
改进YOLO v3算法的航拍小汽车检测*
2022-05-10 07:27王茂琦马佶辰徐康民
计算机与数字工程 2022年4期
王茂琦 李 军 马佶辰 徐康民
(南京理工大学自动化学院 南京 210094)
1 引言
随着传感器、半导体等技术的进步,使用无人机航拍视频检测道路中的车辆正在成为许多学者研究的热点。无人机无论是在民用生活还是在军事方面都有着重要的作用,使用航拍视频对道路中的车辆进行检测,不仅可以对道路的车流量进行统计,而且还可以对检测出的车辆进一步追踪分析,检测车辆有无违反交通情况等[1]。
传统的目标检测是基于人工设计特征和浅层分类器,它不仅在检测精度方面有着很大的提升空间,而且鲁棒性也不尽人意[2]。直到2012年,Hilton课题组使用AlexNet深度卷积网络在ImageNet大赛上不仅取得了第一名的成绩,而且在分类效果上要远超过第二名[3],才使得许多学者开始对深度学习展开了更深一步的研究。近些年来,在目标检测领域出现了许多优秀的深度学习算法。像2014年Ren等 提 出 的R-CNN[4]算 法,它 使 用selective search算法结合卷积操作替代了传统的图像特征提取算法,将平均目标检测精度提升了30%。之后Girshick和Ren等又在R-CNN的基础上进行改善,提出了Fast R-CNN[5]和Faster R-CNN[6]算法,在检测精度和速度上均有很大提高。YOLO(You Only Look Once)算法最早是Redmon等在2015年提出的基于端到端的目标检测算法[7],其检测速度达到了实时检测水平(45f/s)。随后Redmon等又在YOLO算法基础上,提出了YOLO v2[8],YOLO v3[9]等算法,其中YOLO v3算法能够在保持检测速度的同时取得较好的检测精度。2016年,W Liu等[10]提出了SSD(Single Shot MultiBox Detector)检测算法,该算法在检测速度和精度上均取得了不错的效果。
目前广泛使用的深度学习网络主要可以分为两类:第一类是基于区域检测的算法,像R-CNN,Fast-RCNN,Faster-RCNN等算法;第二类是基于回归的目标检测算法,像SSD、YOLO等算法[11]。其中第二类目标检测算法采用的是端到端的目标检测方式,在检测速度上有很大的提升,可以适用于许多需要实时检测的场景。
本文设计的深度卷积网络是基于YOLO v3算法的一种实时检测小汽车算法。它以YOLO v3网络架构为基础,将航拍下的小汽车作为检测目标,对YOLO v3网络进行改进,并且针对航拍下的小汽车检测网络结构进一步优化,设计出一种带有混合深度卷积[12]的YOLO深度学习网络。本次实验测试仿真平台使用的是Nvidia 1060显卡,测试结果表明:所提出的算法在检测精度和速度上相较于原始的YOLO v3均有提高。在航拍的视频检测中,AP(Average Precision)达到了91.60%,比原始算法提高了2.4%;检测速率提高到41.6f/s,比原始算法提高了32.5%。
2 YOLO v3算法原理
2.1 YOLO v3网络结构
YOLO v3网络结构是通过全卷积实现的。它的输入图像大小会重新调整为416×416,并采用3×3和1×1的连续卷积核对输入图像进行特征提取[13]。为了检测不同大小的目标,YOLO v3采用多尺度特征融合来增强网络检测的鲁棒性,特征图的大小分别为13×13、26×26、52×52。YOLO v3网络结构如图1和图2所示,图1为FPN网络结构,图2为特征提取网络结构。A、B和C代表连接点,残差代表残差网络块,Convs代表连续卷积模块。
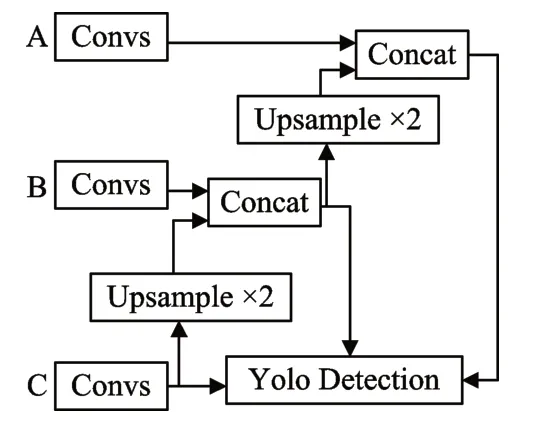
图1 YOLO v3 FPN结构图

图2 YOLO v3特征提取网络结构
2.2 YOLO v3损失函数
YOLO v3在损失函数设计上一共分为三个部分,分别是坐标、分类和置信度损失,最终的损失由三部分相加所得,如式(1)所示:
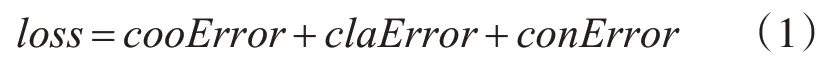
其中cooError代表预测数据与标定数据之间的坐标损失,cla Error代表分类损失,conError代表置信度损失。
坐标损失包含目标框坐标(x,y,w,h)和预测框坐标四个元素的均方和误差,其中表示各自预测框中是否存在待检测的物体,和IOU值大小有关系。s2为网络输入图片划分网格个数,B为每个网格产生候选框(anchor box)个数。坐标损失如式(2)所示:


3 改进YOLO v3算法
原始的YOLO v3网络结构都是采用大小为1×1,3×3的卷积核连续进行卷积操作,在速度和精度上虽然都取得了较好的效果,但是仍有许多改进空间。本文在YOLO v3网络结构的基础上,首先修改了YOLO v3网络结构,用混合深度卷积代替了原有的深度卷积;然后为了增强航拍下的小目标识别能力,将深层特征与更浅层特征相融合,缩小卷积核的感受野;最后在损失函数上进行改进,使用GIOU[14]代替了传统的IOU计算损失。
3.1 混合深度卷积网络结构
在原始的YOLO v3网络结构中,每一次的卷积操作只对应了唯一大小的卷积核。单一卷积核不仅运算量较大、而且对图像特征提取也比较单一。在改进网络结构后,一次混合深度卷积中使用不同大小的卷积核对输入的图像进行特征提取,首先将输入张量分成n维虚拟张量,然后依次使用不同卷积核分别对输入虚拟张量进行特征提取,最后将不同卷积核提取的特征向量合并。提供选择的卷积核大小有3×3,5×5,7×7,9×9。在使用混合深度卷积后,不仅减少了网络参数计算量,而且提取到的图像特征将更丰富,从而改善了网络的检测精度和速度。混合深度卷积的结构如图3所示。
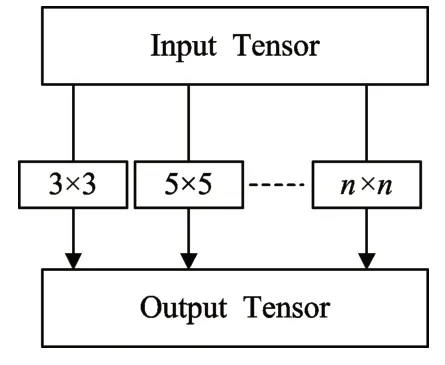
图3 混合深度卷积结构
具体的混合深度卷积过程如下:
1)假设输入张量为X(w,h,c),w为输入空间宽度,h为输入空间高度,c通道大小。首先将输入张量平均划分为n组的虚拟张量X(w,h,c1),X(w,h,c2)…X(w,h,cn),其中所有的虚拟张量和输入张量有相同的宽度和高度,并且有c=c1+…+cn。
2)假设原始的卷积核为W(k,k,c),k为卷积和大小,c为输入通道大小,在将输入张量平均划分好之后,再将卷积核也对应划分为同样的n组虚拟卷积核W(k1,k1,c1),W(k2,k2,c2)…W(kn,kn,cn)。其中c=c1+…+cn ki∈{3,5,7,9},i=1,2···n。
3)对于相对应的两组输入张量和卷积核,得到底t组虚拟输出张量如下:
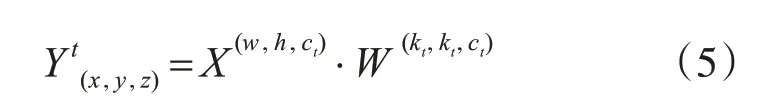
4)最终的输出张量Y(x,y,z)是将所有的虚拟输出张量串联,即:

在原网络结构的基础上,融合混合深度卷积,将原始大小为3×3的卷积核替换成大小为3×3、5×5等的混合深度卷积核。为了适应改进后网络参数学习,将网络的输入图片大小重整为224×224。改进后的网络对比于原先的YOLO v3网络则需要计算更少的网络参数,减小了网络模型,加速了网络的检测速度。
为了改善算法对小目标的检测效果,网络在yolo检测层融合不同尺度特征,在不同的特征图上进行预测。与YOLO v3检测网络结构不同的是,改进后网络重新修改了yolo层检测尺度,将第四次下采样大小为14×14的特征图进行4倍上采样与第二次下采样的特征图进行特征融合。网络最终输出了3个不同大小的特征图进行目标检测,其大小分别为7×7,14×14,56×56。多尺度融合后的网络使得相同的卷积核在原图中的感受野减小,改善网络对于小目标的检测精度。改进后的网络结构如图4、5所示。
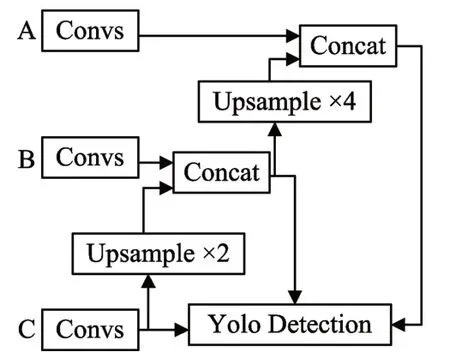
图4 改进后的FPN网络结构
3.2 损失函数改进
IOU(Intersaction over Union)是YOLO v3回归损失中使用的一个损失度量,其计算公式如式(7)所示:
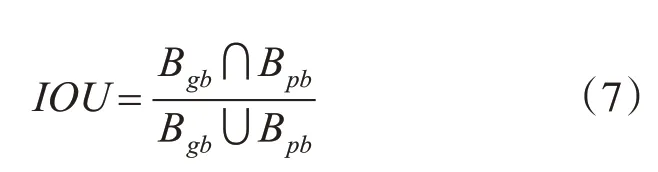
其中Bgb为目标框(ground bounding box),Bpb为预测框(predicted bounding box)。它可以表示预测框和目标框之间的距离,在回归损失中常使用IOU来作为一种损失度量。
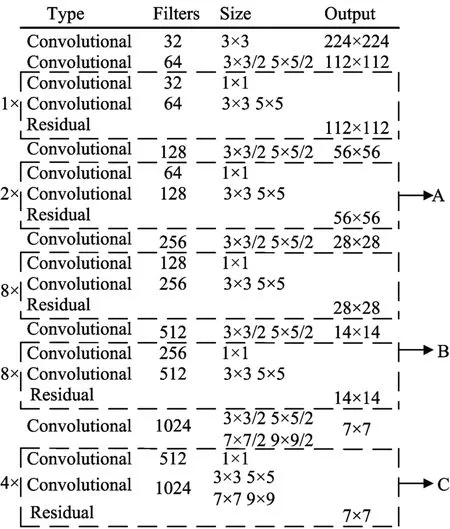
图5 改进后的特征提取网络结构
在直接使用IOU作为度量标准时,如果Bgb与Bpb没有相交,此时的IOU就不能反应真实的距离以及无法进行梯度回传,导致无法进行训练学习。此外,IOU也无法精准反应两个框的重合大小。基于上述问题,对于航拍下的小汽车检测采用GIOU作为一种新的损失度量。GIOU的计算过程如下。
1)对于任意Bgb、Bpb⊂Rn,有最小的一个闭集C,使得Bgb、Bpb⊂C⊂Rn。

对于IOU而言,其值域为[0,1],而GIOU的值域为[-1,1]。在两个形状完全重合时,有GIOU=IOU=1,当两个形状没有重叠部分时,IOU为0,GIOU为-1。在使用GIOU代替IOU作为一种新的损失度量后,即使Bgb与Bpb没有相交,此时的GIOU仍然有损失进行梯度回传,依然可以进行优化。
4 实验结果及分析
4.1 模型训练
为了提高算法在不同环境下的检测效果,本次训练中使用的图像由大疆公司发布的四旋翼无人机Mavic Pro在不同天气、角度、遮挡等情况下拍摄。无人机飞行高度50m~100m,相机拍摄角度垂直向下。视频共拍摄1000张照片,其中训练组900张,测试组100张。带标签小汽车总数为23316辆。仿真平台配置见表1。

表1 测试平台配置表
在环境配置完成后,对YOLO v3和改进后的YOLO v3分别进行训练,训练批次为10000轮。采用随机梯度下降算法对网络模型参数进行更新直至收敛。为了加快网络模型的收敛速度,将权值的初始学习率设置为0.01、8000和9000轮后学习衰减系数分别设置为0.1。
4.2 结果分析
分别对YOLO v3和改进的YOLO v3进行训练时,每1000次训练迭代保存一次最新的网络权值参数文件。在训练过程中发现,经过9000轮的训练,网络的精度和损失几乎没有变化,均达到稳定状态。图6和图7分别显示了训练过程中的AP和平均损失(Avg Loss)。
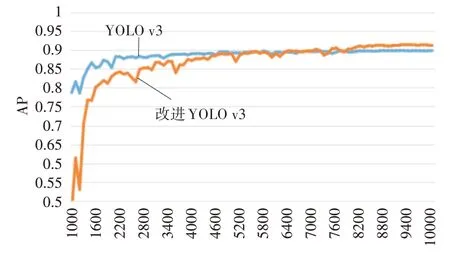
图6 训练过程中AP对比图
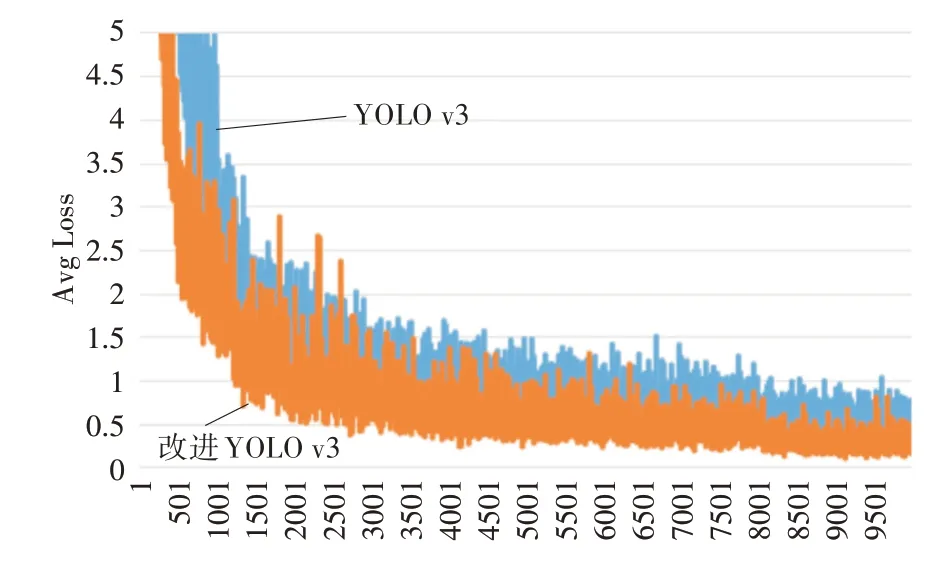
图7 训练过程中损失对比图
为了更准确地比较两种算法的检测精度和速度。训练结束后,利用网络保存的7000轮、8000轮、9000轮的参数权重文件,比较检测精度和速度。在比较两种算法性能时,采用控制变量法分别计算了相同硬件配置下两种算法的AP和检测速度。通过比较不同训练迭代的权重文件,改进后的YOLO v3具有更高的检测精度。结果见表2。
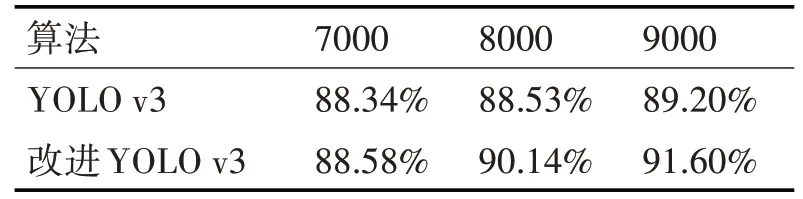
表2 迭代次数与AP对比表
在对不同网络结构的AP进行测试后,选择两种网络结构中AP的最高权值文件,在相同配置下测试检测速度。在检测同一视频文件时,YOLO v3的平均检测速度约为31.4f/s,而改进后的YOLO v3的平均检测速度约为41.6f/s。
为了验证改进算法对小目标检测的准确性,将无人机飞行高度定位在70m处,并在视频上测试了小车检测效果。图8显示了YOLO v3下的检测效果,图9显示了改进的YOLO v3检测效果。从图10的放大图可以看出,与右图相比,左图中标记为A、B、C的车具有更精确的检测框。改进YOLO v3算法可以检测出D车,而YOLO v3算法不能检测到D车。结果表明,改进YOLO v3算法比YOLO v3算法具有更高的检测精度。

图8 YOLO v3检测图
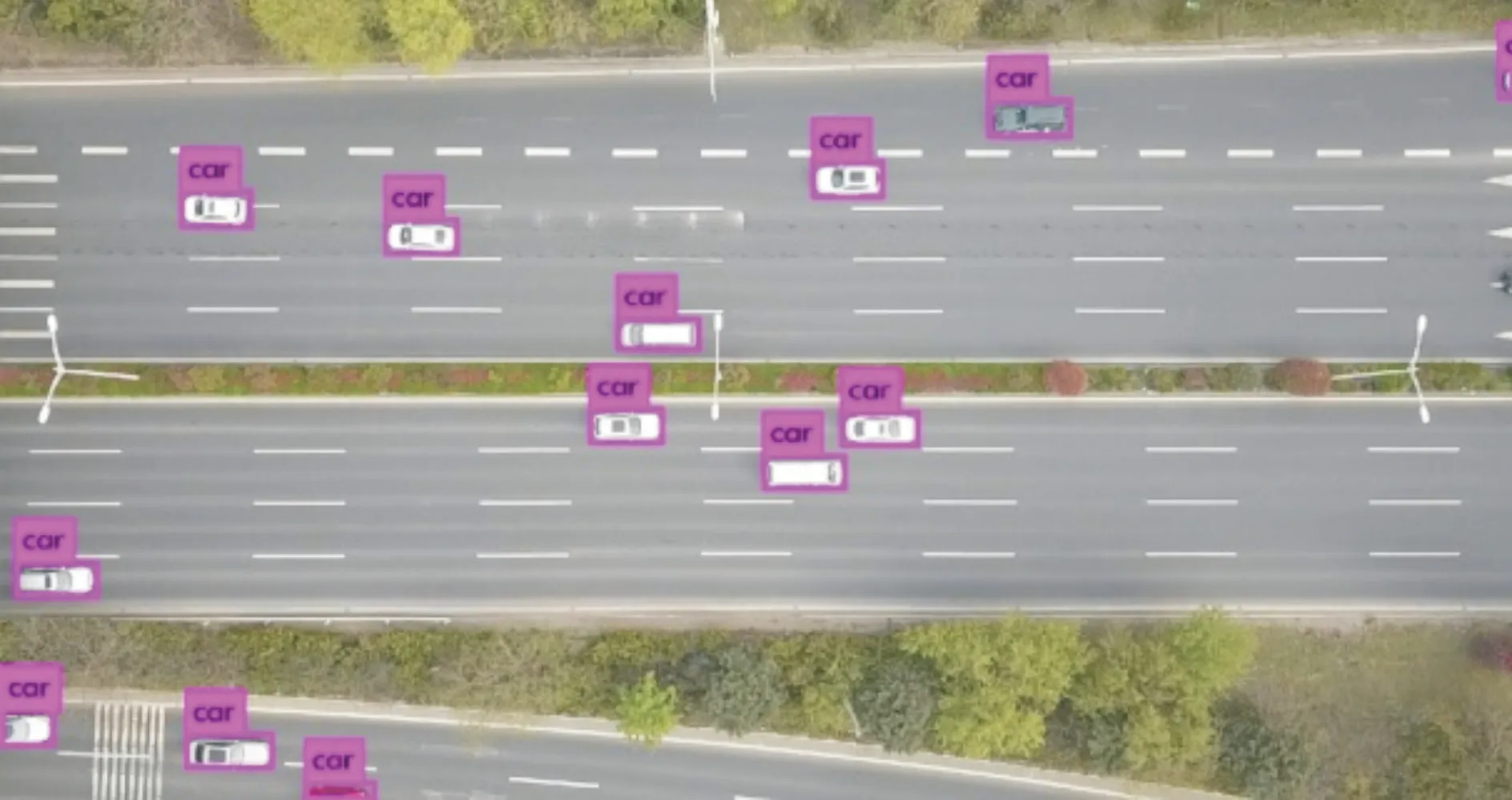
图9 改进YOLO v3检测图

图10 局部放大图
从对比结果来看,在准确度方面,改进后的YOLO v3略有提高,比YOLO v3提高了2.4%。在检测速度上,改进后的速度提高了32.5%。
4.3 不同算法实验对比
为了验证改进的YOLO v3算法的有效性,我们将当前主流的深度学习算法使用相同的训练样本与改进的YOLO v3算法进行了比较,并将其他算法参数设置为默认值。比较结果用检测AP与速度进行评价,结果如表3和图11所示。

表3 不同算法实验结果对比表
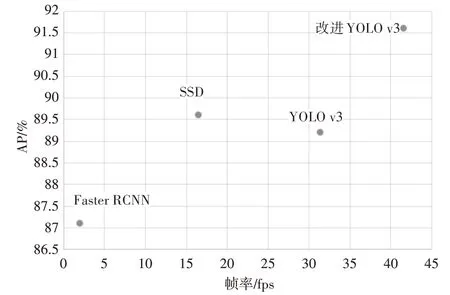
图11 不同算法速度和精度对比图
5 结语
本文提出的改进YOLO v3算法应用于航拍下的小汽车检测,解决了以往算法中检测精度和实时性不足的问题。改进YOLO v3算法在YOLO v3的网络基础上,将原始的单一深度卷积核替换为更适合特征提取的混合深度卷积核并且修改了检测特征图尺度大小,因此模型学习参数减少了,整体的网络检测速率也得到提升。在回归损失函数设计时,使用GIOU代替IOU度量损失,提高了算法的检测精度。测试结果表明,改进YOLO v3算法更适用于航拍下的小汽车检测。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
时代邮刊·下半月(2020年9期)2020-09-23
上海师范大学学报·自然科学版(2019年5期)2019-12-13
照相机(2019年4期)2019-09-10
航空模型(2017年12期)2018-05-08
中国新通信(2017年9期)2017-05-27
科学与财富(2016年15期)2016-11-24
科技视界(2016年18期)2016-11-03
数码影像时代(2015年2期)2015-07-07
