
模糊特征的top-k平均效用co-location模式挖掘
2022-05-17 06:01李金红王丽珍周丽华
计算机与生活 2022年5期
李金红,王丽珍,周丽华
云南大学 信息学院,昆明650500
伴随着互联网和无线通信技术等各项高新技术的不断普及和发展,大量包含空间位置信息的数据不断产生,人们对空间数据挖掘越来越感兴趣。空间co-location 模式挖掘作为空间数据挖掘的一个热门研究方向,受到了更多的关注和期待。空间colocation 模式是一组空间特征的子集,它们的实例在空间邻域中频繁并置出现。例如西尼罗河病毒往往发生在蚊子泛滥、饲养家禽的区域;医院、药店、花店经常并置出现等。近几年来,Huang、Yoo、Wang等学者提出了多个空间co-location 模式挖掘的算法,这些算法大多以特征实例参与并置的程度来度量空间co-location 模式的有趣性,并没有对各特征的重要程度或价值进行区分和研究,这种传统的空间colocation 模式挖掘方法容易忽略那些不频繁出现,却十分有价值的模式。空间高效用co-location 模式挖掘在很大程度上弥补了频繁co-location 模式挖掘所造成的信息遗漏。然而,空间高效用co-location 模式挖掘只考虑了并置特征的效用,忽略了模式长度带来的影响,导致挖掘出的模式包含一些用户不感兴趣的模式或者不是用户真正感兴趣的模式,并且是通过用户设定频繁性阈值来获取有价值的模式,但由于实际应用的不确定性,用户在设置阈值时需要反复尝试、多次分析,整个过程繁琐而复杂,设置的阈值过大可能挖掘不出有价值的模式,设定的阈值过小,导致挖掘到的模式过多,会消耗大量的时间和内存,因此用top-挖掘取代设置最小效用阈值的挖掘是有积极意义的。
在实际生活中,模糊特征无处不在,比如“大型游乐场”“高档餐厅”“严重污染”等,模糊特征在许多应用中也起着十分重要的作用,例如地球科学、公共卫生等。目前对模糊特征的研究范围十分广泛,但在空间co-location 模式挖掘的研究中主要还是基于模糊特征实例参与并置的程度来度量co-location 模式的有趣性,并没有对各模糊特征的重要程度或价值进行区分和研究,容易忽略那些不频繁出现,却十分有价值的模式。例如污染的治理,治理不同类型的污染需要投入的资金不一样,一种不频繁发生却需要投入大量资金来治理的污染组合可能被传统的co-location 模式挖掘忽略。
为了解决以上的问题,本文将模糊集理论与高平均效用co-location 模式挖掘结合起来,不需要用户设定最小效用阈值,找到模糊特征的top-平均效用co-location 模式。主要贡献包括:
(1)基于模糊集理论,定义了模糊特征的外部效用、内部效用以及模糊平均效用。
(2)分析了扩展模糊平均效用的“向下闭合”性质,设计了一个模糊特征的top-平均效用co-location模式挖掘的基本算法。
(3)分析基本算法的性能,提出了一种基于局部扩展模糊效用剪枝的top-平均效用co-location 模式挖掘的优化算法。
(4)在合成数据集和真实数据集上进行了广泛的实验,证明了所提出算法的实用性、高效性和鲁棒性。
1 相关工作
空间数据挖掘,主要是在空间数据集中发现未知知识,提取感兴趣的空间模式或特征等。空间colocation 模式挖掘是空间数据挖掘的一个重要研究方向,最早在文献[1]中被提出,以最小参与率(称为参与度PI)作为空间co-location 模式挖掘的有趣性度量指标,由于PI 满足“向下闭合”性质,利用这一性质能对候选模式进行有效的剪枝。近年来空间colocation 模式挖掘的很多研究都集中在候选模式的剪枝和表实例的计算优化两方面,例如基于完全连接操作的join-base 算法、基于部分连接操作的partialjoin 算法和基于无连接操作的join-less算法等。文献[10]提出了在确定数据集上的top-闭co-location模式挖掘方法,文献[11]提出了基于不确定数据的top-频繁co-location 模式挖掘方法。文献[12]首次将模糊特征的概念引入到空间co-location 模式挖掘中,定义了模糊参与率、模糊参与度的概念,分析其所满足的性质,并分别从剪枝特征、减少实例间连接、改进剪枝步骤等几方面提出了剪枝算法。
随着Yao 等首次将高效用的概念引入到事务数据中,高效用模式挖掘得到了广泛的关注与研究,目前已有许多针对事务数据库的高效用模式挖掘方法。文献[16]首次提出top-高效用模式挖掘方法,文献[17]相继提出了针对top-高效用模式挖掘的改进方法。文献[7]首次将效用的概念引入到空间co-location 模式挖掘中,定义了模式效用、模式效用率(pattern utility ratio,PUR)等概念,并把模式效用率(PUR)作为空间高效用co-location 模式有趣性的度量指标。文献[8]进一步考虑了同一特征的不同实例的效用值差异,提出了一种新的效用参与度(utility participation index,UPI)作为高效用co-location 模式的有趣性度量指标,但该方法注重每个实例的参与性,忽略了一些效用值很小,但对模式的贡献值很大(参与度大)的特征。为此文献[9]进一步提出了一种确定特征在模式中的效用权重的方法。文献[18]首次将模糊特征的概念引入到空间高效用co-location模式挖掘中。但文献[7-9,18]都是通过人为设定阈值来获取有价值的模式,而且获取的模式没有考虑模式长度对模式效用的影响。
高平均效用模式挖掘也叫高平均效用项集挖掘,最早在文献[19]中提出,一个项集只要满足其效用值除以项的个数不小于用户预定义的最小平均效用阈值,那么该项集就可以称为一个高平均效用项集。Lin 等提出了用于挖掘高平均效用项集的HAUP 树结构和HAUP 增长算法。Lan 等提出了一种基于预测的高平均效用项集挖掘(high averageutility itemset mining,HUAI)算法。
本文首次将模糊特征的平均效用的概念引入colocation 模式挖掘中,研究模糊特征的top-平均效用co-location 模式挖掘的问题。
2 相关定义
本章首先介绍了传统co-location 模式挖掘的基本概念和一个经典的空间数据的星型邻居物化模型,接着定义了模糊特征的top-平均效用co-location模式挖掘的相关概念。
2.1 传统co-location 模式挖掘
空间特征集是所有空间数据划分类别的集合,常用表示,记为={,,…,f}。把一个具体位置上的特征称为一个空间实例,将空间实例的集合称为实例集,记为=⋃⋃…⋃S,其中S(1 ≤≤)是对应空间特征f的实例集合。为了区别不同特征的不同实例,给每一个实例一个唯一的编号,一个空间实例信息通常包括(实例所属特征,实例编号,空间位置)。如图1 所示,图中共有5 个特征、、、和,空间特征有5 个实例1、2、3、4 和5,有4 个实例1、2、3 和4,有5 个实例1、2、3、4 和5,有4 个实例1、2、3、4,有3 个实例1、2 和3。如果两个空间实例之间的欧氏距离小于等于用户给定的一个距离阈值,那么就称这两个空间实例在空间中是邻近的,为了便于描述,将满足邻近关系的空间实例在图中用实线连接,如图1 中的5 和3。其中(5,0.7)中的0.7 表示实例5 对模糊特征的隶属度,具体的将在2.3 节进行介绍。
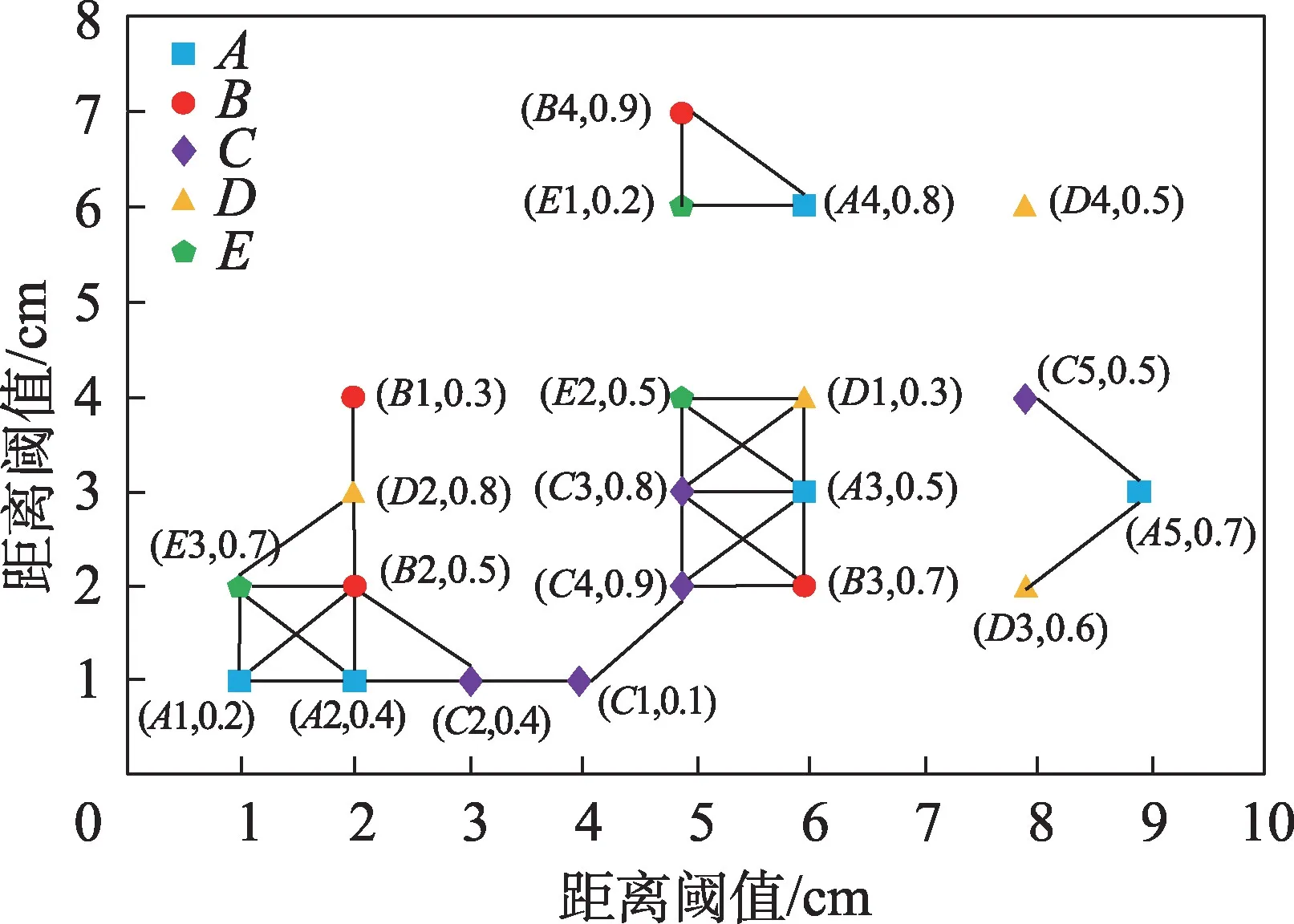
图1 空间模糊特征及其实例分布示例Fig.1 Example of spatial fuzzy features and instances
对于空间特征集的一个子集,称为空间模式,记为={,,…,f},其中的长度称为模式的阶数。对于任意一个空间实例集={,,…,i},如果中任意两个实例都满足空间邻近关系,则称是一个团实例,如果团实例包含了co-location 模式中的所有特征,并且中的任何一个子集都无法包含的所有特征,那么就称为模式的一个行实例,记为()。一个模式的所有行实例的集合称为的表实例,记为()。
2.2 星型邻居物化模型
空间数据的星型邻居物化模型是Yoo等在文献[4]提出的,星型邻居模型是经典的join-less 挖掘算法的基础,以下将介绍星型邻居和星型实例的相关定义。
(星型邻居)给定一个空间实例i∈,它的特征类型是f∈,i的星型邻居被定义为一些空间实例的集合={i∈|i=i∨(f>f∧(i,i))},其中f∈为i的特征类型,“>”表示特征名的字典序,是空间邻近关系。
(星型实例)的星型邻居集={,,…,i}⊆,如果它们的特征类型{,,…,f}是不同的,就称为co-location 模式={,,…,f}的一个星型实例。
数据集中所有实例的星型邻居集组成了空间数据库的星型邻居物化模型。根据定义2,一个colocation 模式{,,…,f}的星型实例{,,…,i}可以从中心特征类型为的星型邻居中收集得到。图1 空间数据集的所有星型邻居实例如表1 所列,每一行为一个星型邻居,给一个序号T。

表1 图1 的空间数据集的星型邻居Table 1 Star neighborhoods of spatial dataset in Fig.1
2.3 模糊特征的top-k平均效用co-location模式
(模糊特征及其隶属度)模糊特征由空间中一组离散的点组成,定义为={<,()>|()>0},其中表示的是空间模糊特征,是属于模糊特征的实例,而()表示空间实例对空间模糊特征的隶属度。图2 为图1 所示空间数据集中的一个模糊特征大型游乐场,其5 个游乐场分别用1、2、3、4、5 表示,根据游乐场的占地面积,各游乐场对大型游乐场的隶属度值依次为0.1、0.4、0.8、0.9、0.5。

图2 空间模糊特征C 及其实例分布示例Fig.2 Example of spatial fuzzy feature C and its instances
(模糊特征的外部效用)对于空间数据库中的模糊特征集={,,…,f},将模糊特征f的外部效用定义为(f),如表2 对应图1 中空间数据集的模糊特征的外部效用。

表2 图1 中5 个模糊特征的外部效用Table 2 External utility of 5 fuzzy features in Fig.1
内部效用在事务数据库中表示项的数量,如用户访问网站的次数、商品的销售数量等。映射到空间并置模式之中,有如下定义:
(模糊特征的内部效用)给定模糊特征的co-location 模式和中的模糊特征f,将的表实例中隶属于该模糊特征f的不重复实例的隶属度之和称之为模糊特征f在模式的内部效用,形式化为:

其中,表示关系的投影操作,例如co-location 模式={,,}中模糊特征的内部效用为(,)=0.4+0.5=0.9,因为的表实例为{{(2,0.4),(2,0.5),(2,0.4)},{(3,0.5),(3,0.7),(3,0.8)},{(3,0.5),(3,0.7),(4,0.9)}}。
(co-location 模式中各模糊特征的效用)对于一个阶co-location 模式={,,…,f},定义模糊特征f的外部效用和它在模式中的内部效用的乘积为模糊特征f在模式中的效用,记为(f,)=(f)×(f,)。
例如,模糊特征在co-location 模式{,,}的效用值为(,)=()×(,)=5×0.9=4.5。
(co-location 模式的模糊平均效用)对于一个阶co-location 模式,把模式中所有的模糊特征在模式内的平均效用之和与模式长度的比值定义为模式的模糊平均效用,记为:

例如co-location 模式={,,}的模糊平均效用为:

co-location 模式的模糊平均效用不满足“向下闭合”性。
在图1 所示的空间数据集中,co-location 模式{,} 的表实例为{{(3,0.5),(1,0.3)},{(5,0.7),(3,0.6)}},({})=13,({})=2.1,({,})=3.45,尽 管({,})>({}),但 是({,})<({}),因此模式的模糊平均效用不满足“向下闭合”性。
(top-模糊平均效用co-location 模式)在空间数据库中,将各模式的模糊平均效用值按降序排序,取前个co-location 模式。
3 挖掘算法
传统的co-location 模式挖掘中的参与度满足“向下闭合”性,利用这一性质,能提前过滤掉大量的候选模式,提升挖掘算法效率和节省内存空间,但由引理1 可知,模糊平均效用值不满足“向下闭合”性,因此其不能作为提前过滤低模糊平均效用的条件,本章将对模式的模糊平均效用值进行扩展,提出扩展模糊平均效用的概念,并根据其具有的“向下闭合”性质提出一种挖掘模糊特征的top-平均效用colocation 模式的基本挖掘算法。对基本挖掘算法的性能进行分析,进一步提出局部扩展模糊平均效用的概念,并基于此概念提出一种局部扩展模糊效用剪枝算法。
3.1 基于扩展模糊平均效用的基本算法
(星型邻居中模糊特征的效用)在一个星型邻居T中,定义一个模糊特征f的外部效用(f)与内部效用(f,T)的乘积作为星型邻居中模糊特征的效用,记为:
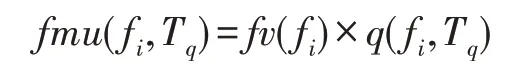
例如在表3 的星型邻居中,模糊特征的效用为()×(,)=3×1.7=5.1。
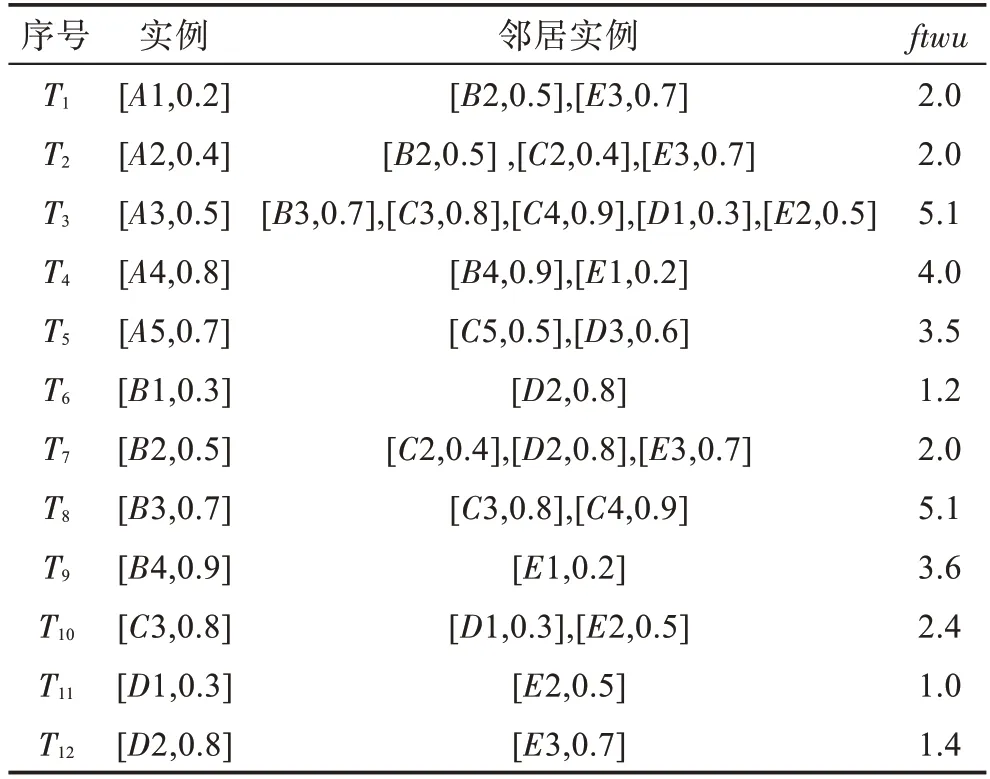
表3 图1 的空间数据集的星型邻居的最大模糊效用Table 3 Maximum fuzzy utility of star neighborhood of spatial dataset in Fig.1
(星型邻居的最大模糊效用)星型邻居T的最大模糊效用值表示为(T),定义为该星型邻居中所有模糊特征效用的最大值,记为:

例如在表3 中,星型邻居的最大模糊效用值为()=max{(,),(,),(,)}=2。
(模式的扩展模糊平均效用)对于任意一个co-location 模式={,,…,f}的扩展模糊平均效用表示为(),定义为所有包含的星型邻居的最大模糊效用值的和,记为:

例如在表3 中,co-location 模式={,,}的扩展模糊平均效用值为()=()+()=2+5.1=7.1。
一个模式的扩展模糊平均效用值不大于其子集的扩展模糊平均效用值。
设模式为一个阶的扩展模糊平均效用模式,模式′为模式的任意一个-1 阶子集。因为′为的一个子集,所以所有包含的星型邻居一定包含′,故包含的星型邻居是包含′的星型邻居的子集,那么有:
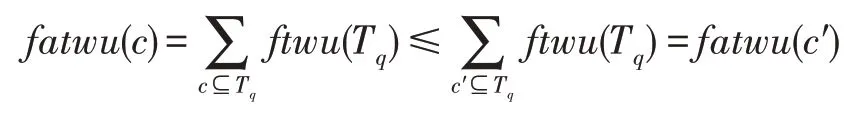
例如,在表3 中({,,})=7.1,({,})=13.1,({,})=10.6,({,})=14.2,模式{,,}的扩展模糊平均效用值不大于其子集的扩展模糊平均效用值。
任意一个模式的模糊平均效用值不大于其的扩展模糊平均效用值。
对于任意的co-location 模式有:

例如,对于co-location模式={,,},有()=5.2,()=7.1,()<()。
根据引理2 和引理3 可得:如果colocation 模式不是一个top-的模糊平均效用模式,那么的所有超集都不是top-模糊平均效用模式。
根据定理1,在计算扩展模糊平均效用的基础上,可以提前过滤掉一些不可能成为top-的模糊平均效用co-location 模式,算法1 就是基于扩展模糊平均效用来挖掘模糊特征top-平均效用co-location 模式的基本算法。
基本算法

算法的第1 步根据输入的空间数据集和空间邻近关系,把空间数据集物化成不相交的星型邻居集,其中是按照字典序排列的。第2 步初始化各变量值。第3 步是一个由低阶到高阶反复迭代的过程,直到不能生成候选模式为止:首先,3.1 步由-1阶的候选模式生成阶的候选模式。然后,3.2 步计算候选模式的()并和进行比较,为top-模糊平均效用co-location 模式中最小的模糊平均效用值。3.3步通过表实例和外部效用表计算阶候选模式的模糊平均效用值(),如果()≥,和原中各模式的模糊平均效用值进行比较,模糊平均效用值最大的前个模式替换原中的模式。3.4 步阶数自增,算法跳转到第3 步执行while 循环条件判断,若此时-1 阶的候选模式集不为空,则继续执行while 循环体内部的子句;反之,若C为空,此时不能够生成阶的候选模式,则会跳转到第4 步,返回top-模糊平均效用co-location 模式集,算法结束。
算法1 的时间复杂度与候选模糊平均效用colocation 模式数相关,而候选模糊平均效用co-location模式数与距离阈值、特征数、实例数等相关。对于未被剪枝的候选模糊平均效用co-location 模式,则需通过扫描邻居关系确定该模式表实例,并通过表实例计算该模式的模糊平均效用值,从而确定top-模糊平均效用co-location 模式。假设有个候选colocation 模式未被剪枝,且其平均长度为,则确定个候选模糊平均效用co-location模式表实例的时间复杂度为×(),其中()为确定一个阶模式的表实例所用时间,这也是算法最耗时的部分,扩展模糊平均效用值的意义就在于通过提前过滤掉不可能成为top-模糊平均效用co-location 模式的候选模式以减少表实例的计算。
3.2 基于局部扩展模糊平均效用的优化算法
由于基本算法中扩展模糊平均效用值过于宽松,导致算法的优化效果不明显。为了更有效地剪枝候选模式,本节将提出一种基于局部扩展模糊平均效用来挖掘模糊特征的top-平均效用co-location模式的优化算法。
(co-location 模式在星型邻居中的效用值)给定一个co-location 模式={,,…,f},其在星型邻居T中的效用值表示为T(),定义模糊特征的外部效用(f)与其在星型邻居T中的内部效用的乘积之和作为该co-location 模式在星型邻居中的效用值,记为:

例如co-location模式={,,}在星型邻居集中的效用值(,,)=5×0.4+5×0.5+3×0.4=5.2。
(星型邻居中剩余特征的最大模糊效用)星型邻居T的剩余特征最大模糊效用值表示为(T),定义为在包含co-location模式={,,…,f}的星型邻居T中除去的剩余模糊特征的外部效用(f)与内部效用(f,T)乘积的最大值,记为:

例如在表3 的星型邻居中,除去co-location 模式={,,}中的特征外,的剩余最大效用值为()=max{()×(,),()×(,)}=max{0.3,1}=1。
(模式的局部扩展模糊平均效用)对于任意一个co-location 模式={,,…,f}的局部扩展模糊平均效用表示为(),定义为在包含的所有星型邻居中,在星型邻居T中的效用值与T的剩余最大模糊效用值之和与模式的长度加1 的比值,即:


一个模式的局部扩展模糊平均效用值不小于其超集的局部扩展模糊平均效用值。
设模式为一个阶的局部扩展模糊平均效用模式,模式′为模式的任意一个+1 阶超集。因为为′的一个超集,所有包含′的星型邻居一定包含,所以包含′的星型邻居是包含的星型邻居的子集,那么有:
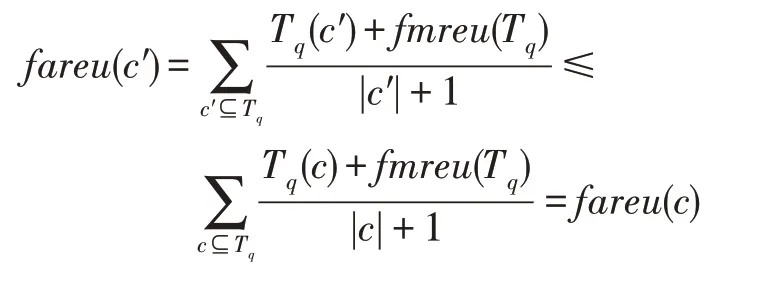
例如,在表3 中,({,,})=4.5,({,})=28.2/3,({,})=18.8/3,模 式{,}、{,}的局部扩展模糊平均效用值不小于其超集的局部扩展模糊平均效用值。
模式的模糊平均效用值不大于其子集的局部扩展模糊平均效用值。
设模式为一个阶的局部扩展模糊平均效用模式,模式′为模式的任意一个-1 阶子集。因为′为的一个子集,所有包含的星型邻居一定包含′,所以有:

例如,在表3 中,({,})=28.2/3,({,})=26/3,({,})=18.8/3,({,,})=5.2,({,,})<({,}),({,,})<({,}),({,,})<({,}),可得模式{,,}的模糊平均效用值不大于其子集的局部扩展模糊平均效用值。
根据引理4 和引理5 可得:如果模式的局部扩展模糊平均效用值小于top-中的最小模糊平均效用值,那么其超集不是top-模糊平均效用colocation 模式。
对于任意co-location模式,有() ≥()成立。
对于任意的co-location 模式有:

例如,在表3中,co-location 模式={,,},()=4.5,()=7.1,()<()。
根据定理2,可以设计算法2:基于局部扩展模糊平均效用剪枝的优化算法。
优化算法

第1、2 步和算法1 一样,这里将不再赘述。第3步是一个由低阶到高阶反复迭代的过程,直到不能生成候选模式为止:首先,3.1 步由-1 阶的候选模式生成阶的候选模式。然后,在3.2 步中,阶的扩展模式M等于阶的候选模式C。在3.3 步中计算候选模式的()并和进行比较。3.4 步通过表实例和外部效用表计算M中每个模式的模糊平均效用值(),如果()≥,和原中各模式的模糊平均效用值进行比较,模糊平均效用值最大的前个模式替换原中的模式。3.5 步阶数自增,算法跳转到第3 步执行while 循环条件判断,若此时-1 阶的候选模式集不为空,则继续执行while 循环体内部的子句;反之,若C为空,此时不能够生成阶的候选模式,则会跳转到第4 步,返回top-模糊平均效用co-location 模式集,算法结束。
由于本文所提出的两个算法只是在生成候选模式数量方面有区别,根据定理3 对于任意co-location模式,有()≥()成立,可得算法2 能剪去更多的候选模式,在top-模糊平均效用co-location模式挖掘中,查找模式的表实例为最耗时的部分。在算法2 中,通过减少更多的候选模式的数量,进一步减少查找表实例的过程。因此算法2 的效率将高于算法1。
4 实验结果与分析
本文所提出的模糊特征的top-平均效用colocation 模式挖掘的基本算法和进一步基于局部扩展模糊效用剪枝算法(AFU)以及用于比较的算法FHUCO(这是文献[18]中提出的方法,本文对其进行了改进,考虑了模式长度对效用的影响)都采用Java编写,实验环境为Win10 系统,Core i7 CPU 和16 GB内存的计算机。
4.1 真实数据集上的实验与分析
实验中用了两类数据集,即合成数据集和真实的“云南贡山某区域植被”数据集1 和“上海市POI”数据集2。数据集1 的数据分布如图3(a)所示,该数据集包含箭竹、冷杉、桤木、铁杉、云南松等25 个树种,共有13 349 个植株。数据集2 的数据分布如图3(b)所示,该数据集包含23 个空间特征和14 446 个空间实例。在以下实验中,表示模糊特征数,表示邻近距离阈值,表示实例总数量。

图3 真实数据集数据分布Fig.3 Distribution of real dataset
4.2 真实数据集上的实验与分析
在本小节实验中,数据集1 中的范围从2 200 m到2 600 m,数据集2 中的范围从250 m 到300 m,值为40 和80,在实验中也尝试取不同的距离阈值,但如果距离阈值设置小于这个范围,由于数据集本身的分布情况,挖掘不到邻近的实例对或者挖掘到的邻近实例对很少,同样如果距离阈值设置大于这个范围,所有的实例对几乎都满足邻近关系,导致结果没有可比性。在实际生活中值的取值是根据用户的需要进行取值的,本文中值的选取可以随机选取,得到的实验结论都是一样的。FHUCO 中的最小效用阈值对应top-模糊平均的最小效用值。
在图4 中,图4(a)为真实数据集1,图4(b)为真实数据集2。两个图都由于AFU 算法基于局部扩展模糊平均效用值进行了进一步的剪枝,提前过滤掉了更多不可能成为top-模糊平均效用模式,使得候选模式的数量小于基本算法。FHUCO 算法以top-中的最小模糊平均效用值作为效用阈值来挖掘模式,由于FHUCO 算法本身剪枝策略的效用上限值过于宽松,导致FHUCO 中的候选模式始终比提出的AFU 和基本算法多。在图5(a)数据集1 和图5(b)数据集2 中由于AFU 算法可以提前减少更多的低效用模式,其运行时间低于基本算法和FHUCO 的运行时间,FHUCO 所需运行时间最长。值变大,候选模式的数量增加,运行时间也随之增加,top-中的模糊平均效用阈值也降低,使得三个算法top-80 的整体候选模式数多于top-40 的,运行时间整体也增多。随着值的增加,邻近区域的面积也随着增大,邻近区域中实例数相应增多,邻近实例对增多,导致其中团的数量也急剧增多,从而增加了表实例的计算。因此随着距离阈值的增加,三种算法的候选模式和运行时间都随之增加。

图4 真实数据中距离阈值d 对候选模式数量的影响Fig.4 Effect of d on the number of candidate patterns in real data

图5 真实数据中距离阈值d 对运行时间的影响Fig.5 Effect of d on running time in real data
在本小节实验中,数据集1 中=2 500 m,数据集2 中=250 m,值为40 和80,FHUCO 中的最小效用阈值对应top-模糊平均效用co-location 模式的最小效用值。
从图6(a)数据集1 和图6(b)数据集2 中各阶数下候选模式数的变化可以看出,AFU 算法在相同阶数下能过滤掉更多的候选模式,在数据集1 中AFU和基本算法超过5 阶就不再生成候选模式,在数据集2 中AFU 超过6 阶就不再生成候选模式,提前终止了不必要的计算。
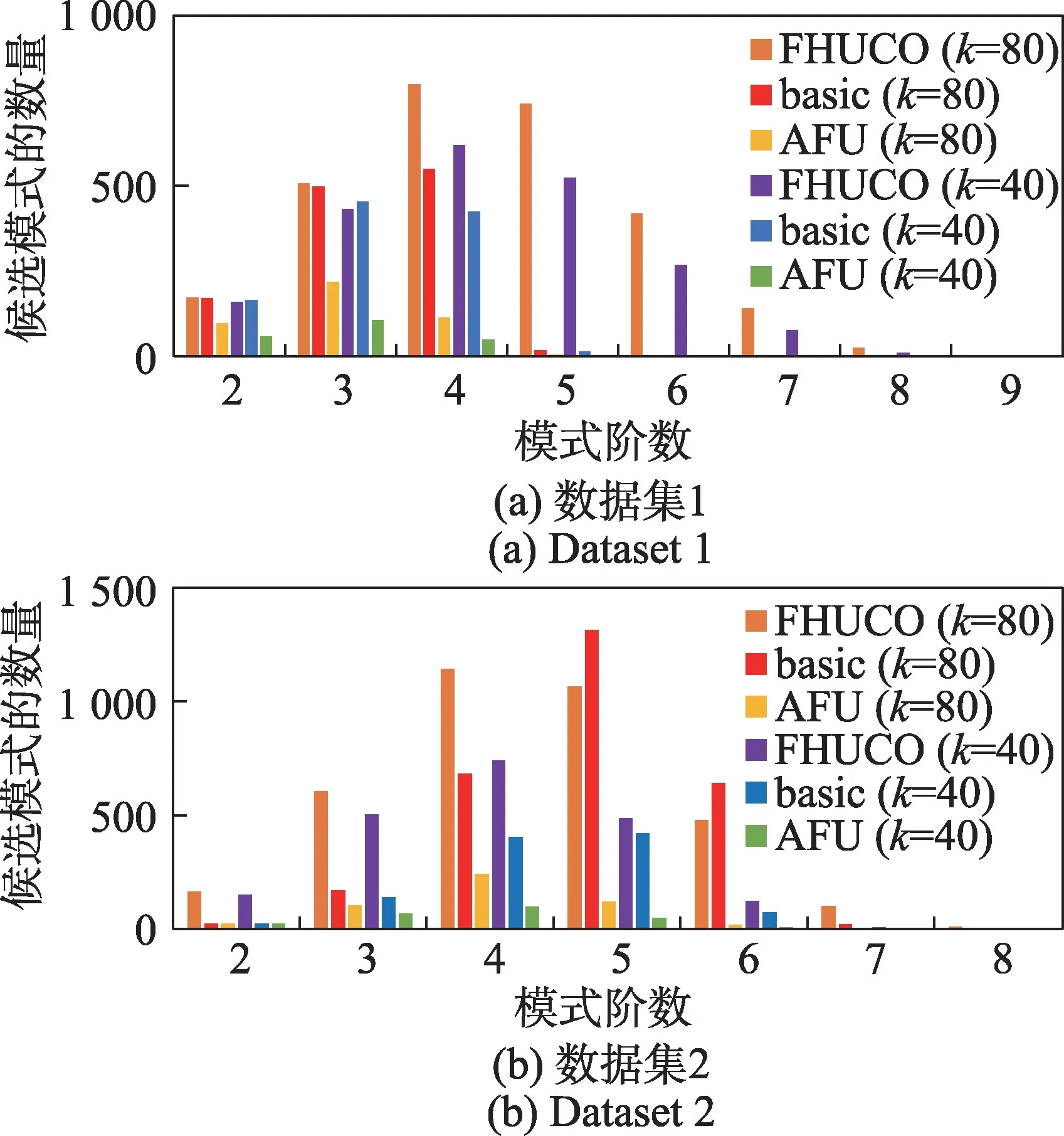
图6 真实数据中模式阶数对候选模式数量的影响Fig.6 Effect of pattern size on the number of candidate patterns in real data
4.3 合成数据集上的实验与分析
在本节实验中,FHUCO 中的最小效用阈值对应top-模糊平均效用co-location 模式的最小效用值。
设置=15,=25,从30 000 增大到80 000。
从图7中可以看到,随着实例数目的增加,三种算法的候选模式的数量都随之增加,这是因为随着实例数目的增加,数据集变得越来越密集。当≥60 000时,FHUCO 算法候选模式数增加速度较快;当=60 000 时,FHUCO 生成的候选模式数是基本算法的12 倍,是AFU 算法的43 倍;当=70 000 时,FHUCO生成的候选模式数是基本算法的12 倍,是AFU 算法的58 倍,其中AFU 产生的候选模式数最少,剪枝效果最明显,这是因为AFU 算法基于局部扩展模糊平均效用值进行了进一步的剪枝,提前过滤掉了更多不可能成为top-模糊平均效用模式,使得候选模式的数量小于基本算法。FHUCO 算法以top-中的最小模糊平均效用值作为效用阈值来挖掘模式,由于FHUCO 算法本身剪枝策略的效用上限值过于宽松,导致FHUCO 中的候选模式始终比本文提出的AFU和基本算法多。在图8 中,由于实例数目的增加会导致实例间距离计算、连接操作的增加,三种算法的候选模式和运行时间都随着实例数目的增加而增加。当实例数目每增加10 000 时,FHUCO 算法的运行时间是前者的3倍左右,基本算法的运行时间是前者的2倍左右。在AFU算法中,运行时间依次增加,是前者的1.6 倍左右,且本文提出的两个算法的运行时间始终少于FHUCO,AFU 所需的运行时间最少,效果最优。
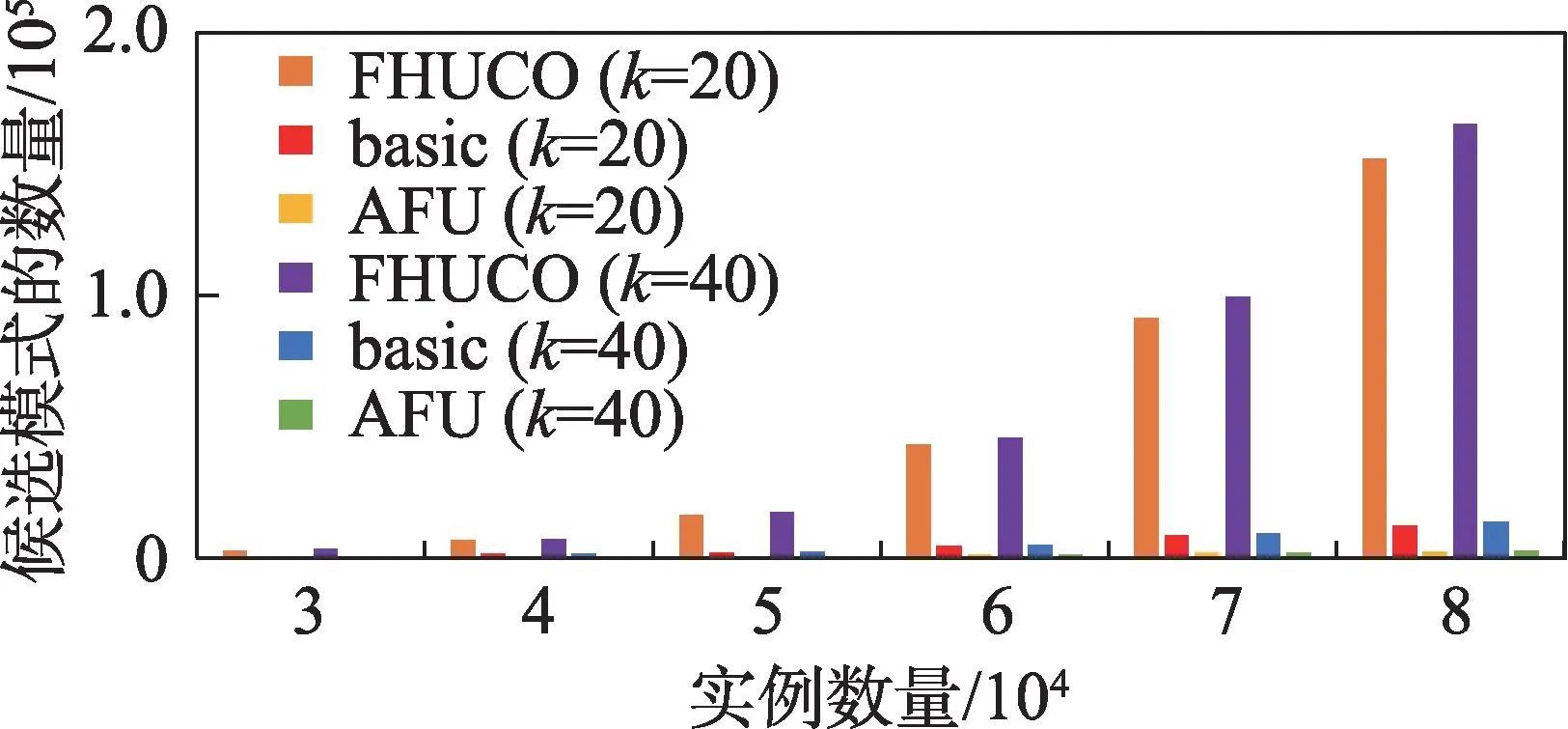
图7 合成数据中实例数量对候选模式数量的影响Fig.7 Effect of the number of instances on the number of candidate patterns in synthetic data
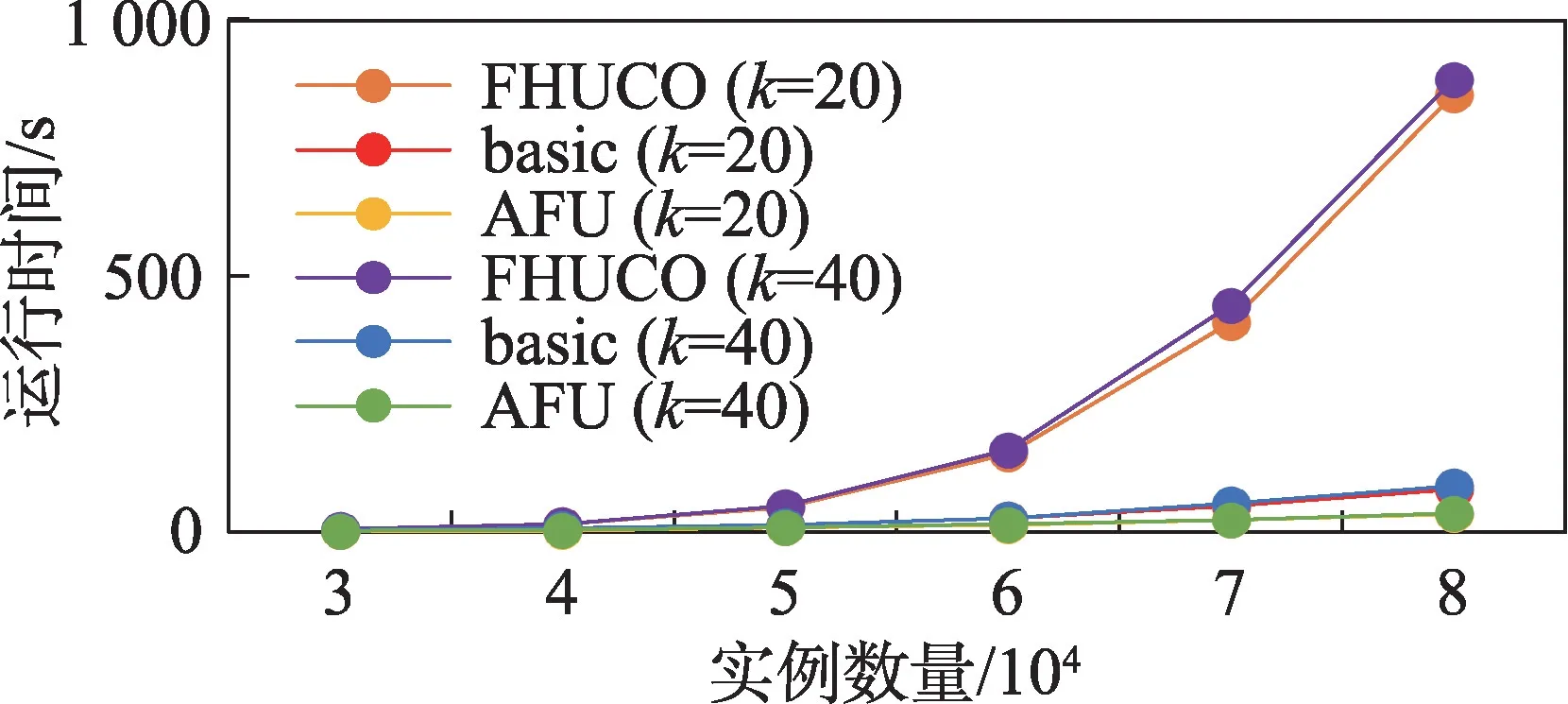
图8 合成数据中实例数量对运行时间的影响Fig.8 Effect of the number of instances on running time in synthetic data
设 置=10,=80 000,=10,从5 到25。在图9 中,随着特征个数的增加,三种算法的候选模式个数都在增加。由于AFU 算法的优势,AFU 的候选模式个数增长速度最慢。在图10 中,随着特征数的增加,三个算法的整体运行时间都在增加,但由于FHUCO 能过滤掉的候选模式数较少,其整体运行速度比基本算法和AFU 都慢。

图9 合成数据中特征数量对候选模式数量的影响Fig.9 Effect of the number of features on the number of candidate patterns in synthetic data
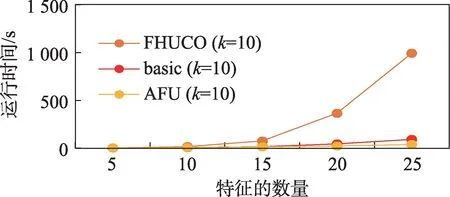
图10 合成数据中特征数量对运行时间的影响Fig.10 Effect of the number of features on running time in synthetic data
5 结束语
本文将top-高平均模糊效用引入到co-location模式挖掘框架中。针对模糊平均效用值不满足“向下闭合”的特性,提出了扩展模糊平均效用的概念,并基于此概念提出了一种模式挖掘的基本算法。为了提高基本算法的效率,又提出了一种局部扩展模糊效用剪枝方法。大量实验结果表明,改进后的算法能够有效、准确地挖掘出用户感兴趣的模式。下一步将继续优化算法,改善其在稠密数据集上的性能。同时考虑基于本体的空间高平均效用co-location模式挖掘问题。
猜你喜欢
保健医苑(2022年5期)2022-06-10
建材发展导向(2021年7期)2021-07-16
中国药学药品知识仓库(2021年18期)2021-02-28
成都信息工程大学学报(2021年6期)2021-02-12
计算机应用(2020年5期)2020-06-07
冰雪运动(2018年3期)2018-12-29
天津诗人(2017年2期)2017-03-16
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
读书(1996年3期)1996-07-15
