
德国通用科研数据基础设施项目GeRDI 的建设与启示
2022-04-26 12:29:48王彦兵
农业图书情报学刊 2022年3期
王 敬,王彦兵
(1.中共安徽省委党校(安徽行政学院)图书和文化馆,合肥 230022;2.山东第一医科大学(山东省医学科学院)图书馆,泰安 271016)
1 引言
数据密集型科学的兴起加速了科研数据的产生,科研数据在增加科研成果的透明性以及可重现方面扮演着重要角色,已经成为科学界“一等研究公民”。对科研数据进行获取、组织、管理与分享已经成为科研周期中不可或缺的重要活动。许多国家科技部门和科研机构通过建立科研数据基础设施 (Research Data Infrastructures,RDI) 来实现对科研数据的管理、共享与重用。RDI 是一个包含软件与硬件,支持科研数据分享与重用,促进全球科研合作,加速科学创新的数据生态系统,是当今数字化科研得以高效运转而不可或缺的支撑性基础设施[1]。早在2010 年2 月欧盟委员会“第七框架计划” 就资助了GRDI2020 项目[2],用以指导欧盟构建一个可以支持数据共享与合作的全球化科研数据基础设施。2016 年4 月,欧盟委员会又资助了欧洲开放科学云计划(European Open Science Cloud Initiative,EOSCI)[3]旨在推动欧洲成为科研数据基础设施的全球领导者,为欧洲科研人员提供用于存储、分享、分析与利用科研数据的虚拟环境,促进跨学科研究。在此背景下,德国国家基金会于2016 年资助了通用科研数据基础设施 (Generic Research Data Infrastructure,GeRDI) 项目,资助金额达300 万欧元,并将其作为实施EOSCI 的一部分[4]。在政策、标准上,GeRDI 与EOSCI 所实施的开放科学云政策和云设施建设软件与服务标准保持一致,如遵守FAIR 数据准则(可发现、可获取、可互操作和可重用)[5,6]和《科学出版物和科研数据开放获取管理指南》(Guidelines on Open Access to Scientific Publications and Research Data)[7]等。在具体实现技术上,GeRDI 使用自包含系统 (Self-Contained System,SCS) 和微服务架构进行软件架构的设计。该框架具有良好的扩展性和灵活性,可以便捷的将新功能以SCS 的方式添加至GeRDI,也可以对现有的服务功能进行删除、修改。该架构方案的设计理念与EOSCI 的目标一致,有利于未来和EOSC 进行深度融合。
GeRDI 是一个针对长尾科研数据的分布式、联合的科研数据基础设施,它基于现有的数据知识库,旨在构建一个虚拟、分布式的科研数据管理系统。GeRDI 的目的是帮助德国所有科研人员,特别是那些拥有长尾科研数据的科研人员存储、分享以及重用符合FAIR 准则的不同学科领域科研数据。GeRDI 的总体目标是:①基于开放的标准,使用注册、协议、元数据模式等方法来连接独立分布的科研数据知识库;②为创建独立分布、基于特定社区的数据知识库提供相关咨询和软件设计与开发支持;③为所有已连接数据知识库提供具有语义搜索能力的数据获取入口。
笔者使用文献调研和网络调研方法,以“通用科研数据基础设施” 和“GeRDI” 为关键词检索中、英文文献,并从GeRDI 网站获取项目建设相关资源,对项目的建设模式和服务功能进行全面调研。通过文献调研发现,国外学者主要侧重从软件工程设计、系统架构以及软件的可持续性等技术角度对GeRDI 软件系统的建设展开研究[8,9],也有学者探讨了使用GeRDI 对跨学科海洋渔业数据进行搜索与分析,侧重于GeRDI的应用研究[10]。国内学者王敬、王彦兵从发展历程、框架模型和实践状况对国外科研数据基础设施进行了调研和分析[1];章昌平、米加宁提出了社会科学研究与数据管理组合生命周期模型和社会科学科研数据基础设施框架模型,并对上述两个模型框架实施需要的保障条件进行了论述[11]。
已有研究尚未有从GeRDI 项目的组织模式、设计原则、元数据模式以及软件架构等多个维度对其成功建设经验进行分析与总结,本文研究期望能为中国科研数据基础设施的建设和发展提供策略参考。
2 GeRDI 的组织模式
2.1 GeRDI 的组织架构
GeRDI 由德国国家基金会(DFN) 资助,4 个机构参与合作开发,分别是德国国家经济图书馆(莱布尼兹经济信息中心,ZBW)、巴伐利亚科学与人文学院莱布尼兹超级计算中心(LRZ)、德累斯顿工业大学信息服务与高性能计算中心(TUD) 以及克里斯蒂安-阿尔布雷希茨大学软件工程团队 (CAU)[12]。其中DFN 和ZBW 负责整个项目的管理、协调与监管。大约有28 个不同领域专业人员合作开发GeRDI 软件系统。GeRDI 项目下设指导委员会、咨询委员会和用户委员会3 个专业委员会。指导委员会主要为GeRDI 项目期间所面临的战略议题提供指导与决策支持,由分别来自每个参与机构的5 名高级别专家组成。咨询委员会为GeRDI 的开发提供有价值的观点、视角以及战略建议,其成员由研究人员、政策制定者以及其他相关科技人员组成,共计11 名。用户委员会是获取GeRDI 项目建设反馈的重要机制之一,由来自科研社区和数据知识库的8 名代表构成。作为利益相关者与GeRDI 团队之间的纽带,用户委员会将有助于不同信息和思想的交流,可以将用户在科研数据管理过程中的需求和问题反馈给GeRDI 团队。5 个机构在项目不同开发阶段中的分工如图1 所示。
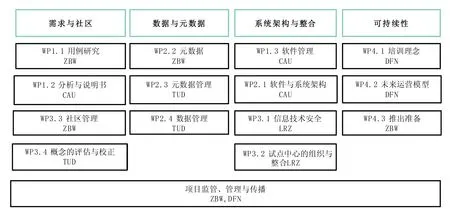
图1 5 个机构在项目不同阶段中的分工[13]Fig.1 Project management and dissemination of five institutions
2.2 GeRDI 的服务模式
为了保障GeRDI 项目资助结束后的可持续性运营,GeRDI 提供了3 种计划服务场景。场景一,提供GeRDI 服务时收取服务费,针对大部分潜在的用户。场景二,将GeRDI 作为现有项目欧洲开放科学云科研数据管理模块中不可或缺的一部分,在此场景下,GeRDI 将从其它项目的运营模式中获取相应的收益。场景三,探索将GeRDI 作为开源项目,免费提供给用户使用,相应的收益将来源于相关咨询、用户驱动的开源软件的二次开发支持及其类似服务。当前,GeRDI 项目仍在开发中,还未最终确定使用哪种服务场景,GeRDI团队计划在项目第二阶段(2019—2022 年) 对这些服务场景进行扩展与分析并提供一个最终服务方案。
3 GeRDI 的设计原则
3.1 长尾科研数据
长尾理论(The Long Tail) 最早由美国《连线》杂志主编ANDERSON 于2004 年提出,用以描述商业领域中小交易群体表现来的巨大市场份额[14]。2008 年HEIDORN 首次将长尾理论用于描述科学研究中的长尾现象[15]。HEIDORN 经调查得出结论,近80%的科研活动都处于科学研究的长尾上,这些长尾科研项目虽然经费少、规模小,但却有众多科研人员参与,产生了大量的科研数据。相对那些专注于核心学科、关键领域且投资巨大的大项目而言,“小科学” 投资小、数据量多,倾向于更前沿、更创新的研究[16]。也就是说,处于科研长尾上的小科研项目往往更容易成为科学创新的源头。但这些小科研项目产生的大量长尾科研数据往往由科研人员自己保存,缺乏专门的数据管理计划和数据管理工具。这就导致这些长尾科研数据很少被共享,很难被重用,没有挖掘出其潜在的巨大价值。
根据规模大小,可以将RDI 分成两类。一类是专注于大数据管理的国家(国际) 数据基础设施,当前,对这类科研数据基础设施关注和建设的比较多,如地球与环境科学的世界数据中心系统(The World Data Center System)[17]和基因组数据库[18]等。另一类是专注于对长尾科研数据管理的基础设施,这类科研数据基础设施建设数量很少,而且非常分散。GeRDI 就是为了实现对长尾科研数据的管理、共享与重用而开发的联合科研数据基础设施。
3.2 科研数据生命周期
科研数据生命周期模型是正确理解科研数据演变过程的重要数据管理框架,它可以用来解释和定义科研数据管理的复杂过程,明确在科研数据服务实践中,不同利益相关者所承担的角色和责任。基于此,GeRDI使用科研数据生命周期模型来更好的理解不同科研社区的科研数据演变过程,继而识别确定GeRDI 所应提供的核心服务内容。在比较研究了若干模型后,GeRDI采用了英国数据存档(UK Data Archive) 数据生命周期模型。该模型非常简单,包含创造数据(Creating Data)、处理数据(Processing Data)、分析数据(Analyzing Data)、保存数据(Preserving Data)、获取数据(Giving Access to Data) 和重用数据(Re-using Data) 6个阶段,如图2 所示。
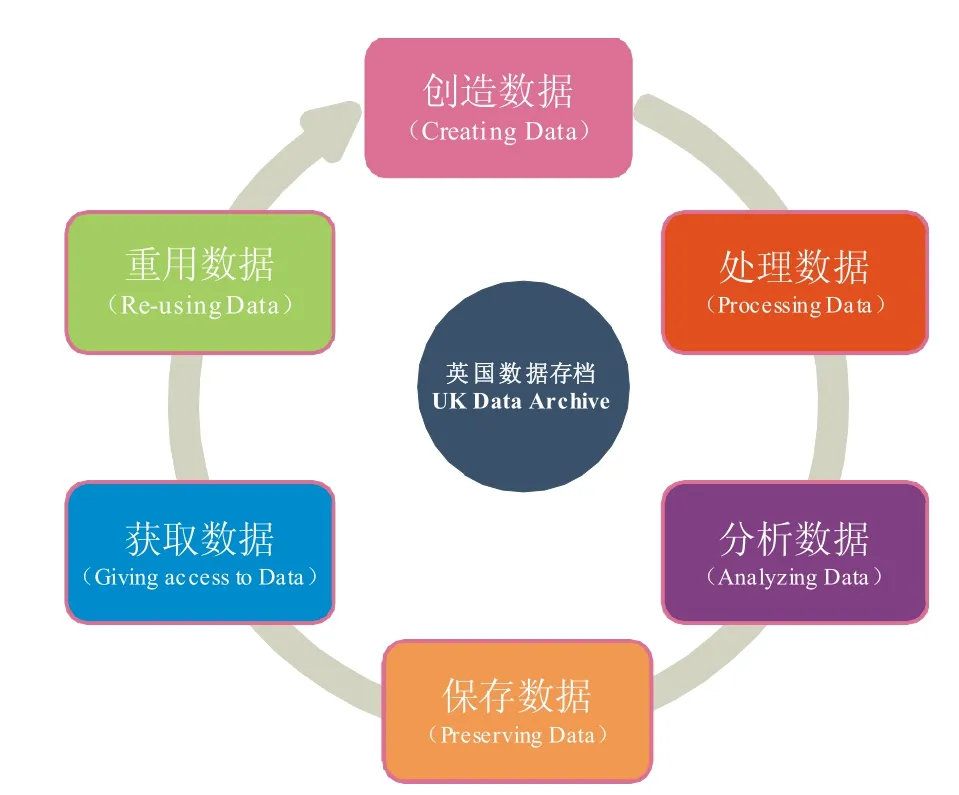
图2 英国数据档案数据生命周期模型[19]Fig.2 UK Data Archive's data life cycle model
3.3 基于试点科研社区的需求收集流程
多样性是长尾科研数据基础设施的主要特征,GeRDI 选取分属4 个不同学科领域的9 个科研社区作为试点。这9 个多学科科研社区如表1 所示。

表1 GeRDI 9 个试点科研社区[20]Table 1 Nine pilot research communities of GeRDI
GeRDI 为每个试点社区设置一名社区管理者,他们既是GeRDI 的项目成员,同时也是项目组与试点社区之间的联络桥梁。他们负责收集不同试点社区的需求,获取社区期望GeRDI 提供的功能与服务,同时向项目组提供有建设性的见解、评价和反馈。社区需求收集包括访谈、制定需求说明书、需求用例模型化、将需求用例与GeRDI 服务映射4 个主要过程。
(1) 访谈。社区管理者以访谈的形式获取试点社区的需求是需求收集的重要方法。根据项目实施阶段的不同,访谈的重点也不同。在项目实施前,社区管理者长时间与用户沟通交流,获取用户的最初需求,在此基础上,不断对需求进行提炼并增加新的需求。在GeRDI V.1 发布后,社区管理者则通过访谈来获取用户使用GeRDI 的评价与反馈,并进一步收集用户的需求。
(2) 制定需求说明书。基于访谈阶段的访问记录,社区管理者识别出最初的用户需求用例,并制定需求说明书。在此阶段,需求开始逐渐转变为用户期望在GeRDI 中可获取到的功能与服务。例如,基本的搜索服务功能,用户期望通过特定的参数来缩小或扩大搜索结果。
(3) 需求用例模型化。为了进一步从上述两个步骤中获取需求,社区管理者使用用例将需求进行模型化。社区管理者可以设置每个用例实现的优先权,并决定是否将某个用例作为一个整体来实现,还是将其分割成更小的实现功能单元。在该过程中,为了更好的向用户展示不同的GeRDI 功能特征,项目组使用了“抛弃式原型” (Throw-Away Prototypes) 开发方法,用来解决需求的不确定性、不完整性和模糊性。
(4) 将需求用例与GeRDI 服务功能进行映射。社区管理者与对应的社区沟通协调,将需求用例与即将在GeRDI 中实现的服务功能进行映射。
4 GeRDI 的元数据模式
元数据是描述资源实体各种特征的结构化、已编码的数据,是实现科研数据发现、管理、共享及重用的重要描述机制,是科研数据基础设施的重要组成部分。GeRDI 关注的是对长尾科研数据的管理,涉及4个不同学科领域的9 个科研社区,因此,设计一个支持描述不同学科领域科研数据的元数据模式是GeRDI项目建设所面临的主要挑战之一。GeRDI 元数据模式在通用元数据与学科领域元数据之间保持了相对平衡,包含通用、操作以及学科元数据3 个部分,分别映射GeRDI 不同的需求类别,为科研社区提供了更好的支持服务,如图3 所示。
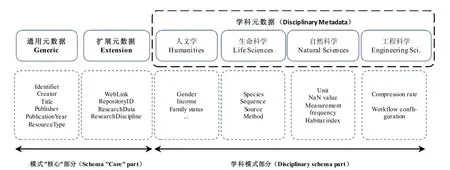
图3 GeRDI 元数据模式[21]Fig.3 GeRDI metadata schema
(1) 通用元数据。包含典型的书目元数据元素,如标题、作者、出版时间等,这些都是支持RDI 服务的通用元数据元素。通用元数据一般包含数量少但稳定的元素。GeRDI 选择重用成熟、流行的元数据标准DataCite,用于科研数据的交换与引用。
(2) 操作元数据。作为基础设施,GeRDI 需要特定的元数据元素支持相关操作,如识别已收割数据资源,跟踪数据来源、所属学科、不同的获取链接(下载、浏览等) 等。操作元数据对元数据收割、维护以及常规RDI 服务支持至关重要。图3 中“扩展元数据”展示了此部分的元数据元素。
(3) 学科元数据。学科元数据可以同时影响用户需求与GeRDI 服务功能,是元数据模式设计过程中最具挑战的一个部分。图3 “学科元数据” 模块展示了根据不同学科领域而组织的元数据元素,充分满足了对多学科科研数据的描述需求。在整个需求收集过程中,科研社区通过用例 (Use Cases) 来决定在GeRDI Schema 中应该加入哪些学科元数据。但是,随着新科研社区的加入或者现有社区提出新的用例,就需要在GeRDI Schema 中持续加入新的学科元数据元素,这就导致学科元数据元素的数量会不断增加。如何在元数据元素的广度与深度之间保持相对平衡是GeRDI 需要持续考虑的主题之一。为了应对该挑战,GeRDI 不断监测、学习一些领先的元数据研究国际组织的最新元数据类型标准,如RDA 数据类型注册工作组(RDA Data Type Registries Working Group)。此外,GeRDI 考虑使用本体应用从基础设施层级来解决该问题。
通用元数据和操作元数据作为核心部分支撑了GeRDI 的通用服务,学科元数据则为学科服务提供支持,这对多学科科研社区来说至关重要。GeRDI 核心元数据与学科元数据分别处于不同的区块,核心元数据区块基本保持稳定,学科元数据区块则根据需求的变化而不断变化。当向学科元数据区块增加新的元数据元素时,开发者首先梳理和确定拟增加的字段结构,然后转换为模板文件,最后在安装部署时将新增加的元数据模板文件导入到对应的学科元数据区块。
5 GeRDI 的架构设计
架构是经过系统性思考,经权衡利弊后在现有资源约束下的最合理决策,是最终确定的系统顶层结构,包括子系统、模块和组件以及它们之间的协作关系、约束规范和指导原则。GeRDI 的目标是设计一个可以应对不断变化的用户需求,避免推倒重建,同时又能够最大限度降低系统设计复杂度的架构。基于用户需求和设计目标,GeRDI 选择自包含系统(Self-Contained System,SCS) 和微服务架构作为软件架构的设计方案。为了避免系统设计的复杂性,自包含系统将GeRDI 主要功能分割成不同的独立组件,每个组件都拥有用户界面、商业和逻辑层的独立网络应用程序,即将其实现成为一个微服务。每个自含式系统由独立的团队开发,伸缩性良好,可持续加入新的功能并将其整合为一个新的微服务,极大的提高了软件开发效率。GeRDI 软件架构如图4 所示。
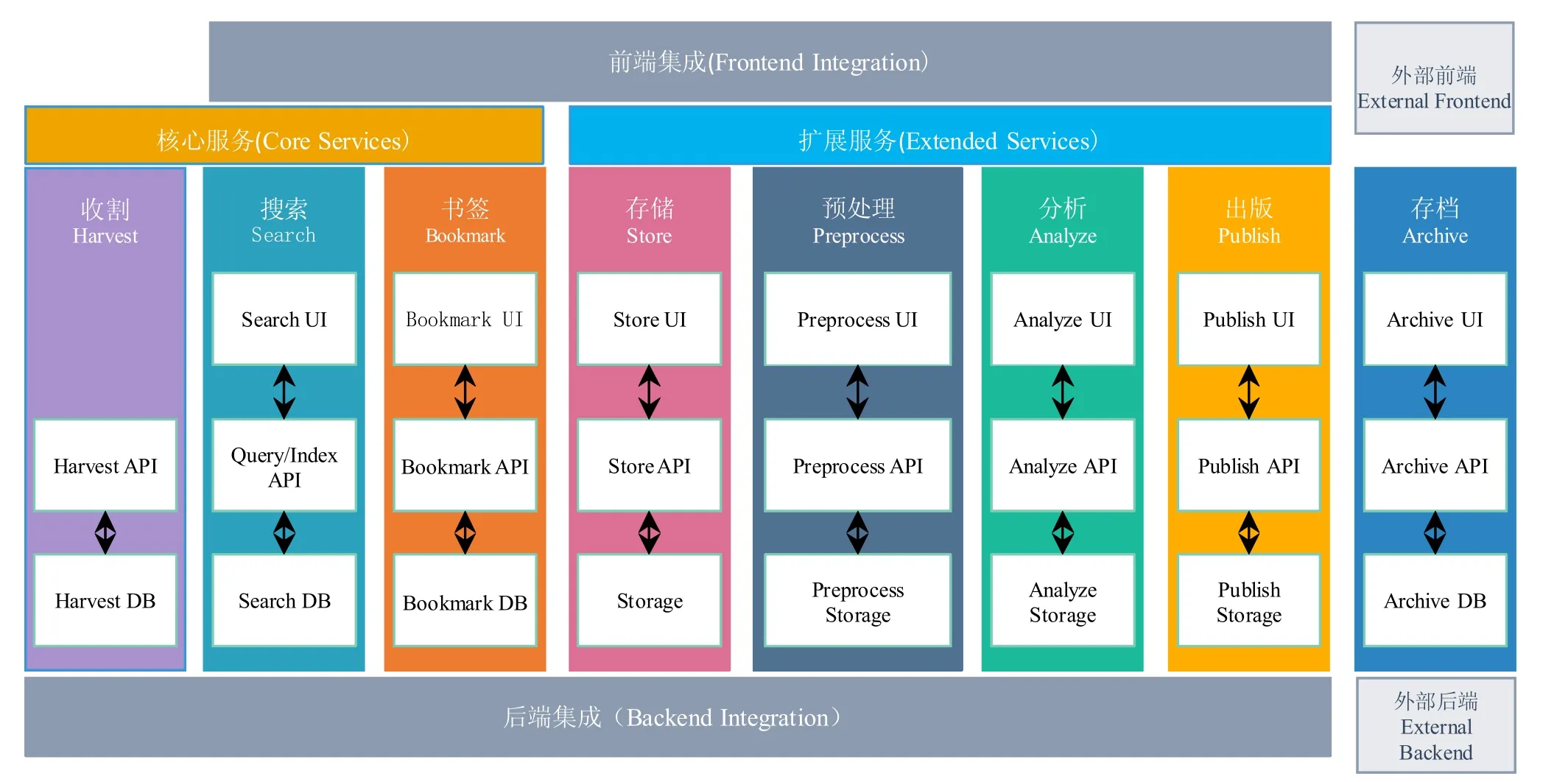
图4 GeRDI 软件架构(服务集) [8]Fig.4 GeRDI system architecture (services)
5.1 将GeRDI 服务与科研数据生命周期映射
需求收集期间对科研用例的识别过程为确定GeRDI的潜在服务提供了足够的反馈。不同的科研社区期望GeRDI 所应提供什么样的服务功能侧重不同,基于用户需求,GeRDI 开发组对科研用例进行分析收集并将其与科研数据生命周期的不同阶段进行映射,如图5所示。
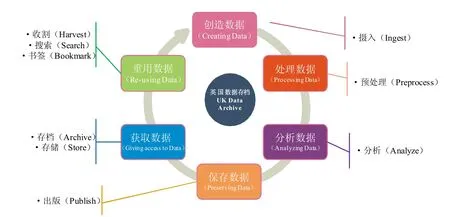
图5 将GeRDI 服务与科研数据生命周期映射[21]Fig.5 Mapping of GeRDI services to research data life cycle
5.2 GeRDI 的服务
GeRDI 的服务集如图4 所示,主要分为核心服务和扩展服务两个部分。每个标颜色的方框代表某项服务功能,对应科研数据生命周期的某个阶段。随着需求收集的不断进行,新的服务功能将不断的加入至核心服务和扩展服务中去。
5.2.1 核心服务
核心服务集包含收割(Harvest)、搜索(Search)和书签(Bookmark) 功能。
(1) 收割。收割服务为元数据的获取提供了接口,GeRDI 从不同社区的科研数据知识库中获取元数据,并将其添加到GeRDI 的索引中去。它也可以丰富充实已收割元数据并将其添加至搜索索引中。当前,GeRDI已经从不同科研社区的数据知识库收割超过37 万个数据集。为了进一步增加索引量同时证明其良好的可扩展性,GeRDI 同时从欧洲著名开放科学数据库Zenodo[22]中收取元数据。
(2) 搜索。搜索服务帮助科研人员通过搜索查询,发现所需科研数据。搜索结果的过滤以及根据检索结果进行推荐等特性也被加入到搜索服务中。
(3) 书签。书签服务帮助科研人员长久保存搜索到的结果,是一种即时收藏服务。此外,它还保存使用过的搜索词,方便用户快速进行再次搜索。
5.2.2 扩展服务
扩展服务组件为感兴趣的科研社区提供了相关功能实现的案例参考,包括存储(Store)、预处理(Preprocess)、分析 (Analyze)、出版 (Publish)、存档(Archive)。
(1) 存储。科研人员可以利用存储服务功能将书签标记的数据下载至本地或者远程存储系统。
(2) 预处理。帮助科研人员提前对科研数据进行过滤、标准化以及预览等预处理操作。
(3) 分析。对已预处理的数据提供数据分析服务,帮助科研人员洞察新的科学发现。
(4) 出版。为新产生的科研数据存入GeRDI 存储库提供出版与摄入服务。
(5) 存档。为科研数据长期保存提供相关知识库服务。
6 GeRDI 对中国科研数据基础设施建设的启示
6.1 在国家层面制定科研数据基础设施建设的战略规划
中国现有科研数据基础设施主要集中在科技云和不同类型的数据中心。2017 年12 月启动了“中国科技云”[23](China Science&Technology Cloud,CSTC) 建设,旨在建成加速科学发现、数据与计算融合的、领先国家级基础设施。2019 年CODATA 北京会议期间提出“全球开放科学云” (Global Open Science Cloud,GOSC) 理念之后,“中国科技云” 与欧洲开放科学云EOSC、非洲开放科学云平台AOSP 以及澳大利亚科研数据共同体ARDC 等开放科学云实践加强国际合作,积极参与GOSC 的规划与建设。2019 年6 月,科技部、财政部在前期科学数据工作的基础上,分别在高能物理、基因组、气象、地震海洋等领域组建了20 个国家科学数据中心,如国家冰川冻土沙漠科学数据中心、国家基因组科学数据中心、国家基础学科公共科学数据中心等。
虽然中国在科研数据基础设施建设方面已取得了一定的成果,但也存在一些问题。“中国科技云” 主要侧重于高性能计算、人工智能、云计算、云存储等云服务,在一定程度上实现了科研数据的开放、共享与重用,但与领先的欧洲开放科学云EOSC 相比还有一定的差距。国内还未建立全学科门类、基于统一政策标准的、基础性开放科学平台。在缺乏国家总体发展规划下,不同类型的数据中心急剧增加,不可避免的会造成重复建设、资源浪费以及不同数据中心之间缺乏统一的数据传输与共享标准等问题。
因此,国家科技部门应抓住机遇,对不同科研社区的需求进行调研,制定科研数据基础设施建设发展国家战略规划,协调国家、领域以及机构等不同层次的科研数据基础设施建设。建立一个基于统一的政策、标准、规范的联合科研数据基础设施,既能够整合国内不同科研数据中心数据资源,实现科研数据一站式访问、获取、互操作以及重用,又能够与国际上重要的科研数据基础设施进行数据交换和共享。
6.2 基于科研社区需求驱动的建设模式
科研社区的真实需求是驱动科研数据基础设施建设和长久运行的原始动力。当前,中国的一些数据中心建设还存在“重建设,轻使用” 的状况。造成这种情况的最主要原因是数据中心的建设通常是“项目驱动” 而非“需求驱动”,只重视项目建设是否完成,未能充分调研用户的真实需求。GeRDI 基于试点科研社区需求驱动的建设模式值得我们借鉴。在进行项目建设时,首先明确项目建设所要服务的目标用户群体,即试点科研社区,然后为每个试点科研社区设置一名管理者,他们既是项目组成员,同时也是项目组与试点社区之间的联络桥梁。通过访谈、制定需求说明书、需求用例模型化、将需求用例与项目服务映射等过程收集不同试点社区的需求,获取社区期望项目提供的功能与服务,同时向项目组提供有建设性的见解、评价和反馈。
6.3 兼容现有的协议、标准,同时又能适应未来的不断变化
科研数据基础设施的建设不可能把现有RDI 全部推倒重建,最佳方案是把当前已建成的数据知识库等分散的基础设施连接起来,形成一个开放、动态、共享的RDI 网络。GeRDI 不是建设一个新的数据中心,而是从不同科研社区已建成的数据知识库获取科研数据,实现科研数据“物理上分布、逻辑上集中”。因此,RDI 的建设要兼容现有的元数据收割协议、网络协议,同时要遵守一致的数据模型、统一的软件技术标准等。只有这样,才能最大限度的降低RDI 建设的成本,并能充分实现不同RDI 之间的数据互操作与共享。
未来RDI 的建设不是一蹴而就的,而是一个动态持续的过程,试点科研社区会不断增加新的需求,同时新的试点社区也会不断加入。这就要求RDI 在建设初期就要把这种动态持续的特性考虑进去,以适应不断变化的未来。具体可以从两个方面着手,一是灵活的架构设计,使用自含式系统和微服务架构将不断变化的需求功能整合至正在运行的系统,而不必将原有的系统推倒重来。二是建立RDI 建设动态监测机制,全面扫描不同机构、领域的RDI 建设,重点关注相关政策、技术标准、先进的软件设计方法等内容,始终让RDI 处于不断进化的状态。
猜你喜欢
中国化肥信息(2022年5期)2022-08-30 01:58:04
宁波大学学报(理工版)(2022年4期)2022-07-08 05:12:02
清华金融评论(2022年4期)2022-04-13 21:33:11
科学与信息化(2021年12期)2021-12-27 01:39:02
华北理工大学学报(自然科学版)(2021年3期)2021-07-03 09:06:34
铁道通信信号(2019年11期)2019-05-21 03:05:46
出土文献与古文字研究(2018年0期)2018-11-04 00:42:00
中国公路(2017年14期)2017-09-26 11:51:43
军事文摘·科学少年(2017年4期)2017-06-20 23:29:09
中央社会主义学院学报(2016年2期)2016-05-04 04:18:29
