
基于灰狼优化的随机森林模型的研究
2022-04-22 08:08范昊东
电子测试 2022年6期
范昊东
(黑龙江科技大学,黑龙江哈尔滨,150022)
0 引言
随机森林是一种组合分类器技术。既可以用于处理分类、回归问题,也适用于降维问题。随机森林对噪音有很好的容忍度且不易出现过拟合,稳健性强。随机森林算法中采用的bootstrap重采样技术是有放回的随机采样,即从原始的训练样本集中随机有放回地抽取与其等数量的样本组成1个采样集,重复n轮得到n个相互独立的采样集;然后利用每个采样集分别生成决策树,n个决策树共同构成森林。即把多个决策树的预测组合成一个模型。
由于随机森林算法中存在的一些问题,为了改进随机森林算法国内外学者们提出了很多方案,孙光民[1]通过优化群投票原理,使用分类与回归树进行预测,将预测结果从小到大排序,只取中间较好的CART用于最终的预测,缩短运算时间,减少预测误差。Mashayekhi等[2]基于爬山策略的贪婪方法,增删决策树来保证随机森林的多样性。Ishwaran等[3]通过引入生存树的概念,提出随机生存森林算法,构建生存函数,生成分析树的内容和预测结果进行综合,提高其分类的性能。薛铭龙等[4]通过设置不同的惩罚项因子可以在训练随机森林中生成结构不同的决策树。
上述改进算法均能有效提升分类精度,但改变决策树的结构,会增加算法的复杂性。增删决策树,虽然计算简单,但会导致随机森林陷入局部最优。所以需要一种简单高效的方法来计算出决策树间的相关性,丰富随机森林的多样性,进而提升随机森林的分类精度。为解决上述随即森林的问题,本文提出了一种基于狼群优化算法优化的随机森林模型,通过迭代优化决策树棵数、剪枝阈值等参数来实现对随机森林模型的优化。
1 随机森林模型及其优化
1.1 随机森林模型
随机森林算法中采用的bootstrap重采样技术是一种有放回的随机采样,从原始的训练样本集中随机有放回地抽取与其等数量的样本组成1个采样集,重复n轮得到n个相互独立的采样集;然后利用每个采样集分别生成决策树,这n个决策树连接形成“森林”。即由多个决策树的预测组合成的模型。
本文选用随机森林作为分类器,随机森林的学习过程可以用以下步骤描述:
(1)首先重采样采用Bootstrap方法,随机产生m个训练子集。
(2)然后基于划分好的训练子集生成对应的决策树。从特征变量中随机选择部分特征组成特征子集,在其中选取最优特征作为决策树节点的分裂属性。
(3)最后采用投票的方法集成各决策树对训练子集的预测结果,将m个决策树中输出最多的类别作为测试集样本所属的类别。
随机森林是让每一棵决策树进行分类,然后取所有决策树中分类结果最多的那类作为最终的结果。因此是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。该模型的优点包括对高维数据无需提前进行特征选择、有效克服单一预测器易陷入过拟合。随机森林模型的实质是一个有许多棵互不相关决策树的分类器。所有决策树都采用Bootstrap方法进行采样,从所有的决策属性中随机挑选出几个属性进行分类。训练完成后,当测试样本输入时,每棵决策树均对测试样本进行分类,通过投票的方法来决定测试样本的最终分类结果。
2 随机森林模型及其优化
随机森林与传统决策树算法不同,其具有不剪枝也能避免数据过拟合的特点,同时具有较快的训练速度,且参数调整简单,在默认参数下即具有较好的回归预测效果[5-6]。以上算法中,剪枝阈值、决策树棵数、预测试样本数等参数对随机森林模型的输出都有一定的影响。常用的群体智能算法有粒子群算法、人工鱼群算法、蚁群算法等。狼群优化算法也属于群体智能算法,狼群优化算法通过模拟灰狼群体捕食,快速选取最优解.本文通过将狼群优化算法引入随机森林模型,迭代优化随机森林算法中的参数,达到了较好的分类效果。
狼群优化随机森林算法的步骤如下∶
(1)确定随机森林算法的参数,随机设定出剪枝阈值、决策树棵数、预测试样本数、随机属性个数的初值;
(2)采用Bootstrap算法采样,随机生产训练集,并在每个训练集中选出预测试样本;
(3)利用每个训练集剩下的样本分别生成决策树;
(4)当结点内包含的样本数少于阈值时,将该结点作为叶结点,返回其目标属性的众数作为该决策树的分类结果;
(5)计算出模型的分类结果作为适应度值,采用狼群优化算法对其中的参数进行迭代优化,从而确定最终模型的参数。
3 实验验证及分析
本文利用加利福尼亚大学的UCI数据库的实验数据来验证随机森林模型中的参数对分类准确率的影响,选取Abalone数据集作为验证数据集,分别对剪枝阈值和决策树棵数进行验证.在实验部分上述UCI数据集上选取abalone数据,共包含8个属性。将数据集进行拆分,其中75%的数据作为训练集,25%的数据作为测试集。灰狼优化随机森林中的迭代优化的结果如图1所示。训练集预测结果如图2示.测试集预测结果如图3所示。
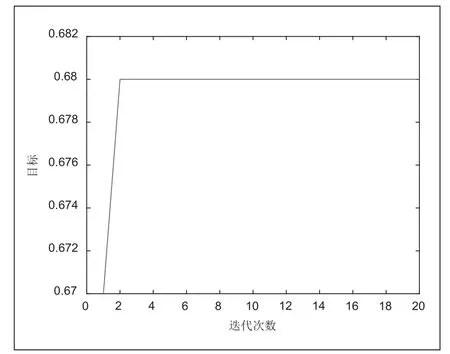
图1 灰狼优化随机森林中的迭代优化
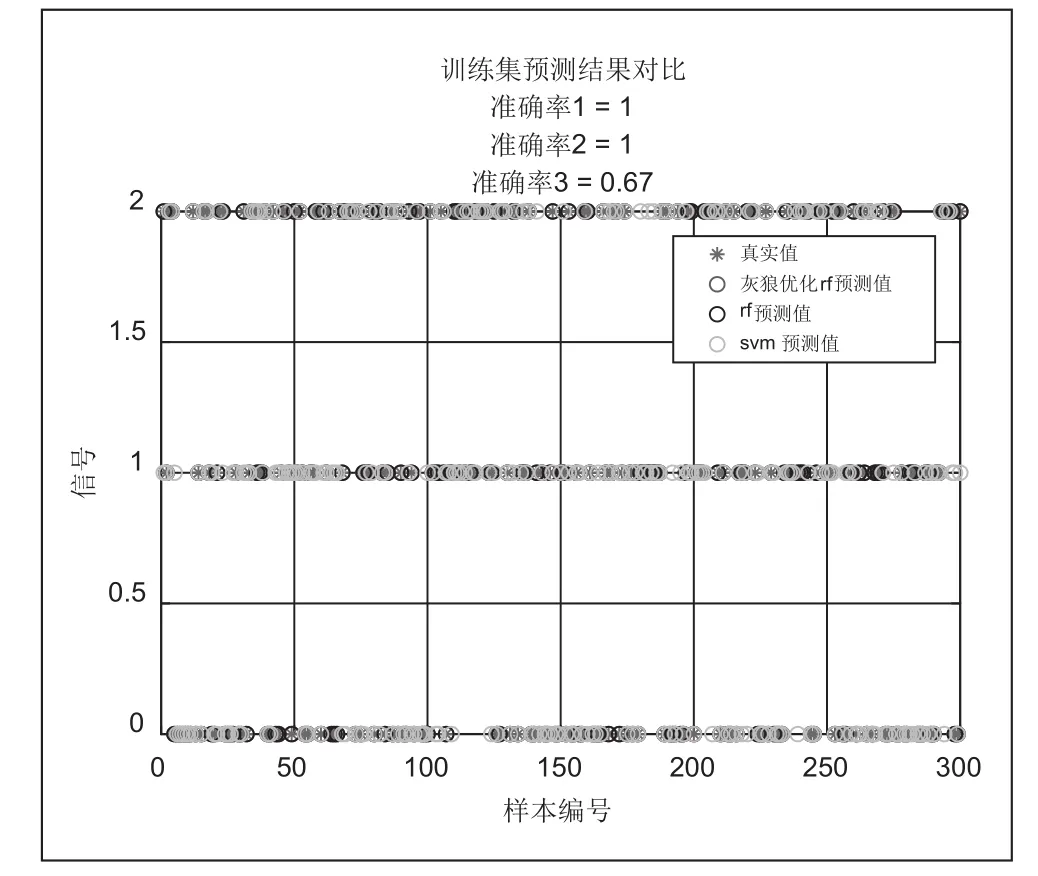
图2 训练集预测结果

图3 测试集预测结果
本文采用狼群优化算法对模型进行优化,并在5组数据集上进行测试。将其训练结果传统随机森林(RF)、支持向量机(SVM)进行对比,结果如表1所示。表1中记录了所有算法对5个数据集的平均分类正确率。
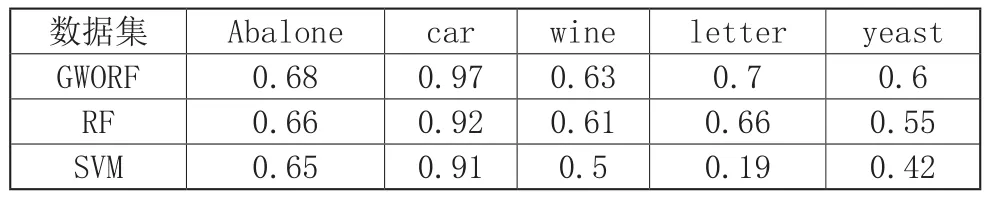
表1 不同算法分类性能比较
4 结束语
本文提出了一种基于灰狼优化算法的随机森林模型。在5个验数据集上该模型都取得了良好的表现。通过对比不同算法对分类性能的影响,选择出最优的算法。经过与传统随机森林算法和SVM的分类结果的对照,本文提出的基于灰狼优化的随机森林模型分类正确率均比传统随机森林算法和SVM高。
猜你喜欢
世界科学技术-中医药现代化(2021年8期)2021-12-21
数学小灵通(1-2年级)(2021年4期)2021-06-09
小学阅读指南·低年级版(2021年3期)2021-03-19
小太阳画报(2019年1期)2019-06-11
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
数学大王·低年级(2018年5期)2018-11-01
电子制作(2018年16期)2018-09-26
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
快乐作文·低年级(2017年3期)2017-03-25
