
基于稀疏预处理和XGBoost的生化检验智能审核*
2022-05-10 07:27何涛陈剑
计算机与数字工程 2022年4期
何 涛 陈 剑
(1.东北大学东软研究院 沈阳 110169)(2.辽宁省工业控制安全工程技术研究中心 沈阳 110169)
1 引言
国务院印发的《新一代人工智能发展规划》文件针对医疗领域,提出了“推广应用人工智能治疗新模式新手段,建立快速精准的智能医疗体系”的目标,任务就是推广人工智能在诊疗过程应用新模式新手段,建立精准的智能医疗体系[1]。
临床检验数据为临床医学提供了一系列检测项目的结果,为医生进行疾病诊断提供最有力的数据支撑,医生会根据患者的每一项检测指标的具体情况,判断患者在该指标上具有哪些风险。临床决策所需信息70%来自检验,包括样本的检测和结果的解读[2]。
临床检验是将患者的血液、体液、分泌物、排泄物和脱落物等标本,通过化学、仪器或分子生物学方法进行检测的方法[3]。然而,并不是每一次的检验结果都是可信的,这其中可能有检验仪器的原因、试剂的原因、采集过程的原因、运输存放的原因等。因此,检验科医生有一项重要的工作就是对检验数据进行审核,筛选出有一定程度偏离的数据,将该部分样本进行一次复查[4~5]。对于这些数据,医生需要花大量的时间进行人为的审核,而且不同的医生对于异常值的判断方式是相对主观的,不同医生的判断也会出现不一致的情况。另外,各个医生的判断方式也很难通过确定的规则来描述。在理想的状况下,异常值的检测应该融合多项相关因素得出综合的判断结果,而且判断结果应该具有一致性和统一性,在这种前提下使用机器学习算法来取代人工就成了大势所趋。因此,如何使用机器学习算法智能地从医生判断的历史记录中探索和发现统一的规则具有很重要的理论意义和现实意义[6~7]。
机器学习算法广泛用于智能审核领域,典型应用包括决策树、支持向量机、人工神经网络、贝叶斯网络等[8]。陆怡德等[9]提出构建临床化学审核规则的方法,以及规则在计算机自动审核的应用。马丽等[10]提出一种使用中间件实现生化检验报告高效审核的方法。郑卫东[11]论述了随着临床实验室信息化进展,计算机自动审核在提高检验报告核发过程中可以极大提高效率。蒋文海等[12]搭建起由LIS、中间体软件、检测仪器和数据审核人员四大部分组成的自动审核系统。何訸等[13]探讨大量历史数据在生化项目自动审核规则测试和自动审核系统验证中的应用。温冬梅等[14]制定自动审核规则,以自动化流水线中间体软件为核心,搭建生化免疫检验结果自动审核系统。极端梯度提升(extreme gradient boost,XGBoost)是由Chen等[15]提出来的一种GBDT的高效实现,因其模型的计算复杂度低、运行速度快、准确度高等特点,XGBoost成为应用比较广泛的集成学习模型之一。
虽然在临床生化检验数据审核方面已有比较多的研究,然而大部分传统方法都是基于设置固定的过滤规则,需要医疗领域的专家根据专业知识,通过不断的调试来选择各个检验项的阈值,这种方法忽略了检验项之间的相关性,不具备学习能力,更缺乏可扩展性。因此,本文提出一种通过XGBoost自动学习和调整判定参数的方法,实验结果表明,该模型具有较高的训练效率和审核准确率,可以替代绝大部分人工审核工作。
2 数据预处理
本文所用数据是从医院HIS和LIS系统中提取出来的,时间跨度为2018年1月份~2019年10月份的检验数据。检验数据包含年龄、性别、看诊科室等离散化因素,以及与纳入检测项目的各种检验指标值,每个指标一般同时包含检测值、参考范围值及历史检验值等多种连续化因素。生化检验包含20多个项目,不失一般性,本文以钾离子检验项目为例。数据预处理流程如图1所示。

图1 数据预处理流程
2.1 特征选择
钾离子是维持细胞生理活动的主要阳离子,钾元素的测定在医疗检验领域具有重要的意义。首先根据检验科专家提出的与钾离子审核相关的其他检测项,使用机器学习算法计算各检测项与钾离子复查相关的皮尔逊系数,遴选出相关项目有钾元素检测值、钠元素检测值、氯元素检测值、肌酐检测值、尿素检测值等项目,并自动生成钾钠氯的历史检测值,并计算钾离子的DeltaCheck值,其公式为
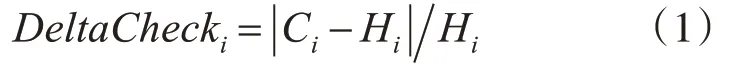
其中Ci表示第i条记录的当前检验值,Hi表示第i条记录的历史检验值,如果当前值与历史值的时间间隔大于7天,或者不存在历史值,则将Delta Ch ecki置为0,DeltaCheck值表示两次检测之间的波动性,波动越大越不正常。
2.2 聚类采样
2018年1月份~2019年10月份的检验数据共包含571032条钾离子检测记录,其中需要复查的异常数据7393条,占样本总数的1.3%。两类样本的分布极不平衡,故采用下采样方法从正常样本中选择与异常数据相当数量的样本。使用全部异常数据7393条,并使用K-Means聚类算法从正常样本中取样。其步骤如下:
1)首先,确定要聚类的数量为8000,并随机初始化它们各自的中心点;
2)通过计算当前点与每个组中心之间的距离,对每个数据点进行分类,然后归到与距离最近的中心的组中;
3)基于迭代后的结果,计算每一类内,所有点的平均值,作为新簇中心;
4)迭代重复第2)和第3)步骤,直到组中心在迭代之间变化不大。
分类完成以后从每个聚类中随机选取两个样本,用于模型的训练和测试。相比于随机采样,聚类采样的优点是由于进行了预分类,使得抽取的样本更具有代表性,可以覆盖大部分正常样本的特征。
2.3 缺失值填充
目前针对缺失值填充可供选用的方法包括:默认值、均值、中位数、众数、KNN、随机森林等,本文提出一种基于深度神经网络(Deep Neural Network,DNN)的填充方法。针对某一包含缺失值的列,以该列的值作为目标值,以其他列作为特征值,深度神经网络的结构如表1所示。
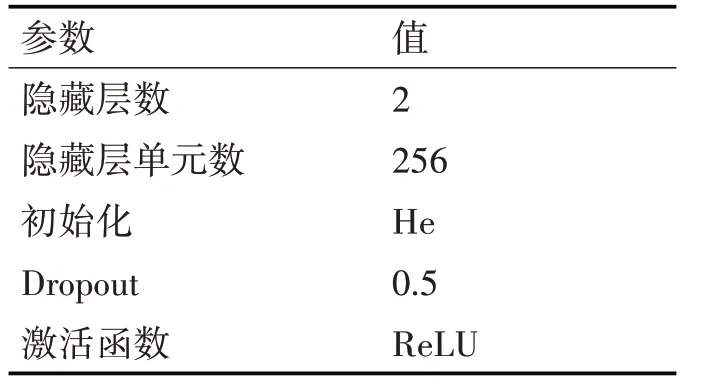
表1 深度神经网络参数
因为需要预测连续值,在隐藏层之后,使用均方误差(MSE)作为损失函数,其公式为
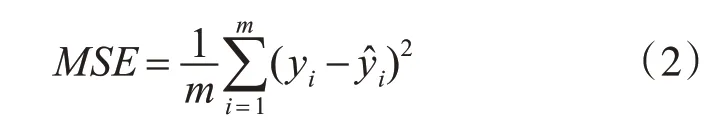
在填充正常值时,使用正常值样本训练DNN模型,在填充异常值时,使用异常值样本训练模型,通过迭代补全所有的缺失值。
2.4 数据稀疏化处理
对于每一个检测项,其数据包含检验值d、参考范围上限Ud、参考范围下限Ld、DeltaCheck值,为了将这些数据转化为稀疏矩阵,需要做如下处理。

2)项获取第i项检验信息的DeltaCheck,并计算:

其中ε是依据生物学要求制定的检查界限,此处设置为0.058。经过这种处理之后,可以将参数矩阵中的大部分数据转化为0。
3 构建XGBoost模型
XGBoost是基于Boosting梯度提升的一种集成学习方法,通过循环训练预测器,使用后一个模型对前一个模型产生的误差进行校正。XGBoost使用决策树作为基础预测器,通过不断拟合残差优化目标函数,从而达到准确的预测分类效果。XGBoost一个重要的特点是对稀疏数据处理更为高效。
对于一个给定的有n个样本和m个特征的数据集D=(xi,yi)(|D|=n,xi∈Rm,yi∈R),使用K个累加的函数来预测输出:

其中q代表每棵树的结构,其可以将每个样本映射到对应的叶节点中,T是树中叶子节点的个数,fk对应于一个独立的树结构q和叶子权重w。为了训练模型中的函数集合,使用的损失函数定义为

其中Ω是正则化项,T和w分别为CART树叶子节点数目和叶子权重值,γ为叶子树惩罚系数,λ为叶子权重惩罚系数,通过使用正则化项能够避免过拟合。
根据梯度提升算法的特点,第t轮的模型预测等于前t-1轮的模型预测加上ft,公式为
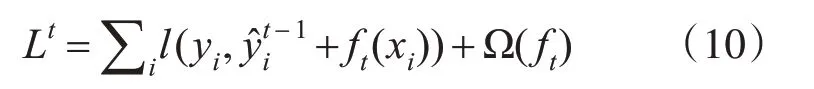
对损失函数进行二阶泰勒展开,移除常数项,简化后得到:
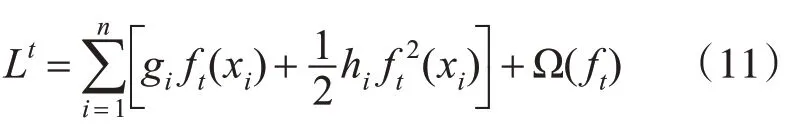
其中gi是一阶导数,hi是二阶导数。
每个样本都会落入一个叶子结点中,将同一个叶子结点样本进行重组,可以把目标函数改写成关于叶子结点分数的一个一元二次函数,可以直接使用顶点公式求解最优W值。

并且计算对应的损失函数最优值。
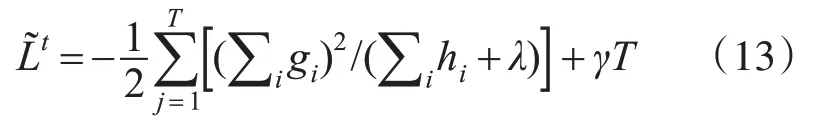
XGBoost则对代价函数进行了二阶泰勒展开,同时用到了一阶与二阶导数,是它在代价函数中加入了正则化项,用于控制模型的复杂度,学习出来的模型更加简单,防止过拟合。
4 实验结果分析
本文实验的硬件环境是Dell R740服务器,挂载两块NVIDIA Tesla P40的GPU卡;深度学习框架使用TensorFlow 1.12.0版本。
4.1 评价指标
在机器学习中评估模型的性能通常使用精度P、召回率R、F1分数三个指标,计算公式分别为
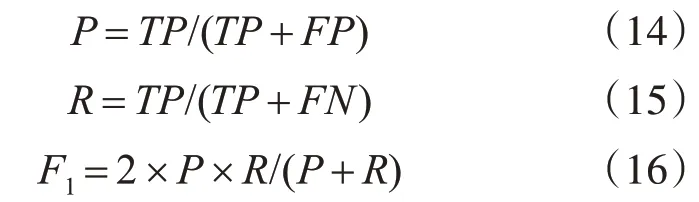
其中TP表示真正类的数量,FP表示假正类的数量,FN表示假负类的数量。由公式可知,P表示正确识别的实体数量与识别出的实体总数的比率,R表示正确识别的实体数量与该实体的总数的比率,F1分数是精度和召回率的谐波平均值,只有当召回率和精度都很高时,才能获得较高的F1分数。
4.2 采样有效性比较
为了验证聚类采样的有效性,本实验与另外两种常用的采样方法进行性能上的比较。随机欠采样是指在正常样本中随机的抽取与异常样本相当数量的样本数。SMOTE算法是对少数类别样本进行分析和模拟,使用KNN算法合成新的少数类样本,并将人工模拟的新样本添加到数据集中,在三类样本上的性能表现如表2所示。
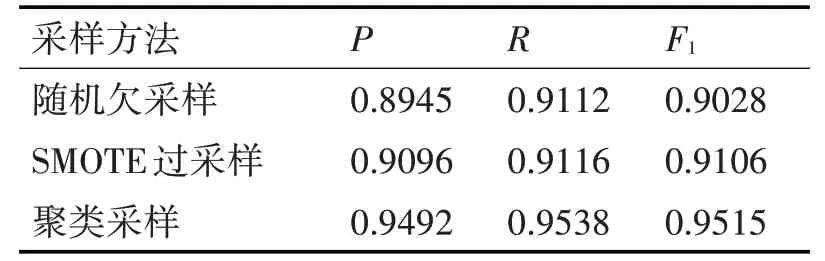
表2 不同采样方法的性能比较
4.3 缺失值有效性比较
缺失值处理的方法主要有:1)默认值法,将所有的缺失值简单地设置为一个默认值,通常为0;2)中位数法,某个属性的所有值进行排序,用中位数填充缺失值;3)众位数法,统计某个属性的分布,使用分布最密的值填充缺失值;4)均值法,用某个属性所有值的均值填充缺失值;5)随机森林法,使用随机森林算法填充缺失值。各种缺失值填充的性能比较如表3所示。
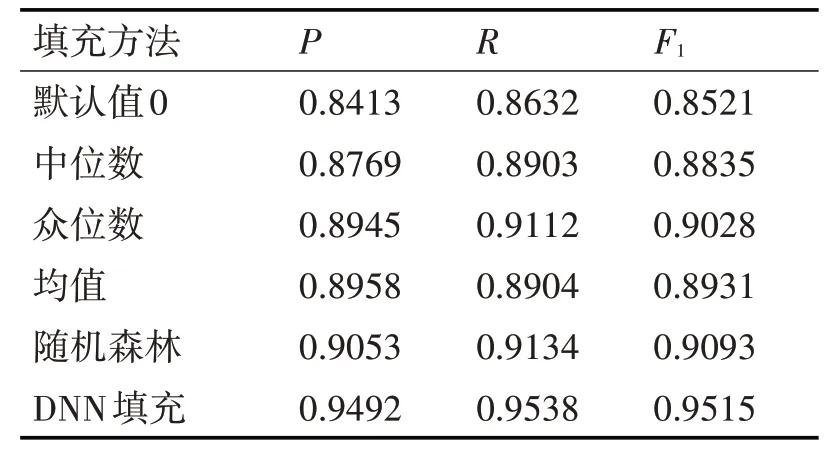
表3 不同缺失值填充的性能比较
4.4 模型性能比较
为了证明本文提出的模型在性能方面的优越性,在相同数据集上,与支持向量机、朴素贝叶斯、决策树、随机森林等模型进行比较。支持向量机与朴素贝叶斯需对数据进行归一化,各个模型在测试集上的表现如表4所示。
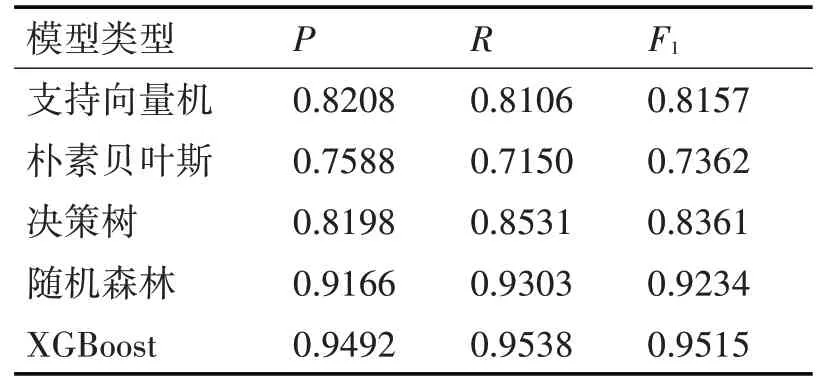
表4 不同模型的性能比较
从实验结果可以看出,XGBoost在测试集上的F1分数达到了0.95以上,比随机森林提高了3%,从另一个角度来看,XGBoost模型训练需要的时间只有随机森林的一半,与其他机器学习算法相比,XGBoost在生化检验智能审核领域的训练效率和预测性能有了显著的提升。
5 结语
为解决目前生化检验数据智能审核存在的劳动强度大、效率低下的问题,本文提出一套完整的数据预处理流程,包括特征选择、聚类采样、缺失值填充、数据稀疏化的详细方法,并将XGBoost算法应用在预处理数据上,训练机器学习模型完成数据的智能审核。实验表明,该方法达到较高的性能,优于目前使用的方法,并得到医院方面的高度认可。
下一步的任务是如何将该模型应用到医院的业务系统中,辅助检验科医生高效完成检验数据的审核工作。
猜你喜欢
中原商报·科教研究(2022年1期)2022-05-13
汽车实用技术(2022年4期)2022-03-07
中国新闻周刊(2021年24期)2021-07-19
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
中学生数理化·高一版(2017年2期)2017-04-25
数学学习与研究(2017年3期)2017-03-09
电子技术与软件工程(2016年23期)2017-03-06
试题与研究·中考化学(2016年1期)2016-09-30
小天使·二年级语数英综合(2015年2期)2015-01-14
计算技术与自动化(2014年1期)2014-12-12
