
基于LSTM模型对印度新冠肺炎疫情的预测
2022-03-21 14:29:56王剑辉蒋杏丽
沈阳师范大学学报(自然科学版) 2022年6期
王剑辉, 蒋杏丽
(沈阳师范大学 数学与系统科学学院, 沈阳 110034)
0 引 言
印度于2020年1月30日报告了首例新冠肺炎疫情确诊病例,随后疫情在印度蔓延并暴发。截至文章成稿时,印度累计确诊人数已经超过了4 000万,仅次于美国[1]。新冠肺炎疫情很难被预知和掌控,很多学者建立神经网络模型来预测新冠的传播规律和发展趋势。
机器学习和人工智能(artificial intelligence)算法被广泛用于预测分析和模式识别[2]。国内外众多研究者也利用机器学习[3]和SEIR(susceptible-exposed-infectious-recovered)模型[4]去分析并预测新冠肺炎疫情。Hidayat等[5]利用线性回归、向量自回归和多层感知机模型来预测印度新冠肺炎疫情。Saleh等[6-7]使用差分自回归移动平均(auto regressive integrated moving average model,ARIMA)模型预测西班牙、意大利等受疫情影响较大的国家的经济状况。与循环神经网络(recurrent neural network,RNN)[8]相比,LSTM在处理时间序列并具长期记忆的数据时更有优势,它更适用于对长序列数据进行分类、处理及预测[9-10]。
首先采集印度确诊病例数据,数据预处理并划分后应用到LSTM模型上,在训练的过程中使用Adam优化器不断优化模型直至完成所定义的Epoch。
1 数据集提取与LSTM模型
1.1 LSTM数据集
研究使用的数据集是印度在2022年3月1日至2022年11月8日期间的新冠肺炎累计确诊病例, 数据来源于印度疫情实时大数据报告网站。 将建模需要的确诊病例提取出来, 部分确诊病例数据见表1。

表1 部分印度每日确诊病例数
数据预处理后,将3月1日至9月7日期间的数据按7∶3的比例划分为训练集和测试集2个部分。其中,训练集用来训练LSTM模型[11]使其参数最优化,测试集对建立的预测模型进行验证并调试参数。为了能实现根据已知确诊病例来预测未来任意一段时间内确诊病例的目的,将后3个月(9月8日至11月8日)的数据用于模型实际应用,以便于观察出模型的预测效果。
1.2 LSTM预测模型
LSTM模型是由Hochreiter和Schmidhuber于20世纪90年代提出的一种特殊的RNN,它很好地解决了RNN梯度消失和梯度爆炸等重大问题。LSTM模型结构如图1所示。
在某一时刻,LSTM的输入包括当前时刻网络的输入值xt、上一时刻LSTM的输出值ht-1以及上一时刻的单元状态ct-1;输出包含当前时刻LSTM的输出值ht和当前时刻的单元状态ct。在LSTM中,有3个门[12]来控制长期状态,每个门[13]利用sigmoid函数来筛选数据,0代表不通过,1代表通过。
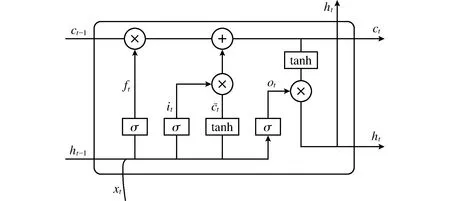
图1 LSTM模型内部结构Fig.1 Internal structure of LSTM model
2 LSTM预测模型的建立及评估
建立LSTM模型预测印度某段时间内新冠肺炎疫情的确诊数, 模型分为输入层、LSTM层和输出层。 输入层中节点数是提取到的数据数量, LSTM隐藏层数设置为4, 输出层引入一个全连接层来将最后结果降成一维并输出。 将参数Batch_Size设置为1, Epoch设置为100, 学习率设置为0.001, 此外还使用了Adam算法[14]作为模型优化器, 将MSE作为模型的损失函数, 选用准确度作为模型的评价指标。 对比LSTM和SVM模型的准确度得到二者的拟合效果, 准确度越大说明模型预测效果越好。
图2为印度在3月1日至9月7日的新冠肺炎确诊病例折线图。
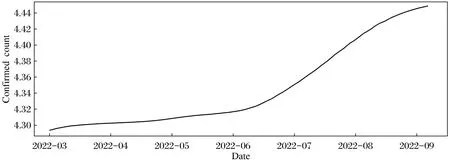
图2 每日确诊病例数Fig.2 Daily number of confirmed cases
将3月1日至9月7日数据的70%用于训练模型,剩下的数据用于对模型进行测试。最后结果如图3和图4所示,建立的预测模型的损失值随着Epoch增大而减小,模型的真实值与预测值拟合效果较好。
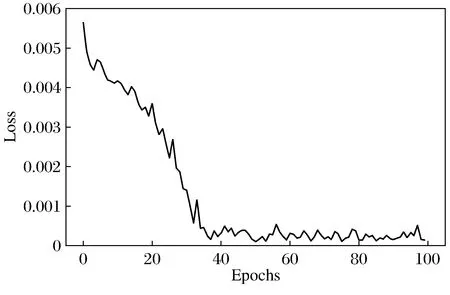
图3 LSTM模型损失值Fig.3 Loss value of LSTM model
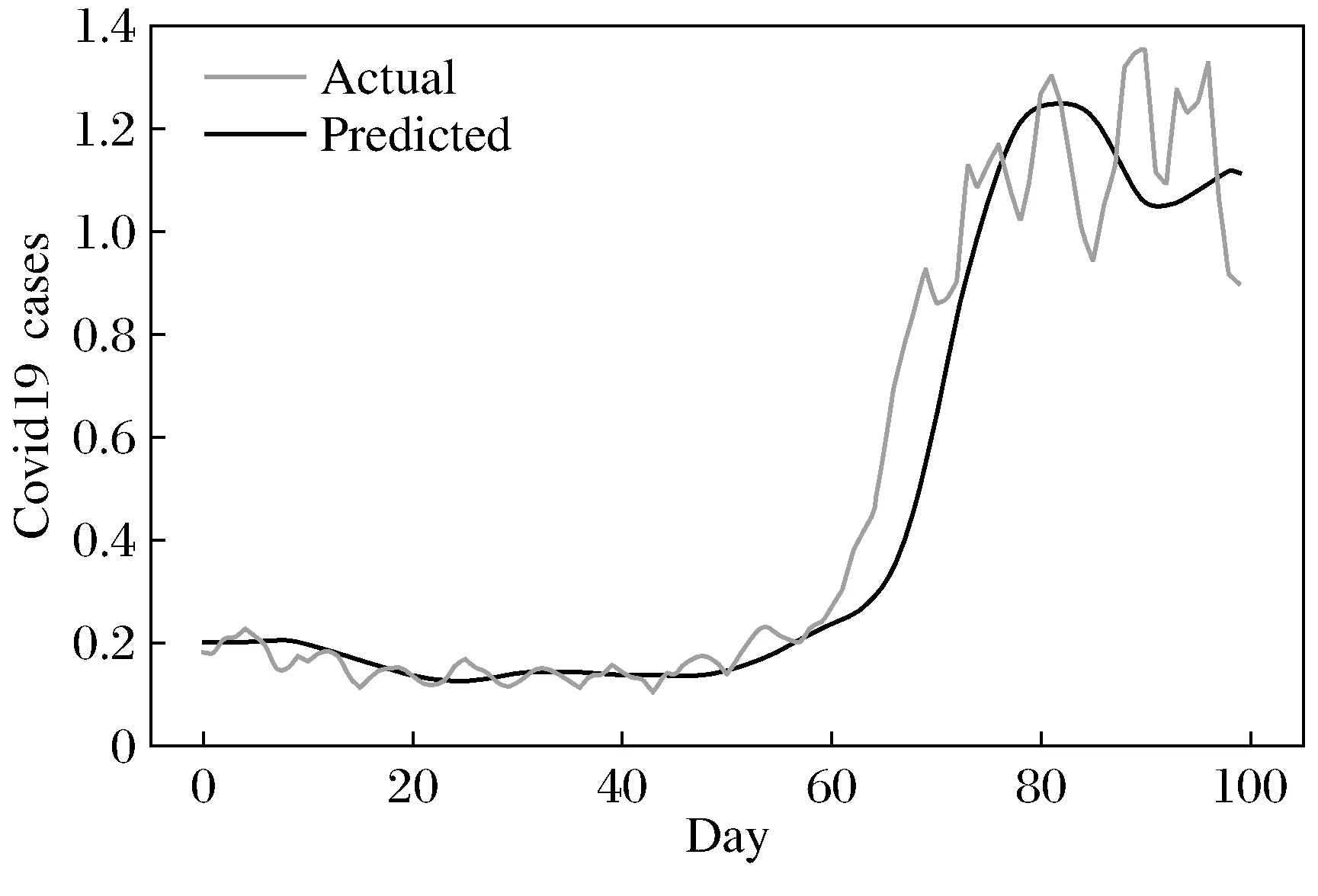
图4 模型预测值与真实值对比
训练好LSTM模型后,图5为模型对印度9月8日至11月8日预测的确诊病例数,图6是同样时间段印度疫情实际确诊病例数统计,对比可知模型确实能够成功预测未来某段时间内的新冠肺炎疫情发展情况。最终得到LSTM预测模型的准确度为87.49%,而SVM模型的准确度仅为73.25%,表明在新冠肺炎疫情预测的效果上LSTM更准确。
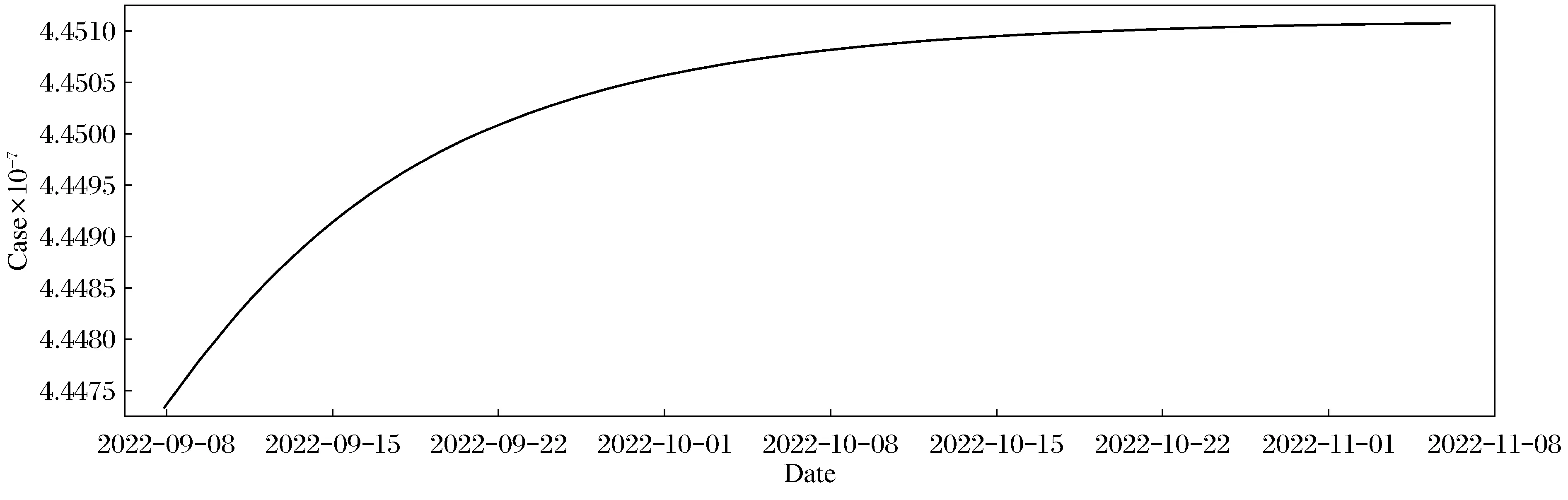
图5 60天内确诊病例预测数Fig.5 Prediction of confirmed cases within 60 days
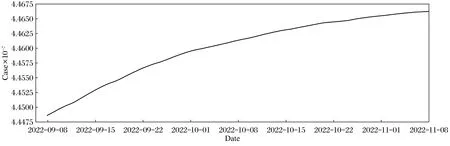
图6 确诊实际数据Fig.6 Actual data of confirmed cases
3 结 论
本文收集印度新冠肺炎累计确诊病例数后,运用深度学习中的LSTM算法对其某一段时间内的累计确诊病例数进行预估。目前使用LSTM模型预测印度新冠肺炎病例数的研究并不多,由于数据大小受限,该模型的预测准确率还需要进一步提高。
猜你喜欢
环球人物(2022年4期)2022-02-22 22:05:06
中外文摘(2021年23期)2021-12-29 03:54:04
小资CHIC!ELEGANCE(2021年32期)2021-09-18 06:17:14
幼儿100(2021年8期)2021-04-10 05:39:44
建筑科技(2018年6期)2018-08-30 03:40:54
中国交通信息化(2016年5期)2016-06-06 03:51:43
爆笑show(2015年4期)2015-06-24 01:55:12
海峡姐妹(2015年5期)2015-02-27 15:11:02
太空探索(2014年1期)2014-07-10 13:41:47
小学阅读指南·高年级版(2014年2期)2014-05-27 05:29:32
