
室内工作面天然采光照度分布实时预测方法
2022-04-24 07:01马梓轩展长虹韩雪莹李光皓
照明工程学报 2022年1期
马梓轩,展长虹,韩雪莹,李光皓
(哈尔滨工业大学建筑学院,寒地城乡人居环境科学与技术工业和信息化部重点实验室,黑龙江 哈尔滨 150001)
引言
随着建筑采光与人工照明技术的进步,人们逐渐意识到光照环境对身心健康的影响,不舒适的光照环境,例如照度过高或者过低都会引起人眼的不适感,从而降低工作学习的效率。得益于目前智慧理念和人工智能技术的发展,建筑照明随着室外光照条件智慧调度成为了颇具发展潜力的新兴技术。天然光只存在于白昼期间,且其在室内产生的照度随时间并不呈线性变化。本文目的是探寻机器学习算法在实时获取工作面天然采光照度分布方面的应用,从而使得这些照度数据能够指导建筑照明的高效调度。
在国内外学者的相关研究中,获取工作面照度的方式不断更新,主要可分为经验公式、数值仿真、实测法以及机器学习。机器学习最早诞生于19世纪70年代,与软件仿真相比,机器学习主要收集实际采集的数据,配合合理的超参数(hyperparameters)与输入特征(features),可实现较好的泛化性能且无须重复建立建筑仿真模型,使得拟合模型更加实用和便捷。
Logar等[1]以充分利用日光保证室内照度并减少照明能耗为导向,提出了一种模糊黑盒模型(fuzzy black-box model),以太阳辐射强度、外部照度、百叶遮挡位置以及灯具开启状态作为输入参量,室内某一点照度作为输出,预测结果的均方误差为25 lx,这种黑盒模型只能预测室内单点照度,如果需要多点预测,则需要多个模型共同运作。Kurian等[2]利用Perez天空亮度分布模型和建筑本身属性(房间尺寸、采光窗尺寸、窗口朝向、传感器位置、时间序列)作为机器学习的输入变量,分别评价了反向传播神经网络、支持向量机和随机森林三种不同的算法来预测室内某方向上眩光产生概率(DGP),判断室内视觉舒适度。Ahmad等[3]利用太阳高度、太阳方位、日光法线直接辐射、窗口遮阳板角度等作为机器学习的输入参数,分别评估了人工神经网络(ANN)和随机森林(Random forest)对室内照明能耗和工作面平均照度的预测性能。Ngarambe等[4]利用窗地比、墙体反射比、传感器距窗口距离、太阳总辐射值等14个特征作为机器学习的输入端,比较了多元线性回归(ML)、深度神经网络(DNNs)、随机森林(RF)、梯度增强模型(GBM)、长短期记忆模型(LSTM)五种算法对室内工作面照度分布的预测。结果表明,当取全部输入参数时,深度神经网络在测试集中的拟合决定系数R2达到0.990,得分在所有模型中为最高值;当取前五个影响效果最强的输入参数时,深度神经网络在测试集中的拟合决定系数R2为0.777,得分仍然是所有模型的最高值。
机器学习算法的出现以及计算机硬件性能的提升,使得探寻数据集中更为深层的关系成为了可能,从上述文献综述可知,机器学习结合现有的理论框架不仅可以提升拟合精度还可以强化泛化能力。由于建筑室内工作面的照度分布受到多种因素的影响,例如天空亮度分布和建筑本身的属性等。本文总结了2006年至2020年30余篇机器学习算法与建筑采光的相关文献[1-39],分别对机器学习算法输入参数、输出参数、建筑类型以及数据来源进行了统计,如图1所示。
1 研究方法
由上述综述可知,超过半数研究将照度值作为机器学习的预测目标,室内工作面照度分布的预测需要保证在时间序列上的数据获取,且要保证一定的泛化能力,因此输入特征也应具备一定的实时性与灵活性。由145点组成的tregenza天空分布模型的数据往往由气象站和实验室向大众提供,更新速度快,准确率高。
本文结合传感器照度信息、天空亮度信息、时间信息以及其他信息(房间尺寸、窗地比、室内平均采光系数、建筑朝向)作为机器学习的输入特征,旨在面对建筑的多样性也能保证良好的泛化能力,合理预测室内工作面照度分布情况,技术路线如图2所示。
1.1 机器学习模型输入特征获取手段
1.1.1 传感器照度信息获取
在以往学者关于工作面照度的研究中,往往会将光照传感器直接布置在工作面上,但这种做法不仅会使传感器占据一定桌面空间,而且人体活动以及物件摆放也容易使其受到遮挡,因此应该将传感器放置于其他位置,保证在长期监测过程中所获得的数据合理有效。
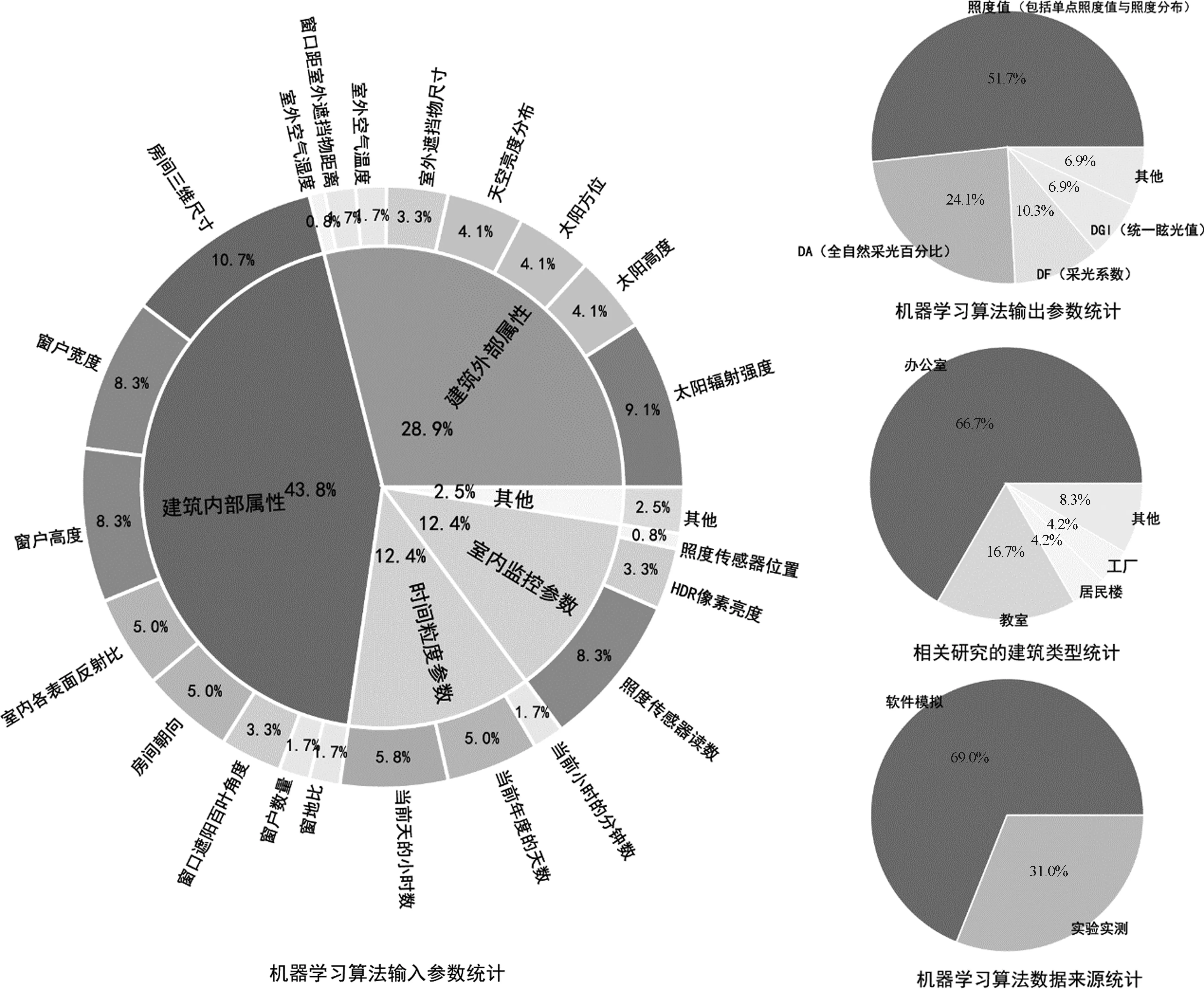
图1 机器学习算法相关研究统计Fig.1 Machine learning algorithm-related research statistics
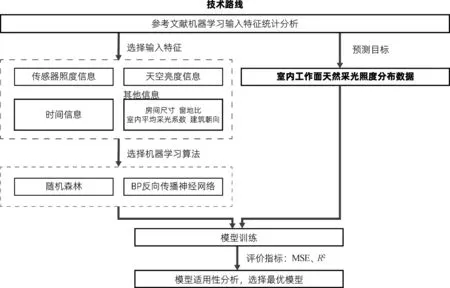
图2 技术路线图Fig.2 Technology roadmap
在空间活动范围内,人体能够触及的储纳最大高度约为2 m[40],传感器放置应尽量高于此高度,同时为避免阳光直射的影响,假设房间长度为L,房间净高度为H0,窗口上沿距天花板高度为H,传感器监测位置放置于采光窗对侧墙体(面向窗户)L/2、H0-H/2处,如图3所示,用于机器学习的输入特征。
1.1.2 天空亮度信息获取
在实测环境下,本文采用哈尔滨工业大学寒地城乡人居环境科学与技术工信部重点实验室所引进的EKO MS-321LR全自动天空扫描仪获取实时天空亮度分布数据。该仪器采用双轴监测,可以监测天空亮度分布信息,满足国际照明委员会设计标准,并可以识别拍摄范围内的障碍物自动修正图像。光谱测量范围为380~780 nm,亮度测量范围为0~50 000 cd/m2,分辨率约为1 cd/m2,可对天空半球内145个面元进行实时监测,每轮扫描时间为4.5 min,间隔为10 min。天空扫描仪实景照片以及其监测软件界面如图4和图5所示。

图4 EKO MS-321LR天空扫描仪实景照片Fig.4 Photo of EKO MS-321LR Sky Scanner

图5 EKO MS-321LR天空扫描仪软件监测界面Fig.5 Monitoring interface of EKO MS-321LR Sky Scanner software
通过EKO MS-321LR全自动天空扫描仪监测系统可以导出任意时间段的天空扫描数据,并输入数据集中。
1.1.3 时间信息获取
由于室内工作面照度分布情况受到外部环境的直接影响,且日光在天空半球的轨迹全周期为一年,因此时间特征应以年度区间进行细分并归一化。本研究拟采用时间步长为15 min,即某一时刻占当年的比例,如式(1)进行计算。
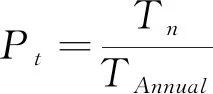
(1)
式中:Pt——某一时刻占当年的比例;
Tn——某一时刻在当年的分钟数;
TAnnual——年度总分钟数。
例如2021年3月22日12:00在当年所占总分钟数为117,360,全年分钟数为525,600,则此时刻在全年的比例参数为0.223 29,此参数作为机器学习数据集的时间特征。
1.1.4 其他信息获取
为保证机器学习训练模型具有一定的泛化性能,即面对不同尺寸房间、不同采光窗大小、不同采光朝向等条件的房间不至于出现预测误差过大的情况,本文结合《建筑采光设计标准》(GB/T 50033—2013),筛选了房间尺寸、窗地比、室内平均采光系数、建筑朝向四个指标作为特征的补充。
1.2 数据集汇总
由前文可知,本研究的机器学习算法的特征向量包括天空亮度特征(天空亮度分布)、照度监控特征(指定位置照度传感器读数)、时间特征[当前时刻(步长为15 min)在全年中所占的比例]以及其他特征(房间尺寸、窗地比、平均采光系数、建筑朝向),如表1所示。

表1 特征划分
1.2.1 机器学习数据集构建
对于数据集中一样本xi,其特征向量所包含的特征可用图6表示。
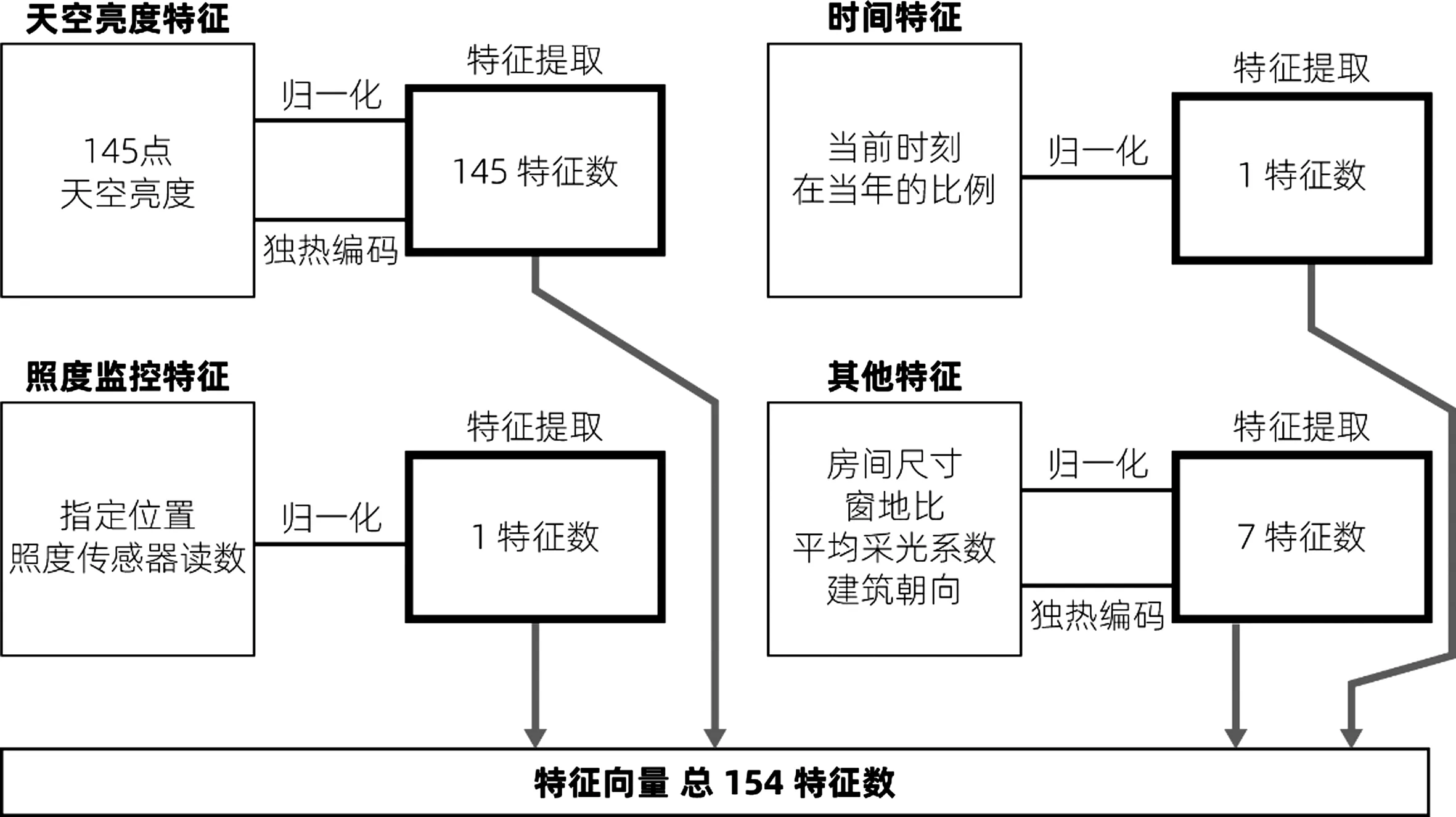
图6 数据集预处理及汇总流程Fig.6 Data set preprocessing and summary processes
1.2.2 预测目标
本研究所采用的采样点数量是根据均匀网格划分工作面,每个网格中心的照度值作为机器学习的目标数组,对于数据集中第i个样本,目标数组可表述为yi=(yi1,yi2,…,yi16),其中yij表示该样本的目标数组中第j点照度值,yi∈y,y是所有样本目标数组的集合。如果预测目标数组为8点照度值,点的位置及其编号顺序如图7所示。对于数据集中某一样本,该样本与目标数组的关系可表示为式(2)。
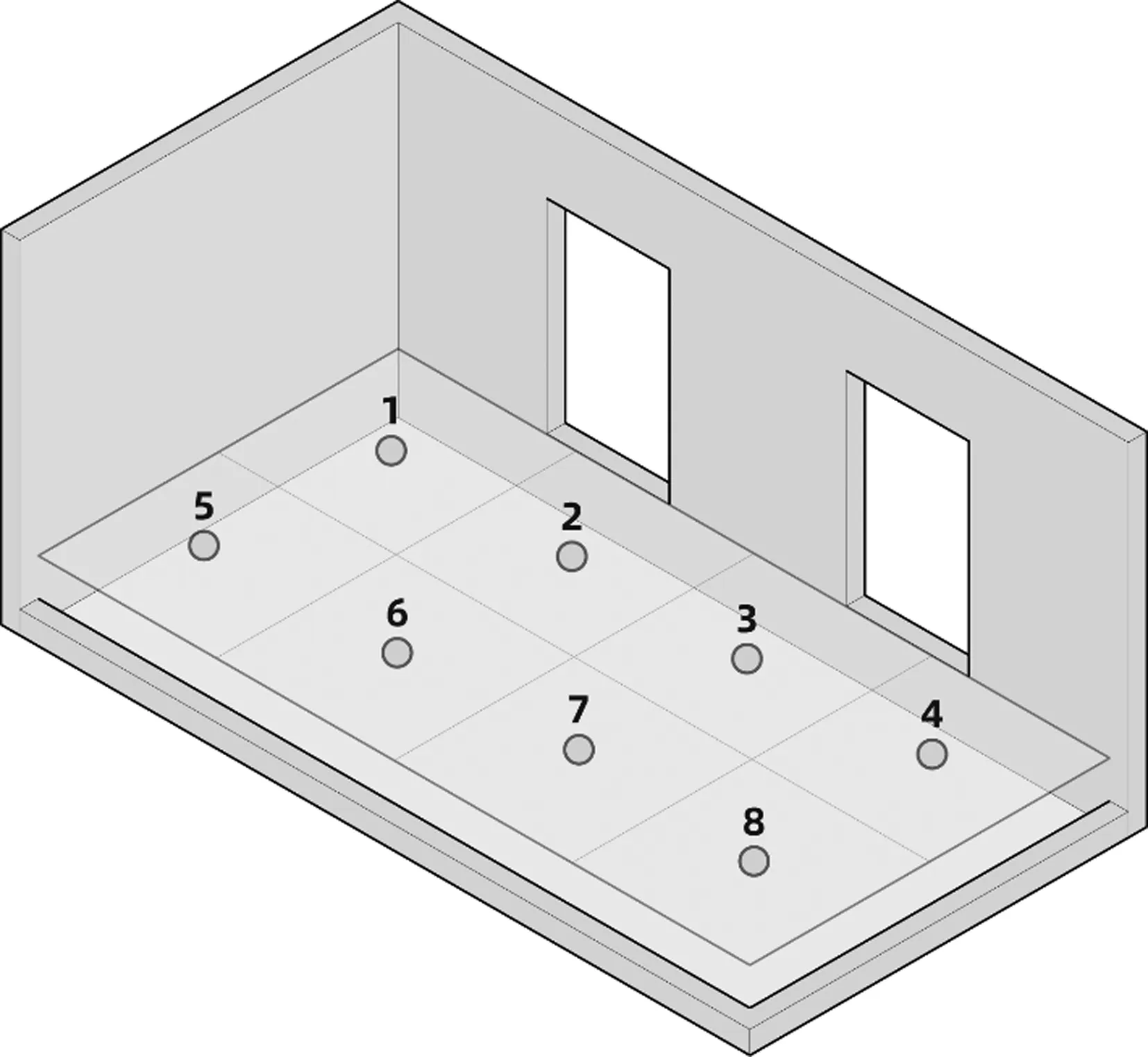
图7 室内照度分布划分8点构成目标数组Fig.7 The indoor illuminance distribution is divided into 8 points to form the target array
(2)
式中:yi——第i个样本的目标数组,yi=(yi1,yi2,…,yi16;
θT——拟合参数,θ=(θ0,θ1,…,θn);
xi——数据集中第i个样本。
1.3 评价指标
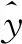
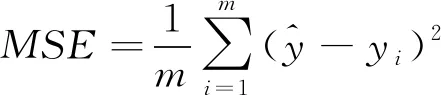
(3)
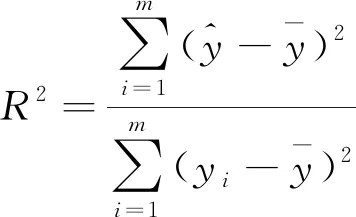
(4)
2 基于实测数据的机器学习模型建立
2.1 实测方案
本研究选取黑龙江省哈尔滨市某高校办公室作为实测对象,地理位置为东经126.631 8°,北纬45.739 2°;房间长度为8.70 m,房间宽度为4.40 m,房间净高度为4.20 m,工作面高度为0.75 m,建筑朝向为北向,共有2扇采光窗,单扇采光窗的尺寸为1.50 m×2.50 m,房间窗地比为0.196,平均采光系数为4.83,室内传感器房间示意图及指定位置传感器安置如图8所示,安装高度为3.70 m,室内工作面共划分为8个预测目标点,点间距为2.00 m,房间实景照片如图9所示。
2.2 数据集
实测方法下数据采集时间为2021年5月4日至2021年6月2日,数据采集时间间隔为30 min,共收集856个数据样本,实测方法下数据集构建流程如图10所示,其中天空亮度特征采用哈尔滨工业大学寒地城乡人居环境科学与技术工信部重点实验室所引进的EKO MS-321LR全自动天空扫描仪获取的实时天空亮度分布数据。
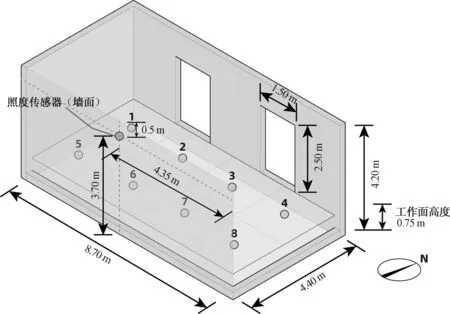
图8 实测方法下房间尺寸示意图Fig.8 A diagram of the room size under the measured method

图9 实测方法下房间实景照片Fig.9 Photo of the room under the measured method
实测方法下,机器学习模型的训练及验证如图11所示。
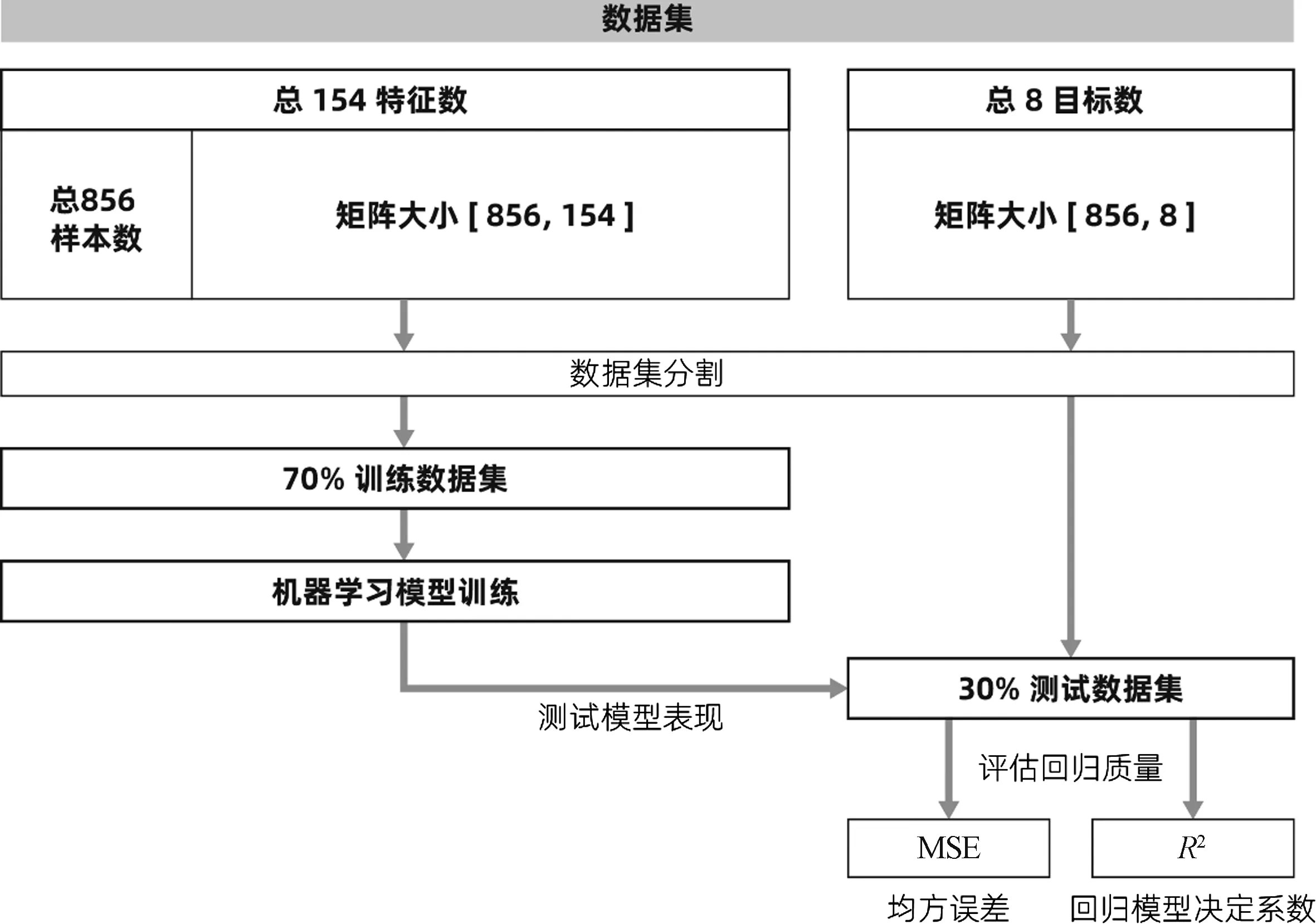
图11 实测方法下机器学习模型的训练及评估步骤Fig.11 Training and evaluation steps of machine learning models under the measured method
2.3 机器学习模型训练及验证
2.3.1 随机森林模型验证
随机森林(Random Forest)是一种机器学习集成算法,也称装袋算法(Bagging meta-estimator)[41],其涵义是构建一个强评估器,其囊括多个弱评估器——决策树。由于随机森林算法的集成特性,其具备以下几点优势:可用于回归问题,适合处理目标数组周期性变化问题,训练所需的数据量较少、且不易发生过拟合问题,能够处理目标数组多值输出问题,这对于室内工作面的多点照度同时预测是十分有利的。
由于随机森林可以很好地控制决策树的过拟合现象,但是随机森林中决策树的数量(N_estimators)也会一定程度上影响硬件负荷。因此,本文通过尝试将随机森林中的决策树数量从2棵以1的步长增至100棵,即训练99个随机森林模型,采用滑动平均法依据数据顺序增减新旧数据获取模型随决策树数量增加拟合表现的滑动平均值(Moving average),即估计局部均值,消除偶然波动,以查看数据趋势。

图12 随机森林回归评价:MSEFig.12 Random forest regression rating: MSE
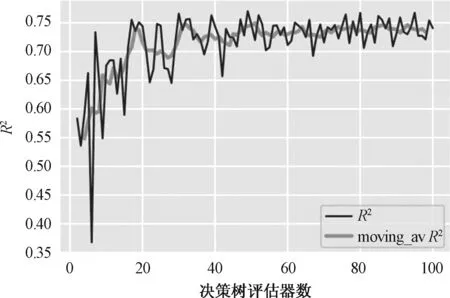
图13 随机森林回归评价:R2Fig.13 Random forest regression rating: R2
由图12和图13可知,随着随机森林中决策树数量的增加,模型在训练集中的表现逐渐趋于稳定,波动范围有所减少,当决策树数量超过60后,模型回归决定系数滑动平均值的波动不超过±0.075,因此将随机森林超参数中决策树数量设定为60。
实测方法下训练完成后的随机森林模型在测试集中回归决定系数R2为0.826。模型对于室内每一点照度的预测回归决定系数R2如图14和图15所示。
本研究选取数据集中2021年5月10日0:00至2021年5月20日24:00,共11天的时间序列,用于比较随机森林模型在实测方法下实际照度值与预测照度值之间的差异,如图16所示。
2.3.2 BP反向传播神经网络模型验证
BP反向传播神经网络目前在人工神经网络中属于发展较为成熟的一种算法,起源于McCulloch和Pitts的“M-P神经元模型”[42]。BP反向传播神经网络是按照反向传播误差进行训练的多层前馈网络,图17为三层神经网络的示例,在数学上具备完整的推导过程,拥有拟合任意非线性函数的能力,其灵活的拟合能力适用于天然采光随着时间和天气变化无常的情况。
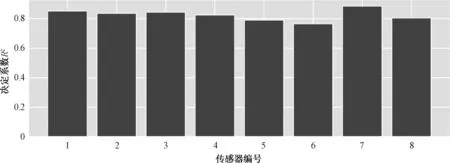
图14 随机森林模型在实测方法下回归决定系数Fig.14 The random forest model regresses the determining coefficient under the measured method
图15 随机森林模型在实测方法测试集中的预测结果示意图Fig.15 Diagram of the predicted results of the random forest model in the test set of the measured method
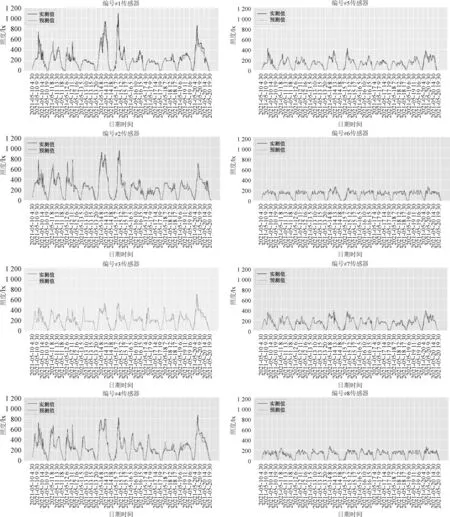
图16 随机森林模型在实测方法下实际照度值与预测照度值对比结果Fig.16 The results of the comparison of the actual and predicted altruistic values of the random forest model under the measured method
在BP反向传播神经网络中,正向传播-反向传播1次称为迭代1轮,迭代次数越多,梯度下降算法在参数空间中越能趋向于最优解。为一定程度避免陷入局部最优解,本文BP反向传播神经网络采用随机梯度下降(SDG),即每次执行梯度下降时都对参数进行一次随机更新;为选择合适的迭代次数,本文尝试迭代次数从10增至1 000,通过判断均方误差(MSE)、回归决定系数R2、回归决定系数滑动平均值(Moving average)选择合适的迭代次数。
如图18和图19所示,随着神经网络迭代次数的增加,模型在训练集中的表现逐渐趋于稳定,波动范围有所减少,当迭代次数超过600后,模型回归决定系数滑动平均值的波动不超过±0.075。因此,在实测方法下,BP反向传播神经网络迭代次数设定为800。
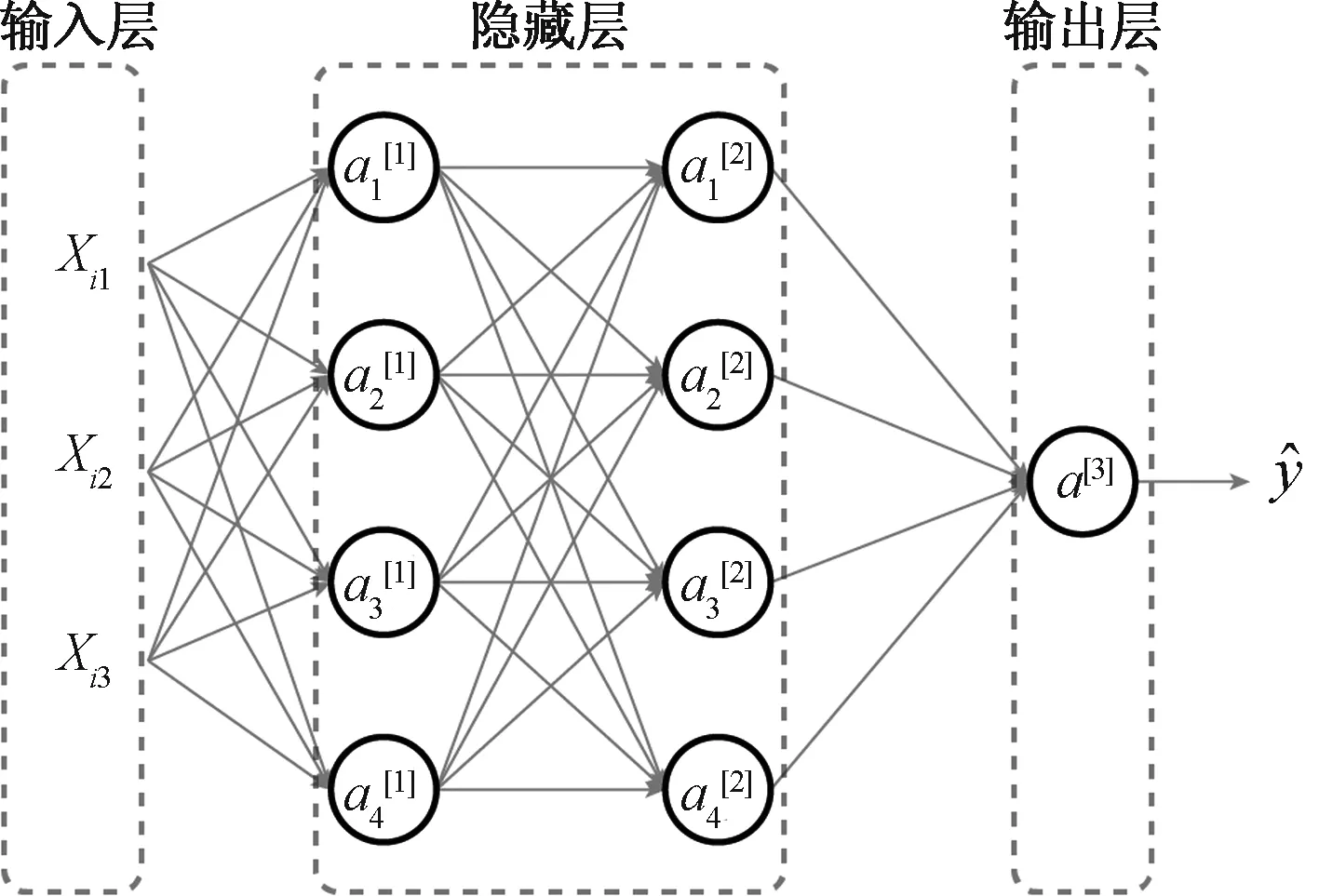
图17 三层神经网络示意图Fig.17 Three-layer neural network diagram
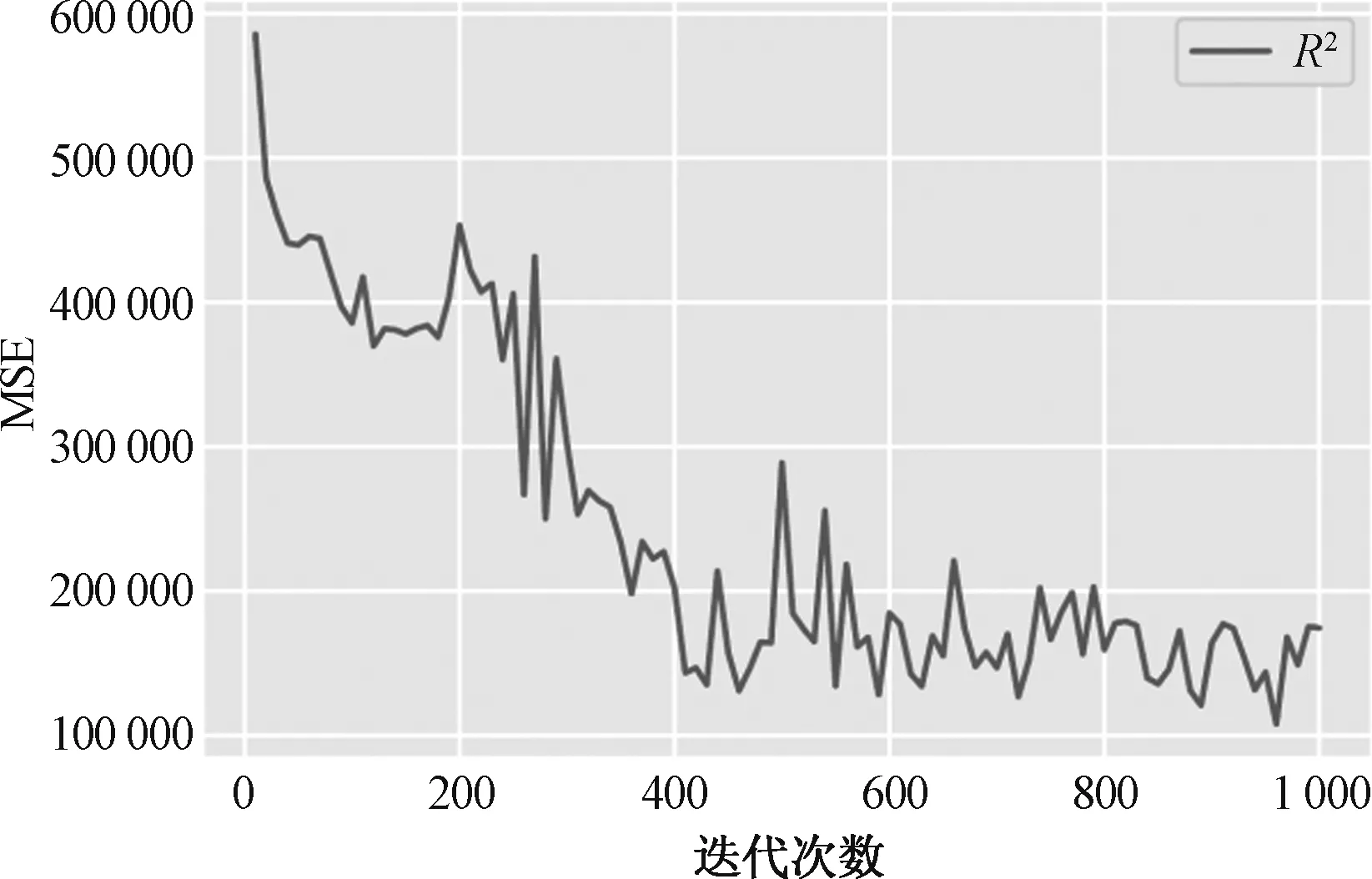
图18 BP神经网络回归评价:MSEFig.18 BP neural network regression rating: MSE
实测方法下训练完成后的BP反向传播神经网络模型在测试集中回归决定系数R2为0.739。模型对于室内每一点照度的预测回归决定系数R2如图20和图21所示。
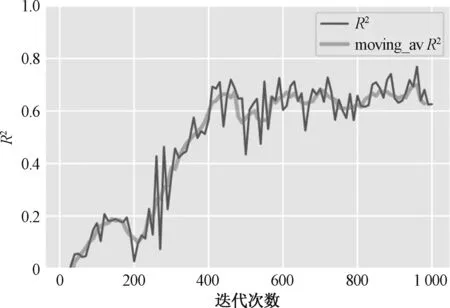
图19 BP神经网络回归评价:R2Fig.19 BP neural network regression rating: R2
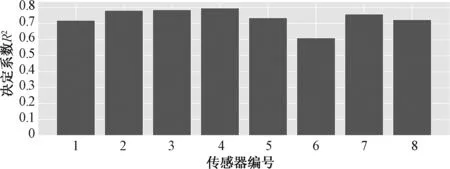
图20 BP反向传播神经网络模型在实测方法下回归决定系数Fig.20 The BP neural network model regresses the determining coefficient under the measured method

图21 BP反向传播神经网络模型在实测方法下测试集中的预测结果示意图Fig.21 Diagram of the predicted results of the BP neural network model in the test set of the measured method
本研究选取数据集中10天的时间序列,用以比较BP反向传播神经网络在实测方法下实际照度值与预测照度值之间的差异,如图22所示。

图22 BP反向传播神经网络模型在实测方法下实际照度值与预测照度值对比结果Fig.22 The results of the comparison of the actual and predicted altruistic values of the BP neural network model under the measured method
3 机器学习模型适用性分析
如表2所示,在实测方法下,随机森林模型在测试集中的回归决定系数R2为0.826;BP反向传播神经网络模型在测试集中的回归决定系数R2为0.739。

表2 两种机器学习模型的回归决定系数
由上述可知,在实测方法下,随机森林的表现相对较好,且随机森林模型的训练成本也相对BP反向传播神经网络较小。
判断现有模型的预测精度能否指导照明系统的调光决策往往需要根据国家相关照明设计标准确定。《建筑照明设计标准 》(GB 50034—2013)中规定,普通办公室内0.75 m工作面上的标准照度值应为300 lx,同时在其修订说明中,照度分级是依据CIE标准《室内工作场所照明》(CIE S 008/E—2001)确定的,由于在主观感觉上,人眼能够明显感知到照度变化的最小照度变化差大约为1.5倍[43],以普通办公室工作面标准照度值300 lx为参考,其临近照度分级为200 lx和500 lx,照度差分别为100 lx和200 lx。本研究所阐述的工作面照度实时监测方法中照度预测值与实测值之间的残差应保证在上述照度差范围内,并指导照明系统进行合理的调光决策,保证视觉的舒适性。
以本文实测收集数据为例,传感器各点实测值与预测值的平均残差如图23所示,两种算法的各点平均残差小于上述最小照度差(100 lx),随机森林相对于BP反向传播神经网络表现更好。
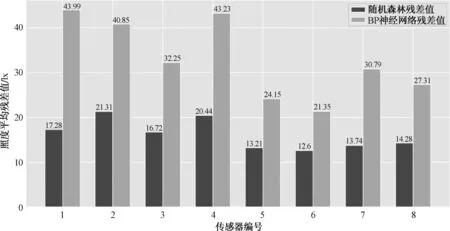
图23 实测传感器各点实测值与预测值平均残差Fig.23 The average residual difference between the measured and predicted points of the measured sensor
4 结论
为实现室内工作面天然采光照度分布的实时获取,同时对现有传感器的数据进行实时校正,本文选择了两种机器学习算法随机森林(Random Forest)和BP反向传播神经网络(Back Propagation Neural Network),并基于实测数据进行建模及性能评价。研究结论如下:
1)本文探索了机器学习在室内工作面照度监测方面的应用,相较于传统室内工作面照度测量的不便,本文阐述的天然采光照度分布预测方法可以同时预测多点工作面照度,并且可以修正不在工作面上布置的传感器读数,不会给使用者带来不利影响,在未来建筑的照明智慧化调光及间接节能方面具有正向促进作用。
2)使用实测方法获取的数据,随机森林模型在测试集中的回归决定系数R2为0.826;BP反向传播神经网络模型在测试集中的回归决定系数R2为0.739。两种机器学习算法在室内照度分布预测方面具备发展潜力。
3)分别计算了两种算法在实测情况下各点传感器实测值与预测值之间的平均残差,以普通办公室工作面标准照度值300 lx为参考,其临近照度分级为200 lx和500 lx,照度差分别为100 lx和200 lx,各点残差均小于100 lx照度差,满足视觉舒适性,预测数据可用于照明系统的调光决策。
猜你喜欢
煤矿现代化(2021年3期)2021-05-21
煤炭工程(2021年3期)2021-03-26
辽东学院学报(自然科学版)(2021年1期)2021-03-12
水产养殖(2021年2期)2021-02-24
南方农业学报(2020年4期)2020-06-04
南方农业学报(2020年10期)2020-01-21
陕西煤炭(2020年1期)2020-01-09
应用心理学(2019年4期)2019-12-05
科学与财富(2018年12期)2018-06-11
