
人工智能支持下基于特征融合的深度知识追踪模型研究
2022-04-28 08:17:30李振周东岱
电化教育研究 2022年4期
李振 周东岱





[摘 要] 精准评估学习者的知识状态是构建自适应学习系统的基石,也是智能教育时代推进个性化学习的根本前提。深度知识追踪模型作为知识状态建模的一种有效方法,已成为教育数据挖掘领域的研究焦点。然而,由于深度知识追踪模型未能将深度学习与领域特征充分融合,导致模型的预测效果不够精准。针对此问题,研究从特征融合的视角出发,提出一种融合测评行为和知识结构特征的深度知识追踪模型。在该模型实现过程中,首先依据xAPI标准对测评行为数据进行采集;然后,采用决策树算法对测评行为特征进行选择,并利用知识传播机制将知识结构融入模型;最后,基于长短期记忆神经网络对学习者的知识状态进行追踪。算法对比实验和实际教学应用效果表明,该模型具有有效性和实用性。该模型在助力核心素养导向的教育评价以及优化智慧学习环境中的智能导学等方面具有广阔的应用前景。
[关键词] 深度知识追踪; 特征融合; 决策树; 知识传播机制; 长短期记忆神经网络
[中图分类号] G434 [文献标志码] A
[作者简介] 李振(1989—),男,山东济宁人。讲师,博士,主要从事自适应学习系统、教育知识图谱、个性化学习路径推荐研究。E-mail:liz666@nenu.edu.cn。
一、引 言
自適应学习系统是信息技术驱动下因材施教和个性化学习理念落地实施的最佳实践,更是智能教育场域中教育服务模式变革和教学提质增效的关键,而学习者模型是自适应学习系统最核心的组件[1]。随着认知理论、情感计算、行为识别等技术的发展成熟,学习者模型已经涵盖知识状态、能力表现、素养发展、情感态度、风格偏好、元认知等多维特征,旨在对学习者进行全方位、立体化、多层次、多模态的建模分析与理解。在学习者模型的多维建构中,精准评估学习者的知识状态依然是自适应学习系统构建的关键,对提升个性化服务质量具有重要意义。
目前,对学习者知识状态进行建模的主流方法是知识追踪模型[2]。该模型的基本思想是:基于学习者外在的、显性的学习表现或行为序列来估测学习者内在的、隐性的知识状态或掌握程度,这已经成为教育数据挖掘领域的研究热点。随着深度学习在图像处理、语音信号处理、自然语言理解、机器自动翻译等领域的广泛应用,以深度学习为基础的深度知识追踪模型成为当前关注的焦点[3]。
然而,深度学习采用的是完全数据驱动的机器学习范式,存在数据依赖性强、模型可解释性差、领域适用性差等弊端。中科院院士张钹教授以及卡内基梅隆大学的Russ教授都曾指出,人工智能将呈现知识驱动与数据驱动相互结合、深度学习与领域特征相互补充的发展态势[4-5]。已有研究也表明,学习者层面的测评行为特征和知识层面的结构特征对于提高知识追踪模型的预测精度有显著影响[6]。因此,本研究以特征融合为切入点,采用决策树、知识传播机制,将测评行为、知识结构特征融入深度知识追踪模型之中,构建融合领域特征的深度知识追踪模型,以期进一步提高学习者知识追踪的效果,为自适应学习系统中的学习者建模提供技术支撑,提升个性化学习的服务质量和学习体验。
二、知识追踪模型研究现状
目前,常用的知识追踪模型主要有两大类:一类是源于心理测量学的项目反应理论模型,另一类是源于人工智能领域的贝叶斯知识追踪模型和深度知识追踪模型。
(一)项目反应理论模型(Item Response Theory,IRT)
项目反应理论也称为潜在特质理论,是现代测量理论的典型代表。该模型认为,学习者的知识状态是一种不可见的潜在心理特质,而这种潜在特质是可以通过测试项目反映出来的,其本质是建模被试能力、题目特性(难度、区分度、猜测系数等)与作答反应之间的关系[7]。
项目反应理论模型是建立在单维性、单调性、局部独立性三个假设之上,需要严格满足以下三个基本条件:一是所有项目都是测量同一个潜在特质,二是项目反应函数是连续、严格、单调的,三是被试在测评项目上的反应是相互独立的[8]。由于这三个理论假设过于严苛,因而不能满足实际应用的需求。此外,以项目反应理论为基础的知识追踪,将学习者的知识状态视为一种概括化的“统计量”,目的在于从宏观层面对学习者进行评估[9],缺乏对知识状态细粒度的评估,也不能实时跟踪知识状态随时间的变化过程。
(二)贝叶斯知识追踪模型(Bayesian Knowledge Tracing,BKT)
20世纪90年代,卡内基梅隆大学的科贝特(Corbett)和安德森(Anderson)两位学者提出了贝叶斯知识追踪模型,该模型以ACT-R 理论和学习过程模型为基础,以概率论和统计学为数学建模思想,针对每个知识组件(概念、原则、事实、规则、技能等)分别建立一个两层的隐马尔科夫模型来评估学习者的知识状态。具体而言,隐马尔科夫模型中的观察层代表学习者的答题表现(答对或答错),隐藏层代表学习者的知识状态(掌握或未掌握),并提取出预知率、学习率、猜对率和粗心率四个关键参数来对该建模过程进行量化[10]。
标准的BKT模型未考虑学习者的个体差异性(先验知识、学习速率等),未考虑学习者对知识结构的短时记忆与遗忘过程,也不能面向多知识点进行应用。因此,许多研究者提出了一些贝叶斯知识追踪模型的变体:(1)学习者个体差异方面,Pardos等人在标准BKT模型中为每个学习者加入不同的先验知识参数,提出了学习者先验知识模型[11];Yudelson等人在标准BKT模型中加入学习者个性差异参数,提出了个性化知识追踪模型[12]。(2)知识遗忘方面,Nedungadi等人将指数衰减函数融入标准BKT模型中来解决遗忘问题[13]。(3)多知识点方面,吴文峻等人使用Logistic回归方法对BKT进行扩展,提出了面向多知识点的改进模型[14]。上述改进虽然取得了一定成效,但贝叶斯知识追踪模型在复杂特征融合、记忆机制等方面存在天然缺陷,因此,无法模拟学习者知识状态的复杂变化过程。
(三)深度知识追踪模型(Deep Knowledge Tracing,DKT)
2015年,斯坦福大学的Piech等人将具有时序建模能力的深度神经网络应用到知识追踪中,提出了深度知识追踪模型。该模型采用丰富的“神经元”来对学习者潜在的知识状态进行建模,克服了BKT模型所存在的缺陷,能对向量化的学习者测评数据进行自动化建模,也能更好地对复杂的学习者知识状态进行预测[15]。
在人工智能与教育教学深度融合的大背景下,深度知识追踪模型的研究吸引了大批来自计算机科学、教育技术学以及心理测量学领域专家的关注。通过文献调研发现,现有研究主要集中在以下几个方面:(1)记忆与遗忘机制优化方面,由认知心理学的基本理论可知,学习者在学习过程中的记忆与遗忘行为是相互交织的,因此,学者们提出了基于学习过程的深度知识追踪模型[16]、融合学习与遗忘的深度知识追踪模型[17]。(2)知识状态显性化方面,由于基于神经网络的深度知识追踪模型采用隐藏层来表示潜在的知识掌握程度,无法实现知识状态的显性化表达,因此,Zhang等人引入静态矩阵(键)和动态矩阵(值)分别存储已追踪的知识点和对应的知识状态,提出了用于知识追踪的动态键值记忆网络[18]。(3)学习者个体差异化方面,由于学习者的学习动机、学习起点、学习情绪等个性特征对学习绩效有显著影响,因此,研究者们将个体的先验知识、个性化学习率、学习情绪、学习态度融入深度知识追踪模型中来获得更加精准的追踪效果[19-21]。(4)预测结果可解释性方面,为了更好地促进深度知识追踪模型的实际教学应用,Lu等人针对深度学习模型的“黑箱”问题,采用相关性逐层传播算法对基于循环神经网络的深度知识追踪模型进行了可解释性研究,并证明了深度知识追踪模型决策的有效性[22]。(5)测评行为特征嵌入方面,Zhang、Yang等人分别提出了基于特征工程和基于决策树的深度知识追踪模型[23-24]。前者需要大量的人工参与和专家知识,而后者能够实现自动特征嵌入。
综合而言,既有深度知识追踪模型的研究在记忆与遗忘机制优化、知识状态显性化、学习者个体差异化、预测结果可解释性、测评行为特征嵌入等方面已取得一定的进展,但已有研究较少关注测评行为特征(学习者层面)和知识结构特征(知识层面)的协同融合问题。因此,本研究以此为切入点,对深度知识追踪模型进行改进优化,以提高模型追踪结果的精准性。
三、基于特征融合的深度知识追踪模型设计与实现
(一)基于特征融合的深度知识追踪模型设计
深度知识追踪主要依据学习者的测评数据来自动化、动态化地追踪学习者知识状态的变化过程,其基本过程可以抽象化地描述为如下形式:假设待追踪的知识状态包含M个知识点,测评题库Q覆盖这M个知识点,t时刻某学习者X所作答的测评题目为qt,作答结果为at(作答正确或错误),则t时刻的作答可表示为xt={qt,at},学习者历史所有的作答序列可表示为Xt=(x1,x2,……,xt),知识追踪模型的目标是利用学习者历史的作答序列来预测下一时刻正确作答题目qt+1的概率,即P(at+1=1丨qt+1,Xt),进而根据题目与知识点之间的关系判断学习者的当前知识状态。
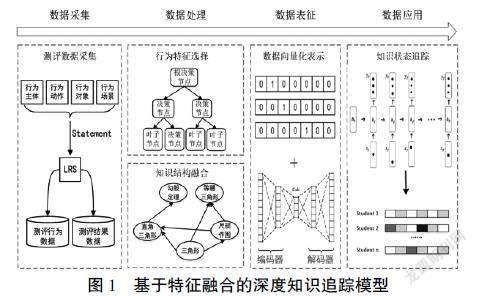
如前文所述,本研究重点关注学习者层面的测评行为特征和知识层面的知识结构特征,将这两方面的领域特征融入深度知识追踪模型中,需要解决两方面的问题:一是测评行为特征的选择问题,二是知识结构的融合问题。对此,本研究引入決策树算法和知识传播机制解决上述问题。在此基础上,按照“数据采集—数据处理—数据表征—数据应用”的思路,设计了基于特征融合的深度知识追踪模型(Deep Knowledge Tracing based on Features Fusion,DKT-FF)。
如图1所示,该模型主要包括测评数据采集、行为特征选择、知识结构融合、数据向量化表示、知识状态追踪五大模块。其中,测评数据采集模块采用xAPI标准对测评过程中的行为数据和结果数据进行获取;行为特征选择模块采用决策树算法评估、筛选有效的测评行为特征;知识结构融合模块采用知识传播机制将学科知识结构特征融入深度知识追踪中;数据向量化表示模块负责将测评过程产生的结果数据、行为数据、知识结构进行向量化,并对其进行降维;知识状态追踪模块通过长短期记忆神经网络追踪学习者的知识状态,并采用学习仪表盘对知识追踪的结果进行可视化呈现。
(二)基于特征融合的深度知识追踪模型实现
1. 基于xAPI标准的测评数据采集
测评数据是指测评活动中所产生的行为数据和结果数据,是学习者知识状态追踪和学习反馈设计的基础,而测评数据采集的标准化是后续处理分析与高效应用的重要保障。本研究参考xAPI标准提出的语义结构,采用“行为主体—行为动作—行为对象—行为场景”模式对测评活动流进行采集。
2. 基于决策树的行为特征选择
特征选择是根据一定的评价标准从全部特征中选取最优特征子集的过程,其目的是使分类、预测等机器学习任务更加精确,泛化能力更强。决策树是大数据时代处理分类和预测问题最常用的机器学习算法之一,具有很强的特征选择能力。因此,本研究采用决策树算法来选取对测评数据具有强分类能力的行为特征。在决策树构建中,非叶子节点分裂是以测评行为特征为条件,叶子节点表示测评结果变量(答对或答错),其过程主要包括以下三个基本步骤:
(1)基尼指数计算阶段
决策树作为一种树形结构,其构建的关键是如何选择节点分裂时的特征。本研究采用信息论中的基尼指数(Gini)作为量化策略对其进行筛选。对于本研究中的测评数据,假设作答行为数据集为D,数据集D中的行为特征集合为A=(A1,A2,A3,……,An),则基于行为特征A对数据集D进行划分后的基尼指数为:
其中,V表示行为特征的取值数量,Dv表示数据集D被行为特征A所划分成的子集。
(2)决策树生成阶段
以测评结果为目标变量,以各类测评行为特征为预测因子,采用“自上而下”的思想,从根节点开始逐层向下选择基尼指数最小的节点进行分裂,递归构建决策树,直至深度达到设定的树深为止。
(3)决策树剪枝阶段
为提高决策树在测评数据上的适应能力、降低过拟合的风险,需通过剪枝操作对其进行优化。剪枝操作的好坏需通过代价函数进行衡量,其目标是使得代价函数最小化。本研究在剪枝过程中采用的代价函数为:
其中,C(T )表示子树T的基尼指数,|T |表示子树T的叶结点个数。
3. 基于知识传播机制的知识结构融合
知识结构融合是指依据测评知识点在网络中的传播机理,将知识点所在的局部网络结构融入知识追踪的过程。本研究基于知识在网络中的传播机制——波纹式传播[25],设计了如图2所示的知识结构融合方法,具体包括知识扩散和知识聚合两个阶段。
知识扩散阶段的过程如下:首先,根据知识追踪所涉及的学科,通过知识抽取、关系挖掘构建学科的知识图谱[26];其次,使用图谱的查询语言在学科知识图谱中定位当前测评题目所考查的知识点(如图中的知识点A和B);然后,在学科知识图谱中分别以A和B为中心点,根据前驱后继关系逐层向外扩散,当涟漪第一次到达新节点时完成一次扩散,接着以这些1阶邻居节点为中心点继续进行第2次扩散,直至达到设定的最大扩散次数n,扩散过程所经过的节点和边一起构成了待追踪知识点的k阶邻居知识结构,记为N(v)。
知识聚合阶段则按照“由外而内”的方向将k阶邻居知识结构信息聚集到当前知识点上。为简化计算过程,本研究采用平均聚合法,对邻居节点每个维度的特征信息取平均值,然后与目标节点进行拼接。假设k表示目标知识点能够聚合的邻接节点跳数,hkN(v)表示第k层中知识点v所有邻居节点的特征信息,hvk表示知识点v在第k层的特征信息,则
其中,MEAN表示平均聚合函数,CONCAT表示拼接函数。
4. 数据向量化表示
深度知识追踪模型一般采用长短期记忆神经网络进行学习,因此,需要将学习者的历史测评数据转换成网络能够处理和识别的形式,即对输入数据进行向量化表示。
针对本研究所提出的模型,其输入数据类别及向量化表示方式如下:(1)测评结果类数据,主要包括题目的编号、题目的作答结果、题目所考察的知识点。对于该类数据,其类型为离散型变量,主要采用独热码形式对其进行向量化。(2)测评行为类数据,包括作答时间、尝试次数、提示次数、作答第一反应等,这些特征依据决策树进行选择,主要选择位于决策树根节点、分叉较早的特征,最后将筛选出的重要特征通过多位0、1编码进行向量化表示。(3)知识结构类数据,即与测评题目知识点相关联的知识结构,该类数据基于知识传播机制进行获取,并结合图嵌入方式进行向量化表示。
多特征数据的向量化表示会带来维数灾难问题,因此,特征降维是DKT-FF模型必不可少的环节。在对多种特征降维方法(如PCA、NMF、tSNE等)进行对比分析基础上,本研究采用自编码器(AutoEncoder)对上述向量进行降维处理[27]。
5. 基于LSTM网络的知识状态追踪
长短期记忆神经网络(Long Short-Term Memory Neural Network,簡称LSTM网络)是人工智能领域解决时间序列问题最常用的深度学习模型[28]。而知识追踪任务的本质是基于测评数据追踪学习者知识状态随时间变化的过程,因此,LSTM网络对于解决知识追踪问题具有较好的适用性。
如图3所示,基于LSTM网络的知识状态追踪包括输入层、隐藏层、输出层。其中,输入层输入的是经过向量化表示和降维处理后的测评数据;隐藏层通过学习、记忆和遗忘机制隐式建模学习者的知识状态与测评数据的关联;输出层输出的是一个与题库知识点数量一致的多维向量,表示下一时刻学习者对各个知识点的掌握状况。LSTM网络的核心是隐藏层中负责记忆管理的记忆单元,每个记忆单元通过输入门、遗忘门、输出门三种门结构来精细调节信息的存入、遗忘、输出。
LSTM网络所具备的追踪能力由各网络层的参数决定,而这些参数需要以测评数据为样本进行训练获得。目前,训练LSTM网络的常用方法是反向传播算法,即将网络的预测值和测评结果的实际值进行比较,将二者的误差从输出层开始反向向前传播,并按照梯度下降法调整各网络层的内部参数,以期使LSTM网络的预测值与真实值之间的差值最小化。在具体计算中,采用下面的损失函数来估算预测值和真实值之间的差异程度:
其中,?詛代表交叉熵损失函数,?啄代表编码方式,a■表示t+1时刻测评结果的真实值,编码向量?啄(q■)表示t+1时刻作答的题目,OT表示长度为知识点总数的输出向量。
四、基于特征融合的深度知识追踪模型
验证实验
为了验证融合领域特征的深度知识追踪模型具有有效性和实用性,本研究依托团队研发的智慧教育云平台,设计并开发了深度知识追踪系统原型(如图4所示),并通过算法对比实验和实际教学应用效果对模型进行了验证。实验对象为使用该系统的X中学初一年级学生,共计208名。
(一)算法对比实验
本研究采集了实验对象在使用深度知识追踪系统过程中产生的测评数据,共计162701条数据记录。按照8∶2的比例将数据集随机划分为训练集和测试集,选取AUC(Area Under Curve)值作为模型的评价指标,将提出的DKT-FF模型与项目反应理论模型IRT、贝叶斯知识追踪模型BKT、原始深度知识追踪模型DKT进行了对比分析,实验结果如图5所示。
从图中可以得出如下结论:(1)源于心理测量领域的IRT模型在预测效果上要优于BKT模型和DKT模型。这是因为IRT模型在预测学生的知识掌握程度时,考虑到了项目的难度、区分度和猜测系数等题目特征,而原始的BKT模型和DKT模型尚未考虑这些特征。(2)对BKT模型和DKT模型进行对比可以发现,DKT模型的预测效果优于BKT模型。这说明采用长短期记忆神经网络的深度知识追踪模型能够更好地学习测评数据的时间序列特征,但DKT模型整体效果稍逊色于IRT模型,究其原因是DKT模型未能充分考虑领域特征和领域知识。(3)本研究提出的DKT-FF模型在本实验数据集上的表现明显优于其他各模型,这表明融合测评行为特征和知识结构特征的DKT-FF模型具有有效性。
(二)教学应用效果分析
教学应用效果分析实验采用对照实验法,将X中学初一年级208名学生随机分成实验组和对照组,实验组使用深度知识追踪系统实时诊断自己的知识状态,而对照组则根据教师反馈判断自己的知识状态。教学应用的实施周期为8周,在第1周开始和第8周结束时,分别对实验组和对照组学生进行前测和后测,通过独立样本t检验和协方差分析,比较两组学生在实验前后的知识水平差异,统计分析结果见表1。
独立样本t检验的结果显示,实验组的前测成绩(83.66)和对照组的前测成绩(84.06)并无显著差异(p=0.462>0.05)。这表明在开展系统的实际应用前,两组学生的知识水平相当,避免了由于学生初始知识水平差异而导致的后测偏差。
协方差分析中,分别以前测成绩和后测成绩为协变量和因变量,判断两组的后测差异。经方差同质性检验,使用协方差分析后测成绩是可行的。协方差分析结果显示,实验组和对照组调整后的均值分别为92.170和85.887,两者相差6.283,两组学生的学习成绩存在显著性差异(p<0.05)。由此可见,使用深度知识追踪系统实时报告学生的知识状态能够提高学生的学习绩效。通过对对照组学生的访谈发现,对照组学生缺少实时的知识状态反馈,在进行补救学习时目标模糊、缺乏针对性,故其学习效率较低、学习进阶缓慢。由以上对比实验可知,深度知识追踪系统对学习绩效具有促进作用,表明本研究提出的改进型深度知识追踪模型具有实用性。
五、基于特征融合的深度知识追踪模型未来应用前景
(一)助力核心素养导向的教育评价
随着学科教学本质的回归,当今世界各国的育人目标体系正经历从“三维目标”到“核心素养”的发展变化过程,教育评价也由传统的知识掌握和能力發展评价向“素养导向、能力为重、知识为基”的评价方向转变。然而,学科核心素养具有内隐性特征,难以通过可观察的外显行为指标进行测量与评价,需要根据学习者在真实情境或模拟情境中解决复杂问题的交互数据进行推断,而深度知识追踪模型为这种表现性评价提供了交互行为特征抽取、问题解决任务追踪以及测评结果推理的能力,对于面向核心素养的教育测量与评价具有重要作用。
在具体操作层面,首先,应厘清学科核心素养内涵及其所包含的知识、能力要素,构建涵盖知识—能力—素养的关系图谱;其次,依据“以证据为中心的设计”理论,按照“任务设计、情境构建、获取证据”的逻辑链条进行测验设计与开发;然后,借助本研究提出的改进型深度知识追踪模型抽取行为特征,进而从评价学习者对学科知识的掌握状态开始,逐步提高层次,推断出学习者学科能力的运用水平、学科核心素养的达成度,最终为学习者提供涵盖知识掌握状态、能力发展状况以及学科素养表现的“学习仪表盘”。
(二)优化智慧学习环境中的智能导学
智能导学是智慧学习环境的基本特征,已成为当前人工智能赋能教育的重要实践场域[29]。智能导学是在融合认知科学理论和人工智能技术基础上,由扮演专家指导者的教学代理或智能体为学习者设计个性化的学习方案,并全过程跟踪学习方案的实施,实时量化分析学习者的过程数据,适时提供个性化的教学指导和有效的助学支架。
一般而言,智能导学的基本体系架构包括学习者知识模型、领域知识模型、适应性指导模型、人机交互模型,而本研究提出的改进型深度知识追踪模型不仅有助于智能导学系统中学习者知识模型的快速、精准构建,而且能够结合聚类分析挖掘出知识之间隐含的语义关系,为领域知识建模打下基础;同时,改进型深度知识追踪模型还具有很好的特征融合能力,为导学系统人机交互模型的行为特征和情感特征提取提供支撑,实现对学习者“知识—认知—情感—交互”多层次的建模分析,进而推动编程教育类、游戏化学习类、STEAM教育类等互动型、情感型智能导学系统的研发和推广应用。
[参考文献]
[1] 李振,董晓晓,周东岱,童婷婷.自适应学习系统中知识图谱的人机协同构建方法与应用研究[J].现代教育技术,2019,29(10):80-86.
[2] 李振,周东岱,王勇.“人工智能+”视域下的教育知识图谱:内涵、技术框架与应用研究[J].远程教育杂志,2019,37(4):42-53.
[3] 朱佳,张丽君,梁婉莹.数据驱动下的个性化自适应学习研究综述[J].华南师范大学学报(自然科学版),2020,52(4):17-25.
[4] 郑勤华,熊潞颖,胡丹妮.任重道远:人工智能教育应用的困境与突破[J].开放教育研究,2019,25(4):10-17.
[5] RUSS S. Integrating domain-knowledge into deep learning[EB/OL]. (2019-04-14)[2021-09-18]. http://www.cs.cmu.edu/~rsalakhu/10 707/Lectures/Lecture_domain.pdf.
[6] 李菲茗,叶艳伟,李晓菲,史丹丹.知识追踪模型在教育领域的应用:2008—2017年相关研究的综述[J].中国远程教育,2019(7):86-91.
[7] 戴海琦,罗照盛.项目反应理论原理与当前应用热点概览[J].心理学探新,2013,33(5):392-395.
[8] 路鹏.计算机自适应测试若干关键技术研究[D].长春:东北师范大学,2012:24-29.
[9] 刘声涛,戴海崎,周骏.新一代测验理论—认知诊断理论的源起与特征[J].心理学探新,2006(4):73-77.
[10] CORBETT A T, ANDERSON J R. Knowledge tracing: modeling the acquisition of procedural knowledge[J]. User modeling and user-adapted interaction, 1995,4(4):253-278.
[11] PARDOS Z A, HEFFERNAN N T. Modeling individualization in a bayesian networks implementation of knowledge tracing[C]//User Modeling, Adaptation, & Personalization, International Conference. Berlin: Springer, 2010:255-266.
[12] YUDELSON M V, KOEDINGER K R, GORDON G J. Individualized bayesian knowledge tracing models[C]//16th International Conference on Artificial Intelligence in Education. Berlin: Springer, 2013:171-180.
[13] NEDUNGADI P, REMYA M S. Incorporating forgetting in the personalized, clustered, bayesian knowledge tracing(pc-bkt) model[C]//International Conference on Cognitive Computing and Information Processing. New York: ACM Press, 2015:1-5.
[14] 徐墨客,吳文峻,周萱,蒲彦均.多知识点知识追踪模型与可视化研究[J].电化教育研究,2018,39(10):53-59.
[15] PIECH C, SPENCER J, HUANG J, et al. Deep knowledge tracing[J]. Computer science, 2015, 3(3):19-23.
[16] ZOU Y, YAN X D, LI W. Knowledge tracking model based on learning process[J]. Journal of computer and communications,2020,8(10):7-17.
[17] 李晓光,魏思齐,张昕,等.LFKT:学习与遗忘融合的深度知识追踪模型[J].软件学报,2021,32(3):818-830.
[18] ZHANG J, SHI X, KING I, et al. Dynamic key-value memory networks for knowledge tracing[C]//International Conference on World Wide Web. New York: ACM Press, 2017:765-774.
[19] SHEN S H, LIU Q, CHEN E, et al. Convolutional knowledge tracing: modeling individualization in student learning process[C]//43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM Press, 2020:1857-1860.
[20] 叶韵.融合学习情绪的学习者知识状态建模及在中学生在线学习中的应用[D].杭州:浙江工业大学,2020:25-28.
[21] 闾汉原,申麟,漆美.基于“态度”的知识追踪模型及集成技术[J].徐州师范大学学报(自然科学版),2011,29(4):54-57.
[22] LU Y, WANG D, MENG Q, et al. Towards interpretable deep learning models for knowledge tracing[C]//International Conference on Artificial Intelligence in Education. Berlin: Springer, 2020:185-190.
[23] ZHANG L, XIONG X, ZHAO S, et al. Incorporating rich features into deep knowledge tracing[C]//ACM Conference on Learning @ Scale. New York: ACM Press, 2017:169-172.
[24] YANG H, CHEUNG L. Implicit heterogeneous features embedding in deep knowledge tracing[J]. Cognitive computation, 2018,10(1):3-14.
[25] 易成岐.社会网络的信息传播机制及控制方法研究[D].哈尔滨:哈尔滨理工大学,2016:33-34.
[26] 李振,周东岱.教育知识图谱的概念模型与构建方法研究[J].电化教育研究,2019,40(8):78-86,113.
[27] 刘思媛.深层稀疏自编码器的人脸识别降维研究[D].西安:西安理工大学,2018:35-44.
[28] SCHMIDHUBER J, HOCHREITER S. Long short-term memory[J]. Neural comput, 1997, 9(8): 1735-1780.
[29] 郑庆华,董博,钱步月,田锋,魏笔凡,张未展,刘均.智慧教育研究现状与发展趋势[J].计算机研究与发展,2019,56(1):209-224.
猜你喜欢
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
成都信息工程大学学报(2018年6期)2018-03-21 05:45:58
软件导刊(2017年7期)2017-09-05 06:27:00
无线互联科技(2017年12期)2017-07-18 17:40:58
科技资讯(2017年11期)2017-06-09 18:28:13
电子技术与软件工程(2017年5期)2017-04-23 23:37:37
现代电子技术(2017年7期)2017-04-14 19:20:42
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
电测与仪表(2016年2期)2016-04-12 00:24:40
