
基于数据分解与重构的光伏发电功率超短期预测
2022-04-26 08:25:04徐先峰郑少杰王世鑫蔡路路
机械与电子 2022年4期
徐先峰,郑少杰,赵 依,王世鑫,蔡路路
(长安大学电子与控制工程学院,陕西 西安 710064)
0 引言
光伏发电是我国应对能源危机和经济发展新形势的战略新兴产业,光伏装机量进而也呈现“井喷式”的发展形势[1]。然而,受气象等因素的影响,光伏发电波动性大、间歇性强的特点对保证电力系统稳定安全运行十分不利[2]。高精度的光伏发电功率预测在降低对电力调度的冲击,帮助电力调度部门制定高效的发电计划方面意义重大[3-4]。
近年来,深度学习由于其强大的数据挖掘和特征学习能力,广泛应用于光伏发电的预测。目前,使用较多的深度学习模型有长短期记忆网络(LSTM)[5]、深度信念网络(DBN)[6]等。文献[5]通过考虑一天中连续几小时之间光伏发电功率的依赖性,利用LSTM联合预测多个输出,但模型简单,精度一般。文献[6]建立基于DBN的短期光伏出力预测模型,光伏输出功率预测精度较高。然而上述文献考虑的因素较少,这与受多因素影响的光伏出力实际不符。组合模型之间能够在很大程度上实现优势互补,因此预测模型也逐渐由单一模型向组合模型转变。
据相关研究表明,先对具备时序性的光伏发电数据进行分解有利于提高预测精度[7]。王育飞等[8]采用集合经验模态分解(EEMD)对隐含特征进行优化提取,但是EEMD加入白噪声是非自适应的。CEEMDAN算法通过在每个阶段自适应的添加白噪声,实现重构误差几乎为零,具备良好的时频分辨率和适应性[9]。DBN有效解决传统神经网络学习过程中存在的低速和过拟合问题[10]。基于LSTM的Seq2Seq架构具备捕捉非线性数据间依赖关系的能力,有效提高输出功率的预测精度[11]。基于上述分析,提出一种基于CEEMDAN-DBN-Seq2Seq的光伏发电预测组合模型。
1 基于CEEMDAN-DBN-Seq2Seq的光伏发电功率超短期预测
如图1所示为基于CEEMDAN-DBN-Seq2Seq光伏功率超短期预测的整体架构,该算法由CEEMDAN分解模块、IMF重构模块及深度学习算法组成。CEEMDAN算法将原始数据进行分解,IMF重构模块依据特性统计分析的结果重构,深度学习算法中DBN与Seq2Seq对重构后数据进行预测,通过求和得到最终预测结果。
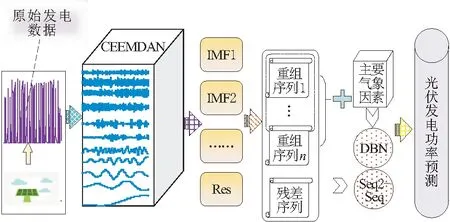
图1 基于CEEMDAN-DBN-Seq2Seq模型示意图
1.1 CEEMDAN分解
CEEMDAN算法是一种可分解复杂时间序列的智能算法[12]。对于具有高度复杂且不稳定特性的光伏出力原始数据,通过CEEMDAN算法将复杂的发电序列转换为简单易学的子序列,将能有效提高预测模型的学习效率。针对信号x(t)的CEEMDAN算法分解步骤如下:
a.通过加入一系列自适应白噪声的方法生成含噪信号集,即
xi(t)=x(t)+ω0εi(t)
(1)
x(t)为原始信号;ω0为加入白噪声的系数值;εi(t)(i=1,2,…,I)为第i次添加的满足高斯分布的白噪声,I为总数,通常取值为10~20。
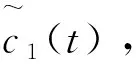
(2)
c.计算第一个信号余量r1(t),即
(3)
d.在r1(t)基础上加入高斯白噪声分量并进行EMD分解,二阶IMF有
(4)
Ej(·)为经CEEMDAN分解后的的j阶IMF;εj为白噪声能量的控制参数。
e.计算第k个信号余量及k+1阶IMF,即:
(5)
(6)
f.重复以上步骤,直至信号余量的极点个数取值为[0,2],表明余量已被分解完毕,公式为
(7)
则原始信号经过CEEMDAN算法分解后为
(8)
1.2 用于光伏发电预测的DBN算法
DBN能够迅速有效解决传统神经网络学习过程中存在的低速和过拟合问题[13]。其中,DBN的训练过程包括预训练和微调2个部分,针对复杂环境下光伏预测的DBN网络结构如图2所示。
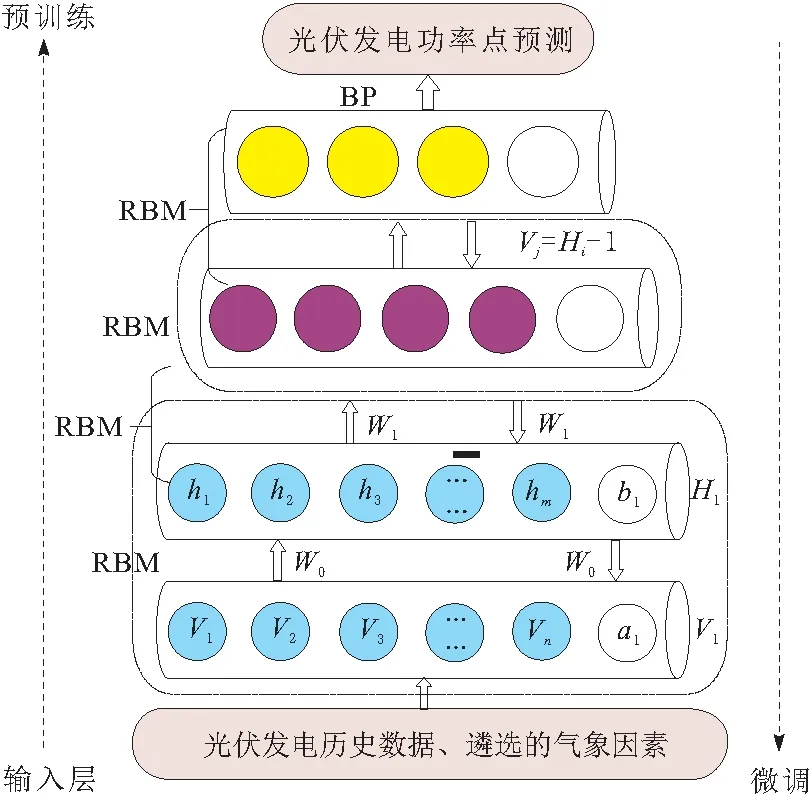
图2 DBN基本结构
1.3 用于光伏发电预测的Seq2Seq算法
序列到序列(Seq2Seq)模型率近年因其在时序信息处理方面能力突出,在电力领域有许多应用,如非侵入式负荷分解、电力负荷预测等[14-15]。
Seq2Seq由编码器、解码器和中间语义向量C组成。即先在编码器的作用下将输入数据编码形成向量,再由解码器完成解码过程。编、解码器选用LSTM搭建Seq2Seq网络,结构如图3所示。

图3 基于LSTM的Seq2Seq模型结构
在编码阶段,Seq2Seq网络输入连续的时间序列x1,x2,…,xn,即为光伏出力残差;然后通过编码对所有隐藏时刻获得C,传递到解码阶段。其计算过程为
(9)
hn为LSTM的第n个时刻的隐藏状态。图3中,背景变量C是在自身q函数的定义下对隐藏状态下生成的。LSTM网络能有效控制信息的流动量,学习到准确的长期依赖关系[5]。
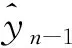
(10)
由理论分析可知,在时间序列预测中,Seq2Seq的编码器负责提取序列本身内在信息,解码器的输出对序列长度等性质无过多要求。
2 CEEMDAN-DBN-Seq2Seq组合预测模型的构建
组合算法构建步骤为:
a.利用CEEMDAN算法将原始光伏数据分解为一系列频率由高到低的固有模态函数IMF1,IMF2,…,IMFn和一个残差序列Res。
b.对所有子序列进行归一化处理,并依据各IMF及残差序列的时频特性同相关性最强的气象因素一起构建新的数据集用于后续建模的输入、输出数据样本。
c.利用DBN算法分别对n个IMF序列进行建模、调参,Seq2Seq对残差序列建立预测模型,捕获各输入样本与输出样本间的关系。
d.通过训练好的DBN、Seq2Seq模型分别对未来光伏出力子序列进行提前1 h预测。
e.将各个子序列的预测值进行反归一化,线性叠加,得到最终的预测结果。
f.依据评价指标对预测结果进行评估。
程序流程如图4所示。
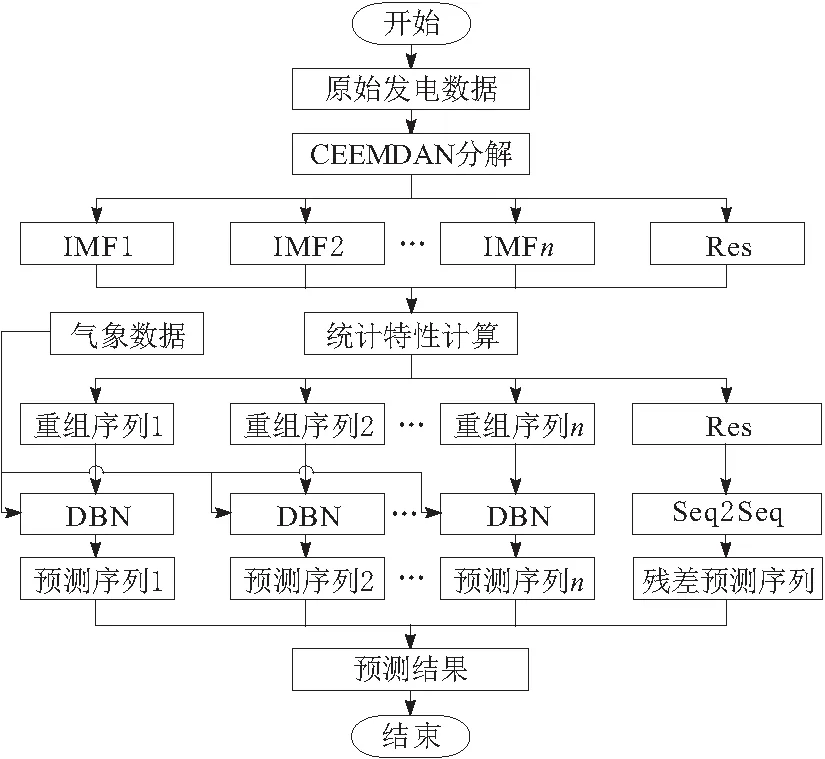
图4 基于CEEMDAN-DBN-Seq2Seq模型程序流程
3 算例分析
3.1 实验数据
本文实验所使用的原始光伏数据为某地区2015年1月1日至5月18日共计3 312条光伏发电数据,以及与之对应的温度(最低温度、最高温度)、湿度、露点(最高露点、最低露点)、风速(最大风速、最小风速)、热指数(最高热指数、最低热指数和风寒指数(最高风寒、最低风寒)11项气象因素。其中前3 216条数据用作训练集,后96条数据用作测试集。
用于评价实验结果的指标为平均绝对误差(MAE)、均方根误差(RMSE)、平均绝对百分误差(MAPE)和决定系数(R2)。
3.2 基于CEEMDAN-DBN-Seq2Seq光伏发电预测
3.2.1 CEEMDAN分解仿真实验
采用CEEMDAN将光伏发电数据进行分解,为增加模型的抗噪性能,添加白噪声。幅度为原始数据标准差0.2,600组,最大分解次数为500次。分解成IMF1-IMF10的10个固有模态函数(频率依次降低)和1个残差序列R,代表光伏发电量在不同时间尺度下的波动趋势。
IMF1~IMF10是按照频率值由高到低依次排列的结果。残差序列则是原始数据与所有IMF做差的结果,可以通过该序列观察光伏出力数据变化的整体趋势。
对各IMF分量及残差序列做统计特性分析。利用皮尔森相关系数法(PCC)进行相关性分析。统计结果如表1所列。
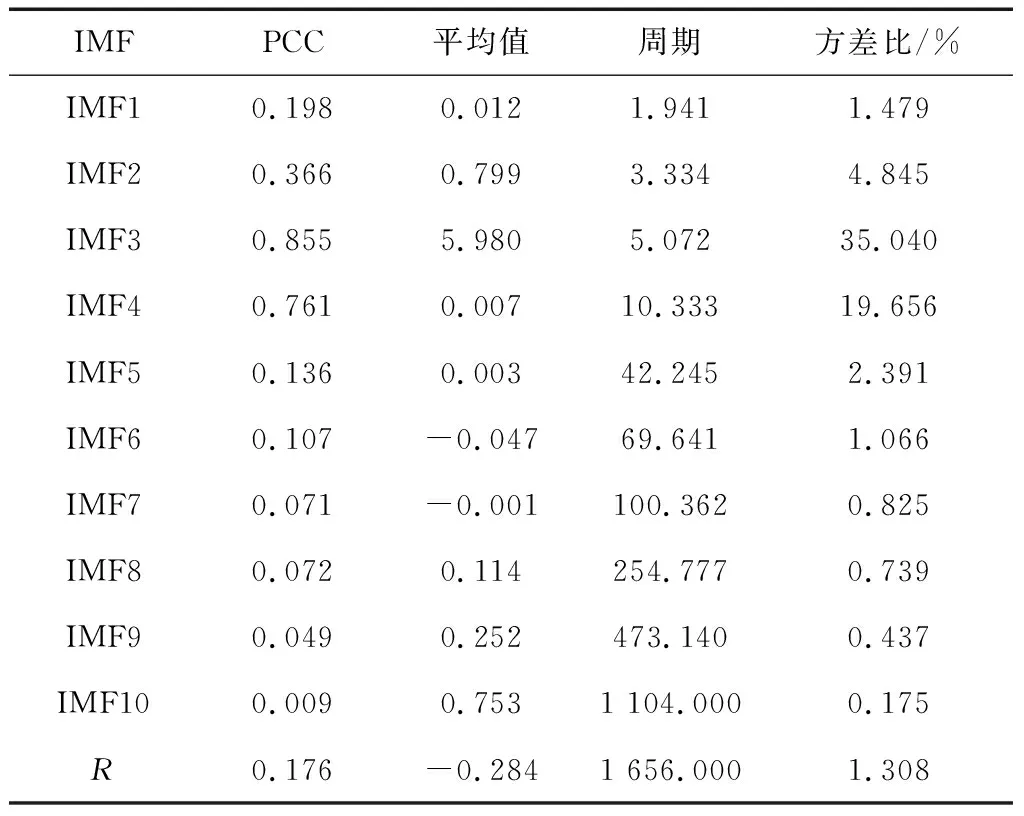
表1 光伏发电各IMF统计特性表
可以看出,除均值外,其他3项统计特性均与频率值表现出明显的相关性。其中,随着频率降低,各IMF分量周期呈上升趋势;PCC和方差占比的变化趋势均为先上升后下降。且IMF1~IMF6周期较短,PCC值和方差比均较大,属于高频部分,说明该部分对光伏发电原始数据相关性及整体波动都有较大影响;IMF7~IMF10周期较长,较小的PCC值和方差,为低频序列,说明和原始序列的相关性较差。残差序列R的PCC值为0.176,方差占比也达到了1.308%,对原始序列也会产生较为重要的影响。综上所述,高频部分对原始光伏序列影响较大,低频部分影响相对较小。
为充分提取子序列的波动趋势,同时降低预测建模的复杂度和避免过拟合,基于上述统计特性分析,将IMF分量进行重构:IMF1~IMF6在实验中被归为同类模式,累计求和后为高频分量;IMF7~IMF10重构为低频分量,原来的残差分量仍作为残差参与分析。重构后的信号曲线如图5所示。

图5 重构后的高低频及残差图像
3.2.2 DBN、Seq2Seq参数确定实验
上述利用CEEMDAN算法对原始光伏出力序列进行分解重构的前期工作完成后,接下来要进行的是DBN算法对高频、低频,Seq2Seq算法对残差总共3个子序列的预测。
为确定最佳的网络结构,对DBN隐藏层的层数及隐藏层节点数超参数的确定,所用方法为纵行对比法。以高频部分的调参实验为例,结果如图6、图7所示。
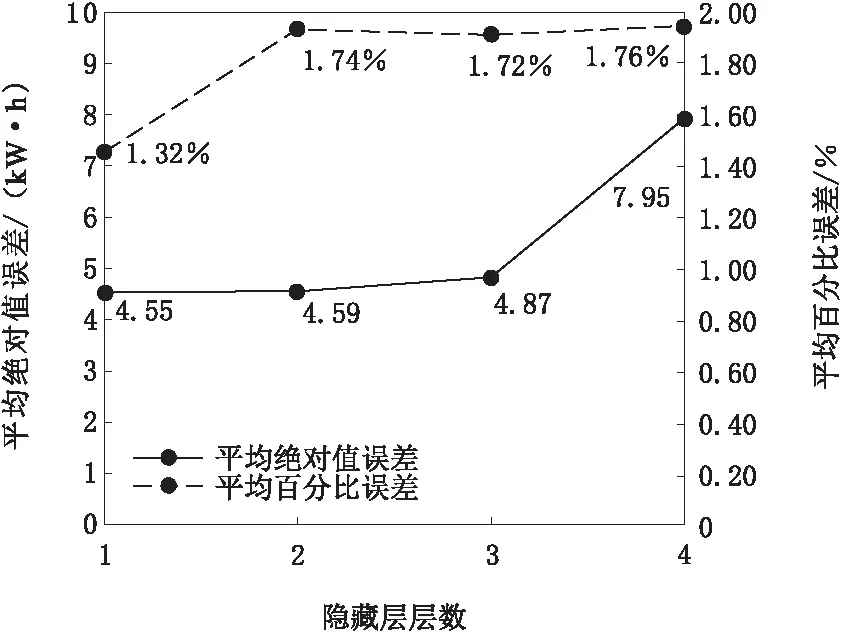
图6 隐藏层层数对模型准确率影响

图7 隐藏层节点数对模型准确率影响
低频部分的实验采用相同的方法进行,得到DBN的参数设置如表2所示(DBN1、DBN2分别指的用于高、低频序列预测的DBN网络模型)。
图6展示了DBN中隐藏层节点数目对预测结果的影响,实验中,每个隐藏层的节点数目均为32。由图6可知,随着层数的增高,准确程度范围会有所下降,所以层数选为2。图7为DBN隐藏层节点数对结果的影响,进行该实验时,设置为2个隐藏层。可以看出,节点数为64时,MAE、MAPE均取得最小值,所以隐藏层节点数确定为64。

表2 隐藏层节点数对模型准确率影响
对Seq2Seq的超参数的确定采用同样的纵行对比法。
3.2.3 DBN、Seq2Seq预测
为了进一步验证CEEMDAN-DBN-Seq2Seq算法的有效性,直观对比出CEEMDAN分解算法的引入与采用单纯DBN、Seq2Seq算法及其他传统预测方法对结果的影响,设置了以下4组对比实验:单一的DBN、单一的Seq2Seq、GBRT和LSTM神经网络,并针对同一数据集进行仿真实验。
对5种算法进行比较,结果如图8所示。虚线为真实光伏发电值,带星虚线部分是采用不同深度学习模型得到的96个预测样本的预测值。依据图8的5条预测曲线与真实的光伏发电功率的拟合程度,得出以下结论:
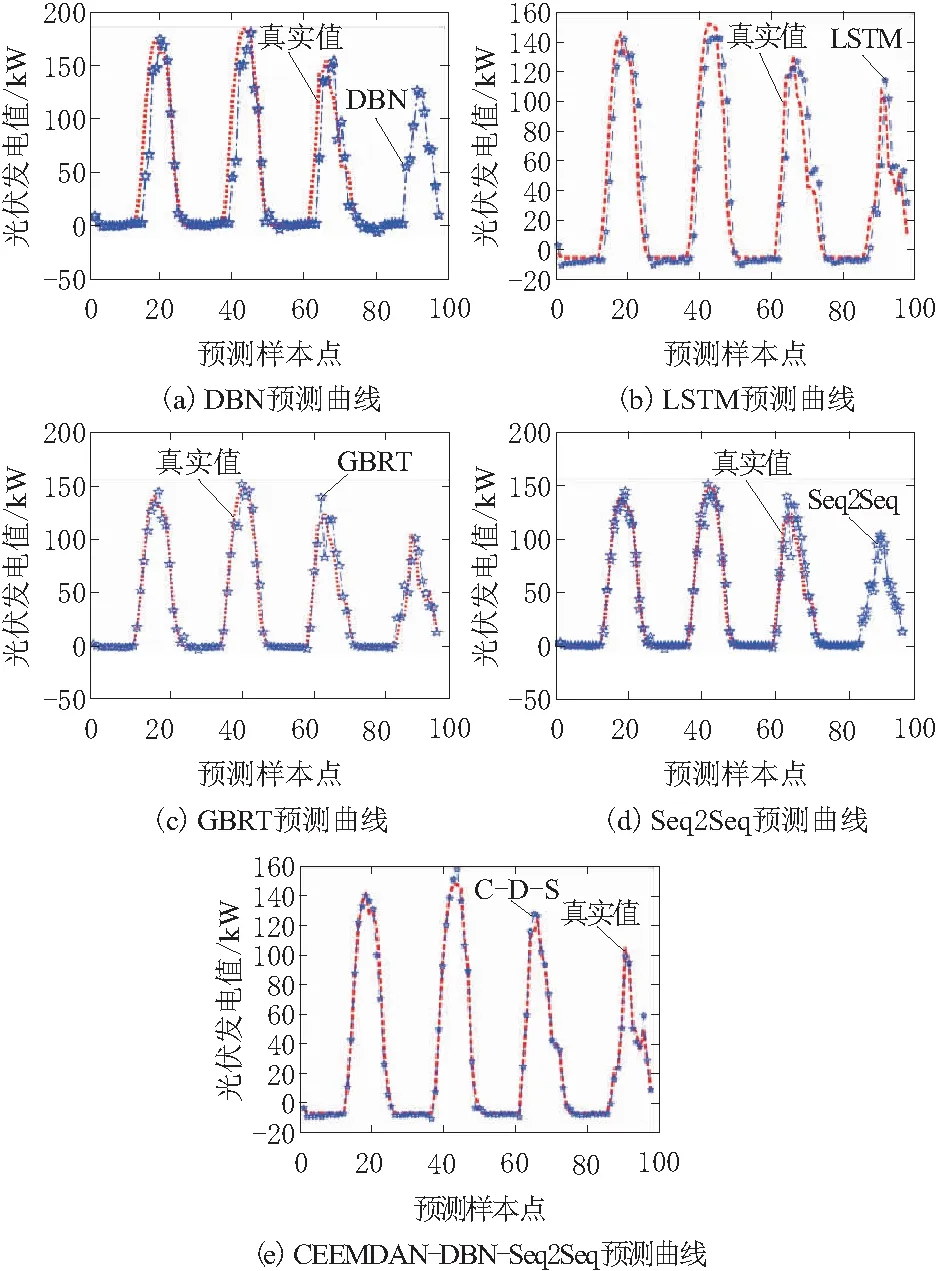
图8 各模型预测曲线对比
a.所有的单一模型中,Seq2Seq算法的预测效果最佳,精度有了很大提升,但是在峰值预测时误差较大,且未能捕捉到有发电急剧变化的趋势。
b.提出的CEEMDAN-DBN-Seq2Seq算法与4种对比算法相较,整体吻合程度最高,除了拐点处出现较为明显的偏差外,其他各部分均紧紧围绕实际值呈较小幅度的上下波动现象,误差波动最小,尤其是在未发电及腰身处,基本实现紧密贴合。与单一的Seq2Seq相比,还有效地改善了其峰值预测效果较差的现象,可以初步断定,CEEMDAN-DBN-Seq2Seq模型能够更好地捕捉样本数据中潜在的内在联系并挖掘其真实模式。
3.2.4 预测结果对比分析
基于上述5种算法分别计算的性能指标如表3所示。

表3 各算法的性能指标计算结果
由图8的预测曲线及表3,可得出以下结论:本文所提出的CEEMDAN-DBN-Seq2Seq无论是曲线的拟合效果还是数据信息,都具备突出的性能优势。与单一的Seq2Seq算法相比,MAE值减小1.76 kW·h,RMSE值减少1.67 kW·h,MAPE值减少1.47%,R2值提升0.85%,各项指标均有较为明显的改善。与单一的DBN算法相比,上述指标值的改善分别为:8.01 kW·h、16.36 kW·h、7.79%、5.43%,改善效果更为明显。同时与其他2种单一算法相比较,预测性能更为突出。
显然,所建立的组合模型预测能力不仅明显优于传统深度学习模型,也优于基础模型,表现出良好的稳定性与低误差性。这也直接显示了深度学习在挖掘数据间潜在非线性关系方面的特殊能力,进一步验证了所提算法的优越性。
4 结束语
本文为提高光伏发电功率预测的准确率,提出了一个融合CEEMDAN、DBN和Seq2Seq的组合算法:CEEMDAN-DBN-Seq2Seq。与单一的Seq2Seq、DBN算法相比,所提算法R2值分别提升了0.85%、5.43%,其他各项指标均有较为明显的改善。并且与其他传统算法进行了全方位多角度的性能比较,从而进一步论证了所提算法通过CEEMDAN分解技术的引入,可以有效改善单一算法的预测精度,具有更高的预测精度和实际应用价值。
猜你喜欢
环球时报(2022-06-15)2022-06-15 15:21:32
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
摄影世界(2022年1期)2022-01-21 10:50:14
科学大众(2021年9期)2021-07-16 07:02:50
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
自动化学报(2019年6期)2019-07-23 01:18:32
知识经济·中国直销(2018年12期)2018-12-29 12:22:14
商周刊(2017年6期)2017-08-22 03:42:36
下一代英才(酷炫少年)(2017年3期)2017-06-15 13:00:06
学与玩(2017年4期)2017-02-16 07:05:40
