
基于Siamese 网络的精准目标跟踪∗
2022-03-18 06:20秦广乾
计算机与数字工程 2022年12期
秦广乾
(中国石油大学(华东)计算机与科学技术学院 青岛 266580)
1 引言
视觉目标跟踪与分类、语义分割和目标检测等是计算机视觉的基础任务。在第一帧中标定目标的位置和大小,跟踪的目的是找到目标在一段连续帧中的轨迹。近年来,大多数的跟踪器使用的是经过预训练的网络,这些网络都是针对Imagenet数据集上的图像分类任务进行训练的。
2016 年孪生网络(Siamese Network)引入到目标跟踪领域,其网络结构简单高效。Bertinetto 等[1]提出了SiamFC 方法,网络为去除补零操作和FC 层的AlexNet,将通过模板分支和搜索分支提取的特征计算相关性得到响应图,采用5 种大小不同尺度解决尺度问题,然而该算法没有模板更新,导致在跟踪过程中不能很好地捕捉到外观发生变化的目标;Guo 等[2]针对SiamFC 模板不更新的问题,引入更新因子和变换因子模拟更新模板,根据上一帧目标外观计算更新因子;针对Siamese 系列跟踪算法多尺度产生候选区域效率太低的问题,Bo Li等[3]引入RPN 网络来产生候选区域,并且回归分支可以微调目标框,但是也带来了新的问题:分类分支和回归分支不匹配。
Bo Li 等[4]提出的DaSiamRPN 算法引入了困难负样本和新的数据增强方法提升算法的泛化和判别能力,提出干扰物感知模块抑制相似目标的干扰,此外针对长时间跟踪当目标丢失时扩大搜索区域;Bo Li 等[5]提出的SiamRPN++和Zhang 等[6]的Si⁃amDW 解决了孪生网络无法使用深层网络的问题,抑制补齐操作对跟踪算法的影响,保持了深层网络的不变性,前者通过对数据增加随机偏移抑制填充操作对绝对平移不变性的破坏;后者提出残差裁剪模块抑制填充操作导致的偏移问题;Wang 等[7]结合了SharpMask 算法[8],在SiamRPN 的基础上增加了Mask分支,该算法适用于跟踪和分割多种任务,候选框由Mask 分支产生,使得产生的目标框不像以往平行于坐标轴;同时使用可分离卷积减少计算量;除此之外还有使用两阶段RPN 的SPM 算法和C-RPN 算法,前者粗糙匹配阶段(CM)先筛选同类别候选框作为正样本,微调阶段(FM)主要用于区分前景或背景。后者是消除一阶段RPN 模块产生的简单负样本,将其输出到二阶段RPN 模块,进一步优化前面RPN产生的候选框。
现有的目标跟踪算法主要存在以下问题:难以应对跟踪过程中目标物体的快速形变;遮挡、相似物体、背景冗杂的影响难以处理。针对遮挡问题和RPN 网络导致的分类分支和回归分支不匹配的问题(NMS 部分需要用到分类分支的得分,分类得分高并不代表回归位置好),本文提出ASiamRPN 跟踪算法,采用正负样本均衡提高了算法的辨别能力;其次加了数据增强手段,提高了算法的鲁棒性,针对目标遮挡问题:模板分支获取目标模板时使用Cutout 增加了大量困难负样本;使用调整的ResNet50 网络[9],使用深层网络虽然有更好的语义信息,但对于目标位置不敏感,本文使用空间感知模块和可变形卷积多层特征融合模块来权衡位置信息和语义信息,可变形卷积特征融合模块融合resnet50 的第3 到第5 等3 个卷积模块的特征,充分利用浅层位置信息和深层语义信息来缓解RPN 网络分类和回归分支的不匹配问题。在Siamese框架[10]的模板分支和搜索分支都增加权值共享的自适应模块,提取更具代表性的特征进行互相关操作。
2 Siamese网络跟踪算法
孪生神经网络最早用于图像检索和人脸识别等计算机视觉任务,两个分支共享权重参数,通过损失函数计算两个分支的相似度。SiamFC 算法并不是第一个使用Siamese 网络的跟踪算法,但是后续的基于Siamese网络的跟踪算法多数是在该算法上做的改进。对于SiamFC 网络两个输入,其中模板分支为Z,其输入是视频序列第一帧给定目标模板;待检测区域分支输入跟踪过程中当前帧的待检测区域X。SiamFC 方法使用全卷积网络的方式计算响应图,其每帧响应图计算方式如式(1)所示:
f()表示卷积操作,⊗表示互相关,Siamese 网络的模板分支与搜索分支的特征进行互相关操作得到响应特征图,响应图最大值的位置即是目标所在位置。
3 更精确的深层Siamese 目标跟踪算法
SiamRPN++和SiamDW 等工作分析并解决目标跟踪无法使用ResNet50 等深层网络的问题,但深层网络虽然有较好的语义信息,但对位置信息不敏感,本文算法为ResNet50 为骨干网络的Siam⁃RPN 为基准算法(框架如图3 所示),将第3 到5 层卷积模块输出的特征用可变形卷积实现多层特征融合并增加空间感知模块,结合浅层位置信息和深层语义信息;在互相关操作之前增加权值共享的自适应模块。
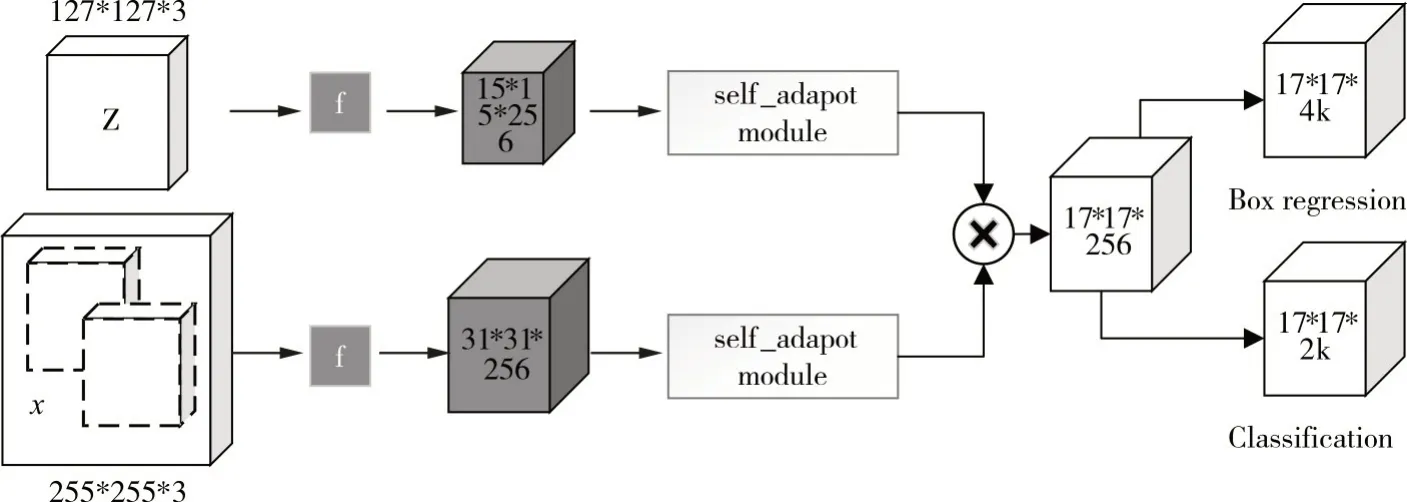
图3 网络结构图
3.1 数据增强的分析
本文针对目标跟踪算法难以处理遮挡问题,引入了Cutout。先从图像序列的第一帧裁剪模板图像Z,然后对其进行翻转、模糊等数据增强后,再对模板图像进行Cutout 处理即C(Z),然后在与搜索分支的特征图做相关。对搜索图像分支X进行Cutout 处理更加符合实际情况,但实验效果并不好。从图2(a)可以看出Cutout操作模拟实现遮挡,极大增加了遮挡样本数量,提高算法针对该问题的鲁棒性。

图2 本文算法的输入图像对
Cutout 主要有两个参数,分别是遮挡图像块的个数和长度L,遮挡图像块个数设置为1。主要在SiamMask-base 和SiamRPN(RN)算 法 上 进 行 测试。分析结果如表1所示。

表1 Cutout数据增强的分析(VOT2018)
在模板Z的随机位置分别产生长度L为8、16、32、64 的遮挡图像块,训练后在VOT2018 数据集[11]测试验证。鲁棒性反映跟踪算法在跟踪过程中的跟丢情况,可以得出cutout 确实对Robustness 有显著抑制效果,跟丢的次数有所减少;当L参数为16、32 时效果较为明显,由于L为64 时效果不稳定,在下面的实验中,设置遮挡块长度L为32。
3.2 空间感知模块和可变形多层特征融合模块
如图1 所示,本文算法基于修改过的ResNet50网络,保留了绝对平移不变性。ResNet50的原有总步长为32,现在设置为8,在第4 和第5 层conv 分别使 用dilation 为2 和4 的 空 洞 卷 积[12]来 增 加 感 受野。具体结构如图1所示。

图1 修改的ResNet50网络
目标跟踪的主要任务是分清物体在何处、是否是目标物体,而浅层特征包含更多的位置信息,深层特征含有更多的语义信息,即分类更需要深层特征,而回归分支更需要浅层特征。而RPN 网络使用深层特征用于分类和回归,这就导致了两个分支不匹配的问题。本文引入可变形卷积多层特征融合模块缓解该问题,将第3个卷积模块的特征图F3下采样、第5 个卷积模块的特征图F5通过双线性插值上采样为第4 个卷积模块特征图F4同一大小再用cat 操作融合,用f1*1卷积将特征图通道数降维成1024 维,通过可变形卷积提取特征。最后将特征图输入到空间感知模块。
本文在ResNet50 的第5 层conv 模块后增加了空间感知模块。该模块由SENet 网络[13]的通道注意力层和CBAM 网络[14]的空间注意力层构成。通道注意力模块让模型关注更重要的通道特征,此处下采样率r=16。W0、W1 分别表示2 层全连接层操作,表示全局平均池化后的1 维通道特征,Finput为输入特征图,Wc表示通道注意力训练得到权重参数,Wc与输入特征通道数相同,是1×1×C维的向量,每一维的数表示该通道的权重(即该通道是否重要)。
在空间注意力层对输入特征在特征通道上分别做Avg 和Max 池化得到两个通道数为1 的特征和,拼接后使用f3*3卷积压缩为通道数为1 的特征图,最后再经过sig⁃moid激活函数得到权重Ws。
σ表示sigmoid 激活函数,f3*3表示卷积核为3的卷积操作。空间感知模块后紧跟着一个1*1 的卷积层把特征图降维成256通道。
3.3 自适应模块
图4 表示自适应模块,该模块权重共享,在Sia⁃mese 网络的两个分支均设有该模块,由通道注意力模块和漏斗模块构成。输入到注意力模块的特征图通道数为256,该模块其他设置和上一小节相同。漏斗模块这里类似于Encoder-Decoder,目的是提取数据的内部隐含关联特征,该模块由3 层卷积层和3 层反卷积层构成,经过漏斗模块得到权重β。β与 前 面 得 到 的 特 征Fout相 乘 得 到
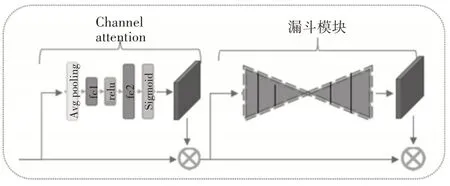
图4 自适应模块图
3.4 实验细节
网络框架:对ResNet50 做了一些改变,相对于王强等的工作,在ResNet50 的第5 个block 后增加了可变形卷积多层特征融合和空间感知模块来提高ResNet50对位置信息的表现。
训练:训练数据集为VID、DET数据集和COCO数据集、YouTuBe-VOS 数据集。选择图像的过程中,对于模板分支的图像单独进行cutout 处理,然后再对两个分支的图像分别进行模糊等数据增强。本文算法是端到端训练的,ResNet50 网络在ImageNet-1K 分类任务上先进行预训练,而且ResNet 网络训练时学习率是自适应模块和RPN 网络的学习率的10 倍。RPN 网络中锚点设置5 种不同的长宽比[0.33,0.5,1,2,3],尺度设置为8。使用带有warmup 参数的SGD 优化器,在前5 个周期学习率从10^(-3)到5×10^(-3),之后的15 个周期就降低为5×10^(-4)。
4 实验与分析
4.1 实验配置
实验时用了4 块Tesla P100 显卡,64G 显存,使用pytorch 工具平台。在VOT2016[15]和VOT2018 两种基准数据集进行测试,两个数据集均有60 个短视频序列,对序列进行了相机移动、光照变化、移动变化、闭塞、尺度变化、目标出视野六种视觉标注,当跟踪过程中目标丢失的时候将会在接下来的5帧重新初始化。

图5 各算法在VOT2016数据集的平均重叠率
4.2 定量分析
如表2 所示,在VOT2016 数据集上将本文算法与SiamFC[1]、SiamRPN[3]、DaSiamRPN[4]、SA-Siam[16]、SPM[17]等 基 于siamese 网 络 的 算 法 和ECO[18]、C-COT[19]、ATOM[20]等相关滤波跟踪算法等进行比较。DaSiamRPN 等诸多siamese-based 算法均使用AlexNet 网络作为backbone,本文使用改进的ResNet50网络,融合浅层位置信息和深层语义信息缓解RPN 网络的不匹配问题,使得回归的目标框更加精准,同DaSiamRPN 算法相比EAO 和Accura⁃cy 分别提升3.1%和2.4%,优于2019 年的SPM[17]和ATOM[20]算法。同时本文算法也具有不错的鲁棒性。

表2 各算法在VOT2016上的性能比较
表3 将本文算法同SiamMask[7]、SiamMask-2B、SiamRPN++[5]、SiamRPN[3]、SiamRPN(RN)等9 种算法在VOT2018 数据集进行测试,SiamRPN(RN)和SiamMask-2B算法都是出自文献[7],SiamMask、Si⁃amRPN++、SiamRPN(RN)以及本文算法的基准框架都是ResNet50。SiamRPN++算法是2019CVPR性能最优的目标跟踪算法,本文算法在Accuracy指标取得最好的性能,略高于SiamRPN++,EAO 排第二。同基准算法SiamRPN(RN)相比A 提升了1.8%、EAO提升了3.6%,R降低了1.4%。图6(b)和(c)的效果对比证明自适应模块能提取更符合跟踪任务的特征,空间感知与多层特征融合模块使算法更加关注目标位置。

图6 DaSiamRPN和本文算法的比较(视频(a)来自VOT2018,大框、中间框和斜框分别是DaSiamRPN,本文算法和真值;(b)和(c)分别为SiamMask和本算法的跟踪结果)
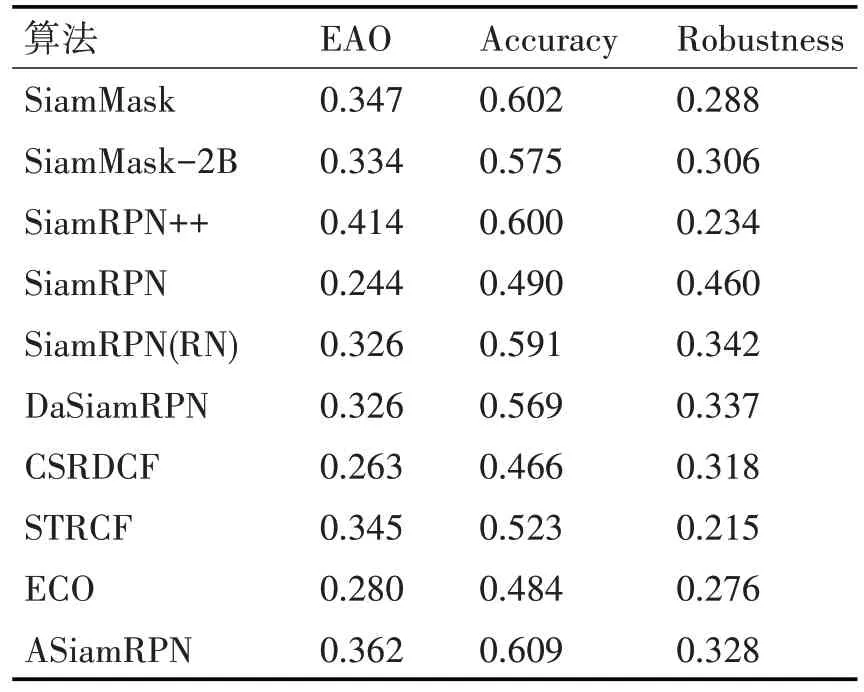
表3 各算法在VOT2018上的性能比较
4.3 消融实验
SiamRPN 的骨干网络为AlexNet,而本文基准算法为SiamRPN(RN),即以ResNet50 为骨干网络的SiamRPN算法。为了评判算法各模块的作用,以在VOT2018 数据集的实验结果为准。从表4 可以看到该基准算法同原始SiamRPN 算法相比有很大提升。基准算法增加了自适应模块后,Robustness明显降低,EAO相较基准算法提升了约1%,证明自适应模块的重要性,提高了网络模型的辨别能力;使用cutout 数据增强的基准算法三种指标都有一定的改善。而增加Cutout和自适应模块后,Accura⁃cy 增加了1.8%,EAO 较基准算法提升了2%;在ResNet50 网络增加了空间感知模块和可变形卷积多层特征融合模块后EAO 再次增加了1.6%。多层特征融合结合浅层信息和深层信息,而空间感知模块使得算法更加关注目标位置,明显提高了平均重叠率,减轻了RPN网络带来的不匹配问题。
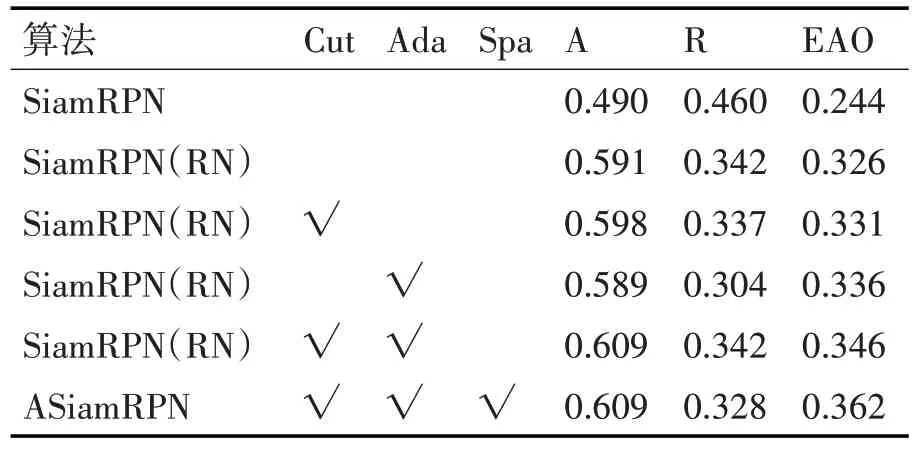
表4 消融实验分析
5 结语
本文在SiamRPN(RN)的基础上做的改进,由于Resnet50 远深于AlexNet,我们认为要充分利用好网络的浅层信息和深层信息,在ResNet50 网络的第5 层卷积模块后先做可变形卷积多层特征融合并增加空间感知模块,缓解RPN 导致的不匹配问题,使用权值共享的自适应模块,上述模块可直接应用于其他目标跟踪算法。本文算法在VOT 数据集上的表现证明了方法的有效性。但仍然具有Siamese-based 跟踪算法的弊端,鲁棒性相较相关滤波类算法差一些;近期不少工作均通过多阶段微调目标框,并缓解了RPN 分类和回归的不匹配问题,接下来会尝试通过可变形卷积融合多帧信息使算法能够利用帧间信息提升跟踪效果。
猜你喜欢
黑龙江大学自然科学学报(2022年1期)2022-03-29
北京航空航天大学学报(2021年9期)2021-11-02
数学物理学报(2021年4期)2021-08-30
水利规划与设计(2020年1期)2020-05-25
电子制作(2019年13期)2020-01-14
学生天地(2019年28期)2019-08-25
电子制作(2019年11期)2019-07-04
铁道通信信号(2018年1期)2018-06-06
北京航空航天大学学报(2018年1期)2018-04-20
中国卫生(2015年1期)2015-11-16
