
基于XGBoost的测井解释规则库自动获取方法
2022-03-25 11:21:44张晋言王镇方姜文宗刘宝弟王延江
石油物探 2022年2期
邢 强,张晋言,王镇方,马 睿,姜文宗,刘宝弟,王延江
(1.中石化经纬有限公司胜利测井公司,山东东营257096;2.中国石油大学(华东)海洋与空间信息学院,山东青岛266580;3.中国石油大学(华东)控制科学与工程学院,山东青岛266580)
近年来,随着深井、超深井、复杂井的日益增多[1],以及油气风险勘探开发力度的不断加大,利用快速发展的人工智能算法实现测井资料处理解释的自动化、智能化[2],提高测井资料处理解释的质量与效率,降低劳动强度,已成为测井资料处理解释的发展趋势。
在测井解释评价领域,解释评价技术存在着区域性差异和共性[3-4]。由于沉积环境、埋深等地质条件的不同,各区块在孔、渗、饱等评价参数方面既有共性又有差异性[5],而采用传统的测井解释方法很难判断这两者的区别,只有通过经验的累积(包括解释软件使用经验、实验室成果分析以及取心、录井资料的对比),才能解决这一问题。
20世纪80年代国外已经发展了多种石油测井解释的专家系统,如地层倾角解释咨询系统、岩性模式识别(LITHO)专家系统以及岩石物性评价知识库(LOGIX)系统,而国内主要有油井测井解释专家系统(OWLI)和石油测井解释专家系统(LIX)[6]。这些系统通过计算机模拟专家的思维方法和解释过程,汇集多个解释专家的知识和经验作为专家规则库,可以让普通解释人员完成类专家级的解释评价任务。但在实际应用中,上述系统存在规则逻辑处理较为复杂、规则库只能由测井解释专家手工编写、不能自动获取规则等问题。近年来,随着人工智能技术的发展,利用机器学习相关的方法进行测井解释已然成为热点研究方向[1-2,5-6]。朱剑兵等[7]提出了基于双向循环深井网络的河流相储层预测方法,有效指导了研究区的勘探部署;林年添等[8]提出了基于无监督与监督学习的多波地震油气储层分布预测方法,较为准确地刻画了含油气储层的分布边界;王兴龙等[9]提出利用C5.0决策树算法来解释储层渗透率,该方法具有一定的普适性;丁磊等[10]针对泥质体积分数高、物性差的储层,基于印度尼西亚公式开发了改进皮克特图版,为测井解释评价提供了更为精确的参数。目前,大多数方法[7-10]使用单个学习器完成测井解释任务,容易出现过拟合和欠拟合的情况,而鲜有方法将集成决策树模型应用于此。集成决策树模型是监督学习中最强大也最常用的模型之一,其本身不是一个单独的机器学习算法,而是通过构建并结合多个机器学习器来完成学习任务,由此来提升算法性能。基于此思想,CHEN等[11]提出了极端梯度提升决策树算法(extreme gradient boosting,XGBoost),学习过程中迭代多棵决策树来共同决策。相比于单决策树的模型,XGBoost训练过程比较稳定,提升了预测效果。
针对上述问题,本文在文献[11]的基础上,提出了一种基于极端梯度提升决策树的测井解释专家规则的自动获取方法。该方法以测井数据、录井资料、地质资料等为特征,以试油结果为标签,在数据集中训练集成决策树模型,建立输入特征与试油结论之间的专家规则。为证明XGBoost算法的有效性,本文使用支持向量机(support vector machine,SVM)算法[12-13]和梯度提升决策树(gradient boosting decision tree,GBDT)算法[14]建立相同的规则库进行效果对比,并将其应用于老井复查以形成研究区内共性的解释知识规则。
1 XGBoost算法原理
集成学习是机器学习的一种范式,该方法通过训练多个弱分类器来解决相同的问题,并将它们结合起来以获得更好的结果。而XGBoost作为一种改进的集成决策树算法,因其性能优越,对输入要求不严格,计算复杂度低等特点,往往是数据挖掘和机器学习[15-16]算法中必备工具之一,在工业界中也有大量应用。
XGBoost使用分类回归决策树(classification and regression tree,CART)模型作为基分类器,将多个决策树以加法训练(additive training)的形式集成起来得到最后的输出模型,训练原理如图1所示。与GBDT不同的是,XGBoost在目标函数中增加了正则化项来控制模型的复杂度,并且对损失函数进行二阶泰勒展开,利用二阶导数信息可使得模型收敛更快,精度更高。
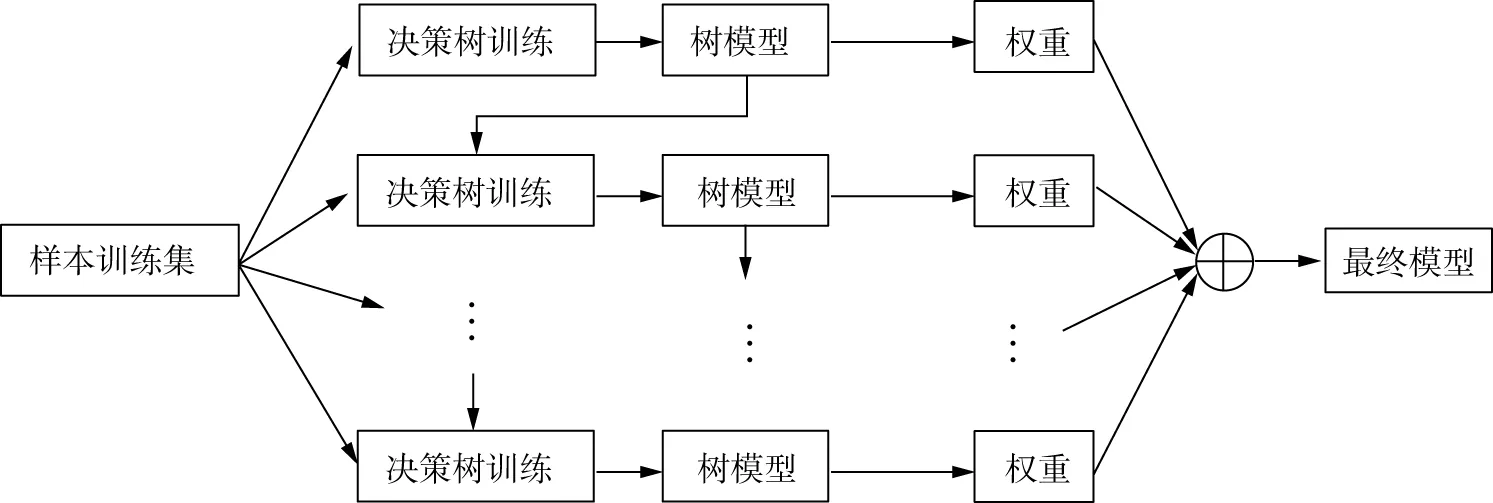
图1 XGBoost训练原理
XGBoost的目标函数J定义如下:
(1)
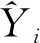
对于加法训练模型来讲,每一轮的训练数据来自于上一轮训练时产生的残差,本轮的总预测值是上一轮的总值和本轮分类模型的预测值之和,即:
(2)

(3)
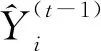
对XGBoost的目标函数取泰勒展开的二阶近似,则目标函数变为:
(4)
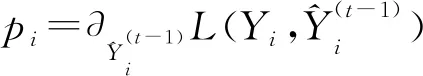
XGBoost中使用叶子节点个数M以及每个叶子节点的得分μ组合成为正则化项Ω,用于控制树的复杂度。这样训练出来的模型既简洁有效,还可以防止出现过拟合。正则化项Ω定义为:
(5)
其中,γ和λ为常数,其默认值分别为0和1。当出现过拟合的情况时,适当增大γ和λ可以使算法更加保守,防止过拟合的发生。由此,第t轮的最终目标函数可以表示为:
(6)
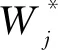
(7)
由(6)式、(7)式可以得到目标函数的最优值:
(8)
在实际训练过程中,XGBoost获取最优切分点时会对树中的叶子结点尝试进行分裂。新分裂一个结点后,需要检测这次分裂是否会给损失函数带来增益(Gain),增益的定义如下:
(9)
其中,
(10)
(11)
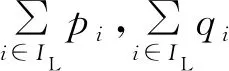
综上所述,将样本特征作为输入,选取CART作为弱分类器,使用增益最大的标准选取最佳切分特征与最佳切分点后,通过计算预测的标签值与真实标签之间的损失来加性地进行训练并集成到一起,即可得到最终的XGBoost模型。
2 应用实例
在测井过程中,面对以发现和评价油气水层为核心目标的复杂储层评价这一难题,建立一种新的基于学习并可自动获取知识的测井规则库是非常有必要的[4]。
本文提出一种基于XGBoost的测井规则自动获取方法,其技术流程如图2所示。首先根据已有的测井数据建立数据集,然后经过特征选择及数据处理等得到训练数据并以此训练XGBoost模型,从而得到自动获取的规则库。
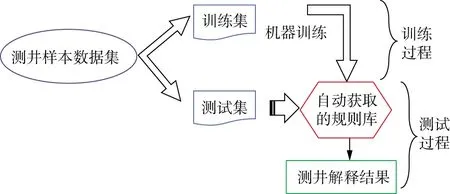
图2 基于XGBoost的测井规则自动获取流程
2.1 创建样本数据集
以胜利油田盐家永安地区砂砾岩油气藏为研究区,选择其中已完成试油的17口井作为研究目标。首先,以0.1m为步长对已完成试油和测井解释的井段的测井曲线进行采样,共获得6489个样本数据。经统计,数据集中样本的试油结论表明共有水层、油层、干层、泥岩层、油水同层、含油水层6类(表1)。
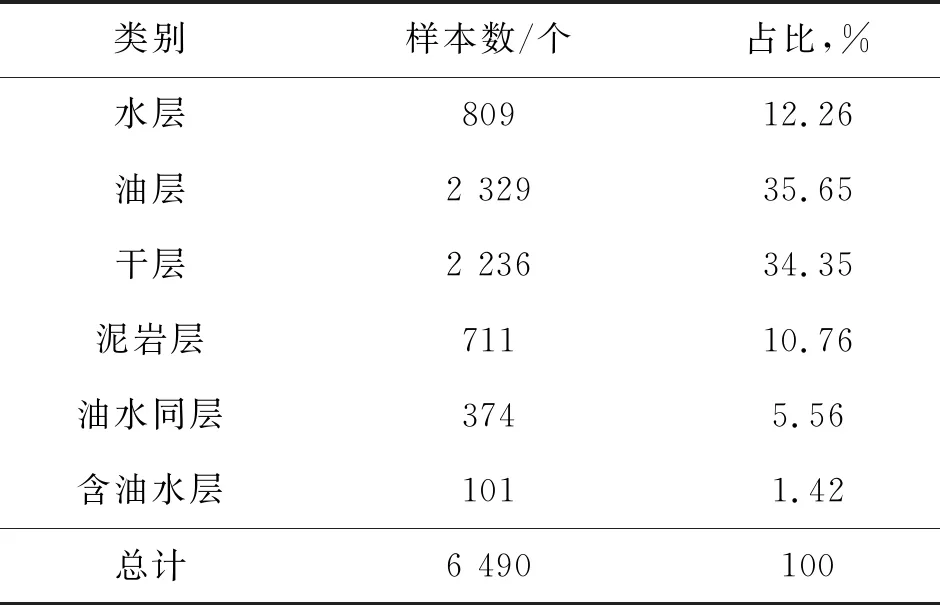
表1 研究目标中各类储层数量及占比
对该研究区内测井资料及地质参数进行分析,选择了补偿中子(CNL)、补偿密度(DEN)、声波时差(AC)、地层真电阻率(RT)、冲洗带地层电阻率(RXO)、自然电位(SP)、井径(CAL)、自然伽马(GR)和全烃曲线(QT)这9个参数作为每个样本的特征,将各样本的试油结论作为真实标签。将所有样本汇总到一起,构建总的大样本数据集。
2.2 数据处理
首先利用现有测井解释软件读取每口井的参数曲线,再将连续的数据按特定步长采样为离散的样本并保存为文本文件,进而转化为方便程序读取的CSV文件。在输入数据时,将各样本的标签信息通过独热编码进行处理,转化为多维向量的表示形式,“1”所在的位置代表其类别,避免了简单数值替换标签带来的一系列影响(表2)。
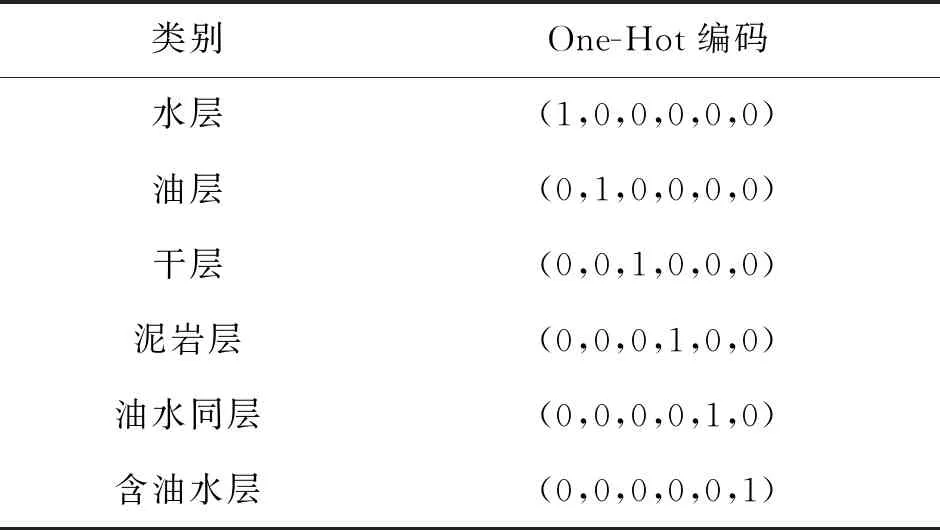
表2 本文方法的One-Hot编码方式
XGBoost作为树形结构模型,其寻找最优点的过程通过寻找最优分裂点完成,而数值缩放不影响分裂点位置,因此特征之间的数据量纲和数量级的不同并不会对其产生影响。因此,相比于线性模型,树形结构模型不需要对数据集进行额外的特征预处理就能满足分类任务,避免了对数据集进行归一化或标准化处理而带来的特征信息损失。
将总样本数据集按7∶3划分为训练集和测试集进行数据处理,其中训练集包含4543个样本,测试集包含1946个样本。
2.3 模型对比及应用
2.3.1 实验环境
利用Python语言建立XGBoost模型。运行环境:服务器内有两块14核CPU,共187.39GB内存,CPU型号为Intel(R)Xeon(R)Gold5120@2.20GHz。
2.3.2 实验设置及实验结果
XGBoost作为机器学习模型,在训练时需要进行各种参数的调整,其中较为重要的超参数有:迭代次数N,即模型迭代的次数;学习率lr,用以调整每棵决策树的权重来提高模型的鲁棒性;最大树深度Dmax,最小样本权重Wmin则是用以停止树的循环生成,当树深度达到最大深度Dmax或样本权重和小于阈值Wmin时则停止分裂,避免树过深导致其学习到过于局部的样本,防止过拟合。在参数寻优过程中,本文采用K折交叉验证与网格搜索(grid search with cross validation)相结合的方式来选取最优参数。
K折交叉验证是指将初始训练集分割成K个子数据集,一个单独的子数据集被保留作为验证模型的数据,其它K-1个子数据集用来训练。交叉验证重复K次,每个子样本验证一次,平均K次的结果,最终得到评估结果。该方法的优势在于可以减少在单次随机划分数据集时,因划分方式不同带来的差别,降低其在调参过程中的影响。考虑到运算时间及内存占用,本文选取K=10进行实验。
网格搜索是一种基于穷举的搜索手段,即在所有候选的超参数选择中,通过循环遍历,尝试每一种可能性,选择得到最高准确率的超参数作为最终的结果。
首先,对于迭代次数N,本文在1~200内进行搜索,并在N=159时取得最大值(图3)。

图3 模型在不同迭代次数下的准确率
其次,在0.1~1.0内对学习率的最优参数进行搜索,取得学习率的最优值为0.281,其实验结果如图4 所示。
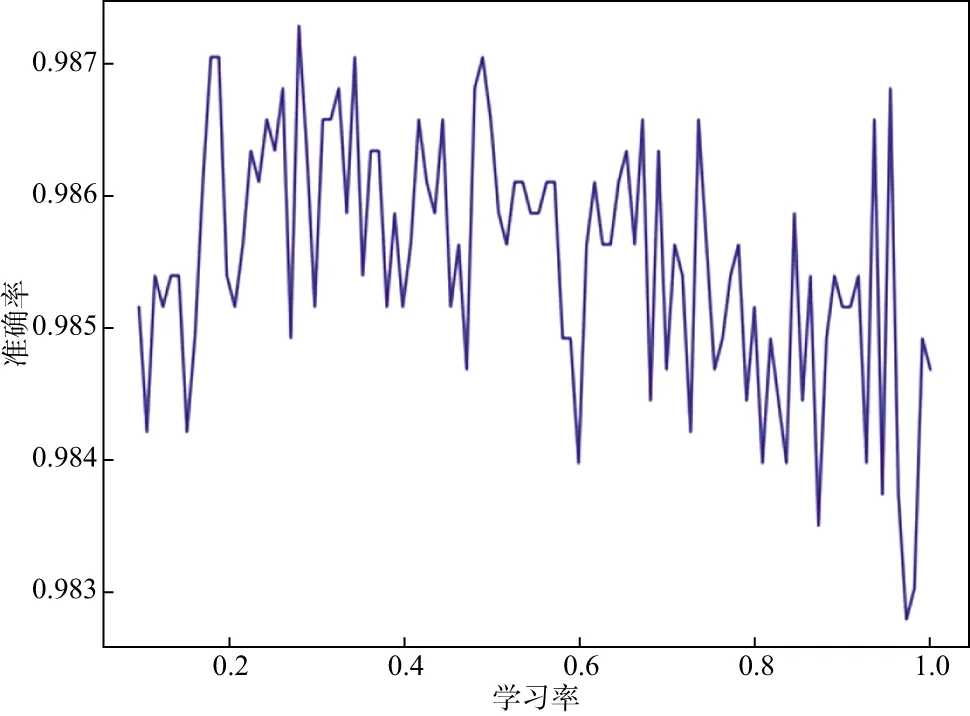
图4 模型在不同学习率下的准确率
同理,使用相同方法对Dmax与Wmin进行搜索,分别取得最优值Dmax=5,Wmin=1。最终的实验结果如表3所示。
由表3可以看出,本文方法对研究区内大部分油气水层的预测结果较好,仅泥岩层的预测准确率稍低。采取多种调优方式后,其准确率仍未得到明显提高,可能是由于所选数据集中泥岩层的各样本不能很好地突显其特征所致。经过多次数据集随机划分实验,含油水层的准确率多数仍能保持在100%,说明尽管含油水层的样本数较少,但本文模型可以较完整地提取到含油水层样本的特征。
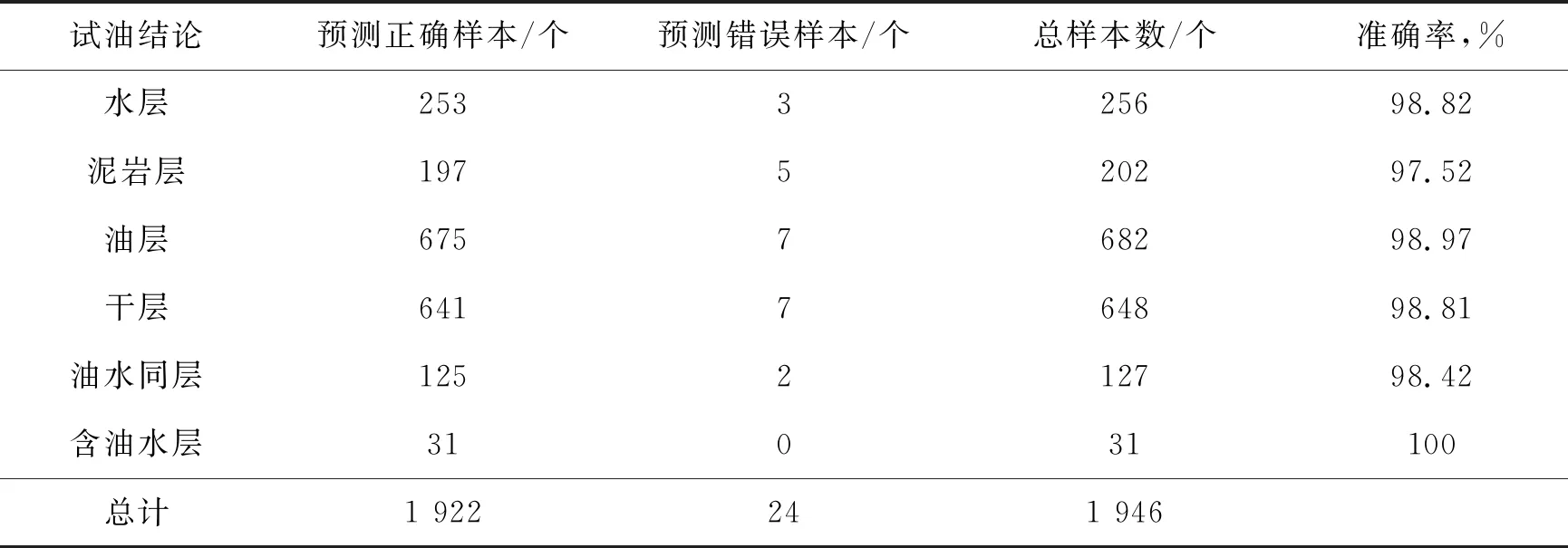
表3 基于XGBoost的类专家规则预测结果
为了进一步证明本文方法的有效性,使用GBDT算法和SVM算法自动获取专家规则,对比结果如表4 所示。
从表4可看出,采用XGBoost算法的预测准确度高于GBDT算法和SVM算法的预测准确度;虽然GBDT算法与XGBoost算法的预测准确率接近,但由于GBDT算法不能很好地利用并行方法对数据进行处理,导致其运行时间约为XGBoost算法的4倍。所以,从时间成本及准确率方面考虑,采用基于XGBoost算法构建专家规则的方法可以取得更好的效果。

表4 不同算法的性能对比
2.3.3 规则库自动获取方法在老井复查中的应用
老井复查是针对解释错误的层位,在得到试油结论后,再次进行测井解释,以形成对某一区块的共性研究。在研究区内应用规则库自动获取方法后,形成了研究区块内的知识规则库,得到了区块共性的解释经验知识。在老井复查中,利用本文提出的新规则库对研究区内的井再次进行测井解释,并与手工编写的原规则库进行对比,两种规则在部分井(Y22井和Y929井)的应用结果如图5、图6和图7所示。
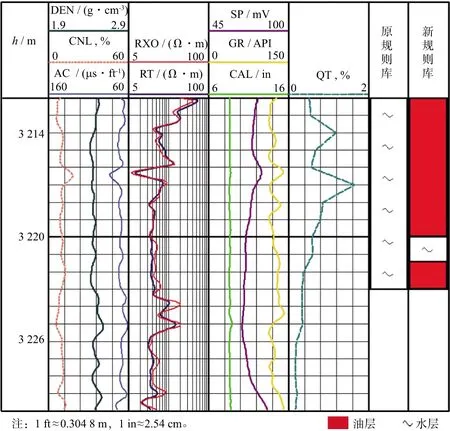
图5 Y22井某油层部分的解释结果
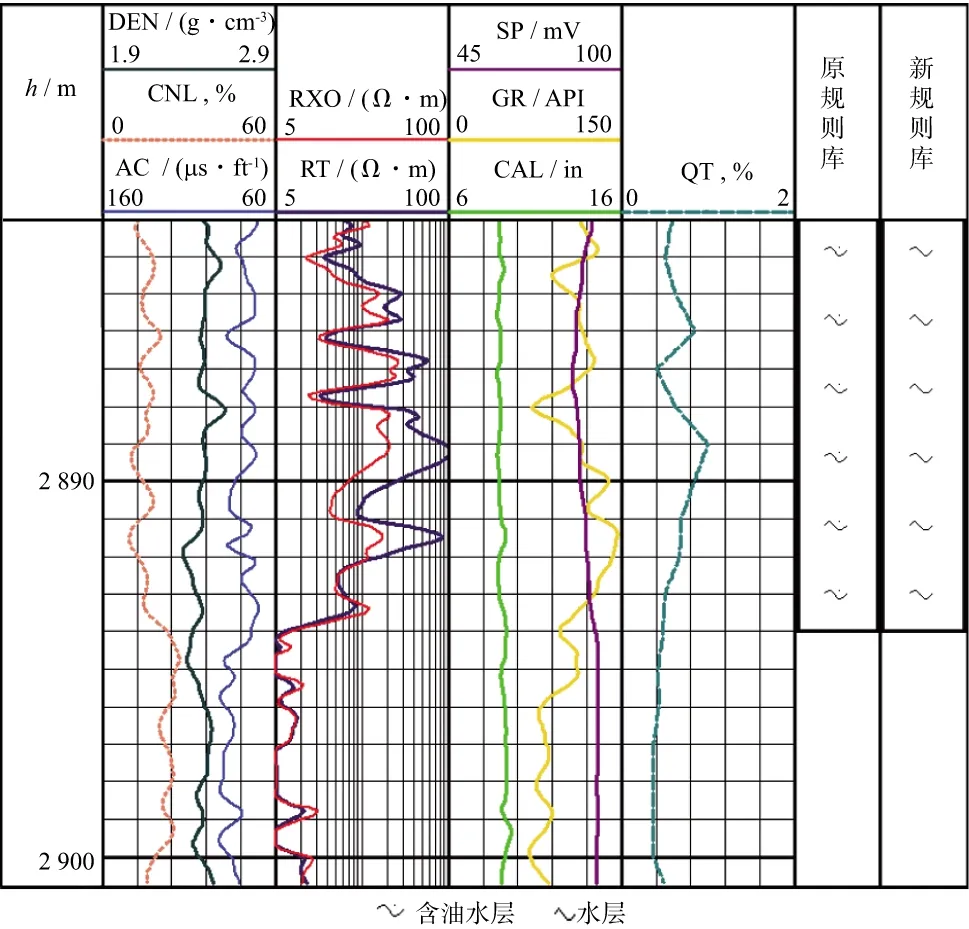
图6 Y22井某水层部分的解释结果

图7 Y929井某水层部分的解释结果
由应用结果可知,与原规则库相比,本文方法较完整地提取了该区块内的知识规则,提升了测井解释的准确率。
2.3.4 讨论与分析
本文方法利用XGBoost模型构建了专家规则的自动获取方法,通过加法训练将多个CART分类器集成到一起,并在损失函数中附加正则项,较好地完成了专家规则库自动获取任务。分析后发现,在实验与老井复查过程中,研究区内的部分储集层较厚,因而实验结果较好。但由于数据有限,目前未能专门针对很薄的复杂岩性储集层进行实验。但本文表明将XGBoost算法应用于测井解释具有较大的潜力,也为复杂储层测井评价等应用提供了新的思路。
3 结论
1) 将机器学习算法与测井专家系统有效结合,代替原有的人工方法建立解释规则库,使得关联规则更容易获取,非专家人员也可以进行类专家规则的生成及测井解释;
2) 采用XGBoost模型经过网格搜索和K折交叉验证优化后,其分类准确率高于SVM算法和GBDT算法,表明采用该模型能够准确预测各类储层;
3) 本文方法在胜利油田盐家永安地区老井复查中的成功应用表明,采用该方法形成了研究区块内的知识规则库,得到了本区块共性的解释经验知识。
猜你喜欢
测井技术(2022年3期)2022-11-25 21:41:51
——北美又一种非常规储层类型
石油与天然气地质(2021年5期)2021-10-29 01:30:08
中国煤层气(2021年5期)2021-03-02 05:53:12
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
西南石油大学学报(自然科学版)(2018年5期)2018-11-06 06:45:58
电子制作(2018年16期)2018-09-26 03:27:06
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
中国煤层气(2015年4期)2015-08-22 03:28:01
中国质量与标准导报(2015年2期)2015-02-28 22:27:15
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
