
基于对抗训练的中文电子病历命名实体识别
2022-05-11 05:47孔令巍朱艳辉欧阳康黄雅淋金书川沈加锐
湖南工业大学学报 2022年3期
孔令巍 ,朱艳辉 ,张 旭 ,欧阳康 ,黄雅淋,金书川 ,沈加锐
(1.湖南工业大学 计算机学院,湖南 株洲 412007;2.湖南省智能信息感知及处理技术重点实验室,湖南 株洲 412007)
1 研究综述
近年来,人工智能的相关技术发展迅速,现已在不同领域中得到了广泛应用。如在医疗领域中,电子病历(electronic medical record,EMR)的普及化为疾病的诊断与治疗、病历信息的管理等提供了有效支持。电子病历是由记录病人的全部就诊档案所形成的文字、数据、医疗图像、图表等一切资料的总和,它具有简便性、快捷性、环保性等优点。电子病历不仅能方便医务人员了解患者疾病的发生、检查、诊断、治疗等医疗活动,还能在疾病预防等方面发挥巨大的作用[1-2]。但是当前的电子病历文本大部分是以非结构化的形式存储,因而如何快速从电子病历中提取所需要的信息,是命名实体识别(named entity recognition,NER)技术在电子病历文本分析中的重要应用。
命名实体识别任务,是指从非结构化的文本中识别出蕴含具体涵义的实体,例如电子病历中的疾病和诊断、检查、药物以及手术部位等,并将之划分到预定义的类别中。关于在命名实体识别任务中出现的问题,研究者们也曾开展过广泛的研究。R.Panchendrarajan 等[3]提出了一种包含双向LSTM(bidirectional long short-term memory ,BiLSTM)和双向条件随机场(bi-directional conditional random fields,Bi-CRF)的神经网络,其利用单词和字符级别的信息,以及相邻标签之间的依赖关系进行命名实体识别,该模型在多个数据集上被证明是有效的,但是它存在实体边界检测不清晰的问题。王若佳等[4]将Bi-LSTM模型应用到中文电子病历上,并在词的不同标注方案下进行了实验对比,取得了不错的实验效果,但是其模型存在鲁棒性不高的缺点。李纲等[5]通过结合Word2Vec和外部的词典资源,对输入的词嵌入进行了更改,并通过Bi-LSTM-CRF模型,在电子病历的数据集中也取得了较高的F1值,但是其数据集存在实体类别不均衡、模型鲁棒性较差等缺点。杨文明等[6]提出了加入独立循环神经网络(indenpendnetly recurrent neural network,IndRNN)的IndRNN-CRF模型和加入膨胀卷积(dilated convolution,DC)的IDCNN-BiLSTM-CRF模型,并通过在线医疗文本进行了命名实体识别,发现该模型的整体性能都优于BiLSTM-CRF模型的。张旭等[7]将SoftLexicon与BiLSTM-CRF相结合,以引入外部词典资源方法对电子病历进行命名实体识别,实验结果表明,相较于NER传统方法,所提出的方法在识别性能和效率上均显著提升。2018年,谷歌[8]发布了一种新的语言表示模型BERT(bidirectional encoder representation from transformers),它将自然语言任务的处理结果推上了更高的阶段。此后,Jia C.等[9]提出了一种半监督实体增强的BERT预训练方法,此方法将词典整合到NER的预训练中。CCKS2020评测中,晏阳天等[10]通过将BERT与字形字音特征相融合,完成了对电子病历的命名实体识别。杨文明等[11]通过将ChiEHRBERT与多个不同模型进行投票融合,在医学领域的命名实体识别上取得了不错的成绩。
但在上述研究中,词嵌入层均存在实体边界检测不清晰的问题,即位于边界旁侧的样本比远离边界的样本更加容易出现识别错误,从而影响模型的实体识别性能,同时,模型的预测能力以及鲁棒性能均不强。为了解决上述问题,本研究提出将对抗训练融合到BERT-BiLSTM-CRF模型中进行命名实体识别。
对抗训练是新兴起的一门技术,由于早期在自然语言任务上难以有效生成对抗样本,所以多数被应用于计算机视觉领域中。近年来,随着对抗样本相关问题的解决,对抗训练在自然语言的各个方面都渐有成效。C.Szegedy等[12]首次提出对抗样本(adversarial examples)的概念,旨在数据集中添加一些细微的干扰,从而形成对抗样本。I.J.Goodfellow等[13]设计了一种快速生成对抗样本的方法(fast gradient sign method,FGSM),该方法简单可行,并且可以利用该攻击方法产生的对抗样本再次进行对抗训练,它系统地阐释了对抗样本的存在性、攻击性、防御方法3个方面,该方法之后被广泛应用于各领域中。Zhang H.Z.等[14]提出MHA(master high availability)算法,它基于Metropolis-Hastings算法的采样法来生成对抗样本。T.Miyato等[15]又在FGSM的计算扰动部分做了一些修改,并根据具体的梯度进行标准化,从而得到了更好的对抗样本,但存在其实验所花费的时间会大幅度增加的缺点;A.Madry等[16]提出了PGD(projected gradient descent)模型,该模型通过多次迭代,以“小步走,走多次”的策略找到最优扰动。董哲等[17]融合了BERT和对抗训练,从而在食品领域进行命名实体识别,提高了识别实体边界的精准率。
本研究拟将对抗训练融合到BERT-BiLSTM-CRF模型中,并通过对抗训练,在词嵌入层加入扰动因子,生成的对抗样本可以增强模型的抗干扰能力,从而提高模型的鲁棒性和预测能力,解决了模型中鲁棒性不强的问题。
2 基于对抗训练的中文电子病历实体识别模型
2.1 基于对抗训练的实体识别模型
本研究基于对抗训练的模型结构由Embedding层、BiLSTM层和CRF层3部分组成,如图1所示。中文电子病历数据在进入深度学习模型之前,先将分字后的文本经预训练语言模型BERT转换为对应的字向量表示。以图1中的“胆囊多发结石”为例,其中每个字都被处理为字向量,然后将对抗训练的扰动因子与字向量相加得到对抗样本,并将对抗样本送到BiLSTM神经网络中。经前向传播和反向传播获取序列的特征,随后通过CRF层学习序列标签的约束信息,最后得到正确的序列标签。
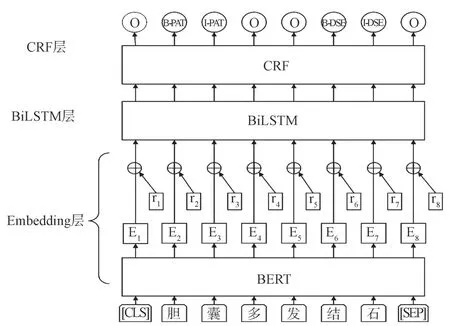
图1 基于对抗训练的模型结构Fig.1 Model structure based on adversarial training
图1中,“[CLS]胆囊多发结石[SEP]”为输入的文本序列,Ei(i=1~8)为输入离散的字转换为连续的字向量表示,ri(i=1~8)为字向量层的扰动。
2.2 BERT模型
BERT是基于深度学习的网络架构,它通过预训练,从大量文本中获取了语义和语法的基础知识,解决了自然语言处理任务中词与词之间颗粒度不同、指代现象,以及词的理解依赖于上下文等问题。其中,BERT模型创新性地给出了MLM(masked language model)和NSP(next sentence prediction)2个任务,各自捕获词级别和句级别的表达,并进行联合训练。MLM主要用于训练深度双向语言的表示向量,方法为遮住句子中的某些词汇,让解码器预测此单词的原始词汇。NSP是指通过预训练一个二分类的语句模块来学习语句之间的关联,具体是让模型学习区分训练语句中的两个输入语句之间是否为连续片段。本研究中建立的BERT预训练语言模型的网络结构,如图2所示。
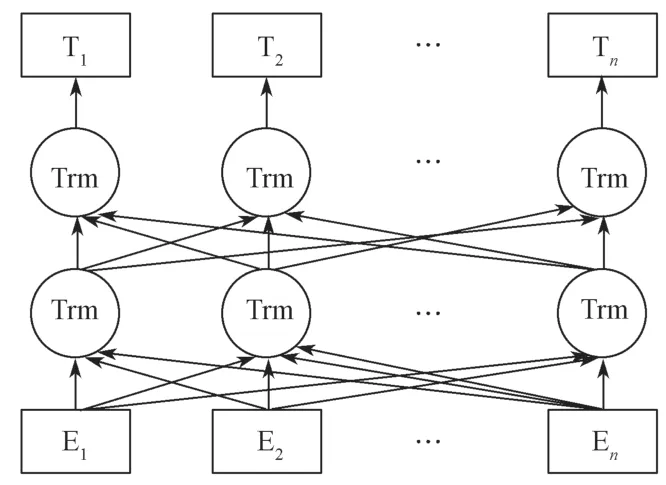
图2 BERT预训练语言模型的网络结构图Fig.2 Network structure diagram of BERT pre-training language model
BERT预训练语言的输入是电子病历中的每一个字符,而输出则是每个字符所对应的特征向量。特征向量由字向量、句子的切分向量和位置向量相加得出。模型的输入如图3所示,第一个位置的符号[CLS]和最后一个位置的符号[SEP]分别代表输入序列的开始位置和结束位置。例如输入的文本是“病人患有胆结石”,经标记处理就变成“[CLS]病人患有胆结石[SEP]”,这两个特殊字符将在分类和划分句子中起到作用。
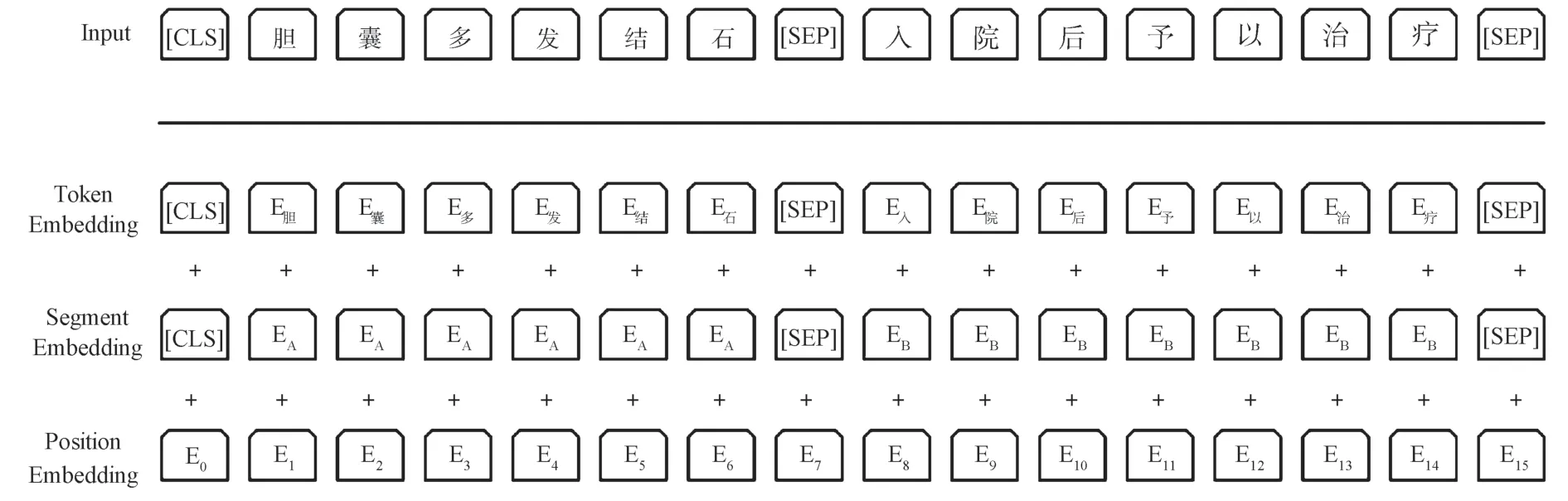
图3 BERT模型输入示例Fig.3 BERT model input samples
在BERT中,字嵌入层是将每个字转化为768维的向量表示,并且文本在输入到字嵌入层之前,会进行标记化处理,即在文本的开头和结尾处插入两个特殊的标记——[CLS]和[SEP],分字后的文本通过字嵌入层转换为对应的向量表示。切分嵌入层主要用来区别两种句子,即判断两个句子的先后顺序,前一个句子的标记都用A表示,后一个句子的标记都用B表示。位置嵌入层则是用来对序列中的每个标记进行编号,用以记录每个标记的位置信息,同时每个编号都对应一个向量。在BERT的一条序列语句中,如果其长度被设置为512,那么位置嵌入层的向量表示为(512,768),位置向量的计算公式如式(1)和式(2)所示。最后,将这3个嵌入层相加,即可以得到其特征向量。
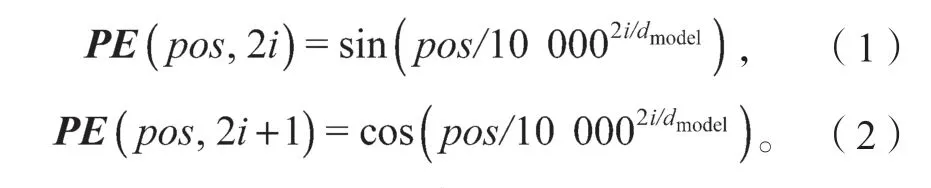
式(1)(2)中:i为电子病历中字的维度;
pos为字所在位置;
dmodel为编码后的向量维度。
本文选用BERT来获取输入向量表示而非传统Word2VEC的原因,在于BERT提高了词与词之间的联系性和表达性,在Word2VEC中,词向量的表达是静态的,即一个词无论在何种上下文环境中,它的向量表示都是相同的。而由于BERT的向量表示中包含了关于周围词的信息,在截然不同的上下文环境中,对这个词向量的表示方式也是截然不同的,即是动态的。因此,BERT为进行对抗训练提供了更加全面的词向量表达。
2.3 对抗训练
对抗训练(adversarial training)是一种引入噪声的规范化监督学习方法,用于提高分类器对于样本数量小或者有损坏情况的样本鲁棒性。该方法通过在嵌入层的字向量中添加一些较小的干扰,而不是在对原始输入的样本本身加以干扰,将获得的对抗样本再馈送给模型。对抗训练也可以认为是在加入扰动后的对抗样本下,预测出真实标签的概率,对抗训练的定义可简化为如下公式 :
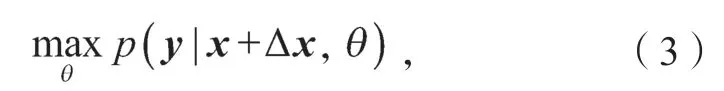
式中:y为真实标签;
x为原始样本;
Δx为添加的扰动;
θ为模型参数;
p为增加扰动后预测真实标签的概率。
在实验中,医疗文本“胆囊多发结石,入院予以治疗”,经过BERT预训练语言模型生成对应的字向量,然后根据字向量、字向量对应标签及模型参数计算出扰动值,将扰动值与字向量相加即可得到对抗样本。其中,常见的扰动计算方法有两种,其一为FGM(fast sign method)法,具体思路以输入序列的嵌入向量x=[v1,v2, …,vt](式中v为字向量,t为字的位置下标)为例,首先复制预训练阶段的词向量字典,计算出x的梯度,并且根据梯度作标准化处理得到扰动值Δx,扰动值的计算公式如式(4)所示;随后将得到的扰动值与x相加,用新的词向量重新求出其梯度,并累加到原梯度上,然后根据此时的梯度对参数进行更新。
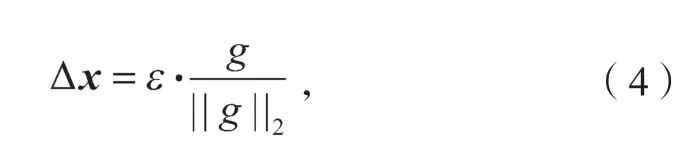
式中:ε为一个缩放因子;
g为损失函数关于x的偏导,即梯度,且
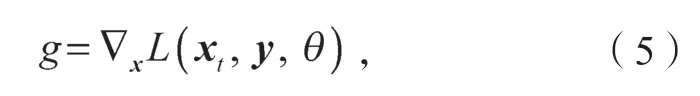
其中,L(x,y,θ)为损失函数。
2.3.1 FGM算法描述
对于数据集中的x:
1)计算x的前向损失、反向传播得到梯度;
2)通过embedding矩阵的梯度算出Δx,并加在当前embedding上,结果相当于是x+Δx;
3)计算x+Δx的前向损失,反向传播得到对抗的梯度,累加到1)的梯度上;
4)将embedding恢复为1)时的值,并根据3)的梯度对参数进行更新;
5)重复以上过程,直到模型训练全部完成。
FGM的思路是梯度上升,但是由于它的跨步大,有可能无法找到约束内的最优点;相较于FGM来说,PGD进行数次迭代,运用“小步走”的策略,从而找到最优解。PGD的扰动值计算公式如式(6)和式(7)所示。
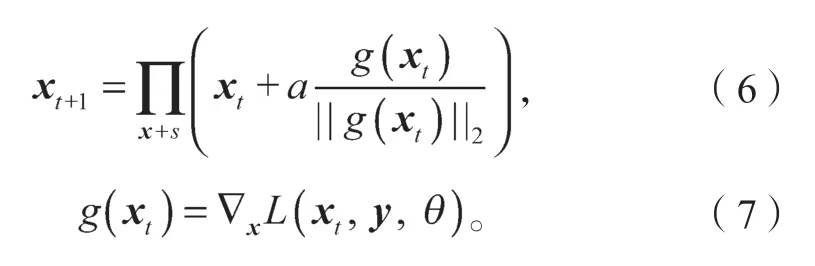
式(6)(7)中:
α为步长;
xt、xt+1分别为前一次和后一次的词向量。
2.3.2 PGD算法描述
1)对于数据集中的x,通过计算x的前向损失以及反方向传播,获得梯度并备份;
2)对于每步k,通过embedding矩阵的梯度计算出Δx,并且加到当前的embedding上,就相当于x+Δx;
3)如果k不是最后一步,则将梯度归零,根据1)的x+Δx计算前向和后向的梯度;
4)如果k是最后一步,则恢复1)的所有梯度,计算最后的x+Δx,并把所有梯度累加到1)上;
5)将embedding恢复为1)时的值,并根据4)的梯度对参数进行更新;
6)重复以上过程,直到模型训练全部完成。
2.4 BiLSTM网络
LSTM(long short-term memory)模型是一种RNN(recurrent neural network)模型,它是对Simple RNN的改进,同时LSTM模型通过门控制单元避免了梯度爆炸。相比RNN来说,LSTM对于输入中长期依赖的信息拥有更优秀的表达,单个LSTM神经元及其运行机制如图4所示。
美国学者Tamanaha在阐述法治的作用时说:“法治不是有关人民寄希望于政府的任何美好事物。对它作这种解读的终极诱惑是法治具有象征性力量的实际证明,但我们不能沉迷于它。”[16]对“法不禁止皆自由”这条奉为圭臬的法治原则亦应当辩证地看待,缺乏法律边界的自治并非解决任何问题的灵丹妙药。政府对网约车的管理正体现了自由状态下的适度管制,网约车管理领域适用负面清单模式并非完全照搬,也需要因地制宜、适度修正。
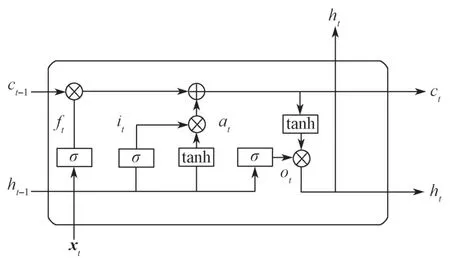
图4 LSTM内部结构示意图Fig.4 LSTM internal structure diagram
LSTM模型的遗忘门、输入门、输出门,以及隐藏状态的计算公式分别如下:
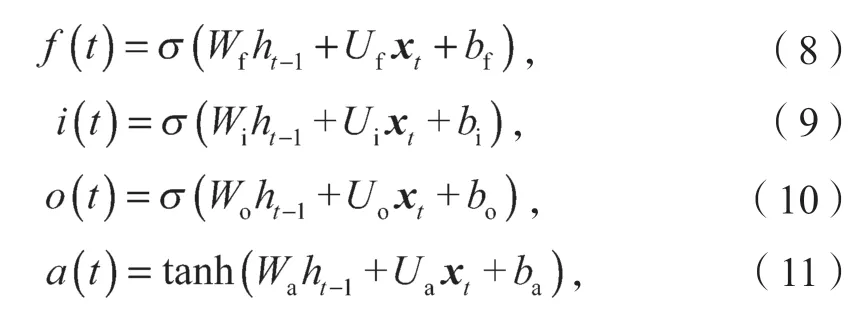
式(8)~(12)中:xt为t时刻的输入;
ht-1为t-1时刻的隐藏层状态值;
Wf、Wi、Wo、Wa分别为遗忘门、输入门、输出门以及在特征提取过程中ht-1的权重系数;
Uf、Ui、Uo、Ua分别为遗忘门、输入门、输出门以及在特征提取过程中xt的权重系数;
bf、bi、bo和ba分别为遗忘门、输入门、输出门以及在特征提取过程中的偏置值;
由于遗忘门和输入门计算的结果作用于c(t-1),构成t时刻的细胞状态c(t)表示为
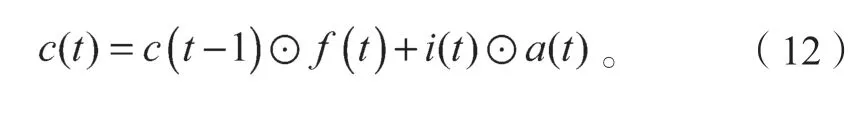
最终t时刻的隐藏层状态h(t),可由输出门o(t)和当前时刻的细胞状态c(t)求出:

由于LSTM只能保留处理过的信息,但是在序列标注任务中,上下文的信息同样重要,于是提出在原本的模型结构上再加上一层反向的LSTM,从而组成BiLSTM,如此,便可以对上下文同时进行信息处理。在本实验中,经Embedding层得到的对抗样本分别以正序和逆序方式被注入到LSTM中,然后将两个输出的特征向量加以拼接,作为最后的特征向量表达式。
2.5 CRF层
在本实验中,BiLSTM层输出的特征向量经由CRF层确定最终的输出标签,即“胆:B-PAT”、“囊:I-PAT”、“多:O”等。CRF层相较于BiLSTM层,不仅能确保输出标签之间的关系,而且会在标签之间创造规则,起到了约束作用。对于每一个序列的输入x,得到了预测标签序列y,定义预测得分函数S的表达式如下:
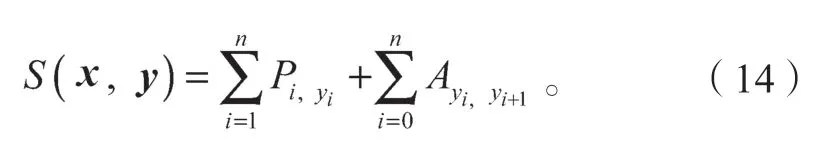
此函数有效弥补了BiLSTM的不足,对标签之间的关系起到约束作用,如在一个以人名为实体的例子中,I-Person不能存在于B-person前。随后对每个训练样本X,求出代表每个可能性的标注序列y的分数S,并且对每个分数进行归一化处理,公式如式(15)所示:
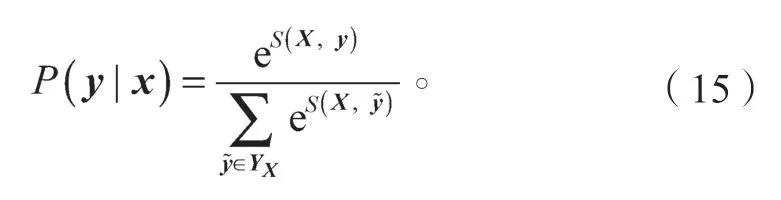
式中:y为正确的标注序列;
YX为所有出现的标签序列。
然后,利用对数似然法求出它的损失函数:
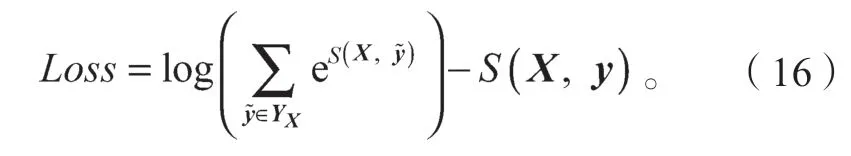
随后,用梯度下降法进行网络学习,更新参数,直到训练结束。
预测时,通过训练好的参数求出每个可能的y序列所对应的S得分,本文在此处采用维特比算法,算出最高概率标签序列y*。
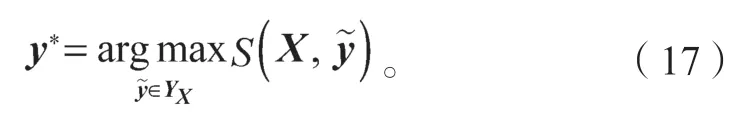
3 实验设计与结果分析
3.1 中文电子病历数据集
为了能更加全面地评估本文中对抗训练模型的效果,在两个数据集上对模型进行相关实验。其一为CCKS2021面向中文电子病历的医疗实体以及事件抽中任务一的数据集,以下简称为数据集1 ;另一个数据集同样为医疗电子病历数据,不同的是,相比于数据集1,其中“疾病和诊断”与“解剖部位”两类数据略多于其它4类数据,此数据集各类别的数据分布更加均匀,以下简称为数据集2。CCKS(China Conference on Knowledge Graph and Semantic Computing)评测目的是为了建立检测知识图谱与语义计算相关技术,以及软件系统的网络平台与信息资源,而本次CCKS2021的实体识别任务是环绕中文电子病历语义化展开的系列评测的一种扩展,它是在CCKS2020评测任务的基石上做出的继续与扩充。数据集1具体标注有实体的起始位置和终止位置,以及预定义类别,其类别依次为疾病和诊断、检查、检验、手术、药物、解剖部位等6种,具体的类别定义参考表1。

表1 CCKS2021预定义实体类型Tabel 1 CCKS2021 predefined entity categories
数据的标注方法为BIO 三位标注法,即B-X代表实体的开头,I-X代表实体的结尾,O代表不属于任何类型的非实体。数据集1有1 500条数据,数据集2与数据集1的标注方法以及预定义类别相似,共有1 300条数据。将各数据集中的数据按照6∶2∶2的比例,划分为训练集、验证集和测试集,具体的划分情况参见表2。

表2 实验数据集的划分Table 2 Experimental data division
3.2 评价指标
此次实验采用精确率P(precision)、召回率R(recall)和F1值为主要评价指标。精确率又称查准率,是指实际预测正确的标签数量占全部预测正确标签的比率;召回率又称查全率,是指实际预测正确标签占全部正确标签的比率;F1值则是精确率与召回率之间的调和平均值。各指标的计算公式如(18)~(20)所示。
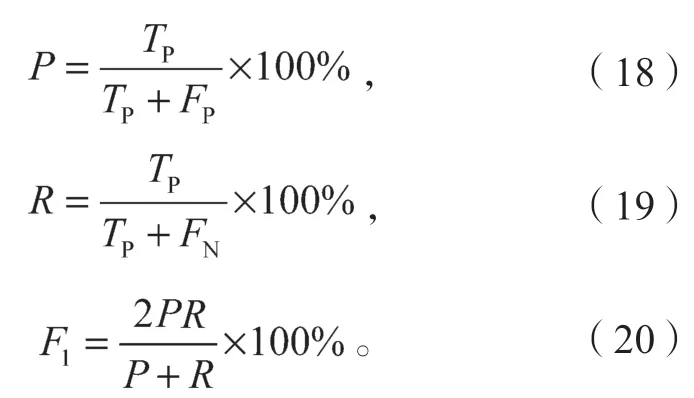
式(18)~(20)中:
TP为序列中实际预测正确的标签;
FP为实体为非正确标签却被预测为正确的标签;
FN为实体为正确标签却被预测为非正确的标签。
3.3 实验环境及参数设置
本次实验环境如下:操作系统为Ubuntu 16.04 LTS,CPU i7-10750H@2.60 GHz,内 存 为8 GB,GPU NVIDIA Geforce RTX2080Ti,Python3.8,Pytorch1.6.0+cu101。
本次实验的参数设置如下: BiLSTM隐藏层单元数为768,Batch_size为8,学习率设置为0.000 1,Epoch为40。
3.4 实验方案
为了验证对抗训练在中文电子病历上命名实体识别的表现,将BERT-BiLSTM-CRF、BERT-FGMBiLSTM-CRF、BERT-PGD-BiLSTM-CRF模型分别在数据集1和数据集2上进行实验,具体实验步骤如表3所示。

表3 实验设计方案Table 3 Experimental design scheme
3.5 实验结果与分析
根据上述实验方案,得到的各实验方法下的数据集识别结果如表4所示。
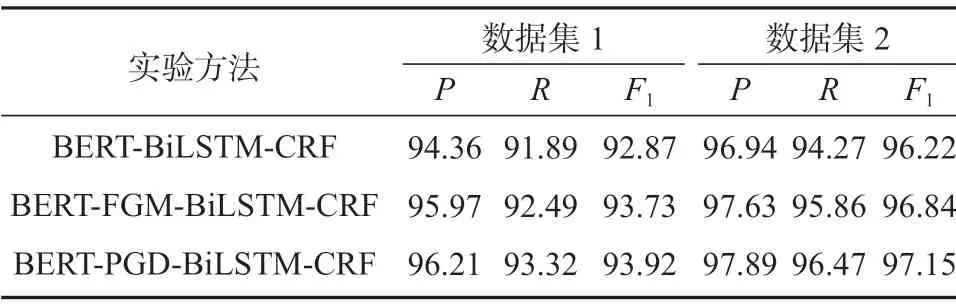
表4 实验结果对比Table 4 Comparison of experimental results %
分析表4中的实验数据可以得知,相对于基线模型BERT-BiLSTM-CRF,基于对抗训练的BERTFGM-BiLSTM-CRF模型和BERT-PGD-BiLSTM-CRF模型,它们在两个数据集上的实体识别效果、识别精度均有不同程度的提升,其中加入FGM的实体识别模型,其F1值在两个数据集上分别提升了约0.86%和0.62%;而加入PGD方法的实体识别模型,其F1值在两个数据集上分别提升了约1.05%和0.93%,由此可见,加入了PGD法的模型的识别效果要略优于加入FGM法的模型。究其原因,很可能是由于这两种对抗训练迭代攻击的次数不同,FGM只进行了一次迭代,而PGD是一种迭代攻击的方法,它进行了多次迭代,并且每次迭代都将扰动投射到规定范围内,从而造成了结果上的差异。
加入了FGM法和PGD法的模型在面对输入数据的微小变动时,依然能够保持高精度的识别效果,而且本文模型不只在一个特定的数据集上保持良好的识别效果,对于新数据,它依然能够保持敏感性,说明加入对抗训练的模型在面对数据变化时依然能够保持其稳定性及鲁棒性。
综上所述,加入对抗训练的模型能够提升命名实体识别在中文电子病历上的准确性以及模型的稳定性,同时对于实体标签的预测能力也相应提高。
4 结语
为了进一步提高命名实体识别在中文电子病历上的精确率,本文提出了加入FGM和PGD对抗训练方法的命名实体识别模型,该方法在中文电子病历评测任务中达到了良好的成效。但是中文电子病历的命名实体识别尚有较大的改善空间,在后续研究中可从如下方面着重加以完善:
1)由于中文电子病历中存在大量的专有词汇,导致识别困难,可加入专有医疗词典提升实体识别对于专业医疗词汇的识别率;
2)加入对抗训练的模型普遍具有需要花费较长时间的特点,后续将研究更有效的方法,以提升模型的识别效率。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
科学家(2022年3期)2022-04-11
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
作文评点报·低幼版(2020年25期)2020-07-23
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
福建基础教育研究(2019年3期)2019-05-28
西部资源(2018年1期)2018-11-01
中国社区医师(2016年8期)2016-12-20
中学生数理化·高三版(2016年9期)2016-05-14
高中生学习·高三版(2016年9期)2016-05-14
