
基于轻量化网络的遮挡人脸检测
2022-05-08 03:51:20李文豪周斌胡波张子涵
中南民族大学学报(自然科学版) 2022年3期
李文豪,周斌*,胡波,张子涵
(1中南民族大学 计算机科学学院,武汉 430074;2武汉市东信同邦信息技术有限公司,武汉 430074)
人脸检测是一项非常重要的计算机视觉任务,是目标检测中的一个重要分支[1].基于深度学习的目标检测算法主要分为两类:一类基于区域建议,一类无区域建议.基于区域建议的目标检测算法主要有R-CNN、Fast R-CNN、Faster R-CNN等[2],这类基于区域建议的目标检测算法分为两个步骤,首先会基于目标生成一系列候选框,然后再由卷积神经网络分类和坐标回归.基于区域建议的目标检测算法准确率较高,但模型参数往往过大且实时性也较差.无区域建议的目标检测算法主要有2016年REDMON等[3]提出的YOLOv1,将候选框生成过程和分类回归结合在一起,大大降低了神经网络的计算复杂度,但是相较于基于区域建议的两阶段法在准确率上较低.2017年REDMON等又提出了YOLOv2和YOLOv3算法[4],通过加入先验框,在保证模型推理速度的同时提高了准确率.2020年ALEXEY等人在YOLOv3的基础上引入空间金字塔结构(SPP)、跨阶段残差结构(CSP)等模块提出了YOLOv4,在平均精度均值(mAP)上提升了10%,在检测速度FPS上提升了12%[5].
这些主流的目标检测算法往往需要高算力设备,但移动设备以及嵌入式设备在算力上无法支撑起这类复杂模型,为了设计出能更好满足不同算力设备的高准确率和实时性高的目标检测器,模型缩放技术十分重要[5].最直接的模型缩放技术是改变骨干特征提取网络的深度和卷积层中卷积核的个数,然后训练出适合于不同设备的骨干网络.例如,在ResNet系列网络中,ResNet-152和ResNet-101通常部署在云服务GPU这种超高算力的设备上,而ResNet-50和ResNet-34通常部署在个人GPU上,低端的嵌入式设备通常采用的是ResNet-18和ResNet-10.高阳等人利用多层特征融合使得Faster R-CNN检测精度提升了2.2%[5].鞠默然等人在YOLOv3的基础上将经过8倍下采样的特征层通过上采样连接到4倍下采样特征层,加强模型浅层特征对目标的检测能力[7].邵伟平等人为了实现网络轻量化,将YOLOv3网络的主干特征提取网络替换成Mobilenet,使得模型参数大小降低了90%[8].
近年来,一些精巧设计的网络模型和算子被提出.HOWARD等设计出MobileNets,将卷积神经网络中的普通卷积替换为深度可分离卷积,大大降低了计算量和参数量[9].WANG等人提出了一种新的上采样算子CARAFE,相较于传统以插值为基础的上采样拥有更大的感受野,CARAFE算子使每个像素点能够更好地利用周围的信息[10].CARAFE上采样核基于输入内容上采样,这使得上采样核和特征图的语义信息相关.CARAFE不会引入过多的参数,也不会带来多余的计算量,模型实现更加轻量化.
2017年LIN等人提出了特征金字塔网络FPN(Feature Pyramid Networks),通过将高语义信息的深层特征图通过上采样然后再横向连接到高分辨率低语义的浅层特征图上,加强了模型浅层特征对目标检测的能力[11].但FPN采用的是基于最近邻插值法的上采样,这样会导致每个像素点无法很好地使用周围像素点的信息.MISTRA在2019年提出了Mish激活函数,计算量较LeakyRelu有略微增加,但是在最终精度上比LeakyRelu激活函数提升了1.671%[12].
综合考虑计算量、参数量和模型推理速度,本文在YOLOv4-Tiny的基础上提出YOLO-SD-Tiny,YOLO-SD-Tiny在主干特征提取网络上将第五部分CSP-Body替换成基于Mish激活函数的MCSP-body,将第六部分CBL替换成CBM,使得信息可以更好地深入神经网络.在特征金字塔网络中将基于最近邻插值的上采样替换成基于CARAFE提出的SD(Self-DeConvolution),让每个像素点可以更好地利用周围信息,并且减少计算量和参数量.最终实验结果表明,YOLO-SD-Tiny相较于YOLOv4-Tiny在遮挡人脸数据集OccludeFace上检测速度提升了9.64%,AP提升了4.89%,在准确率和实时性上有一定提升,可以更好地部署于算力较低的设备中,具有工程应用价值.
1 YOLO-SD-Tiny模型
YOLO-SD-Tiny模型图见图1.由图1可见YOLO-SD-Tiny由主干特征提取网络、FPN特征金字塔网络和YOLO Head三部分组成.主干特征提取网络用来提取信息;FPN特征金字塔网络将深层特征图上采样然后横向连接到浅层特征层,增强浅层目标检测能力;YOLO Head部分用来预测.

图1 YOLO-SD-Tiny网络结构图Fig.1 YOLO-SD-Tiny Network structure diagram
1.1 FPN特征金字塔网络
FPN也就是特征金字塔网络,是一种自上而下的特征融合方法[11].特征金字塔网络采用的是自上而下的简单融合,也就是将更抽象,语义更强的高层特征图上采样,将上采样得到的特征图通过横向连接至前一层特征图.在将高层特征融合到浅层特征之后可以帮助浅层特征更好地检测目标.传统的上采样是基于插值法,插值法无法利用特征图语义信息,且感受野也很小.本文在CARAFE的基础上提出Self-DeConvolution,简称SD.SD分为两个模块,第一个模块是上采样核预测模块,第二个模块是特征遍历模块.对于形状为H×W×C的特征输入图F,给定整数上采样率为σ,SD之后会得到一个形状为σH×σW×C新的特征图.对于输出特征图中的某一个点lt=(xt,yt),在输入特征图F中都可以找到一个点l=(x,y)与之相对应,其中x=将l的邻域记为N(Fl,k).
上采样核预测模块中,首先通过1×1卷积将通道数压缩到Cr.接下来通过卷积φ为lt基于输入特征图F预测一个与位置信息相关的核ωlt,在此阶段参数为其中kencoder=karea-1,ωlt的计算如式(1):

然后再将得到的核ωlt通过加权求和算子reshape后得到.最终通过softmax归一化核σH×σW×karea×karea使得核权重和为1.的计算见式(2):

上采样核预测模块整体流程如图2所示.

图2 上采样核预测流程Fig.2 Upsampling kernel prediction process
特征遍历模块见图3.对于在输出特征层(上采样核)的点lt,将其映射回输入特征图对应的点l,取出以之为中心的karea×karea的区域,和预测出的该点的上采样核做点积,得到输出值.相同位置的不同通道共享同一个上采样核.这样对于特征输入图F中的一点l邻域图N(Fl,karea),在l的karea×karea区域每个像素点对输出特征图的贡献不同,基于特征的内容而不是位置的距离.这样特征重组而来的特征图语义可以比原始特征图更强,因为每个像素点都可以关注来自局部区域中相关点的信息.
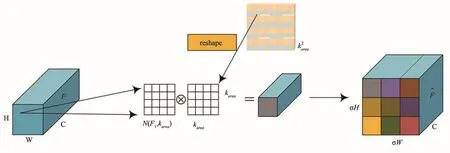
图3 特征遍历流程Fig.3 Feature traversal process
1.2 激活函数
激活函数可以完成神经元输入到输出的非线性变化,对神经网络的训练有重要意义.神经网络常采用的激活函数有Sigmoid、Tanh、ReLU、LeakyReLU等[13],但它们都有一定的缺陷.以ReLU激活函数为例,当输入为负的时候,梯度会变为零,从而导致梯度消失;LeakyReLU激活函数接受负值输入时,允许轻微的负梯度,在一定程度上避免了输入为负所带来梯度消失的影响.Mish激活函数于2019年提出[12],Mish激活函数计算见式(3).
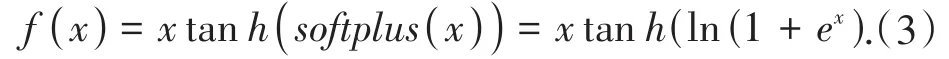
Mish激活函数的取值范围为[≈-0.31,+∞].Mish激活函数与LeakyReLU激活函数曲线的对比见图4.由图4可见,Mish激活函数在取值范围上允许存在轻微负值和没有设置最大值带来了效果更好的梯度流.神经网络的输入在经过平滑的激活函数映射后可以让信息更好地深入网络,得到更好的准确率.
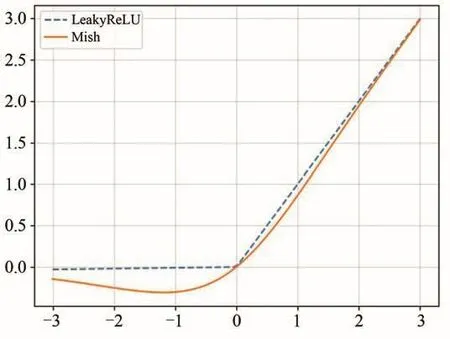
图4 Mish和LeakyRelu的比较Fig.4 Comparison of Mish and LeakyRelu
1.3 损失函数
YOLO-SD-Tiny的损失函数分为三个部分,分别为置信度损失、分类损失和边界框回归损失.采用CIOU损失函数来作为边界框回归损失[5].IOU指的是预测框和真实框的交集和并集的比值,作为边界框回归准确程度的衡量标准[14],IOU,CIOU计算见式(4)和式(5):

其中,B为预测框,Bgt为真实框.

其中,α为权重函数,v是用来衡量边界框的长宽比的参数见式(6):
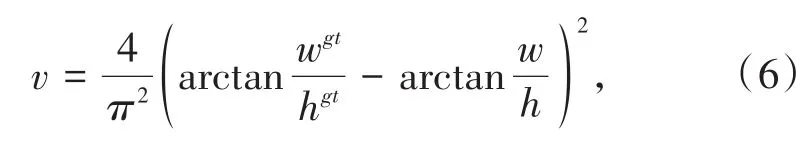
在分类损失方面,引入GHM(gradient harmonizing mechanism)损失用来解决正负样本不平衡的问题和特别难分的样本(离群点)的问题[15].离群点的梯度模长d要比一般的样本大很多,如果模型被迫去关注这些样本,反而可能会降低模型准确率.为了同时衰减易分样本和特别难分的样本提出梯度密度GD(g),计算见式(7):
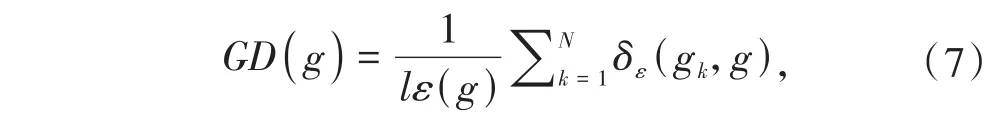
其中,δε(gk,g)表明在样本1-N中,梯度模长分布在范围内的样本个数,lε(g)代表了区间的长度.因此梯度密度GD(g)的物理含义就是单位梯度模长g所处部分的样本总数.接下来,使用交叉熵和该样本梯度密度的倒数作乘法就可以得到GHM损失,计算见式(8):
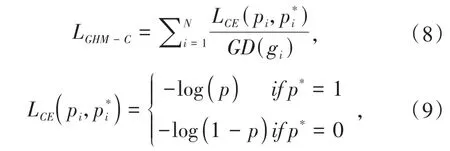
其中N是样本总数,公式(9)是二元交叉熵损失,p∈[0,1]是模型预测的概率,p*∈{0,1}是某个类别的真实标签.
YOLO-SD-Tiny的损失函数在边界框回归损失采用CIOU损失来加快边界框回归速度,在分类损失采用GHM损失来解决正负样本不平衡的问题以及特别难分的样本(离群点)的问题.
1.4 网络整体模型
当以416×416为输入的时候,YOLO-SD-Tiny的整体网络模型见图1.由图1可见,YOLO-SD-Tiny分为三个部分,主干特征提取网络,特征金字塔网络和YOLO Head.主干特征提取网络由两个CBL、两个CSP-Body、一个MCSP-Body和CBM构成.CBL代表卷积(Convolution)、批量归一化(Batch Normalization)和LeakyReLU激活函数,CBM是将CBL中激活函数替换成Mish激活函数.CSP-Body由三个CBL结构和一个Maxpool组成,CSP-Body将上一层传递过来的特征图划分为两个部分,然后通过跨阶段层次结构将它们组合起来.CSP-Body通过残差结构可以增强神经网络的学习能力,在保证神经网络精度不损失的同时减少内存占用以及降低计算量[5].MCSP-Body将CSP-Body中的CBL结构替换成基于Mish激活函数的CBM结构,使得信息更好地流入网络.FPN模块采用SD上采样,减小计算量和参数量.
YOLO-SD-Tiny目标检测整体过程:首先需要用S×S个网格划分输入图像,这S×S个网格中每个网格仅仅负责预测中心点落在该网格中的目标,并计算出3个预测框,每个预测框对应5+C个值;其中,C表示数据集中类别总数,5表示预测边界框中心点坐标(x,y)、预测框宽高尺寸(w,h)和置信度.然后,求解网络预测的类别置信度,其与目标落入网格的概率P(nobject)、网格预测第i类目标的精度P(nclass|nobject)、交并比(IOU)有关,表达式见式(10):
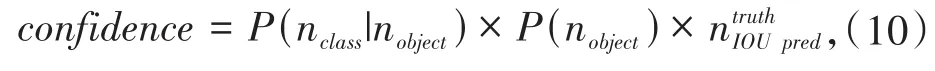
若目标中心落入该网格,则P(nobject)=1,否则为0;为预测框和真实框之间的交并比.最后,使用DIOU NMS[16]筛选出得分最高的预测框作为目标检测框,输出特征图分别为26×26、13×13,从而实现目标的定位和分类.
2 实验与数据分析
2.1 实验数据集
制作OccludeFace数据集基于WIDER FACE[17].根据人密集程度、遮挡程度、背景复杂程度选取1500张图像,然后对采集到的数据样本进行旋转、拼接等数据增广处理,最终获得3000张图像,随机选取90%图像用作训练集,10%图像作为测试集.
2.2 评价标准
当前在目标检测领域有多种性能评估指标,本文采用最为广泛使用的准确率(Precision)和召回率(Recall)来评估模型,计算公式见式(11)、(12):
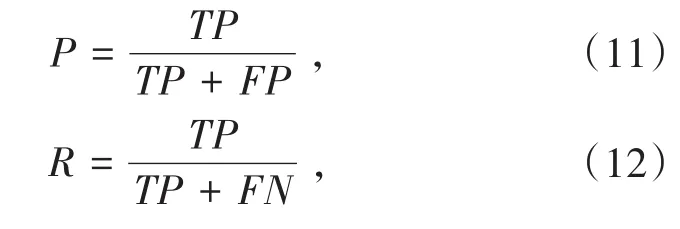
其中准确率P是用来评估预测结果的,式(11)中TP(True Positive)表示模型把正样本正确地预测为正样本的个数,FP(False Positive)表示被预测为正样本的负样本个数;召回率是用来评估样本的,表示的是全部样本中有多少正样本被正确地预测了,FN(False Negative)表示模型把原本是正样本的输入预测为了负样本.
AP表示单个类别在不同置信度阈值下Precision和Recall构成的PR曲线与坐标所围成的面积,综合考虑了准确率和召回率,对单类目标检测的识别效果评价较为全面.FPS为模型一秒可以检测的图像数量,FPS值越大说明模型的检测速度越快.
2.3 实验结果分析
使用Pytorch深度学习框架搭建实验环境,通过RTX2060 6GB显卡进行GPU加速,具体环境如表1所示.

表1 实验环境配置单Tab.1 Experimental environment configuration sheet
迁移学习可以运用已有的知识来学习新的知识,核心问题就是找到已有知识和新知识之间的相似性.在OccludeFace数据集与PASCAL VOC2007[18]数据集之间存在着相似性,因此可以利用PSCAL VOC2007数据集先行训练网络,然后将训练好的参数通过迁移学习的方式运用到OccludeFace数据集上,这样就可以解决OccludeFace数据集数据量较小的问题.具体做法就是将整体网络通过VOC2007数据集训练,然后在OccludeFace训练的时候就可以冻结主干特征提取网络来加快训练速度.
设置输入为416×416,总迭代次数total_epoch为100,冻结主干特征提取网络freeze_epoch为50,冻结训练的batch_size为4,初始学习率lr为0.001,未冻结训练的epoch为50,batch_size为2,初始学习率lr为0.0001.YOLO-SD-Tiny和YOLOv4-Tiny训练loss见图5.

图5 训练损失比较Fig.5 Training loss comparison
将本文算法与YOLOv4-Tiny在数据集OccludeFace上做对比分析.同时对YOLO-SD-Tiny(with MCSP-Body)和YOLO-SD-Tiny(with GHM&CIOU)做消融实验(图6),验证不同模块对模型的影响,实验结果见表2.由表2可见,引入基于Mish激活函数的MCSP-Body相较于YOLOv4-Tiny在AP上提升了0.51%,说明梯度不会消失且平滑的激活函数可以使信息更好地深入网络,从而提升检测准确率.在分类损失部分引入GHM损失和在边界框回归部分引入CIOU损失的YOLO-SD-Tiny相较于原始的YOLOv4-Tiny模型在AP上提升了1.61%,说明综合考虑了重叠面积、中心点和纵横比的CIOU和解决了正负样本不平衡和难分样本的GHM损失可以增加模型的检测准确率.YOLO-SD-Tiny相较于YOLOv4-Tiny在AP上提升了4.89%,检测速度FPS上提升了9.64%.综合表2中各种实验数据对比,可以验证本文所提出的改进方法可以有效提高人脸检测精度和检测速度(图7).

图7 实验检测结果对比Fig.7 Comparison of experimental test results

表2 实验结果对比Tab.2 Comparison of experimental results
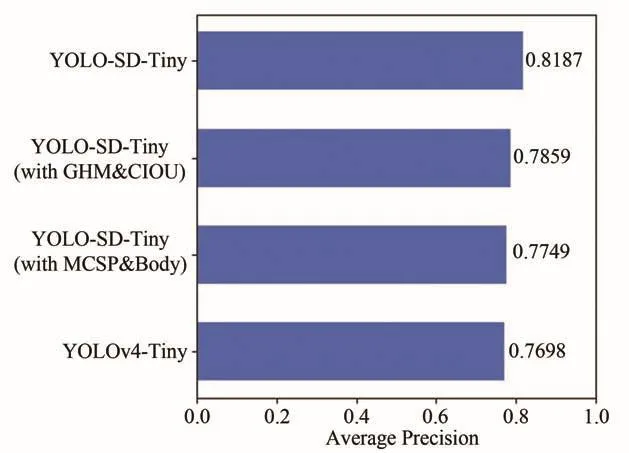
图6 消融实验结果对比Fig.6 Comparison of ablation experiment results
3 结论
本文针对目标检测模型过大而导致在低性能设备上无法部署,实时性差等问题,提出YOLO-SDTiny模型.在主干特征提取网络部分引入基于Mish激活函数MCSP-Body,让信息可以更好地流入网络.在特征金字塔网络部分引入SD模块来加快特征融合的速度和感受野.通过实验结果分析可以看出,在OccludeFace数据集上本文所提出的YOLO-SDTiny相较于YOLOv4-Tiny在AP提升了4.89%,检测速度提升了9.64%,具有一定的工程应用价值.
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
今日农业(2019年15期)2019-01-03 12:11:33
电子制作(2018年19期)2018-11-14 02:37:08
中国交通信息化(2018年5期)2018-08-21 03:37:40
自动化学报(2017年11期)2017-04-04 02:52:58
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
