
基于半监督多视图特征协同训练的网络恶意流量识别方法*
2022-05-10 02:20:46卢宛芝丁要军
通信技术 2022年4期
卢宛芝,丁要军
(甘肃政法大学 网络空间安全学院,甘肃 兰州 730070)
0 引言
随着互联网应用的快速发展,加密技术和伪装技术不断升级,基于传统深度报文解析(Deep Packet Inspection,DPI)的网络流量识别方法准确率下降,使用机器学习和深度学习[1]进行网络流量分类是目前较为准确的方法。传统的有监督机器学习需要大量标记样本来训练分类模型,但获取准确标记的网络恶意流量训练样本较困难,而现有的网络流量采集设备很容易获取到大量的未标记样本,因此使用少量标记样本和大量未标记样本共同训练分类模型的半监督学习受到了学界的高度重视。
2007 年Erman 等人[2]首次提出将半监督学习应用到流量分类领域,解决了传统流量分类方法无法对未知流量进行提取和分类的问题。Rezaei 等人[3]使用一维卷积神经网络(Convolutional Neural Networks,CNN)模型,通过无监督预训练和有监督微调,仅使用流的前几个包就达到了比监督学习更好的识别准确率。协同训练[4]作为半监督领域的重要分支之一,在图像识别等领域取得了很好的成绩。网络流量识别领域中,Wu 等人[5]提出了基于Co-training 的入侵检测算法,在训练过程中可以提高检测准确率,但训练时间较长且算法稳定性有待提高。
目前网络流量的特征表示方式[6]分为字节流特征、统计特征、数据包的时间序列特征和有效载荷数据,但现有的研究成果大多是基于一种特征表示方式进行网络流量识别。本文提出一种融合原始字节流特征和网络流统计特征的多特征视图,通过协同训练结合大量未标记样本进行网络恶意流量识别,来提升模型的鲁棒性。
1 网络流量特征表示
1.1 字节流特征
网络流指具有相同五元组(源IP、源端口、目的IP、目的端口、传输层协议)的所有包。本文参考Wang 等人[7]对数据的处理方法,将原始流量pcap 切分为多个流,只选取每个流的前784 字节,每个字节对应取值范围在[0~255]之间,输入堆叠自动编码器(Stacked Auto Encoder,SAE)进行无监督的自动特征提取,编码器输出一组编码后的高级特征作为协同训练的特征视图a,如图1 所示。
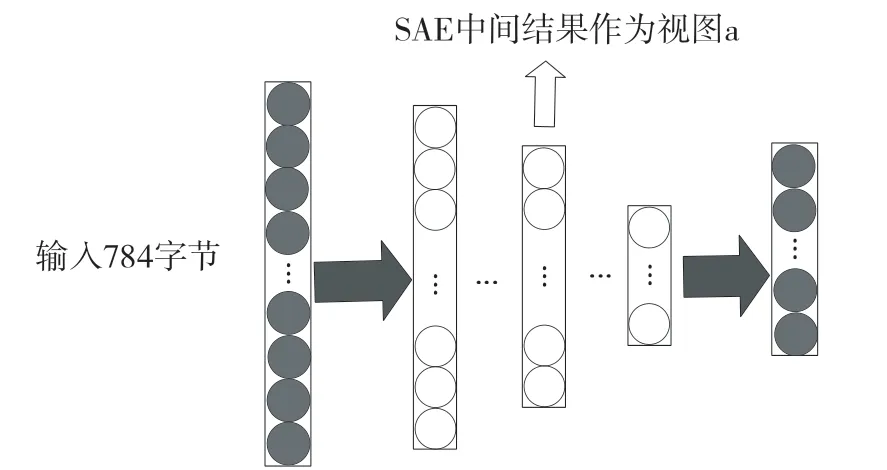
图1 SAE 生成字节流特征视图a
1.2 统计特征
数据流可以通过IP 数据包统计特征[6],如包最小时间间隔、包总数、平均字节数等。定义数据集X=[X1,X2,…,XN]T是由N个网络流量样本组成的数据集,对于每个流量样本Xi都有m个统计特征,即Xi=[xi1,xi2,…,xim],向量Y=[y1,y2,…,yN]T表示数据集中每个流样本的类别,如Dos Hulk、Zeus 等。针对数据集81 个统计特征,为了降低训练模型对端口信息的依赖,删除目的端口和源端口两个特征,用随机森林算法[8]进行特征选择,选择40 个统计特征作为视图b,其中部分特征如表1 所示。
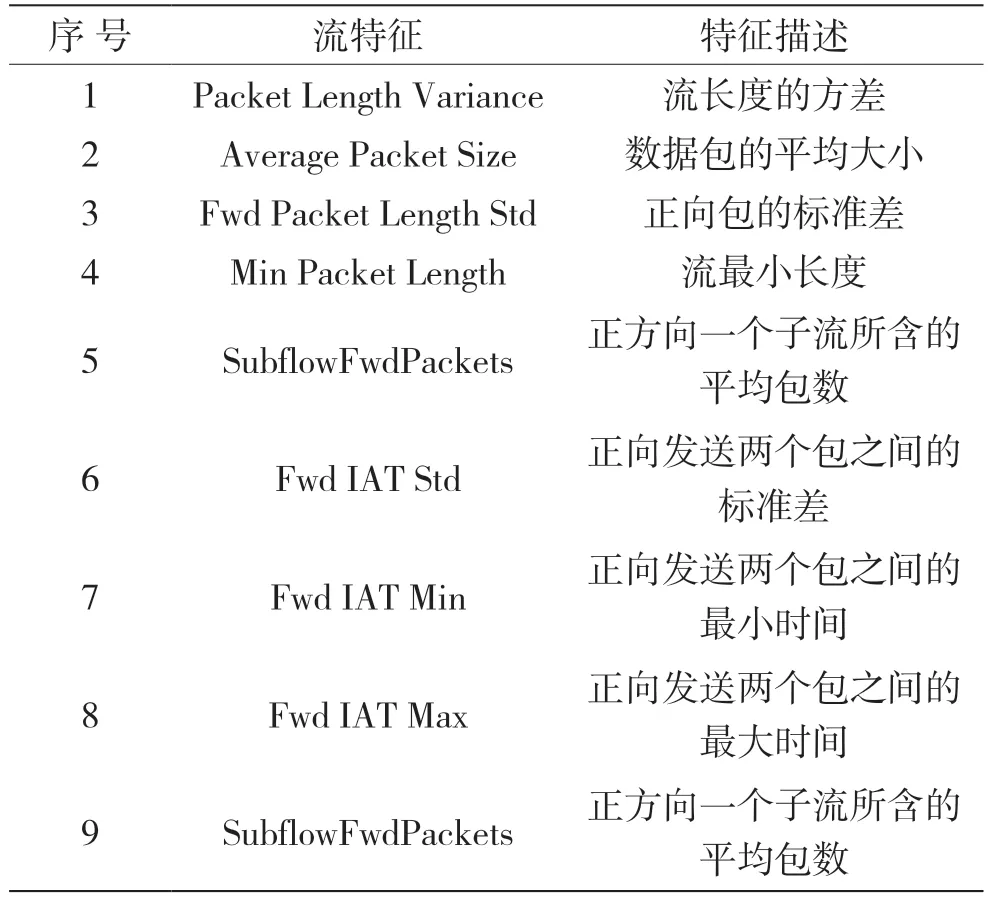
表1 部分网络流统计特征
2 基于半监督多视图特征协同训练的网络恶意流量识别方法
2.1 基分类器
本文使用极端随机树[9](Extremely Randomed Trees)作为协同训练的基分类器,并作为一种集成算法,在节点分裂时随机从M个特征中选择m个特征,以基尼系数或信息增益熵选择最优属性进行分裂,分裂过程中不剪枝,直到生成一个决策树(基分类器),最后利用投票决策对所有基分类器统计产生最终分类结果。一般来说,极端随机树算法优于决策树,具有更好的平滑性,能有效减小偏差和方差,对于一个z维输入空间,极端随机树的集合可以产生一个连续的分段多线性逼近样本lsz,为了证明这一点,考虑大小为Z的样本数。

式中:sz代表样本z的大小;是一个n维的特征向量;ni为对应输出值
设第j个属性的样本值通过增序取得,则样本值可简化为:
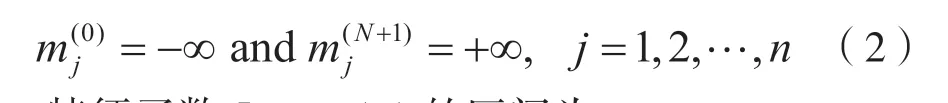
特征函数I(i1,i2,…,in)(m)的区间为:
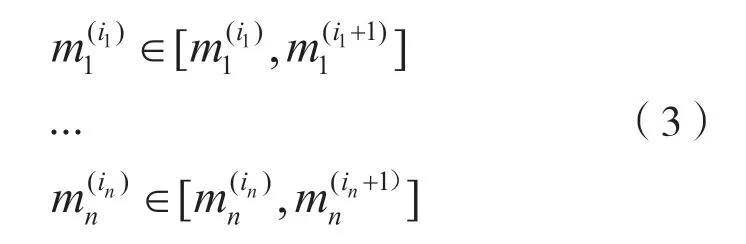
基于此得出一个无限极端随机树的近似表示(m):
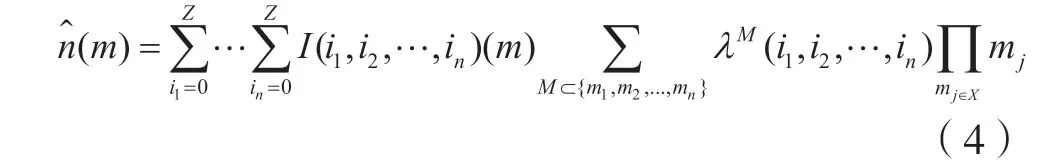
式中:参数λM(i1,i2,…,in)由输入样本mi和输出样本ni决定。
因此,分别使用原始字节流特征和网络流统计特征两种特征视图,训练两个基分类器,保证了视图的差异性,能进一步提升最终集成模型的准确率。
2.2 基于协同训练的网络恶意流量识别
协同训练算法最初的思想是在两个独立的属性集上训练两个分类器,并将其中一个分类器的预测样本加入到另一个分类器的训练集中,如此反复训练,样本得到扩充,分类界面得到修正。
如图2 所示,xi(i=1,2,3,…) 为有标签数据,xj(j=1,2,3,…)为无标签数据。首先对标记的数据xi进行拆分,得到两种不同视图下的数据表示xi1,xi2;其次使用基分类器C1、C2 作为初始分类器训练两种视图;最后利用初始分类器估计未标记样本的标签置信度,将可信样本加入训练数据集进行迭代训练,优化分类器,当所有未标记的样本都完成自我标记时训练结束。
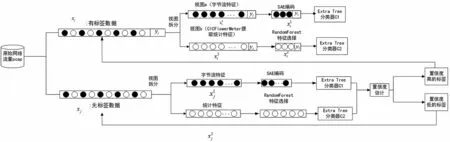
图2 基于半监督多视图特征协同训练的网络恶意流量识别方法结构
2.3 协同训练算法描述
协同训练算法首先定义标记数据集L由x1和x2组成,记为L(x1,x2),并在x1和x2分别训练两个分类器h1和h2;从未标记数据集U随机选取u个样本放入集合U中。算法如下:
(1)有标签的网络流量训练集L,无标签的网络流量训练集U´;
(2)循环K次用L的x1部分训练一个分类器h1,用L的x2部分训练一个分类器h2;
(3)用h1对U´中的所有数据进行标记,从中选出p1,p2,p3个正标记和n个负标记,用h2对U´中的所有数据进行标记,从中选出p1,p2,p3个正标记和n个负标记;
(4)选择置信度(confidence score) 高 的2(p1+p2+p3)+2n个标记加入到L中;
(5)随机从U中选取2(p1+p2+p3)+2n个数据补充到U´中,直到所有的无标记数据全部加标记放入到L中时,结束循环,训练终止。
3 实验结果及分析
3.1 数据集
CIC-IDS2017[10]数据集由加拿大网络安全研究所(Canadian Institute for Cybersecurity,CIC)于2017 年发布,USTC-TFC2016[11]数据集是捷克共和国的捷克理工大学(Czech Technical University,CTU)的研究人员采集,如表2 和表3 所示。
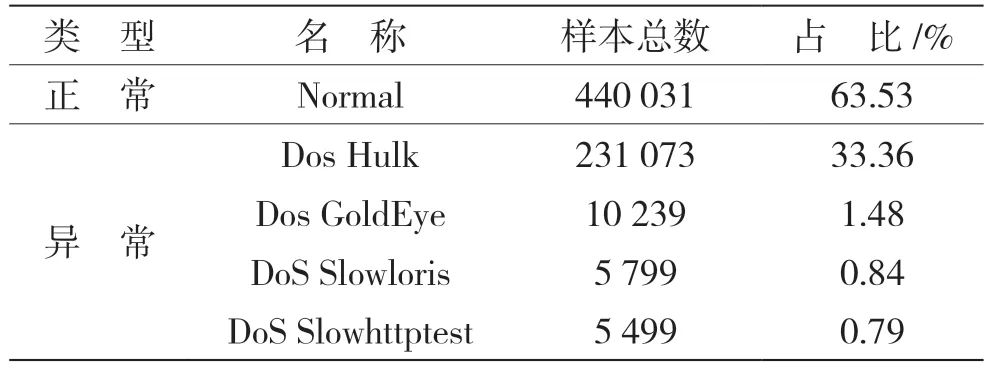
表2 数据集CIC-IDS2017 介绍
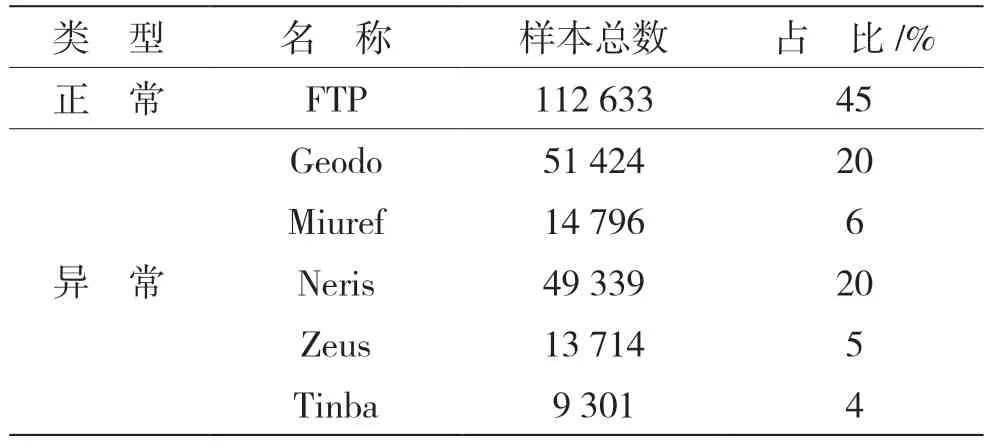
表3 数据集USTC-TFC2016 介绍
3.2 评价指标
本实验采用总体准确率、查准率、召回率、F1值来作为评估性能的指标。
3.3 实验环境
实验平台使用的软件框架是Pytorch 1.3.1,运行在Windows10 系统环境下,16 GB 内存,Intel(R)Core(TM) i5-9300H @ 2.40 GHz 处理器,实现Cotraining 框架。
3.4 协同训练双视图生成
本文通过使用网络原始流量的两种特征表示方式,自然地将同一数据集分割成两个相互独立的视图,分别作为协同训练模型的视图a 和视图b,详细过程如下所示。
(1)视图a 的生成:本文参考王伟对网络流数据的处理方法,将原始流量pcap 切分为多个流,只选取每个流的前784 字节,输入SAE 进行无监督的自动特征提取,编码器输出一组编码后的高级特征作为协同训练的特征视图a。
(2)视图b 的生成:本文选用CICFlowMeter作为流特征提取工具,该工具能够根据提交的pcap文件生成有81 个统计特征的字符分隔值(Comma-Separated Values,CSV)文件。由于实验使用的两个数据集中的CIC-IDS2017 已用CICFlowMeter 提取出了统计特征,本文即不再做相关的处理。对于数据集USTC-TFC2016,用CICFlowMeter 提取出81个统计特征。同时为了降低训练模型对端口信息的依赖,删除目的端口和源端口两个特征,按照随机森林算法特征重要性排序,选择出最优的前40 个统计特征作为视图a。
3.5 相关参数确定
3.5.1 SAE 生成特征视图维数确定
实验从时间效率和准确率两个角度来考虑,对视图a 选取的前784 字节,分别选择10 到100 维的10 种情况进行实验,确定经过SAE 编码后特征数目为多少时,SAE 提取到的特征分类效果最佳,实验结果如图3 所示。
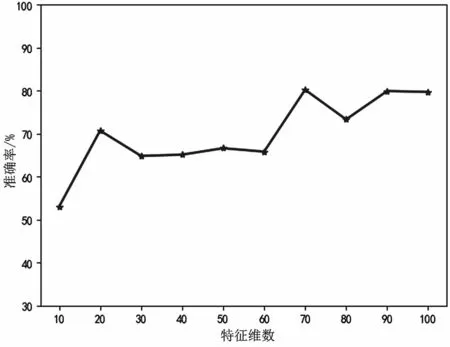
图3 特征视图维数确定
当特征维数为70 时,堆叠自动编码器SAE 模型的准确率最高达到80.2%,此后随着维数的增加,模型准确率趋于平缓。因此,视图a选取特征维数70 来进行实验。
3.5.2 标记样本比例确定
选取2.5%、5%、10%和15%的数据作为标记样本,进行对比实验,剩余的作为未标记样本。
如图4(a)所示,对于数据集CIC-IDS2017,在迭代次数epoch 为20,标记样本数为15%时,模型的准确率最高是99.3%;如图4(b)所示,对于数据集USTC-TFC2016,在迭代次数epoch 为20,标记样本比例为15%时,模型准确率最高到99.06%。因此确定迭代次数为20,标记样本比例为15%,作为后续实验的基础。
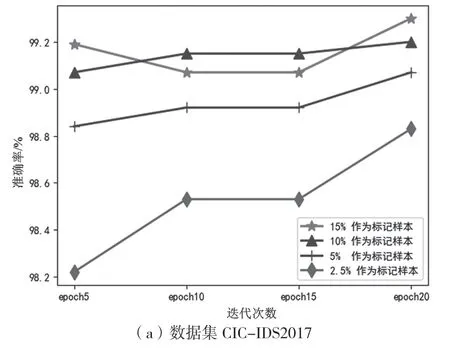
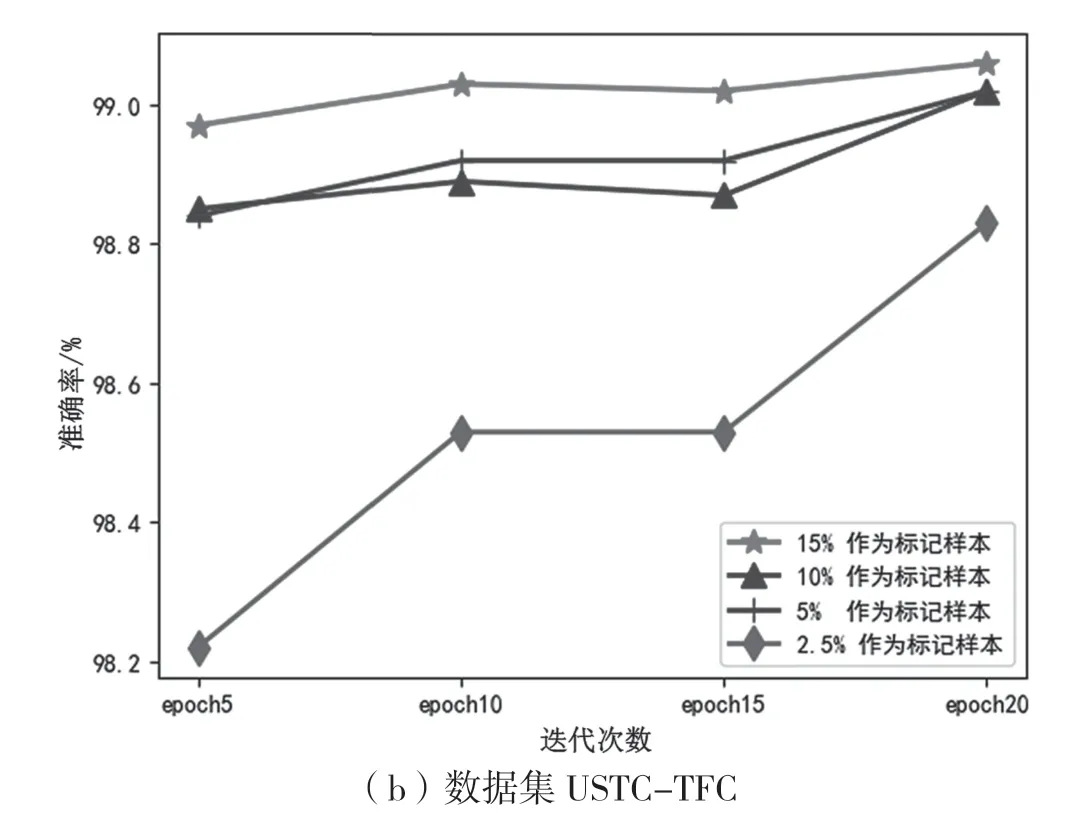
图4 标记样本比例确定
3.5.3 基分类器的选择
协同训练通过两个学习器之间的相互协作,在两个不同的特征视图上分别训练,提高模型的泛化能力和鲁棒性。由于不同模型学习机制的差异,选择不同的基学习器进行协同训练可以获得更全面的数据信息。本文通过对比5 种基分类器选择出最适用于网络流量数据识别的协同训练基分类器,表4 和表5 分别介绍了不同基分类器对于模型的分类准确率对比。

表4 数据集CIC-IDS2017 不同基分类器的分类准确率 %
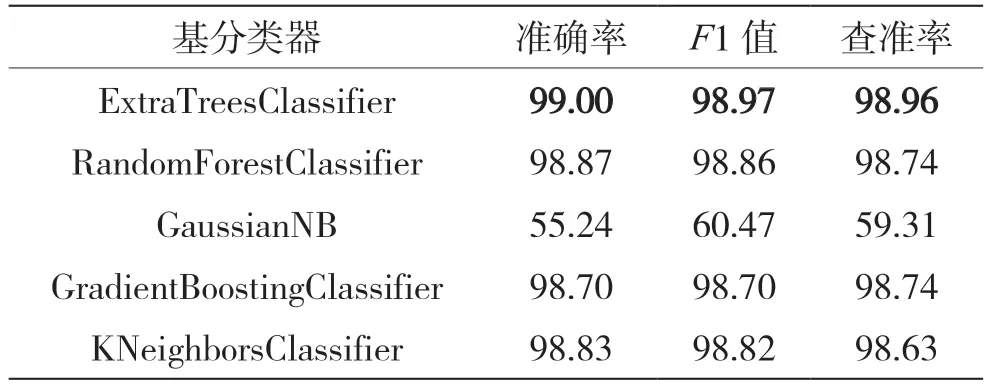
表5 数据集USTC-TFC2016 不同基分类器的分类准确率 %
如表4 和表5 所示,分类器极端随机树(Extra TreesClassifier)的分类效果最好,在准确率、查准率和召回率上都比其他4 种分类器高,因此选择ExtraTreesClassifier 作为协同训练框架的基分类器。
3.6 与其他模型对比结果
本文将提出的半监督协同训练(co-training)方法分别与两种监督学习[7-12]和两种半监督学习[13,14]结果进行对比。监督学习使用卷积神经网络和决策树;半监督学习使用阶梯网络(Ladder Net-work) 和标签传播算法(Lp_SVM 和Lp_Xgboost)。由于协同训练使用了两种网络流量特征,因此,在与其他半监督和监督学习对比时分别用两种视图进行实验,选择实验结果最佳的视图与协同训练对比,其中卷积神经网络使用视图a,决策树使用视图b,阶梯网络和标签传播算法选择视图b。
表6 介绍了在数据集CIC-IDS2017 和数据集USTC-TFC2016 上,协同训练模型与半监督学习模型的对比结果。在CIC-IDS2017 上,协同训练模型的准确率、查准率、召回率、F1 值均高于其他半监督模型,与阶梯网络相比,分别提高了1.44%、0.34%、2.32%和2.03%;与标签传播算法(LP_SVM)相比,分别提高了1.85%、20.72%、3.12%和13.32%;与标签传播算法(LP_Xgboost)相比,分别提高了1.46%、19.12%、2.62%和14.02%。在数据集USTC-TFC2016 上,协同训练模型的准确率、召回率均高于其他半监督模型,与阶梯网络相比,分别提高了0.16%、0.19%;与标签传播算法相比,准确率、查准率、召回率和F1 值分别提高了2.4%、2.15%、2.21%和2.28%;与标签传播算法(LP_Xgboost)相比,分别提高了1.16%、0.9%、1.52%和1.47%。因此,通过上述对实验结果的分析,验证了本文提出的基于半监督协同训练的网络恶意流量识别方法的可行性。
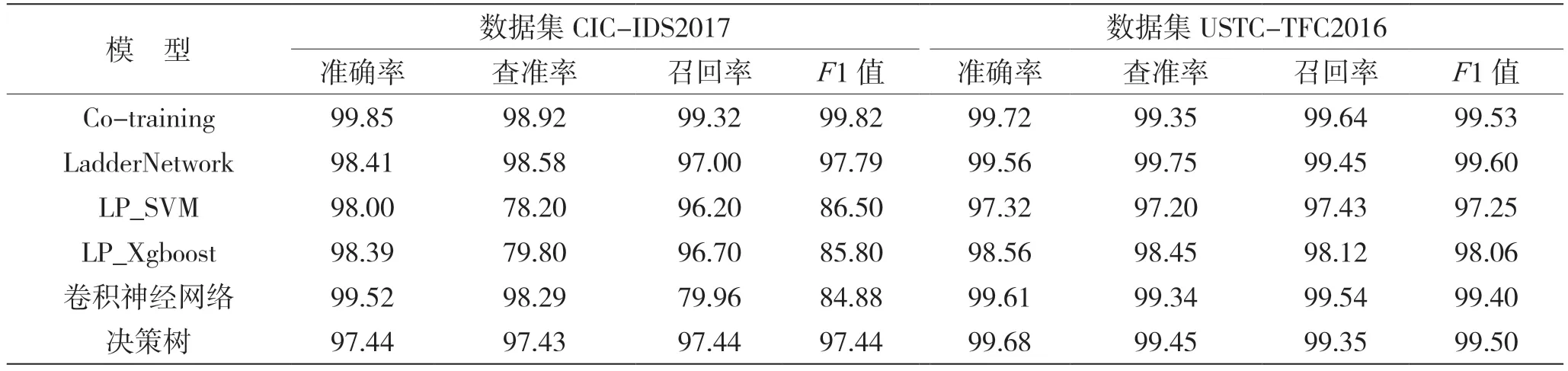
表6 协同训练模型与其他模型对比结果 %
4 结语
本文通过分析当前具有代表性的半监督协同训练算法,结合协同训练的运行是建立在同一数据集中存在两个充分冗余且独立视图的假设下,并考虑实际应用环境中受到很多限制等因素,针对网络流量数据量大且未标记数据易获取等特点,融合字节流特征和统计特征这两种特征表示方式,生成协同训练框架所需的视图a 和视图b,实现了基于半监督的网络恶意流量识别,保证了在少量标记样本和大量未标记样本下,半监督协同训练模型仍具有对恶意流量识别的良好效果。然而,文章还存在一些不足之处,如在协同训练模型中训练两视图的分类器时,可以尝试更多种的组合和更优的分类器。下一步工作将在基分类器的选择上作出更优的调整,以及在网络流量的特征工程上开展更深层次的研究。
猜你喜欢
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
中国交通信息化(2018年5期)2018-08-21 03:37:40
电子测试(2018年1期)2018-04-18 11:52:35
中学生数理化·中考版(2017年6期)2017-11-09 02:46:46
非公有制企业党建(2017年10期)2017-11-03 02:26:27
现代兵器(2017年4期)2017-06-02 15:59:24
现代兵器(2017年4期)2017-06-02 15:58:14
光学精密工程(2016年4期)2016-11-07 09:05:00
