
基于多粒度语义交互的无监督法律裁判文书检索
2022-03-25 09:19:04周献杭申妍燕
集成技术 2022年2期
周献杭 申妍燕
(中国科学院深圳先进技术研究院 深圳 518055)
1 引 言
近年来,司法部持续加强法律服务智能化建设,深化“数字法治、智慧司法”建设,旨在建设覆盖行政立法、行政执法、刑事执行、公共法律服务四大职能的“大平台、大系统、大数据”。随着互联网技术的飞速发展,以及裁判文书网等司法公开措施的推进,人们可以获得越来越多的裁判文书,但信息过载问题也日益严重,快速且准确地对海量法律文书进行检索显得非常必要。如,法官通过检索相似案例来获取办案参考;律师援引相似案件来作为论证依据等。
法律裁判文书检索(Legal Case Retrieval)[1],是指从历史裁判文书集合中抽取与用户查询相关的裁判文书的任务。具体地说,文本检索模型通过计算查询语句(或文档)与每个待检索裁判文书之间的相似度,然后根据相似度大小对裁判文书进行排序,从而返回满足用户需求的裁判文书集。法律文本作为一种特殊的文本形式,具有篇幅较长、结构复杂、专业性强等特点,传统的基于关键字的文本检索方法已经不能满足用户查询法律信息的需求。基于关键字的检索方法主要是对用户查询关键字进行匹配,虽然能够快速查找到所需的信息,但该类方法容易出现查准率低、检索不全等问题。此外,新用户很难通过识别合适的关键词来准确检索法律裁判文书。
随着深度学习的快速发展,学者们对语义检索进行了深入的研究和探索。语义检索能够更加准确地通过用户输入的查询信息理解其真正意图,从而具有更高的查全率和查准率[2]。然而,基于语义的文本检索方法大多依赖于有大量标注数据的有监督学习方法,并且法律文本数据的人工标注过程严重依赖专家知识,费时费力,这无疑给研究工作带来巨大的人力成本。
为了更好地解决上述问题,本文提出一种基于无监督学习的法律裁判文书检索模型,分别从法律概念级别、词语级别和词组级别 3 个方面进行多粒度文本匹配,避免了没有训练数据导致的冷启动问题。具体地说,该模型利用词语级别的交互特征来捕获用户输入查询和候选文档的关键词信息;利用词组级别的交互特征来更加灵活地捕获特定表达信息;利用官方法律案由级别信息和提取的案由数据构建法律知识词典,并通过该词典捕获用户查询和文档之间的法律概念级别匹配信息。然后深度融合法律概念级别、词语级别和词组级别的匹配信号,得到最终的排序结果。实验结果表明,与基准模型相比,本文模型在法律裁判文书检索上取得了更好的效果,具有有效性和先进性。
2 检索算法研究现状
信息检索(Information Retrieval,IR)[3]任务是将用户的检索查询内容与数据库中大量的文档集合根据特定的条件进行相关性建模,计算检索语句与文档间的相关程度并召回,再对召回的文档根据用户需求重新排序后返回给用户。在过去几十年的不断探索实践中,已经相继提出许多不同的检索模型,包括布尔模型[4]、向量空间模型[5]和概率模型[6]等传统检索模型,以及统计语言模型[7]和排序学习模型[8]。这些检索模型成为了信息检索技术研究的基础。其中,基于排序学习的检索模型已经在许多应用中取得了巨大的成功,至今仍被学者不断研究改进,并广泛应用于商业检索系统。近年来,大数据研究掀起的机器学习热潮,在语音识别、计算机视觉和自然语言处理任务中取得了令人激动的成果,加速了信息检索技术的发展。目前,信息检索的研究主要分为两个方向——基于表示学习的检索模型和基于匹配函数学习的检索模型[9]。
2.1 传统检索模型
1972 年,Jones[10]提出了 TF-IDF 模型,该模型将文档和检索语句转换为特征向量,并利用加权技术评估一个字词在文档集合中的重要程度。这个模型在 20 世纪 80 年代一直是科研人员的研究重点,直到现在,基于 TF-IDF 的衍生模型仍然被搜索引擎采用。1992 年,Robertson 等[11]提出了基于概率的 BM25 模型,该模型在传统 TFIDF 模型的基础上增加了可调节的参数,并且将文档长度作为惩罚因子,使检索模型具有更高的实用性。该模型在许多信息检索任务中表现优异,成为重要的基准算法。
传统检索模型主要通过提取词条的特征信息,利用集合论知识、代数模型和概率模型方法进行检索,不需要标注数据的支持和复杂的模型结构,属于无监督检索模型范畴,可以有效解决没有训练数据导致的冷启动问题。传统检索模型依靠特征提取,但原始文档中的噪声信息和进行句法分析时累积的匹配误差会引起错误的召回,从而影响最终的检索效果。此外,传统检索模型会忽略语料库外词语的特征信息,同时使用孤立的关键词特征脱离了上下文语言环境,难以还原语义信息,从而影响模型最终的检索效果。
2.2 基于表示学习的模型
基于表示学习的模型会分别学习输入检索语句和数据库中文档的高层向量表示,通过构造评估函数,来得到检索语句和文档集合的匹配得分。2013 年,微软 Huang 等[12]提出 DSSM 模型,这是首个成功地将表示学习应用在文本匹配任务的模型,其采用有监督训练方式,不需对文档集合进行特征标注工程,且利用预先计算文本向量可大幅降低在线计算的消耗,该模型为深度语义匹配模型的鼻祖。2014 年,微软 Shen等[13]提出的 CNN-DSSM,以及 2016 年,Palangi等[14]提出的基于循环神经网络的 LSTM-RNN 模型,都对 DSSM 模型进行了优化,但两者仍需要大量的训练数据及 GPU 支持,导致许多业务难以开展。
2.3 基于匹配函数学习的模型
基于匹配函数学习的模型,主要围绕构建交互函数以获得检索语句和文档中词语的详细交互信号。2014 年,Hu 等[15]在 NIPS 上提出了 ARCII模型,该模型通过对检索语句和文档中的单词进行 N-Gram 的卷积提取词序信息,然后对各自卷积后得到的词向量按对进行计算,从而得到一个匹配度矩阵。2016 年,Guo 等[16]提出了 DRMM模型,该模型将检索语句和文档分别表示为由M个和N个词语组成的向量。将检索语句和文档逐一比对计算相似度,以直方图的形式进行分桶计算代替池化操作,可以更好地区分相似和完全匹配,并保留原始信息。基于匹配函数学习的模型规避了对长文本进行准确编码的困难,但构造交互矩阵难以进行在线计算,效率有限。
2.4 面向法律领域的匹配模型
在法律文本匹配领域[17],可利用词嵌入的方式在文本和向量之间建立连接[18]。有的学者在基于符号的方法上引入可解释的标签[19],从而在法律文件中的符号之间进行推理。Sugathadasa 等[20]将法律案件转移至向量空间,从而进行文档检索任务。Chalkidis 和 Kampas[21]主要围绕将现有的词嵌入方法(如 word2vec[22])应用于法律语料库。Tran 等[23]设计了一种编码摘要模型,该模型将给定法律文档编码到连续的向量空间中,同时嵌入文档的摘要属性。法律领域的匹配模型仍在快速发展,为了获取法律领域专业词汇的表述,可以在词嵌入中捕获法律知识,Liu 等[24]将知识图谱结构化信息引入神经网络检索模型中。Zhang 等[25]利用图嵌入技术,使神经网络检索模型能够利用图的结构化数据自动进行特征提取,这不仅有助于克服点击数据的长尾问题,而且可以通过结合外部信息来改善搜索结果。由于法律领域包含许多规则和知识,将知识进行建模对于法律文本匹配同样至关重要[26]。
与通用领域的检索模型相比,法律领域的检索模型面向大量结构化的法律文献、法律法规和案件文书,若采用传统的关键字检索模型,则无法得到关键词之间的内在联系,因此,检索文档的召回率和排序的准确率难以得到保证。由于法律信息包含司法专家长期实践的经验以及法律领域专业知识汇总形成的专业术语和复杂的结构表达,所以想要搜索出检索语句和文档之间更深层的含义,在获得高召回率的同时,提高排序的准确率以及增加检索结果的可用性,仍然有许多障碍[26]。因此,在前期没有标注数据的前提下,根据用户输入的自然检索语句,构建基于多粒度语义交互的无监督法律裁判文书检索模型,优化法律领域的文献检索,提升排序准确率具有现实意义。
3 无监督法律文书检索模型
多粒度语义交互的无监督法律裁判文书检索模型(Unsupervised Legal Case Retrieval based on Multi-granularity Semantic-aware Interaction,ULRM)的输入为用户的检索语句,模型针对检索语句分别从词语级别、词组级别、法律概念级别进行信息匹配,综合 3 个模块的打分结果来决定召回文书的最终排名顺序,随后输出精排后的裁判文书并反馈给用户。利用词语级别的交互特征来捕获用户输入查询和候选文档的关键词信息;利用词组级别的交互特征来更加灵活地捕获法律领域的特定表达;利用官方法律案由级别信息和提取的案由数据构建法律知识词典,从而更准确地匹配用户的需求,提升检索效果。ULRM模型结构如图 1 所示。
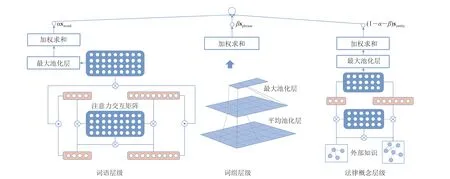
图1 ULRM模型结构图Fig. 1 The architecture of the ULRM
3.1 词语级别匹配
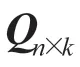

其中,n为用户输入的检索语句经分词后的关键词个数;m为数据库中裁判文书经分词后的关键词个数;k为关键词转换成词嵌入后向量的维数;qi为检索语句经预处理后序列中第i个词向量,维度为k;dj为裁判文书经预处理后序列中第j个词向量,维度为k。



3.2 词组级别匹配
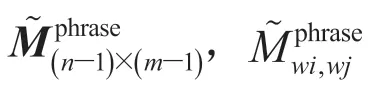

3.3 法律概念级别匹配
对律所提供的 8 000 万份法律文书经分词和去停用词处理后进行特征提取,得到案由数据共计 1 427 条,整合律所提供的 1 392 条专业案由知识数据,两份数据集进行去重整理后,得到刑事、民事、行政案由信息共计 1 541 条。结合官方法律案由知识信息和提取的案由关键词数据,构建法律案由知识词典。利用 TransE[28]算法将知识词典中的实体信息、实体间的关系映射到连续低维向量空间,并表示为三元组(h,r,t)。其中,h,t分别表示实体向量信息;r为关系向量,代表实体向量h,t间的翻译。基于实体与实体间关系的向量表示,通过训练调整h,r,t,最终使得h+r≈t。其中,t为h+r的最近邻,且t与h+r的距离足够远。图 2 为构建的部分法律知识词典示例。

图2 法律知识词典示例Fig. 2 The example of legal knowledge base


4 结果分析与评估
4.1 数据集与评价指标
实验检索语句数据集由法律行业专业从业人员进行整理,其利用专业知识和长期实践经验分别从债权债务、劳动纠纷、基础设施、婚姻家事、房地产、投资并购和知识产权 7 个方面提炼检索语句共计 958 条;将检索语句输入Elasticsearch 法律文书数据库,数据库包含法律文书 8 000 万份,每条语句召回的前 30 份相关文档交由法律行业专业从业人员进行相关性标记,共计标记文书 23 196 份,构成检索文档数据集。
数据集描述如表 1 所示,将 958 条检索语句按 8∶2 的比例拆分成训练集和测试集,其中,训练集共计包含文档 18 589 份,平均每条检索语句标记正相关文档 10.64 份,负相关文档 13.78 份,每份文档预处理前标题平均长度为32.09 字,本院认为部分平均长度 1 188.99 字;测试集共计包含文档 4 648 份,平均每条检索语句标记正相关文档 11.07 份,负相关文档 13.19份,每份文档预处理前标题平均长度为 30.73字,本院认为部分平均长度 1 209.19 字。
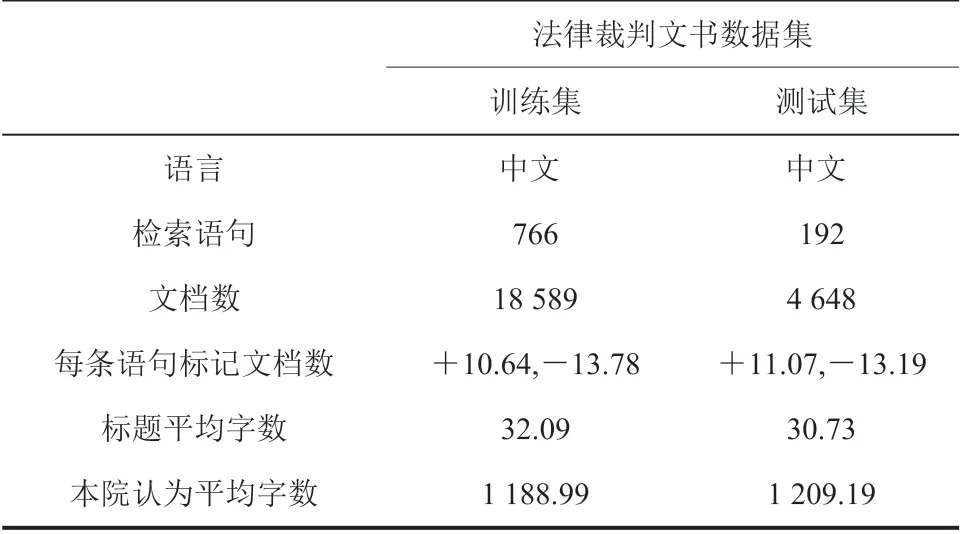
表1 法律裁判文书检索数据集描述Table 1 Statistics on legal case retrieval dataset
实验采用的评价指标为检索模型通用评价指标分别为 MAP, MRR, NDCG@10。
平均精度均值(Mean Average Precision,MAP),从多个查询上反映模型的整体检索性能。Q为相关检索的次数,N为每次检索的相关文档数,position为相关文档i的排名位置,相关文档排名越靠前则AvgP越高,MAP值也就越高。若系统没有返回相关文档,那么AvgP值为0,具体计算公式如下:


4.2 实验结果
本文利用表 1 的法律数据集进行法律文书检索实验,数据集中检索语句与法律文书的相关性均通过人工标注,以保证检索结果的正确性。为证明实验结果的有效性,本文还选用相同的法律数据集,将 ULRM 模型与过去发表的无监督检索模型和在法律领域预微调的训练模型进行对比实验。对比的基准模型有:
(1)Jones[10]提出的 TF-IDF 模型,将检索文档和检索语句转换为特征向量,计算词频和逆文档频率,用以评估检索关键词对语料库中文件的重要程度,还利用加权技术得到检索语句与检索文档的相关性得分。
(2)Roberston[11]提出的 BM25 模型,在 TFIDF 模型的基础上增加了可调节的参数,控制最终得分对单一词频的敏感程度,计算检索语句中每个词与每个文档的相关性得分,然后加权求和,同时引入文档长度和平均文档长度之比作为惩罚因子,最终得到相关性得分。
(3)查询似然模型(Query Likelihood Model,QLM)[28]为集合中每个文档构建对应的语言模型,利用贝叶斯算法计算给定的查询语句在文档集合中的生成概率,然后得到似然排序。
(4)Gysel[29]提出的 NVSM 模型以无监督的的方式使用梯度下降算法,从零开始学习检索语句和文档的低维向量表示,最后根据文档和检索语句向量间的相似性对文档进行排序。
(5)Shao 等[30]提出的 BERT-PLI 模型,利用BERT 捕获段落级别的语义关系,然后通过汇总段落级别的交互来推断两个案例之间的相关性。本文使用划分的法律检索数据集对 BERT 模型进行微调,使其适用于法律场景。
4.3 讨论与分析
表 2 为已有基线模型与 ULRM 模型在法律裁判文书数据集上的检索实验结果。TF-IDF 与BM25 模型指标相近,QLM 模型指标则较两者表现稍差,由此可得,在法律裁判文书检索领域,利用文档与检索语句之间的相关性建模方式效果略差于基于关键词匹配的 TF-IDF 与BM25 模型。与已有无监督的基线模型相比,ULRM 模型利用外部法律知识提高了法律知识的匹配能力,综合词语级别、词组级别和法律概念级别 3 个方面的匹配信号,在 MAP、MRR 和NDCG@10 指标上有明显提升;与基于 BERT 并在法律数据集上微调的预训练模型 BERT-PLI 相比,ULRM 模型在 MRR 与 NDCG@10 指标上仍有小幅优势。本实验结果证明,ULRM 模型在法律文书检索数据集上检索的有效性。
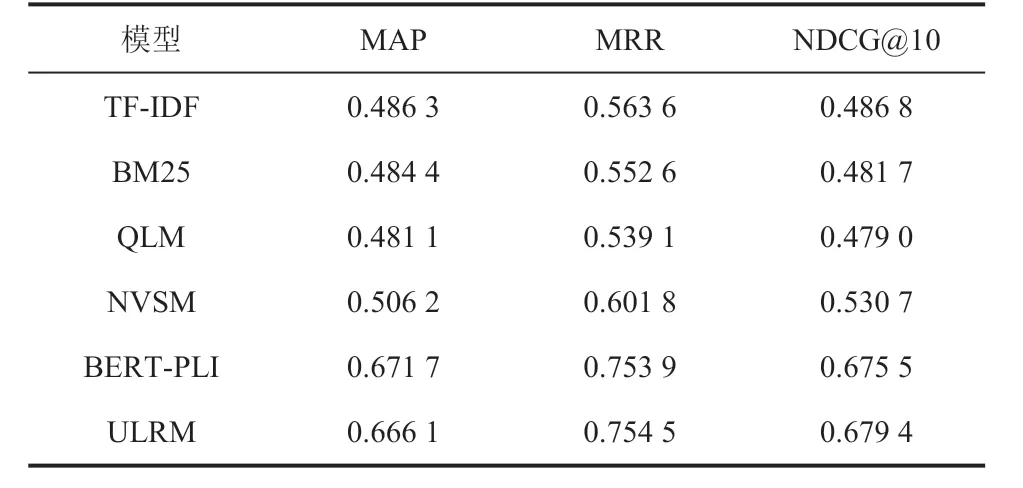
表2 法律裁判文书数据集检索实验结果Table 2 Retrieval performance on legal case retrieval dataset
ULRM 模型最终得分由词语级别匹配、词组级别匹配和法律概念级别匹配 3 个方面的评分综合得出。为了评估各模块的重要性,本文还对ULRM 模型进行了消融实验,即在单次实验中去除一个模块后观测实验指标的变化情况,实验结果如图 3 和表 3 所示。从表 3 中可以发现:

图3 ULRM 模型消融实验结果Fig. 3 ULRM ablation experiment
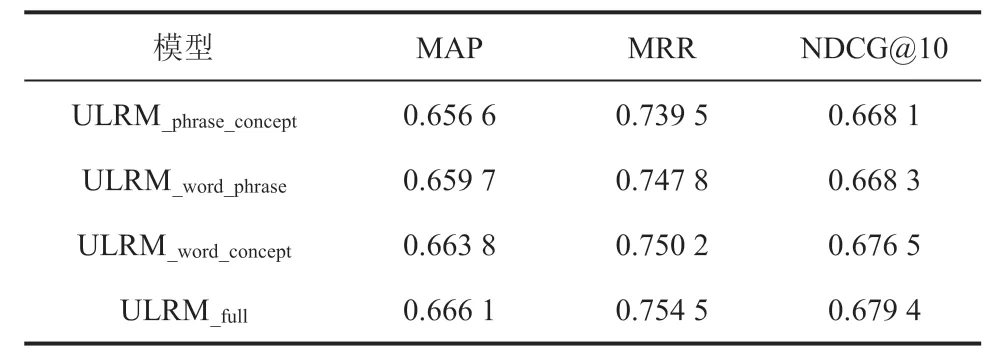
表3 法律数据集检索消融实验结果Table 3 Ablation experiments on legal case retrieval dataset
(1)仅使用一个模块时,按词语级别匹配 3个指标分别为 MAP:0.655 3、MRR:0.735 2、NDCG@10:0.667 8,较其他模块下降最少。按词组级别匹配 3 个指标分别为 MAP:0.642 1、MRR:0.711 2、NDCG@10:0.653 6,较其他模块下降最多。按法律概念匹配 3 个指标分别为MAP:0.652 3、MRR:0.731 4、NDCG@10:0.660 5。综上所述,可知按词语级别匹配对ULRM 模型的作用最大。
(2)当禁用按词语级别匹配时,随着按词组级别匹配比例的增加,MRR 指标趋于平缓,当比例超过 0.4 时逐渐降低;MAP 和 NDCG@10指标随比例的增加呈缓慢上升趋势,当比例在0.7 时趋近最大值,然后快速下降。
(3)当禁用按词组级别匹配时,随着按词语级别匹配比例的增加,3 个指标变化趋势基本一致,呈逐渐上升趋势,在 0.7 附近时,3 个指标均逼近最大值后逐渐下降,其中,MRR 指标下降明显。
(4)当禁用按法律概念级别匹配时,随着按词语级别匹配比例的增加,MRR 指标变化明显,呈快速上升趋势,在 0.8 附近接近最大值后缓慢下降。MAP、NDCG@10 指标先呈缓慢上升趋势,当比例超过 0.2 时趋于平缓。
本实验验证了按词语级别匹配、按词组级别匹配和按法律概念级别匹配对于模型的指标均有积极作用。当使用单一模块时模型 3 个指标的表现普遍降低 0.1~0.2,引入法律知识词典中的实体信息用更为准确的语义描述进行匹配,可以将按词语级别匹配的 MAP、MRR、NDCG@10 分别从 0.655 3、0.735 2、0.667 9 提升至 0.663 8、0.750 2、0.676 5;将按词组级别匹配的 MAP、MRR、NDCG@10 分别从 0.642 1、0.711 2、0.653 6 提升至 0.656 6、0.739 5、0.668 1。控制一个模块后逐渐变化各模块的比例时模型表现呈献先上升后下降趋势。对比各模块占比对实验指标的影响,选用按词语级别匹配比例 0.42,按词组级别匹配比例 0.39,按法律概念级别匹配比例 0.19 时可以获得接近最优的指标,此时 MAP 为 0.666 1,MRR 为 0.754 5,NDCG@10 为 0.679 4。表 4 为法律裁判文书检索示例,其以“土地出让合同约定了建设规模、容积率,但建成物业的建设规划、容积率超出土地出让合同约定的法律后果?”为检索问题,各模型经检索排序后的第一个结果标题及案由信息如表 4 所示。

表4 法律裁判文书检索示例Table 4 An example of legal case retrieval
5 结 论
在法律文书检索领域,由于文书内容的特殊性,往往缺乏大量的标注数据,从而难以通过训练得到效果优异的深度学习模型。此外,标注训练数据需要耗费大量法律行业从业人员的时间及精力,人工成本较高。因此,本文提出了基于无监督的法律裁判文书检索模型 ULRM,综合词语级别、词组级别和法律概念级别 3 个方面的打分结果,来对召回文书进行重排名:在词语级别,利用注意力机制获取用户输入信息和法律文书的关键词信号;在词组级别,引入平均池化层模拟短语匹配从而获取更多关键词匹配信号;在法律概念级别,考虑法律专业术语实体信息从而更准确地获取匹配信号,提升模型的检索效果。
模型使用无监督的方式避免了对大量标注数据的依赖,并通过实验验证,该模型在法律裁判文书数据集上的 MAP、MRR、NDCG@10 指标远超已有基线模型,与基于 BERT 并在法律数据集上微调的预训练模型 BERT-PLI 结果相近,能够对召回文书进行有效重排序。由于模型 3 个模块主要使用关键字信息进行检索,对于语料库中缺少的内容无法识别,同时由于词袋模型的使用无法关联上下文语义,对模型指标的提升仍有局限。因此,将模型部署上线,利用无监督模型获取用户的检索及点击数据,对于标注数据的获取及后期进行有监督模型的训练具有重要意义。
猜你喜欢
邯郸学院学报(2022年2期)2022-07-05 07:26:30
基层中医药(2021年8期)2021-11-02 06:25:02
新世纪智能(语文备考)(2020年4期)2020-07-25 02:28:50
安徽警官职业学院学报(2020年6期)2020-07-21 01:38:56
西夏学(2019年1期)2019-02-10 06:22:40
家庭影院技术(2018年5期)2018-06-29 07:42:10
家庭影院技术(2018年3期)2018-05-09 07:06:12
作文评点报·低幼版(2017年44期)2017-11-16 08:24:58
中学生(2017年13期)2017-06-15 12:57:48
语文知识(2014年4期)2014-02-28 21:59:52
