
基于分层压缩激励的ASPP网络单目深度估计
2022-05-09 06:52:34廖志伟张超凡杨学志
图学学报 2022年2期
廖志伟,金 兢,张超凡,杨学志
基于分层压缩激励的ASPP网络单目深度估计
廖志伟1,2,金 兢1,2,张超凡3,杨学志2,4
(1. 合肥工业大学计算机与信息学院,安徽 合肥 230009;2. 工业安全与应急技术安徽省重点实验室,安徽 合肥 230009;3. 中国科学院合肥物质科学研究院,安徽 合肥 230031;4. 合肥工业大学软件学院,安徽 合肥 230009)
场景深度估计是场景理解的一项基本任务,其准确率反映了计算机对场景的理解程度。传统的深度估计利用金字塔池化(ASPP)模块可以在不改变图像分辨率的情况下处理不同像素特征,但该模块未考虑不同像素特征之间的关系,导致场景特征提取不准确。针对ASPP模块在深度估计中出现的弊端,提出了一种改进型的ASPP模块,解决了该模块在图像处理中存在的失真问题。首先在卷积核后添加基于分层压缩激励的ASPP结构块,结合各像素特征之间的关系,让网络自适应学习感兴趣部分;再通过构造差值矩阵解决网络层次优化问题;最后在室内公共数据集NYU-Depthv2上进行深度估计网络模型的搭建。与当前主流算法相比,文中算法在定性、定量指标上均有良好表现。在相同的评估指标下,1阈值精度提升近3%,均方误差(RMSE)、绝对误差(Abs Rel)下降1.7%,对数域误差(lg)下降约0.3%。该方法所训练的网络模型,解决了传统ASPP模块未考虑不同像素特征之间关系的问题,特征提取能力增强,场景深度估计的结果更加准确。
深度学习;卷积神经网络;深度估计;空洞空间金字塔池化;分层设计
当利用成像设备采集三维场景图像时,往往只能得到二维信息,忽略了一个维度的信息,即深度信息[1]。场景深度估计任务是恢复场景中每个像素的深度信息,深度图像包含了真实场景下的固有空间信息,广泛应用于各种图像处理任务中,如目标识别、语义分割、三维重建等[2-3]。因此,场景深度估计任务受到了众多研究人员的重点关注和研究。
当前,深度信息的获取主要有直接获取法和间接获取法2种。直接获取法是通过硬件测量获取深度。目前市面上有各式各样的传感器用来感知3D场景,常见的设备有激光雷达、Kinect等,激光雷达通过发射激光束获取参数信息,信号远距离的传输会存在多径衰落,进而影响测量精度。此外,激光雷达内部构造精细且复杂、成本较高。Kinect由于工作范围有限,一般感知深度的有效范围在10 m以内,多应用于室内场景,采集场景图像时,环境光照的强弱将影响成像结果,不可避免地带来噪声。间接获取法是基于图像处理的手段获取深度信息。根据视觉传感器的数量又可分为单目、双目、多目深度估计。基于双目法获取深度信息,主要通过双目视差模拟人眼对深度感知的方法。采集场景图像时需配置2台具有相对人眼位置的相机,根据三角测量原理[4]转化为图像之间的几何约束关系求解深度,但易受外部环境及硬件配置(如基线长度等)影响,导致固有的几何约束关系变弱,进而难以获得高质量的视差图,具体方法如图1所示。基于多目法获取深度信息是利用多目图像之间的冗余信息计算深度信息,计算结果较为准确,但是在采集场景图像时需要配置摄像机阵列,故在实际应用中很少被使用[5]。
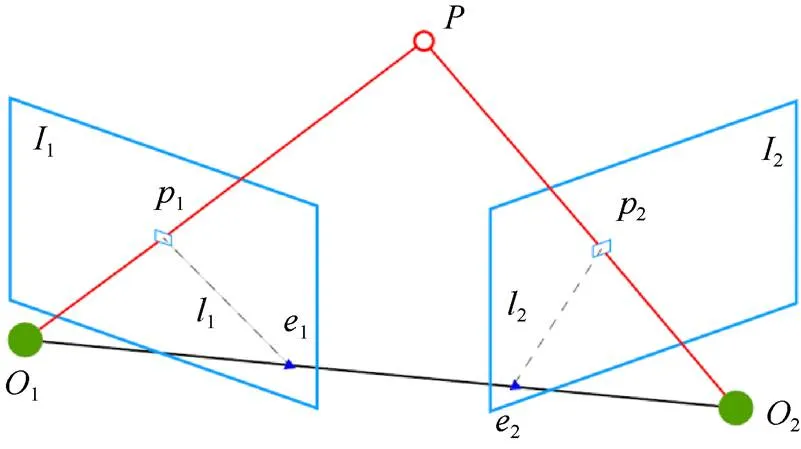
图1 三角测量原理计算深度
与上述基于双目、多目方法相比,单目相机具有价格低廉,获取信息内容丰富,体积小等诸多优点,且单目深度估计方法所需的相机数量少、参数量低。给定一张图像,就能估计出其深度信息,其操作灵活且便捷。考虑到大多数应用场景只有一个视点的数据,最贴近实际应用需求。然而,一个三维空间坐标可以对应无数多个平面坐标,而且单张图像本身存在信息缺失,因此单目深度估计为不适定问题,具有较大的挑战。如果能够从单目视频或单目图像中准确恢复深度信息,这将对计算机视觉领域的发展起到极大的促进作用。
单目深度估计的研究由来已久,早期的方法是通过几何约束[6]和手工提取特征[7]的方式推导出深度线索,进而得到深度信息。由于这些方法对环境要求严格,算法仅适用于小景深图像。随着深度学习技术的日益成熟,人们利用该技术在一定程度上解决了单目深度估计所具有的不适定问题[8-9]。2012年,KRIZHEVSKY等[10]提出的卷积神经网络(convolutional neural networks,CNN)模型取得了历史性的突破,首次将深度学习用于大规模图像处理任务中。近年来,随着CNN在图像处理领域的成功应用,研究人员开始尝试利用CNN处理单目深度估计问题;2014年,EIGEN等[11]将CNN划分成粗尺度和细尺度2种不同的网络分别提取场景的全局、局部信息,再利用尺度融合手段得到高分辨率深度图像;2015年,EIGEN和FERGUS[12]在已有工作的基础上,增加了第3个尺度的网络,提出了一个统一的多尺度网络框架,采用多任务联合训练的方法分别将其用于深度估计、表面法向量估计、语义分割3个任务中;2016年,LAINA等[13]提出了一种基于残差学习的全卷积网络架构用于单目深度估计,利用全卷积网络并结合上采样模块使预测的准确率有了较大地提升;2018年,CAO等[14]从深度信息本身的性质出发,利用深度信息和语义分割信息具有很强的相关性,将深度估计问题转化为像素级的分类问题处理;2019年,HU等[15]提出了一种有效的多尺度特征融合模块,对原有深度图的粗糙边缘进行改进,虽取得了较好的效果,但对于复杂场景仍然存在估计不准确的问题。上述算法的提出极大地促进了深度估计技术的发展,但网络生成的深度图仍存在空间分辨率低、边缘结构信息容易丢失、小目标预测失真等问题。
神经网络中有一系列下采样操作,一定程度上网络的输出降低了图像的分辨率,让输出图像变得模糊。虽然空洞空间金字塔池化(atrous spatial pyramid pooling,ASPP)可以在不改变图像分辨率的情况下有效地获得不同的感受野大小[16-17],但该方法未考虑不同像素特征之间的关系;再者,膨胀卷积核不连续,并不是所有的像素均参与运算,容易忽略某些重要像素点的信息,进而对场景特征提取的不准确,影响后续网络输出的深度效果。最近的相关研究表明,通过将学习机制[18]整合到现有的单目深度估计网络框架中,有助于捕获特征的空间相关性,使得CNN特征提取能力更强,进一步加深了对图像的理解,并取得了较好的效果。
针对上述问题及其研究思路,本文根据单目深度估计问题特性,结合现有的学习机制技术,引入了分层的压缩激励结构块(hierarchical compress excitation,H-CE),对原有的单目深度估计网络进行改进,提出了一种分层压缩激励ASPP的结构块,寻求更好的模型空间依赖性,将空间注意纳入网络结构中,允许网络进行特征重新校准。根据特征的重要程度,网络自行对特征进行合适的放大或缩小,有效地解决了当下ASPP模块存在的图像失真问题。
1 方 法
利用相机采集场景图像时,离相机较远区域的物体会出现拍摄模糊不清的情况,即存在远距离的图像失真问题。利用ASPP可以捕捉不同大小的物体,能够在不改变图像分辨率的情况下有效获得不同的感受野大小。
1.1 网络架构
本文网络模型采用编、解码的方式完成深度估计任务。如图2所示,编码端首先对输入的图像进行特征提取,综合参数量及模型的复杂程度,选择DenseNet-121[19]折中网络作为输入端的特征提取器。然后利用本文提出的分层压缩激励ASPP结构块,保证前面提取的特征能够高效利用。解码端采用上映射的方式让输出的特征图分辨率和网络输入端图像保持一致,通过与编码端的跳跃连接技术优化网络输出。
1.2 构建分层压缩激励的ASPP网络
1.2.1 空洞卷积及感受野
在神经网络中,既要获得图像的全局信息,也要获得局部和细节信息,实现这一关键步骤需要通过感受野来搭建桥梁。感受野越大,意味着可能蕴含更为全局、语义层次更高的特征;反之,值越小则表示其所包含的特征越趋向局部和细节。但是对图像进行卷积处理时,感受野和图像分辨率本身是一对矛盾。为了在保持图像分辨率不变的同时不断扩大其感受野,使用空洞卷积[20]。
1.2.2 H-CE模块
感受野是CNN每一层输出的特征图上每个像素点在原始图像上映射的区域大小,利用感受野的值可以用来判断每一层的抽象层次。本文根据感受野的大小将网络进行分层。H-CE模块的基本构造及其实现过程如图3所示。在经过任意一层卷积或任意一层密集块操作后,就可以构造相应的H-CE层作为特征权重校准。针对网络处于不同的阶段,使用不同的特征权重校准策略。假设H-CE模块的输入特征图的大小为ʹ×ʹ×ʹ,其中ʹ和ʹ分别为宽度和高度,ʹ为特征图的通道个数。经过一个卷积转换操作F,转换后的特征图的大小为××,F转换操作的输入输出定义、每个通道的转换操作分别为
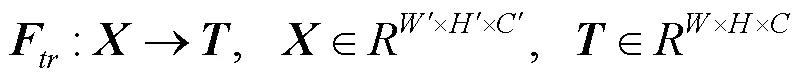
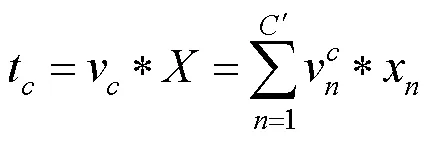

图2 单目深度估计网络架构
H-CE模块的主要计算过程分为3个步骤:
步骤1.压缩操作。用一个全局平均池化操作对特征图由原来××合并成1×1×的形状。由于卷积操作的作用域是针对局部感受野的,因此不能利用卷积核尺寸大小之外的其他区域。图像是有多个通道的,而通道与通道之间又存在一定的依赖关系,因此需要考虑输出特征中每个通道的信号。全局平均池化技术从图像的全局出发,解决了卷积操作无法利用上下文信息的弊端,计算过程为

其中,=[1,2,3,···,t],t和z分别为卷积变换后、压缩操作后第个通道的输出;等式的左边为全局特征压缩变换函数。
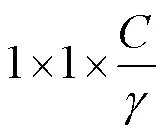

步骤3.利用激励操作得到的激励向量重新加权原特征图,即利用逐元素相乘的方式将最终的输出直接传入后续层。H-CE模块的输出定义为
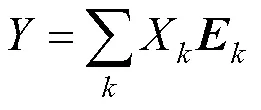
其中,的下标取值遍历了输入特征图的所有通道。
1.2.3 分层压缩激励的ASPP结构块
ASPP结构中卷积的步长设置为={3,6,12, 18,24},针对不同的步长,采用不同的层次化压缩激励策略,总体模块实施方案如图4所示。本文根据感受野的大小及参数设置,将分层压缩激励ASPP分为低级Low、中级Middle、高级High等3个不同层次,分别提取网络对应这3个不同层次逐像素点的图像特征,记为(),()和()。按照提取特征的先后顺序,先将()和()做外积操作,再经过所属层压缩激励的ASPP结构块后,得到这个位置对应的双线性特征0()。将该位置上得到的双线性特征与()做外积,再经过High层H-CE块,此时得到了该位置经过3个不同层次后的最终双线性特征()。为了得到整幅图像的特征,对每个位置得到的双线性特征()求和,采用CLR聚类算法对特征相似类进行聚类。
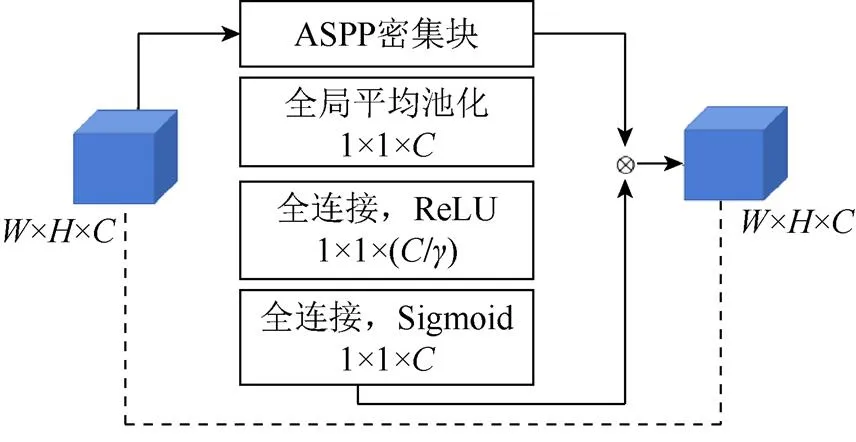
图4 分层压缩激励ASPP密集块下网络实现过程
将训练集的每幅图像看成是一个矩阵,就图像各像素点的局部信息而言,相似性矩阵可以保证样本之间的距离较近;就图像的全局而言,为了能得到全局最优解,需构造一个差值矩阵。首先,先根据CLR聚类算法计算相应2个类之间的权重系数,并按照位置对应关系写入相关矩阵;再从全局出发,计算与该场景相关联的所有类别的权重,得到全局矩阵。将上述2个矩阵作差,得到差值矩阵为
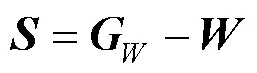
网络中的层次优化问题:分层设计通过差值矩阵的非零行的个数进行约束,同时学习相似矩阵和聚类问题。在网络的低、中、高等3个密集块下,网络的层次优化可以转化为求解最小值问题,即

其中,0为差值矩阵中最小特征值对应的特征向量;为通过该方法设计的网络训练出来的特征矩阵。
在初始化0下,不断地进行循环更新,当与特征矩阵距离达到最小时,记录此时的值。将网络训练得到的送入后端H-CE网络,并有目的地处理这些特征。
由式(5)可知,模块综合了各通道的加权输出,网络根据各通道下的权重自适应选择对其有用的部分,从而模型收敛速度加快,减少了网络运行时间,进一步提高了模型准确性。当输入图像进行第一个步长为3的卷积后,就将其输出结果送入第一个分层压缩激励的ASPP块,此时将其定义网络为起始端,目的是尽可能地让图像在较高的分辨率下提取全局场景特征。起始端后的各层网络都是基于该分层压缩激励的ASPP块的输出信息进行通道间处理,通过拼接技术融合各个阶段的场景特征信息,进一步减少网络丢失特征信息的风险。当图像处理操作分别到达低、中、高等3个阶段后,在每层密集块后,均添加一个分层压缩激励的ASPP模块。当网络处于较低层次时,分层压缩激励的ASPP模块用来学习激励特征,增加待处理图像各通道之间的相互依赖性,增强图像特征共享的能力。网络达到较高层次时,由于提出的模块是在DenseNet-121基准网络上进行的,基准网络到达网络层次的后端时,随着感受野范围的增大,网络可以同时受益于在此之前产生的低层、中层和高层特征,此时分层压缩激励的ASPP模块自适应能力更强,网络累积到后端其特征重新校准的能力也更强。
1.3 损失函数
在网络的训练过程中,大多数目标深度图均丢失一些值,尤其在物体边缘处、弱纹理区域或镜面反射处丢值现象极其明显。本文采用掩膜方法处理这些问题,即通过一个掩膜矩阵,重新计算图像中的每一个像素值,只计算有效点上的损失,忽略无效点的像素。本文结合1.2和1.3节的分析,采用尺度不变误差损失函数[11],利用场景中点与点的相对关系消除尺度不确定性带来估计精度的影响,即损失函数为
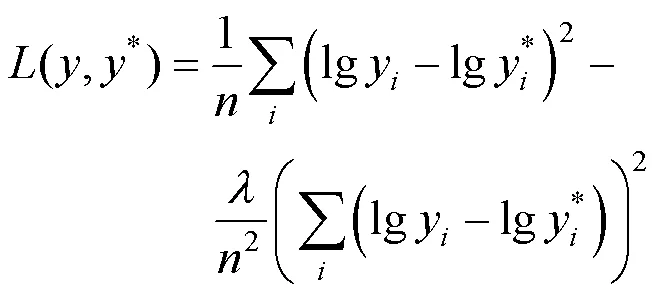
其中,为网络预测得到的深度图;*为地面真值数据,本文网络的输入、输出图像大小均为640×480;和*为图像中每一点的像素值,输出的像素值组成了640×480的矩阵表达形式;为整个图像的像素点数;为尺度因子,其设定为0.5。
2 实 验
2.1 实施细节
运用深度学习的方法训练时,往往需要海量数据,这样才有利于训练出更好的模型。采用数据增强的方式扩充实验的数据集,进一步获得图像的多样性。本文实验操作系统为Ubuntu18.04,算法基于pytorch深度学习框架,网络训练的硬件为NVIDIA Tesla P100 PCIe 16 GB GPUs。选用Adam优化策略优化网络参数,设置优化器的超参数1=0.9,2=0.999,并使用10-4作为权重衰减,训练轮数设为50,批大小设置为3。
2.2 NYU-Depthv2数据集介绍
在一个室内场景重建的RGB-D数据集NYU Depthv2上评估本文方法,NYU-Depthv2数据集包含了40万张大小为640×480的RGB图像、深度图像对,由464个场景组成,这些场景是用微软的Kinect相机拍摄的,官方的分割方法包括249个训练场景和215个测试场景。在本文实验中,对数据集进行了数据扩充,裁剪后的每张RGB图像大小为544×416,然后对其下采样至1/8的全分辨率下作为设计的网络分层压缩激励的ASPP端输入。相应数据集如图5所示。

图5 RGB-D数据集部分图片((a) RGB图像;(b)与RGB图像对应的深度图)
2.3 评估指标
在评估环节,采用深度估计领域公共指标,即平均相对深度误差(Abs Rel)、均方根误差(RMSE)、对数阈误差(lg)、阈值精度(Threshold)分别为
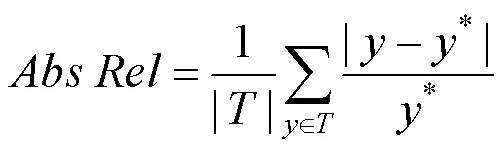
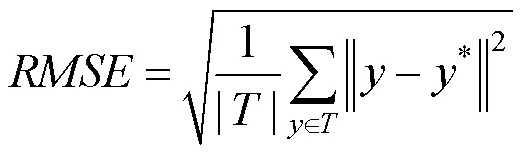

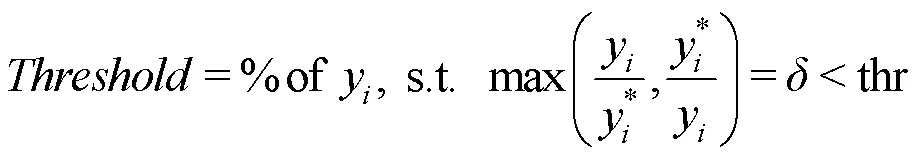
其中,为网络预测得到的深度图;*为地面真值数据;thr为给定阈值,其参数设置为1<1.25,2<1.252,3<1.253。
2.4 消融实验
本文采用网络变量进行评估,验证该核心模块的有效性。针对网络参数问题进行了消融实验,以此保证了网络构建过程中,参数设计的鲁棒性,即参数和网络层数不影响网络的整体有效性。本文解决了参量、计算量这一矛盾问题,如式(6)和式(7)。网络分层设计可以使网络有目的处理提取到的特征,减少了计算的冗余。从仅由基础网络DCNN组成的基线网络开始,逐一添加各模块,以查看添加的模块是否提高深度估计精度。随着模块的增加,整体性能得到了提高,消融实验结果见表1,从网络参数量可见,本文的分层压缩激励ASPP模块虽使网络参数量增加了0.3 M,但第一阈值精度却提升了近2个百分点,其他评估指标均得到了显著地提升。
2.5 实验结果
通过1.1节设计的网络结构,根据2.3节提出的评估指标,得到了各项指标数值,为了尽可能消除实验中所带来的随机误差等影响,本文进行了独立重复10次实验,每次实验后的各指标结果如图6所示。从10次结果来看,本文算法在结果上具有较好的稳定性。取10次后的平均值作为最终评估指标结果,并与当下主流的网络算法进行对比,各项指标对比结果见表2。采用计算机视觉中常用的颜色映射算法jet,对数据集中的深度图以及网络根据RGB彩色图恢复出的深度图进行着色处理,深度估计可视化结果如图7所示。无论从评估指标还是从视觉效果上看,本文算法结果均是理想的。在取得理想效果的同时,还得重点考虑网络的参数量以及单张图像所需的处理时间。在网络训练时间上,本文网络训练50轮所需的时间约为52.1 h,在相同的硬件平台下,文献[17]的网络训练50轮需要约70.8 h,在网络的训练时间上本文算法的优势是明显的。在计算效率上,在服务器端单张图片处理时间约为0.077 s,但在本地笔记本上进行处理就会出现卡顿的情况,离实时处理还有一定的距离。

表1 消融实验结果
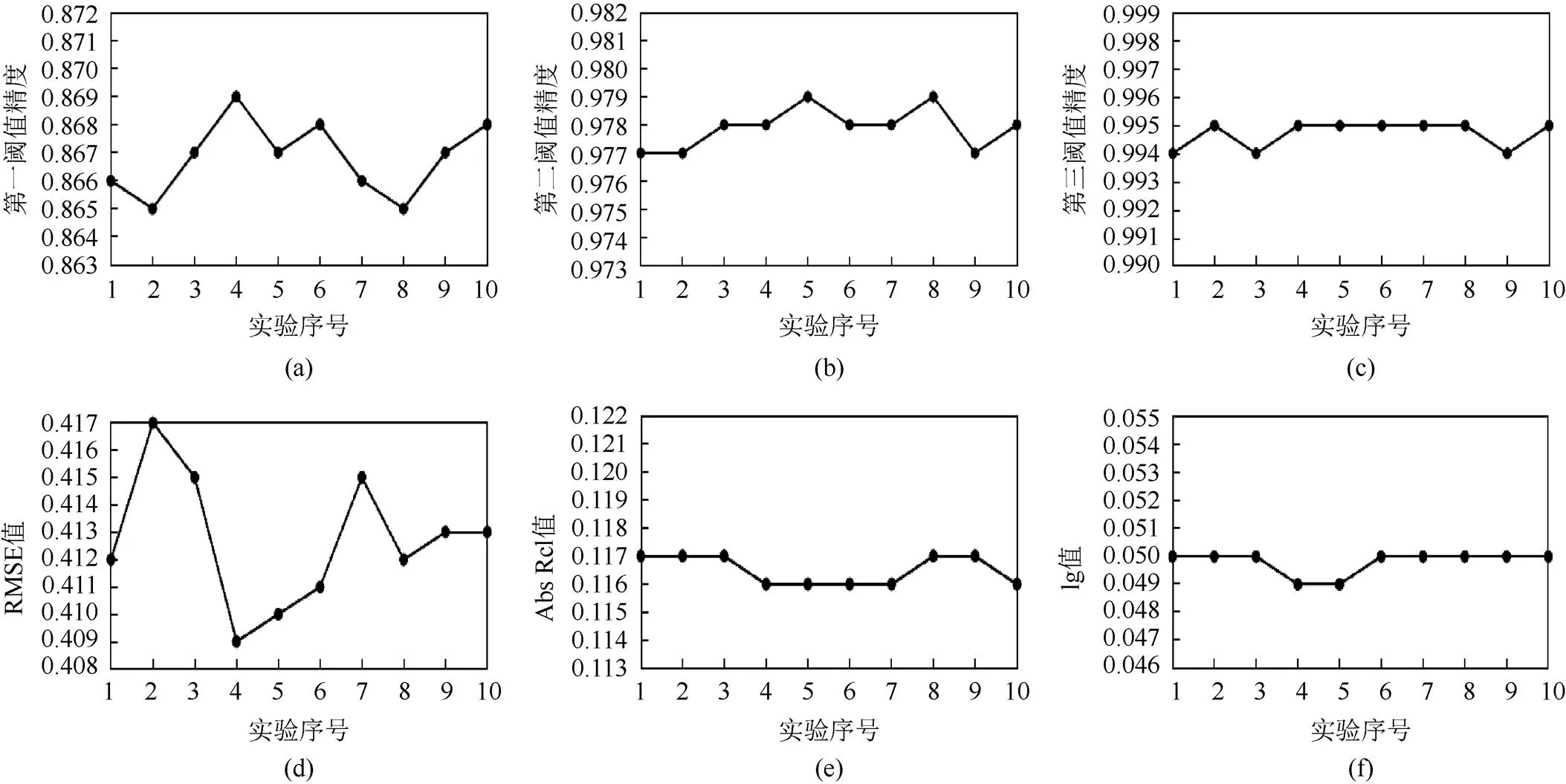
图6 多次重复实验下各项指标数值变化图((a)第一阈值精度;(b)第二阈值精度;(c)第三阈值精度;(d) RMSE数值;(e) Abs Rel数值;(f) Lg数值)
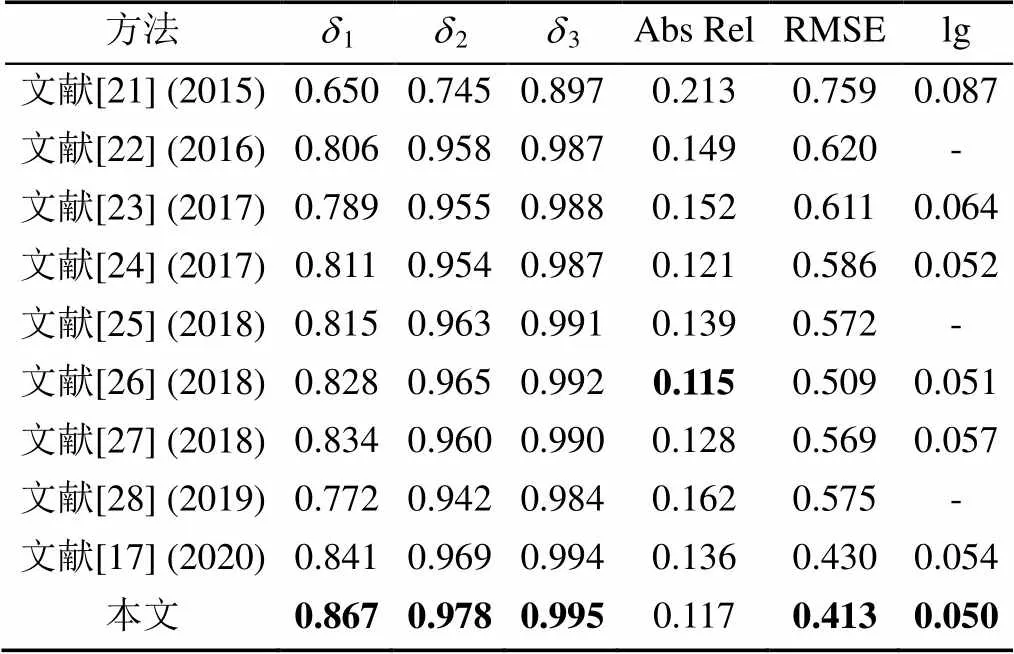
表2 在NYU-Depthv2数据集上与当下主流算法指标比较结果
注:加粗数据为对应指标的最优值

图7 深度估计可视化结果1 ((a)原图;(b)地面真值;(c)文献[17];(d)本文方法)
2.6 讨 论
为验证本文网络的泛化能力,选用实验室现有的Xtion深度相机拍摄教室、图书馆、实验室、书吧、食堂、快递点等场景的RGB-D图,将其送入已训练的网络模型中,输出的可视化结果如图8所示。为了便于直观看出采集数据的质量,对于深度图本文未进行着色处理;可以看出,原始采集的深度信息带有很多空洞,且测量距离受限。为了让读者能够直观看出网络恢复深度的效果,对其进行着色处理。根据热度图颜色与距离关系的变化规律可知,网络恢复的结果符合预期,而且边缘、纹理等细节信息较为丰富,甚至可以精确到图中具体的成像目标。即使硬件设备采集到的深度图质量不佳,网络依然能够根据RGB图恢复其深度图,且恢复出的图像质量比实验中的地面真值更优,进一步体现了本文算法训练出网络模型的有效性。

图8 深度估计可视化结果2 ((a)原图;(b)地面真值;(c)本文方法)
针对本文的实验结果,给出如下分析:首先对数据源头进行分析,数据集在采集过程中难免有抖动的情况发生,这会给数据引入噪声干扰,进而影响网络模型的构建;再从场景环境进行分析,成像设备采集场景图像时往往因不同的光照条件、反射等因素致使网络很难学习其内在特征。如当遇到镜子等玻璃面时,场景中原有的物体会成像,人眼也很难辨认,网络学习出现错误也在情理之中。虽然从特征通道的角度对场景的特征进行考虑,提高网络的全局信息表示能力,但训练出的模型对于复杂环境下仍有提升空间,未来工作的重点将从光照恒常性、相机稳相等角度出发解决深度估计网络学习中存在的问题,让估计更加准确。同时在网络设计上搭建合适的轻量级网络,使处理单张图像的时间加快。
3 总 结
感受野和图像分辨率二者存在着矛盾关系。图像分辨率越高,意味着感受野较小,进而不利于网络更好地学习图像特征等信息。ASPP模块可以有效地缓解这一矛盾,但其卷积核不是连续的,这势必会造成某些像素信息的缺失。本文在原有的ASPP模块上做改进,形成分层压缩激励ASPP网络。结合特征提取模块,使用DenseNet-121紧凑型学习方法,允许其在整个网络上重用特征,两者共同引导网络更好地学习特征图通道间的相互依赖关系,增强卷积特征的学习,使网络能够提高对信息特征的敏感性。通过动态信道特征重新校准策略提高网络的代表性能力,有效地解决了ASPP技术存在的图像失真问题,在本文的单目深度估计结果中取得了较理想的效果。
在本文实验中设计的模块虽使模型参数量略微增加,但却带来了整体深度估计精度的显著提升。通过更加精准地调整超参数和学习率等策略,可以进一步提高分层压缩激励的ASPP网络对场景深度估计的精度。由于单目深度估计问题本身的不确定性和利用深度相机采集场景图作为地面真值具有低质性,致使网络的泛化能力仍有待加强。后期工作的重点将结合现有技术,聚焦于解决尺度模糊问题,并将深度估计结果其后期工作的重点在于其应用于视觉SLAM任务中,实现基于场景感知的智能机器人及时定位、建图和自主导航。
[1] HE L, DONG Q L, HU Z Y. The inherent ambiguity in scene depth learning from single images[J]. Scientia Sinica Informationis, 2016, 46(7): 811-818.
[2] CHENG Y H, ZHAO X, HUANG K Q, et al. Semi-supervised learning and feature evaluation for RGB-D object recognition[J]. Computer Vision and Image Understanding, 2015, 139: 149-160.
[3] XIA Z Y, KIM J, PARK Y S. Real-time 3D reconstruction using a combination of point-based and volumetric fusion[C]// 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems. New York: IEEE Press, 2018: 8449-8455.
[4] 赵妍, 解迎刚, 陈莉莉. 基于SLAM算法的机器人智能激光定位技术的研究[J]. 激光杂志, 2019, 40(7): 169-173.
ZHAO Y, XIE Y G, CHEN L L. Research on robot intelligent laser location technology based on SLAM algorithm[J]. Laser Journal, 2019, 40(7): 169-173 (in Chinese).
[5] YI H W, WEI Z Z, DING M Y, et al. Pyramid multi-view stereo net with self-adaptive view aggregation[C]//Computer Vision - ECCV 2020. Cham: Springer, 2020: 766-782.
[6] BILBEISI G, MALIK J. 3D Hand pose estimation using depth RGB and RGBD images[R]. Rhineland-Palatinate: Technische Universität Kaiserslautern, 2019.
[7] ŽBONTAR J, LECUN Y. Stereo matching by training a convolutional neural network to compare image patches[J]. The Journal of Machine Learning Research, 2016, 17(1): 2287-2318.
[8] GENG M Y, SHANG S N, DING B, et al. Unsupervised learning-based depth estimation-aided visual SLAM approach[J]. Circuits, Systems, and Signal Processing, 2020, 39(2): 543-570.
[9] TANG C, HOU C P, SONG Z J. Depth recovery and refinement from a single image using defocus cues[J]. Journal of Modern Optics, 2015, 62(6): 441-448.
[10] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84-90.
[11] EIGEN D, PUHRSCH C, FERGUS R. Depth map prediction from a single image using a multi-scale deep network[J]. Advances in Neural Information Processing Systems, 2014, 3(January): 2366-2374.
[12] EIGEN D, FERGUS R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture[C]//2015 IEEE International Conference on Computer Vision. New York: IEEE Press, 2015: 2650-2658.
[13] LAINA I, RUPPRECHT C, BELAGIANNIS V, et al. Deeper depth prediction with fully convolutional residual networks[C]//2016 Fourth International Conference on 3D Vision. New York: IEEE Press, 2016: 239-248.
[14] CAO Y, WU Z F, SHEN C H. Estimating depth from monocular images as classification using deep fully convolutional residual networks[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2018, 28(11): 3174-3182.
[15] HU J J, OZAY M, ZHANG Y, et al. Revisiting single image depth estimation: toward higher resolution maps with accurate object boundaries[C]//2019 IEEE Winter Conference on Applications of Computer Vision. New York: IEEE Press, 2019: 1043-1051.
[16] KARSCH K, LIU C, KANG S B. Depth transfer: depth extraction from video using non-parametric sampling[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(11): 2144-2158.
[17] WU K W, ZHANG S R, XIE Z. Monocular depth prediction with residual DenseASPP network[J]. IEEE Access, 2020, 8: 129899-129910.
[18] 刘杰平, 温竣文, 梁亚玲. 基于多尺度注意力导向网络的单目图像深度估计[J]. 华南理工大学学报: 自然科学版, 2020, 48(12): 52-62.
LIU J P, WEN J W, LIANG Y L. Monocular image depth estimation based on multi-scale attention oriented network[J]. Journal of South China University of Technology: Natural Science Edition, 2020, 48(12): 52-62 (in Chinese).
[19] HUANG G, LIU Z, VAN DER MAATEN L, et al. Densely connected convolutional networks[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 2261-2269.
[20] 汪璟玢, 赖晓连, 雷晶, 等. 基于注意力机制的多尺度空洞卷积神经网络模型[J]. 模式识别与人工智能, 2021, 34(6): 497-508.
WANG J B, LAI X L, LEI J, et al. Multi-scale dilated convolutional neural network model based on attention mechanism[J]. Pattern Recognition and Artificial Intelligence, 2021, 34(6): 497-508 (in Chinese).
[21] LIU F Y, SHEN C H, LIN G S, et al. Learning depth from single monocular images using deep convolutional neural fields[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(10): 2024-2039.
[22] CHAKRABARTI A, SHAO J Y, SHAKHNAROVICH G. Depth from a single image by harmonizing overcomplete local network predictions[J]. Advances in Neural Information Processing Systems, 2016, 29: 2658-2666.
[23] LI J, KLEIN R, YAO A. A two-streamed network for estimating fine-scaled depth maps from single RGB images[C]//2017 IEEE International Conference on Computer Vision. New York: IEEE Press, 2017: 3372-3380.
[24] XU D, RICCI E, OUYANG W L, et al. Multi-scale continuous CRFs as sequential deep networks for monocular depth estimation[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 161-169.
[25] LEE J H, HEO M, KIM K R, et al. Single-image depth estimation based on Fourier domain analysis[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 330-339.
[26] FU H, GONG M M, WANG C H, et al. Deep ordinal regression network for monocular depth estimation[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 2002-2011.
[27] QI X J, LIAO R J, LIU Z Z, et al. GeoNet: geometric neural network for joint depth and surface normal estimation[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 283-291.
[28] GUR S, WOLF L. Single image depth estimation trained via depth from defocus cues[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2019: 7675-7684.
Monocular depth estimation of ASPP networks based on hierarchical compress excitation
LIAO Zhi-wei1,2, JIN Jing1,2, ZHANG Chao-fan3, YANG Xue-zhi2,4
(1. School of Computer Science and Information Engineering, Hefei University of Technology, Hefei Anhui 230009, China;2. Anhui Key Laboratory of Industrial Safety and Emergency Technology, Hefei Anhui 230009, China; 3. Hefei Institute of Physical Science, Chinese Academy of Sciences, Hefei Anhui 230031, China; 4. School of Software, Hefei University of Technology, Hefei Anhui 230009, China)
Scene depth estimation is a basic task of scene understanding, and its accuracy reflects the degree of computer’s understanding of scene. Traditional depth estimation employs the atrous spatial pyramid pooling (ASPP) module to process different pixel features without changing the image resolution. However, this module does not consider the relationship between different pixel features, leading to inaccurate scene feature extraction. In view of the disadvantages of the ASPP module in depth estimation, an improved ASPP module was proposed to solve the distortion problem of the ASPP module in image processing. Firstly, the proposed module was added after the convolution kernel. Combined with the relationship between the features of each pixel, the method of enabling the network to adaptively learn the part of interest can effectively extract the features accurately according to the given image. Then the problem of network hierarchy optimization was solved by constructing difference matrix. Finally, the depth estimation network model was built on the indoor public dataset NYU-Depthv2. Compared with the current mainstream algorithms, the algorithm can achieve good performance in both qualitative and quantitative indexes. Under the same evaluation index, compared with the most advanced algorithm, the accuracy of1threshold is improved by nearly 3%, the root mean square error and absolute error are decreased by 1.7%, and the log domain error (lg) is decreased by about 0.3%. The improved ASPP network model proposed in this paper addresses the problem that the traditional ASPP modules fail to take into account the relationship between different pixel features. It can effectively make the model more convergent, significantly improve the ability of feature extraction, and produce more accurate results of scene depth estimation.
deep learning; convolutional neural networks; depth estimation; atrous spatial pyramid pooling; hierarchical design
TP 391
10.11996/JG.j.2095-302X.2022020214
A
2095-302X(2022)02-0214-09
2021-08-31;
2021-11-15
安徽高校协同创新项目(GXXT-2019-003);中央高校基本科研业务费专项(PA2021GDSK0069);安徽省自然科学基金项目(2108085QF286)
廖志伟(1997–),男,硕士研究生。主要研究方向为数字图像处理与计算机视觉。E-mail:Cv17088537@163.com
金 兢(1986–),男,讲师,博士。主要研究方向为计算机视觉、信号处理与分析、SLAM等。E-mail:jjin@hfut.edu.cn
31 August,2021;
15 November,2021
The university Synergy Innovation Program of Anhui Province (GXXT-2019-003); The Fundamental Research Funds for the Central Universities of China (PA2021GDSK0069); Provincial Natural Science Fund of Anhui (2108085QF286)
LIAO Zhi-wei (1997–), master student. His main research interests cover digital image processing and computer vision. E-mail:Cv17088537@163.com
JIN Jing (1986–), lecturer, Ph.D. His main research interests cover computer vision, signal processing and analysis, SLAM, etc. E-mail:jjin@hfut.edu.cn
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
工程与建设(2019年2期)2019-09-02 01:34:14
电子制作(2019年11期)2019-07-04 00:34:38
中国惯性技术学报(2019年1期)2019-05-21 00:58:30
动漫星空(兴趣百科)(2018年4期)2018-10-26 03:40:40
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
北京航空航天大学学报(2017年4期)2017-11-23 05:48:16
中学生数理化·八年级物理人教版(2017年3期)2017-11-09 03:05:29
光学精密工程(2016年4期)2016-11-07 09:05:11
机械工程师(2015年10期)2015-02-02 01:13:47
