
网络新媒体视听监测数据库构架模式及巡检监测的探析
2022-04-22 10:56:48李敏
西部广播电视 2022年3期
李 敏
(作者单位:四川广播电视监测中心)
1 互联网视听网站监测系统采集识别技术存在的问题
随着广播电视融媒体的迅速发展,对网络视听持证机构和视听类网站的监测也越来越受到相关部门尤其是宣传管理部门的重视,视听类网站承担了越来越多重要时段的宣传任务[1]。但现有监测系统的网站采集技术,仍是基于通用网络信息采集技术(Web crawler),通过解析网页源代码或网页关键词来判断网站是否为视听类网站,并采集相关数据保存到本地集群存储中。在经过大量监测任务的实践后,笔者发现相对老化的采集识别技术明显存在着很多问题,导致视听网站的识别率较低,采集的可用数据率较差,主要问题如下:
1.1 视听类网站识别率较低
由于现在网站技术的多元化,特别是非持证网站,网页上存在大量欺骗性代码,不仅能欺骗搜索引擎,使搜索引擎产生误判,也会欺骗Web crawler,导致网站的误识别,ICP备案号的获取错误或无法获取。对监测工作的影响主要体现在如果不定时对数据库进行清理,那么数据库的容量将会被无效数据无限占用,数据库一直处于高利用率的运行状态。系统占用的计算资源被无限增加,不仅加大了对系统运维的难度,也使得系统的监测效率低下。
1.2 消耗资源巨大
因采集的可用数据率较差,在数据采集和分析过程中,消耗了大量的计算、存储、网络和数据库资源,导致系统在运行时反应较慢、监测任务效率低下等,在日常的监测工作中,这给监测业务部门和运行维护部门带来了较大的工作压力。
基于以上问题,笔者迫切地需要探索出一套优化的监测系统网站数据库构建模式,并寻求如何更加有效、准确地获取视听网站信息,以及如何设计和完善一套行之有效的自动巡检监测机制。Web crawler的工作原理图如图1所示。
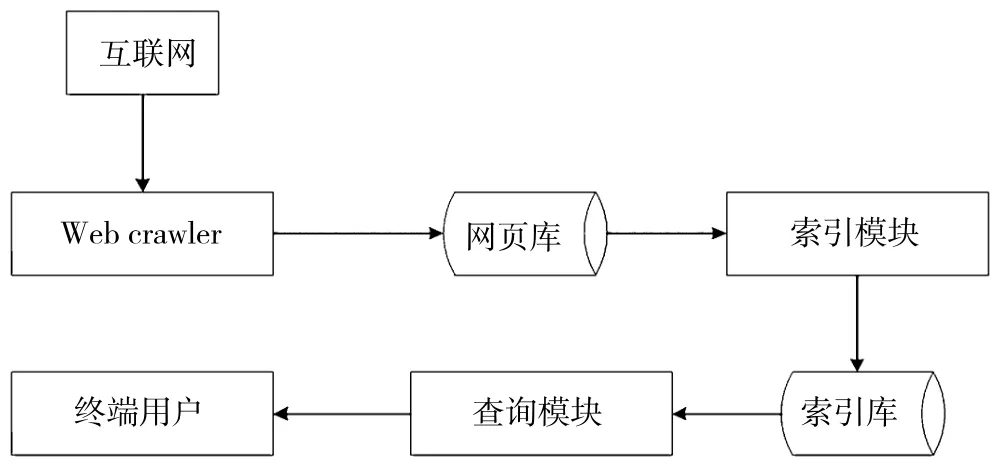
图1 Web crawler工作原理图
2 总体思路
本技术方案旨在实现准确、有效地获取视听网站信息,优化本地视听网站数据库的构建模式和完善视听网站巡检机制。根据新的视听网站数据库构建模式,对巡检监测机制进行重新设计和完善,并依据日常监测任务,尝试创建重点视听网站巡检列表,对数据库中的重点网站信息进行定期的智能巡检,实现对网站类型的判定监测,网站视听页面的标题、视听节目内容、文字简介信息采集监测,网站失效性判定监测和网络视听节目内容监测等。
根据日常监测任务和监测数据,整理出一份重点监测对象和数据清单,以此创建一套固有模式的巡检信息库,对重点网站和重要数据进行定向、定期的巡检监测。当每轮巡检结束后,对巡检信息库和系统数据库进行同步数据更新。利用有限的资源,完成采集日常绝大部分监测任务的数据,重点监测任务和临时监测任务则通过其他系统模块进行临时性的调整应对,在日常工作时,不再过多占用系统资源[2]。在理论上,通过以上方式,可有效地减少系统占用的计算、存储、网络和数据库资源,并在当前系统的暂无大规模升级更新的计划下,临时解决监测数据采集数据不完整、网站识别率低、采集效率低、漏监等问题。
3 方案设计
本方案主要采用的技术有端口扫描(Port scanning)技术、网络信息采集技术、视听数据判定技术、数据库技术等。
3.1 重点监测网站
根据统计日常监测任务的类型和监测对象,重点监测网站主要分为两类:一类是持有互联网视听节目服务许可证(AVSP)的网站(官方媒体网站),一类是国内互联网头部企业在四川省分支机构的网站(社会媒体网站)。官方媒体网站一般为电视台、出版社、广播电视网络公司或政府机构的官网,该类型网站的主要职能是权威发布有关党政机构的官方信息、热门话题、热点新闻的视频节目等。社会媒体网站一般为互联网企业开办的视听类服务网站,该类型网站的主要职能是转载或发布热点新闻、娱乐类的视频节目。
通过整理和归纳,将网站信息同时写入Web crawler程序和数据库。将原有Web crawler程序的70%修改为定向Web crawler和深层Web crawler,定制化地采集指定网站、指定网页和多层级网页的数据;空余30%的通用Web crawler用于采集通用网页的数据。利用1个月的时间,对反复采集的网页数据进行无效性筛查、核验,比对采集信息的一致性,并进行必要的修正,逐步完成网站数据库的构建和完善巡检监测清单(见图2)。
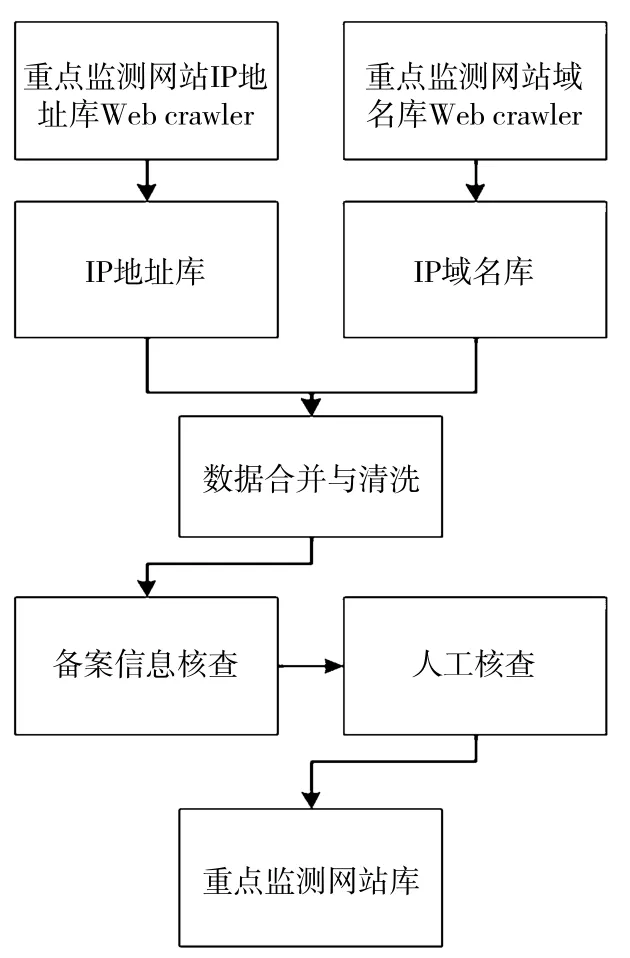
图2 重点监测网站发现流程图
3.2 视听网站数据库的构建
根据日常监测任务,对现有系统中的事件、人物、单位等关键词库进行重新归纳和整理,利用自动化渲染、特征提取等现有技术,将各类关键词与事件、人物等进行关联性连接。其中自动化渲染技术是采用服务器渲染完成对视听网站的访问动作,通过标签化数据,达到快速访问海量本地数据库数据的目的;特征提取技术是将网站中包含视频链接特征、视频播放器特征、视频图像特征、视频文本特征中的一种或多种特征加以标记,以实现视听网站的判别和分类,最终形成本地视听网站数据库(见图3)。
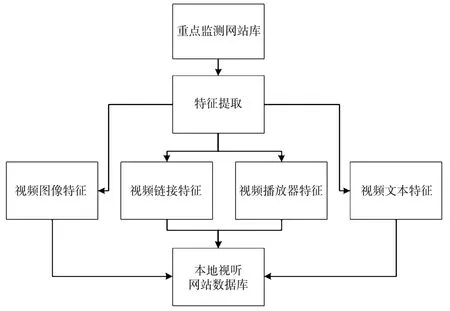
图3 视听网站数据库构建图
3.3 智能巡检监测
智能巡检监测主要由判断网站是否失效、网页是否更新、视听节目链接是否自动下载、视听节目链接中的文本内容是否自动保存等系统行为组成。
利用视听网站数据库,定期对数据库中的网站进行数据采集,若返回值为空值(null),则可判断网站已失效或已过期;对网站进行采集时,发现网页特性值发生变化时,即可认为是网站对网页进行了更新,并将更新的链接自动写入数据库,记录更新网页数量;对涉嫌违反《互联网视听节目服务管理规定》相关要求的视听节目,提取并下载该网页的文本描述和视频文件,通过特征提取技术,写入数据库。通过时间积累的数据和定期对Web crawler系统的更新维护,系统在反复循环此流程后,即可形成对视听网站的精确智能巡检监测。
4 运行测试
因新媒体监测业务不能中断,目前对系统只能进行补丁式的修改和技术探索分析。Web crawler是较为通用的一种网络技术,利用空闲的服务器资源,即可搭建完成,并对原有Web crawler服务器的替换,在替换过程中,对业务不会产生影响[3]。
利用云平台系统临时划分出两台虚拟机,针对四川省某新闻网站开展定向Web crawler和深层Web crawler系统的测试。通过对近一周的采集数据进行跟踪和对比,笔者发现对特定网站的名称、域名、链接、ICP备案号、AVSP证书号、文本等关键信息采集数据的准确性和采集率明显提高。测试前,通用Web crawler在3月22日至24日对持证网站的有效信息采集率为89.7%、91.5%和91.3%(见表1)。测试时,定向Web crawler、深层Web crawler在4月8日至10日对指定网站的有效信息采集率达到了97.2%、95.8%和96.3%(见表2),对网站有效信息的采集率上平均提升了5.6%。通用Web crawler采用通用模板,一般网页最多只能采集3层的网页链接,而定向Web crawler、深层Web crawler采用定制化的网站模板后,能采集最高达7层的网页链接(见表3)。

表1 通用Web crawler有效信息采集情况表

表2 定向Web crawler、深层Web crawler有效信息采集情况表

表3 定向Web crawler、深层Web crawler采用定制化网站模板后有效信息采集情况表
若以测试数据为基础,优化视听网站数据库的构建和智能巡检监测技术,系统不仅会更加智能化,更能提高网络视听节目的监测监管效率。
5 结语
近年来,随着互联网各种视听类业态的爆发式增长,视听节目也呈现出多元化的业务形态,主管部门对网络视听行业传播内容的监管要求也越来越明确,各系统的建设厂家对技术的敏感度很高,但对业务的敏感度相对会滞后。随着各项网络新媒体类的规章制度的发展和完善,监测部门在不断探索监测业务的同时,更需了解和掌握互联网前沿技术,在业务和技术上深入思考,将互联网技术逐步转变为实用性监测技术和监测手段,提升监测人员的监测能力,提高业务的智能化水平,为主管部门做好数据服务工作提供保障。
猜你喜欢
今日农业(2021年17期)2021-11-26 23:38:44
电子制作(2018年10期)2018-08-04 03:24:38
电子制作(2017年2期)2017-05-17 03:54:56
财经(2017年2期)2017-03-10 14:35:35
财经(2016年15期)2016-06-03 07:38:02
互联网天地(2016年2期)2016-05-04 04:03:28
互联网天地(2016年1期)2016-05-04 04:03:20
财经(2016年3期)2016-03-07 07:44:46
财经(2016年6期)2016-02-24 07:41:51
电子测试(2015年18期)2016-01-14 01:22:58
