
单图像盲去模糊方法概述
2022-03-13 09:18:46刘利平高世妍
计算机与生活 2022年3期
刘利平,孙 建,高世妍
华北理工大学 人工智能学院,河北 唐山063210
在现代信息社会,图像已经成为人们获取事物信息的主要工具,人类获取的海量数据有一半以上来自图像。近年来随着科学技术的不断进步和图像采集方法的多样化,图像数据大多来自手持和手机摄像头、卫星、闭路电视等图像资源。由于拍摄和成像过程的不完善,图像很难避免拍摄的图片有退化的趋势。在拍摄过程中,手机或者数码相机光学缺陷或者镜头对焦不准确难免会使记录的照片出现模糊的现象。模糊图像是在记录某些时刻画面时经常出现的一种现象,图像去模糊的目的是以尽可能低的代价从模糊的图像中恢复出比较清晰的原始图像。
近年来,单帧运动模糊图像的去模糊问题越来越得到人们的关注。从二十世纪六七十年代就被Stockham等人和Oppenheim等人当作案例处理卷积问题,从而也证明了是可以通过图像处理算法对运动模糊图片进行盲去模糊的。与此同时,Fergus 等人也通过应用自然图像先验和先进的统计技术,从照片中消除相机抖动效应,而且采用贝叶斯框架进行求解最大后验概率估计(maximum a posteriori estimation,MAP),从而达到去除模糊的效果。因为基于图像盲去模糊的问题大都是在估计模糊核的基础上进行的,所以在接下来的几年里,学者大都是在MAP 的框架上拓展研究的。直到You 等人提出一种新的变分模型来处理模糊核的估计问题。在后续研究中,Chan 等人、Krishnan 和Fergus相继提出了全变分模型和拉普拉斯分布的方法来进行运动图像的盲去模糊,两者之间相辅相成,对模糊核的估计和还原出清晰的图像有着较大的影响。
1 传统的单图像盲运动去模糊方法
全局运动模糊图像复原:(1)基于极大后验估计的方法。2013 年,Pan 等人首次利用图像梯度的范数来构建正则化先验。2016 年,Pan 等人利用自然图像的重尾分布提出了一种超拉普拉斯先验。同年,Pan 等人将图像的强度以及梯度先验进行结合,提出一种针对文本图像的正则化先验。接下来,Pan等人在He 等人启发下率先提出了在图像去模糊领域采用暗通道先验方法能够取得比较好的实验效果。同时,Yan 等人也提出了一种亮通道先验,并将其与暗通道先验相结合提出了一种极端通道先验去模糊的方法。(2)基于边缘估计的方法。Joshi等人从单个模糊图像中以边缘子像素分辨率估算非参数、空间变化的模糊函数,从而估算出模糊核达到去模糊的效果。Jia在研究了物体边界透明度和图像模糊之间的关系后,将图像去模糊分为滤波器估计和图像去卷积过程,并提出了一种从alpha 值的角度估计运动模糊滤波器的新算法,将滤波器估计公式转化为解决具有定义的可能性和先验透明性的最大后验(MAP)问题,从而更好去处理模糊图像。
局部运动模糊图像复原:(1)经典单层图像模型方法。Bar 等人及Sorel 等人分别采用了一层图像模型和一个空间变化的点扩散函数(point spread function,PSF)来对图像的部分模糊进行去除。(2)适度用户交互的局部估计技术去模糊方法。研究人员借鉴抠图技术提出了两层图像模型,通过消光技术、强大的图像先验模型和用户的帮助,实现了前景层和背景层的同时恢复,取得了良好的实验效果。(3)完全自动化的局部估计技术去模糊。Bae 等人提出了一种增加图像散焦的图像处理技术,以模拟具有较大孔径的透镜的浅景深。Dai等人利用光流约束和运动模糊约束之间的相似性解决了许多空间变化的运动模糊估计问题。Joshi 等人从单个图像以亚像素分辨率估计非参数的、空间变化的模糊函数,用来测量由有限的传感器分辨率造成的模糊,即使对于对焦图像也可以通过估计亚像素、超分辨率的PSF 来实现。Levin将图像分割成具有不同模糊的区域,将模糊部分能用单个核来建模,并且可以用相同的核去卷积整个图像减轻形成的伪影。表1 显示了更多的传统的图像盲去模糊的方法。
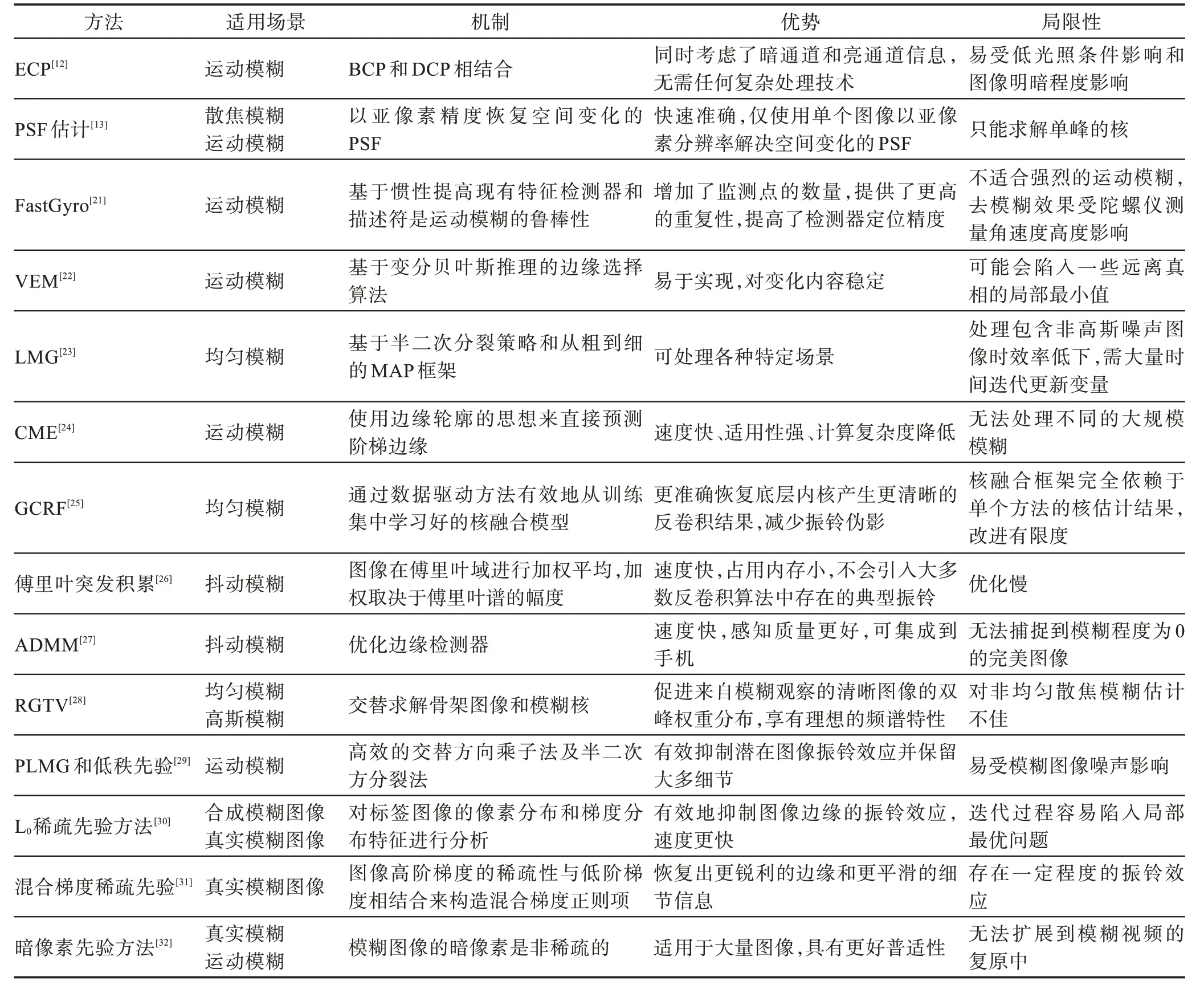
表1 传统的盲去模糊方法Table 1 Traditional blind deblurring methods
2 基于深度学习的单图像盲去模糊方法
卷积神经网络盲去模糊:使用卷积神经网络(convolutional neural networks,CNN)对图像进行去模糊并提高其分辨率(超分辨率)已得到广泛且成功的研究。基于卷积神经网络的图像运动模糊恢复方法利用了图像局部权值共享的优点。卷积运算可以方便地处理高维数据,避免特征提取过程中数据重构的复杂性。图像运动去模糊的早期工作只能满足整个图像的均匀运动模糊。Fergus 等人提出方法是首先确定模糊核,然后执行反卷积以校正相机抖动来避免图像模糊。Cronje通过使用卷积神经网络估计图像块的运动矢量,将所有预测的运动矢量组合起来,以形成密集的非均匀运动估计图,准确地确定了不均匀的运动模糊并恢复模糊的图像。Xu 等人提出了一种用于图像去模糊的深度学习算法,它能够学习从模糊图像中提取尖锐边缘以进行内核估计,且不需要启发式边缘选择步骤或在图像去模糊中广泛使用的从粗到细的策略,极大地简化了核估计过程并降低了计算成本。针对传统盲去模糊算法中需要估计模糊核的问题,Hradiš等人以端到端的方式专门针对文本图像训练了一个深层的CNN 模型,可以直接从模糊的输入中重建高质量的图像,而无需假设任何特定的模糊和噪声模型。Schuler等人提出了一种神经网络来估计模糊核,以进行通用图像去模糊。然而,该方法需要针对不同大小的内核训练不同的网络,由于实际情况下的运动模糊相当复杂而限制了其应用的领域。
循环神经网络盲去模糊:循环神经网络(recurrent neural network,RNN)因其在顺序信息处理中的优势而成为一种流行的去模糊工具。循环神经网络同样也适用于图像盲去模糊中,其具有记忆功能的神经网络,在某种程度上创新于卷积神经网络,适合序列数据的建模,还应用于图像处理领域。Zhang 等人提出了一种用于动态场景去模糊的新型端到端空间变异递归神经网络,其中RNN 的权重是由深层CNN 来学习的,通过分析提出的空间变体RNN 与去卷积过程之间的关系,表明了空间变体RNN 能够对去模糊过程进行建模,得到训练后的模型明显更小。另外,Tao 等人提出了一个标度递归网络,以及每个标度中的编码器-解码器ResBlocks 结构,新的网络结构比以前的多尺度去模糊参数具有更少的参数,并且更易于训练,取得了良好的实验效果,并为后续的研究提供了新的方向。
对抗网络盲去模糊:随着人工智能的兴起,生成式对抗网络(generative adversarial networks,GAN)也日益广泛应用到图像处理领域,从低分辨率(low resolution,LR)对应物估计高分辨率(high resolution,HR)图像再到现在对模糊图像的处理,越来越得到了人们的重视。生成对抗网络被用于去模糊,是因为它们在保留纹理细节和生成逼真图像方面具有优势。2014 年Goodfellow 等人提出一种新型的深度学习模型-生成式对抗网络。在图像去模糊的应用中,对抗网络的生成器根据鉴别器的判别结果进行优化,鉴别器尝试从生成的图像中判别出清晰的图像,直到鉴别器无法从生成的图像中分辨出清晰的图像,此时生成器的去模糊效果达到最佳。
近年来,GAN 网络在图像领域表现得越来越突出,Ledig 等人提出一种用于图像超分辨率(superresolution,SR)的生成对抗网络,其运用的深层残差网络能够在公共基准上从大量降采样后的图像中恢复逼真的纹理,且在均值评分(mean opinion score,MOS)测试显示,使用SRGAN(super-resolution generative adversarial networks)可以显著提高感知质量,因此该方法可以很好地应用到图像的去运动模糊问题当中。Chen 等人对于解决由于天基成像系统抖动或观测目标运动而导致图像退化的去模糊问题,结合WGAN(Wasserstein GAN)网络提出了一种利用生成对抗网络实现端到端图像处理的无需在轨核估计运动去模糊策略,证明了该方法的可行性和有效性,同时表现出在定量和定性方面均优于现有的遥感图像盲去模糊算法。2018 年,Kupyn 等人首先根据条件对抗网络去除相机抖动的模糊,然后提出一种无核盲运动去模糊学习方法来弥补之前的不足,使用多分量损失函数进行优化的条件对抗网络Deblur-GAN,对不同的模糊源进行建模,极大地帮助了对模糊图像的检测。与此同时,在2019 年,Kupyn 等人首次将特征金字塔网络引入去模糊,并提出了一种新的端到端生成对抗网络DeblurGAN-v2,用于单图像运动去模糊,大大提高了去模糊的效率、质量和灵活性。表2 显示了更多的深度学习图像盲去模糊方法。
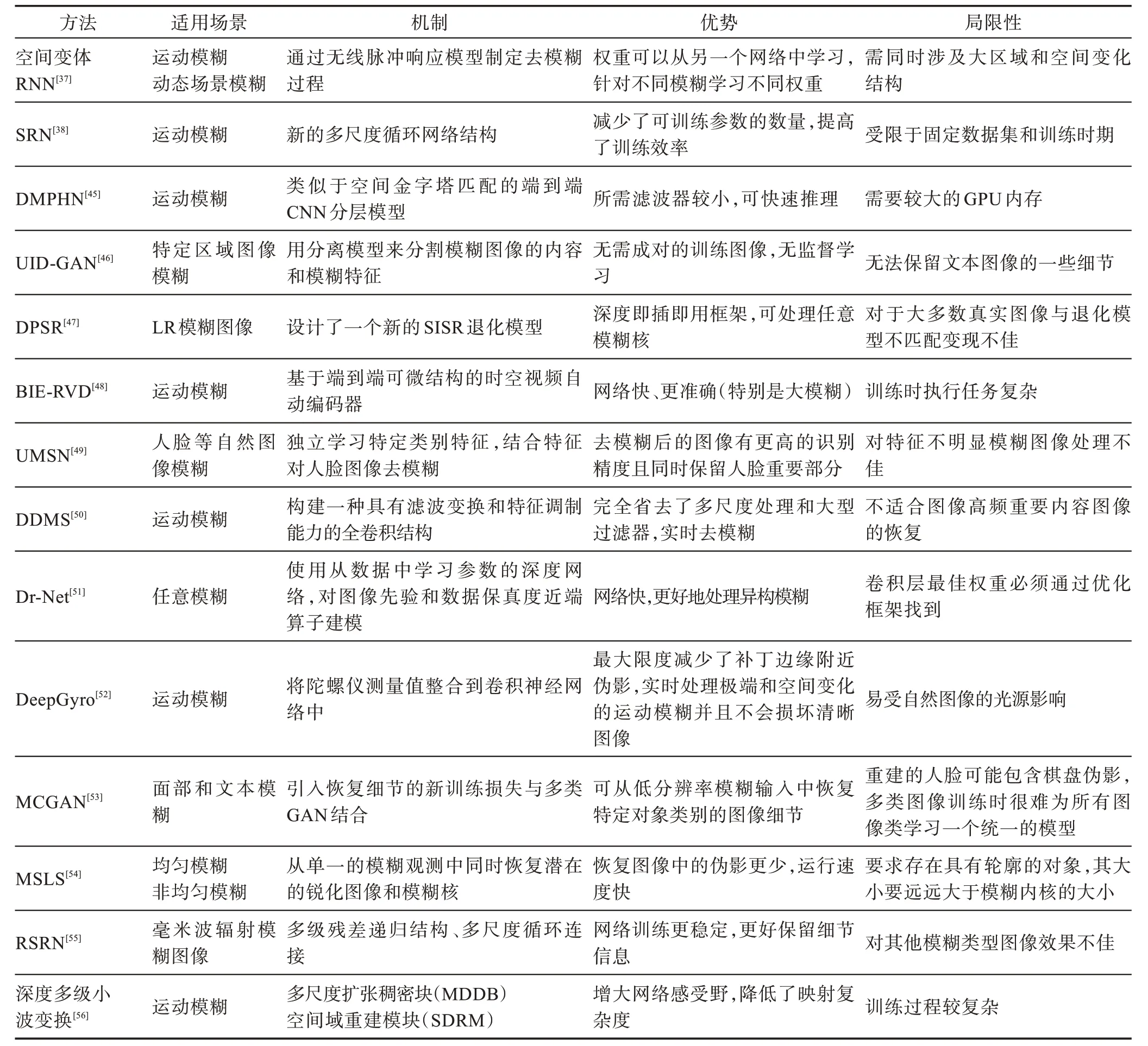
表2 基于深度学习的盲去模糊方法Table 2 Blind deblurring method based on deep learning
3 图像盲去模糊的关键工作
3.1 数据集的构建
传统数据集中的大部分模糊图像都是通过一些固定核进行模糊处理的,很难模仿自然的模糊图像。当使用机器学习中的算法处理某些问题时,数据集的质量直接会影响到算法运行的结果,因此高质量的数据集在研究后续问题中占有重要的地位。在当下去模糊的工作当中,很难在同角度、同位置且光线不变的情况下拍摄出一对清晰和模糊的图像,相比于一些局部图像恢复的数据集而言,对图像去模糊的数据集的获取标准更高一些,因此根据现有技术可以将数据集构造方法分为以下三类。
第一类是由图像处理算法合成数据集。数据集可以像Levin 等人和Sun 等人由清晰图像数据集图像与模糊核卷积得到模糊图像的数据集。同样也可以像Lai 等人和Kupyn 等人一样利用模拟生成的运动轨迹算法生成模糊核来构造模糊图像的数据集,虽然容易获得,但是该方式在三维平面上构造的运动模糊中存在很多的不足。
第二类是由摄像机运动轨迹综合的模糊数据集,最典型的就是Kohler 等人在2012 年提出的Kohler数据集。Kohler数据集由4个图像组成,每个图像有12 个不同的内核,这是用于评估盲去模糊算法的标准基准数据集。随着科学技术的进步,2017 年Nah 等人采用高速摄影机获得了当前最大的GOPRO 模糊数据集。GOPRO 数据集是随着时间的推移整合清晰的图像来模糊图像。而且GOPRO还可以模拟自然场景中的图像模糊类型,其中包含2 103 个用于训练的图像对和1 111 个在测试集中的图像对。通过这类方式构建的数据集虽然比较繁琐,但是较第一类方式更能真实地模拟出生成运动模糊图片的过程。
第三类是现实场景中拍摄的模糊图像数据集,不会进行任何的后期算法处理。通过这种方式获得的图像数据集只有模糊的图片,无法使用深度学习的算法对该方式生成的模糊图像进行训练,但依旧可以被用来作为测试集对去模糊后的图片进行检测评估。
3.2 图像去模糊后的质量评价方法
图像质量的评价可分为主观评价和客观评价。主观评价主要是对人的视觉感官进行评价,而客观评价则采用一种评价标准来比较图像质量。常用的客观评价方法有峰值信噪比(peak signal to noise ratio,PSNR)和结构相似性(structural similarity,SSIM)。峰值信噪比反映了估计图像和原始清晰图像的失真程度。一般来说,峰值信噪比越大,图像恢复效果越好。它的表达式为:

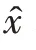
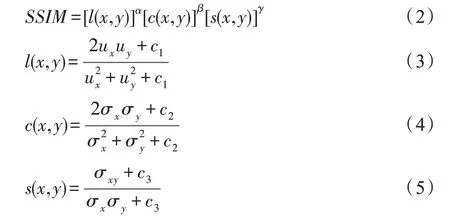
SSIM 是比较全面的图像评价指标,分别从亮度、对比度和结构相似度评价图像,其中u、u分别表示图像和的均值,σ、σ分别表示图像和的方差,σ表示图像和的协方差。SSIM 衡量的是两幅图像的相似度,其值在0 到1 之间,越趋近于1说明相似度越高,复原的结果越好。
3.3 实验评估
为了比较传统去模糊方法及深度神经网络去模糊方法的去模糊性能,对部分去模糊方法在GoPro 数据集、Kohler数据集、Lai数据集中的“face2”公共数据集、Helen数据集、CelebA数据集和实拍模糊图像上进行了定量和定性的评估实验。定量评估主要是使用不同去模糊方法的峰值信噪比(PSNR)和结构相似性(SSIM)的值来测试去模糊的效果。定性评估则是使用视觉图形来直观地对去模糊后的图像进行评估。
在单图像盲运动去模糊实验中,为了直观对比传统优化模型的去模糊性能,本文选择Kohler 数据集上的自然图像定性评估算法的优劣性能。图1 显示了四种传统优化模型在Kohler 的某个数据集上去模糊的效果,其中(a)~(d)的去模糊算法实验均是在Windows10 系统下的Matlab 2020 中完成。为了使实验的精度和速度达到平衡,实验中设置步长为0.1,=5,=10 和一些超参数==0.004,=2。通过比较这几种方法,和较先进的Pan 等人的方法相比,Li的方法可以生成更清晰的图像和更少的振铃伪影。为了评估深度学习技术对模糊图像的去模糊性能,Kupyn等人选择了Lai公共数据集中“face2”图像进行测试。图2 展示了几种传统优化模型和深度学习模型在Lai 数据集的“face2”测试图像的定性比较。其中(a)、(b)、(c)、(d)、(f)的去模糊算法是在Windows10 系统中Python=3.6 搭载PyTorch1.4.0环境下完成的,(e)、(g)算法是在Windows10 系统的Matlab 2020 中完成的,(h)算法是在Windows10 系统的OpenCV 中完成的。结果表明,利用DeblurGANv2 算法和SRN-DeblurNet 算法得到的图像是当中表现得较好的两个结果,两者都在边缘锐度和整体平滑度之间取得了很好的平衡。但是通过仔细观察,发现SRN 在这个图像上仍然会产生一些鬼影,例如,从衣领到右下面部区域的白色“侵入”,但DeblurGANv2 算法与其他神经网络和传统算法相比,模型无伪影,图像表现得更平滑,视觉上更令人愉悦。因此DeblurGAN-v2 无伪影去模糊性能较图2 中其他方法更加突出。

图1 Kohler数据集中钟摆图像不同方法去模糊后的结果Fig.1 Results of different methods of deblurring pendulum image in Kohler dataset

图2 Lai数据集的“face2”测试图像的定性比较Fig.2 Qualitative comparison of“face2”test images of Lai dataset
为了更好地评估一些去模糊方法的性能,将传统的部分去模糊方法与深度学习的方法进行了定量的比较,其中包括4 种传统的去模糊模型优化方法,10 种深度学习的去模糊方法。为了比较不同方法对图像去模糊后的复原程度,在GoPro 和Kohler数据集中选择出设定好的训练集和测试集统一进行对比评估。传统的去模糊方法在Windows10系统下的Matlab 2020 中完成;深度学习去模糊算法在Windows10 系统中Python=3.6 搭载PyTorch1.4.0 环境下完成,使用ADAM(adaptive moment estimation)优化器,设置学习速率为10,每次学习150个历元,线性衰减至10,保存预先训练的主干权重3 个历元,然后保存所有的权重并继续训练,最终利用训练好的权重对测试集进行评估。表3 显示了不同网络和优化技术在GoPro数据集上的PSNR 和SSIM 结果。传统的优化技术模型在GoPro 数据集上进行定量评估中,通过比较这几种方法的标准性能指标(PSNR、SSIM),Whyte 等人的参数化几何模型较其他方式效果较好;深度学习不同网络模型在PSNR/SSIM方面定量评估中,Aljadaany等人提出的Dr-Net 网络模型和Tao 等人提出的SRN 网络模型较其他方式效果较好。表4 显示了不同网络和优化技术在Kohler 数据集上的PSNR 和SSIM 结果。传统的优化技术模型在Kohler数据集上进行定量评估中,通过比较这些方法的标准性能指标(PSNR、SSIM),Xu 等人提出的去模糊优化方式在该数据集上较其他方式效果较好;深度学习不同网络模型在PSNR/SSIM 方面定量评估中,Aljadaany 等人提出的Dr-Net网络模型和Tao等人提出的SRN网络模型在Kohler数据集中较其他方式效果较好。

表3 GoPro 数据集上不同方法的PSNR 和SSIMTable 3 PSNR and SSIM of different methods on GoPro dataset

表4 Kohler数据集上不同方法的PSNR 和SSIMTable 4 PSNR and SSIM of different methods on Kohler dataset
在Kohler 数据集实验过程中,DR-Net 虽然达到了很高的峰值信噪比,但在PSNR 方面还没有达到最好的水平。Xu 等人获得了27.47 dB 的高值。尽管如此,DR-Net 在SSIM 方面获得了最优的0.865,Xu等人紧随其后,为0.811。但是,Xu 等人在GoPro测试集上获得了20.30 dB 的低分贝,而DR-Net 获得了30.35 dB。这可能是因为Xu 等人需要对整个图像进行单一的模糊核估计,同时也说明了Xu 等人对于空间上均匀的模糊(如Kohler 测试集中的模糊)有很好的处理性能。然而,GoPro 是一个具有空间异质模糊的真实世界测试集,因此强制对整个图像进行单一内核估计不是理想的方法,这导致Xu 等人在GoPro 上表现不佳,这也有助于证明DR-Net 没有这个问题,可以很好地处理空间异构模糊(它在GoPro测试集上获得了最优的技术)。
在对人脸模糊图像盲去模糊中,人脸等自然图像的内在语义结构是一个重要的信息,可用于改善去模糊结果。很少有技术以语义标签的形式使用这些先验信息,这些方法没有考虑到与人脸对应的语义图的类不平衡,与面部皮肤、头发和背景标签相比,面部的内部部分(如眼睛、鼻子和嘴巴)的代表性较少。表5展示了Helen数据集上的PSNR和SSIM 结果。表6 展示了CelebA 数据集 上的PSNR 和SSIM 结果。其中传统的去模糊方法在Windows10 系统下的Matlab 2020中完成;深度学习去模糊算法在Windows10系统中Python=3.6 搭载PyTorch1.4.0 环境下,批次大小为16,学习率设置为0.000 2,使用ADAM 优化器进行训练完成。从表中的PSNR 和SSIM 值可以得出,基于传统的MAP的方法Cho等人、Krishnan等人、Xu 等人、Shan 等人、Zhong 等人在去模糊人脸图像方面效果较差,导致了较多的振铃伪影,而Pan等人基于MAP 的人脸去模糊方法对噪声不具有鲁棒性,并且高度依赖于参考图像的相似性。Nah 等人基于CNN 的方法没有考虑人脸语义信息,从而产生过于平滑的结果。相比之下,虽然Shen 等人所提出的方法利用全局和局部人脸语义来恢复具有更多细节和更少视觉伪影的人脸图像,但是Yasarla等人提出的不确定性引导多流语义网络去模糊方法还要优于Shen 等人提出的语义类方面的性能。此外,还利用Xu 等人、Zhong 等人、Shen 等人方法对部分真实模糊图像进行了实验。不同去模糊方法的结果如图3 所示。其中(a)、(b)的去模糊算法是在Windows10 系统中Python=3.6 搭载PyTorch1.4.0 环境下完成的,去模糊算法(c)、(e)是在Windows10 系统的Matlab 2020 中完成的,去模糊算法(d)是在Windows10 系统的OpenCV 中完成的。从图中可以看出,与最先进的方法相比,Yasarla 等人提出的UMSN(uncertainty guided multi-stream semantic network)可以产生更清晰的图像。例如,Xu 等人、Zhong等人方法产生包含伪像或模糊图像的结果。如图3的第1~6 张所示,Kupyn 等人、Shen 等人无法重建眼睛、鼻子和嘴巴。然而,眼睛、鼻子和嘴巴区域在对应于Yasarla 等人使用的UMSN 方法中的图像是清晰可见的。

图3 真实模糊图像上的去模糊后的结果Fig.3 Results of deblurring on real blurred image
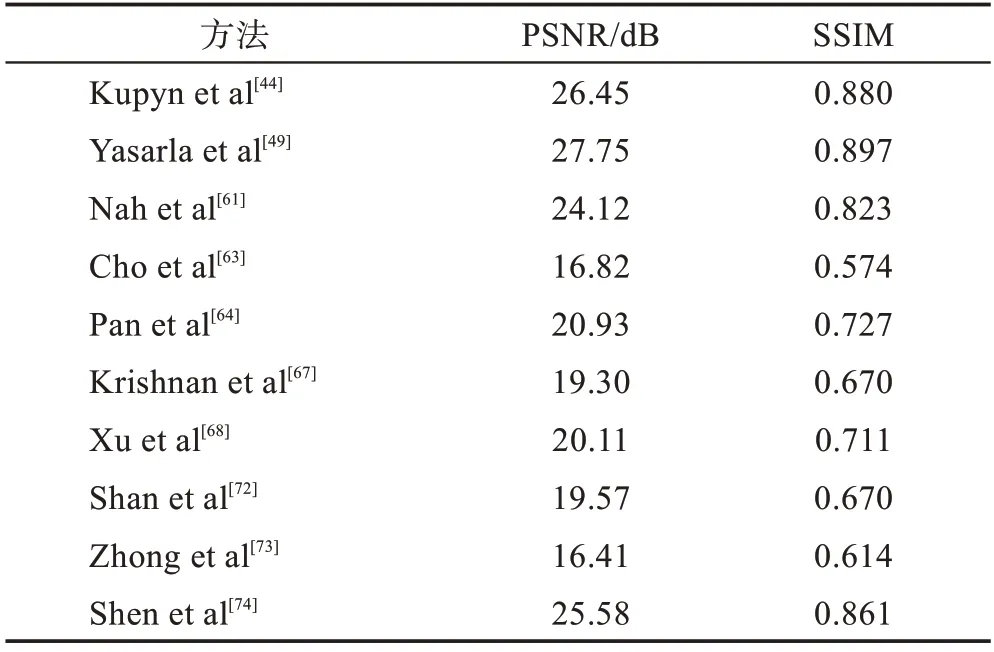
表5 Helen 数据集上不同方法的PSNR 和SSIMTable 5 PSNR and SSIM of different methods on Helen dataset
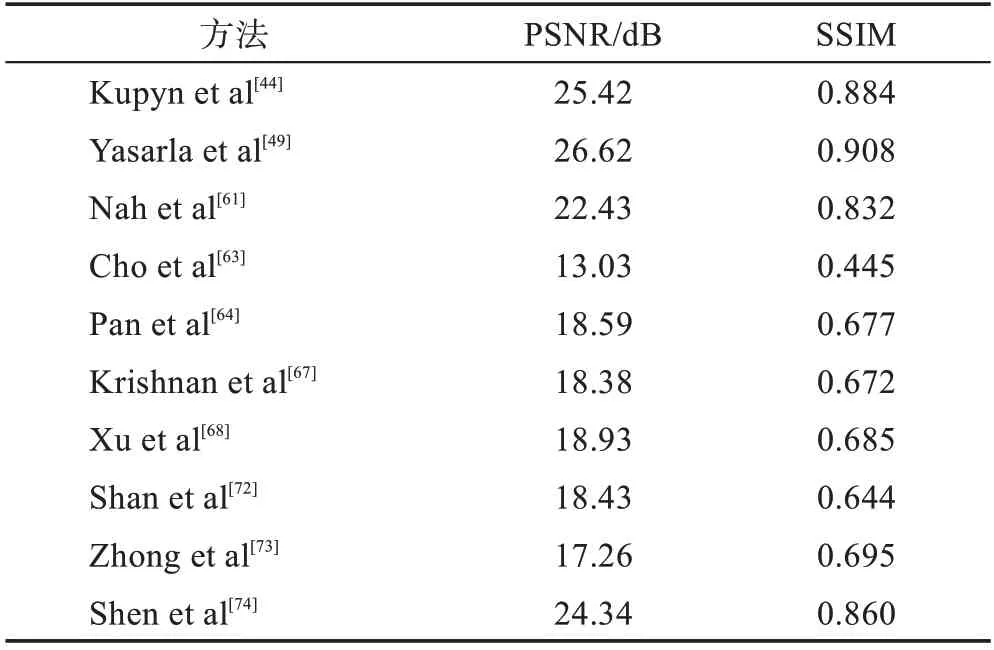
表6 CelebA 数据集上不同方法的PSNR 和SSIMTable 6 PSNR and SSIM of different methods on CelebA dataset
为了使本文实验更具有参考价值,使用iPad 平板设备相机在现实生活中捕获了一张分辨率为512×512 像素的运动模糊图像,然后在Windows10 系统下的Matlab 2020 中用几种传统的优化技术对模糊图像进行去模糊处理,其中设置步长为0.1,=5,=10 和一些超参数==0.004,=2。图4 显示了捕获的带有星巴克模糊标识图像在几种不同去模糊方法下的结果。从处理后的结果来看,Pan等人利用正则化强度梯度先验算法和Li 等人采用的基于数据驱动判别性先验算法得到的图像是当中表现得较好的两个结果。Krishnan 等人、Xu 等人和Pan 等人处理后的图像有明显的伪影,清晰度也很低。直观对比来看,Li等人的方法生成的图像更清晰且伪影更少。

图4 不同方法对星巴克模糊图像处理后的结果Fig.4 Results of different methods on Starbucks blurred image processing
综上来说,通过比较这些方法的标准性能指标(PSNR、SSIM)和视觉图形结果可以很容易得出:传统的优化方法存在严重的振铃伪影和较大的模糊,这是优化方法的一个关键问题,但不影响深度学习方法。深度学习方法在小模糊和大模糊上表现出稳定的性能,而优化方法在从小模糊重建更清晰的边缘方面做得很好,但在大模糊上表现不好。这些观察结果表明,深度学习方法在小模糊上的性能仍需要改进。
4 趋势展望
图像去模糊在图像处理领域越来越得到学者的关注,无论是理论研究还是实际应用方面都取得了较多的成果和进展,但未来仍有一些待提高的方面有待完善和解决。
4.1 数据集的更新
在深度学习中,数据集的质量直接影响着后续的实验效果,数据集的质量和更新对图像的去模糊有着较深的意义。现在常用的最大数据集为GOPRO 数据集,该数据集仅仅是扩大了数据集的数量,得到的数据集多样性不够且场景太单一,甚至有的表现得运动模糊不是特别明显。同样其他一些由算法合成的数据集,数据量较少,在论证时表现得不够充实。因此在当前形势下,需要对数据进行丰富和更新,不仅要保证数据量充足,还要充分满足实验的要求。
4.2 网络结构的改进
随着机器学习在图像处理领域算法的成熟,深度学习的网络结构也变得越来越多样化,因此由不同的需求对网络结构进行不同方向的创新和改进变得很有必要。Yan 等人在进行图像去模糊中只是运用了简单的生成网络,没有延伸其网络结构。但是随着网络结构的丰富,追求更高的去模糊效果,则需要在原来的网络结构模型结构中进行拓展和加深,而不再单单满足于基础的网络结构。
4.3 更客观的评价指标的提出
如今广泛应用的峰值信噪比和结构相似性指数与人们的主观感受相差甚远,特别是当图像中存在不均匀运动模糊时,因此在处理实验结果的时候,一个可参考的评价指标能够很好地对处理过后的去模糊图像进行评价和对使用算法的合理性进行评估。随着去模糊技术的发展,为了公平公正地对处理后的去模糊后图像进行评估,需要在该领域得到一种公认的评价标准,而不再是在论文后面还要附上人们的感知测试效果。
5 结束语
本文对图像去模糊的传统优化方法以及深层神经网络方法进行了比较、研究和总结。注意到在用深度学习去模糊的过程中,很难获得包含成对的锐化和模糊图像的数据集。到目前为止,最好的数据集是那些由相机和对象运动产生的高速视频短序列的数据集,但这些数据集对于训练去模糊网络仍然不理想。更重要的是,现有数据集没有包含足够的图像训练去模糊网络来处理不同的自然场景。可以在网络上获得大量的单独的清晰和模糊的图像,而使用未配对的图像来训练去模糊网络的方法将是一个突破。两项开创性的研究最近展示了如何使用模糊特定的表示和特征解决以无监督的方式训练去模糊网络。但是,只有在表现出空间不变模糊的人脸图像上才能取得成功,因此将无监督学习扩展到广泛的自然图像有着很大的潜力。现有的评估方法在实验过程中也有很多的不足。首先,合成的模糊图像往往不能捕捉到真实运动模糊退化的复杂性和特征。对这些数据集的评价不能反映真实图像上单幅图像去模糊算法的性能。其次,现有的方法使用PSNR 和SSIM 来量化性能,这在图像去模糊中不能很好地与人的感知相关。由于缺乏对人类感知的研究,很难对去模糊算法的性能进行比较。针对评估方法的不足,在未来的实验中可以选择许多全参考和非参考的图像质量度量指标进行评估,从而更好地量化去模糊的性能。最后,通过本文的论述、评估和分析,希望能够对未来的盲去模糊的课题研究提供一定的理论基础。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
电子制作(2019年19期)2019-11-23 08:42:00
数学物理学报(2017年5期)2017-11-23 07:51:31
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
质量与标准化(2015年9期)2015-07-10 15:12:07
海军航空大学学报(2015年4期)2015-02-27 13:45:47
浙江人大(2014年5期)2014-03-20 16:20:25
新课程学习·中(2013年3期)2013-06-14 05:55:20
