
基于对抗不变性解散的说话人识别*
2022-05-10 07:28黄多林郑智燊
计算机与数字工程 2022年4期
黄多林 刘 栋 郑智燊
(江苏大学计算机科学与通信工程学院 镇江 212013)
1 引言
近几年,众多研究表明深度学习在说话人识别领域的特征学习中取得了巨大的成功,许多研究人员开发出利用深度神经网络结构来生成说话人特定表征形式[1~2]的模型。深度学习模型是进行复杂数据分析的一种强大工具,这些模型对于文本相关[3]和文本无关[4~5]的说话人识别任务表现出优异的识别性能,逐渐成为语音领域的主流框架。
本文探索一种在说话人特征中引入鲁棒性的方法,以应对复杂的声学环境。采用最近在视觉领域中提出的无监督对抗不变性(UAI)框架[6]作为基准模型进行改进,提出基于对抗不变性解散的说话人识别方法(Speaker Recognition Based on Adversarial Invariance Disentangled,SR-AID)。该方法将i-vector[7]映射到两个低维的嵌入空间中解散出两个潜在特征,第一个潜在特征通过注意力机制和解散模块的训练,只包含说话人相关的可区分性信息,而所有其他说话人无关信息则被提取到第二个潜在特征中。实验结果证明,注意力机制和解散模块能够提高说话人识别准确率,即帮助第一个潜在特征学习到说话人相关信息。
SR-AID与文献[6,8]中提出的无监督对抗不变性技术的改进之处在于本文的方法利用注意力机制分离出第一个潜在特征的干扰因素,通过解散模块重构出第二个潜在特征,使干扰因素流入到第二个潜在特征以学习到说话人无关信息用于重构i-vector,从而使第一个潜在特征只包含与说话人识别相关的信息来提高说话人识别性能。
2 对抗不变性解散网络

2.1 i-vector特征提取
i-vector特征显示出对说话人识别任务较好的鲁棒性,并且与PLDA[9]一起实现了最先进的性能。因此,本文使用i-vector作为模型的输入特征。在实验中,语音信号以16kHz的采样率采样,并以25ms的汉明窗(以10ms的偏移)进行分帧。采用隐马尔可夫模型工具包(HTK)[10]提取MFCCs声学特征,然后采用MSR工具箱[11]构建GMM-UBM系统来提取i-vector。
2.2 无关信息特征选择
编码器将所有预提取好的i-vector映射到两个低维嵌入空间,得到A1和A2潜在特征用于不同的任务,即A1只包含与说话人相关的信息,而所有其他的干扰因素被A2捕获。本文使用注意力机制从A1中选择出说话人无关信息A'1,再与A2拼接后重构输入i-vector,计算方式如式(1)所示:
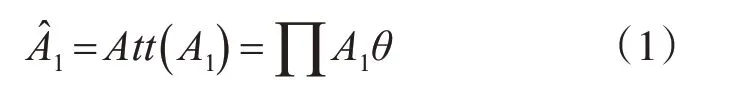
其中θ表示注意力层的输出权重向量,通过将潜在特征A1与注意力权重θ相乘来选择所有其他说话人无关信息。权重向量θ可以通过式(2~3)计算:

其中f(·)表示多层感知机,ω代表中间变量。
2.3 对抗不变性说话人识别
本文采用对抗不变性解散技术的目的是进一步消除i-vector中干扰信息的影响,数据集中所有说话人的语音信号都已经被预提取为i-vector特征向量,一条语音被提取为一个i-vector向量。
SR-AID的对抗思想主要体现在包含编码器、解码器以及分类器的主模型与包含两个解散模块的对抗模型之间形成了极小极大游戏。主模型的目标是最大化潜在特征A1对说话人预测的分类能力,并使用A2对其进行重构,而对抗模型则最小化A1和A2的分类能力,因此,这种对抗训练使两个潜在特征解散开来,该方法的总目标函数如式(4)所示:

式(4)中解码器和分类器之间形成一种竞争关系,分类器希望提取与说话人y相关的信息到A1中,而解码器尝试将所有关于i-vector(X)的信息提取到A2中,通过注意力层从A1中提取说话人无关信息和A2拼接在一起重构X。这种竞争关系使X的信息分别流入到A1和A2中,A1倾向于包含更多与说话人y相关的信息,而A2倾向于包含更多与识别任务无关的信息。但是,这种竞争并不能够保证A1和A2之间形成完全互补关系,A2中可能包含说话人相关信息,更严重的是A1中可能包含无关信息的干扰因素,进而影响模型识别性能。因此,式(4)中的Ldis1和Ldis2两个解散模块尝试对潜在特征A1和A2进行“清理”。其中,编码器、解码器、分类器和两个解散模块的参数分别用ϵe、ϵd、ϵp、ϵd1和ϵd2表示,本算法通过反向传播的方式进行端到端训练,采用式(5)中的极大极小策略优化。
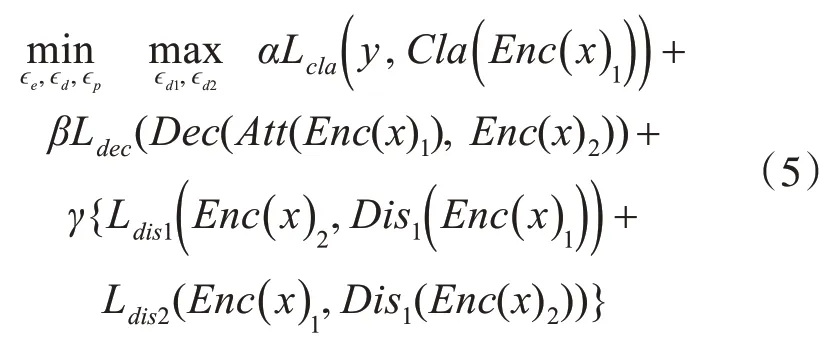
SR-AID使用交叉熵损失函数优化分类器,而解码器和两个解散模块使用均方误差损失函数。在多分类任务中,交叉熵损失可以衡量真实说话人标签y与模型预测标签y^的相似性,通过反向传播算法,最小化二者的误差来更新网络,对于一个训练样本的交叉熵计算方式如式(7),首先通过式(6)的分类器计算出样本的预测标签y^,再和真实标签一起计算损失。
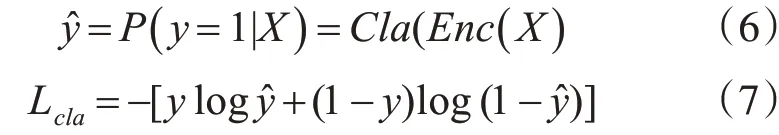
在重构任务中,均方误差常被用来评价重构的数据序列与真实值的偏离程度,解码器和两个解散模块的损失计算如式(8)。
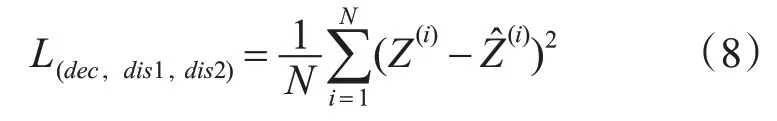
其中Z表示真实数据,例如代表解码器中的i-vector或解散1中的A2以及解散2中的A1。Z^分别表示不同模块重构出的数据序列,N表示数据的维数。
在实验中,编码器、解码器分别包含3个隐藏层,每层的节点数为256、512和256,分类器包含一个节点数为512的隐藏层,而两个解散模块分别包含1个节点数为256的隐藏层,潜在特征A1和A2的尺寸分别为256和128。基于文献[6]中的分析,在α远大于β的情况下,通过递增β的值来观察分类器的性能选择β。最后,将分类器的损失权重值α设置为100,编码器的损失权重值β设置为4,以及解散模块的损失权重γ设置为2时,模型的性能最好。对模型进行了2500次迭代训练,批量样本大小为128。将编码器、解码器和分类器看作是主模型,将解散模块1和解散模块2看作是对抗模型。在每个迭代期间,每进行一次批量的主模型更新时,使用5次批量的对抗模型更新训练。使用Adam优化器优化主模型和对抗模型,学习率分别设置为1e-2和1e-3,并且两者的权重衰减因子均为1e-4。对抗不变性解散训练的步骤如下。

3 实验
3.1 实验环境
本文所有实验的环境都是基于Ubuntu16.04LST操作系统,GPU为NVIDIA TIITAN X,编程语言为Python3.5,深度学习开发框架为PyTorch。
3.2 实验数据
实验采用TIMIT[12]数据集来评估本文方法的性能。该数据集是由麻省理工学院(MIT),SRI International(SRI)和Texas Instruments,Inc.共同设计,在TI(Texas Instruments)录制,并由美国麻省理工学院(MIT)转录,国家标准与技术研究所(NIST)对CD-ROM的生产进行了验证和准备。TIMIT包含美国8个主要方言地区的630位演讲者的宽带录音,每位演讲者被要求朗读10个语音丰富的句子。数据集包含时间对齐的字形,丰富的语音内容和单词转录,以及每个发音为16kHz语音.wav格式的波形文件,该数据集常用于说话人识别和语音识别模型好坏评判的基准数据集。
3.3 TIMIT数据集上不同方法准确率对比
为评估SR-AID的识别性能,在两类数据划分设置下与其他几种公认的说话人识别方法进行比较:GMM-UBM[13~14]、i-vector/PLDA[14]、EML[15]和VAE[14]。两类不同的数据划分统计如表1和表2所示,而ELM[15]和VAE[14]方法分别是这两类数据划分下目前准确率最高的方法,GMM-UBM和i-vector/PLDA是TIMIT数据集上的基准方法。
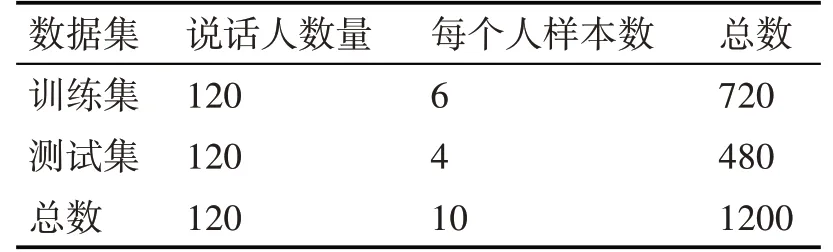
表1 TIMIT上120个说话人样本的训练集和测试集的实验设置
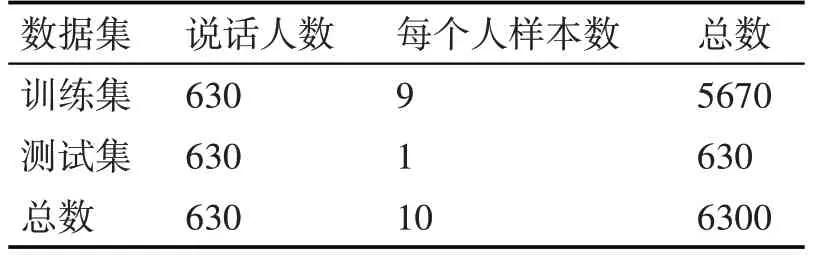
表2 TIMIT上630个说话人样本的训练集和测试集的实验设置
表3展示了TIMIT数据集上说话人数量为120时不同方法的识别准确率。在相同GMM混合物数量(256)和i-vector维度(100)的条件下,SR-AID比基准方法的准确率提高了4.41%,比最好的方法ELM高2.74%。

表3 TIMIT上120个说话人的准确率对比
为了评估SR-AID对比VAE的性能,采用所有说话人(630位说话人)的语音数据训练,实验设置如表2。从表4的实验结果观察可知,SR-AID的识别准确率比基准方法GMM-UBM和i-vector/PLDA分别提高了8.58%和8.42%,比最好的方法VAE提高了2.86%。
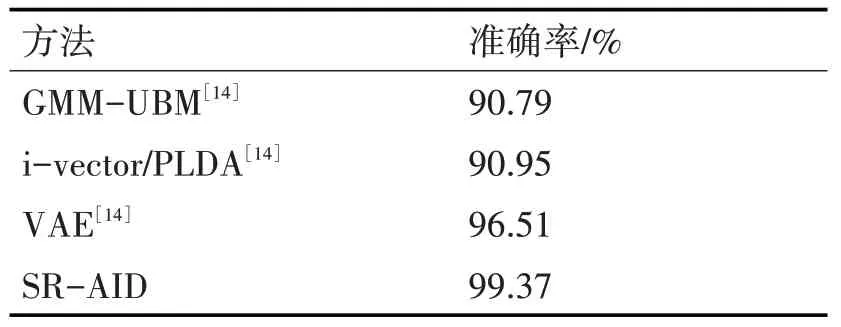
表4 TIMIT上630个说话人的准确率对比
表4和表5的结果清楚地表明本文方法在TIMTI数据集上,相对于最好的说话人识别方法,准确率有明显地提升。
3.4 解散层与注意力机制对模型的影响
本小节在测试集损失和测试集准确率两个方面上,分析解散层、注意力机制和编码器分别对SR-AID的影响。在损失对比实验中,本文只在630人的数据设置下进行实验。准确率的对比实验是在120人和630人两种数据设置下实现。
3.4.1 测试集损失的对比实验
图2直观地展示了移除注意力机制的方法与SR-AID对测试集损失的影响。有注意力机制和无注意力机制两种情况下,有注意力机制时损失值下降更低。并且随着迭代次数增加,无注意力机制的损失值出现往上轻微波动,而有注意力机制的本文方法表现稳定,甚至有继续下降的趋势。
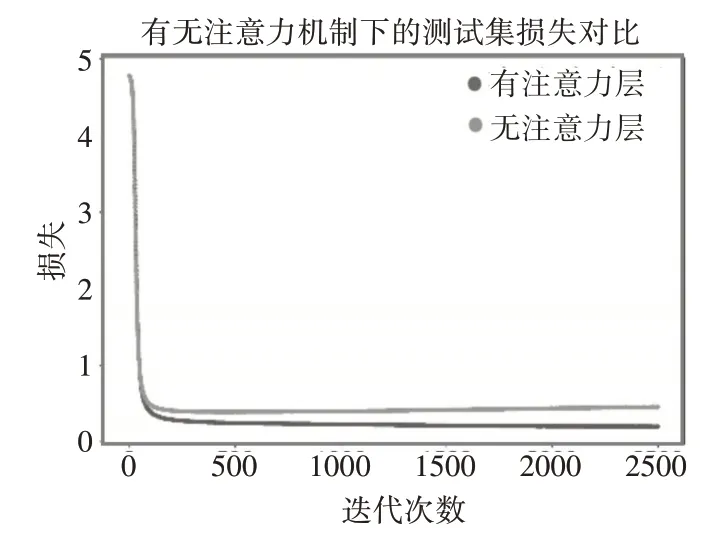
图2 注意力机制对测试集损失的影响
同样从图3中观察可知,有解散层的SR-AID比无解散层的损失值更低。不断训练的过程中,有解散层的SR-AID使损失值继续下降,与无解散层的损失值拉开距离。
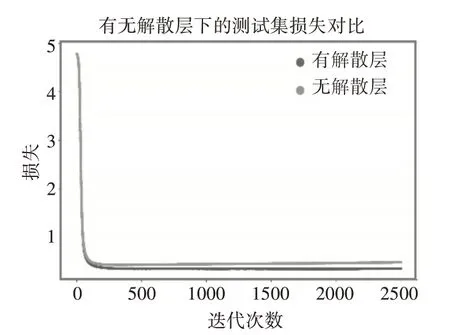
图3 解散模块对测试集损失的影响
从图4可知,无编码器的SR-AID损失在训练初期下降较快,这是由于编码器相对于注意力层和解散模块,拥有更多的参数需要训练,因此无编码器的SR-AID对比上述两种情况下的SR-AID,模型参数量更少,所以图1和图2中的训练前期,有无注意力机制和有无解散层的对比损失的下降速率十分接近。但是随着迭代次数的不断增加,无编码器的SR-AID损失几乎没有变化,而有解码器的SR-AID下降明显。

图1 基于对抗不变性解散的说话人识别方法
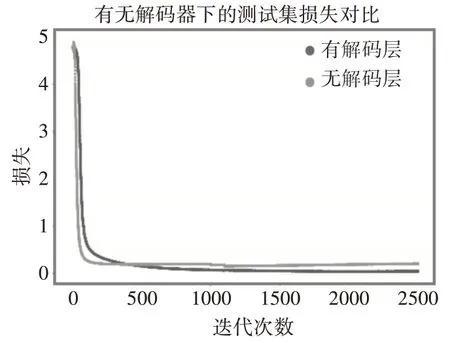
图4 解码器对测试集损失的影响
3.4.2 测试集上的识别准确率对比实验
为了验证SR-AID的注意力机制是否能够有助于提高说话人识别准确率,做了如下对比实验,用Dropout代替注意力层选择潜在特征A1中说话人无关信息到解码器中,结果如表5所示。
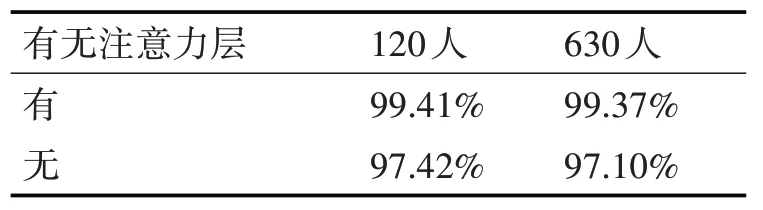
表5 有无注意力层的说话人识别准确率对比
从表5可知,在120人和630人数据划分下,有注意力层的准确率比无注意力层的准确率分别提高了1.99%和2.27%。结果验证了本文方法的注意力层能够帮助潜在特征A1捕获更多说话人相关信息以及分离其他干扰因素来提高模型识别性能。
从图3可知,在模型训练时,有解散层使测试集的损失更低,但是否能够提高说话人识别准确率,却有待验证。因此,表6展示了有解散层与无解散层两种情况下的准确率对比结果。
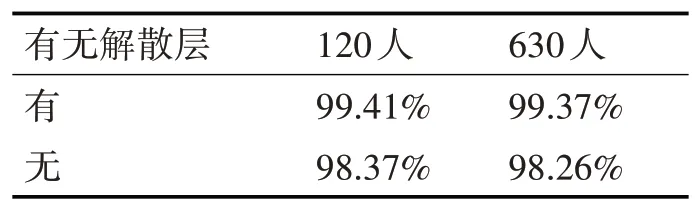
表6 有无解散层的说话人识别准确率对比
表6显示,在120人和630人数据划分下,有解散层的本文方法的准确率比无解散层的准确率分别提高了1.04%和1.11%。结果验证了本文方法中的解散层确实解散出说话人相关特征,提高说话人识别任务的准确率。通过对比图2和图3以及表5和表6可知,注意力机制比解散层对SR-AID的作用更大。
为了验证编码器是否对SR-AID起到积极作用,表7展示了在120人情况下,有编码器的SR-AID比无编码器时提高0.78%,在630人情况下提高0.81%,实验结果表明解码器对本文方法的有效性。

表7 有无解码器的说话人识别准确率对比
5 结语
本文提出一种对抗不变性解散的说话人识别方法,通过对抗不变性解散训练和注意力机制,从语音信号包含的所有其他干扰因素中学习到说话人相关信息,得到说话人鲁棒性特征,并将这些说话人特征用于说话人识别任务。在TIMIT数据集上的实验结果验证了本文方法的有效性,在两类数据设置下均取得了最高的识别准确率,并且通过实验分析了注意力机制、解散层和编码器对本文方法的影响。在未来的工作中,我们将关注于使用低维的声学特征通过该方法获得说话人嵌入特征,进一步提高在其他复杂场景下的说话人识别鲁棒性。
猜你喜欢
计算机时代(2022年9期)2022-11-03
农业工程学报(2022年12期)2022-09-09
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
现代信息科技(2019年18期)2019-09-10
科技创新与应用(2017年26期)2017-09-12
软件导刊(2017年4期)2017-06-20
科技与创新(2017年5期)2017-03-28
中国信息技术教育(2016年13期)2016-09-10
电脑爱好者(2015年24期)2015-09-10
