
OGSRN: Optical-guided super-resolution network for SAR image
2022-04-27 08:22:44YanshanLILiZHOUFanXUShifuCHEN
Chinese Journal of Aeronautics 2022年5期
Yanshan LI, Li ZHOU, Fan XU, Shifu CHEN
a ATR National Key Laboratory of Defense Technology, Shenzhen University, Shenzhen 518060, China
b Guangdong Key Laboratory of Intelligent Information Processing, Shenzhen University, Shenzhen 518060, China
KEYWORDS SAR image;Super-resolution;Optical image;Attention mechanisms;Convolutional Nerual Networks (CNNs)
Abstract Although Convolutional Neural Networks (CNNs) have significantly improved the development of image Super-Resolution (SR) technology in recent years, the existing SR methods for SAR image with large scale factors have rarely been studied due to technical difficulty.A more efficient method is to obtain comprehensive information to guide the SAR image reconstruction.Indeed, the co-registered High-Resolution (HR) optical image has been successfully applied to enhance the quality of SAR image due to its discriminative characteristics.Inspired by this,we propose a novel Optical-Guided Super-Resolution Network(OGSRN)for SAR image with large scale factors. Specifically, our proposed OGSRN consists of two sub-nets: a SAR image Super-Resolution U-Net (SRUN) and a SAR-to-Optical Residual Translation Network (SORTN). The whole process during training includes two stages.In stage-1,the SR SAR images are reconstructed by the SRUN. And an Enhanced Residual Attention Module (ERAM), which is comprised of the Channel Attention (CA) and Spatial Attention (SA) mechanisms, is constructed to boost the representation ability of the network. In stage-2, the output of the stage-1 and its corresponding HR SAR images are translated to optical images by the SORTN,respectively.And then the differences between SR images and HR images are computed in the optical space to obtain feedback information that can reduce the space of possible SR solution.After that,we can use the optimized SRUN to directly produce HR SAR image from Low-Resolution (LR) SAR image in the testing phase. The experimental results show that under the guidance of optical image, our OGSRN can achieve excellent performance in both quantitative assessment metrics and visual quality.
1. Introduction
Synthetic Aperture Radar(SAR)is an active microwave ground observation imaging system, which realizes the imaging in the line of sight and azimuth. Due to its inherent advantages such as working all day and all weather, SAR image is widely used in various tasks of the earth remote sensing observation.However,the resolution of SAR image is low due to the limitation of imaging equipment and the interference of irresistible factors,which fails to meet the application requirements in the practice.So how to improve the resolution of SAR image has been a hot topic in the field of SAR image processing.
In addition, enlarging the acquired low-resolution SAR image with large scale factors such as × 8 and × 16 is usually highly demanded in many SAR remote sensing applications such as land classification.Increasing the SAR image resolution with a large scale factor can improve the accuracy of classification. Nevertheless, most existing Super-Resolution (SR)work concentrates on small-scale reconstruction such as × 2 or median-scale reconstruction such as × 4. It is a very challenging problem to reconstruct SAR image with large scale factors due to limited available information from Low-Resolution(LR)image.Moreover,SAR image usually highly suffers from speckle noise and lacks useful high-frequency components.When being reconstructed, many missing details need to recover. Even if the number of LR image increases, reconstructing high-frequency information with large scale factors is also too difficult.The way to address large scale SAR image reconstruction better remains to be explored.
As a matter of fact,High-Resolution(HR)optical image is easier to obtain than HR SAR image. SAR image has a low signal-to-noise ratio and contains less amplitude information than optical image.As a result, the spatial resolution of SAR image is much lower than that of optical image. The existing research has resoundingly studied the relationship between SAR image and optical image to improve the quality of SAR image, for instance, optical-driven SAR despeckling.Considering the discriminative characteristics of optical image,the effective information can also be found for SAR image super-resolution. To our knowledge, establishing the mapping from LR image to HR image is typically an ill-posed problem,especially with large scale factors,which makes it very difficult to find a good solution. To tackle this problem, we introduce an additional optical constraint to reduce the space of possible functions so that the promising SR image can be produced.Ideally, if the mapping from LR image to HR image is optimal,the SR image can be translated to obtain the same optical image that is translated by its HR counterpart.
The existing SAR image super-resolution methods have gone through three stages of interpolation, estimation reconstruction and shallow learning.Recently, Convolutional Neural Networks(CNNs),which have powerful feature extraction and mapping capabilities,have made prominent achievements in the field of SAR image super-resolution.Moreover,the attention mechanism is able to lead the utilizable computing resources to the most informative features effectively as well as optimize the reconstruction process by combining with the network.
Driven by these facts, we propose a new Optical-Guided Super-Resolution Network (OGSRN) to produce highfidelity SR image with large scale factors. Super-resolving is performed in an end-to-end manner, operating exclusively on SAR image. Specifically, the proposed OGSRN consists of a SAR image Super-Resolution U-Net (SRUN) and a SAR-to-Optical Residual Translation Network (SORTN). And the whole training process includes two stages. In stage-1, we obtain the SR image via the SRUN equipped with the proposed Enhanced Residual Attention Module (ERAM).ERAM is constructed to use the effectiveness of Channel Attention (CA) and Spatial Attention (SA) mechanism and strengthen the representation capacity of the network. In stage-2, we first translate the output of the previous stage and its HR counterpart to optical image by the SORTN,respectively. And then the differences between SR images and HR images are calculated in the optical space in order to find effective feedback information for SAR image superresolution. More importantly, since the network weights are optimized by taking into consideration also the guidance of optical image only during the training, we can directly learn from LR image in the testing phase. The contributions of this article are listed as follows:
(1) A novel model for SAR image super-resolution called OGSRN is proposed under the guidance of optical image, which can exploit both the low-frequency information of LR SAR image and the feedback information of co-registered HR optical image during reconstructing even under large scale factors.(2) To produce SR image in the OGSRN, a sub-net named SAR image Super-Resolution U-Net (SRUN) is introduced based on U-net structure, which employs downsampling module to expand the receptive field of the convolutional layer and uses shortcut connections to quickly transmit abundant low-level information shared between LR image and HR image.
(3) To boost the representation capacity of the SRUN, an Enhanced Residual Attention Module (ERAM) is proposed, which effectively integrates two new attention mechanisms: CA and SA mechanisms.
(4) To achieve optical guide in the OGSRN,a sub-net called SAR-to-OpticalResidualTranslationNetwork(SORTN) is designed, which is the first CNNs model specially designed to assist reconstruction of SAR image by translating the SAR image to optical image.
The rest of this paper is organized as follows. In Section 2,we briefly introduce the related work. Section 3 gives the detailed information of OGSRN. Sections 4 and 5 present the experimental results and analysis, respectively. Section 6 summarizes the research findings.
2. Related work
At present, the research of image super-resolution is divided intothreemaintypes:theinterpolation-based,reconstruction-based and learning-based methods. Earlier interpolation-based methods utilized the sampling theory to estimate the unknown pixel, such as bicubic interpolation.However, these methods failed to reconstruct sharp edge details. Later, formulating SR to a degradation process, more useful reconstruction-based methods have been developed through solving the inverse problems. As the deep learning technology develops at a relative rapid speed, learning-based methods can be further divided into two categories: the shallow learning methods and the deep learning methods. The SR algorithms based on shallow learning, such as example learning-based methodand sparse representation-based method,mainly include three parts: the establishment of training samples, model learning and high-frequency information reconstruction. Each stage of this kind of algorithm is designed and optimized independently, which results in the limited ability of feature extraction and expression of the model. SR methods based on deep learning have attracted extensive attention because their emergence makes up for the shortcomings of traditional shallow learning methods. Shi et al.designed an Efficient real-time image Super-resolution sub-Pixel Convolutional Network (ESPCN) by taking the LR image as network input directly and rearranging reconstructed feature maps. Enhanced Deep Super-Resolution(EDSR),proposed by He et al., employed the enhanced residual blocks and scaling technique to increase the model capacity. Ledig et al.presented the very deep residual network for image super-resolution to obtain the pleasing results.Wang et al.proposed the Residual-in-Residual Dense Block(RRDB) to further improve the performance by removing unnecessary batch normalization layers. In addition to focusing on increasing the depth of the network, some other networks, such as Residual Channel Attention Networks(RCAN),achieved impressive SR performance by taking into account the feature correlations in channel dimensions.
The SR of SAR image,because it is necessary to consider the influence of inherent speckle noise of SAR image, has developed from early interpolation and estimation reconstruction to sparse representation.With suitable adjustments in measurement noise covariance and noise covariance processing for intensity estimation framework,Kanakaraj et al.proposed an Adaptive ISUKF to present better performance of SAR image super-resolution.Wang et al.proposed a SAR image super-resolution method based on cartoon-text decomposition framework.Nowadays,deep neural networks have been widely used in SAR image superresolution reconstruction. For example, Wang et al.proposed super-resolution SAR image Reconstruction via Generative Adversarial Network (SRGAN), making a remarkable success both in reconstruction accuracy and efficiency.Zheng et al.proposed Self-Normalizing Generative Adversarial Networks(SNGANs)to achieve SAR image super-resolution reconstruction by introducing scaled exponential linear unit and removing the batch normalization layer after convection.
Although the above algorithms have made excellent improvements in the field of SAR image super-resolution,they still have some shortcomings. For example, with the increase of scale factor, SR performance degrades seriously, which has become the bottleneck of its development. If the scale factor is increased to more than two, the solution space will become extremely large.Theoretically,a large number of HR SAR images can be downsampled to obtain the same LR SAR image.In addition,due to the excessive lack of high-frequency information in lowresolution SAR images, feature extraction and representation have become very difficult, which naturally limits the ability to recover more real and detailed textures.
And most of the above work merely focuses on learning the relationship between LR and HR image pairs from the single SAR image space, which can hardly provide comprehensive information for SAR image super-resolution. In contrast, we additionally learn the relationship between SAR image and optical image and thus take advantage of the feedback information in the optical space to guide SAR image super-resolution.
3. Methodology
The proposed OGSRN includes an SAR image Super-Resolution U-Net (SRUN) and an SAR-to-Optical Residual Translation Network (SORTN).
Specifically, the training of OGSRN can be decomposed into two stages for SAR image super-resolution reconstruction as shown in Fig.1(a),where the black line and blue line denote dataflow in stage-1 and stage-2, respectively. Op_HR and Op_Gen represent co-registered high-resolution optical image and translated optical image by SR image, respectively. In stage-1, we use SRUN to obtain the SR image from the LR image and develop an enhanced residual attention module to strengthen the representation ability of the network. In stage-2, an effective SORTN is built to translate the output of the SRUN to optical image. By computing the difference between the translation result of SR SAR image and the corresponding HR SAR image in the optical space,practical feedback information can be collected to guide the OGSRN to produce high-quality SAR images. And then the optimized SRUN can directly reconstruct HR image from LR image in the testing phase as given in Fig. 1(b).
3.1. SAR image super-resolution U-Net
SAR image super-resolution can be regarded as the mapping from LR image to HR image. In this process, a large amount of low-level information such as structural information is shared between the input and the output. It is a wise choice to transmit abundant low-level information through the shortcut connections,so that the network can concentrate on recovering the lost high-frequency information. With regard to the attention mechanism, it promises stronger adaptability and efficiency in training by recalibrating the obtained feature maps. Therefore, following the principle of U-net,we propose a new SAR image SRUN with an enhanced residual attention module. Next, we describe the network structure and objective function of the SRUN in details.
3.1.1. SRUN architecture
The symmetric architecture of the SRUN is shown in Fig. 2,which is mainly decomposed of downsampling and upsampling modules. Each module contains log(s ) basic blocks,where s is the scale factor. The yellow box represents the feature maps of the downsampling module (left half) while the green box stands for the feature maps of the upsampling module (right half). The corresponding shallow and deep feature maps are concatenated via shortcut connections
Taking × 8 enlargement as an example, the low-resolution SAR image is first sampled up to the target size through an upscale layer that consists of a sub-pixel convolutional layer.And then the initial shallow features Fare extracted via convolutional layers, which can be formulated as follows:

where Irepresents the input low-resolution SAR image,Conv denotes the 3 × 3 convolution operation with the stride of 1, and frefers to the function of upscale layer.
Then the shallow features Fare downsampled thrice in turn. Each downsampling basic module is composed of two 3×3 convolutional layers and a LeakyReLU activation layer,where the first convolutional layer with the stride of 2 is employed to achieve dimensional compression.The first downsampling operation extracts the shallow features Fas follows:
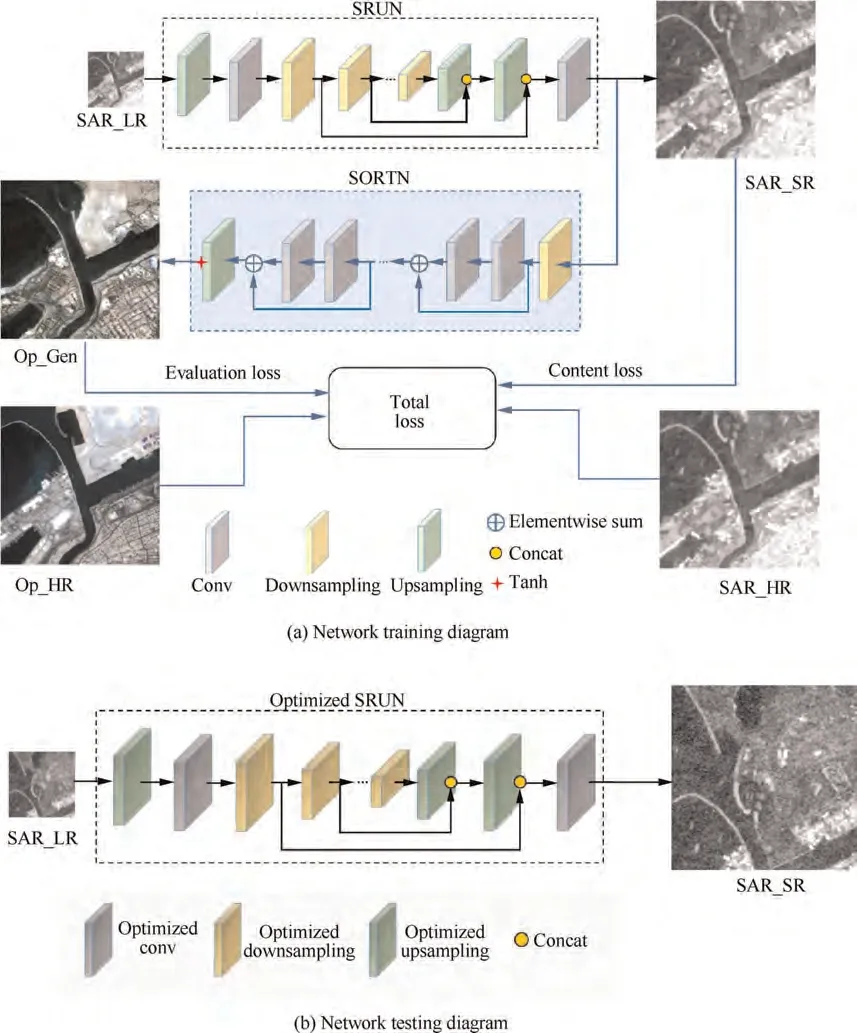
Fig. 1 Overview of the proposed OGSRN.

Next,three upsampling operations are carried out for Fin turn.Each upsampling basic module consists of an upsampler,a 1 × 1 convolutional layer, and R Enhanced Residual Attention Module (ERAM) which is described in detail in Section 3.1.2. ERAM can effectively improve the mapping capability of the network. And the upsampler is built with one sub-pixel convolutional layer to upscale the dimension of feature maps fast.
Except that the input of the first upsampling basic module is the output feature maps of the last downsampling module,the input of other upsampling module is the concatenated result between the output of the corresponding downsampling module and the previous upsampling module. Specifically, the input of the first upsampling operation is the deep features F,and the output is the upsampling shallow features F, which can be formulated as follows:
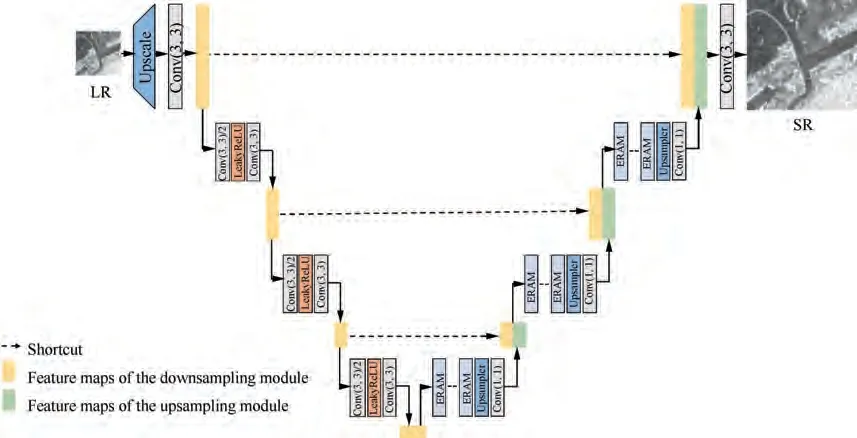
Fig. 2 Architecture of SRUN on × 8 enlargement.


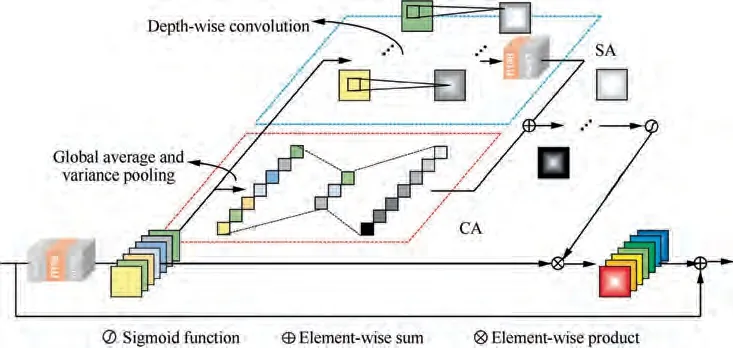
Fig. 3 Structure of ERAM.
where ^Xstands for the recalibrated feature maps by the i-th ERAM, which is the residual component of the input. And where f(·)is the function of fully connected convolution layer,and convdenotes depth-wise convolution with 3 × 3 convolutional layers.
In order to simultaneously utilize the advantages of the above two attention mechanisms, element-wise sum is employed between previous produced CA maps and SA maps.Finally, the results are used to recalibrate the input initial residual feature maps.

where Θ is the parameters of SRUN, and fdenotes the mapping function learned by the SRUN from LR SAR image to HR SAR image.Here,the Lnorm of the objective function is used instead of Lnorm, because the L1 norm has better convergence performance and can tolerate outliers,which contributes to achieving better image super-resolution reconstruction.
3.2. SAR-to-optical translation network
Translating SAR image to the optical space is the key to assist the OGSRN in the training process. The specific explanation will be given in the background. Therefore, we propose a SAR-to-Optical Residual Translation Network (SORTN) to achieve this goal. The background of the SAR-to-optical translation for SR is presented first in this part. Then we describe the network structure and objective function of the SORTN in details.
3.2.1. Background
Given the ill-posed nature of the problem of a single SAR image super-resolution,it is a wise approach to use regularization to constrain the solving space. Mathematically, we can estimate the HR counterpart a of an LR image b as long as the following Maximum A Posteriori (MAP) problem is solved.

From the perspective of the MAP framework,effective regularization term design can limit or reduce the space of possible solution, thereby assisting the SR model to generate highfidelity SR image. Therefore, we propose a new regular term model from image translation. However, it is difficult to directly model this multimodal regularization term via CNNs.The reason is that SAR image and optical image have different imaging mechanisms in the practice. In the next section, we will propose a SAR-to-optical residual translation network to resolve this problem.
3.2.2. SORTN architecture
Recently, conditional Generation Adversarial Networks(cGANs)have shown its powerful ability in learning the translation relationship between multimodal images. Therefore,under the framework of cGANs,we propose the SORTN to learn the translation relationship H(·)between SAR image x and optical image y , which can be formulated as follows:

The proposed SORTN is composed of three parts: an encoding module, a residual module and a decoding module,and its architecture is displayed in Fig. 4.
In the encoding module, a series of layers are employed to downsample SAR image step by step.Then,512 channels with the size of 16 × 16 SAR image coding tensors are output. In this process,the 7×7 convolutional layer is conducted to contain more neighborhood information as well as reduce the interference caused by the speckle noise. After that, SAR image tensors with high-level semantic information and coding expression are obtained.
In the residual module, six residual blocks are adopted to improve the ability of the network, so that the feature coding can be completely translated.Input of this module refers to the coding tensors of the previous SAR image, and the output at the same size with the input will be produced through the mapping.Through this part,the coding tensors are translated from SAR image to optical image.
In the decoding module, deconvolutional layers with the stride of 2 are used to upsample the optical image coding tensors to the same size as the co-registered HR optical image.Then three channel optical image at size 256 × 256 output is generated based on the 512 channel optical image encoding tensors input at size 16 ×16.The 7×7 deconvolutional layer is also applied to consider more information of the adjacent pixel.
3.2.3. SORTN objective function
In order to realize the realistic translating between SAR image and optical image, we take the SORTN as a generator G and introduce a discriminator D named PatchGAN.The task of discriminator is to distinguish the optical samples generated by the SORTN from the real optical samples. If x and y are true SAR and optical image pair, the discriminator should be predicted to be true. If y is generated by the SORTN, the discriminator should be predicted to be false.In this adversarial training, we propose a robust objective function to enable the SORTN to properly translate SAR image to optical image,which can be expressed as

After the optimization of the SORTN,the optimal translation relationship between SAR image and optical image can be obtained.
3.3. OGSRN loss function
Different from the previous work that only learns the relationship between LR image and HR image from a single SAR image space, we propose a novel loss function guided by high-resolution optical image to provide comprehensive feedback information for the super-resolution reconstruction of SAR image.It includes content loss and evaluation loss,which
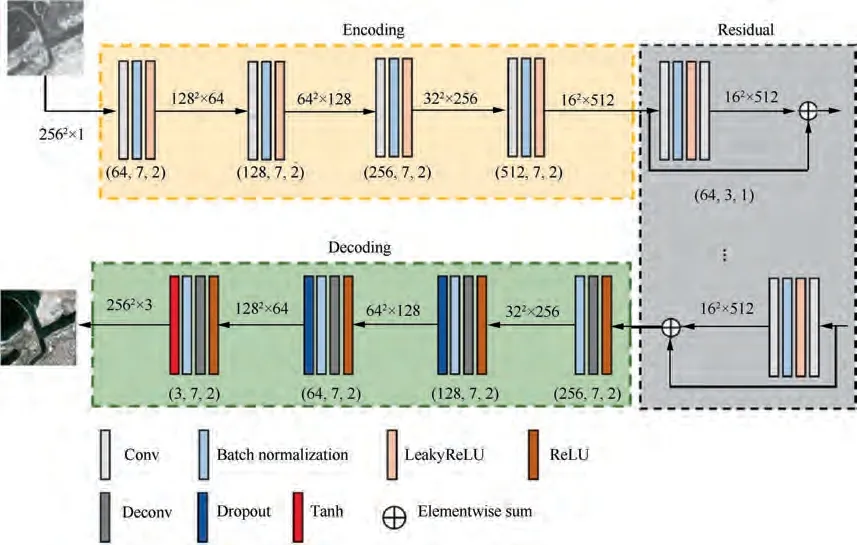
Fig. 4 Architecture of SORTN. The numbers in parenthesis refer to the number of filters, filter size and stride respectively, and the numbers in square brackets indicate the output feature maps dimensions of each module.

where Orepresents the i th optical image in the corresponding scene, and frepresents the translation relationship between SAR image and optical image learned by the SORTN.
Theoretically, if the SR image reconstructed by the SRUN is optimal, ℓshould be very close to ℓ. Therefore, in this paper, a loss function guided by co-registered optical image is additionally optimized to provide effective constraints in finding the best mapping function from LR SAR image to HR SAR image.
4. Experiments
4.1. Datasets
SAR images and the corresponding optical images used in the experiment are all from SEN1-2 dataset,which is a large scale public dataset that collects scenes of SAR images and optical images around the world. In the dataset, SAR images are from Sentinel-1 satellite with the VV channel and optical images come from Sentinel-2 satellite with the bands 4, 3,and 2. In Sentinel-1 data, each item has one channel of 8-bit,256 × 256 pixel images. And their range and azimuth resolutions are 50 meters and 20 meters per pixel, respectively. Similarly,in Sentinel-2 data,each item has three channels of 8-bit,256 × 256 pixel images. Their spatial resolution is 10 meters.The 800 pairs of co-registered SAR/optical images in the‘‘summer” data are selected as the training set and 10 pairs are used as the test set. Some selected images of the dataset are shown in Fig. 5.
4.2. Implementation details
In this section, we first remove speckle noise of SAR images with Block-Matching and 3D filtering (BM3D).Then, we alternately train the SORTN using the PatchGAN with an updated ratio of two. The negative slope of LeakyReLU is set as 0.2, and the Adamis introduced to optimize the SORTN with β= 0.5, β= 0.99. To realize the instancelevel transformation,we set the batch size as 1.And the α corresponding to the Ldistance weight is set to 100.The value of the learning rate in the first 100 epochs is 2 × 10, and this value decreases linearly to zero in the last half of the epochs.And then we apply the well-trained SORTN on SAR images in training set to obtain their corresponding optical images.Next,the HR SAR images are downsampled by bicubic kernel to generate their LR counterparts.And then we take LR SAR images as input and augment the data with random horizontal and vertical flips. Finally, we jointly employ the SORTN and the SRUN to train our OGSRN. Concretely, we train the SRUN from scratch while the SORTN from pre-trained model.We also apply Adam with β=0.9,β=0.99 to optimize the SRUN. The hyperparameter λ is set to 0.1, the basic channel number of feature maps is set to 12,and the number of ERAM is set to 20. The learning rate is initialized to 1 × 10and then reduced to 1 × 10in the manner of cosine annealingand other settings are the same as the SORTN.All experiments are based on PyTorch framework and NVIDIA TITAN Xp GPU.

Fig. 5 Some selected image pairs in SEN1-2 dataset.
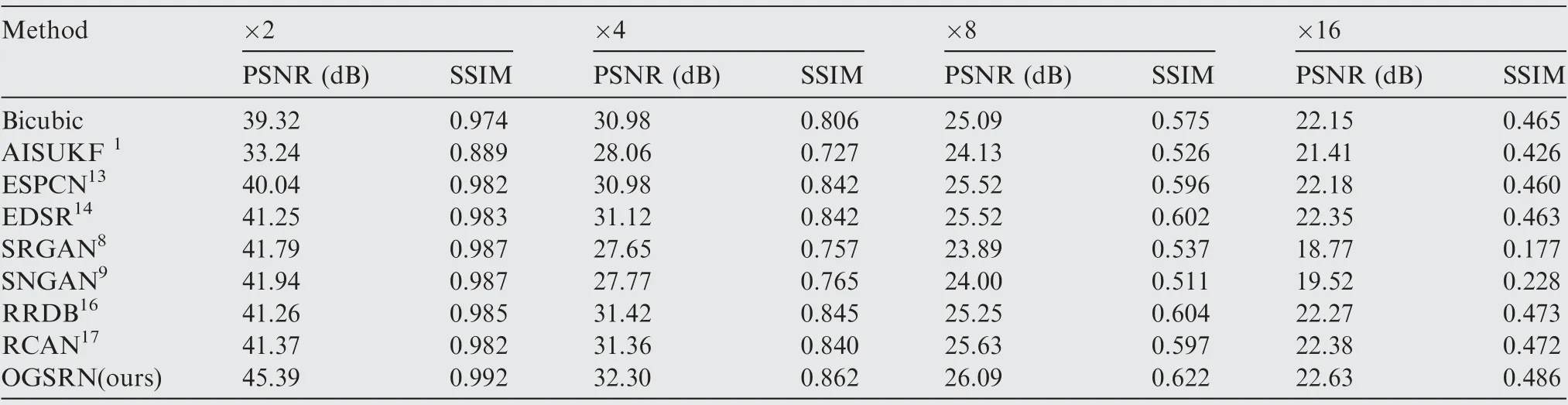
Table 1 Average PSNR and SSIM values of reconstructed HR SAR images obtained by various methods.

Fig. 6 Super-resolved HR images of ‘‘p143.png” using various methods with a scale factor of × 2.
4.3. Evaluation metrics
In the experiments, two widely used image quality evaluation indexes, Peak Signal-to-Noise Ratio (PSNR)and Structural Similarity (SSIM)are employed to assess the performance of SR method. The higher the PSNR value is, the better the quality of the super-resolved image is. And the higher the SSIM value is, the closer the super-resolved image is to the ground-truth image.
4.4. Comparison with the state-of-the-art methods
The proposed OGSRN is compared with the Bicubic interpolation, Adaptive_ISUKF based on improved Kalman filter estimation,as well as several state-of-the-art methods,including: SRGAN,, SNGAN,ESPCN,EDSR,RRDBand RCAN.In the experiment, all the compared methods used their open parameter settings and the same data for a fair comparison.
4.4.1. Objective evaluation
In order to objectively evaluate the SAR image super-resolution performance,Table 1 lists the average PSNR and SSIM values of various SR methods at scale factors of×2,×4,×8 and×16,in which red color presents the best performance of the method while blue color indicates the suboptimal method.

Fig. 7 Super-resolved HR images of ‘‘p142.png” using various methods with a scale factor of × 4.
As shown in Table 1,SR methods based on the deep learning have better performance than the traditional bicubic interpolation method and adaptive_ISUKF based on estimation because all of these models use a well-designed network to learn the mapping relationship between LR image and HR image. However, they only evaluate the loss in a single image space and lack sufficient discrimination, leading to the lack of rich texture details in the reconstructed SAR images and the low objective evaluation values. Unlike these models, when the scale factors are 2,4,8,and 16,the proposed OGSRN outperforms the second-best algorithm by 3.45, 0.94, 0.46, and 0.25 dB in PSNR respectively, and by 0.005, 0.017, 0.018,and 0.013 in SSIM respectively. There are three main reasons for this. First, the SRUN, a sub-net of the OGSRN, has a Unet structure that transmitted directly abundant low-level information shared between input and desired output through the shortcut connections.Second,ERAM is equipped to boost the representation capability of the network. Third, the SORTN, another sub-net of the OGSRN, can provide SAR image reconstruction information feedback in the optical space, which guides the OGSRN to output HR SAR images that are very close to ground-truth.
4.4.2. Subjective evaluation
In Figs. 6-9, we show the visual comparison for ×2, ×4, ×8,and × 16 SR, respectively. The numbers in the bracket refer to the PSNR (dB) and SSIM values of the corresponding result. In order to make a better comparison, we provide a close-up of the area marked by the red rectangle below the counterpart image. Comparison of the ‘‘p143.png” with × 2 enlargement is presented in Fig. 6. It is clear that the texture of bridges of OGSRN is much clearer and closer to the real high-resolution image than the image reconstructed by other algorithms. Fig. 7 shows a comparison of ‘‘p142.png” when the scale factor is set to × 4. It can be observed that the proposed OGSRN has clearer coast line edge in comparison with other algorithms. Fig. 8 displays the super-resolved images produced by various methods for ‘‘p521.png” with × 8 enlargement.Compared with other algorithms,the reconstruction result of the OGSRN is more accurate,such as the geometry of bright spots. A comparison for ‘‘p84.png” with × 16 enlargement is illustrated in Fig.9.The results show that more details can be obtained through our proposed methods.

Fig. 8 Super-resolved HR images of ‘‘p521.png” using various methods with a scale factor of × 8.
Above experimental results show that most existing SR methods cannot accurately recover the details of the SAR image information, especially with large scale factors. However, under the guidance of high-resolution optical image,the proposed OGSRN can reconstruct more accurate highfrequency details on the same test set with the best visual quality.
5. Analysis
5.1. Influence of SORTN on OGSRN
As far as we know, the SORTN is the first CNNs model specially designed to indirectly mine SAR image details from coregistered high-resolution optical image to guide SAR image super-resolution. The SORTN can be used independently or taken as a part of SR models to provide optical space feedback information. A series of ablation analysis is presented to explore the influence of the SORTN in this section.
A single SORTN is trained to observe its ability to translate SAR image to optical image. As shown in Fig. 10, Fig. 10(a)is a real high-resolution optical image of the same scene corresponding to ‘‘p84.png”, and Fig. 10(b) and 10(c) are obtained by translating SR image and HR image to optical image, respectively. As displayed in Fig. 10, the optical image corresponding to the SR image is inferior to that corresponding to the HR image in terms of quality index and visual effect. Inspired by this, the difference between SR image and HR image can be quantitatively calculated in the optical space to reflect the missing high-frequency information of SR image compared with ground-truth HR image.

Fig. 9 Super-resolved HR images of ‘‘p84.png” using various methods with a scale factor of × 16.

Fig. 10 A comparison of optical images obtained by translating SR image and HR image when scale factor is set as × 8.
In this part,we take the SORTN as part of the OGSRN to provide guidance for SAR image super-resolution. To verify the influence of the SORTN, we compare the average PSNR and SSIM values of the SR image produced by the proposed OGSRN and the single SRUN without the SORTN in the training. As shown in Table 2, the PSNR and SSIM values of the single SRUN are not as good as that of the OGSRN, and with the increase of scale factor,the performance of the OGSRN decreases less than that of the single SRUN.All these prove that with the assistance of the SORTN, the SRUN can reconstruct high-quality SAR image that is closer to ground-truth.
To further evaluate the influence of the SORTN on SR performance of the OGSRN, we show the PSNR and SSIM comparison of the OGSRN combined with several general translation algorithms such as CycleGAN,Pix2pix,and SORTN-in Table 3.The SORTN-denotes that we remove the Lnorm constraint in Eq. (18) from the SORTN. As shown in Table 3, the OGSRN combined with SORTN achieved the best performance. The reason may be that,compared with CycleGAN and Pix2pix,it not only has considered the characteristics of SAR image, but also uses a multi-layer residual structure to improve the translation capabilities.And compared with the SORTN-,the SORTN adds Lnorm constraint, which can more accurately translate the rich texture in SAR image to optical space.
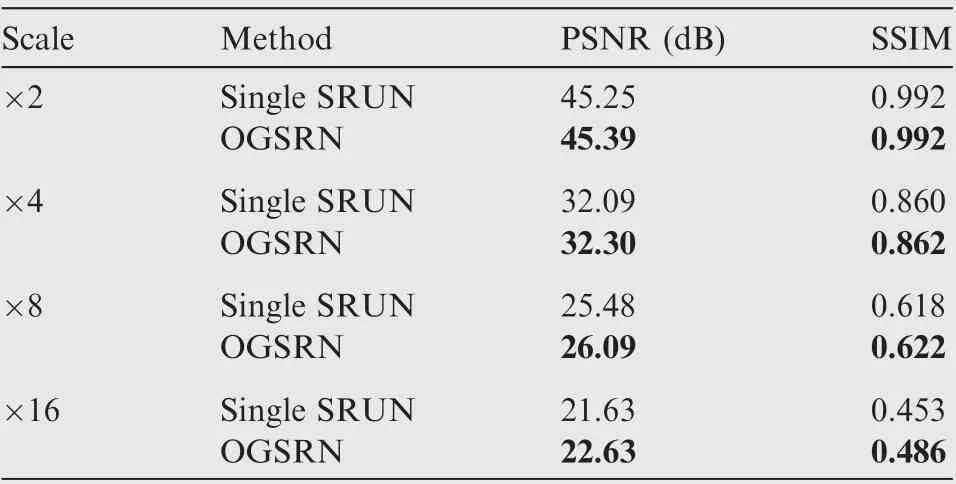
Table 2 Average PSNR and SSIM value by using single SRUN and OGSRN.
These above results reveal that the SORTN is effective and the high-quality feedback information provided by the SORTN can improve the SR performance of the OGSRN.
5.2. Effectiveness of co-registered optical image guidance
To explore the effectiveness of co-registered optical image guidance, ESPCN,which contains only five convolutional layers, takes its role as our benchmark model. Accordingly, a comparison model named ESPCN + SORTN, which intro-duces the optical evaluation in the training, is constructed.Note that when retraining ESPCN + SORTN, we fixed the parameters of SORTN. The average PSNR and SSIM values of ESPCN and ESPCN + SORTN are shown in Table 4.Apparently,the performance of ESPCN+SORTN has made a big improvement compared to ESPCN, which shows the effectiveness of co-registered optical image guidance.
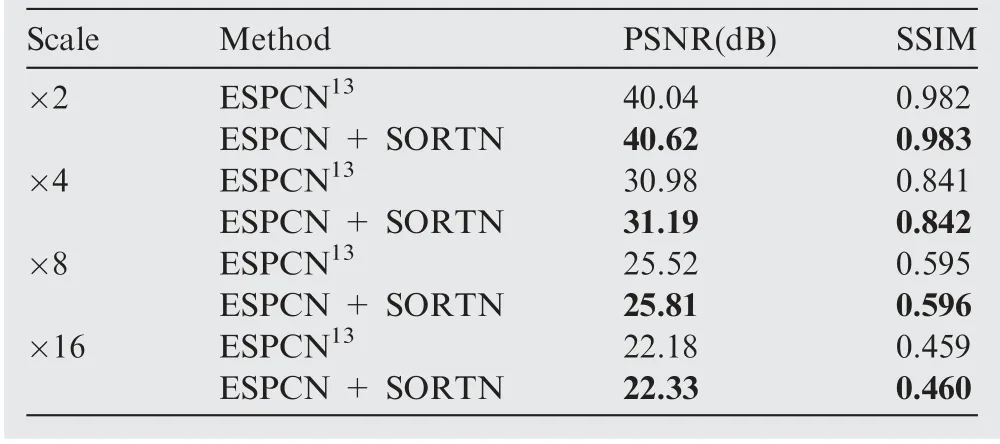
Table 4 Comparison of average PSNR and SSIM between ESPCN13 and ESPCN + SORTN.

Table 3 Comparison of average PSNR and SSIM of OGSRN under the guidance of different optical images obtained by CycleGAN,31 Pix2pix,24 SORTN- and SORTN.

Table 5 Comparison of average PSNR and SSIM of model effect with different values of λ.
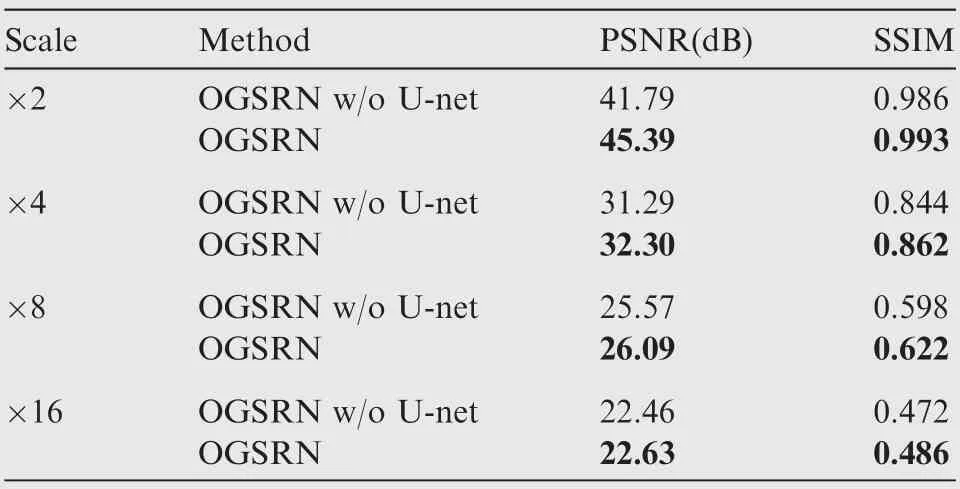
Table 6 Comparison of average PSNR and SSIM of model with and without U-net structure.
5.3. Influence of hyperparameter λ on OGSRN
λ is a hyperparameter utilized to control the composition of the evaluation loss.To explore the influence of hyperparameter λ on the OGSRN, different values of λ are used to train the OGSRN model with various scale factors.As shown in Table 5,when we increase λ from 0.001 to 0.1,the high-frequency information of SAR images fed back from HR optical images becomes more and more important, which can provide a strong supervision for the OGSRN. However, if we further increase λ from 0.1 to 1.0, the evaluation loss would have a negative impact on the original content loss, dragging down the final performance.To obtain the best relative contribution of the evaluation loss, we set λ=0.1 in our final model.
5.4. Effect of U-net structure on OGSRN
One of the differences between the proposed OGSRN and the existing methods is that the U-net structure is applied to our method. To verify the impact of U-net structure on the OGSRN, we compare the average PSNR and SSIM values of SAR images reconstructed by OGSRN, and OGSRN without U-net. The result presented in Table 6 indicates that the PSNR performance decreases sharply when the U-net structure is removed from the OGSRN which verifies the influence of U-net structure.
5.5. Effectiveness of enhanced residual attention module
To evaluate the effectiveness of Enhanced Residual Attention Module (ERAM), we compare it with other attention mechanisms.For the sake of fairness, we implement the various attention mechanisms in each residual block of the same baseline network (OGSRN). Taking × 2 SR as an example, their performance is displayed in Table 7. It clearly shows that,the average PSNR and SSIM performance of OGSRN combined with our proposed ERAM is the best and thus we can confirm the effectiveness of the ERAM.From the comparison of various CA mechanisms’ performance(the third,sixth, and ninth columns of Table 7),it can be proved that the pooling of the squeeze process is effective for SAR image superresolution. In addition, the proposed CA mechanisms which extract channel-specific statistics through using variance and average pooling finally present the best performance. When it comes to the SA mechanisms in the fourth, seventh, and tenth columns of Table 7, evaluation index of our method is higher than that of all the comparison methods.Based on this result, preserving the channel-specific information with depthwise convolution and depth activation is suitable for SAR image super-resolution.

Table 7 Performance of × 2 SR by our proposed ERAM and existing attention methods in terms of PSNR and SSIM.
6. Conclusions
The main conclusions of this article can be drawn as follows:
A new Optical-Guided Super-Resolution Network(OGSRN) for SAR image with large scale factors is presented, giving consideration to both the low-frequency information of low-resolution SAR image and the feedback evaluation of high-resolution optical image.
A sub-net of the OGSRN called SRUN is proposed to establish the mapping relationship from low-resolution SAR image to high-resolution SAR image, which employs U-net structure to make the network focus on recovering the lost high-frequency information.
An Enhanced Residual Attention Module (ERAM) is designed to selectively enhance the feature representation ability for SAR super-resolution, which combines the advantages of the proposed channel attention mechanism and spatial attention mechanism.
Another sub-net of the OGSRN named SORTN is introduced to obtain the guidance information of the optical image, which translates the SAR image output by the SRUN and the corresponding high-resolution SAR image to the optical space respectively.
Experimental results on public SEN1-2 dataset well demonstrate that the proposed OGSRN has better performance in both quantitative index and visual quality compared to the state-of-the-art SR algorithms.
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
This work was supported by the National Natural Science Foundation of China (Nos. 61771319, 62076165 and 61871154), the Natural Science Foundation of Guangdong Province, China (No. 2019A1515011307), Shenzhen ScienceandTechnologyProject,China(Nos.JCYJ20180507182259896 and 20200826154022001) and the otherproject(Nos.2020KCXTD004and WDZC20195500201).