
基于多模态图和对抗哈希注意力网络的跨媒体细粒度表示学习
2022-04-06 07:57:06梁美玉王笑笑杜军平
模式识别与人工智能 2022年3期
梁美玉 王笑笑 杜军平
在线社交网络和互联网的迅猛发展,如Flickr、Twitter、Facebook、新浪微博等,网络中积累大量的用户数据,包括文本、图像、视频等不同媒体类型的跨媒体数据.这些海量的跨媒体数据中蕴含有价值的信息,而且不同媒体数据对于信息的描述是互补性的,因此,通过跨媒体数据搜索(如基于文本搜索图像,或基于图像搜索文本)可实现从社交网络和互联网中获取更全面、丰富的话题或事件信息[1-2].
由于语义上的差距,不同媒体类型的数据之间无法直接进行相似性对比.为了衡量不同媒体数据之间的相似性,需要学习跨媒体数据间的语义相关性,将不同的媒体数据映射到一个统一的语义表示空间,再进行跨媒体相似性匹配和搜索[3-4].
深度学习技术具有较优的非线性特征学习能力,近年来基于深度学习的跨媒体语义表示学习方法吸引学者们的广泛关注.现有方法主要包括两类:基于连续的深度特征空间的方法[5-9]和跨媒体哈希方法[10-12].由于较低的存储成本和快速的搜索速度,跨媒体哈希方法已成为跨媒体搜索领域的研究热点.通过跨媒体哈希技术,将原始空间中高维度特征表示映射为短小的二进制哈希编码,然后在获取的二进制哈希表示空间,通过海明距离快速计算,进行跨媒体匹配[13].
目前的跨媒体哈希方法主要包括传统浅层学习方法和基于深度学习的方法.根据是否利用语义标签作为指导信息以学习跨媒体语义关联,跨媒体哈希方法主要分为无监督的跨媒体哈希方法和有监督的跨媒体哈希方法.无监督的跨媒体哈希方法学习跨媒体相关性和媒体内相似性,最大化不同模态数据间的语义关联,将来自不同模态的数据映射至一个统一的哈希语义空间,如UGACH(Unsupervised Generative Adversarial Cross-Modal Hashing Approa-ch)[12]和UCH(Unsupervised Coupled Cycle Genera-tive Adversarial Hashing Networks)[14]等.有监督的跨媒体哈希方法利用语义标签信息指导跨媒体关联学习过程,获取统一的哈希表示,如CDQ(Collective Deep Quantization)[15]、SSAH(Self-Supervised Adver-sarial Hashing)[16]、SePH(Semantics-Preserving Hashing Method)[17]、SCM(Semantic Correlation Maximiza-tion)[18]、CMSSH(Cross-Modality Similarity Sensitive Hashing)[19]等.
近年来,受到深度学习特征学习能力的激励,基于深度神经网络的跨媒体哈希方法广泛应用于跨模态搜索领域[20-23].Peng等[20]提出MCSM(Modality-Specific Cross-Modal Similarity Measurement),采用基于联合嵌入损失和注意力机制的循环注意力网络,为不同模态构建独立语义空间,并进行跨模态关联学习.Zhuang等[21]提出CMNNH(Cross-Media Neural Network Hashing),保持模态间的判别能力和模态内部数据的联系,学习跨模态哈希函数.Jiang等[22]提出DCMH(Deep Cross-Modal Hashing),将跨模态特征学习和哈希函数学习集成在一个端到端的框架下联合学习.Shi等[23]提出EGDH(Equally-Guided Discriminative Hashing),联合语义结构和判别性,实现哈希编码学习.
然而,现有的跨媒体哈希方法往往基于跨媒体数据的全局特征表示建立语义关联,未考虑数据的局部显著性特征,因此无法有效捕捉不同模态数据间的细粒度语义关联,而实际上,图像中的显著性区域和文本中的关键性单词具有较强的语义相关性.通过人眼视觉注意力机制[24-27],充分捕捉显著性图像区域和关键性的文本单词,可发现更多潜在的细粒度跨媒体语义关联,提升跨媒体搜索的性能[28-31].
生成对抗网络(Generative Adversarial Network, GAN)现已应用在跨模态搜索领域,如CM-GANs(Cross-Modal GANs)[7]、ACMR(Adversarial Cross-Modal Retrieval)[8]、AGAH(Adversary Guided Asymmetric Ha-shing)[13]、SSAH(Self-Supervised Adversarial Ha-shing)[16]等.Wang等[8]提出ACMR,在实值特征空间将对抗学习技术应用于跨模态检索.Li等[16]提出SSAH,将对抗学习应用于跨模态哈希,构建两个对抗网络,联合学习不同模态数据的高维特征和统一哈希编码.
但是,现有的跨模态对抗哈希方法未考虑图像和文本之间的局部显著性细粒度特征之间的互相指导和协同学习,无法实现细粒度的跨媒体关联学习[32-34].而且,社交网络中的多媒体数据通常表现出语义稀疏性和多样性,并包含很多噪音,导致现有的跨媒体表示学习方法不能有效应用于此类数据.
为了解决上述问题,本文提出基于多模态图和对抗哈希注意力网络的跨媒体细粒度表示学习模型(Cross-Media Fine-Grained Representation Learning Model Based on Multi-modal Graph and Adversarial Hash Attention Network, CMFAH).为了获得高质量和紧凑的跨媒体统一哈希语义表示,将基于跨媒体注意力的细粒度特征学习、跨媒体关联学习、对抗哈希学习集成在一个统一的对抗哈希注意力网络下,联合学习跨媒体统一语义表示.为了捕获更多潜在的细粒度跨媒体语义关联,构建基于跨媒体注意力的图像和文本细粒度特征学习网络,实现跨媒体显著性特征学习,通过图像和文本显著性特征之间的互相指导和协同注意力学习,实现不同模态间的细粒度语义关联学习.为了进一步最大化跨媒体数据的语义关联和特征分布一致性,缩小跨媒体语义鸿沟,构建跨媒体GAN,通过联合跨媒体细粒度关联学习和对抗哈希学习,获取不同模态数据的统一哈希语义表示.此外,为了解决社交网络数据的语义稀疏性、多样性问题,构建图像-单词关联图,并在图上通过随机游走实现语义关系扩展,发现更多潜在的图像和单词之间的语义关联.实验表明,CMFAH在2个公开标准跨媒体数据集上均取得较优的跨媒体搜索性能.
1 基于多模态图和对抗哈希注意力网络的跨媒体细粒度表示学习模型
1.1 模型框架
本文解决文本和图像之间的跨媒体搜索问题,提出基于多模态图和对抗哈希注意力网络的跨媒体细粒度表示学习模型(CMFAH),用于社交网络跨媒体搜索,模型框架如图1所示.

图1 CMFAH模型框图Fig.1 Framework of CMFAH
CMFAH主要包括3部分:基于图像-单词关联图的语义扩展、跨媒体细粒度特征学习、跨媒体对抗哈希.首先,构建图像-单词关联图,学习图像和文本单词间的直接语义关联和隐含语义关联,实现跨媒体语义关系扩展.然后,基于构建的图像和文本细粒度特征学习网络,实现跨媒体细粒度显著性特征学习.基于深度卷积神经网络提取图像的区域特征及文本的单词特征,并结合跨媒体注意力机制学习图像和文本的细粒度语义关联,分别获取图像和文本的细粒度特征表示,并通过长短时记忆神经网络(Long Short-Term Memory, LSTM)学习图像和文本特征的细粒度上下文特征关联,获取语义增强后的文本和图像特征表示.最后,构建对抗哈希网络,在语义标签数据的指导下,通过对学习的图像和文本统一特征表示进行对抗学习,通过媒体内语义相似性损失、跨媒体语义相似性损失、跨媒体判别损失的联合优化,获取高效紧凑的跨媒体统一哈希表示.
1.2 问题形式化描述

Hv=fv(Fv,θv),Ht=ft(Ft,θt),
其中Fv、Ft表示图像和文本统一特征表示,θv、θt表示网络参数,进而通过
Bv=sgn(Hv),Bt=sgn(Ht)
实现图像和文本特征空间到哈希空间的映射.
1.3 模型描述
1.3.1 基于图像-单词关联图的跨媒体语义扩展
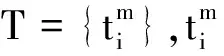
N表示扩展后的单词个数.结合Wikipedia知识Twk进一步扩充数据,获取最终的内外部联合扩展后的图像关联文本:
Tio=Trs+Twk.
在此基础上,基于SkipGram构造语义嵌入学习模型.在该过程中,最大化上下文情境中的单词tu和tv之间的相似度,获取语义嵌入表示,目标函数为:
并采用分层softmax实现目标函数的优化.
1.3.2 跨媒体细粒度特征学习
首先,基于跨媒体协同注意力机制构建跨媒体细粒度特征学习网络,实现图像和文本的细粒度特征联合学习,包括图像特征学习和文本特征学习两个子网络.
对于图像特征学习网络,构建深度卷积神经网络,实现图像的深度语义特征学习(本文采用VGG 19深度网络),并提取VGG 19网络的最后一个池化层的特征图作为图像的局部区域特征,定义为
V={v1,v2,…,vm1},
其中,m1表示图像区域的总数,vi表示第i个区域的视觉特征表示.
在文本特征学习网络,首先基于语义嵌入模型word2vec,学习由图像-单词关联图进行语义扩展后的嵌入表示,并联合TextCNN学习文本的深度语义特征.利用word2vec处理文本,获得词向量矩阵,每个单词的词向量维度为k,因此包含n个词的一个句子可表示为一个n×k的矩阵,作为TextCNN的输入.此外,TextCNN后接一个全连接层,其输出作为每个句子的文本表示,即T={t1,t2,…,tm2},其中,m2表示文本单词的总数,tk表示第k个单词的特征表示.
在提取的图像特征和文本特征的基础上,基于图像和文本不同模态之间的细粒度语义相关性,以及不同模态数据之间的互相指导学习,通过跨媒体协同注意力机制学习图像和文本的细粒度注意力特征表示.
首先,基于余弦距离函数计算所有区域-单词对之间的语义相似度,第i个图像区域与第k个单词之间的相似度表示为:
其中,m1表示图像区域的总数,m2表示文本单词的总数.
对于图像模态的每个图像区域vi,利用文本中的所有单词学习图像区域的注意力权值:
(1)
其中
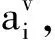
最终获取到整个图像细粒度注意力特征表示
对于文本模态的每个文本单词tk,利用图像模态的所有图像区域学习文本单词的注意力权值:
(2)
其中
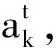
最终获取到整个文本细粒度注意力特征表示
获取图像和文本的细粒度注意力特征表示之后,基于LSTM学习图像特征和文本特征的细粒度上下文特征关联,得到语义增强后的图像特征表示Fv={f1,f2,…,fm1}和文本特征表示Ft={f1,f2,…,fm2},其中fi、fk分别表示语义增强后的第i个图像区域特征和第k个文本单词特征.
为了解决不同模态数据之间的异构间隙问题,本文构建对抗哈希模型,学习跨媒体数据的语义关联,将不同媒体的异构数据映射至统一的哈希语义空间.利用生成对抗学习策略,将跨媒体细粒度特征学习网络作为跨媒体GAN中的“生成模型”,联合学习媒体内语义相似性损失函数和跨媒体语义相似性损失函数,获取跨媒体统一语义表示,尽可能保持模态内语义相似性和模态间语义相似性.通过跨媒体对抗损失,对生成模型得到的跨媒体统一表示进行模态判别,作为“判别模型”.联合学习和优化生成模型和判别模型,利用两者之间的动态博弈过程,最大化不同模态数据间的语义相关性和特征分布一致性,进一步缩小跨媒体语义鸿沟.
令跨媒体细粒度特征学习网络作为跨媒体生成对抗网络中的“生成模型”,构建生成损失函数Lgen,函数包含2个部分:媒体内语义相似性损失Lintra和跨媒体语义相似性损失Linter.
在尽可能地保持同模态内部的语义相似性的前提下,构建和优化媒体内语义相似性损失函数:
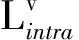
其中,J1和J2为2个triplet-margin loss函数,J1表示添加在同一模态如图像/文本特征级别的约束,J2表示添加在同一模态如图像/文本哈希级别的约束,J3表示哈希量化误差,通过实值哈希码和二进制哈希码之间的均方差(Mean Square Error, MSE)计算.
J1(F*,F+,F-)=
勃列日涅夫执政时期的第一个五年计划(1966—1970年)经济情况较好,社会总产值比上个五年计划增长7.4%(1961—1965年增长6.5%)。这一时期,勃列日涅夫对改革持积极态度,力图通过改革扭转经济下滑趋势。也是在这一时期,勃列日涅夫也站稳了脚跟。但从70年代上半期开始,保守、僵化与停止改革趋势日益明显,后来实际上取消了改革。在1971年的苏共二十四大后,就不准用“改革”一词了,而改用“完善”一词。俄罗斯学者说得好,这一改变是向“停滞”过渡的标志。
J2(H*,H+,H-)=
Fv、Ft为学习的模态特征表示,Hv、Ht为学习的实值哈希码,Bv、Bt为学习到的二进制哈希码.α、β、γ、margin为超参数,sim为相似度函数,通过cosine距离进行计算.
在不同模态之间添加模态间语义相似性约束,学习不同模态数据之间的语义关联关系.构建跨媒体语义相似性损失函数:
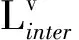
其中,J4和J5为2个Triplet-Margin loss函数,分别表示添加在不同模态即图像和文本特征级别和哈希级别的约束.
J4(Fv,Ft,+,Ft,-)=
J5(Hv,Ht,+,Ht,-)=
其余参数含义与Linter一样.
最后,联合媒体内语义相似性损失函数和跨媒体语义相似性损失函数,构建跨媒体生成对抗网络生成模型的总体目标函数:
Lgen=Lintra+Linter
.
分别为文本和图像模态构建跨媒体生成对抗网络中的“判别模型”.对于图像模态判别器Dv,采用文本特征学习网络作为图像特征的生成器,将学习的图像特征作为真实的图像特征,而文本特征学习网络学习的特征作为生成的图像特征.图像模态判别器的目的在于区分输入的图像特征是真是假.对于文本模态判别器的构建也是类似的.图像模态和文本模态的判别器均是基于三层的多层感知网络(Multilayer Perceptron, MLP)实现,网络参数分别为θDv和θDt.构建的判别器类似于以交叉熵为损失的一个二分类器,将输入的特征进行模态分类为0或1,1表示输入与输出来自同一模态,0表示输入与输出来自不同模态.定义跨媒体对抗损失函数:

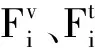
学习和优化模型,最终可生成图像和文本的统一哈希语义表示
Bv=sgn(Hv),Bt=sgn(Ht).
在训练学习过程中,令
B=sgn(Hv+Ht),
使语义上相似的图像和文本实例生成相似的哈希码.整体的跨媒体语义表示学习目标函数如下:
基于随机梯度下降(Stochastic Gradient Descent, SGD)的反向传播(Back Propagation, BP)算法学习所有的网络参数.首先,初始化所有超参数及生成模型与判别模型.再训练GAN:固定生成器的参数,训练判别器;固定判别器的参数,训练生成器.不断迭代,直到模型收敛或达到最大迭代次数.CMFAH优化学习算法如算法1所示.
算法 1CMFAH优化学习算法
输入图像集V,文本集T
输出哈希码矩阵B
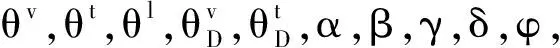
批大小bs,最大迭代值Tmax
Repeat
Fortiteration do:
根据BP算法更新参数θ:
End For
更新B,B=sgn(Hv+Ht)
直到收敛
1.4 基于CMFAH的跨媒体搜索
基于CMFAH获取跨媒体统一语义表示之后,采用基于内积距离的近似最近邻方法实现跨媒体相似性搜索.对于大规模跨媒体数据搜索而言,原始实值特征空间上的相似度匹配效率较低.为了在保证搜索准确性的同时进一步提高面向大规模数据量的搜索效率,本文将非对称量化距离函数作为相似度函数,计算给定查询q(图像或文本)和待搜索的数据点x(文本或图像)之间的语义相似度.近似误差分析验证发现,非对称量化距离函数可逼近实值特征空间的距离,并可在跨媒体搜索精度和时间效率之间取得平衡.基于非对称量化距离的跨媒体语义相似度计算方法表示如下:
其中,zq表示查询q的深度特征表示,Bx表示待搜索数据点的哈希编码表示.
2 实验及结果分析
2.1 实验环境
实验数据集选取国际标准的NUS-WIDE社交跨媒体数据集和MIR-Flickr 25k社交跨媒体数据集,具体信息如表1所示.

表1 数据集信息Table 1 Information of datasets
NUS-WIDE数据集包含269 648个图像-文本对,含81个语义类别标签.在实验中选取出现频率最高的前21个语义类别作为数据集,合计195 834个图像-文本对.随机选取10 500个图像-文本对作为训练集,2 100个图像-文本对作为查询集,剩余的图像-文本对作为待检索数据集.
MIR-Flickr25k数据集包含25 000个图像-文本对,含38个语义类别标签.在实验中选择包含24个语义类别的实例,总共20 015个实例.随机选取10 000个图像-文本对作为训练集,2 000个图像-文本对作为查询集,剩余的图像-文本对作为待检索数据集.
采用的性能评价指标为MAP(MeanAveragePrecision)和Top-k准确率(P@k)曲线.
根据所有查询的平均准确率(AveragePrecision,AP)的均值计算MAP:
其中:Q 表示查询次数,AP(q)表示第q次查询的平均准确率.MAP值越大,说明跨媒体搜索性能越优.
P@k计算公式如下:
其中,tr表示相关的搜索结果数, fr表示不相关的搜索结果数,tr+fr表示所有的搜索结果数.
本文选择如下对比算法.
1)CMSSH[19].构建二进制分类模型和Boosting算法,实现哈希学习.
2)SCM[18].构建和最大化保持跨模态语义相似性矩阵,学习哈希函数.
3)UGACH[12].充分利用GAN无监督下表示学习的能力,挖掘跨模态数据的基本流形结构.
4)SSAH[16].构建2个对抗网络,联合学习高维特征和不同模态下的哈希编码.
5)AGAH[13].提出对抗学习指导下的多标签注意力机制,加强特征学习,生成较高层级关联和保留多标签语义的二进制哈希码.
CMSSH和SCM为传统的跨模态哈希算法,UGACH、SSAH和AGAH为基于对抗学习的深度跨模态哈希算法,AGAH为联合对抗学习和注意力机制的跨模态哈希算法.
此外,为了验证CMFAH的有效性,设计3种不同的变种:1)CMFAH-ca.从整个模型中删除跨媒体注意力模块.2)CMFAH-ia.仅添加文本对图像的注意力.3)CMFAH-ta.仅添加图像对文本的注意力.
实验环境为NVIDIATitanXGPU.在语义扩展过程中,设置图像-单词关联图中的随机游走步长为5.语义嵌入word2vec词向量长度为1 000维.跨媒体统一特征表示的维度为512维.统一哈希表示长度分别设置为16位、32位、64位、128位.批尺寸大小为128,文本和图像的初始学习率为0.000 7.实验中超参数α=β=γ=δ=φ=1.另外,针对目标损失函数中超参数margin、对抗网络学习率gan_lr及epoch,设计参数敏感性分析实验,最终确定margin=0.5,gan_lr=0.000 8,epoch=150.
2.2 不同哈希编码位数下的跨媒体搜索性能对比
基于跨媒体搜索任务,验证CMFAH的性能,本组实验将各算法在NUS-WIDE、MIR-Flickr25k数据集上对比跨媒体搜索任务(图像搜索文本I→T和文本搜索图像T→I)的性能.实验中哈希编码的长度分别取16位、32位、64位和128位.
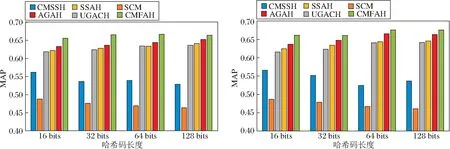
在NUS-WIDE、MIR-Flickr25k数据集上,不同算法针对不同哈希编码长度下的MAP值对比如表2和表3所示.图2给出不同哈希编码长度下,各算法在NUS-WIDE、MIR-Flickr25k数据集上的MAP平均值曲线.
观察表2和表3可看出,相比其它算法,CMFAH在I→T和T→I两个跨媒体搜索任务上均取得较高的MAP值,并且哈希码位数较短的结果优于其它算法哈希码位数较长时的结果,说明CMFAH性能更优.这是因为,CMFAH充分学习不同模态数据之间的语义关联,生成更具有判别性、高质量的哈希码.并且随着哈希编码长度的增加,CMFAH的MAP值越来越高,这是因为较长的哈希编码能保留足够多的语义信息,因此可提升跨模态搜索性能.此外,通过实验可发现,一味增加哈希编码的长度,一方面并不能保证MAP值越来越高,这是因为,较长的哈希编码可能会造成模型训练过拟合,影响MAP值.观察实验结果可看出,CMFAH在64位哈希编码时取得最优的MAP值.另一方面,随着哈希编码位数的增加,搜索时间开销也越大.因此,为了在搜索精度和时间效率方面取得较好折衷,本文将哈希编码位数设置为64位.
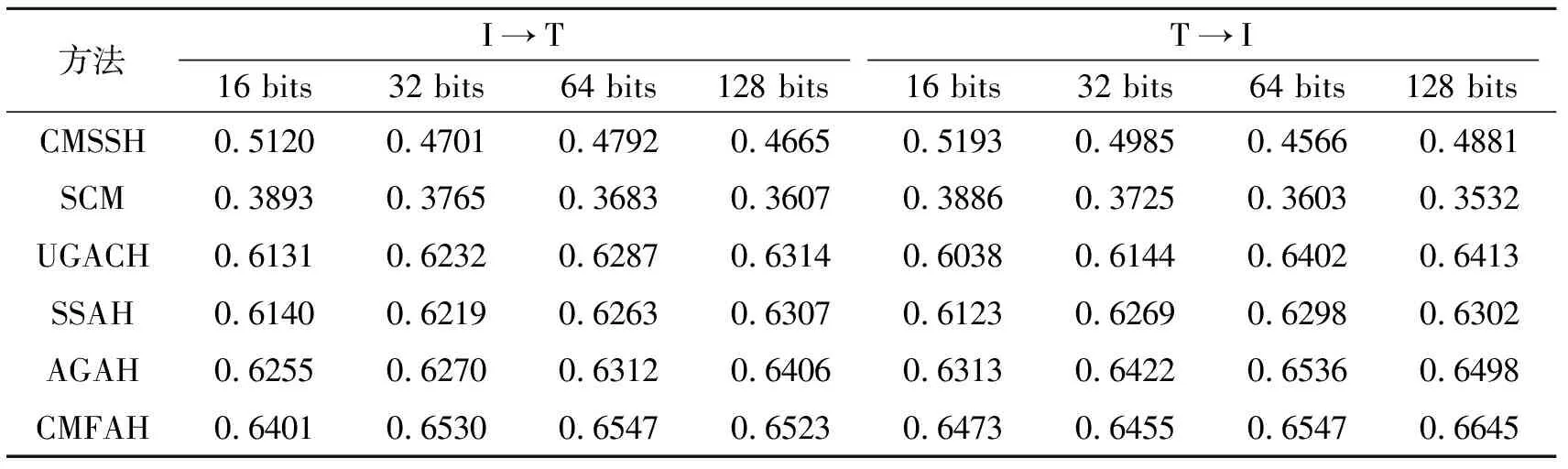
表2 各算法在NUS-WIDE数据集上的MAP值对比Table 2 MAP comparison of different algorithms on NUS-WIDE
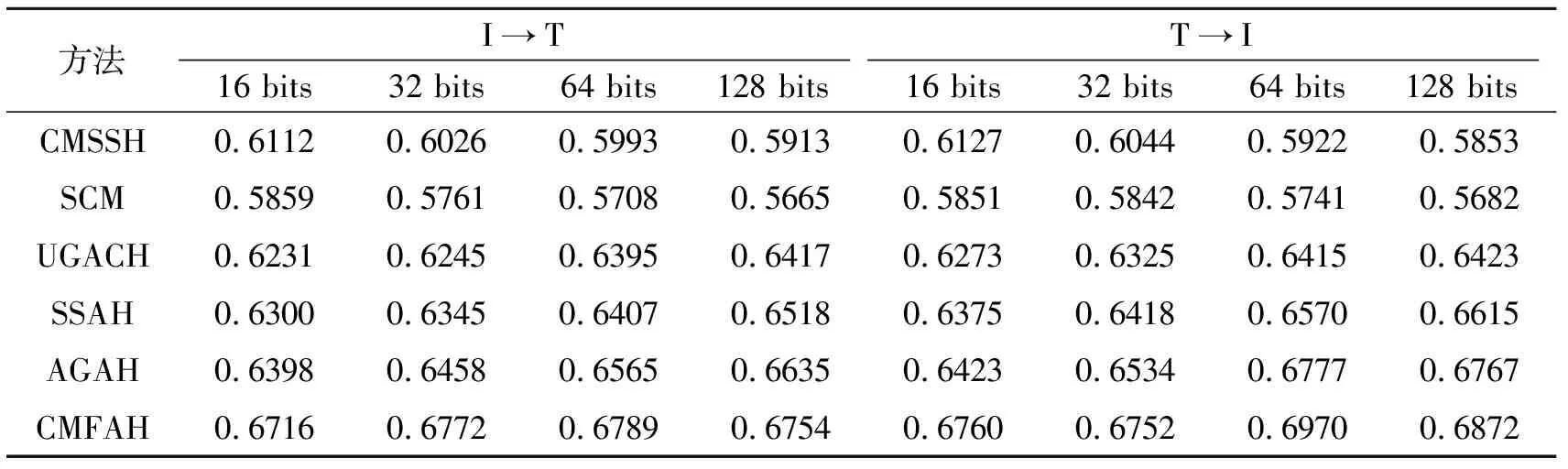
表3 各算法在MIR-Flickr 25k数据集上的MAP值对比Table 3 MAP comparison of different algorithms on MIR-Flickr 25k
(a)I→T (b)T→I
此外,从时间效率上看,CMFAH和AGAH训练时长类似,平均每个epoch训练时长分别为26 s和24 s.相比AGAH,CMFAH取得更高的MAP值,在I→T搜索任务上平均提升3%,在T→I搜索任务上平均提升2%.主要原因是CMFAH基于不同模态数据间的协同注意力机制,可学习到更具显著性的细粒度特征,并通过构建图像-单词关联图进行语义关系扩展,发现更多细粒度和潜在的跨媒体语义关联,获取更有判别力和精确的跨媒体统一哈希表示,因此跨媒体搜索的整体性能更优.
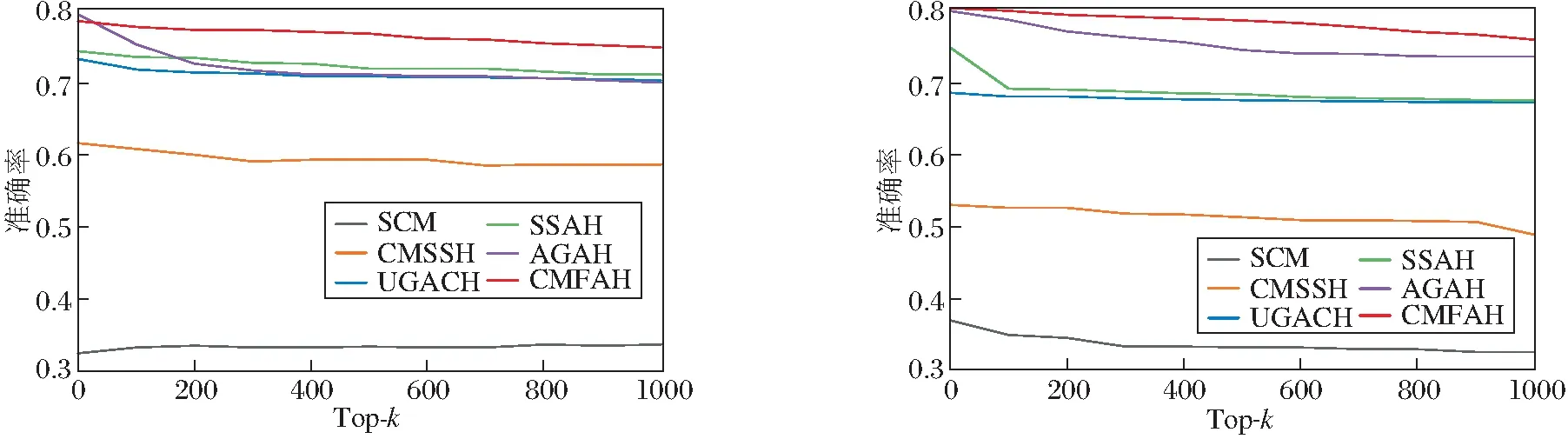
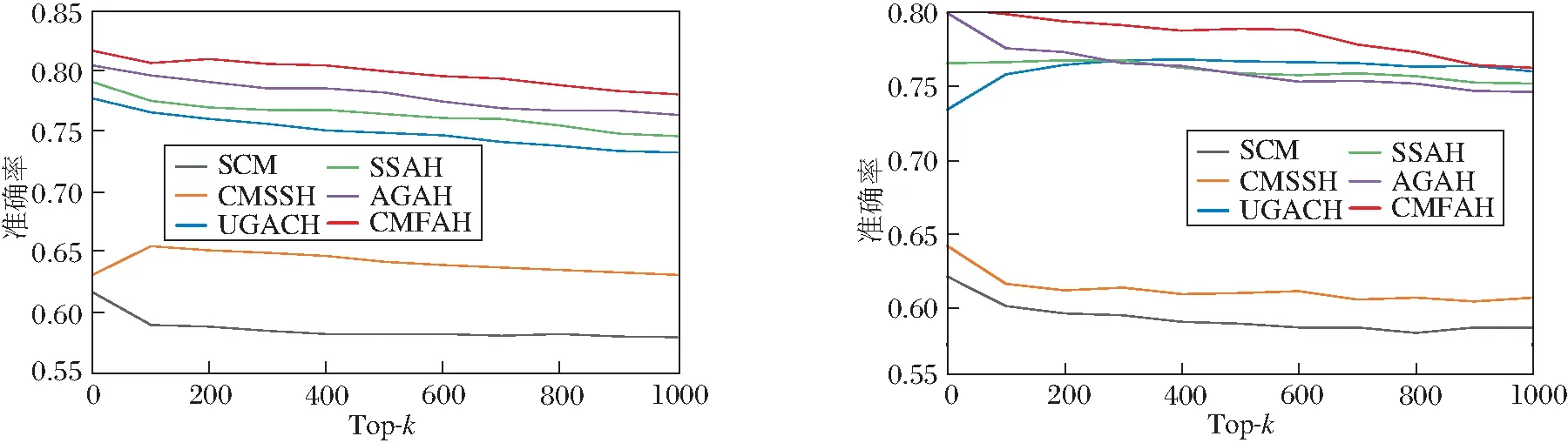
在NUS-WIDE、MIR-Flickr 25k数据集上,各算法在I→T和T→I两个跨媒体搜索任务上的Top-k准确率曲线如图3所示.
Top-k准确率曲线反映前k个返回的搜索结果中,正确的搜索结果所占的比例.由图可看出,CMFAH在任何Top-k值下均取得最优性能,并且随着k的增大,准确率有轻微下降.当k取较大值时,如k=1 000时,CMFAH也取得较高的准确率,这说明当用户需要较多的候选结果时,CMFAH也有较优的搜索性能.
(a1)I→T (a2)T→I
(b1)I→T (b2)T→I
2.3 消融性实验结果
为了验证CMFAH的有效性,在MIR-Flickr 25k数据集上,对CMFAH的3种不同变种CMFAH-ca、CMFAH-ia和CMFAH-ta进行对比分析.实验中哈希编码位数取64位.CMFAH的不同变种的MAP值对比如表4所示.由表可看出,相比CMFAH,不添加跨媒体注意力的CMFAH-ca的MAP值平均降低0.06.仅添加任一模态的注意力的CMFAH-ia和CMFAH-ta的性能均具有显著提升.综合对比发现,添加跨媒体注意力机制的CMFAH取得更高性能.由此说明,相比单一模态的注意力机制,跨媒体注意力机制对于跨媒体搜索性能具有显著提升作用.这主要得益于通过添加跨媒体注意力,CMFAH可充分学习不同模态数据之间的细粒度语义关联,取得更优的跨媒体搜索性能.
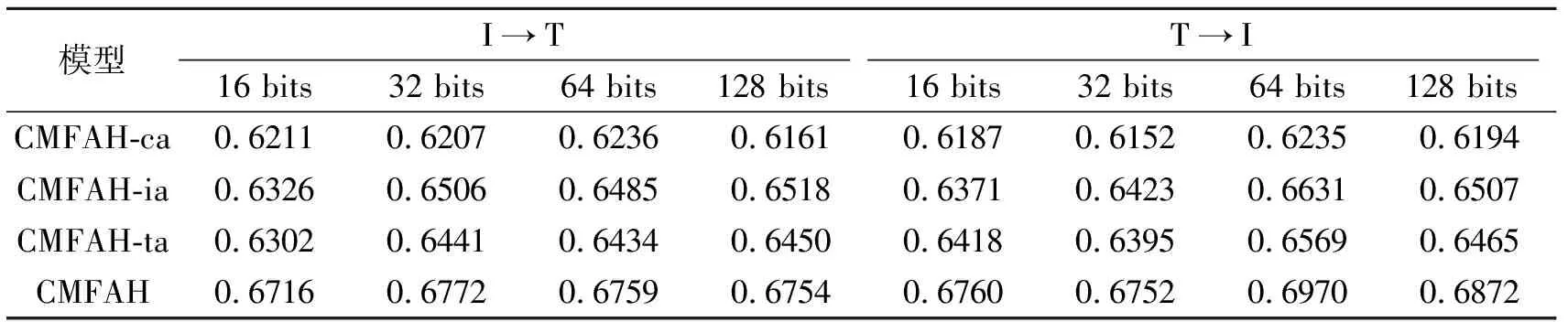
表4 CMFAH不同变种的MAP值对比Table 4 MAP comparison of different variants of CMFAH
2.4 参数敏感性分析
本组实验分析目标函数中超参数margin对于模型的影响.margin值表示在一个triplet三元组中,不相似的数据对的cosine相似度相比相似对的cosine相似度之间的间隔.在64位哈希码时,不同margin值对于MAP值的影响如图4所示.由图可看出,MAP值随着margin的增大而增大,当margin>0.5时又开始下降.当margin值较小时,模型较难区分相似对和不相似对,因此MAP值相对较小.当margin=0.5时,MAP在I→T和T→I搜索任务中取得更高值.因此,本文中设置margin=0.5,用于所有实验.

图4 margin对MAP值的影响Fig.4 Influence of margin on MAP
本组实验分析对抗哈希网络学习率gan_lr对模型性能的影响.在码长为64位时,gan_lr对于MAP值的影响如图5所示.由图可看出,当gan_lr=0.000 8时,在I→T和T→I搜索任务中取得的MAP值最高.因此,本文实验中设置gan_lr=0.000 8.
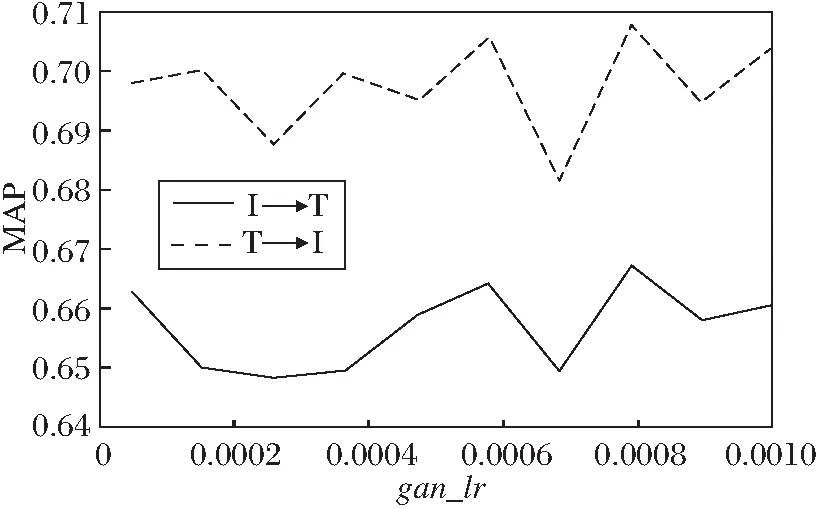
图5 gan_lr对MAP值的影响Fig.5 Influence of gan_lr on MAP
本组实验分析epoch值对跨媒体搜索性能的影响.在MIR-Flickr 25k数据集上进行实验,结果如图6所示.由图可看出,随着epoch的增大,模型逐步实现收敛,大约在epoch=150时,模型收敛趋于稳定.

图6 epoch对MAP值的影响Fig.6 Influence of epoch on MAP
3 结 束 语
为了解决跨媒体数据间的特征异构和语义鸿沟,以及社交网络数据的语义稀疏性、多样性问题,实现高效的大规模社交网络数据跨媒体检索,本文提出基于多模态图和对抗哈希注意力网络的跨媒体细粒度表示学习模型(CMFAH),将不同媒体类型的数据映射至高效的统一哈希语义空间内.构建基于跨媒体注意力机制的跨媒体细粒度特征学习网络及对抗哈希学习网络,将细粒度的跨媒体语义关联学习和对抗哈希学习集成在一个统一的框架下进行协同学习和优化,进一步增强跨媒体统一表示的语义一致性,获取更紧凑高效的统一哈希表示.此外,通过构建图像-单词关联图,充分挖掘图像和单词间的直接语义关联和隐含语义关联,实现语义关系扩展,进一步增强面向社交网络数据的跨媒体语义关联的学习能力,克服社交网络数据的稀疏性、多样性等问题.今后将结合图神经网络、对比学习等技术,进一步增强不同模态的深层次高阶语义关联学习能力.
猜你喜欢
计算机应用(2023年6期)2023-07-03 14:12:38
计算机应用(2023年5期)2023-05-24 03:18:12
红外技术(2022年11期)2022-11-25 03:20:40
高技术通讯(2021年1期)2021-03-29 02:29:24
电脑与电信(2018年11期)2018-02-16 05:41:32
信息安全研究(2016年3期)2016-12-01 06:06:41
工业设计(2016年8期)2016-04-16 02:43:34
出版与印刷(2015年3期)2015-12-19 13:15:13
计算机工程(2015年8期)2015-07-03 12:20:04
计算机工程(2014年6期)2014-02-28 01:27:19
