
融合GRU 与注意力机制的胶囊文本分类方法
2022-03-16 10:31张凌慷
科技创新与应用 2022年5期
张凌慷
(上海电力大学电子与信息工程学院,上海 201306)
随着互联网的不断发展,互联网中的文本信息呈指数性增长。文本分类技术可以从纯文本的大量冗余信息中分类出所需的信息,分类后的文本可以应用于自然语言处理的许多下游任务中,例如问答系统、主题分类、信息检索和情感分析等领域。
文本分类主要可以分为特征提取、分类器选择与训练、评估分类结果与反馈等3 大过程。其中特征提取和分类器的选择与训练共同决定了文本分类任务的最终效果。在传统的机器学习方法中,往往选择提取词频和词袋特征,再训练模型。经典的机器学习方法有朴素贝叶斯、支持向量机等。使用传统的机器学习方法会导致文本分类准确率较低,存在特征提取时表征能力有限、数据稀疏和特征向量维度过高的问题。
随着深度学习的流行,基于深度学习的神经网络也被应用于文本分类任务中,并取得了相对较好的分类效果[1]。Kim 等[2]在卷积神经网络(Convolutional Neural Network,CNN)的基础上提出了TextCNN,直接对句子进行文本分类。长短时记忆网络(Long-Short Term Memory,LSTM)[3]和基于序列的自动编码器[4]和在LSTM 词嵌入层加入对抗扰动[5],得益于该模型在文本表示和对复杂特征强大的表征能力,取得了较好的效果。文献[6]提出使用门控循环单元GRU(Gated recurrent Unit)和注意力机制进行文本分类。
Zhao 等[7]首先在文本分类任务中引入了胶囊网络(Capsule Network),减少了CNN 在池化操作中特征丢失的问题。
本文在胶囊网络的基础上,提出一种融合GRU,注意力机制的胶囊网络文本分类模型。先使用GRU 取代原有的卷积神经网络来进行特征提取,结合注意力机制对GRU 提取的特征重新进行权重分配,对文本内容贡献大的分配较大的权重,最后使用胶囊网络进行文本分类,从而解决CNN 在池化过程中的特征丢失问题。
1 胶囊网络
CNN 在每次卷积之后,都会进行池化操作对特征图进行下采样来简化计算并改善局部特征。但池化操作从上一层传递到下一层的是标量,导致无法考虑一些位置与姿态的信息。因此CNN 在识别具有空间关系的特征时存在很大的局限性。
为了解决CNN 中存在的问题,Hinton[8]于2011 年首次提出了“胶囊”的概念。其创新之处就是使用向量胶囊来取代CNN 中的标量神经元,使得胶囊可以保留输入对象之间的空间信息。基于此,Sabour 等[9]在2017 年进一步提出了具有动态路由算法的胶囊网络结构,该网络包括一层卷积层来提取特征;初级胶囊层将标量特征图编码为向量胶囊;高层胶囊层进行分类。
Zhao 在句子中的不同位置用卷积操作提取局部特征,接着训练2 层胶囊层提取全局特征,最后在全连接层输出每个文本类的概率送入Softmax 分类器进行分类。Kim 等[10]将静态路由代替动态路由机制,忽略句子中部分空间信息,达到简化路由计算的目的。
2 融合GRU 与注意力机制的胶囊文本分类模型
本文提出一种融合了GRU 和注意力机制的胶囊网络文本分类模型,主要由全局特征提取模块和胶囊网络文本分类模块组成,结构如图1 所示。
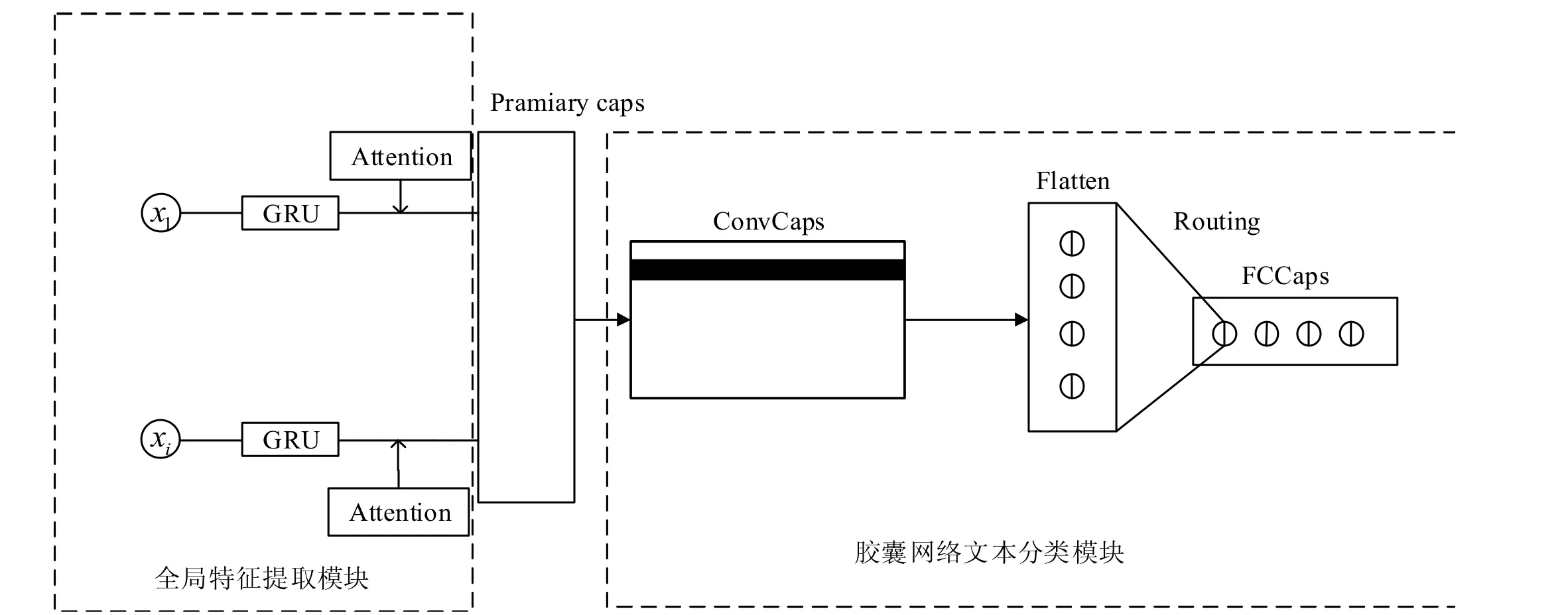
图1 模型结构
2.1 全局特征提取模块
2.1.1 GRU
GRU 是循环神经网络(Recurrent Neural Network,RNN)的一种,相比LSTM,使用GRU 能得到相当的效果,并且更容易训练,能够很大程度上提高训练效率。GRU 由更新门Zt、重置门rt组成,ht为记忆单元。其结构如图2 所示。
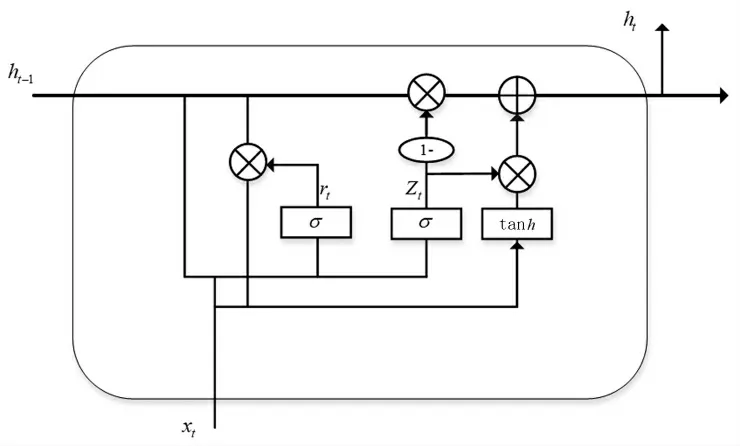
图2 GRU 结构图
首先,通过上一个传输下来的状态ht-1和当前节点的输入xt来获取重置门rt和更新门Zt的状态:

更新门Zt信号范围为0~1。门控信号越接近1,代表记忆下的数据越多。GRU 的优点在于使用同一个门控Zt同时进行遗忘和选择。
2.1.2 注意力机制
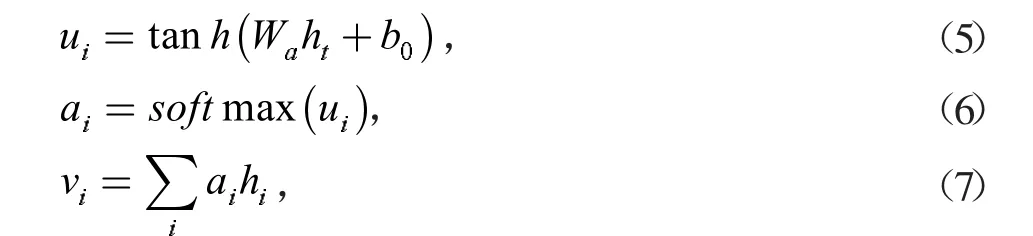
在文本分类任务中,一个句子中的不同单词对于分类效果的影响是不同的,引入注意力机制可以将较重要的单词分配较大的权重。将GRU 输出的ht作为输入:其中:Wa为权重矩阵,b0为偏置,ai为经过softmax 函数后得到的每个词的标准化权重,然后通过加权计算得到注意力机制的输出向量vi作为胶囊网络的输入。
2.2 胶囊网络分类模块
胶囊网络的核心思想就是用向量胶囊来取代CNN中的标量神经元,通过动态路由算法来不断迭代低层胶囊和高层胶囊之间的权重,以确保每个输出发射到高层胶囊中。
动态路由中每个低层胶囊到高层胶囊的概率:

在公式(4)中,利用挤压函数(Squash Function)进行归一化后得到高层胶囊Vj:

动态路由多次迭代之后,不断调整耦合系数Cij,得到修正后的高层胶囊Vj。
3 实验与结果分析
3.1 实验环境
为了验证算法在文本分类任务上的效果,采用基于Tensorflow 的Keras 进行开发,编程语言为Python3.7。服务器配置如下:操作系统为Ubuntu16.04,内存为16G,GPU 为Nvidia GeForce Titan X。
3.2 实验数据与预处理
采用今日头条中文新闻分类数据集TNEWS 进行实验,该数据集包含382 688 条新闻文本,可被标出类别的共有15 类,去掉5 类样本数不足的数据,保留剩下10 类样本作为分类文本分解。每类数据都选取2 000 条文本,随机打乱数据集。训练集、验证集和测试集的划分比例为8∶1∶1。实验的预处理部分先将下载好的文本转码,采用jieba 分词工具对新闻文本数据进行分词处理,再加上对应的标签。
3.3 评价指标与实验设计
为了准确评价本文所提出的模型的性能,采用准确率(Accuracy)作为评价指标,其定义:

其中:TP代表正确识别的正样本数量;FP代表实际为正样本,识别为负样本的数量。
将预训练得到的word2vec 词向量作为GRU 的输入,文本长度100,词向量维度300。训练使用学习率0.001 的Adam 优化器,在每个epoch 将学习率衰减为0.99。卷积层中将每个文本数据都处理成100×300 的矩阵形式。超过100 的文本截取前100 个词,不足的文本加零补齐。GRU 单元设置为64 个,底层胶囊个数设置为32个。动态路由迭代次数为3 次,高层胶囊个数11 个,对应10 类新闻分类,其中标签0 不用,胶囊的模长代表所属分类的概率。采用TextCNN 和capsule-B 作为基线进行对比分析。
3.4 实验结果与分析
TextCNN、Capsule-B 与本文方法在TNEWS 上的实验结果见表1。
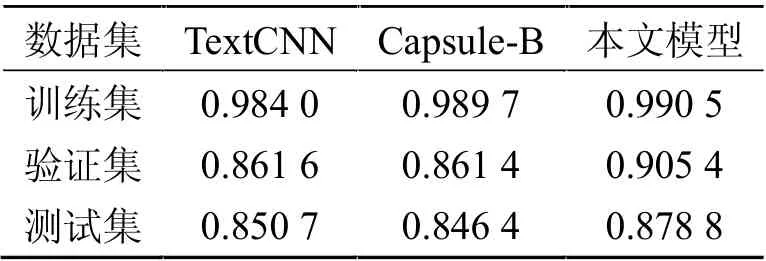
表1 对比实验分类结果(准确率)
3 种方法的epoch 都设置为40。由表1 可见,在TNEWS 数据集上,本文提出的模型分类效果比传统的CNN 算法,以及原有的胶囊网络算法的分类效果要好。本文模型在测试集上的分类准确率达到了87.88%,比TextCNN 的分类结果高2.81%,比Capsule-B 的分类结果高3.24%。验证了本文提出的模型分类有效性。
4 结论
本文融合GRU 和注意力机制的优点,提出了一种融合GRU 和注意力机制的胶囊网络文本分类方法。该方法使用GRU 有效提取文本的全局特征,用注意力机制进行权重分配,进一步关注文本序列中的关键信息。替换掉了原有胶囊网络特征提取时使用的CNN,去除了池化操作带来的信息丢失问题。实验结果证明本文算法有效地提高了文本分类的准确性。下一步工作将对模型进一步优化,提高分类的准确率。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
铁道通信信号(2020年9期)2020-02-06
太原学院学报(自然科学版)(2019年3期)2019-09-23
电子制作(2019年15期)2019-08-27
太原科技大学学报(2019年3期)2019-08-05
科技与创新(2018年1期)2018-12-23
电子制作(2018年19期)2018-11-14
传媒评论(2017年3期)2017-06-13
自动化学报(2017年11期)2017-04-04
第二课堂(课外活动版)(2016年2期)2016-10-21
