
基于PointConv 改进的点云分类网络∗
2022-03-18 06:20国玉恩任明武
计算机与数字工程 2022年12期
国玉恩 任明武
(南京理工大学计算机科学与工程学院 南京 210094)
1 引言
随着数据采集技术的飞速发展以及3D 传感器的迅速普及,3D 数据的识别与分析成为计算机视觉与模式识别领域的热门研究方向。点云作为3D数据的一种广泛应用形式,吸引了众多研究者探索开发用于形状分类的高效表示方法。
对于点云数据,一种直观的想法是类比CNN的操作,通过体素化将非结构化的点云数据转换为规则的三维网格,在此基础上应用3DConvNets[2~3]。但是点云的稀疏性导致体素化之后每个网格分辨率严格受限,三维卷积核的特征提取也使得计算成本成指数增长,尽管有相关研究使用kd树[4]和八叉树[5]分层划分三维空间以利用点云的稀疏性,但并没有针对局部几何结构进行特征提取,其本质仍是高维空间的卷积,难以获得高分辨率的数据。
另一种是基于多视图的方法,从点云的不同方向生成一组视图,然后利用较成熟的卷积神经网络提取特征,比如AlexNet[6]、VGG[7]、GoogleNet[8]、ResNet[9],最后融合不同视图的特征进而完成分类任务。例如,MVCNN[10]提出一种用于三维形状识别的多视图卷积神经网络,不同视图的特征通过池化转换成全局形状特征;CNN-BiLSTM[11]使用双向长短期记忆模块BiLSTM聚合不同视图的信息。但是受角度的限制,该方法的每个视图仅呈现整个点云的局部平面结构,因而丧失了很多空间结构信息,难以做到有效的特征提取。
相比于体素化数据和多视图数据,点云包含更多空间结构信息,是描述三维对象最简洁直观的一种表示形式,可以使用RGB-D 相机、雷达等传感器轻松获取。尽管如此,使用点云作为直接输入的分类识别任务仍然具有相当的挑战性。点云的无序性、旋转不变性特点决定了其不能直接使用传统的深度学习方法进行特征提取,这也激发了大批学者的研究热忱。
PointNet[12]作为直接使用点云的开创者,创造性地使用最大值对称函数和STN 空间变换网络解决了这两个难题,使得点云深度学习成为可能。但是PointNet 仅仅局限于对全局特征的提取,对于更精细的局部特征并没有有效利用。为此,其作者又提出PointNet++[13],将点云划分为不同大小的邻域,分级提取局部特征,尽管分类准确率有所提高,但是对于每一个局部分组而言,其本身仍然是一个“整体”,只是对原始点云的缩小化。而PointConv利用逆密度加权的非线性卷积提取局部特征,对于给定点云,使用核密度估计计算密度,并使用MLP进行逆密度自适应加权,不仅有效利用了局部密度特征,而且在显存消耗和计算效率上也有出色表现。
本文首先对PointConv 的基本架构进行简要介绍,然后详细描述本文基于PointConv 改进的分类网络架构。其中,使用密集特征Dense Feature 对PointConv 进行改进,聚合多尺度、多层次的局部邻域语义信息,通过对低层次空间结构特征和高层次抽象语义特征的综合利用,提高网络的泛化能力。在数据集ModelNet40上的对比测试表明,本文提出的改进网络的整体准确率和类平均准确率均显著提高。
2 PointConv网络架构
该网络将传统CNN 中的滑动滤波器扩展到一个新的卷积运算,即PointConv。该卷积运算可以视为局部坐标的非线性函数,由核密度函数和权函数组成,基于PointConv 可以构建直接应用于点云的深度卷积网络。
2.1 PointConv
PointConv 卷积由三维连续卷积推导而来,是其蒙特卡罗近似的扩展。对于每个滑动滤波器,使用多层感知机MLP 来逼近权函数,使用核密度估计方法计算每个局部邻域的密度。逼近权函数的思想也有在其他网络模型[14~15]中使用,但是并没有考虑密度特征的近似。为了让网络自适应地决定是否应用核密度估计,使用最大似然对所得密度做非线性变换得到其对应的逆密度因子,其公式如下:
其中,K和k分别代表K近邻局部区域和索引下标,Cin和cin分别代表输入特征图的通道数及其索引。图1 显示了一个K近邻局部区域内的Point⁃Conv操作。

图1 PointConv操作
其中,Plocal∊RK×3,代表K近邻局部邻域内其他近邻点相对于中心点的局部坐标,Compute Weight是使用1×1 卷积实现的多层感知机网络,经此步骤后得到权函数W,W∊RK×Cin×Cout;Density 代表离线计算得到的密度,Compute Inverse Density Scale是另一个多层感知机网络,用来计算与密度相对应的逆密度因子S,S∊RK;Fin∊RK×Cin,代表局部邻域特征,与逆密度因子逐点相乘后再与权函数做矩阵乘积,最后经过1×1 的卷积得到经逆密度加权的局部特征Fout,Fout∊RCout。
PointConv 通过在所有点之间共享MLP 的参数解决点云的无序性问题。对任意一个局部区域而言,其内部点相对于中心点的相对位置是不变的,用相对位置作为权函数的输入,解决点云的旋转不变性问题。
2.2 整体网络架构
PointConv 整体网络架构中使用PointNet++的multi-resolution grouping(MRG)层提取点集特征,该结构由采样层、分组层和PointConv 操作组成,通过堆叠数个MRG 层将局部邻域特征组合成覆盖更大邻域的高维特征,最后经过全连接网络FCN得到点云类别信息,其整体网络架构如图2所示。
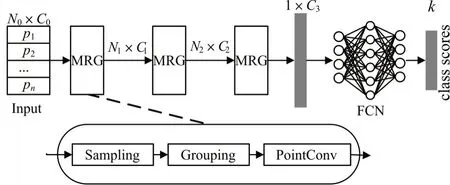
图2 PointConv整体网络架构
N0代表初始点云中点的数量,N1,N2,N3分别代表不同采样层中采样中心即局部邻域的个数;C0代表除三维坐标以外的其他信息,如法线、颜色等;C1,C2,C3分别代表特征通道数。MRG 层的输入为N×C特征图,相对应的输出为N'×C',在其前向传播过程中,Sampling 操作采用最远点采样FPS 算法得到局部邻域的中心点,Grouping 根据中心点坐标和邻域半径从输入点云中找出nsample个近邻点构成局部邻域,最后输入到PointConv 中提取特征。
前两个MRG 层的采样中心点个数依次递减,采样半径依次增大,第三层MRG 将所有特征信息聚集在一个点上,所以不再需要根据采样半径划分局部区域,而是直接与全连接网络连接得到分类结果。尽管有效利用了高层次的抽象特征,但是缺少对低层次空间结构特征的直接利用。
3 本文网络架构
本文在PointConv 整体架构的基础上,用多层次、多尺度的密集特征Dense Feature 对其进行改进,通过对上下文语义信息的聚合,实现了对多级局部邻域特征的综合利用,从而达到增强网络泛化能力的目的。
3.1 Dense Feature
PointConv 的整体网络架构中,特征的传递仅发生在前后两层之间,每个后续层只对前一层的输出进行操作,所以该操作缺少了对不同层次特征的利用;考虑到前后两层之间的采样半径也是不同的,所以还缺少了对不同尺度特征的利用。
针对以上问题,本文受DenseNet[16]中密集连接模式的启发,建立不同层之间的连接关系,充分利用各层的特征图,在保证网络中特征提取层与全连接网络之间最大程度信息传输的前提下,直接将所有特征图连接起来组成密集特征Dense Feature。
在特征提取的基础上,首先利用特征压缩函数处理每一层的特征图,出于对点云无序性的考虑,特征压缩函数必须是一个对称函数(例如MAX 或者SUM),经过处理后的特征图可以直接在通道维度上进行拼接,用于后面的上下文聚合。加入特征压缩的PointConv卷积如式(2)所示。
其中,Ψ 代表特征压缩函数,DFout代表经压缩函数压缩后的特征图。图3 即为加入特征压缩函数后的PointConv卷积示意图。
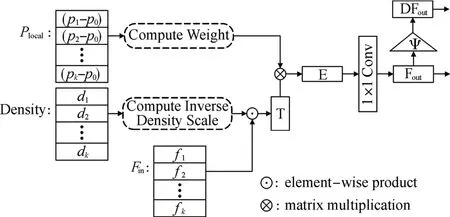
图3 利用密集特征改进的PointConv操作
随着网络层次结构加深,特征图的通道数也越来越多,拼接之后往往导致复杂度过高,为此,本文将网络中每一层输出的特征维度都限定在较小的范围内。在得到所有的压缩特征图之后,利用Con⁃cat操作对其进行拼接,公式如下:
其中,DFi代表第i个MRG 层压缩后的特征图,得到的DFcon即为融合多层次、多尺度语义信息的密集特征,有效保证了特征信息传输的最大化,将此密集特征输入到全连接网络中,即可得到最终的分类结果。
3.2 本文整体网络架构
改进后的网络架构如图4 所示,需要注意的是,因为Dense Feature中的拼接操作需要保证除通道数以外的维度一致性,本文的网络架构在提取特征的时候,并没有将采样中心点的数目逐级递减,而是固定一个常数N不变,这也是我们的网络架构与PointConv 的重要区别。由于侧重于对多级邻域特征的聚合,固定邻域数目也能说明密集特征的有效性,这一思想类似于图卷积神经网络DGCNN[17]的动态更新,不同之处在于,DGCNN 固定的是局部邻域中点的数目,而本文中不变的是局部邻域的数目。

图4 本文整体网络架构
从图4可以看出,本文在PointConv整体网络架构的基础上增加了一个MRG 层,用于提取更多层次特征。类比CNN 中深层次卷积核能获取更大的感受野的特点,四个MRG 层中局部邻域的采样半径和邻域点数依次增加,以此获得多尺度的邻域特征。
四个MRG 层中,采样中心点的数目均为512,每个局部邻域中的采样点数依次为(24,32,40,48),采样半径依次设为(0.1,0.2,0.4,0.8),同时,为了降低显存消耗,提高计算效率,我们将每个MRG层中用于特征提取的MLP 减少为两层;全连接网络使用相同的结构和参数设置,具体设置如表1 所示。

表1 具体参数设置
4 对比测试结果分析
为了验证改进模型的有效性,我们在Model⁃Net40 公开数据集上与PointConv 进行了对比测试,该数据集包含40 个类别的CAD 模型,由9843 个训练模型和2468个测试模型组成。
对比测试在Ubuntu18.04 系统上使用Py⁃torch1.1 框架在一块NVIDIA TITAN V 显卡上进行训练,为了保证对比实验的准确性,我们采用与PointConv 相同的初始超参数和优化器,仅使用三维点云坐标作为输入;为了降低实验数据的偶然性,我们在多次训练后取测试集平均值作为最终结果。以整体准确率OA(Overall Accuracy)和类间平均准确率AA(Average Class Accuracy)作为评价指标,测试结果如表2所示。

表2 对比测试结果
由表2 的结果可以看出,本文的网络模型在测试集上的整体准确率和类间平均准确率上均取得了优于PointConv 的效果。相比之下,整体准确率提升了1.54%,是比较显著的提升,而类间平均准确率的提升幅度相对较小,达到0.43%。
图5展示了不同Epoch下训练集Loss的变化曲线,从中可以看出,本文的网络模型收敛速度更快,更够在训练较少Epoch 的情况下,将Loss 降到相对更低的水平,同时模型的Loss 震荡幅度明显小于PointConv。
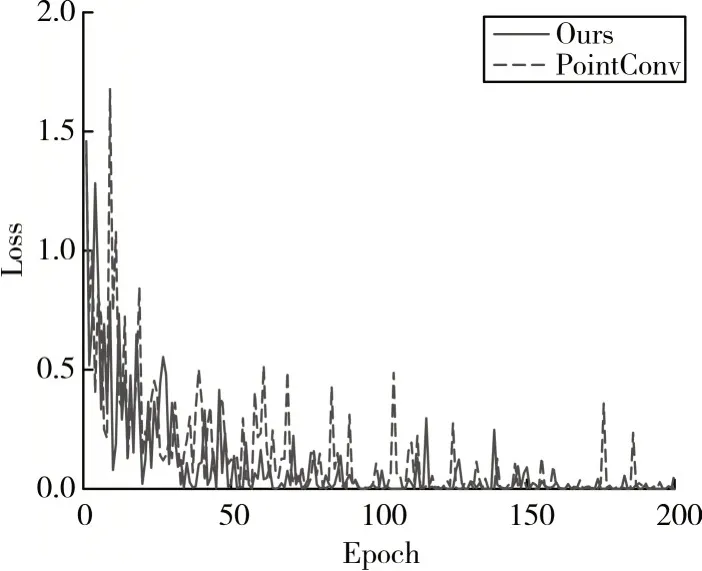
图5 训练集Loss变化曲线
图6展示了不同Epoch 下测试集OA 的变化曲线,从中可以看出,在训练较少的Epoch 之后,本文的模型即可取得明显优于PointConv 的整体准确率,且后续曲线波动小,结果稳定。

图6 测试集OA变化曲线
5 结语
本文提出了一种基于PointConv 改进的点云分类网络,其核心在于聚合多层次、多尺度的上下文语义形成密集特征,使得全连接网络的输入既包含高维的抽象语义特征也包括低层的空间结构特征,在固定采样中心的个数的前提下依次递增局部采样点数和采样半径,实现了对多级局部邻域特征的综合利用。经与原网络架构测试比较,本文的模型在ModelNet40 数据集上的整体分类准确率和类间平均准确率均有所提升,其中整体分类准确率提升显著。
现提出以下几点展望:
1)尝试在不同的数据集上进行测试。本文的对比测试仅采用ModelNet40一个数据集,该数据集仅包含40 个类别,采用更大的、类别更广泛的数据集可以更好地验证模型泛化能力。
2)适当地对原始点云进行数据增强。本文的训练数据直接采用三维点云坐标,如果训练之前先做一些数据增强工作,例如随机缩放、裁剪等,可能对最终的分类结果有益。
3)加深网络模型。已有研究证明可以通过增加网络的深度来增加二维图像的识别效果,尽管点云与图像在数据规整性上存在巨大差异,但是可以借鉴图像在深化网络模型中的可取之处进行探索。
我们将在以后的工作中针对上述问题进行尝试。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
农业工程学报(2022年7期)2022-07-09
汽车工程(2021年12期)2021-03-08
吉林大学学报(理学版)(2020年3期)2020-05-29
时代人物(2019年27期)2019-10-23
自动化学报(2018年7期)2018-08-20
中学生数理化·中考版(2017年6期)2017-11-09
非公有制企业党建(2017年10期)2017-11-03
计算机测量与控制(2017年6期)2017-07-01
现代兵器(2017年4期)2017-06-02
