
基于多线程worker的高可靠数据分发服务模型
2022-05-10 13:13郑嘉成,张亚楠
哈尔滨理工大学学报 2022年1期
郑嘉成,张亚楠


摘要:针对传统数据分发服务中,由慢订阅者与慢连接问题引起的高丢包率问题,提出多线程数据分发模型,降低丢包率。采用多线程技术,基于actor模型,引入多线程worker实现订阅者并行接收数据,改进订阅者无状态消息返回发布者可能引起的慢连接问题,建立了基于多线程worker的高可靠数据分发服务模型,有效降低了數据传输过程中的丢包率。不仅通过与ZeroMQ(zero message queue,零消息队列)进行对比试验,表明该模型在接收不同长度报文情况下,能有效降低丢包率。而且通过对模型进行压力测试,验证其降低丢包率的有效性。
关键词:数据分发服务;发布订阅;丢包率;多线程;慢订阅者
DOI:10.15938/j.jhust.2022.01.003
中图分类号: TP393 文献标志码: A 文章编号: 1007-2683(2022)01-0014-09
Highly Reliable Data Distribution Service Model Based
on Multithreaded Worker
ZHENG Jiacheng,ZHANG Yanan
(1School of Computer Science and Technology, Harbin University of Science and Technology, Harbin 150080,China;
2School of Software and Microelectronics, Harbin University of Science and Technology, Harbin 150080,China)
Abstract:A multithreaded data distribution model is proposed to reduce the packet loss rate caused by slow subscribers and slow connections in traditional data distribution services. Based on the actor model, the multithreaded worker is introduced to enable subscribers to receive data in parallel and to improve the slow connection problem caused by lack of status message from subscribers to publishers, and a highly reliable data distribution service model based on the multithreaded worker is established to reduce the packet loss rate during data transmission effectively. A contrast experiment ZeroMQ (zero message queue) shows that the model can effectively reduce the packet loss rate when receiving messages of different lengths. The effectiveness of the model in reducing packet loss is also verified through stress tests.
Keywords:data distribution service; publish and subscribe; packet loss rate; multithreading; slow subscriber
0引言
数据分发服务(data distribution service,DDS)是一种网络数据通信的核心技术,满足分布式实时应用的通信需求,促使数据实时、高效地分发[1]。目前DDS数据分发服务在仿真领域的应用十分广泛,例如战场指挥[2-4],雷达仿真与声纳仿真[5-9],在军事领域尤其突出。与此同时,民用领域也逐渐开始采用数据分发服务,例如船舶管理[10-11],飞行器协同[12]以及电力系统管理[13-14]。随着应用场景的不断扩展,许多实际工作都因数据传输丢包率高,仿真效果不佳而停滞不前,例如强化学习对于仿真精度以及传输效率要求都比较高,高丢包对于多智能体间数据交换会产生极大的负面影响,在很大程度上降低模型评估的正确性,目前许多研究都致力于降低数据分发服务的高丢包问题。
目前对于定位丢包位置[15]和丢包率建模[16]的技术已经存在,但对于丢包问题本身还难以有效解决。通过上行增强技术[17]优化降低上行丢包率的方法,在适用场景上略显不足。利用关联分析法对MR数据的深度挖掘[18],借此实现精准优化,但该方法仅能从宏观上降低丢包率,微观上的丢包问题并没有得到解决。调整发送接收队列长度以及引入心跳机制的处理方法[19-20],在面对不同节点硬件时,存在通用性较低的问题。
本文通过改进零消息队列(zero message queue,ZMQ)发布订阅模式,引入actor模型的思想,提出一种基于多线程worker的订阅者,实现多线程协同数据接收,引入轮询池任务调度与收集器概念,改进传统发布订阅模式,建立一种高可靠的数据分发服务模型,有效降低数据分发过程中的丢包率。相比于从宏观上降低丢包率,本模型从微观上分析并解决了引起丢包率高的慢订阅者问题和慢连接问题;且本模型通用性较高,面对不同节点条件都能得到较好的应用。
1问题提出与分析
1.1高丢包率
使用ZMQ发布订阅模式进行数据发布时,发布者节点可能会因慢订阅者或慢连接问题造成高丢包率。因此,如何解决传统发布订阅模式下丢包率高的问题,是本文关注的重点。
1.2慢订阅者问题
当发布者与订阅者双方已经建立连接,此时主要的丢包原因在于订阅者接收报文速度无法跟上发布者发送报文速度。订阅者接收报文后,报文需要经过业务流处理,当业务流线程时间开销较大时,会造成订阅者进程中recv线程阻塞,阻塞结束后再次侦听发布者报文。ZMQ底层采用边缘触发机制,当订阅业务(SUB)流线程阻塞后多个报文到达时,触发器只会触发一次,报文中仅有实际触发的报文会被读取,未触发的报文则被丢弃。图1为SUB进程示意图。
解决慢订阅者有两种方法。一种是将报文贮存在发布者缓冲区中,但在高吞吐量应用场景下,发布者缓冲区由于堆积数据会导致内存溢出,尤其是面对多个订阅者的情况,磁盘缓冲更容易溢出。另外一种是将报文在订阅者缓冲区中贮存,这也是ZMQ的默认行为。该方法在瞬间消息量很大的应用场景下十分适用,订阅者可能只是暂时跟不上发布者速度,最终会赶上进度,然而,在连续接收大消息量的场景下,订阅者会因缓冲区溢出而崩溃,该方法并没有解决慢订阅者问题本身。
1.3慢连接问题
订阅者与发布者间进行数据传输,需要建立TCP连接,订阅者通过硬编码端点字符串向发布者建立连接,这一过程涉及TCP三次握手。对于订阅者来说,该握手过程通常会花费数毫秒时间;对于发布者来说,启动发布者接收开始命令后就开始将原始数据封装成报文进行发送。PUB进程与SUB进程并行执行,ZMQ在后台进行异步I/O传输,由于发布者发送消息在时间上领先于订阅者建立连接,因此对于发布者来说,此时会形成无订阅者接收消息的情况。zmqPUB套接字出于减轻系统负载的目的,会在无接收者期间自动丢弃所有报文,基于该
处理机制,发布者在订阅者建立连接期间发送的报文会全部丢失。即使尝试在启动订阅者之后再启动发布者,也无法规避TCP三次握手所需要的数毫秒,最终还是会导致发布者丢弃在建立连接之前发送的所有报文。图2为慢连接问题示意图。
针对慢连接问题,有两种解决方法。方法一是发布者延迟发布,在发布者启动后阻塞其PUB进程,SUB进程在PUB进程阻塞期间建立连接,实现进程同步。该方法的不足之处在于无法准确设置PUB进程阻塞时间长短,阻塞时间设置过长会造成不必要的时间开销,阻塞时间设置过短则不能完全同步收发双方进程,无法彻底解决慢连接问题。方法二将发布者数据流看作无限流,没有所谓的起点与终点,从订阅者建立连接后接收到的第一条报文作为起点,忽略建立连接时被丢弃的报文。该方法并没有解决慢连接问题,且适用的场景较少。
2设计与实现
传统订阅者消息接收线程与业务流线程串行执行,引起慢订阅者问题;本模型订阅者通过多线程worker实现,多个worker间并行执行消息接收线程与业务流线程。通过共享内存的inproc协议作为worker与订阅者间通信的桥梁,以提高模型执行效率。多线程worker订阅者将传统模型订阅者缓冲区在逻辑上划分为若干分区,通过多个worker线程分别读取逻辑上划分的分区,达到优于单一线程处理整个缓冲区的效果,提高订阅者消息接收能力。
在此基础上,为了实现worker间负载均衡,本模型订阅者中新增并实现了轮询池作为worker状态轮询接口,负责有序管理多个缓冲分区,通过双向异步侦听和轮询算法实现worker负载均衡,防止同一个worker处理过多消息,提高发布订阅模型并发性;另外,在传统订阅者的基础上,设计并实现用于消息汇总的订阅者收集器,不同worker将各自处理的消息结果进行异步汇总,通过公平队列这样的无锁算法实现订阅者消息接收能力的进一步提升。
传统发布订阅模型中,发布者与订阅者之间只能进行单向通信,订阅者对发布者而言不可见,引起慢连接问题。本模型通过架设双向通路实现发布者与订阅者间双向通信,基于双向通信达到发布者与订阅者间状态同步,控制发布者进程与订阅者进程同步执行,防止慢连接问题引起的丢包现象。
2.1模型设计
基于多线程worker的高可靠数据分发服务模型,主要包含3个部分的内容:订阅者与worker之间关系结构的设计、worker之间的消息分配设计、worker资源释放时机的控制。①订阅者与worker之间关系结构的设计,该设计涉及订阅者与worker间是否解耦,不同worker间能否相互通信,对于发挥模型并发性来说非常关键。订阅者启动时,通过其上下文subscriber_context创建多个worker实例,创建的worker为订阅者服务,由此构成一个能够多线程并行处理消息的订阅者。设计良好消息分配机制的worker可以有序管理订阅者缓冲区的不同分区,对于充分发挥模型的的并发性,降低worker之间耦合性,都具有重要意义。②worker之间的消息分配设计,由于worker是消息驱动的,为同一订阅者服务的多个worker之间相互解耦,不直接进行消息通信,取而代之的是由订阅者创建轮询池为worker进行消息分配。此外,消息分配是否合理决定了worker任务分发是否高效,基于轮询池的负载均衡分配方式与数据分发服务业务场景相契合,采用轮询算法进行消息分配的轮询池有利于提高worker接收消息利用率,有利于充分发挥多线程编程的并发效率。③控制worker资源释放时机,多线程worker数据分发服务模型中,订阅者可以动态控制worker资源释放时机,這一点对于数据分发系统来说至关重要。如果将数据分发到某个worker处进行接收,那么系统必须等待该消息的接收结果,该等待过程包括消息的接收、处理和汇总。当不再需要worker接收消息时,订阅者可以适时释放worker资源,达到节约系统资源的目的,释放worker资源时采用Python语言经典的资源回收机制,当worker引用计数为零时,会被视为垃圾进行处理,回收worker所占用的内存空间,由于该操作涉及较大的危险性,因此采用Cpython解释器提供的自动垃圾回收机制,防止由于内存回收造成可能的内存溢出问题。图3是多线程worker数据分发模型消息架构。
多线程worker数据分发服务模型的消息数据流向如图3所示,分为3个部分:发布者、worker和收集器,分别表示数据源端的发布者,数据实际接收的worker端和数据处理结果汇总的收集器端,发布者、worker和收集器都有具体名称、地址以及端口号。对于需要跨机器通信的情况,可以利用硬编码端点字符串,即IP地址和端口号,对于用户来说,发布端作为相对固定的端点,其地址和端口是透明的,通过连接发布端地址和端口,与应用程序进行消息通信。其中消息数据在各部分的具体过程如下,图4为订阅者创建worker时序图。步骤一:上层应用产生原始数据,向发布者zmqsocket(zmqPUB)发送selfstart()命令,此时发布者等待订阅者connect()方法的返回。步骤二:订阅者通过self__init()__方法初始化,在订阅者上下文subscriber_context中创建若干worker,并通过Pollerregister()方法将worker注册进轮询池,每一个worker管理一块订阅者缓冲分区。同时,对发布者建立连接。步骤三:发布者将原始数据进行封装,以报文的形式发送给订阅者,订阅者在调度上下文中将消息分配给worker处理。步骤四:worker接收到消息后,在调度上下文中完成业务逻辑处理,并将处理完成的结果封装成ZMQ消息发送给收集器。步骤五:收到终止信号后,收集器调用worker的终止事件回调,对worker进行停止操作,订阅者释放worker资源。
2.2轮询池设计与实现
為了实现消息快速高效的接收,防止在一个worker处集中过多的数据,导致该worker负载过大,尽可能降低worker队列中消息的等待时长是至关重要的。新增订阅者轮询池,主要负责订阅者消息分配,侦听发布者是否发送新消息以及分配最后一个工作的worker为其进行处理。图5为轮询池的数据结构。
轮询池是一个状态轮询接口,映射Python内置轮询机制,通过selfsockets列表保存轮询对象与轮询事件的二元组(worker_x, event_x),利用self_map哈希表保存轮询对象在self_map中的索引值,提高轮询时的查询速度。
在订阅者上下文中创建worker的同时,在轮询池中注册worker。订阅者主线程接收消息时,轮询池对同一线程中的不同轮询对象进行双向异步侦听,侦听对象为已注册的ZMQ套接字,注册时采用ZMQ套接字引用与特定事件对的方式,当侦听到特定事件发生在对应ZMQ套接字上时,发送回调激活套接字。上游侦听发布者,为避免轮询循环内的任何阻塞调用,采用poll()方法检查是否有可用数据,如果侦听到上游有可用数据进入,则弹出下一个worker套接字对其进行业务处理;下游侦听worker,当轮询池侦听到可用数据时,刷新worker套接字recv()端口,采用轮询算法分配worker套接字处理消息。采用轮询作为实现多线程worker负载均衡的算法。轮询算法适用于订阅者订阅一种主题时,多个worker处理的消息的业务逻辑完全相同,可以近似地认为每一个worker处理一条消息的开销相同,图6为轮询池消息分配示意图。
2.3多线程WORKER设计与实现
为实现数据并行处理,订阅者部署多线程worker负责处理业务逻辑。将节点概念扩展,节点可以是主机、进程甚至是线程,worker节点通过inproc协议(进程内连接)与订阅者线程建立连接,采用inproc协议作为订阅者与worker之间通信的桥梁,inproc协议是一种在单个ZMQ上下文线程间通过共享内存实现消息传递的协议,可以显著提高多线程worker数据传输效率。为了提高模型的并发性,对
多线程worker隔离性与一致性提出了要求。对于隔离性,worker间应避免使用锁和信号量等技术来实现并发隔离,在不使用时间开销较大的方案的前提下,需要防止同一报文重复被多个worker业务流处理,降低处理效率。基于此考虑,多线程worker通过轮询池消息分配实现并发编程隔离性,轮询算法作为一种无状态调度算法,确保每条消息只会由一个worker进行处理,且ZMQ并发编程本身采用无锁算法,从而在保证性能的前提下实现多线程worker隔离性。一致性方面,worker接收到报文后对报文解包,进行相应业务流处理后,将处理结果封装成ZMQ报文,发送至收集器汇总,收集器接收汇总消息,激活回调函数,更新统计信息;worker通过zmqPULL套接字发送汇总消息,与收集器之间通过inproc协议建立快速的进程内连接,多个worker间采用公平队列算法实现消息汇总,采用该调度算法的优点在于不会因高负载worker而阻塞其他worker汇总消息,可以在保证消息汇总一致性的同时,进一步提高多线程worker性能。worker类图如图7所示,包括zmqcontextContext定义上下文,zmqsocketSocket定义通信套接字等。
worker通过订阅者上下文sub_context初始化后,与轮询池建立进程内连接,完成操作后通过workerrecv()方法异步等待消息分配,轮询池侦测到消息到来后,会将消息分配给worker,worker对接收到的消息进行业务流处理,通过ZMQ消息的形式发送结果给收集器,每处理一条消息,判断一次当前消息发送是否发生已经结束,如果当前状态不再有新的消息传入,则通过Python GC机制实现资源回收,节约开销。worker流程图如图8所示。
2.4状态同步
受制于传统发布订阅模式单向数据传输的思想,订阅者可以接收来自发布者的消息,但发布者无法获取订阅者的状态,双方建立连接时无法做到状态同步。因此,需要改进传统单向数据传输模式,使发布者可以获取订阅者的状态信息,通过数据双向传输达到状态同步的目的。在发布者接收到上层应用开始命令后,通过新增REP套接字阻塞等待订阅者状态报文;订阅者建立连接后,通过新增REQ套接字向发布者发送状态报文。REP套接字接收状态报文,回调激活发布者,实现发布订阅双方状态同步,解决慢连接问题。图9为订阅者流程图。
3测试与分析
3.2测试方案
通过测试原生ZMQ发布订阅模式与基于多线程worker的ZMQ发送不同长度报文、固定个数报文以及进行压力测试时的丢包率。本次测试的网络环境为3684Mb带宽。用于发送报文的计算机配置如下:Win10操作系统,运行内存16G,内存500G,CPU为AMD r5,六核,主频为21-40GHz;用于接收报文的计算机配置如下:Win10系统,运行内存12G,内存500G,CPU为Intel CORE i5,四核,主頻为230GHz。
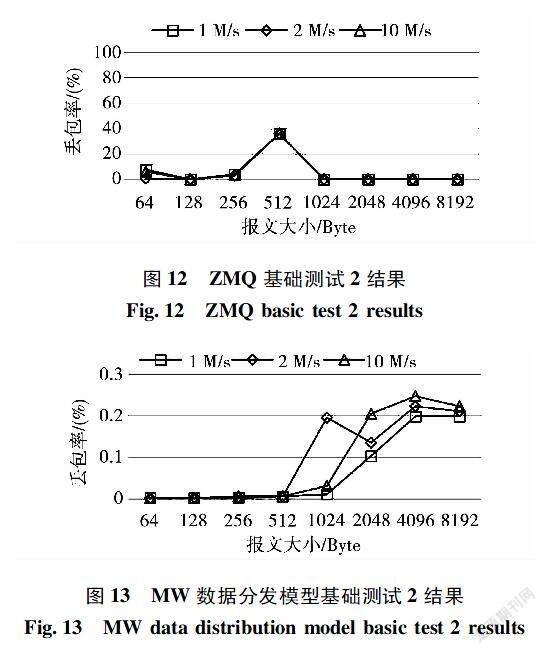
本次测试分为两项基础测试与两项压力测试,第一项基础测试内容为发送端发送一百万条不同大小报文,报文大小分别为64、128、256、512、1024、2048、4096、8192Byte;第二项基础测试内容为发送端发送总字节数为一百万Bytes的报文,每条报文的大小分别为64、128、256、512、1024、2048、4096、8192Byte。第一项压力测试内容为在不同额外负载下,发送一百万条消息,即测试性能时,同时以3M/s、6M/s和30M/s的速率发送其他流量,以非测试报文挤占带宽;第二项压力测试内容为长时间连续发送报文,发送时长分别为1~10 min。
上述基础测试中发送端均不设置发送间隔,并控制发送端分别以1M/s、2M/s和10M/s的速率进行发送,测试其丢包率。上述压力测试不设置发送间隔与发送速率,测试其丢包率。
3.2测试结果
基础测试与压力测试结果如图10~17所示。图10为ZMQ基础测试1丢包率,分别测试发送一百万条报文,报文长度分别为64、128、256、512、1024、2048、4096、8192Byte时的丢包率,发送速率分别为1M/s、2M/s和10M/s,当报文大小增长到512Byte时,丢包率有明显提升,达到了6745%;图14和图16分别为ZMQ压力测试1和压力测试2的丢包率,可以观察到在512Byte时丢包率陡增,分别达到了6899%和7296%。该现象是由于报文过大导致订阅者业务流阻塞时间过长,期间缓冲区溢出以致于大部分报文被丢弃。
从基础测试和压力测试结果中可知,原生ZMQ在发布512Byte以下大小报文时,可以保持较低的丢包率,即使是在带宽被挤占和长时间发送的情况下,发布小型报文的丢包率都较低;而当报文大小增长到512Byte及以上时,丢包率发生陡增,说明原生ZMQ对于大报文的处理能力较低。本文提出的多线程worker数据分发模型通过worker并行读取数据,提高订阅者缓冲区的利用率,增强订阅者面对大型报文时的处理能力,在保持高效处理小型报文的基础上,提高了订阅者处理大型报文的能力,测试结果表明,本模型在处理不同大小报文的压力测试下,都能保持5%以下的丢包率。
4结论
本文针对传统数据分发模型高丢包问题,提出了一种基于多线程worker的高可靠数据分发服务模型,解决传统模型中慢订阅者与慢连接问题。在发送不同长度报文和相同总长度报文的基础测试中,接收长度小于512Byte的短报文时丢包率降低2211%;接收长度大于等于512Byte的长报文时丢包率降低8737%。在非测试报文挤占带宽压力测试中,本模型降低丢包率5920%,在长时间连续发送报文压力测试中,本模型降低丢包率5565%。实验表明,本文提出的多线程数据分发模型在发布订阅长度在8192Byte以内报文时可以显著降低丢包率,该模型是一种有效的模型。
基于多线程的数据分发模型丢包率低,可以用于改善强化学习中多智能体间数据交互,使得模型评估更加精准,仿真效果更加完善。虽然该模型可以有效降低报文丢包率,但在发布者高频发送报文的情况下,丢包率仍然较高,因此仍然需要进一步研究高频发送报文丢包的原因和解决方案。
参 考 文 献:
[1]郝玲玲,傅妍芳.发布/订阅模型DDS应用研究及其性能评价[J].西安工业大学学报,2020,40(3):290.
HAO Lingling, FU Yanfang. Application and Performance Evaluation of DDS Based on Publish/Subscribe Model [J]. Journal of Xi′an Technological University,2020,40(3):290.
[2]朱子杰,汪敏,李荣宽,等.基于DDS战术服务框架的实现机制[J].指挥信息系统与术,2020,11(4):52.
ZHU Zijie, WANG Min, LI Rongkuan, et al. Implementation Mechanism for Tactical Service Framework Based on DDS [J]. Command Information System and Technology,2020,11(4):52.
[3]雷媛元,焦璐,王锐,等.基于数据分发服务的通用仿真框架技术[J].计算机应用,2020,40(S1):146.
LEI Yuanyuan, JIAO Lu, WANG Rui, et al. General Simulation Framework Based on Data Distribution Service[J]. Journal of Computer Applications,2020, 40(S1):146.
[4]刘家雨,王永生,刘爱东.基于DDS的防空武器信息交互系统[J].指挥控制与仿真,2021,43(2):127.
LIU Jiayu, WANG Yongsheng, LIU Aidong. Air Defense Weapon Information Exchange System Based on DDS [J]. Command Control & Simulation,2021,43(2):127.
[5]山寿,王鹏,聂瑶佳.基于任务容器的多源数据实时监控技术研究[J].计算机测量与控制,2020,28(3):98.
SHAN Shou, WANG Peng, NIE Yaojia. Research on Multisource Data Realtime Monitoring System Based on Task Container [J]. Computer Measurement & Control,2020,28(3):98.
[6]孫晓冬.基于数据分发服务的雷达仿真系统设计[J].科技视界,2019(18):6.
SUN Xiaodong, Radar Simulation System Design Based on Data Distribution Service [J]. Science & Technology Vision,2019(18):6.
[7]山寿,郝明哲,孙伟.基于数据分发服务和WPF技术的试飞实时监控系统设计[J].计算机测量与控制,2020,28(3):119.
SHAN Shou, HAO Mingzhe, SUN Wei. Design of Realtime Monitoring System for Flight Test Based on DDS and WPF Technology [J]. Computer Measurement & Control,2020,28(3):119.
[8]毕晓龙.基于数据分发服务的声呐仿真系统的研究[J].舰船电子工程,2019,39(12):191.
BI Xiaolong. Research on Sonar Simulation System Based on Data Distribution Service [J]. Ship Electronic Engineering,2019,39(12):191.
[9]CHA J H, KIM D S. Design and Implementation of a Realtime Monitoring Tool for Data Distribution Service[J]. IEIE Transactions on Smart Processing & Computing,2018,7(4):264.
[10]刘元斌,占日新.航电系统仿真环境通信架构研究[J].中国新技术新产品,2021(3):16.
LIU Yuanbin, ZHAN Rixin. Research on Energy Electronics System Simulation Environment Communication Architecture [J]. China New Technology New Product,2021(3):16.
[11]王坤,房玉吉,冯源,等.基于Qt和OpenDDS的船舶电力模拟训练系统指令处理方法[J].船海工程,2018,47(6):50.
WAN GKun, FANG Yuji, FENG Yuan, et al. Command Processing of the Ship′s Power Simulation Training System Based on QT and OpenDDS [J]. Ship & Ocean Engineering,2018,47(6):50.
[12]杜越洋,赵盾,闫智超.基于数据分发服务的无人机任务载荷综合仿真平台研究[J].无人系统技术,2021,4(1):79.
DU Yueyang, ZHAO Dun, YAN Zhichao. Research on DDSbased Integrated Simulation Platform for UAV Mission Payload [J]. Unmanned Systems Technology,2021,4(1):79.
[13]TAREK A.Youssef,Mohammad Mahmoudian Esfahani,Osama Mohammed. DataCentric Communication Framework for Multicast IEC 61850 Routable GOOSE Messages over the WAN in Modern Power Systems[J]. Applied Sciences,2020,10(3):848.
[14]史佳雯,汪洋,张庚,等.面向电力通信网的分布式仿真系统[J].计算机工程与应用,2019,55(19):246.
SHI Jiawen, WANG Yang, ZHANG Geng, et al. Distributed Simulation System for Power Communication Network [J]. Computer Engineering and Applications, 2019,55(19):246.
[15]金志平,梁志标,刘胜华,等.自适应动态视频流传输策略研究[J].网络安全技术与应用,2021(5):57.
JIN Zhiping, LIANG Zhibiao, LIU Shenghua, et al. Research on Adaptive Dynamic Video Flow Transmission Strategy [J]. Network Security Technology & Application,2021(5):57.
[16]韩旭,赵国荣,王康.基于线性编码补偿方法的非固定丢包率下的分布式融合估计器[J].北京航空航天大学学报,2020,46(6):1229.
HAN Xu, ZHAO Guorong, WANG Kang. A Decentralized Fusion Estimator Using Linear Coding Compensation Method with Nonfixed Dropout Rates [J]. Journal of Beijing University of Aeronautics and Astronautics,2020,46(6):1229.
[17]孙学军.降低上行丢包率提升VoLTE语音质量的研究[J].中小企业管理与科技(上旬刊),2019(7):182.
SUN Xuejun. Research on Reducing Uplink Packet Loss Rate and Improving the Quality of VoLTE Speech [J]. Management & Technology of SME, 2019(7):182.
[18]王建,王康,劉方森.基于MR的VoLTE高丢包优化分析方法研究[J].电信技术,2019(6):19.
WANG Jian, WANG Kang, LIU Fangsen. Research on MRbased Volte High Packet Loss Packet Optimization Analysis Method [J]. Telecommunications Technology, 2019(6):19.
[19]李春雷,高峰,颜运强.基于Actor模型的软总线设计[J].计算机工程,2019,45(5):77.
LI Chunlei, GAO Feng, YAN Yunqiang. Design of Soft Bus Based on Actor Model [J]. Computer Engineering,2019,45(5):77.
[20]童佳锋.基于DDS的软件接口测试方法研究[J].电子测试,2021(9):113.
TONG Jiafeng. Research on DDSbased Software Interface Testing Method [J]. Electronic Test, 2021(9):113.
(编辑:王萍)
