
一种用于甲骨字符提取的双分支融合网络
2022-04-08 13:01:28刘国英陈双浩焦清局
厦门大学学报(自然科学版) 2022年2期
刘国英,陈双浩,焦清局
(1.安阳师范学院计算机与信息工程学院,河南 安阳 455000;2.郑州大学信息工程学院,河南 郑州 450001)
甲骨拓片,作为甲骨文字的重要载体,由于某些历史原因,长久掩埋在地下的废墟中,因此,在甲骨拓片表面不可避免地存在一定的退化,例如:噪声、裂痕等,如图1所示.这些不同程度的退化严重干扰了甲骨文字的可视性及可读性,对后续甲骨文字检测与识别等视觉任务带来极大的阻碍.考虑到甲骨字符是甲骨学研究的第一手资料,从甲骨拓片图像中自动提取甲骨字符将有助于甲骨学研究的开展,并对甲骨文活化与利用产生重大帮助.
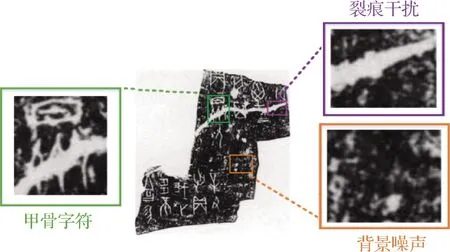
图1 甲骨拓片图像局部特征展示Fig.1 Local feature display of oracle rubbing image
由于甲骨拓片图像表面存在着严重的退化、污染问题,自动化提取拓片图像中的甲骨字符是一项极具挑战性的任务,其具体面对的问题有:1) 甲骨拓片表面包含大量不规则的噪声,这些噪声密集的分布在拓片图像表面,不仅干扰字符特征的识别,还容易增加字符提取模型过拟合风险. 2) 甲骨拓片表面存在各种样式的裂痕干扰,这些裂痕具有不同的尺度和形状并且在外观上和甲骨字符十分相似,严重干扰甲骨字符的识别.3) 甲骨字符在拓片图像中的位置信息、几何先验等是未知的,为字符特征的判别及约束字符在空间上的完整性上,带来了极大的阻碍.
甲骨学是一个极少数人参与的冷门学科,在图像处理领域,少数的方法被用于解决和拓片图像相关的计算机视觉问题.如:Liu等[1]基于甲骨字符的数据特征对描点框的大小、宽高比进行重新设计,并提出空间金字塔块结构以稳定特征和缓解噪声干扰.Meng等[2]将SSD300(single shot multibox detector 300)[3]扩展到SSD1024,构建了单阶段的甲骨字符检测模型.王浩彬[4]搭建了基于区域的全卷积网络(region-based fully convolutional networks,R-FCN)[5]的甲骨字符检测框架,并提出一个甲骨字符识别辅助检测算法,帮助检测模型减少对容易误检的甲骨裂痕的误判.Liu等[6]利用卷积神经网络(CNN)强有力的图像特征描述能力,设计了基于CNN的甲骨字符识别算法.Li[7]通过提取甲骨字符的行特征,用于甲骨字符的识别.然而,这些方法大多数侧重于预测甲骨字符在拓片图像中的位置或对单个甲骨字符进行识别,几乎不存在专门的方法用于提取拓片图像中的甲骨字符.
近几年来,随着深度学习在诸多视觉领域的成功应用,出现了一些在理论上能够直接或间接用于提取拓片图像中甲骨字符的方法.这些方法大致分为两大类:基于图像生成的方法和基于图像分割的方法.图像生成的方法(如Pix2Pix[8])将甲骨字符的提取视为一个图像到图像的转换任务,通过训练一个端到端的神经网络,学习拓片图像与相应字符图像间的映射.基于图像分割的方法(如U-Net[9]、SegNet[10])将甲骨字符提取视为像素分类任务,通过对拓片图像进行逐像素分类,预测出字符在拓片图像中的所在区域.然而,在实验中,上述方法提取的甲骨字符的效果往往存在一定的问题.相比于基于生成的方法,基于分割的方法对背景和字符特征有较好的区分,但得到的字符图像往往比较粗糙,存在字符笔画粘连、模糊等问题,如图2(b)和(c)实线框所示;而相较于基于分割的方法,基于生成的方法具有较强的结构信息描述能力,生成的甲骨字符在局部笔画细节上更为清晰,但往往会受背景噪声和裂痕的干扰,如图2(b)和(c)虚线框所示.

图2 基于分割和生成方法的甲骨字符提取结果Fig.2 Character extraction results based on segmentation and generation methods
为充分利用基于分割方法的背景噪声去除能力和基于生成方法的结构信息描述能力,本文将两种方法相结合,构建了一个甲骨字符提取的双分支融合网络(dual-branch fusion network for extracting Oracle characters,EOCNet)模型.EOCNet将甲骨字符提取任务视为图像到图像的转换任务,以生成网络为模型的基础架构,将分割网络嵌入编码器网络以消除拓片背景噪声的影响,以期建立更为准确的拓片图像与对应甲骨字符图像间的映射关系.具体地:1) 为了缓解拓片图像中背景噪声和甲骨裂痕的干扰,EOCNet的生成网络包含一个嵌入学习分支以实现特征嵌入空间中甲骨背景和甲骨字符的可判别特征的学习;2) 为适应拓片图像中甲骨字符大小的变化并生成清晰完整的甲骨字符图像,EOCNet将残差模块和多尺度特征通道连接,在生成网络中构建了一个字符生成分支;3) 为了在降低甲骨噪声和甲骨裂痕干扰的同时保证字符在空间结构上的完整性,生成网络利用空间注意力模块对两个分支的结果进行融合;4) 为保证生成的甲骨字符图像整体完整且细节清晰,EOCNet采用与文献[11-12]类似的生成结果判别方法,基于全局判别器和局部判别器来评估生成的甲骨字符图像的一致性.
1 EOCNet的构建
本研究构建的EOCNet由生成网络和判别网络构成(图3).
1.1 生成网络
生成网络包含两个共享特征编码的子分支:字符生成分支和嵌入学习分支(图3).字符生成分支学习拓片图像到对应字符图像之间的映射;嵌入学习分支学习拓片背景和字符的可判别特征嵌入.在训练过程中,两个分支并行执行,相互补充,相互适应.
1.1.1 嵌入学习分支
嵌入学习分支以原始的甲骨拓片图像IO作为输入,经过前向传播,最终产生一个嵌入特征图IE和字符区域得分图AC.在网络结构上,嵌入分支由5个卷积块组成的编码器和一个多尺度特征融合模块(2个3×3卷积+并行的2个3×3卷积)构成.训练过程中,编码器首先对原始拓片图片输入进行特征编码,以获取多个尺度的特征图.紧接着对来自于卷积_1、卷积_3、卷积_5的特征图依次经过上采样、通道连接等操作后送入多尺度特征融合模块进行上下文融合,最终得到的嵌入特征图IE和字符区域得分图AC.
1.1.2 字符生成分支
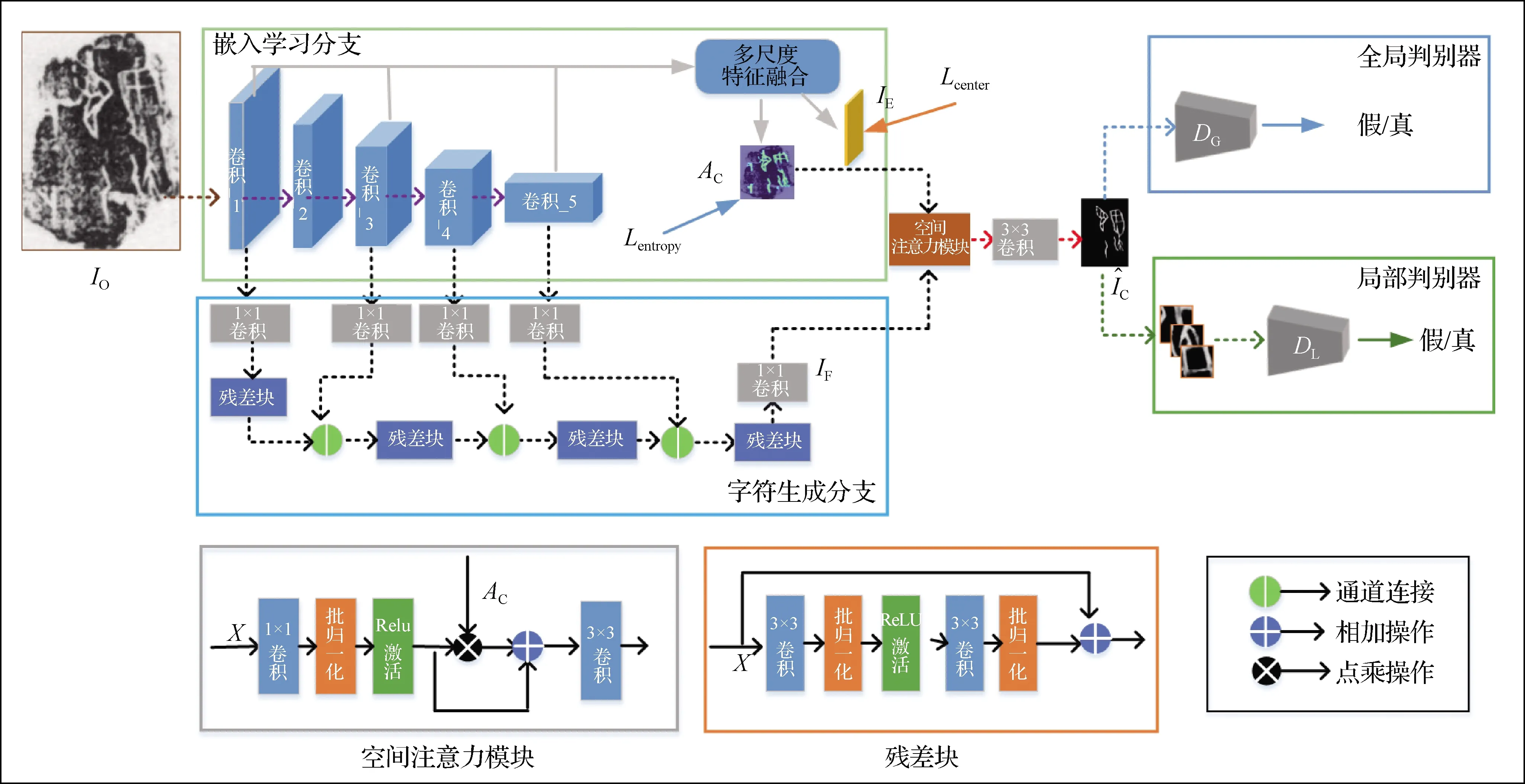
图3 EOCNet的整体结构Fig.3 The overall structure of the EOCNet

1.2 判别网络
判别网络采用两个子判别网络,分别从全局和局部角度对生成的字符图像进行质量评估,其中,全局判别网络注重字符图像总体状况,检查其是否引入了额外的噪声、裂痕等干扰.局部判别网络注重字符图像的局部细节,检查是否存在笔画残缺.特别地,为了便于局部判别网络注重生成图像的局部笔画细节,生成的字符图像输入网络之前,需要进行区域裁剪操作.默认情况下,本文算法将生成的字符图像裁剪为若干个等大小的局部块,并计算其与对应真实标记的差异,选择一些误差大的局部块作为输入,以便于网络感知更多困难的局部样例.其次,全局判别网络和局部判别网络具有相似的网络设计,均采用PatchGAN(patch generative adversarial network)[13]网络结构,通过预测N×N大小的置信矩阵用于评估更加细致的局部细节.不同的是,全局判别网络更深,卷积核视野更大,而局部判别网络相对更浅,卷积视野更小,全局和局部判别器具体的结构和参数设置如表1所示.

表1 全局和局部判别网络Tab.1 The global and local networks
2 可判别嵌入特征学习
为缓解拓片图像中噪声、裂痕的干扰,嵌入学习分支将甲骨背景和甲骨字符视为不同的类别实例,鼓励相同类别的嵌入特征朝着特定的特征中心靠拢,以学习它们的可判别嵌入特征.
近来,少数其他领域(目标分类、目标检测)的方法采用聚类的思想在嵌入空间学习可判别嵌入特征,并取得一定的效果.例如DeepCluster[14]对分类网络的预测进行聚类,并利用聚类结果更新深度卷积网络参数,用于无监督视觉特征学习.Tian等[15]将任意形状的场景文本视为不同的实例,并鼓励属于相同实例的像素特征朝着相同的特征中心靠近,反之远离.然而,这些方法往往针对特定的应用场景,仅仅考虑嵌入特征是否可分,忽视了目标实例的视觉特征属性,因此不能直接应用到字符提取任务.
本文通过提高背景特征和字符特征的“类内一致性”以实现可判别特征学习并兼顾实例特征的视觉属性.首先,利用分割网络对拓片图像进行逐像素分类,分别学习甲骨背景和甲骨字符对应的视觉特征.然后,自适应学习它们对应的特征中心,并鼓励属于同一类的视觉特征在嵌入空间朝着相应的特征中心靠近.本文中采用CenterLoss[16]的中心特征学习策略,通过模型迭代优化的方式自动学习对应的视觉特征的中心.具体的语义分割损失Lentropy和中心损失Lcenter表达如下:
(1)
(2)

3 拓片图像与字符图像间的映射学习
本文将甲骨字符提取视为一种图像到图像的转换任务.和大多数图像到图像转换模型一样,字符生成分支,通过训练一个编码和解码网络来学习拓片图像与对应字符图像之间的映射.在学习过程中,甲骨字符在拓片图像中的位置信息是未知的,在生成网络的末尾,字符生成分支使用嵌入学习分支中的字符区域预测,用以突出融合特征图中的字符区域.最后,为了约束生成的甲骨字符在空间结构上的完整性,使用对抗生成网络(generative adversarial network,GAN)[17]作为结构模型,用以融入字符的空间结构先验.与一些图像修补方法一样,使用全局和局部判别器评估生成的字符图像全局和局部特征的一致性.在训练过程中,本文使用LSGAN(least squares GAN)[18](相比于CGAN(conditional GAN)[19], LSGAN在训练过程中更加稳定,收敛速度更快).设生成网络为G,全局和局部判别网络分别为DG和DL,生成网络和判别网络的对抗损失函数为:
Lglobal(G,DG)=EIC~Pdata(IC)[(DG(IC)-1)2]+
EIO~Pdata(IO)[(DG(G(IO)))2],
(3)
Llocal(G,DL)=EIC~Pdata(IC)[(DL(T(IC))-1)2]+
EIO~Pdata(IO)[(DL(T(G(IO))))2],
(4)
Ladv(G,DG,DL,IO,IC)=Lglobal+Llocal,
(5)
其中,E表示数学期望,Pdata表示训练数据的经验分布,IO表示原始的拓片图像输入,T表示裁剪和连接操作.
此外,为了约束生生成的字符图像在像素值上更接近真实值,在生成网络的末尾使用了L1损失,其具体的表达如下:
(6)
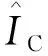
训练过程中,本字符提取模型同时接受多个损失函数的共同约束,具体表达如下:
Ltotal=λadvLadv+λenLentropy+λcenLcenter+λ1L1,
(7)
其中:λadv、λen、λcen、λ1分别表示Ladv、Lentropy、Lcenter、L1的权重系数,在实验中分别为3,1,0.003,3;Ladv和L1作用于重建的字符图像,约束其与真实图像的数据分布和像素特征保持一致;Lcenter作用于嵌入特征图IE促使生成网络学习甲骨背景和字符的可判别特征;Lentropy作用于AC约束学习粗糙的文字区域,用于指导空间注意模块有向性融合.
4 实验结果及分析
4.1 甲骨拓片图像数据集
目前为止,在甲骨学研究领域几乎不存在公开可达的像素水平的甲骨文数据集,因此本研究使用的像素级甲骨文数据集来自于本课题组的手工构建.数据集中的甲骨拓片来源于安阳师范学院甲骨文信息处理教育部重点实验室公开的甲骨文检测数据集,该数据集主要由甲骨拓片和对应的字符水平位置标记组成,但不包含像素级标记信息.本研究中,人工从甲骨文检测数据集中挑选了一定量具有代表性且退化严重的拓片图像进行训练和验证.
具体来说,本研究采用的甲骨拓片图像数据集包含了405对训练样例(甲骨拓片图像和对应的甲骨字符图像)、35对验证样例和300张测试样例.
为了确保模型能够学习准确的特征表示,根据上述的拓片图像训练样例,对样本进行简单扩充.扩充主要涉及以下操作:
1) 线性变换:缩放、裁剪、平移、操作;
2) 仿射变换:随机旋转、翻转、变形操作;
3) 颜色变换:模糊、对比度提升、高斯滤波等操作;
4) 拓片图像与字符图像重新组合.首先,利用工具软件从拓片图像中裁剪甲骨字符,构成甲骨字符字典; 然后,选取若干张背景复杂的拓片图像并移除其中的甲骨字符,得到候选甲骨背景;最后根据字符字典和甲骨背景进行重新组合,具体过程如图4所示.
最终,得到了(405 + 2 825)对训练样例、(35+165)对验证样例、(300+200)测试样例的一个混合甲骨拓片数据集.
4.2 模型评估指标
本文从两个角度对提出的字符提取模型的性能进行评估:图像生成角度和图像分割角度.
1) 从图像生成角度,使用峰值信噪比(PSNR,RPSN)和结构相似性(SSIM,SSIM)指标来测量预测值和真实值之间的差距.PSNR和SSIM是一种常见的评估图像生成质量的客观标准.PSNR和SSIM的值越高,表明生成的字符图像质量越高,越接近真实值.PSNR的计算如下:
(8)
G(i,j)‖2,
(9)
其中,EMS为生成图像与对应真实图像的均方误差,CMAX表示图像RGB颜色的最大值.SSIM的计算式如下:
(10)
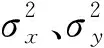
2) 从图像分割的角度,由于大多数甲骨字符的像素值(归一化后)趋向于1(字符边缘或者一些特殊字符除外),可近似地将生成的字符图像视为一种特殊的图像分割(二分类).和图像分割模型的评估相似,使用平均交并比(mIoU,RmIoU)和单个字符类别的交并比(IoU(char),RIoU)分别测量生成的字符图像与真实值之间的相关程度以及局部字符与对应真实值的相关程度.其中,RmIoU或RIoU的值越高,说明像素被正确分类的比例就越高,生成的字符图像接近真实值的概率就越大.此外,由于生成的甲骨字符图像的非字符区域像素值接近于0,但不为0,对于字符图像的RIoU计算可能存在一定的误差.为了获得更加准确的RIoU值,在RIoU计算之前,需要对生成的字符图像进行阈值选择处理.具体的阈值根据经验设定,本实验中,该阈值设置为0.2,RIoU的计算式如下:
RIoU=NTP/(NTP+NFP+NFN),
(11)
其中,NTP、NFP、NFN表示分类结果为真正、假正、假负的像素个数.
此外,为验证模型抑制裂痕干扰的能力,本文实验对生成的字符图像上的裂痕数量进行了统计.对于生成的字符图像,假设其仅仅由背景噪声、甲骨字符和裂痕构成,其中的背景噪声相对稀少,可通过简单的形态学开运算进行滤除,而裂痕干扰则可以使用对应的字符真实值选取,最后求解裂痕干扰中的连通分量并统计其个数.具体包括以下5个步骤:
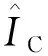
(12)
2) 使用形态学开运算对粗糙的裂痕背景进行膨胀和腐蚀操作,去除其中的背景噪声,得到纯净的裂痕.
3) 计算纯净裂痕中的连通分量,并去除关于背景的连通分量.
4) 遍历每个连通分量,并移除小于30个像素大小的连通区域.
5) 对现有的连通分量进行统计,得到每一张字符图像上的裂痕总数.
4.3 与其他主流模型的比较
4.3.1 与其他主流图像生成模型的比较
本小节将EOCNet与主流的图像到图像的转换模型(Pix2Pix[8],CycleGAN[20],BicycleGAN[21])进行比较.为公平起见,直接使用了这些模型的官方代码和默认的超参数设置.相应的定量评估、定性评估以及裂痕统计结果如图5、表2和3所示.
如图5所示,主流的图像到图像的转换模型一定程度上也可以提取拓片图像中的字符信息,并能保留清晰的局部细节.然而,对于一些尺度较小、不太显著的字符有可能被忽略(如图5第1行所示).其次,在生成的字符图像上引入大量和字符特征比较相似的噪声或裂痕干扰(如图5第2和4行所示).相反,由EOCNet生成的字符图像几乎将拓片上的字符信息完全保留,并没有引入过多的噪声和裂痕干扰(如图5(e)所示).因此主观上看,EOCNet能够生成更高质量的甲骨字符图像.

图5 甲骨拓片图像和主流的图像生成模型的字符提取结果Fig.5 Oracle bone rubbing image and character extraction results of state-of-art image generation models
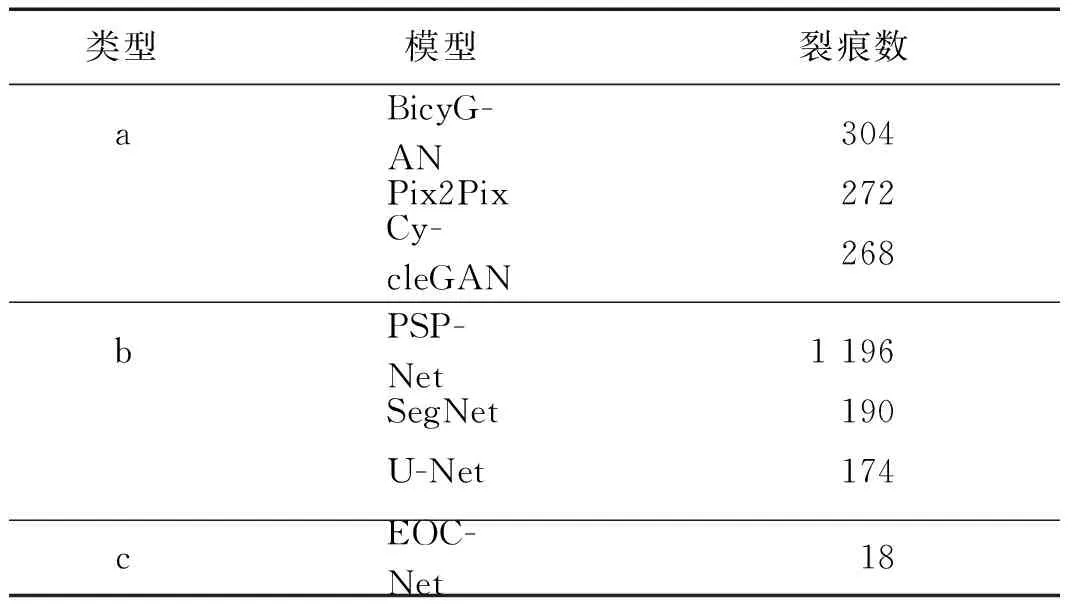
表2 生成图像裂痕个数统计Tab.2 Statistical results of crack number in generate image
本实验中,随机从190条验证集记录中抽取50条作为统计样本,统计不同模型得到的生成图像中存在的裂痕数量,统计的结果如表2所示.其中类型a表示不同的生成模型输出的字符图像中裂痕连通分量的个数,整体上这3个模型的输出中都引入了较多的裂痕,其中Pix2Pix模型引入的最少,但也高达272个.类型c表示EOCNet的统计结果,仅仅包含18个,远低于其他3个模型,这表明,相比于主流的图像到图像的转换模型,EOCNet对裂痕干扰的抑制是有效的.
表3展示了不同的生成模型输出的字符图像在PSNR和SSIM指标上的测量结果.很显然,EOCNet在这两个指标上均是最佳的,并大幅超越次优结果Pix2Pix(PSNR和SSIM指标分别提高了5.27 dB 和5.93个百分点).这表明,相比于主流的图像到图像转换模型,EOCNet生成的字符图像中包含更少的噪声,且捕获了更多的字符局部细节.

表3 和主流生成模型的量化比较结果Tab.3 The quantitative results comparison to the state-of-art generation models

图6 甲骨拓片图像和主流的图像分割模型的字符提取结果Fig.6 Oracle bone rubbing image and character extraction results of state-of-art image segmentation models
综上所述,无论是在裂痕引入量上,还是PSNR和SSIM指标上,EOCNet均取得较优的效果,因此上述的主观结论是正确的,相比于主流的图像到图像转换模型,EOCNet能够生成更加清晰、更加完整的字符图像.
4.3.2 与主流图像分割模型的比较
大多数甲骨字符特征的像素值(归一化后)趋向于1,可近似地将生成的字符图像视为一种特殊的图像分割(二分类).因此,本小节将EOCNet与主流的图像分割模型(全卷积网络16(fully convolution network 16,FCN16)[22]、ERFNet(efficient residual factorized ConvNet)[23]、U-Net[9]、SegNet[10])进行比较.考虑到拓片图像中字符像素和背景像素在比例上存在严重的失衡,不利于分类问题训练得到最优参数,在模型训练期间,默认为每个分割模型使用相同的类别平衡策略,以获得更佳的字符分割效果.类别平衡策略的具体表示如下:
(13)
其中,W(c)代表不同类别实例的权重系数,Nc和N分别代表类别c的像素个数和拓片图像中总的像素个数.
图6展示了EOCNet和分割模型的字符提取效果.从视觉上看,分割模型几乎将所有的字符区域都预测出来,并且引入了较少的噪声或裂痕干扰.然而,通过分割的方式得到的字符图像,在字符的局部细节上往往比较模糊、粗糙,甚至存在部分笔画粘连的问题(如图6(b)~(d)列所示).其次,由于分割的方法仅仅预测出字符在拓片图像上的区域信息,并没有对字符特征进行重建,一些字符笔画存在与真实字符风格不一致的问题(如图6第二行所示).相反,EOCNet对拓片图像进行重建,生成的字符图像在结构上更为清晰、风格更为统一(如图6(e)所示).
表2(b)展示了不同分割模型输出的字符图像中裂痕连通分量的个数,其中SegNet、U-Net引入了相对较少的裂痕,远低于表2类型a中的图像生成模型.但相对于EOCNet模型,仍有一定的差距,这也表明,即使相较于主流的分割模型,本文的模型仍然具有抑制裂痕干扰的优势.
表4展示了不同分割模型与EOCNet mIoU、IoU(char)的比较.结果显示,EOCNet在mIoU和IoU(char)指标上次于最优的SegNet,但仅仅存在0.53和0.22个百分点的差距.这表明EOCNet在交并比指标上与主流的分割模型差距甚微.鉴于生成模型在计算IoU(char)过程中使用阈值字符区域掩膜时会存在一定误差,可以认为:EOCNet在具备主流的分割性能的同时,能够生成更加清晰、真实的甲骨字符.
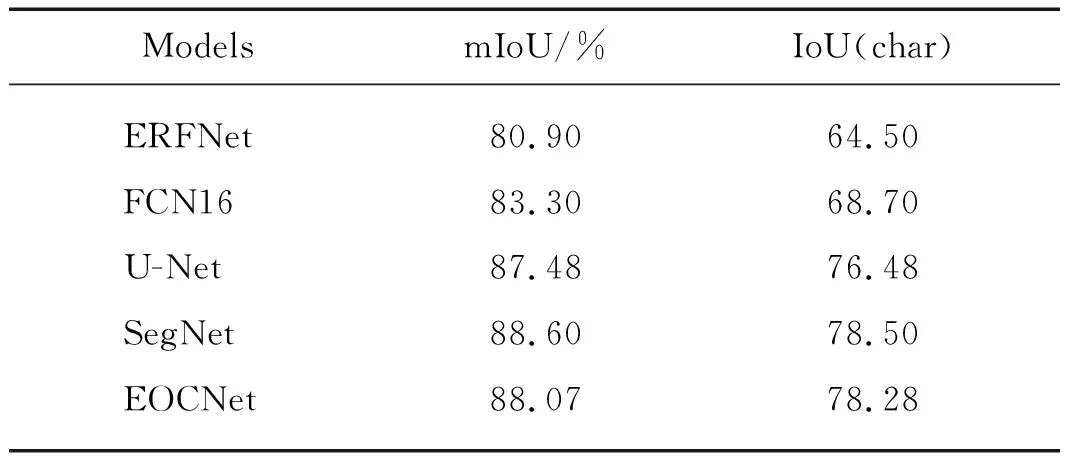
表4 和主流的分割模型的量化比较结果Tab.4 The quantitative results comparison to the state-of-art segmentation models
4.4 消融实验
4.4.1 可判别损失函数
EOCNet联合交叉熵损失Lentropy和中心损失Lcenter共同约束嵌入学习分支的甲骨背景和甲骨字符的可判别嵌入特征学习.为验证该联合损失的有效性,将其与单独的使用交叉熵损失Lentropy、区别损失(DiscLoss[24],LDisc,基本思想类似于聚类:在嵌入空间强迫同簇的特征朝向相同的中心靠拢,反之相反)进行对比.在实验设置上,除了损失函数的不同之外,整个甲骨字符生成模型的结构及超参数设置均是相同的.表5展示了在不同损失函数下的评估结果.
从表5中可以看出,区别损失LDisc在各项指标上都是最差的.其原因可能是在鼓励同簇特征向中心靠拢过程中,丢失了某些视觉属性(例如:极端情况下,嵌入特征朝零向量方向靠近).相比于区别损失,交叉熵损失Lentropy的表现更优(指标mIoU、IoU和SSIM分别提升了0.63,1.18和0.43个百分点,PSNR增加0.51 dB).最关键的是,在联合损失(Lentropy+Lcenter)的监督下,甲骨字符提取模型的表现最佳,在各项指标均为最优.这表明联合交叉熵损失和中心损失能够更有利于字符可判别嵌入特征的学习和甲骨字符图像的生成.
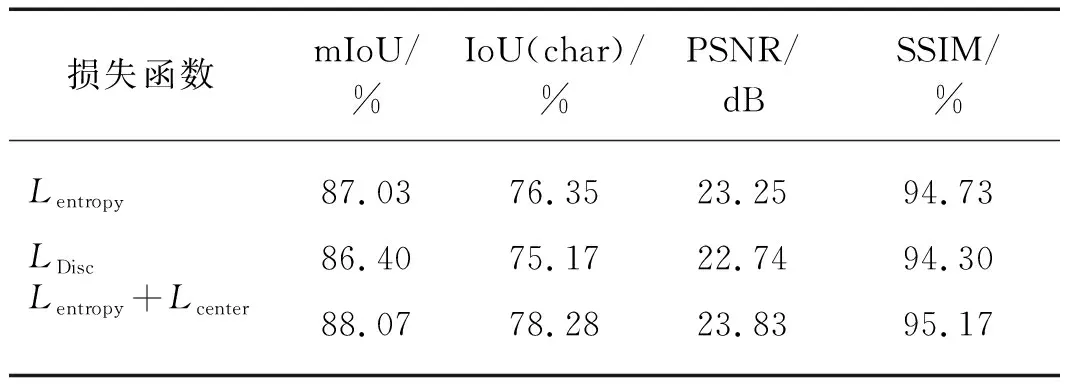
表5 不同可判别损失的比较结果Tab.5 The comparison results of different discriminative losses
4.4.2 嵌入学习分支
为缓解拓片图像中噪声、裂痕对字符提取的影响,EOCNet引入了额外的嵌入学习分支.为了验证嵌入学习分支的有效性,将嵌入学习分支从字符提取模型中移除.对比模型CGL和模型ECGL的各项指标(表6)可以发现:移除嵌入学习分支后,mIoU、IoU(char)、PSNR和SSIM出现明显下降,这充分表明嵌入学习分支的存在对甲骨字符提取模型的提取效果有显著的提升.

表6 字符生成模型不同模块组合的评估结果Tab.6 Evaluation results of different module combinations in character generation model
4.4.3 空间注意模块
给出一张甲骨拓片图像,甲骨字符提取模型的目标是生成对应的甲骨字符图像.该过程中,甲骨字符在拓片图像中的位置信息是未知的.为此,在生成网络的末尾,引入了空间注意力模块.该模块利用来自于嵌入学习分支中的字符区域信息,指导字符生成分支注重特征图的字符区域.为了证明使用空间注意力模块的有效性,本实验对甲骨字符提取模型中的空间注意力模块进行移除得到模型ECGL,移除后的评估结果如表6所示.通过对比较可以看出,移除字符空间注意力模块后,字符提取模型的性能出现小幅下降.相比于使用空间注意力模块,模型ECGL在mIoU、IoU和SSIM指标上,分别降低了0.37,0.68和0.73个百分点,PSNR降低0.72 dB.这在一定程度上表明,在生成网络的末尾使用空间注意力模块对字符提取模型的性能是有益的.
4.4.4 局部判别器
甲骨字符形状多样、结构复杂且随机的分布在拓片上的任意位置.为约束生成的字符在空间结构上的完整性,使用额外的局部判别器评估字符特征的局部一致性.为验证局部判别器空间约束的有效性,在训练期间,将局部判别器移除,得到模型ECGA.对比模型ECGA和模型ECGLA的结果可以看出,移除局部判别器后,字符提取模型的性能出现一定的下降.相比于使用局部判别器,移除后模型在mIoU、IoU和SSIM指标上分别降低了0.44,0.82和0.17个百分点,PSNR降低0.31 dB.这意味着,使用局部判别器约束字符的局部细节的完整性是有效的.
5 结 论
一直以来,拓片图像中复杂的噪声和各种各样的裂痕干扰,是解决甲骨文相关视觉任务的重要阻碍.本文的研究结果表明:在嵌入空间学习拓片图像的可判别特征,是一种更为简单且有效的方式.该方式不仅可以有效避免直接对拓片图像中复杂的噪声、裂痕等干扰进行处理,而且更有利于端到端方法的实现.
本文基于深度学习技术,构建了一个专门的甲骨字符提取模型EOCNet,能够自动提取拓片图像中的字符信息,并生成甲骨字符图像.这对后续加速甲骨文的研究及推广具有重大意义.像其他深度学习方法一样,训练字符提取网络需要依赖大量的监督训练数据.由于甲骨拓片数据自身的特殊性,获取大量的拓片图像以及相应的监督数据十分困难.因此,下一步,本课题组将针对小样本条件下的甲骨字符的提取以及识别等相关任务进行深入的探究.
猜你喜欢
中国书法(2023年12期)2023-02-02 16:45:53
中国书法(2023年12期)2023-02-02 15:51:36
公民与法治(2022年5期)2022-07-29 00:47:48
英语文摘(2021年11期)2021-12-31 03:25:28
黄河·黄土·黄种人(华夏文明)(2021年7期)2021-12-23 08:20:08
小猕猴智力画刊(2021年9期)2021-10-11 15:12:44
教育周报·教育论坛(2021年21期)2021-04-14 00:09:18
黄河·黄土·黄种人(华夏文明)(2020年6期)2020-07-14 12:05:34
汉字汉语研究(2019年4期)2019-03-04 09:52:28
汉字汉语研究(2019年4期)2019-03-04 09:52:28
