
基于Flutter动态化的作用域管理研究
2022-03-31 06:29刘桐刘刚郭发玉孙晓栋袁伟
电子技术与软件工程 2022年24期
刘桐 刘刚 郭发玉 孙晓栋 袁伟
(1.数字化家电国家重点实验室 山东省青岛市 266103 2.青岛海尔科技有限公司 山东省青岛市 266103)
(3.海尔优家智能科技(北京)有限公司 陕西省西安市 710000)
随着互联网行业的飞速发展和用户基数的不断扩充,高速化的迭代需求日益凸显,而传统的移动终端应用开发往往不能满足迭代的速度性,这就促使着开发者不断寻求一种在保障性能的情况下提升迭代速度的解决方案。鉴于此,行业内衍生出了混合开发,但不管是 Hybrid、React Native 还是Webview 嵌套 H5,都存在一个共同的弊端:即在性能纬度上,远远达不到原生应用的效果,Flutter 框架依靠其高性能的渲染引擎 Flutter Engine,开发出的移动应用性能几乎与原生应用无差别[1]。这也是Flutter 对比混合开发的最大优势,但也存在很大的弊端——无法支持热更新,这就意味着需求无法以最快的速度触达到用户,这也就成为了一些开发者选择Flutter 比较顾忌的点。
为了使 Flutter 能够具备动态化热更新的能力,本文给出一种有效的解决方法。首先,利用 Dart 官方提供的 Analyzer分析库,将 Dart 代码生成为 AST[2],然后根据 AST 信息组装生成所需要的 DSL JSON 文件,在 APP 运行时开发一套解析器来解释和执行DSL JSON 文件。而对于运行时的作用域管理,是决定运行时执行效率的关键点。目前在计算机领域中作用域管理通常采用“堆栈”形式的数据结构,即“先进后出”的工作模式[3]。然而,这种堆栈式的数据结构存在数据读取效率不高的问题。例如,现有技术在基于无序的数据索引情况下,使用传统堆栈时查找的时间复杂度是O(n),插入的时间复杂度是O(1),其中查找相比于插入效率就会低很多,这对于软件层面上的执行来说效率是低下的,尤其对于涉及到需要快速读取和频繁读取的工作中。
针对传统的作用域管理存在的问题,本文提出了一种新的数据结构来实现运行时作用域管理。该数据结构包括了哈希表与双向链表两部分[4]:双向链表包括若干用于存储函数唯一哈希值以及函数作用域的键值结点,哈希表包括了若干用于存储函数唯一哈希值以及链表结点的链接结点;各个键值结点之间均为双向连接,且每个链接结点保存了对应的键值结点的引用。基于散列函数计算key 键值对应的哈希码,读取哈希码对应的链接结点。通过将哈希表与双向链表的结合,从而简化了逻辑,相对于堆栈来说,上述技术可以将查找的时间复杂度从线性时间O(n)降低至常数时间O(1)。线性时间复杂度,表示算法的运行时间随着输入数据的规模线性增长。而常数时间复杂度,不论输入数据的规模是多少,对于运行时间来说,其对外表现的运行查找效率是一致的。
本文第1 节介绍本文所需的基础知识,包括抽象语法树和深度遍历。第2 节介绍本文阐述的作用域模型。第3 节介绍了运行时的内存释放机制。第4 节通过对比实验验证了所提模型的有效性。最后总结全文。
1 基础知识
本文所提方法主要基于抽象语法树,下面就相关概念和基本知识予以介绍。
1.1 抽象语法树
抽象语法树(Abstract Syntax Tree,缩写:AST)是用正式语言编写的文本(通常是源代码)的抽象语法结构的树形结构表示。树的每个结点表示文本中出现的构造。抽象语法树是编译器中广泛使用的数据结构,用于表示程序代码的结构。AST 通常是编译器语法分析阶段的结果。它通常通过编译器所需的几个阶段作为程序的中间表示,并且对编译器的最终输出有很大的影响。
1.2 标识符
标识符(Identifier)是指用来标识某个实体的一个符号,在不同的应用环境下有不同的含义。在计算机编程语言中,标识符是用户编程时使用的名字,用于给变量、常量、函数、语句块等命名,以建立起名称与使用之间的关系。标识符通常由字母和数字以及其它字符构成。
1.3 深度遍历
深度遍历(Depth-Frist-Search,缩写:DFS)是一种用于遍历或搜索树或图数据结构的算法。该算法从根结点开始(在图的情况下选择某个任意结点作为根结点)并在回溯之前沿着每个分支尽可能深地探索。当结点v 的所在边都己被探寻过,搜索将回溯到发现结点v 的那条边的起始结点。这一过程一直进行到已发现从源结点可达的所有结点为止。如果还存在未被发现的结点,则选择其中一个作为源结点并重复以上过程,整个进程反复进行直到所有结点都被访问为止。通过深度遍历,就可以遍历整个图,从结点的角度来说,通过深度遍历,就可以遍寻到所有的结点。
1.4 统一资源标识符
统一资源标志符(Uniform Resource Identifier,缩写:URI)在电脑术语中是用于标志某一互联网资源名称的字符串。该种标识允许用户对任何(包括本地和互联网)的资源通过特定的协议进行交互操作。
1.5 作用域
作用域(Scope)在程序设计中,是标识符与实体的绑定保持有效的一部分计算机程序。不同的编程语言可能采用不同的作用域(静态作用域/动态作用域);静态作用域又称词法作用域,采用词法作用域的变量叫词法变量。词法变量有一个在编译时静态确定的作用域。相反,采用动态作用域的变量叫动态变量。只要程序正在执行定义了动态变量的代码段,那么在这段时间内,该变量一直存在;代码段执行结束,该变量便消失。本文阐述的作用域为静态作用域。
2 模型设计
为了解决运行时查找效率低下的问题,以及使用哈希表存储数据时,容易产生哈希冲突的问题。本文阐述了一种使用哈希表替换堆栈,作为运行时作用域管理的数据结构,以及生成唯一哈希值解决现有技术中哈希冲突的问题。
基于 Dart SDK 内置的 analyzer 分析库,解析出 dart 目标文件,生成抽象语法树(AST),同时获取抽象语法树中所有的标识符(identifier)结点;基于标识符的自身信息,获取其所声明文件的URI。通过标识符结点中的信息,再基于自定义Builder,能够在编译阶段生成其种类及唯一的标识,具体步骤如下:
(1)基于 dart 目标文件,生成抽象语法树;
(2)通过对抽象语法树进行深度遍历,找出所有标识符结点;
(3)基于标识符结点中的信息,得到其名称;
(4)基于标识符结点所声明文件的URI,得到其全限定名;
(5)结合自定义Builder,所有的标识符都会被赋予一个种类,比如顶级变量、全局函数、局部变量等;
(6)基于步骤(3)和步骤(4)得到的名称和全限定名,结合自定义Builder 进行整合拼接,能够得到一个唯一的 hashcode,此 hashcode 可以替代该标识符存储在作用域中;
运行时作用域模型设计,具体包括:双向链表以及哈希表。其数据结构模型如图1所示:双向链表中的结点,key存储对应函数的hashcode,value 存储其对应的函数作用域;哈希表中的结点,key 同样存储函数的hashcode,value 指向其对应的双向链表结点。具体实现思路如下:

图1:作用域模型
(1)APP 运行时,解析器开始加载DSL JSON 文件,此时需要先构造出全局作用域来存储顶级变量的数据模型,在双向链表中创建一个头结点,此结点中key 存储字符串字面量‘global’,value 存储全局作用域的引用。全局作用域的存储数据结构为{key:value}键值对形式,其中key 为顶级变量的hashcode,value 存储其具体的数据模型;
(2)解析器在加载到顶级变量时,从 DSL JSON 文件中提取出顶级变量的信息,同时开始解析其DSL JSON 信息,并生成对应的数据模型来表示具体的顶级变量,最后将该数据模型存储在全局作用域中;
(3)全局作用域构造完成后,需要在哈希表中增加一个键值对,key 同样存储字符串字面量‘global’,value 指向双向链表中全局作用域结点;
(4)解析器在加载到全局函数时,从DSL JSON 文件中提取出函数对应的信息,其中函数信息包括函数对应的标识符名称及全局唯一的 hashcode,基于函数信息,构建出对应全局函数的数据模型。同时在双向链表尾部插入一个结点用于存储该全局函数作用域,哈希表中新增一个键值对来指向该函数作用域。
(5)解析器在加载到全局函数调用语句时,先根据全局函数的hashcode 从哈希表中找到其对应的作用域;
(6)解析器在加载到全局函数中的代码块语句时,将其中的局部变量转化为对应的数据模型,并存储在其所处函数的作用域中;
(7)解析器在加载到函数内部声明的局部函数时,将局部函数内声明的局部变量转化为对应的数据模型,并存储在其所处函数的作用域中;
(8)解析器在解析执行变量查找时,首先根据该变量在编译阶段生成的种类,判断需要从哪个作用域中进行查找。例如:变量种类为顶级变量时,则直接从全局作用域中进行查找;变量种类为局部变量时,则直接从对应函数的作用域中进行查找。
以图2、图3 代码为例,具体说明运行时中作用域的符号/变量查找流程。

图2

图3
(1)执行函数调用语句test(),在哈希表中根据test 全局函数的hashcode 查找其函数作用域;
(2)在 test 函数体中,执行语句;
(3)执行到变量声明语句时,将变量c 存入当前函数作用域;
(4)runtime 在执行到 a>b 时,需要先根据编译阶段生成的种类,判断需要从当前函数作用域查找还是从全局作用域中查找;
(5)发现变量a、变量b 均为顶级变量,则会直接在全局作用域中查找;如果为局部变量的话,则直接在当前的函数作用域中进行查找;
(6)在全局作用域中查找到了变量a、变量b,读取其值;
(7)执行比较结果,发现a>b 结果不成立;
(8)继续执行 c=func() 这条赋值语句;
(9)从哈希表中,根据func 的hashcode 查找func 的函数作用域;
(10)查找到后,执行func 函数体中语句并返回结果。
在本示例中,双向链表的头结点指向全局作用域,双向链表中的头结点存储值为 ‘global’,global 为全局作用域的意思,这样有利于程序的变量共享,可以简化添加和修改的流程。在源码的运行时,即代码中函数语句执行时,在创建一个链表结点之后,将函数的 hashcode 作为key、将其对应的作用域作为value,存储在新增的结点上,同时会将函数标识符即 hashcode 作为 key 值、其对应的链表结点引用作为 value 存入哈希表中。
在函数调用语句执行前,首先根据函数的hashcode 在哈希表中进行查找,查找到后,哈希表中存储的value 指向了其对应的函数作用域。在函数内部语句执行的过程中,则会根据标识符的种类分别在不同的作用域中进行查找。源码中的函数语句执行完成后,会将其对应的函数作用域进行释放。
本示例中,首先在编译阶段结合自定义Builder,生成标识符的种类以及唯一的 hashcode,通过函数标识符的hashcode 在双向链表中增加新的链表结点,并且在双向链表中存储key 以及函数作用域,同时将hashcode 作为 key、其对应的链表结点作为 value 存储在哈希表中。此方法可以将传统的作用域查询效率提升到最优(常数阶:O(1)),与存储的数据规模(n)无关。从而相对于堆栈的方式来说,降低了查询的时间复杂度。
综上,该模型具体涵盖了三部分,包括:编译阶段生成标识符种类及唯一的 hashcode,加载阶段生成作用域模型,解释运行时阶段变量的查找及赋值。其中:
(1)编译阶段:基于目标 dart 源文件生成抽象语法树。结合自定义Builder,找到抽象语法树中所有的标识符结点,根据标识符的 name 信息、URI 信息,然后进行整合拼接,生成唯一的 hashcode。
(2)加载阶段:解析器在加载 DSL JSON 文件时,根据在编译阶段生成的标识符种类,遇到顶级变量声明语句,则将其转化为具体的数据模型存储在全局作用域中。遇到全局函数声明结点,则在双向链表中新增一个结点,将其标识符对应的 hashcode 作为key,其对应的函数作用域作为value 存储到新增的结点中;同时将 hashcode 存储在哈希表中作为 key 值,其对应的链表结点作为 value;哈希表中存储的结点始终指向其对应链表结点。
(3)解释运行时阶段:根据标识符的种类,如果是顶级变量,则直接在全局作用域中进行查找;如果是局部变量,则直接在当前作用域中进行查找。如果标识符的种类是函数,则在哈希表中根据hashcode 查找其对应的函数作用域。
3 内存释放
内存空间是所有程序的公共资源,排除已经被占用的内存,空闲内存往往是散落在各个地方的。我们知道,存储数组、栈等数据结构需要内存空间连续,当我们需要申请一个很大的数组、栈时,系统不一定存在这么大的连续内存空间。而链表则更加灵活,因为其每个结点都是通过指针相连,所以存储链表时并不需要内存地址是连续的,只要剩余内存空间大小够用即可。
如何将APP 的内存开销降低到最小,以保证APP 整体运行的稳定性及用户体验,这就成为了本研究中无法避免的问题。上述方案中,能够导致内存增加的主要原因就是随着程序执行,作用域中存储的数据会越来越多,如果不进行内存释放,则很有可能会导致APP 运行时内存溢出崩溃,进而影响用户的使用意愿。
本研究采取的方案为:基于上述整体设计,在函数调用语句整体执行完后,将其对应的函数作用域置为空,保留其在双向链表中的结点及哈希表中的引用;在整个页面退出时,将运行时持有的作用域全部释放,包括将双向链表置为空及哈希表置为空。此方案不仅能够将内存使用开销降低至最小,还可以保证运行时作用域查找的效率。
4 性能比对
对于本研究设计方案的计算性能,我们考虑使用Nilakantha 级数来计算 Pi 的值,在该公式中,从3 开始,依次交递加减以4 为分子、三个连续整数乘积为分母的分数,每次迭代时三个连续整数中的最小整数是上次迭代时三个整数中的最大整数。反复计算多次,结果与 Pi 非常接近。
具体公式如下:
π=3+4 ⁄(2×3×4)-4 ⁄(4×5×6)+4 ⁄(6×7×8)-4 ⁄(8×9×10)+4 ⁄(10×11×12)…
具体实现代码如图4所示,使用 Dart DevTools 分析工具,分析图4 代码的运行结果。对于使用堆栈进行作用域管理,在进行变量查找时,其自身耗时过多。综合平均运行时间为1.58 秒,在使用本文阐述的新数据结构后,使用相同的测试代码,综合平均运行时间为486 毫秒,对比改造前的运行效率提升了69.2%。

图4:具体实现代码
对于页面渲染帧率,使用Dart DevTools 分析工具获取操作页面后的平均帧率如表1 格所示,可以看到动态化页面渲染帧率基本与AOT 页面持平,其表现已接近于Flutter 原生性能。
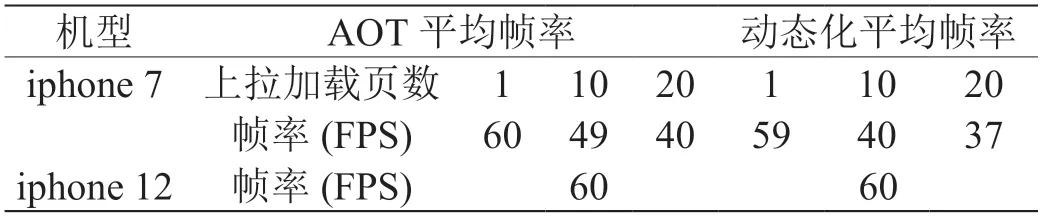
表1:平均帧率
5 结束语
本方案阐述了一种运行时作用域管理的整体方案流程,在编译阶段结合自定义Builder,对所有标识符赋予特定的种类以及整合后唯一的 hashcode,就可以将传统的作用域管理的数据结构—堆栈,转化为哈希表及双向链表的结合;这样就可以将作用域查询效率从O(n)提升至O(1),从而达到最优的运行时效率。本方案阐述的数据结构,因为其自身的存储特性,可以最大程度的利用系统的内存空间
猜你喜欢
中国设备工程(2023年16期)2023-08-29
计算机应用(2022年8期)2022-08-24
计算机系统应用(2020年8期)2020-03-22
成都信息工程大学学报(2019年2期)2019-08-28
成都信息工程大学学报(2018年1期)2018-05-31
计算机工程(2015年8期)2015-07-03
电测与仪表(2014年1期)2014-04-04
计算机工程(2014年6期)2014-02-28
电子设计工程(2014年12期)2014-02-27
