
基于深度学习的化妆品舆情事件实体关系抽取技术研究
2022-04-02 01:25吴迪,刘月恒,孟宏,邱显荣,张青川
电脑知识与技术 2022年33期
吴迪,刘月恒,孟宏,邱显荣,张青川



摘要:互联网的快速发展,使得舆情信息会在短时间内大范围传播。通过构建化妆品相关的知识图谱能够快速有效地发现舆情的焦点内容,有助于相关部门更好地掌握舆情导向,并且很好地支持后期的舆情分析。关系抽取和命名实体识别是构建知识图谱的关键技术。针对化妆品舆情存在的多实体关系问题,文章在BERT预训练模型的基础上构建了BERT-BiLSTM-CRF化妆品舆情实体关系抽取模型。在化妆品舆情数据集上进行了对比实验,实验结果表明:基于BERT-BiLSTM-CRF的化妆品舆情实体关系抽取模型比常用的几种神经网络模型高出2.68%~4.83%,验证了模型的合理性和有效性。
关键词:化妆品舆情;BERT;关系抽取
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2022)33-0025-03
1 概述
随着社交平台的快速发展,网民可以随时随地通过自己的社交软件参与舆情事件的讨论、发表观点、表达态度[1]。近年来,化妆品舆情的体量不断增加,在最近的统计信息中,化妆品负面舆情整体占比呈上升趋势。快速把握舆情信息的焦点内容有助于对舆情事件做出及时处理,正确引导公众的情绪,从而避免造成更严重的后果。然而在互联网平台存在大量的非结构化、具有歧义的文本数据。因此如何快速、精准且有效地对海量数据进行分析处理并将其转换为可以直接查询的结构化信息是至关重要的。
化妆品舆情知识图谱是以化妆品行业为基础,挖掘化妆品舆情事件之间的内在联系,在化妆品安全、化妆品舆情分析等方面都发挥着重要的作用。实体关系抽取是构建化妆品舆情知识图谱的重要基础工作之一,实体识别是指从文本中提取已命名的实体,并将其划分为指定的类别。关系提取是为了识别实体之间的一些语义关系。
在之前的研究中大多采用神经网络模型来抽取实体和关系,Li[1]提出了一个增量联合框架,使用结构化感知器提取实体和关系。Bai等人[2]提出了通过词嵌入的方式提取局部语义特征,设计了一种基于卷积神经网络(Convolutional Neural Network,CNN)的片段注意机制来提取实体关系。与CNN模型相比,RNN能更好地学习语句中上下文的语义信息。Socher等人[3]首次将矩阵-递歸神经网络模型(MV-RNN)应用于自然语言处理,有效地解决了单词向量模型无法捕捉长短语或句子的组成意义的问题。长短期记忆(LSTM)网络模型[4]与RNN模型具有相同的总体框架。但是LSTM允许每个神经单元忘记或保留信息,在一定程度上解决了RNN存在的爆炸梯度问题。Zhang等[5]提出了一种基于LSTM序列的位置感知注意机制,该机制与一种实体位置感知注意相结合,以实现更好的关系提取性能。随着预训练模型的不断发展,BERT预训练语言模型在各种自然语言处理任务上都取得了表较好的效果。Gao等[6]提出了一种基于BERT的医学关系提取模型,该模型将从预先训练的语言模型中获得的整个句子信息与两个医疗实体的对应信息相结合,完成关系提取任务。
本文在分析现有实体关系抽取方法的优劣的基础上,针对化妆品舆情方面的语料,构建了基于BERT-BiLSTM_CRF的实体关系抽取模型,能够很好地抽取实体和关系信息。
2 基于BERT-BiLSTM-CRF的化妆品舆情实体关系抽取模型
本文构建的是实体关系抽取模型包括是BERT层、BiLSTM层和CRF层三部分,模型结构如图1所示。
2.1 BERT层
基于已有的Word2Vec、GPT等语言模型,2018年Google团队提出BERT[7]预训练语言模型,该模型可以学习输入序列的特征表示,然后再把学习的特征表示应用到不同的下游任务中任务。BERT可以通过无监督的方式使用大量未标记的文本进行训练。通过构建标记语言模型,BERT可以随机覆盖或替换句子中的任何单词,使模型能够预测被上下文随机覆盖的部分,得到该单词的分布式上下文表示。BERT模型中Transformer采用自注意力机制和全连接层处理输入的文本。Transformer采用的多头注意力机制,可以获得多个维度的信息。本文模型将BERT的输出结果输入BiLSTM[8]层中。
2.2 BiLSTM层
BiLSTM接收BERT输出的向量作为输入,从而获得更加全面的语义信息。BiLSTM对每个训练序列应用一个前向和后向LSTM网络,两个LSTM网络连接到同一个输出层。LSTM计算主要是三个门结构:输入门、遗忘门和输出门。具体计算公式如下所示:
[it=σ(Wi∙[ht-1,Xt]+bi)] (1)
[ft=σ(Wf∙[ht-1,Xt]+bf)] (2)
[Ct=tanh(WC∙[ht-1,Xt]+bC)] (3)
[ot=σ(Wo∙[ht-1,Xt]+bo)] (4)
[Ct=ft*Ct-1+it*Ct)] (5)
[ht=ot*tanh(Ct)] (6)
其中,[Wi]、[Wf]、[Wo]是加权矩阵,[bi]、[bf]、[bo]是LSTM的偏差。[it]、[ft]、[ot]分别代表t时刻的输入门、遗忘门和输出门,[Xt]表示在t时刻的输入,[ht]表示在t时刻的输出。
2.3 CRF层
条件随机场(CRF)[9]是一种以指定的随机变量为输入,解决随机输出变量的条件概率分布的算法。近年来,它被广泛应用于词性标记、句法分析和命名实体识别等领域。CRF可以考虑相邻标记结果之间的关系,并在全文中得到最优的标记序列结果。CRF的基本算法定义如下:
[S(x,y)=i=1nAyi-1yi+i=0npi].[yi] (7)
[P(y|x)=eS(x,y)~y∈YxeS(x, ~y)] (8)
其中BiLSTM层的输出结果定义为[Pmn],其中n表示单词数,m表示标签类别。其中,[Pij]表示第i个标签与第j个标签匹配的概率。对于输入的句子序列x={x1,x2,...,xn}及其预测的序列y={y1,y2,...,yn}。
3 实验
3.1 数据集与数据预处理
本文将在化妆品舆情领域单独构建的舆情数据作为实验数据集。自建语料库从专业和权威网站通过爬虫获取有关化妆品舆情(如百度、微博)的数据。对需要处理的数据采用BIO标注方式,其中,B表示实体的第一个字,I表示第二个单词以及后面的字和O表示不属于特定实体的词。
3.2 实验参数设置
3.3评价指标
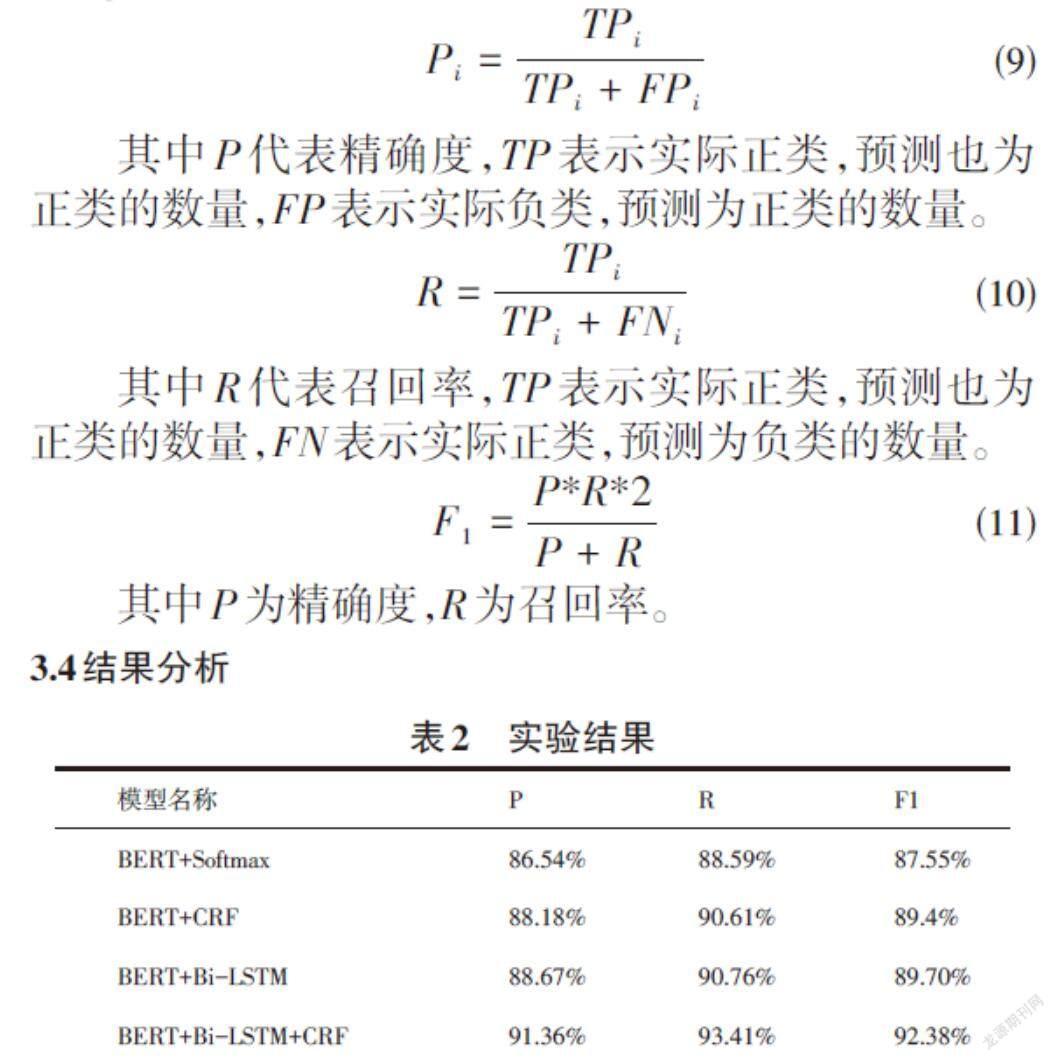
本文采用三个常见的指标,即精度(P)、召回率(R)和F1来评估模型。计算公式如下:
[Pi=TPiTPi+FPi] (9)
其中P代表精确度,TP表示实际正类,预测也为正类的数量,FP表示实际负类,预测为正类的数量。
[R=TPiTPi+FNi] ; (10)
其中R代表召回率,TP表示实际正类,预测也为正类的数量,FN表示实际正类,预测为负类的数量。
[F1=P*R*2P+R ] (11)
其中P为精确度,R为召回率。
3.4结果分析
实验结果如表2所示,笔者的模型在P、R、F1三个指标上均取得了更好的效果。此外,通过对比不同模型之间的实验结果,可以发现,BERT+CRF模型的性能高于BERT+Softmax模型,证明了CRF模型可以有效解决标签之间的依赖关系,避免生成错误的标签序列。BERT+Bi-LSTM模型的性能高于BERT+CRF模型与BERT+Softmax模型,证明了双向长短时记忆网络可以有效利用上下文信息,并可以有效建模序列特征之间的依赖。
4 结束语
本文提出了一种基于Bert-BiLSTM-CRF的化妆品舆情实体关系提取模型,该模型通过Bert对文本进行向量化,随后利用BiLSTM模型学习上下文信息,更好地进行特征提取,进而完成实体关系的提取。实验结果表明,本文提出的模型相较于其他深度学习模型在性能上更优。
参考文献:
[1] Li Q,Ji H.Incremental joint extraction of entity mentions and relations[J].52nd Annual Meeting of the Association for Computational Linguistics,ACL 2014 - Proceedings of the Conference,2014,1:402-412.
[2] Bai T,Guan H T,Wang S,et al.Traditional Chinese medicine entity relation extraction based on CNN with segment attention[J].Neural Computing and Applications,2022,34(4):2739-2748.
[3] Socher, Richard Semantic Compositionality through Recursive Matrix-Vector Spaces.EMNLP ,2012.
[4] Miwa M,Bansal M.End-to-end relation extraction using LSTMs on sequences and tree structures[J].54th Annual Meeting of the Association for Computational Linguistics,ACL 2016 - Long Papers,2016,2:1105-1116.
[5] Zhang Y H,Zhong V,Chen D Q,et al.Position-aware attention and supervised data improve slot filling[C]//Proceedings of the 2017 Conference on Empirical Methods in Natural\n Language Processing.Copenhagen,Denmark.Stroudsburg,PA,USA:Association for Computational Linguistics,2017s.
[6] Gao S X,Du J L,Zhang X.Research on relation extraction method of Chinese electronic medical records based on BERT[C]//Proceedings of the 2020 6th International Conference on Computing and Artificial Intelligence.Tianjin,China.New York:ACM,2020:487-490.
[7] Devlin J,Chang M W,Lee K,et al.BERT:pre-training of deep bidirectional transformers for language understanding[EB/OL].2018:arXiv:1810.04805.https://arxiv.org/abs/1810.04805
[8] Chen C M.Feature set identification for detecting suspicious URLs using Bayesian classification in social networks[J].Information Sciences,2014,289:133-147.
[9] Lafferty J D,McCallum A,Pereira F C N.Conditional random fields:probabilistic models for segmenting and labeling sequence data[C]//Proceedings of the Eighteenth International Conference on Machine Learning.New York:ACM,2001:282-289.
【通聯编辑:唐一东】
