
基于深度学习的业务稽查规则知识图谱构建
2022-04-20 07:24余安国刘继鹏郭伟孙志杰张艳丽
电子设计工程 2022年7期
余安国,刘继鹏,郭伟,孙志杰,张艳丽
(国网冀北电力有限公司营销服务中心(资金集约中心、计量中心),北京 100032)
随着我国经济社会和科学技术的不断发展,互联网大数据技术在社会生产生活中得到越来越广泛的应用,知识图谱技术也应运而生[1-2]。知识图谱技术主要包括应用数学、信息科学和可视化技术等,将相关联的知识内容根据其关系进行关联图谱划分构建,整合成一个相互关联的知识信息关系图谱。比如在浏览器中输入一个关键词,出来的搜索界面中会推荐与其存在关联关系的其他关键词,并且随着搜索关键词次数的增加,推荐的关联性内容信息增多[3]。
知识图谱技术能够从整个互联网资源中提取知识信息,为用户提供系统化、关联化的关键词知识体系。目前的许多浏览器、社交软件和其他网络平台都需要应用知识图谱技术[4]。
随着知识图谱技术的推广与普及,该文针对许多企业公司或事业单位业务稽查规则方面存在的问题,基于深度学习方面的原理和技术,构建了业务稽查规则知识图谱,有利于相关企业单位提高自身业务稽查的管理能力和工作效率。
1 业务稽查规则信息采集
构建业务稽查规则知识图谱首先需要对该企业所需的业务稽查信息内容进行采集整理,完成实体抽取和关系挖掘[5]。针对营销业务方面,由于各部门负责的工作内容具有一定的分散性和独立性,需要将分散的管理规则分别采集到一个统一的数据库中。将各部门内的业务稽查规则从系统中复制并提取出来,按照部门进行分类整理,根据数据处理系统的业务规则内容进行数据预处理,检验业务规则内容的合理性,筛选并排除存在异常的业务规则和管理内容。
将所有正常的业务稽查规则整合到一起后,进行业务规则的关系挖掘[6-7]。根据企业设定的稽查主题和核心规则,制定支持主题核心规则的相关稽查规则。依据规则的内容要求,提取业务规则数据库内部的相关关键词,并按照关联度进行排序,根据关键词所属的业务规则,将相关联的业务规则进行关系搭建[8-9]。知识图谱信息业务关系如图1 所示。
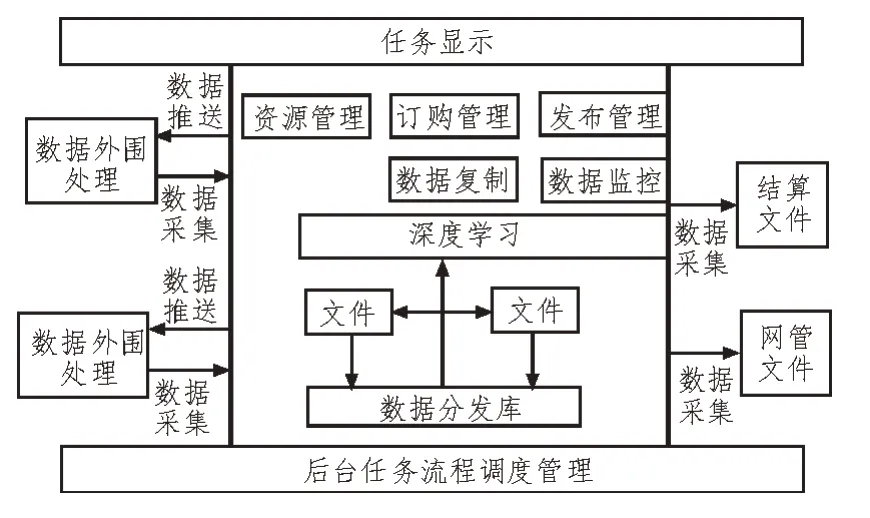
图1 知识图谱信息业务关系
上述分析初步对业务稽查规则的关系进行搭建,为了实现业务稽查规则知识图谱的智能化,需要对业务规则内容和关键词进行相关的语言描述。将初步形成的关联关系业务稽查规则内容,通过系统检索程序进行相关描述内容检索,参与业务稽查规则知识图谱的构建,有利于实现该知识图谱的智能化[10]。
2 业务稽查规则知识图谱构建
业务稽查规则知识图谱构建过程包括两个主要步骤:知识要素识别和关系分析,基于深度学习的业务稽查规则知识图谱构建流程如图2 所示。
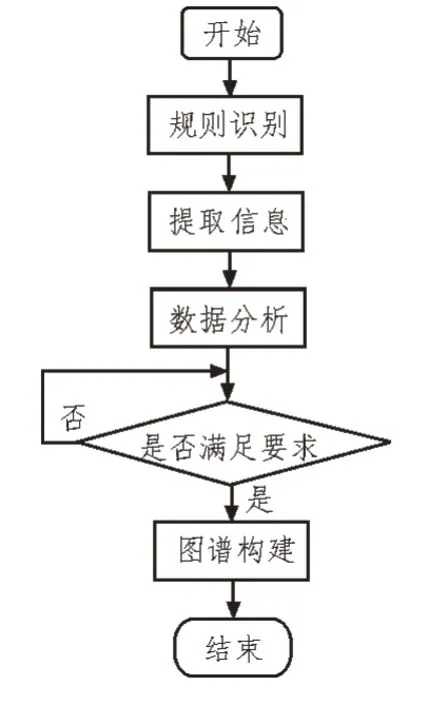
图2 业务稽查规则知识图谱构建流程
2.1 基于深度学习的业务稽查规则知识识别
业务稽查规则知识实体识别通过NLP 自然语言处理和深度学习模型算法来实现。将之前采集整理好的业务稽查规则信息资源传输到数据处理系统,系统的数据处理程序先对业务规则内容进行内容知识实体识别,并对识别出的知识实体进行关键词特征提取,包括词汇特征、语言特征、关联特征等,根据特征情况对知识实体进行相关描述,然后将描述信息对应标注在知识实体内容中[11-12]。知识识别内容如图3 所示。
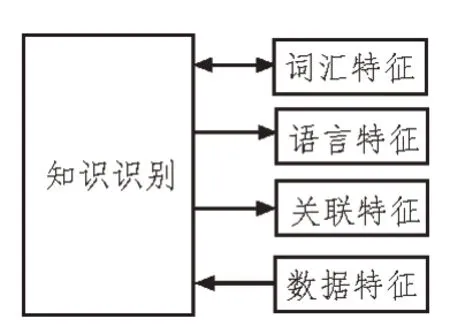
图3 知识识别内容
NLP 自然语言处理技术主要负责业务规则内容和相关语言描述在计算机语言和自然语言的相互转化,实现人机之间的自然语言通信。在自然语言处理技术的基础上,对知识图谱的知识实体进行识别分析。知识实体识别一般以相关词典为基础,对业务稽查规则进行知识图谱构建,可选用业务稽查规则相关词典作为识别基础。将字典中的关键词汇及其描述的相关特征导入识别程序中,然后采用深度学习算法,对业务规则知识图谱的样本信息数据进行关联运算。根据运算所得的关联程度,对知识实体和相关词条进行关系识别[13-14]。根据深度置信网络进行知识实体和关系识别的运算。关键词特征判定公式为:

式(1)中,v表示该词汇的所属特征判定结果,d表示其对应的描述特征,E表示存在关联性的词汇。运算结果越接近于1,则表示两词汇的关联度越高,词汇存在的关系越强。然后对词汇在其所属文档或网页出现的频率进行计算,公式如下:
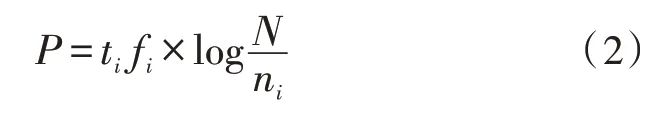
式(2)中,P表示词汇在其所属文档或网页出现的频率,ti fi表示词汇ti在文档或网页fi中出现的次数,N表示知识图谱数据库中的文档总数,ni表示该文档出现词汇ti的相关词汇树。根据此公式能够得出词汇的重要性和与其相关的关联文档,进而获取多个文档之间存在的关系。
基于特征法对关键词汇进行关系识别判定,得到的特征识别结果如图4 所示。
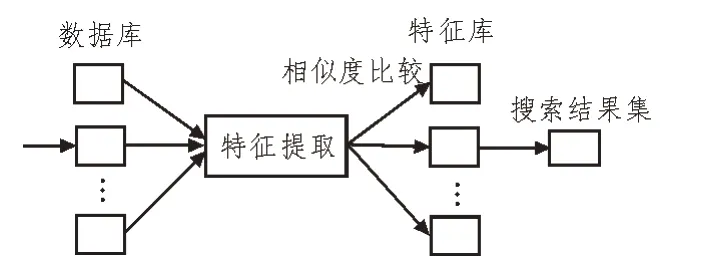
图4 特征识别结果
根据图4 可知,对获取到的知识实体词汇及其关联词汇和文档进行语言处理和关系识别。知识实体语言作为分析对象,根据描述特征选择不同的识别方法,比如字符特征、词性特征、含义内容等。更具体的识别可根据业务稽查规则的相关词汇分类进行特征关系识别,比如人名、地名、机构名称、专业工作词汇等。在业务稽查规则知识图谱中,关键词汇或语言主要包括稽查目标、问题描述、快速输出、与稽查目标相匹配的稽查主题和业务管控规则等。
根据描述特征对存在关联关系的词汇和语句进行特征识别分析,推断出两者之间的关系性质,并进行关系定义描述,增加关联词条解释,同时双方所属文档也参与到这两个词汇或语言的关系图谱构建中;对于文档内容的关系识别,则需要从关键词双方的关联程度入手,结合其他语言描述关系的识别结果和关系判定结果进行关联关系构建,并对关系描述词条加以注释[15-16]。
2.2 业务稽查规则知识图谱构建
在完成了业务稽查规则知识特征提取和关系识别后,整合其关系处理数据资源,对业务稽查规则知识图谱进行构建。将分析处理好的知识实体信息和相关数据按照一定的关系进行划分。分批次导入到模型构建系统的数据库中,系统采用Cypher 语言对词汇和文档关系模型进行框架程序编写。Cypher 能够在系统资源数据库和互联网平台中,查询词汇或文档的关联节点和所有关系特征的关键描述,根据检索所得的关系结果进一步完善词汇之间的关系网和关联描述,层层推进,构建互相关联的关系网。同时Cypher 还能够根据查询到的关系信息对其关联度进行个性化的判定,依据关联程度的大小构建紧密程度不同的关系网。因此,使用者在使用该知识图谱时,系统会根据搜索关键词的关联程度推荐关联度较高的信息内容,其他内容推荐的数量根据关联程度依次递减,使用者能够享受到比较个性化、智能化的检索服务。此外,该图谱与系统数据库保持同步联系的状态,会对检索内容进行相关的记录,并随时更新录入的信息资源,保持知识图谱的实时性,保障企业单位的业务稽查规则和相关工作内容记录的真实性、完整性。构建的业务稽查规则知识图谱如图5 所示。
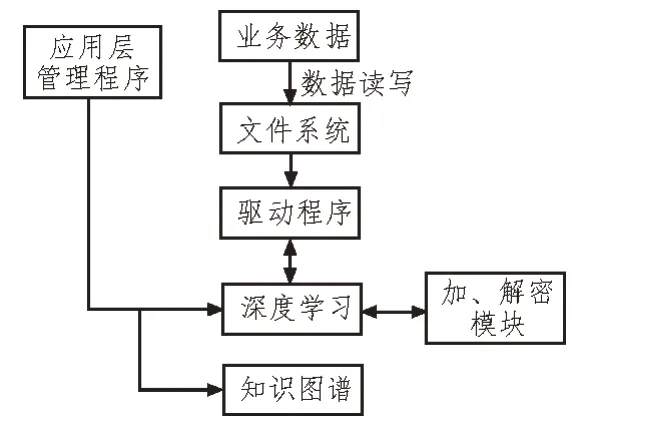
图5 构建的业务稽查规则知识图谱
同时业务稽查规则知识图谱还具备检验功能,能够根据自身的检索规则对业务内容进行检验分析,对于存在问题的部分内容,可自动进行错误指出和修改纠正,智能解析稽查工单的原始信息和核实后的原因说明,提出稽查核实步骤和整改措施指引等反馈信息,判断导致异常的原因类型,并标记问题产生的原因标签,辅助业务人员开展工作,提升稽查规则的创建维护管理效率,从而实现业务管控支撑的智能化。采用Python 语言对知识图谱进行模块操作训练。图6 为基于深度学习的业务稽查规则知识图谱工作运行流程。
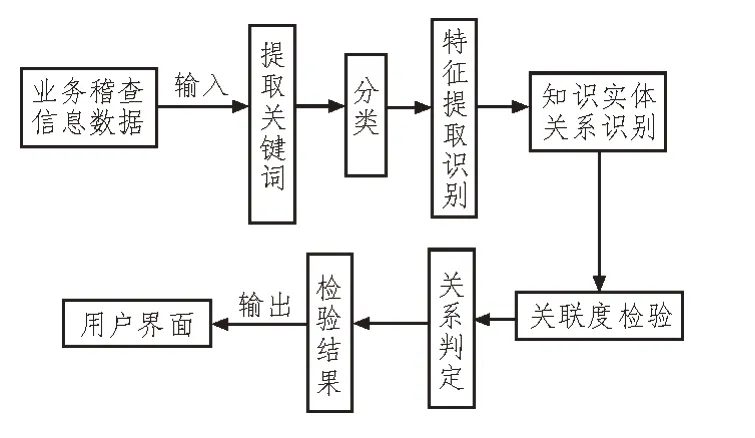
图6 基于深度学习的业务稽查规则知识图谱工作流程
选取该企业的本季度业务工单为实验对象,对其进行问题稽查,检验其存在问题的类型。将公司业务工单内容等信息资源传输到知识图谱处理系统中,进行词汇提取分类和特征提取识别,根据其特征和相关描述获取词汇和语言之间的关系描述,并做好标注;然后进行信息数据集检验,检验业务规则信息内容的正确性,判断工单信息是否存在问题,在知识图谱系统中,根据其关键词和关系描述情况对不同文档或词汇之间的关联程度信息内容进行判定,若存在问题则标注出问题原因;最后将检验结果输出到用户显示界面中。
3 实验研究
为了检验构建的基于深度学习的业务稽查规则知识图谱的实际应用效果,该文进行了实验研究,以某公司本季度的业务情况和工单资料为实验数据样本,通过业务稽查规则知识图谱识别检验出公司业务工单中存在问题的类型。实验采用配备Windows 10 系统、MySQL 数据库、储存内存为256 GB 的计算机为基础设备。
采集的数据信息如表1 所示。

表1 数据信息
根据表1 可知,该文的知识图谱构建方法识别的信息更多。
关系识别的准确度越高,对内容判断的准确率越高,对业务工单存在的问题的检验结果越准确。该文选取了传统的业务稽查规则知识图谱进行对比实验操作,记录并比较关系识别结果的准确率,其识别结果准确率如图7 所示。
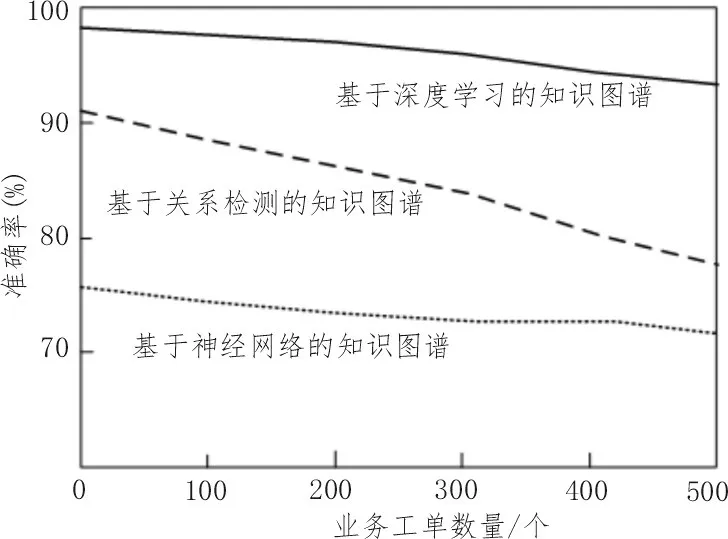
图7 业务稽查规则知识图谱识别准确度
从图中信息可以看出,基于深度学习的业务稽查规则知识图谱的关系识别准确率均在90%以上,虽然随着检验数量的增加有所下降,但基本变化比较稳定,体现出其识别效果比较良好;基于关系检测的知识图谱识别准确率一开始比较高,随着检验数量增加,准确率下降较快,当检测数量达到500 时,准确率已经低于80%,说明其识别准确率受检验数量影响较大,不适合进行大量数据关系的识别;基于神经网络的知识图谱准确率保持较为稳定的水平,基本在75%左右,关系识别准确率不高。
4 结束语
该文针对目前社会经济的发展需求,构建了基于深度学习的业务稽查规则知识图谱,并进行了实验研究。实验结果表明,基于深度学习的业务稽查规则知识图谱具有良好的应用效果,能够满足当前企业单位对业务稽查方面的技术需求,同时能够为相关领域的知识图谱研究提供一定的技术参考。
猜你喜欢
军事文摘(2022年24期)2022-12-30
客联(2022年3期)2022-05-31
世界科学技术-中医药现代化(2021年7期)2021-11-04
中国新闻周刊(2021年26期)2021-07-27
湖南税务高等专科学校学报(2021年3期)2021-07-21
少先队活动(2020年12期)2021-01-14
中国交通信息化(2020年12期)2020-02-06
中国交通信息化(2019年8期)2019-11-04
中国交通信息化(2019年7期)2019-10-08
电脑爱好者(2017年7期)2017-05-06
