
基于多数据源融合的用户画像构建方法*
2022-05-10 07:27袁苗苗侯瑞春
计算机与数字工程 2022年4期
袁苗苗 侯瑞春 陶 冶 杨 宁
(1.中国海洋大学 青岛 266100)(2.青岛科技大学 青岛 266061)
1 引言
伴随着互联网应用范围的扩大,企业了解用户的特性变得简单。以信息技术为支撑,洞察用户需求为根本,通过用户画像技术,企业能更好地开展精准营销,根据用户画像对用户进行针对性的服务,从而提高企业的收益。
用户画像凭借着其广泛的应用,在当前仍然是一个热门研究问题。许多学者利用互联网大数据为用户构建画像,从各方面描述用户的属性特征,如陈学实[1]等提出基于用户画像对电力营销的差异化服务进行研究,通过确定用户的需求目标来提升产品的实际价值。崔春生[2]等提出情景环境下基于用户画像的旅游产品的推荐算法,借鉴标签化技术,将用户画像应用于旅游产品,有利于旅游预订网站为客户提供更加精细化的服务,为交通部门的交通规划和决策提供支持[3]。王正友[4]等提出了基于用户画像的视频精准推荐,通过挖掘和提炼用户的视频点播习惯和观看偏好形成用户画像,进而根据用户的喜好向其进行视频的推荐,达到提高平台收视率和网站流量的目的。另外,用户画像还在农产品的分析[5]、数字图书馆的智能阅读推荐模式[6]、小米手机的营销[7]等发挥着作用。由此可见,用户画像对企业来说有着很大的帮助,因此,本文提出融合多数据源进行用户画像的方法,全面挖掘用户融合不同领域特征后的行为偏好。
目前,在对用户特征进行描绘的研究中,存在如下的几个问题:1)原始数据来源单一,同构同质数据偏多,忽略了其他领域的数据对用户特征分析的作用;2)生成的用户画像比较片面,从多个领域的角度来分析用户的单一属性[8];3)缺乏直观的可视化方法;4)同一用户在不同领域的数据难获取。因此,本文提出基于多数据源融合的用户画像构建方法,分别获取用户不同领域的行为偏好,然后根据不同领域行为偏好之间的关系,融合用户的行为偏好获得用户画像。
2 相关研究
为了得到完善的用户画像,融合多数据源的用户画像得到了越来越多的研究人员的关注。孟琳[9]通过LDA算法进行机构主题的发现,利用论文数据、致谢数据和每个老师的基本信息对全校老师和学校机构做画像,经过验证,算法判断的实验室话题与实验室的实际发展方向一致,从而验证了用户画像能够挖掘属性特征。魏塬梅[10]提出了一种融合设计媒体内容和行为数据的用户画像技术,根据文本数据与行为数据来标注用户的兴趣特征,并与用户选择的兴趣做比较,实验表明,融合文本内容和行为数据进行预测与依据单文本内容进行预测相比,提高了预测准确度。范晓玉[11]提出融合多数据源的科研人员画像构建方法,分别从科研人员的基础属性、兴趣偏好和科研关系三方面形式化描述了科研人员信息,并提取了各个维度的标签,最终以可视化的方式展示了科研人员的画像,对快速认识和了解科研人员做出了很大的帮助。王星雅[12]引入了用户关键词聚合度的算法从而改进了k-means聚类算法,将用户兴趣词的词权重得到了提升,过滤了非用户关键词,从而更有利于挖掘和描述用户的兴趣特点。
3 用户画像构建过程
3.1 聚类算法建立标签库
融合不同领域的数据建立用户画像,首先需要分别针对不同领域的用户数据建立标签库。本文针对某比赛中提供的20万用户在浏览器中历史一个月的搜索记录数据和爬取的某品牌手机的网购评论数据建立用户兴趣偏好标签库和用户消费偏好标签库,构建流程如图1所示。
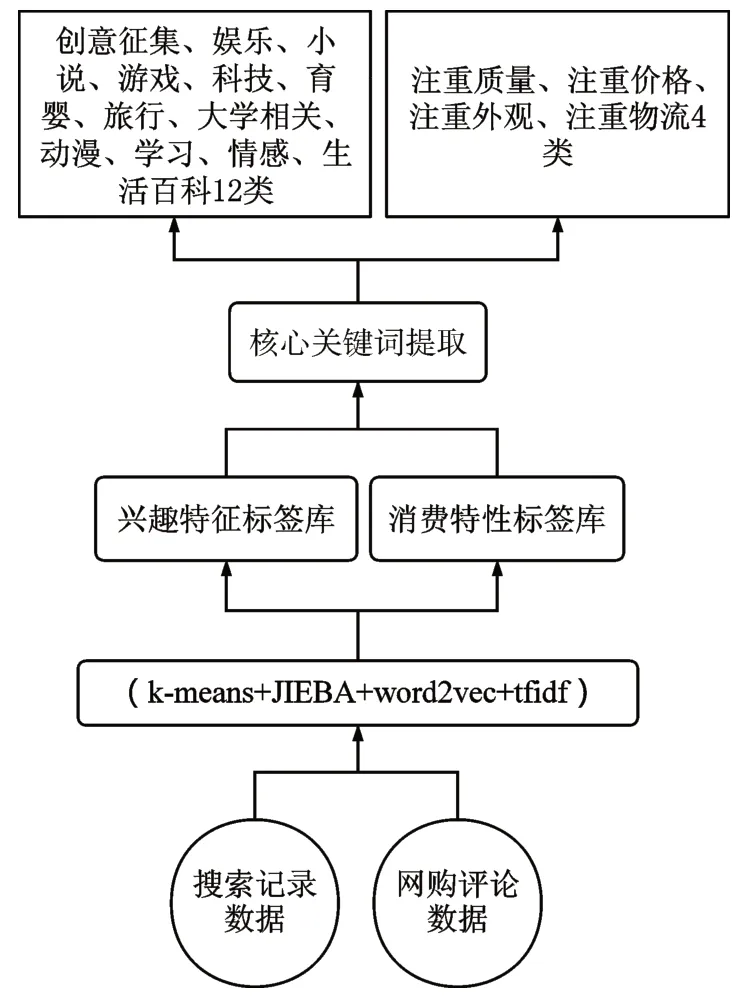
图1 不同领域标签库构建流程
首先是用JIEBA分词对原始数据进行分词处理,然后通过TF-IDF算法获得每一个分词wi的T F ID Fi值,再使用k-means算法进行聚类分析,为了滤除各个类别中的非核心关键词,引入了分词聚合度的算法,以向量内积的方式计算特征词之间的相似度,每一个分词wi与其他所有的分词之间向量内积和根据公式求得。计算每个分词的内部聚合度之后,每个分词wi的值为T F ID Fi*Di。每一个类别下取wi值最高的N个分词当作该类别下的代表关键词,形成“用户偏好-关键词”的标签库[13~14],标签库与部分关键词如表1~2所示。

表1 用户消费特性标签库及部分关键词

表2 用户兴趣特征标签库及部分关键词
3.2 获取不同领域的用户偏好
标签库的建立对该领域内所有用户的行为偏好进行了划分,获取不同领域的某一用户的偏好流程如图2所示。
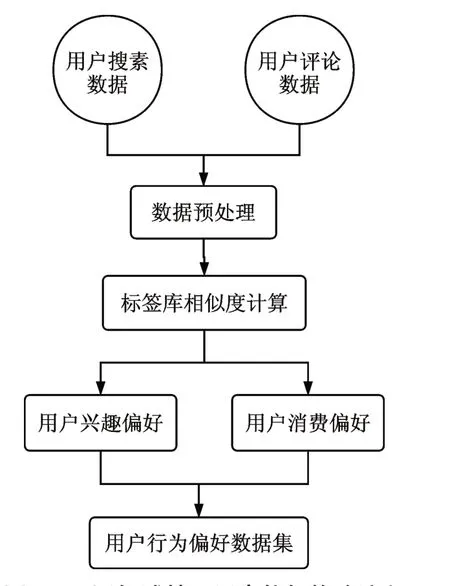
图2 不同领域某一用户偏好构建流程
本文通过word2vec算法计算用户数据集分词与每一个类别下关键词的相似度来获取用户的兴趣偏好和消费特性偏好。相似度计算值的大小代表用户偏好系数的大小。相似度值越大,代表用户在该类别的偏好系数越高,即用户对这一类别越感兴趣。经过计算,最终可以得出用户不同领域的偏好集{(p1,f1,weight1),…(pn,fn,weigh tn)}。pi代表用户偏好名,fi代表用户关键词输入的概率,weigh ti代表用户偏好系数。
3.3 用户偏好融合及可视化
单一领域的数据集下的用户偏好不具有全面性[15],融合多数据源计算用户偏好能够提高用户偏好描述的准确性。
如图3所示,不同领域的用户偏好之间存在互斥、独立、重合三种关系,从用户行为偏好集中获取用户pi,fi,weighti后,将用户不同偏好之间按照独立不影响、互斥取高信值、重合来加强的原则进行融合计算,重新获取用户该偏好的系数,从而得出融合后的用户偏好集。
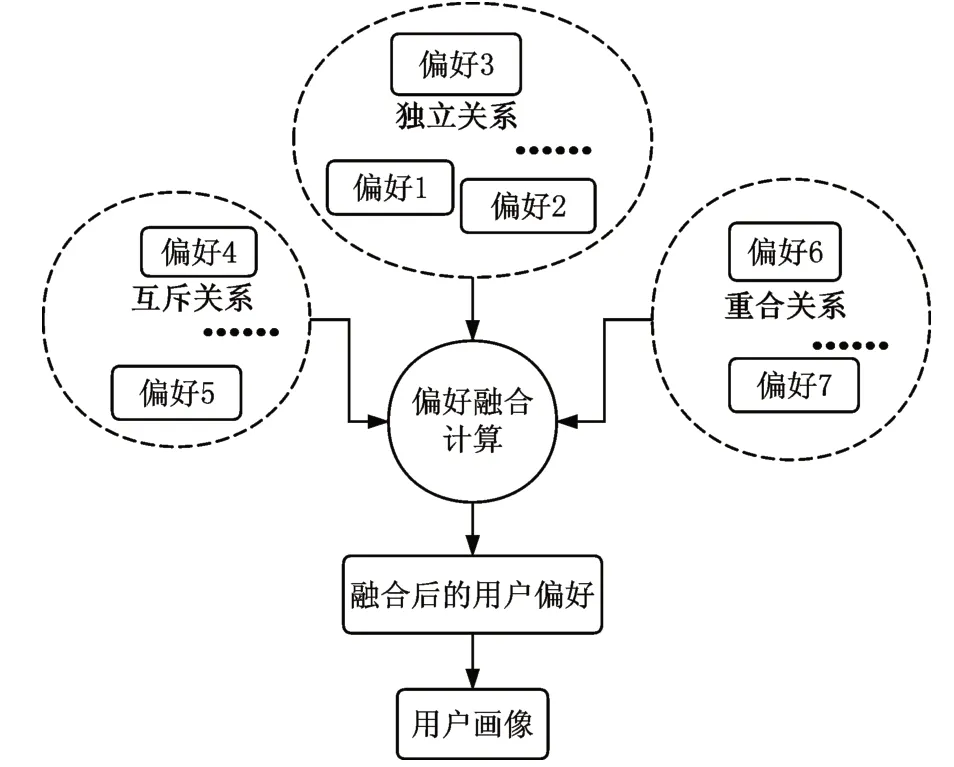
图3 用户偏好融合过程
融合后的用户偏好系数的确立由用户关键词输入概率、用户偏好系数和用户偏好之间的关系三部分确定。当用户偏好为互斥关系时,若用户关键词输入概率fi>fj,则融合用户偏好系数为fi*weigh ti,若用户关键词输入概率fi<fj,则融合用户偏好系数为fj*weigh tj,当用户偏好为独立关系时,融合用户偏好系数为fi*weigh ti,当用户偏好为重合关系时,融合用户偏好系数为fi*weigh ti+fj*wei ghtj,计算公式如式(1)所示。按照公式将融合后的用户偏好系数继续与剩余偏好系数重复上述计算,得出最终用户偏好系数。
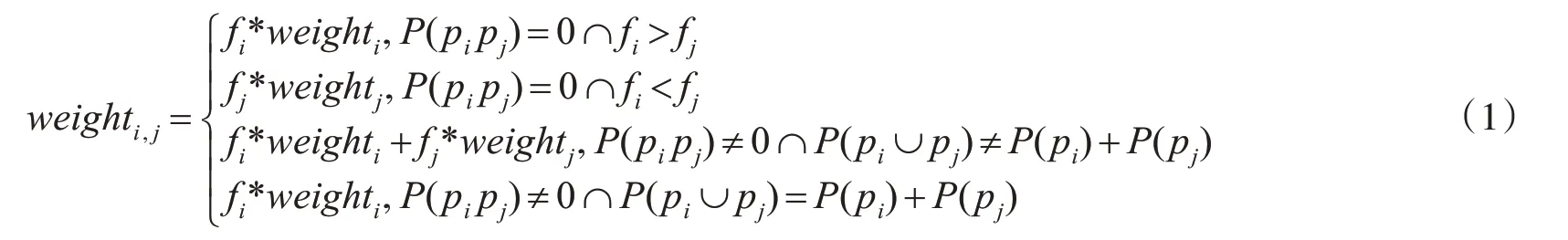
4 实验和讨论
为了验证该方法可以针对多数据源形成融合用户画像,进行了如下实验。
本文分别采集了某个用户近一个月内的网络搜索记录和京东评论数据。经上述过程,得出该用户的偏好数据集{(创意征集,0.1,0.1014),(娱乐,0.2,0.113),(小说,0.3,0.333),(游戏,0.08,0.081),(科技,0,-0.033),(育婴,0.02,0.029),(旅行,0,-0.067),(大学相关,0,-0.034),(动漫,0.2,0.136),(学习,0.1,0.071),(情感,0,0.005),(生活百科,0,-0.0004),(注重质量,0.2,0.254),(注重价格,0.2,0.247),(注重外观,0.4,0.384),(注重物流,0.2,0.230)}。
由于用户消费特性标签库建模来自于某品牌手机,因此在计算过程中,本文删除了标签库中不存在的用户评论数据分词。
根据用户兴趣偏好和消费偏好之间的关系,进一步获得用户在多领域下的融合用户偏好集{(创意征集,0.1,0.041),(娱乐,0.2,0.090),(小说,0.3,0.553),(游戏,0.08,0.077),(科技,0,0.092),(育婴,0.02,0.053),(旅行,0,0),(大学相关,0,0),(动漫,0.2,0.109),(学习,0.1,0.028),(情感,0,0),(生活百科,0,0),(注重质量,0.2,0.616),(注重价格,0.2,0.600),(注重外观,0.4,1.943),(注重物流,0.2,0.004)}。
从图4中可以看出,该用户在单一领域计算得出的用户行为偏好系数与融合消费领域与兴趣爱好领域的行为偏好系数的大小具有相似的特征:1)不同行为偏好的相对大小几乎一致且小说和注重外观的行为偏好系数都排在前列。从而可以验证该融合方法是有效的,融合前后都表明了用户喜爱看小说和购买产品时更注重产品的外观这两个行为。2)结合用户购买产品时注重质量的特性,融合后用户喜欢科技的行为偏好系数增大,因此,融合多数据源对用户的行为偏好进行分析,能够更加全面准确地把握用户属性特征。

图4 融合前后用户偏好系数对比
5 结语
融合多数据源便于企业进一步挖掘用户的属性特征,给用户提供更加精确的服务。在对用户画像的研究中,对于非量化的信息的研究是相对较少的,但是在多数的情况下,非量化的信息能够有力地表现出用户的特征。因此,本文分别从用户的搜索记录和评论记录中挖掘该用户在单一领域下的兴趣偏好和消费偏好,并提出了融合用户偏好的建模方法,有效地解决了不同领域相同用户数据难获取的问题。计算融合偏好系数时存在的问题主要在于三种不同关系的确立。用户偏好系数融合了多领域属性特征之间的影响,既充分利用了现有的数据资源,同时有效地支撑了企业的精准化服务和个性化推荐。与单一领域相比更能全面准确地代表用户的行为偏好程度。
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
非公有制企业党建(2020年10期)2020-10-27
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
电脑爱好者(2018年14期)2018-08-05
瞭望东方周刊(2017年7期)2017-03-01
电脑知识与技术(2016年8期)2016-05-19
科教导刊·电子版(2016年6期)2016-04-19
电脑爱好者(2015年20期)2015-09-10
小火炬·阅读作文(2014年2期)2015-03-11
