
基于深度学习与步态分析的身份识别算法
2022-04-20 07:23王金珠
电子设计工程 2022年7期
王金珠
(河北北方学院附属第一医院,河北张家口 075000)
新型冠状病毒疫情的爆发给世界各国的医疗卫生行业带来了巨大风险和压力,为了减少医院的疾病传播风险,众多医疗机构采用计算机技术对医护人员进行身份识别。由于医护人员通常身着防护服和各种护具,传统的人脸、指纹、虹膜等生物特征识别方法[1]无法使用。为此,步态身份识别成为一个研究的热门话题。该种识别方法可以远距离识别且无需医护人员进行防护暴露,具有非侵犯性、无需刻意配合和分辨率高等优点[2]。
1 步态识别技术
通常情况下,步态识别的研究方法主要有两类:基于模型的方法和非模型的方法。目前,大部分研究均是基于模型的,该方法首先将人体模型与系统的输入图像进行匹配,然后通过建模提前预测运动者的步态特征,从而实现识别功能[3]。王修晖等人提出了基于连续密度隐马尔可夫模型,利用自然步态周期进行特征提取,然后构造观测向量集,最终用Cox 回归分析实现步态识别[4]。More S A 等人构造了双通道小波滤波器组来分析杂乱无序的步态,从而进行识别并获得了较高的准确率[5]。传统的机器学习算法虽然在步态识别领域有一定的发展,但识别准确率较低,尤其是在视角变化和着装干扰的情况下,几乎无法满足实际应用[6-9]。
目前,基于深度学习算法的步态识别方法虽然取得了较为理想的效果,但由于使用卷积网络获取特征,导致图像特征丢失,只能反映出局部信息,而且当存在外部干扰因素时,如拍摄角度多变、行人穿着多样,识别效果将显著降低。为了解决这些问题,文中提出了新的顺序残差卷积神经网络(SRCN),其中卷积神经网络被优化,以理解时间序列的运动特征。具体而言,时空信息学习通过行为信息提取器(BIE)和多帧聚合器(MFA)两个子块进行,采用权重共享残差神经网络(ResNet)提取每幅图像的空间特征。然后,BIE 通过学习表示运动的行为模板来分析时间序列中帧之间的关系。最终,MFA 将整合并提取所有特征从而实现步态识别。
2 理论方法与算法设计
文中提出了一种新的顺序残差卷积神经网络(SRCN)模型来进行步态识别,整体框架如图1 所示。首先输入一组图像序列,然后将每一帧按顺序输入3组类似结构。每个结构包含一个过渡块和一个步态块,以此提取出每个帧的时空特征。最后,构造了一个多帧聚合器(MFA),用一个序列来整合所有特征。
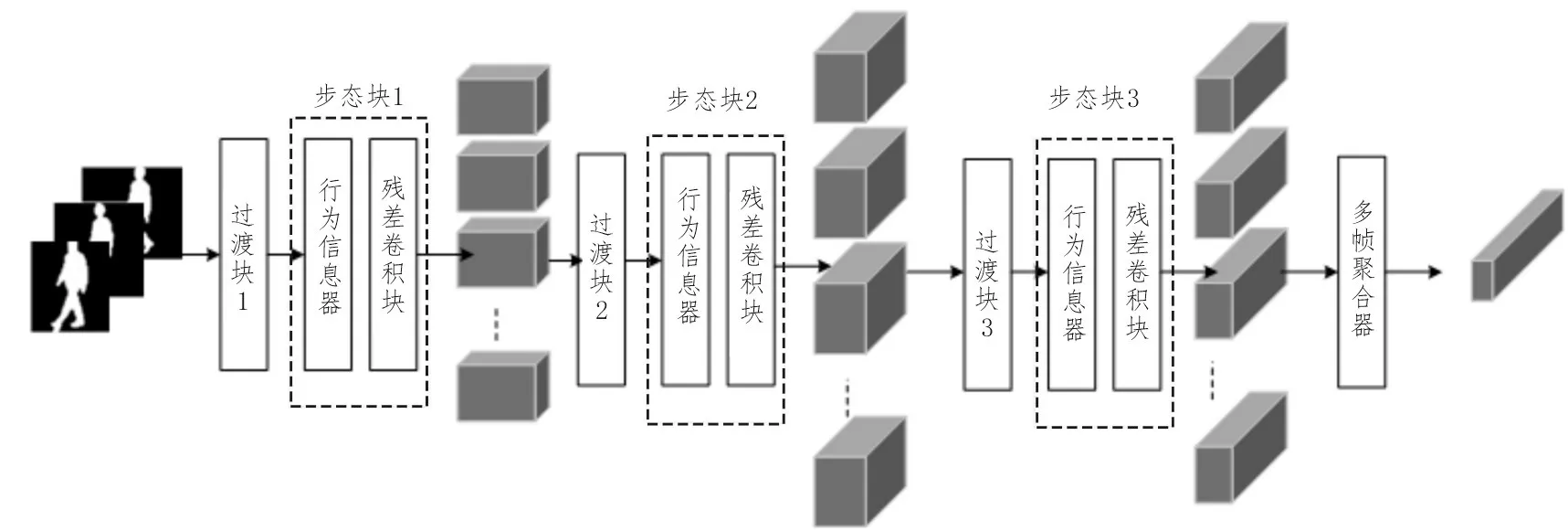
图1 整体框架图
2.1 基于运动模板的行为信息提取器
由于卷积神经网络在处理连续视频信息方面存在困难,其更适合于处理分析单个图像。因此,卷积神经网络更多地关注于每个图像中人的外观来进行识别。实际上,步态识别希望利用人们的行走习惯和行为进行识别,因此文中提出了一种新的卷积方法——信息提取器。首先通过一组序列特征计算出运动模板,然后将模板表示的运动信息引入到原始特征中,从而使卷积可以提取时间信息。
运动模板的目的是从一系列特征中提取运动特征。由于卷积网络无法理解帧之间的顺序与关系,因此需要使用模板来探索和分析图像特征的相关性。该文构建了3 种类型的模板来表达这种相关性,分别基于差异、多差异和去除静态信息。
基于相邻帧间特征差异的模板,从每一帧图像中提取的特征图代表每个步态轮廓的抽象信息。由于特征是通过权重共享网络学习的,因此相邻特征之间的差异可以反映出运动信息。第k个模板td,k可以表示为:

其中,Finput,k为第k帧的特征模板,Td为差异模板。
基于相邻帧间特征多差分的模板,由于将两帧作为一个运动单元的可能很小,因此使用相邻帧间特征多差分的模板来覆盖更多的运动信息,具体第k个模板tmd,k用公式表示如下:
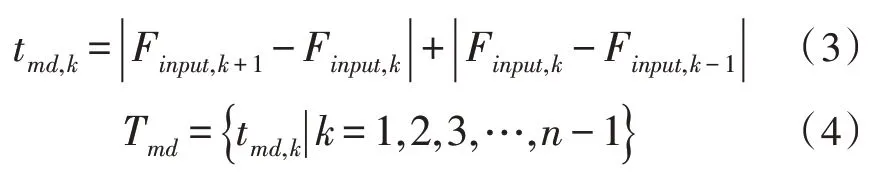
由于个体的静态特征在序列的每一帧中均是相同且具有通用性的,因此公共共享特征可看作是静态信息的近似。该文使用均值滤波来提取静态特征,如式(5)所示。值得注意的是,其也可以使用式(6)所示的中值滤波方法,两者并无明显差异。每个帧的原始特征与静态特征之间的差异可以表达动态信息tse,k,其表达式为:
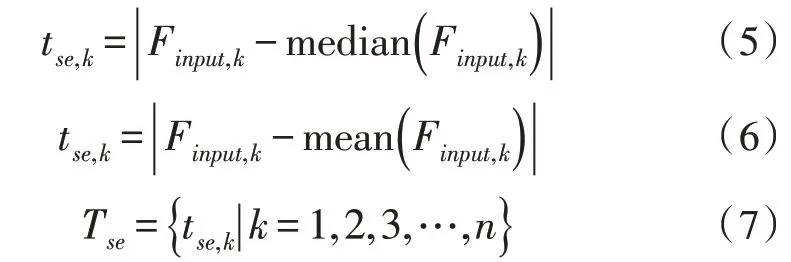
2.2 引入残差神经网络
该文采用的网络结构是残差神经网络(ResNet)[10],其解决了梯度爆炸的问题,并能够加速神经网络的训练过程。ResNet 的适用性良好,可以用于目前的多种现成网络框架。通过在网络结构模块中添加一条直连通道,这样就保留了前一层网络的输出特性,可以将最开始的信息传递到后续的网络层,尽可能地保留图像的特征。而下一层在学习特征时,则只需学习输入和输出差别部分的信息即可,这样就大幅提高了识别效率和准确率,如图2 所示。
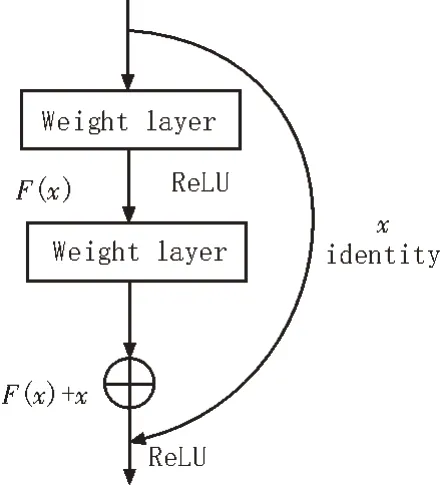
图2 ResNet残差学习模块
根据残差学习模块的概念,可以将其定义为:
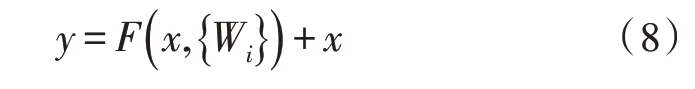
其中,x、y代表所考虑层的输入和输出向量,F(x,{Wi})代表要学习的残差映射,通过快捷连接和逐元素添加来执行。
2.3 多帧聚合器(MFA)
步态识别的本质是一项视频理解任务,虽然上述步骤只能学习每一帧图像的特征,但也考虑了相关的帧间信息。多帧聚合器MFA 的目的是整合所有帧级信息F来学习序列级特征输出的区别性特征featureoutput:
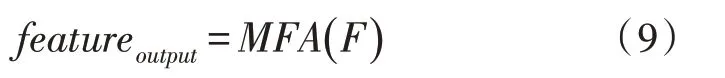
其中,F={Fi|i=1,2,3,…,n}。由于行人与相机之间的距离变化,步态轮廓大小不同,所以视频通常需要通过预处理将数据调整为相同的大小。此外,由于步态视频的长度n在现实生活中是不确定的,难以部署一个固定的地点作为MFA,所以一些经典的方法直接采用统计函数来解决上述问题[11-12],例如max(·)和mean(·)。但这些方法过于简单,无法融合帧级信息,该文设计了一个移动聚合器来解决这一问题。
从第一个特征开始,将F切成长度为L的分段,然后将分段送入残差网络卷积层,得到相应的集成特征Foutput,1。接着卷积网络以最小单元为步幅进行滑动,将分段有序地发送给卷积网络。即卷积网络在F上滑动,滑动窗口的长度为L,因此Foutput,j是基于每个分段FS,j进行学习的。
3 实验与数据分析
3.1 数据集
该文使用CASIA-B 数据集进行实验验证,该数据集是目前最常用的步态数据集之一。其包含了124 名实验者的视频图像,每个实验者包含11 个(0°,18°,36°,…,180°)行走视图和3 个行走条件(正常情况、携带包、不同衣服)。每个视图下的每位实验者有6 种正常情况下的序列(NM)、两种携带包的序列(BG)、两种衣服的序列(CL)。所以一个受试者在一个特定视图上有10 个序列,共110 个序列[13]。在该方案中,前74 名受试者被部署到列车组,其余50 名受试者保留测试。在测试过程中,NM (NM1-4)的前4个序列构成图库集,其余6 个序列包含在探针集中,探针集分为3 个子集:NM5-6 的NM 子集、BG1-2 的BG 子集、CL1-2 的CL 子集。
3.2 实验环境
该文采用的编程语言为Python3.6,实验服务器配置处理器为Intel Core i7-8550,内存64 GB,显卡GTX2080×2,操作系统为Linux。由于PyTorch 机器学习框架具有使用简单、性能优越的特点,故实验采用该学习框架。
3.3 训练过程
顺序残差卷积神经网络SRCN 中的过渡和卷积块结构是基于残差学习的,由卷积层、Max Pooling层和Leaky ReLU 激活函数组成,3 个块的输出通道依次为32、64 和128。此外,卷积层的核为3×1×1,步长为1,输出形状与输入形状相等,卷积块如图3所示。
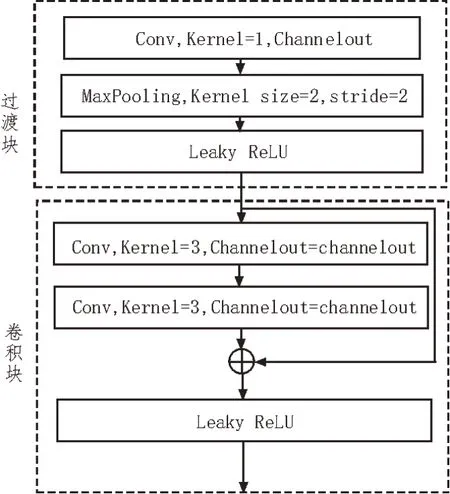
图3 卷积块
首先得到输入轮廓的步态边界框,然后对轮廓帧进行对齐并调整大小为64×44,训练片段的长度设为30。具体而言,即丢弃长度小于15 帧的原始序列,对长度大于15 帧但小于30 帧的原始序列进行重复采样。
3.4 实验结果
为了验证所提模型框架的有效性,表1 给出了该文方法与同类文献在NM 子集上的实验结果数据对比,表中的结果是11 个图库视图实验的平均值,可以看出文中提出的方法在多视图中表现出了更优的结果。对于CNN-LB 和步态关节,它的输入是可以代替视频的步态图像GEI 的,这种预处理方法可以降低计算复杂度和计算量,但可能会忽略运动特征,导致精度不理想。Partial RNN 将步态序列视为一组混叠图像,并将部分方法应用于Partial RNN 中以增强鲁棒性。虽然优化设计的网络可以提取轮廓特征,尤其是部分Partial RNN 的结果与SRCN 同样较为理想,但其忽略了表明行为模式帧之间的关系,在应用中,难以实现行为模式的准确识别,而且扩展性差。值得注意的是,虽然Partial RNN 和SRCN 从不同的角度解决了步态识别中的障碍,但是SRCN并不注重外形轮廓,相反其可以通过分析时间序列中的顺序来学习行为信息。PoseGait 采用骨骼来表示物体的运动,简单高效,但忽略了物体的外观,降低了识别精度。GaitNet 可以通过三维卷积和LSTM学习运动特征,这是一种比较复杂的方法,会大幅增加计算量,而该文方法只是基于卷积层,故而较易于实现。

表1 实验结果数据
4 结束语
该文提出了无需用户配合的基于深度神经网络的步态识别模型方法,该方法包含行为信息提取器和多帧聚合器,行为信息提取器通过分析帧间关系的运动模板来理解时间序列中的中间特征图,从而提取出行走模式信息;多帧聚合器可通过移动卷积层集成可变长度序列的特征。实验测试结果表明,该文所提出的方法更具优势,识别率更高。但由于目前各医疗机构所采用的视频收集设备不统一,且存在人员地域步态差别较大等问题,因此在应用时仍需要进一步优化模型,并优化选取硬件设备。
猜你喜欢
现代仪器与医疗(2022年4期)2022-10-08
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2020年10期)2020-11-14
电子制作(2019年13期)2020-01-14
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年11期)2019-07-04
电子制作(2018年18期)2018-11-14
科学之谜(2018年4期)2018-09-17
