共有18 种属性,具有样本量多、属性数少的特点;APS Failure at Scania Trucks 数据集是一个记录斯堪尼亚卡车APS 故障和操作的数据集,该数据集包含了60 000 条样本,共有171 种属性,具有样本量适中、属性数适中的特点,数据集的具体信息如表2 所示。

表2 实验数据集Table 2 Experimental datasets
3.3 PRFITN 算法的性能分析
为验证PRFITN 算法在大数据环境下的可行性,本文选取随机森林中决策树的棵树为50、100、150,分别将PRFITN 算法应用于Farm Ads、Susy、APS Failure at Scania Trucks 3 个数据集中,独立运行10次,取10 次运行结果的均值,通过对算法运行时间和准确度的比较,从而实现对PRFITN 算法性能的总体评估。图3 为PRFITN 算法在3 个数据集下的执行结果。
从图3 可以看出,当决策树数量从50 变化到100再到150 时,算法在Farm Ads 数据集运行的时间分别增加了8 700 s 和9 000 s,准确度分别增加了3.8 个百分点和1.5 个百分点;在Susy 数据集运行的时间分别增加了4 250 s 和6 000 s,准确度分别增加了2.5 个百分点以及降低了0.7 个百分点;在APS Failure at Scania Trucks 数据集运行的时间分别增加了750 s 和4 500 s,准确度分别增加了3.0 个百分点和1.1 个百分点。从图片反映出的数据可以看出,PRFITN 算法在三种数据集上的时间复杂度和准确度都逐渐增大,且时间复杂度的增幅逐渐增大,准确度的增幅却逐渐减小。前者产生主要是由于随着决策树数量的增长,在建模阶段中分配到计算节点的任务量增多,同时键值对的数量也会成倍增加,故需要消耗更多的时间处理它们;后者产生主要是由于随着决策树数量的增加,树与树之间的差异将会减小,进而对随机森林分类结果的影响程度就会越来越小,因此准确度的增长幅度会随着决策树的增加而减少。
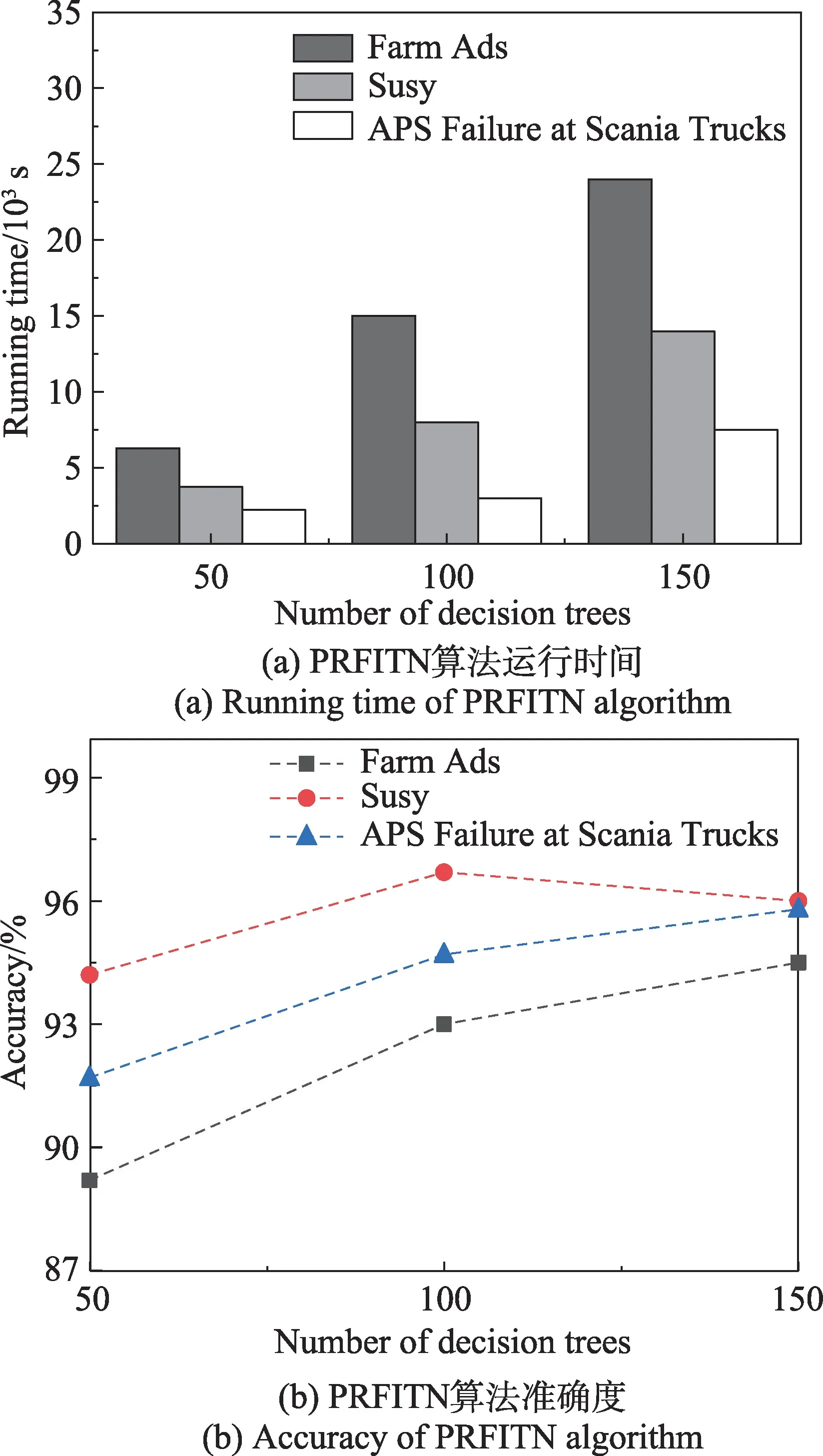
图3 PRFITN 算法的性能分析Fig.3 Performance analysis of PRFITN algorithm
3.4 PRFITN 算法的性能比较
为验证PRFITN 算法的时间复杂度,本文基于Farm Ads、Susy、APS Failure at Scania Trucks 3 个数据集进行实验,根据所得到的运行时间,与改进的MR_RF 算法、PRF 算法以及PRFMIC算法进行综合的比较。与此同时,为了探究负载均衡对PRFITN算法的影响,进一步运行了不使用RSKP 策略的PRFITN 算法,记为PRFITN-ER。具体的时间复杂度如图4 所示。

图4 五种算法在不同数据集上的运行时间Fig.4 Running time of five algorithms on different datasets
从图4 中可以看出,在Farm Ads 数据集上,PRFITN 算法的运行时间比PRFMIC 算法、PRF 算法以及改进的MR_RF 算法的运行时间平均分别高出2 300 s、3 833.3 s 和8 666.7 s;在APS Failure at Scania Trucks 数据集上,PRFITN 算法的运行时间比PRFMIC算法、PRF 算法以及改进的MR_RF 算法的运行时间平均分别高出200 s、416.7 s 和733.3 s。出现上述两种情况是由于在构建随机森林模型时PRF 算法对训练特征采取了数据降维处理,PRFMIC 算法对特征采取了分层处理,而PRFITN 算法对特征同时采取了数据降维及特征分层处理,且PRFITN 算法的降维及分层策略偏重于直接评估特征本身,因此在处理特征相对较多的Farm Ads 和APS Failure at Scania Trucks数据集时,PRFITN 算法明显比PRFMIC、PRF 以及改进的MR_RF 算法所用时间多。相反,在处理样本量较多、特征数较少的Susy 数据集时,PRFITN 算法的运行时间比PRFMIC 算法和PRF 算法的运行时间分别低6 783.4 s 和3 750 s。这是由于特征数量较少时,PRFITN 算法在数据降维以及特征分层阶段所用时间较少,同时PRFMIC 算法使用了RSKP 策略,平衡了每个节点的负载量,降低了时间复杂度。此外,为了更直观地判断出负载均衡对模型的影响程度,即RSKP 策略对模型的优化效果,对比PRFITN 算法和PRFITN-ER 算法在三种数据集上的运行时间可以看出,在Farm Ads 数据集、Susy 数据集以及APS Failure at Scania Trucks 数据集上,PRFITN 算法的运行时间要比PRFITN-ER 算法平均节约1 733.33 s、1 583.33 s以及295 s,故RSKP 策略的采用将在一定程度上节约模型学习的时间。
为验证PRFITN 算法的准确度,本文基于Farm Ads、Susy、APS Failure at Scania Trucks 3 个数据集进行实验。根据分类结果,与改进的MR_RF 算法、PRF 算法以及PRFMIC 算法进行综合的比较。具体的准确度如图5 所示。
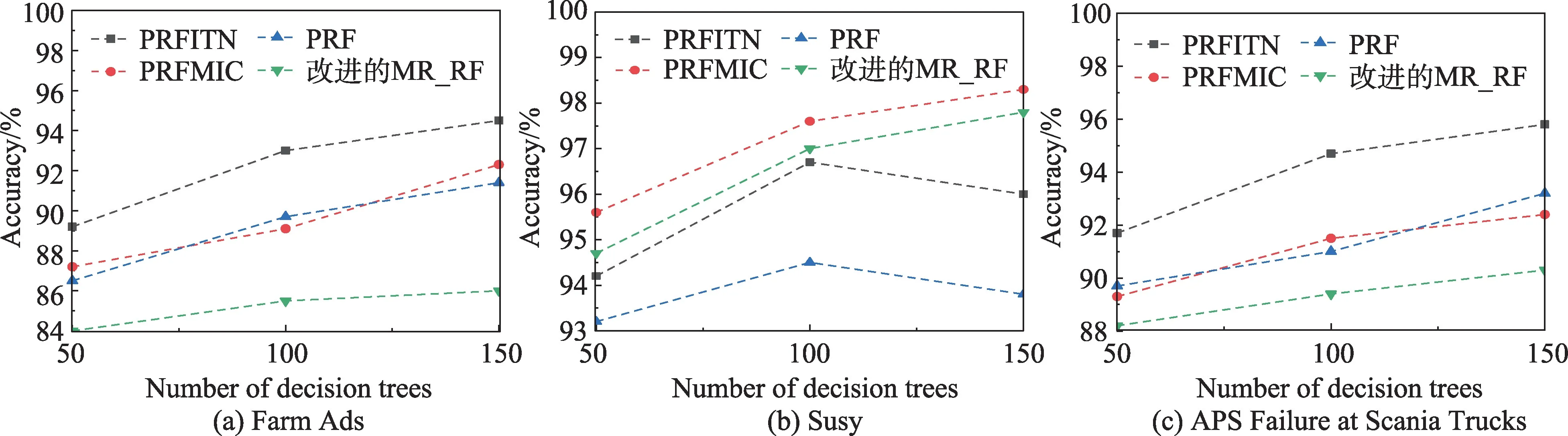
图5 四种算法在不同数据集上的准确度Fig.5 Accuracy of four algorithms on different datasets
从图5 中可以看出,PRFITN 算法在处理大数据集时具有很好的准确度。在特征较多的Farm Ads 数据集和APS Failure at Scania Trucks 数据集中,如图5(a)、图5(c)所示,PRFITN 算法的准确度比PRFMIC算法的准确度平均高出2.7 个百分点和2.8 个百分点,比PRF 算法的准确度平均高出3.0 个百分点和2.6个百分点,比改进的MR_RF 算法的准确度平均高出7.1 个百分点和4.5 个百分点。这是由于PRFITN 算法在建模前采用DRIGFN 策略,相比PRF 算法以及PRFMIC 算法的降维策略,DRIGFN 策略有效过滤掉了冗余与不相关特征,提高了特征的质量。同时,在模型的构建阶段,算法采用了FGSIT 策略,该策略在考虑特征-特征与特征-类别影响的基础上,对特征进行了分层处理,保证在生成决策树的过程中训练特征含有较高的信息量。然而,在特征数较少的Susy数据集中,如图5(b)所示,PRFITN 算法的提升效果并不是很明显,其准确度甚至低于PRFMIC 和改进的MR_RF 算法,并且当随机森林中决策树的数目由100 变化到150 时,PRFITN 和PRF 算法的准确度反而出现了下降。以上情况的出现是由于Susy 数据集特征本身质量较高且特征量较少,故PRFITN 和PRF 算法中的数据降维策略并不能达到优化特征的目的,反而会使特征集丢失部分信息量。即便如此,PRFITN算法的准确度还是优于PRF 算法,这是因为DRIGFN策略在降维时迭代对转换矩阵进行优化,有效减少了在降维过程中所损失的信息量。故从以上实验结果可以看出,PRFITN 算法对处理样本规模较大且特征数量较多的数据集优势较为明显。
4 总结
为解决并行随机森林算法在大数据环境下的不足,本文提出了一种基于信息论和范数的并行随机森林算法PRFITN。首先,该算法充分考虑到大数据集中冗余与不相关特征较多的问题,提出了一种混合降维策略DRIGFN。该策略不仅能有效地降低数据集的维度,而且可以极大限度地降低数据降维时所损失的信息量。其次,为了提高随机森林中训练决策树所用特征的信息量,提出了一种特征分组策略FGSIT,该策略充分考虑了特征-特征以及特征-标签之间的关系,在此基础上将特征划分为两组,按比例抽取训练特征,保证了构建决策树时所选特征的信息量。最后,考虑到集群负载对并行算法效率的影响,设计了键值对重分配策略RSKP,对并行算法得到的中间结果进行均匀分组,平衡了集群中reducer节点的负载量,减少了算法的时间复杂度。同时为了验证PRFITN 算法的分类性能,本文在Farm Ads、Susy、APS Failure at Scania Trucks 三个数据集上与改进的MR_RF 算法、PRF 算法以及PRFMIC 算法三种算法进行对比分析。实验结果表明,PRFITN 算法在大数据环境下,尤其是针对特征数较多的数据集的分类有着较高的准确度。
猜你喜欢
车主之友(2022年4期)2022-08-27
科海故事博览·下旬刊(2022年4期)2022-05-07
汽车实用技术(2022年4期)2022-03-07
数码世界(2020年4期)2020-06-18
装备环境工程(2020年3期)2020-04-03
海峡姐妹(2019年12期)2020-01-14
科学与信息化(2019年28期)2019-10-21
科学与财富(2016年32期)2017-03-04
价值工程(2016年32期)2016-12-20
考试周刊(2016年34期)2016-05-28
