
基于Matlab并行计算工具箱的SAR回波数据仿真方法研究*
2022-05-10 07:28章张
计算机与数字工程 2022年4期
张 章张 磊
(1.宝鸡职业技术学院机电信息学院 宝鸡 721000)(2.陕西烽火通信集团有限公司产品研究所 宝鸡 721000)
1 引言
雷达成像相比于常见的光学成像,具有全天时、全天候、远距离的成像优势,可以大大提高雷达的信息获取能力,特别是战场感知能力。现在国外对战场感知要求高的雷达都配有二维成像功能,因此,SAR已成为国内外研究的热点。随着对成像、InSAR和GMTI等算法问题的深入研究,要大批符合特定条件下的大场景原始回波数据,这些回波数据通过实测录得,数据量太大,不太现实,所以通过计算机仿真来模拟所需要的大场景回波数据是一个重要的方法。
计算机模拟回波数据时,通常需要在一个地面分辨单元内放置多个散射点来模拟整个场景的回波数据,这样就出现以下两个问题。第一,仿真过程中每一个点的回波数据是以慢时间为周期循环产生的,当仿真的散射点过多时,仿真时间过长。第二,每台计算机的内存容量都是有限的,数据量过大会导致计算机内存溢出而无法继续仿真。当仿真大场景回波数据时,以上两个问题就越发突出了,通常的仿真方法在单台PC机上很难完成。目前通常的做法是采用利用集群系统[1],运用BSP(Bulk Synchronous Parallel)计算模型,按照场景分解的方法进行较大场景回波仿真,但该方法基于C语言,使用了MPI并行程序设计[2],而且生成的每个子场景的回波数据需要进一步加和处理才能得到需要的整个大场景回波数据,具体实现复杂,不易操作。
本文提出一种利用Matlab并行化运算工具[3]和场景及数据矩阵划分相结合的仿真方法,该方法能有效地解决上述问题完成大场景回波数据的仿真,且操作简单,成本低。最后的仿真结果验证了本文方法的有效性和正确性。
2 回波数据仿真基本原理
SAR原始回波数据仿真能够并行处理正是由其数据录取方式决定的,下面先了解一下产生数据的基本方法,设雷达发射信号是线性调频脉冲信号[4]:
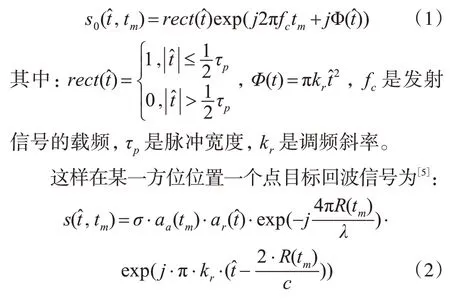
式中,ar(·)为雷达线形调频信号的窗函数,aa(·)方位窗函数。
当场景比较复杂时,可以通过大量的点目标来描述,设条带内点目标的个数为M×N,合成孔径时间为t0≤tm≤tn,所以回波信号模型为

3 基于并行运算的大场景回波数据仿真
基于回波生成原理,可以看出数据录取在慢时间以及散射点上都是相对独立的,所以在仿真大场景回波数据时可以将其分块生成,这样即避免内存溢出,还可以利用并行运算缩短仿真时间。这里本文采用Matlab并行计算模型(Distributed Computing Toolbox&Distributed Computing Engine)来对回波进行并行仿真。Matlab并行计算模型只需若干台PC机联机即可,无须专门仪器设备,编程相对简单。如果需要联机,任务分解时,需要注意计算机与计算机之间数据交互传输量是有上限的。
3.1 任务分解方法
基于信号模型,有两种任务分解方法。
第一,基于场景的任务分解
设将场景按列分解成h块,大小分别为N1,N2,…,Nh,N1+N2+…+Nh=N,则可分别产生h个大小相同的回波数据矩阵,矩阵的回波信号分别为
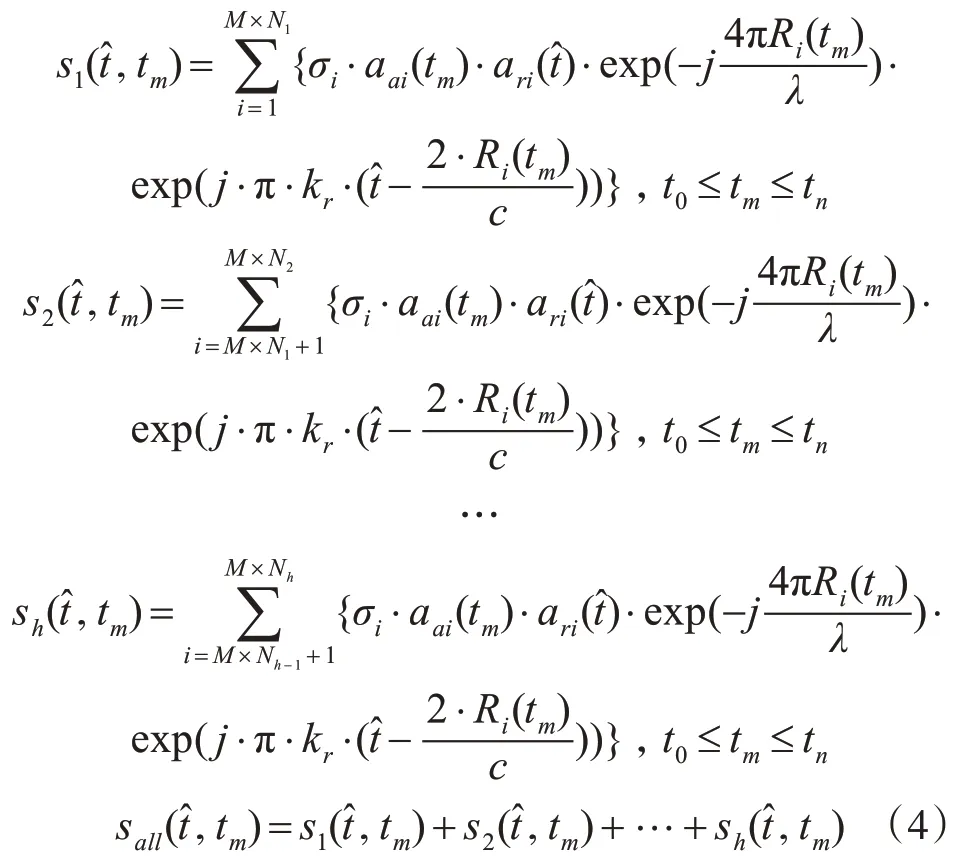
以上,就是整个场景的回波数据。
第二,基于慢时间的任务分解
我们知道,数据矩阵的方位向长度对应于慢时间采样点,所以按慢时间分解任务也就是对数据矩阵做分块处理。设将数据矩阵按列分为n块,也就是将慢时间分为n段,即t0≤t1≤t2≤…≤tn-1≤tn,这样,矩阵内的回波信号为
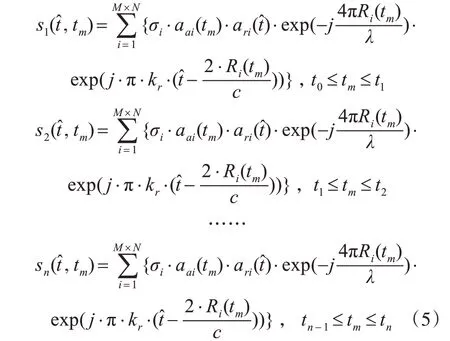
这些矩阵可在并行计算的工作机中单独生成,之后再按顺序拼接起来,便可以得到整个场景的回波数据。
通过上面的分析,我们可以看出,第一种方法将场景分块,不但可使主机向工作机传输的一次数据量降低,防止传输的数据量超过数据交互量的上限,而且还可以避免一次读取整个场景矩阵数据量太大而造成得内存溢出,但这样做,增加了最后一步的求和运算,效率相对较低;为了提高效率,可以采用第二种方法,将回波数据矩阵分块分别在工作机中生成,这样降低了工作机将生成的数据返回主机时的数据量,同时按顺序接收子回波矩阵,可以接收一块,存储一块,从而有效避免了内存不足问题,但这种方法相当于是将整个场景一次传输,如果场景太大超过数据交互上限时,会造成交互失败。在仿真大场景时,其场景非常大,回波数据矩阵也非常大,以上两种方法均不能满足仿真需求,我们可以将两种方法结合起来分解任务,每一个任务仿真如式(6)的回波信号,最后,将所有的任务回收、加和、拼接,得到大场景原始回波数据。
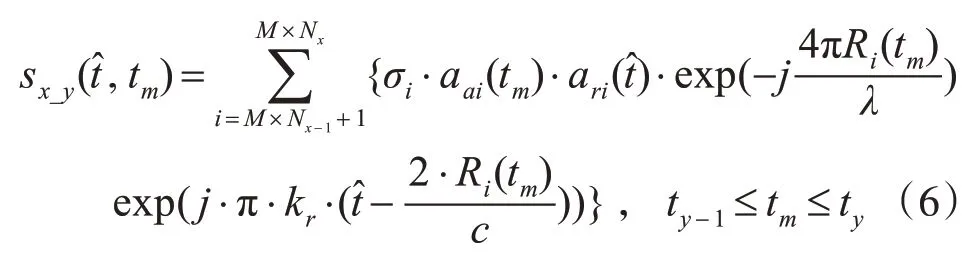
下面我们定量的分析一下这样做的优点,设Nr为距离向采样点数,其中Na为距离向采样点数Namp_r为场景在距离向的点数,Namp_a为场景在方位向上的点数,Dt为一个浮点数占用的字节数,Cf为一个目标点的计算量,所以对一台计算机而言在数据量方面按场景划分为2Dt Na Nr,按慢时间划分为 2Dt Na Nr/Nmatrix,本文的方法为2Dt Na Nr/Nmatrix,在计算量方面按场景划分为Namp_a Namp_r Cf/Namp,按慢时间划分为Namp_a Namp_r Cf,本文的方法为Namp_a Namp_r Cf/Namp,其中,Nmatrix、Namp分别为回波矩阵分块数以及场景分块数。从上面可以看出在数据量,计算量方面,本位的方法都是最优的,可以大幅减少单机的数据量、计算量,从而加快仿真速度,避免内存不足,使大场景仿真成为可能。具体仿真流程如下。
3.2 大场景回波仿真
在仿真真实场景回波数据时,采用已有的实测数据图像作为所产生回波的地面散射点,并在其中加入高程信息,在每个散射点上加入距离向及方位向上的随机偏移量,使其更接近真实地面的散射点分布。如流程图1所示,首先对慢时间分块,在一段慢时间内,再对场景分块,将一段慢时间内一块场景要产生的回波划分为并行工作的一个任务,分配给一个工作机产生回波数据,这里对于整个任务划分有一个排序问题,本文是按慢时间块为大体顺序,场景块为内部顺序排列的,也就是说第一个任务为第一块慢时间的第一个子场景,第二个任务为第一块慢时间的第二个子场景,当所有子场景都遍历一遍后开始对第二段慢时间分配任务。这样做可避免回收数据时主机由于数据量过大而引起的内存溢出。依据上述方法分配任务,回波数据也按此顺序生成,这样主机也即可按顺序先回收第一段慢时间上所有场景的回波数据,将回波数据矩阵加和后(此即为此段慢时间内的仿真数据)保存在硬盘中,并清空内存(clear),再产生下一个慢时间块的数据直至回波数据全部产生保存,这样就生成了大场景的原始回波数据。
从以上流程可以看出,任务划分解决了仿真大场景时PC机内存不足的问题,并行计算解决了大场景回波仿真时间过长的问题,从而使大场景SAR原始回波数据仿真成为可能。
4 仿真结果及分析
实验系统采用7台普通计算机,一台作为主机,收发保存数据,6台作为工作机,并行计算回波数据,配置为Pentium(R)4 CPU 3.0GHz,1GB内存,计算机之间通过百兆以太网连接,场景大小为800×5000个点目标,雷达脉冲重复频率为2000Hz。
场景分块个数为Namp=(Namp_r×Namp_a)/Ntra_max,Ntra_max为主机与工作机之间的传输上限。回波矩阵分块个数为Nmatrix=(Nr×Na×Nantenna)/Ntra_max,Nantenna为一发多收时接收天线的个数。通过计算可知实验系统Namp=12,Nmatrix=9。
图2是用上述方法得到的大场景SAR回波数据仿真结果,每一块子矩阵为整个场景在这一段慢时间内产生的回波数据,通过这9块数据可以大体看出这块场景的回波形状。图3为不同工作计算机数目下产生回波所用时间的曲线,在任务划分方式不变(即Namp=12,Nmatrix=9)的情况下,一台计算机用时220.4h,三台计算机用时75.6h,六台计算机用时38.9h,基本符合Tn=T1/n这一原则,这里Tn为n台计算机所用时间。而对于内存使用,取决于场景与回波矩阵的分块数量,数量越多内存占用率越少,但这里注意如果分块数量太多会使计算机之间的数据传输花费很长的时间,严重影响数据产生的效率,所以在保证内存不溢出的情况下合理的分配任务,才能实现较高的数据,产生效率。
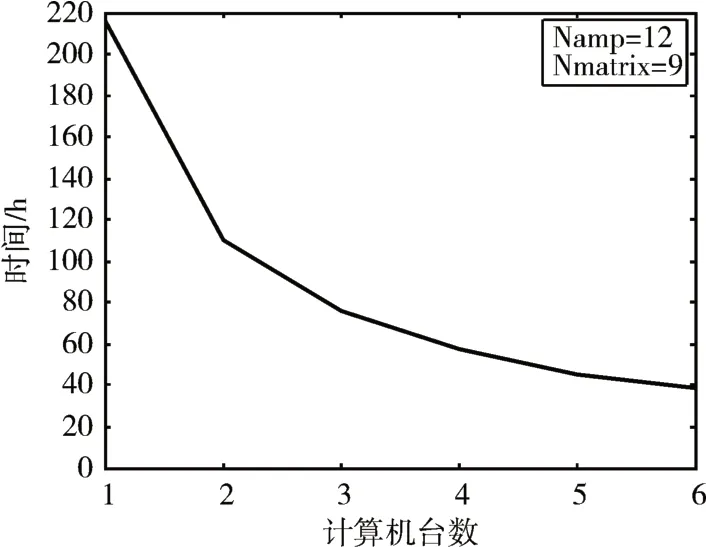
图3 工作计算机台数与仿真时间关系

图4 仿真回波数据成像结果
通过仿真可知,利用场景划分和并行化运算相结合的方法产生大场景SAR原始回波数据,可以充分解决由于PC机内存不足引起的无法仿真问题以及仿真时间过长问题。
5 结语
本文基于场景划分和并行化运算寻找到一种在普通计算机上进行大场景SAR原始回波数据仿真的方法,仿真实验证明本方法可大大缩短仿真时间,降低内存使用量,且成本低实现简单,易操作,是可行的、高效的。
猜你喜欢
电脑爱好者(2020年19期)2020-10-20
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
软件导刊(2018年3期)2018-03-26
读与写·教育教学版(2017年10期)2017-11-10
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
电脑爱好者(2015年21期)2015-09-10
南都周刊(2015年1期)2015-09-10
科技与创新(2014年11期)2014-08-21
