
美国All of Us队列项目建设模式与特点分析*
2022-05-11 08:27孙学会陈兴栋
世界科技研究与发展 2022年2期
李 伟 孙学会 徐 萍 陈兴栋 王 玥 许 丽**,
(1.中国科学院上海生命科学信息中心,中国科学院上海营养与健康研究所,上海 200031;2.复旦大学生命科学学院,上海 200433;3.复旦大学人类表型组研究院,上海 201203;4.复旦大学泰州健康科学研究院,泰州 225316)
美国All of Us队列项目(All of Us Research Program,AoURP)是美国精准医学计划(Precision Medicine Initiative,PMI)重点布局的任务[1],目标是建立至少包含100万美国居民的国家级大型队列,以深入研究影响健康与疾病的遗传、社会和环境因素。为体现项目的包容性与开放性,该项目名称于2016年10月由美国精准医学计划队列项目(PMI Cohort Program,PMI-CP)更改为美国 All of Us队列项目,即美国全民队列项目,旨在鼓励全民参与、实现全民受益[2]。美国All of Us队列项目于2015年开始筹备,2018年开始在全美全面实施,并计划跟踪随访数十年(图1)。截至2021年初,该项目已招募约27.6万名核心参与者(指已同意参与,并完成健康状况问卷调查、授权共享电子健康记录、进行体格检查测量、并提供至少一项生物样本等初始步骤的参与者),预计到2024年达到招募100万名核心参与者的目标[3]。该队列采取边建设、边应用的策略,目前已开放共享部分数据[4]。
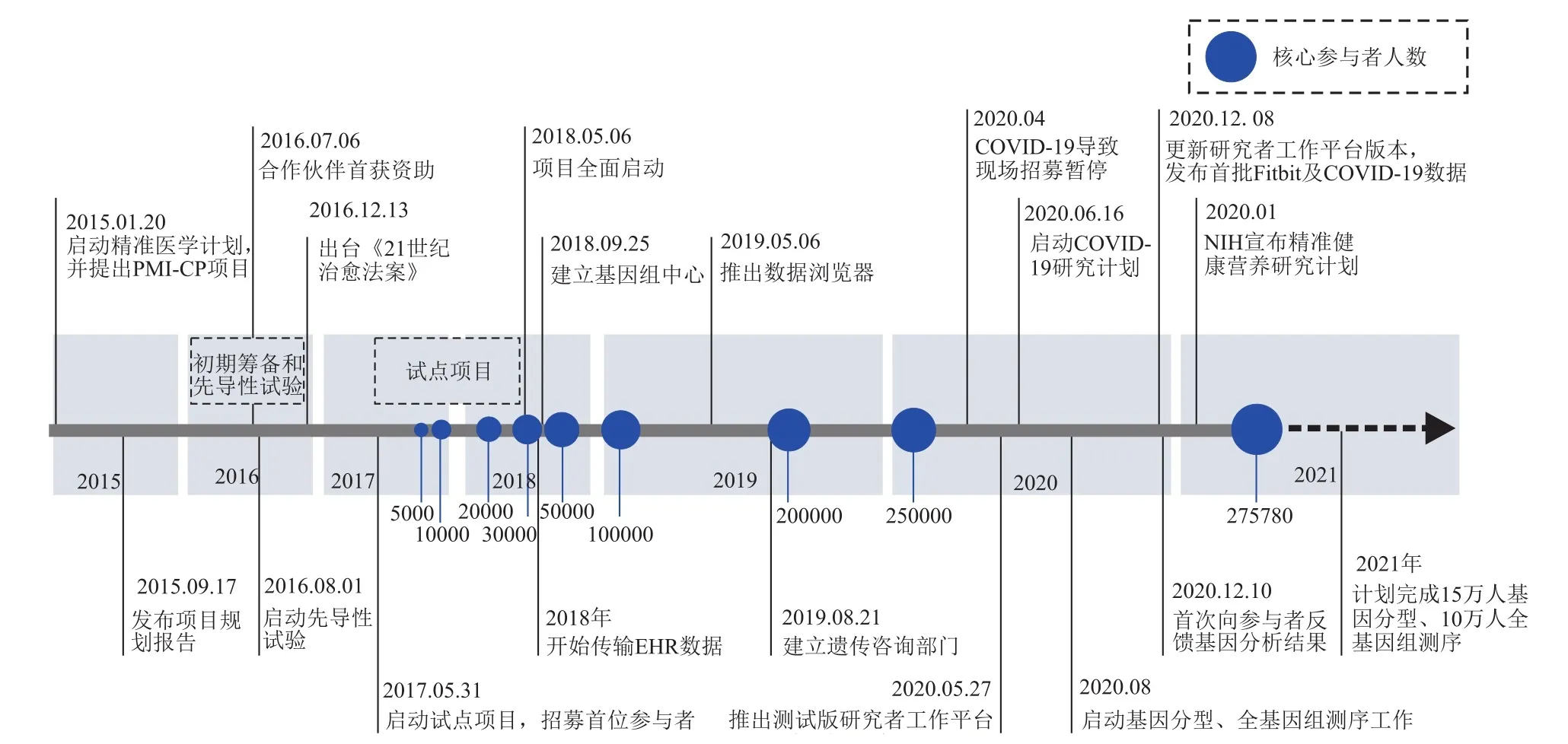
图1 All of Us队列项目发展进程Fig.1 Timeline of the All of Us Program[4,5]
美国All of Us队列项目是由美国政府主导建设、一体化组织和管理的大型队列,其规划设计完善,研究对象的选择更注重人群的广覆盖和多样性,采集资源类型更全面、丰富、精细,通过统一规范管理保证队列资源的标准化、规范化和系统化,并充分利用前沿技术、构建完善法律体系实现数据安全与开放共享等。本文从组织管理视角出发,对美国All of Us队列项目的前期规划设计、组织与管理、经费保障机制进行了梳理,并详细分析了该队列建设中的招募方式、资源采集、数据管理、数据安全与隐私保护、数据共享策略等方面,总结了该队列建设的特点与经验,以期为大型队列建设提供参考。
1 前期规划与预研
美国All of Us队列项目提出之初,美国国立卫生研究院(National Institutes of Health,NIH)即组建了“精准医学计划”院长咨询专家委员会工作组,对项目进行充分论证,并制定详细实施方案。工作组先后组织了4次研讨会、2次公众意见征集、以及多次现场会议和电话会议,与领域专家、政府机构及商业组织进行磋商,广泛征集利益相关者的意见,最终于2015年9月发布了名为《精准医学队列项目——建立21世纪医学研究基础》的项目规划报告(图1),阐释了招募100万人群目标设定的科学依据,提出了队列建设的管理机制、组织模式、招募路径、政策体系,生物样本和数据资源的采集、存储与管理方式等,确立了项目实施的路线图[6]。
同时,All of Us队列项目还经过严谨的试运行与预研,建立了统一的标准和规范的工作流程,以保证数据采集质量和队列建设的标准化、规范化。All of Us队列项目完成初期筹备后,2016年8月开始招募5000名参与者启动先导试验,开展基础设施建设,进行工作流程设计。2017年5月,All of Us队列项目启动参与者招募工作,并开展为期一年的试点项目,测试和改进工作流程。2018年5月,试点项目完成,共招募到2.7万余名核心参与者,随后All of Us队列项目开始正式面向全美居民招募参与者,进入全面建设阶段。
2 组织与管理机制
2.1 一体化的管理与协调体系
美国All of Us队列项目建立了一体化的组织管理体系,以协调各机构的有效合作,推动大型队列的稳定有序运行。All of Us队列项目由NIH集中管理与协调,NIH主任统筹领导,并任命项目首席执行官负责具体事宜。项目首席执行官负责项目的筹资、决策与协调,并领导其下设的指导委员会、执行委员会、项目办公室、机构审查委员会等开展具体管理工作(图2)[7,8]。
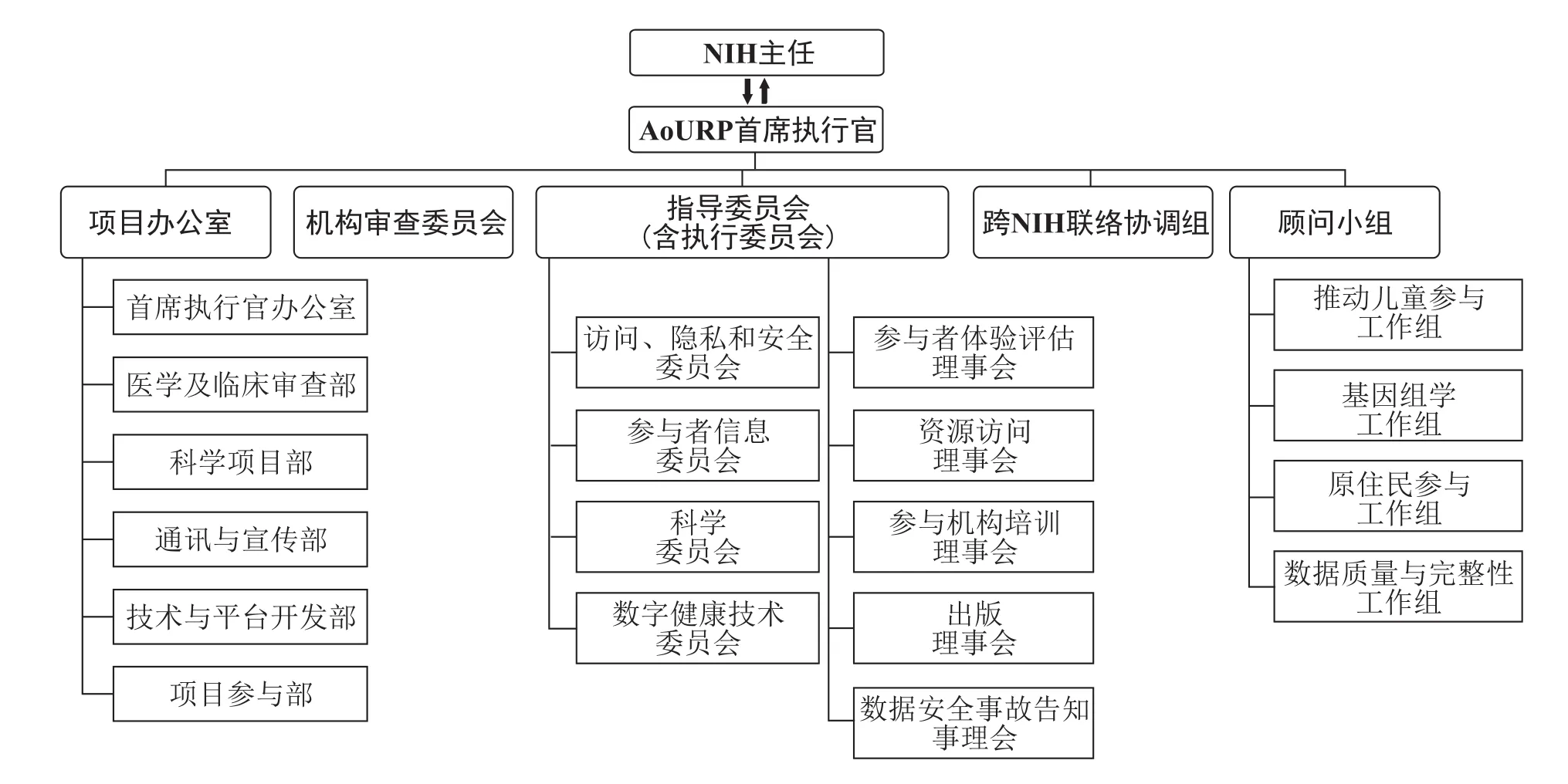
图2 All of Us队列项目的管理体系[7,8]Fig.2 Governance Structure of All of Us Research Program[7,8]
其中,指导委员会负责拟定All of Us队列项目的战略方向,审查项目运作中的相关规划,监督项目实施过程及相关协调工作等,通过设立一系列子委员会和子理事会进行全方位监督。指导委员会的部分成员组成了执行委员会,协助项目首席执行官作出相应决策以应对项目面临的挑战和障碍。此外,项目办公室负责项目规划和运营,且为确保All of Us队列项目运行过程的专业性,项目首席执行官还根据具体研究项目所属领域来选择相应专家建立顾问小组,负责新资助计划审批、研究项目评估等,从而就All of Us队列项目的愿景、科学目标和运营提供外部监督和专家建议。同时,All of Us队列项目重视参与者权益与参与度,一方面设置了负责统一监督、保护研究参与者权益的机构审查委员会,负责审查项目的研究方案、知情同意书以及其他针对参与者的材料;另一方面,通过引入参与者代表在All of Us队列项目的多个管理机构任职,辅助队列项目的设计、实施和管理,实现参与者的深度参与。除以上管理部门外,All of Us队列项目还通过成立跨NIH联络协调组与NIH下属的其他研究所、中心及各办公室进行沟通,协调项目的实施。
在实际运行方面,All of Us队列项目依托全美100余家医疗机构、研究所、高校、企业、社区等各类组织和机构负责具体实施。All of Us队列项目在全美建立了340余个招募站点(Recruitment Sites)开展参与者招募及资源采集工作,并设立参与者中心(Participant Center)统筹协调招募过程、维持参与者的长期稳定参与。All of Us队列项目还建立了中央生物样本库(Biobank)、数据与研究中心(Data and Research Center),对海量生物样本和数据资源进行统一管理。同时,All of Us队列资助美国贝勒医学院、麻省理工学院-哈佛大学博德研究所、华盛顿大学西北基因组学中心以及阿尔法生物技术研究所建立4个基因组研究中心(Genome Centers),对生物样本进行基因组测序和分析。
2.2 长期稳定的经费保障机制
充足的经费来源是大型队列得以顺利建设和运行的有效保障,All of Us队列项目经费主要由政府提供,并通过立法确保了长期稳定支持。
美国投入了2.15亿美元支持精准医学计划的启动,其中60%的经费(1.3亿美元)用于支持All of Us队列项目。此后,在2016年通过的《21世纪治愈法案》[9]中提出,在 10年(FY2017-FY2026)内将为All of Us队列项目拨款14.55亿美元,以确保项目获得长期稳定的经费支持。综合来看,All of Us队列项目经费一方面来源于NIH依据《21世纪治愈法案》设立的创新基金(NIH Innovation CURES Act funds),另一方面来源于NIH院长办公室共同基金(OD Common Fund)和其他基金(Other OD Funds)提供的经费支持。截至2020年,美国政府为All of Us队列项目拨款总额已达15.26亿美元(表1),而2021财年预算为其申请的资助经费为4.36亿美元[10]。
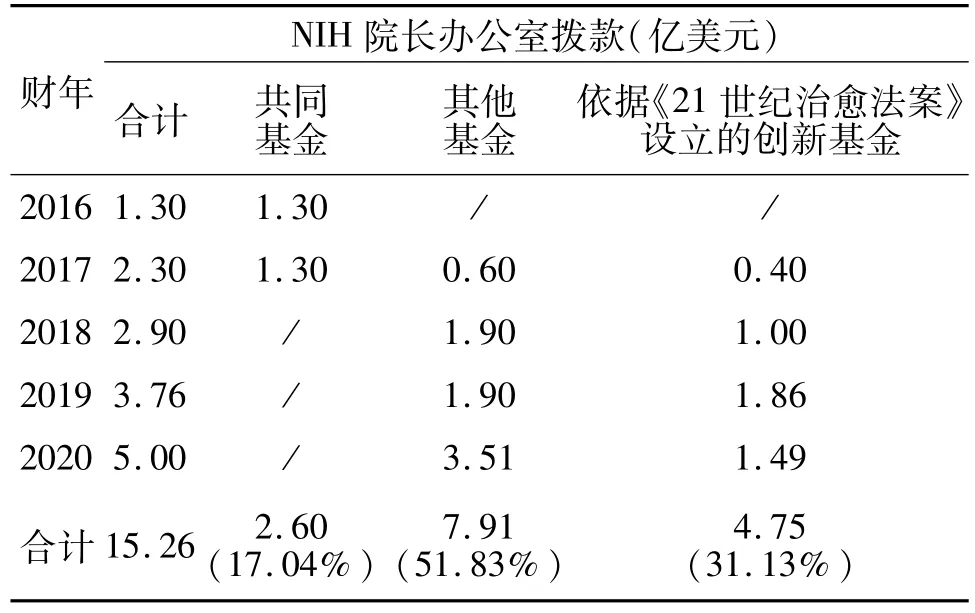
表1 All of Us队列项目获得的执行经费[10]Tab.1 Operating Funds of All of Us Research Program[10]
2.3 数据安全与伦理监管机制
为保障参与者隐私与数据安全,在All of Us队列项目启动之初,美国白宫即成立跨机构工作组,参考美国国家标准与技术研究所(National Institute of Standards and Technology,NIST)的“网络安全框架”(Cybersecurity Framework)制定了《精准医学计划:隐私和信任原则》[11]和《精准医学计划:数据安全政策原则与框架》[12]。All of Us队列项目依据这两项原则和政策指导相关活动和决策,具体措施如:1)采用问责制,开展独立、持续的伦理审查;2)在识别和解决数据安全风险时以“参与者至上”为导向,数据管理全流程对参与者透明;3)在安全、加密的平台上处理、存储和共享数据,且定时审核并测试其安全性和稳定性;4)参与者数据去除个人信息标签,并进一步适当模糊参与者数据;5)数据按照保密级别进行分层级储存、访问和使用;6)用户注册访问及受控访问前,接受安全培训并签署《数据用户行为准则》(Data User Code of Conduct,DUCC)是美国范德堡大学医学中心和All of Us队列项目数据授权用户之间的协议,数据用户必须签署DUCC才能访问和使用注册层级和受控层级数据)。
3 队列建设与运行
All of Us队列项目于2018年5月10日正式面向全美开放,各执行部门和招募站点采用统一的标准和规范化工作流程[13]开展参与者招募、生物样本与数据资源采集、存储和管理(图3)。
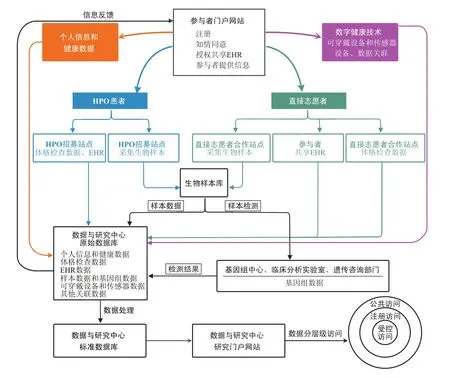
图3 All of us队列项目建设和运行的工作流程[4,13]Fig.3 Workflow for Constructing and Operating the All of Us Research Program[4,13]
3.1 参与者招募方式
All of Us队列项目强调全民参与,招募全美范围内不同地区、种族和社会经济层次的有完全行为能力的成年人。其招募对象为自然人群,即不限制特定疾病或健康状况,并优先招募既往生物医学研究上代表性不足(Underrepresented in Biomedical Research,UBR)的人群。
为实现人群的广覆盖,All of Us队列项目采取与HPO合作和直接志愿者自愿加入两种途径进行招募(图4)。其中,依托HPO招募是主要的招募方式,该途径依托社区卫生中心、区域性医院和退伍军人事务部医疗中心等医疗机构,通过HPO招募站点进行招募,此方式可提高招募效率、降低随访难度和失访率,保障参与者的长期参与;直接志愿者招募则通过社区宣传等方式进行招募,由直接志愿者以个人方式通过参与者中心直接注册参与,并在直接志愿者合作站点进行生物样本和数据采集,这种方式有利于招募医疗服务可及性较低的人群。目前,该项目基于HPO网络以及指定的诊所、血库、实验室或医疗机构建立了340余个站点,参与者可到各招募站点或自行通过项目网站、手机应用程序等方式在线完成注册、基线健康调查及EHR共享授权等步骤,通过健康调查评估后再前往相应招募站点进行生物样本和数据采集(图4)。
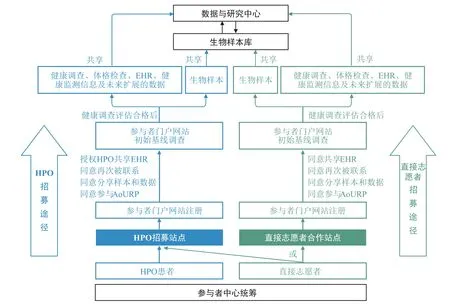
图4 All of Us队列项目参与者招募、生物样本和数据采集的途径Fig.4 Pathway of Participant Recruitment,Biospecimen and Data Collection in All of Us Research Program
3.2 资源采集类型
All of Us队列项目采集的数据类型更加全面和丰富,为研究基因、行为和环境三者相互作用与健康的相关性,实现生物医学研究目标提供坚实数据基础。
All of Us队列项目目前采集的数据和样本资源类型包括基本健康调查数据、体格检查数据、生物样本、EHR以及数字化健康数据(可穿戴设备数据)等,并逐步加入全基因组测序数据、医疗理赔数据、以及环境暴露数据甚至社交网络信息等更多样化的数据(表2)。该项目将开展长达十年甚至数十年的长期随访监测,通过关联EHR、医疗理赔数据等方式持续跟踪采集动态的健康数据,还将邀请参与者就具体研究目的有针对性的提供相关生物样本和数据。

表2 All of Us队列项目数据采集类型和来源[4]Tab.2 Data Categories and Data Sources of All of Us Research Program[4]
3.3 资源存储与管理
All of Us队列项目依托梅奥诊所(Mayo Clinic)和美国范德堡大学医学中心等,建立了国家级中央生物样本库、数据与研究中心,对海量生物样本和数据资源进行统一管理。
3.3.1 生物样本集中存储及分析
All of Us队列项目依托梅奥诊所建立了两个生物样本库:主库和第二生物样本库,存储在主生物样本库中约25%的样本拥有备份,存储在第二生物样本库中。各招募站点通过标准操作流程,使用统一供应的试剂盒采集参与者的生物样本,运送至主生物样本库进行集中存储和分析[13]。之后,生物样本经基因组中心、临床分析实验室(Clinical Validation Laboratory,CVL)等部门进行测序、分析,产生的数据传输至All of Us数据与研究中心进行管理(图5)。形成的分析报告通过遗传咨询资源(Genetic Counseling Resource,GCR)服务部门反馈给参与者[14]。
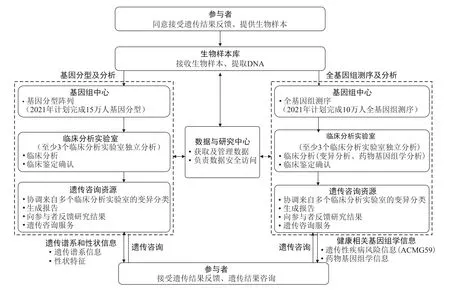
图5 All of Us队列项目遗传分析及遗传结果反馈流程[14]Fig.5 Workflow for Genomic Data Generation and Return of Genetic Results in All of Us Research Program[14]
3.3.2 生物数据分层级存储和管理
队列研究的数据来源复杂、类型丰富,需进行规范化的数据处理和完善后,再进行数据存储和共享(图6)。如,All of Us队列项目采用“观察性医疗成果合作方的通用数据模型”(OMOP Common Data Model)基础结构对EHR源数据进行标准化处理,随后再进行数据核查、清洗和质量控制,以及多源异构数据的分析和整合,再存储到标准数据库中,以支持后续的数据挖掘及综合分析。
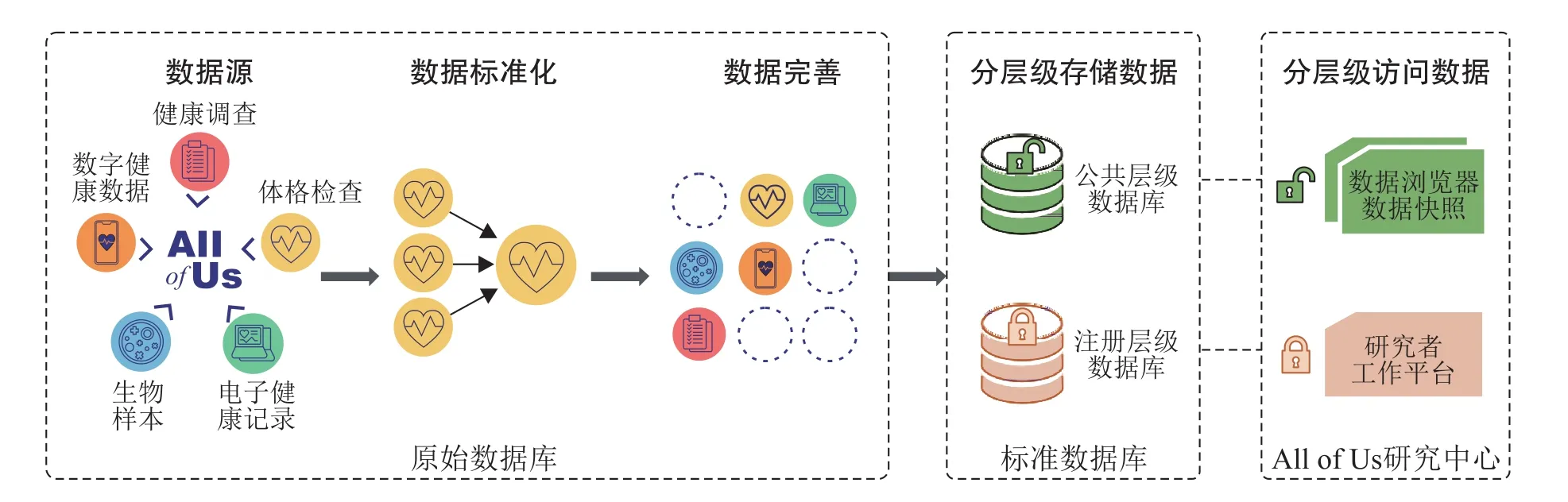
图6 All of Us队列项目数据处理、存储及共享过程Fig.6 Data Processing,Storing and Sharing Procedure in All of Us Research Program
另外,All of Us数据与研究中心利用区块链技术等建立了安全的云环境,对数据进行云存储与云共享,并通过个人信息去标识化、分层级存储和访问数据等措施,以有效保护参与者隐私与数据安全。All of Us队列项目依据可开放程度,将数据分别存入公共级别和注册级别两个独立数据存储库中,其中,公众可通过公共数据浏览器(Data Browser)和数据快照(Data Snapshots)等[15]在线浏览部分安全级别较低的数据集,如反映参与者总体情况的数据;对于更高安全级别的数据集及去除个人信息的个体数据,研究人员可通过“数据通行证模式”(Data Passport Model)获得数据访问授权,利用研究者工作平台(Researcher Workbench)[16]在线访问和使用[17]。
4 总结
大型队列储备了大规模生物样本和数据资源,为生物医学研究和卫生决策提供大量的科研基础和资源支撑,其意义不断凸显,各国相关科技规划也重点布局了大型队列的建设与研究,但仍存在较多挑战。因此,基于对美国All of Us队列项目建设经验的分析,总结出以下特点,以期为大型队列的建设与管理提供借鉴。
4.1 国家主导规划与政府出资,一体化组织与管理确保大型队列顺利建设
美国All of Us队列项目是由美国政府主导建设的大型队列,其顶层设计完善,组织相关领域专家和机构进行了充分磋商与科学规划,制定了科学可行的大型队列建设与实施方案。其组织和管理上,建立了由NIH集中管理,协调全国各类组织和机构共同实施的一体化组织和管理机制,充分调动和集合全国力量共同推动项目实施,提高了队列建设的工作效率和可操作性;建立了以政府资助为主、鼓励社会各界不同主体以资金投入和技术支持等方式参与的多元化资助机制,保障大型队列可获得长期稳定的经费支持,使其得以顺利建设和运行。
4.2 统一规范管理,保证队列资源的标准化、规范化和系统化
在队列建设和资源管理中,首先通过先导试验和试点项目充分开展预研,进行工作流程设计、测试、改进和培训,制定人群招募及数据和生物样本资源采集、存储、管理的统一规范和标准,再依托各地组织和机构设置多个招募站点,采用规范化流程和标准进行队列建设,确保实施流程的顺畅和统一规范。同时,在生物样本和数据资源管理上,建立国家级中央生物样本库和数据库,采用中心化模式进行集中存储及科学管理,并在各环节进行严格的质控、清洗和标准化处理,可有效保证队列资源的标准化、规范化和系统化。
4.3 加强多系统互动,保证队列研究人群的广覆盖和高随访率
队列建设及运行中,其研究人群的招募既依托现有的医疗体系,又设计个人直接参与方式,保证招募人群的广覆盖、多样性,以及随访的高应答率;同时,充分利用国家完善的EHR系统及个人智能穿戴设备,高效整合大量综合医疗记录、主动随访个体健康状况,并通过加强同医疗、医保系统、队列参与者和公众互动,极大的降低研究对象的数据采集、长期随访监测以及随后开展临床试验的难度。
4.4 数据分层管理,实现参与者数据的安全保护与开放共享
在数据安全保护和开放共享上,一方面,充分利用大数据、区块链、人工智能等技术,建立安全的云环境对海量生物样本和数据资源进行云存储、云访问;另一方面,构建完善的隐私保护和数据安全法规制度以及保护措施,采取去除个人身份识别信息等方式进行加密处理;同时,依据可开放程度对健康数据分层级存储和访问,公众可浏览安全级别较低的数据集,科研人员可通过权限申请获得更深层次的数据访问权,既保障了参与者隐私与数据安全,又尽可能广泛地实现数据共享。
猜你喜欢
体育科技文献通报(2022年3期)2022-05-23
南京理工大学学报(2022年1期)2022-03-17
中学生数理化·高一版(2021年2期)2021-03-19
科学导报·学术(2020年26期)2020-10-21
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
军营文化天地(2018年2期)2018-12-15
领导决策信息(2018年16期)2018-09-27
数学学习与研究(2017年3期)2017-03-09
计算机技术与发展(2017年1期)2017-02-22
