
基于AdaBoost回归树的电网投资模型设计
2022-04-29 05:02:32杨俊义孙小磊朱前进
粘接 2022年4期
高 骞,杨俊义,洪 宇,孙小磊,朱前进
(1.国网江苏省电力有限公司,江苏 南京 210000;2.国网江苏省电力有限公司连云港分公司,江苏 连云港 222000;3.国网江苏省电力有限公司检修分公司,江苏 南京 210000;4.国网江苏省电力有限公司宿迁分公司,江苏 宿迁 223800)
电网作为一种重要产业,其建设水平高低直接影响了我国国民经济水平的整体发展,电网投资通常会涉及到以下3个环节,分别是各个城市能力评估、确定各个城市发展需求以及国家电网实际发展方向、全面分析和评估各个城市经济效益。在落实电网投资环节期间,相关人员要利用AdaBoost回归树,加强对电网投资模型的科学设计,为实现电网投资的规范化、标准化分配打下坚实的基础。
1 预测模型的总体研究方案
1.1 电网基建投资预测总体思路
为了实现对电网投资模型的科学构建和设计,现提出如图1所示的电网基建投资模型的总体流程图。

图1 电网基建投资模型的总体流程图Fig.1 Overall flowchart of power grid infrastructure investment model
该流程图主要包含以下3个步骤,(1)填补缺失数据,该环节重点解决电网数据缺失问题。在对缺失数据进行填补期间,需要采用正确的填补方法,对运营数据进行一系列的补全处理。对于运营数据而言,主要是由历年各个城市所对应的数据组成,所以,通过利用该填补方法,除了要综合考虑各个城市运营数据外,还要充分结合单个城市所对应的数据特性,只有这样,才能确保补全方法的科学性、有效性和完整性;(2)合理选择若干特征。该环节重点解决影响电网投资指标众多的问题。在对若干个特征进行选择期间,首先,要确保所筛选的特征,对电网投资产生的影响程度较大,该环节需要对所有指标物理含义进行全方位解读,同时,还要全面地考量各个指标对电网投资所产生的影响程度,然后,将最终所选用的运营指标设置为电网投资模型的重要特征;(3)建立电网投资模型。该环节重点解决难以科学构建电网投资预算模型问题。该环节在具体的实施中,首先,要选出合适的模型,然后,根据二次选取特征与电网投资额之间的关系,在充分结合电网实际需求的基础上,对电网投资额进行科学预测,从而保证最终预测结果的精确性和真实性。
1.2 电网缺失数据智能填补研究
数据缺失主要是指在采集数据期间,通常会因为调查失误、机器故障、人工操作不当等原因,造成所收集的数据集缺乏一定的真实性和完整性。数据缺失这一问题具有一定的普遍性,一旦出现这一问题,将会直接影响最终研究结果的精确性和真实性。在处理数据缺失这一问题时,通常需要用到以下填补方法。(1)非聚类算法填补。非聚类算法填补主要是指将上一年缺失数据与下一年缺失数据进行求和,然后,取平均值,并将最终计算结果设置为缺失数据填补值,这种方法尽管操作简单、清晰明了,但是却降低了数据的波动性,无法真实有效地反映出缺失值的变异性特征;(2)聚类算法填补。聚类算法填补方法主要是指从众多的样本数据集中选出一些类,然后,对各自的中心点进行初始化处理,从而得到相应的分类数,然后,精确地计算出所有样本数据点与聚类中心点之间的距离,并将指定的数据点科学地划分到相应的聚类中心点位置处。借助,在充分结合聚类结果的基础上,实现对聚类中心的自动化更新,以达到填补缺失数据的目的。
1.3 电网运营数据特征
对于电网运营数据而言,其特征必须要满足以下3个条件:(1)采用定量分析法,得出各个指标对电网投资额所产生的影响程度;(2)通过根据各个指标的变化情况,对电网投资额变化趋势进行科学的解释和分析;(3)由于运营数据指标分布状态是不断变化的,没有任何规律,所以,要确保所选用的方法无视数据分布规律特征。
2 基于AdaBoost回归树的电网投资模型设计
2.1 AdaBoost算法原理
AdaBoost算法作为一种常用的迭代型算法,主要是在参照Boosting思想的基础上所研发的,该算法除了可以用于分类外,还用于回归,有效地突破Boosting算法的局限性。本文研究的主要是AdaBoost回归问题,因此,现以“AdaBoost回归迭代”为例,构建出如图2所示的AdaBoost算法用于回归流程图。

图2 AdaBoost算法用于回归流程图Fig.2 Flow chart of AdaBoost algorithm used for regression
从图2中可以看出,该回归流程主要包含以下4个环节:(1)在做好对数据集收集和准备的基础上,选用合适的弱回归模型,并确定出相应的迭代次数;(2)对各个样本的权重进行初始化处理,并将总样本数量设置为m,此时,单个样本初始权重为1/m;(3)训练弱回归器。在单次迭代后,需要精确地计算和确定出样本所对应的最大误差,此外,还要做好对单个样本相对误差的精确计算,然后,根据最终计算结果,精确地计算出学习误差率,在此基础上,精确地计算和确定出弱回归器的权重系数,总之,采用环环相扣的方式,根据弱回归器权重系数,对当前样本权重分布情况进行更新;(4)组合形成强回归器。当形成大量的弱回归器后,需要对这些弱回归器进行组合处理,从而形成强回归器。在利用AdaBoost回归树,对弱回归器进行组合期间,首先,要对弱回归器所对应的权重系数进行科学排序,然后,将回归器的中位数设置为相应的强回归器。
2.2 弱回归模型选择
弱回归器算法主要包含以下两种:(1)回归树。回归树作为一种常用的算法,具有较高的启发性,该算法所用到的核心思想是通过利用相关规则,从回归树上的所有节点中选取相应的特征,然后,利用递归方式,完成对回归树的构造。这种算法具有操作高效、计算复杂度低、解释难度低等特点。同时,通过利用该算法,不会对数据提出过高的要求,整体预处理流程比较简单。此外,还要针对所形成的回归树,完成对逻辑表达式的归纳和推导。但是,该算法的使用容易引发拟合问题,而“剪枝”方法的运用,可以有效地避免以上不良问题的发生;(2)支持向量机回归。支持向量机回归(英文简称为“SVR”),该算法仅仅用于回归,在解决非线性问题方面具有重要作用。
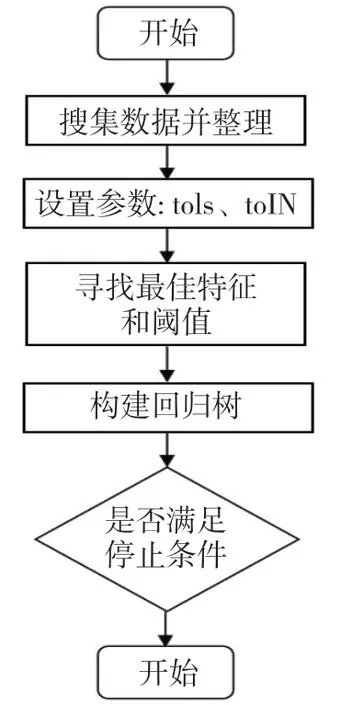
图3 回归树算法流程图Fig.3 Flow chart of regression tree algorithm
2.3 电网基建投资预测模型建立以及优化设计
在AdaBoost回归树的应用背景下,对电网投资模型的实现流程进行详细介绍,AdaBoost回归树的电网基建投资预测模型的流程图如图4所示。
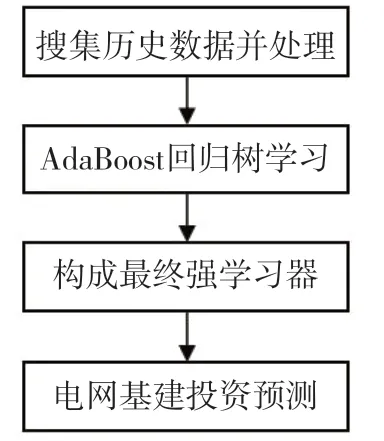
图4 AdaBoost回归树的电网基建投资预测模型的流程图Fig.4 Flow chart of the power grid infrastructure investment prediction model based on AdaBoost regression tree
通过利用AdaBoost回归树,对可能出现的过拟合问题进行预测和分析,并提出相应的解决方案。首先,采用“后剪枝”的方式,对弱回归树进行处理,然后,将样本划分为以下两种类型,一种是训练集,另一种是测试集,利用测试集,完成对回归树的构建,当回归树构建成功后,对其进行剪枝处理,剪枝处理过程如下:(1)当子集上仅仅含有一棵树时,要采用剪枝操作的方式,对该子集进行处理;(2)对所有子集进行合并处理,然后,将合并后的子集全部替代为叶子节点,并对合并后的子集误差值进行科学计算;(3)对没有合并的子集误差进行计算;(4)通过将所有的子集进行合并,以达到缩小误差的作用。
2.4 预测实验结果及对比分析
根据电网运营数据特点,通过利用AdaBoost回归树算法,科学地预测分析电网投资额。在这个过程中,首先,要采用年比例化的方式,精确地确定出电网投资额。同时,采用交叉验证的方式,全面地对比和分析实验结果。即通过科学地预测2020年电网投资额,将2020年以外数据设置为训练集,该训练集含有120个样本;将2019年以外数据设置为训练集,该训练集含有120个样本;将2018年以外数据设置为训练集,该训练集含有120个样本。然后,利用Ada-Boost回归树算法,根据2020年、2019年、2018年各个城市的电网投资额,完成对相应电网投资模型的构建,分别得出如图5、图6、图7所示的AdaBoost回归树“树形图”。

图5 2020年比例化特征生成的AdaBoost回归树Fig.5 AdaBoost regression tree generated by proportional features in 2020

图6 2019年比例化特征生成的AdaBoost回归树Fig.6 AdaBoost regression tree generated by proportional features in 2019
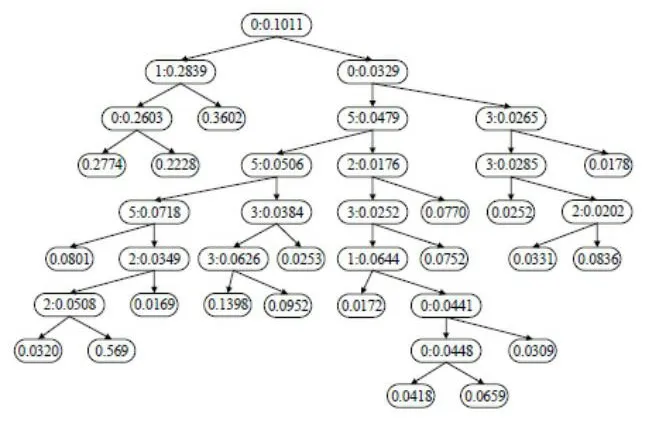
图7 2018年比例化特征生成的AdaBoost回归树Fig.7 AdaBoost regression tree generated by proportional features in 2018
在此基础上,将2020年、2019年、2018年特征分别代入到所生成的回归树模型中,得到如表1、表2、表3所示的预测值。现以2020年AdaBoost回归树“树形图”为例,图5中的各个节点均包含两个信息,一个是特征名,另一个是分类阈值。图5中的顶端节点{0∶0.241 0}表示当特征x值没有超过0.2410时,会自动进入到右子树中,并形成相应的节点{4∶0.046 7},否则自动进入到左子树,形成相应节点{1∶0.283 9}。从图5、图6、图7中可以看出,、、主要集中存在于前两层中,这表明、、三种值对电网投资额存在直接性的影响,其中,特征始终存在于首个分界点,说明特征对电网投资额存在直接性的影响。
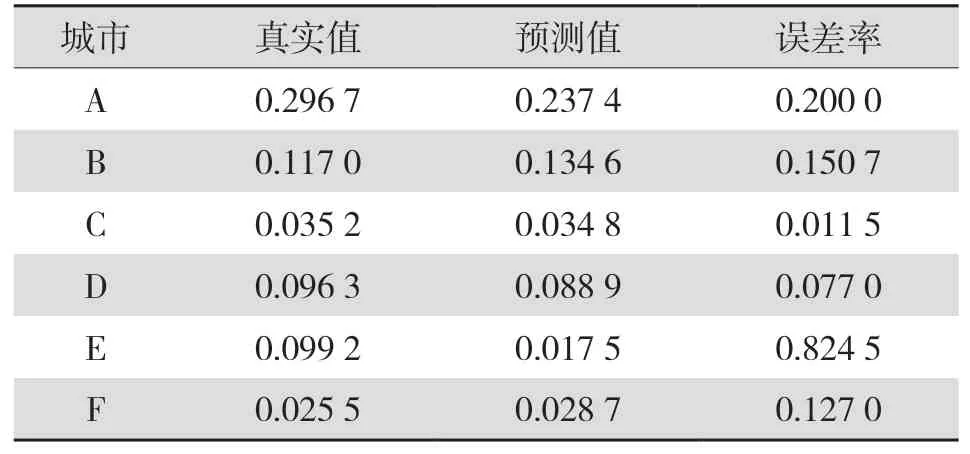
表1 2020年AdaBoost回归树预测结果表Tab.1 Prediction results of AdaBoost regression tree in 2020
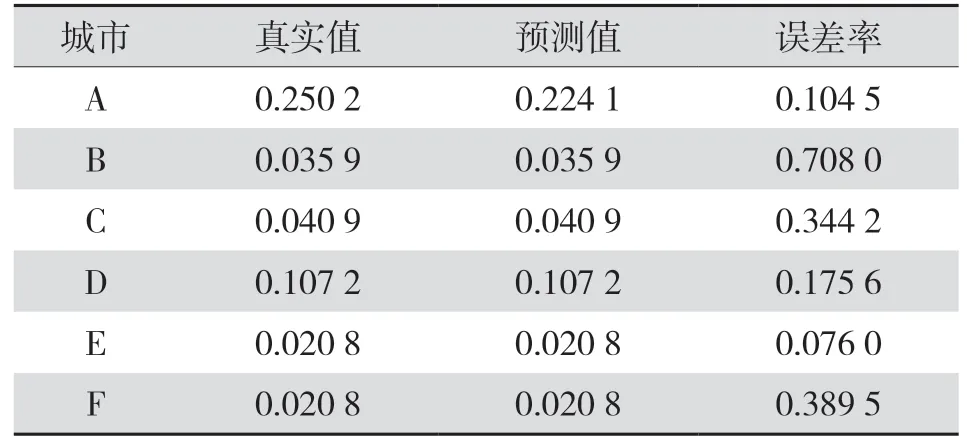
表2 2019年AdaBoost回归树预测结果表Tab.2 Prediction results of AdaBoost regression tree in 2019
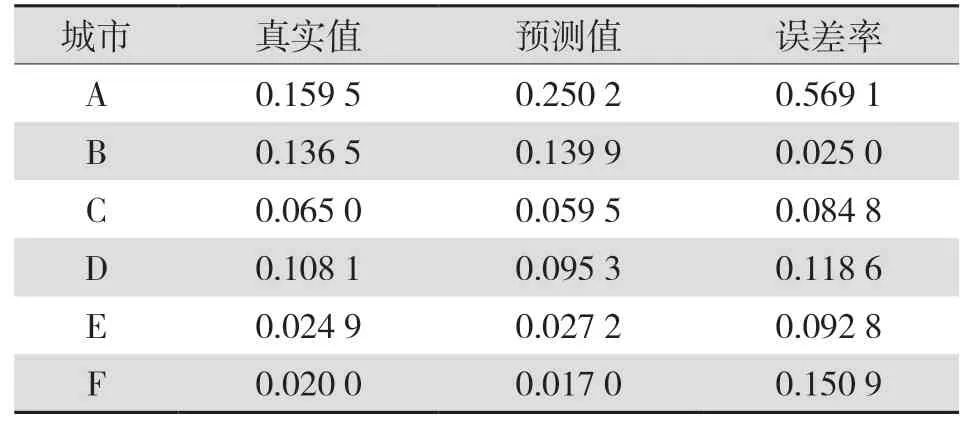
表3 2018年AdaBoost回归树预测结果表Tab.3 Prediction results of AdaBoost regression tree in 2018
从表1、表2、表3中的数据可以看出,在Ada-Boost回归树的应用背景下,电网投资预测结果具有较高的精确性,通过对2020年、2019年、2018年的平均误差进行精确地计算和统计,发现这3个年份的平均误差分别为14.92%、18.41%、18.48%。电网相关专家明确指出各个年份电网投资预测误差低于20%时,才能确保预测结果准确。2020年6个城市所对应的预测误差率均低于20%;2019年6个城市所对应的预测误差率均低于20%;2018年6个城市所对应的预测误差率均低于20%,这表明以上3个年份各个城市所对应的预测准确率较高。
为了更好地验证电网投资模型设计方法的有效性和科学性,现全面的分析和对比特征比例化数据和特征标准化数据,然后,利用AdaBoost回归树,完成对以上3个年份电网投资额与特征的有效建模,并得出相应的“树形图”,从而得出如表4、表5的模型优化前后预测误差对比表、预测结果误差在20%以内的城市个数。

表4 模型优化前后预测误差对比表Tab.4 Comparison of prediction errors before and after model optimization

表5 预测结果误差在20%以内的城市个数Tab.5 Number of cities with prediction result error within 20%
从表4、表5中的数据可以看出,与模型优化前相比,经过模型优化后所获得的3个年份城市平均误差均低于20%,这表明模型优化后可以获取比较良好的预测结果,由此可见,通过利用AdaBoost回归树,对电网投资模型进行优化设计,可以极大地提高模型预测结果的精确性和真实性,这表明本文所设计的AdaBoost回归树模型具有较高的科学性、规范性和可行性。
通过苟家井AdaBoost回归树模型,不仅可以降低以上3个年份的预测平均误差率,提高预测结果的精确性和真实性,还能突出AdaBoost回归树模型的预测准确性高、可解释性强等优势,为进一步提高电网投资模型设计水平,保证电网投资分配的科学性和合理性打下坚实的基础。
3 结语
综上所述,在电力市场体制的不断改革下,电网投资模型设计工作取得了圆满成功,为了实现对电网投资的合理分配,电网企业要在充分结合电网运营数据的基础上,发现电网运营数据在实际运用中,经常出现缺失现象,然后,采用数据填补法,提出一种先进、有效的智能填补方法,该方法在实际运用中,除了综合考虑数据样本与数据特征之间的关系外,还涉及到了时间序列概念,使得填补数据的精确性和可靠性得以大幅度提升。此外,还要针对电网投资实际分配需求,利用AdaBoost回归树,完成对电网投资模型的优化和设计。
猜你喜欢
数学大王·趣味逻辑(2021年11期)2021-12-03 11:04:30
电子测试(2017年15期)2017-12-18 07:19:27
中亚信息(2016年9期)2017-01-18 05:50:04
河南电力(2016年5期)2016-02-06 02:11:32
智能系统学报(2015年4期)2015-12-27 09:38:39
河南电力(2015年5期)2015-06-08 06:01:46
河南电力(2015年5期)2015-06-08 06:01:46
金属加工(冷加工)(2015年22期)2015-04-17 02:10:25
金属加工(冷加工)(2015年16期)2015-04-16 23:54:01
电子设计工程(2015年6期)2015-02-27 12:04:53
