
强化学习中的策略重用:研究进展
2022-03-11 01:50:48唐文泉
系统工程与电子技术 2022年3期
何 立, 沈 亮, 李 辉,2,*, 王 壮, 唐文泉
(1. 四川大学计算机(软件)学院, 四川 成都 610065; 2. 四川大学视觉合成图形图像技术国家级重点实验室, 四川 成都 610065; 3. 江西洪都航空工业集团有限责任公司, 江西 南昌 330024)
0 引 言
深度学习(deep learning, DL)被认为是解决连续决策任务的一个有原则和有效的方法,在这个方法中,学习智能体通过与环境进行交互,不断试错来提高其性能。近年来,随着强化学习(reinforcement learning, RL)的快速发展,将RL算法嵌入DL框架组合而成的新结构深度RL(deep RL, DRL)进一步推动了RL的发展。
无论是在学术界还是在工业界,DRL都被广泛应用以解决之前难以解决的任务,比如,其在控制、游戏中的人机对抗等领域都取得了不错的成绩。尤其是当AlphaStar和AlphaGo在与顶级人类玩家的对弈中取得胜利,这些足以说明DRL取得的巨大成功。
虽然RL在不断发展和进步,但在将其应用到诸多场景中的时候,依然面临着困难和挑战,例如高采样复杂度和脆弱的收敛性等。除此之外,RL问题中的环境模型一般来说是未知的,智能体只有在保证与环境充分交互的前提下,才能利用与环境交互得到的知识来提升自身的性能。由于环境反馈的信息存在部分可观测性、奖励稀疏性、延迟性以及高维度的观测值和动作空间等问题,智能体在不借助任何先验知识的情况下收敛到最优策略是非常困难和耗时的。迁移学习(transfer learning, TL)是一种用相关的、类似的数据来训练相似问题的方法,能够将学习到的知识从一个场景迁移到另一个场景。这种利用外部专业知识来加速智能体的学习过程的思想,在很大程度上能够弥补RL缺乏先验知识的问题。将TL应用在RL中的一个显著效果是保证了RL训练结果的复用性和时效性。主要原因是TL能够复用现有的知识,不会丢弃已有的大量工作和成果,而这一点是RL无法做到的。此外,对于新问题,TL能够快速迁移和应用已有的成果,体现时效性的优势。
策略重用(policy reuse, PR)作为一种TL方法,通过将源任务中的最优策略迁移到目标任务中来解决上述RL中的问题,也因而成为RL领域的一个热门研究课题。
本综述所作的贡献:从策略结构的角度出发,对现有的RL中的PR方法进行了总结、分析和对比,并扩展到了DRL和多智能体领域,为研究者提供了新的研究思路和未来研究方向的建议。
1 基本概念
本节简述了RL、DRL和PR的基本概念,并且说明了这篇综述中所需要使用到的一些关键术语。
1.1 RL
典型的RL问题是训练一个RL智能体与一个满足马尔可夫决策过程(Markov decision process,MDP)标准的环境交互。在每次与环境的交互中,智能体从初始状态开始,识别自身所处的状态,并遵循某种策略执行相应的动作,环境则会产生该“状态-动作”对的奖励。执行完动作后,MDP将会依据转移函数过渡到下一个状态。智能体在与环境的交互过程中累积折扣奖励,这一系列的相互作用称为一个episode。RL问题就是重复训练大量的episode直至智能体学习到最优策略。图1表示RL的基本框架。
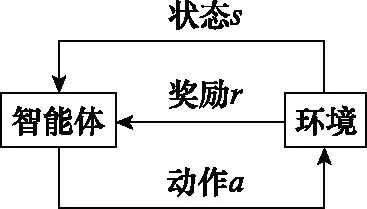
图1 RL基本框架Fig.1 Basic framework of RL
在目前的RL问题中,都是采用MDP来描述RL任务。MDP表示为一个五元组=〈,,,,〉,其中:是状态空间;是动作空间;:××→[0,1]是智能体在状态∈下采取动作∈转移到下一个状态′∈的概率分布;:×→是智能体在状态下采取动作转移到下一个状态′所得到的环境反馈的即时奖励;是折扣因子,∈(0,1],用于平衡瞬时奖励和长期奖励对总奖励的影响。
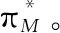
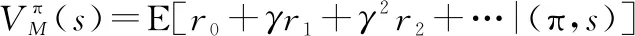
(1)
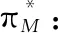
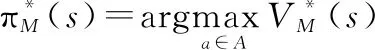
(2)
与状态值函数类似,每个策略还关联一个在状态和动作上定义的函数,用于评估“状态-动作”对的表现,表示为
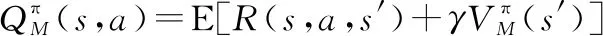
(3)
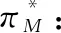
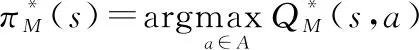
(4)
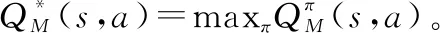
上述两种方法都是基于值函数(value based,VB)的RL方法,其中的经典算法有Q-learning、Sarsa等。与上述方法不同,基于策略梯度(policy pradient,PG)的方法用参数化后的策略来替代函数,再用梯度下降方法来近似求解最优策略。这类RL方法中的经典算法有PG、确定性PG(deterministic PG, DPG)。
1.2 DRL
传统RL方法常会遭遇“维度灾难”,即状态和动作空间有时候会非常复杂,×的维度过于庞大。比如Q-learning,通过将“状态-动作”对的值存入表格,读取表格数据来进行学习。一旦×的维度过大,表格的规模也会相应增大,算法迭代收敛的时间就会非常长,甚至无法收敛。除此之外,还有学习速度慢、奖励稀疏和泛化性差等问题。
DRL通过利用深度神经网络近似值函数和策略,以解决高维度状态和动作空间的问题。深度Q网络(deep Q-network,DQN)是一种经典的基于值函数的DRL方法,用神经网络近似值函数,而且不再用表格去存储值,取而代之的是用经验回放池(experience replay buffer,ERB)存储智能体与环境交互后的经验单元〈,,,′〉,以便智能体通过从ERB中采样的方式训练和更新神经网络参数。
VB方法的缺点在于难以解决连续动作空间的问题,PG方法则没有这方面的困扰。具有代表性的方法如深度DPG (deep DPG, DDPG)。其基于行动者-评论者(actor-critic,AC)框架,包含4个神经网络:Actor当前网络负责策略网络参数的迭代更行,根据当前状态选择动作,与环境交互生成下一个状态′和奖励;Actor目标网络定期复制网络参数,根据从经验池采样的下一状态′来选择下一动作′;Critic当前网络负责价值网络参数的更新,用于计算当前的值;Critic目标网络定期复制网络参数,计算目标值。除了DDPG,还有异步优势行动者-评论者(asynchronous advantage actor-critic,A3C)算法和近端策略优化(proximal policy optimization,PPO)等算法。
1.3 PR
DRL虽然在一定程度上解决了高维度状态和动作空间的问题,但是其在解决两个相似问题的时候,依然需要从零训练,学习速度慢、资源消耗大和难以复用的问题仍然存在。比如现有两个RL问题,表示为=〈,,,,〉和=〈,,,,〉,这两个问题之间的差异仅仅在于奖励函数。然而状态值函数()和函数(,)高度依赖MDP,这意味着,无论是基于值的方法还是基于策略的方法,只要问题稍稍改变,()和(,)等过去的知识都不再适用,之前的学习结果就会失效,而重新训练的代价却是巨大的。对于此类RL问题,高昂的训练代价和事倍功半的效率的缺陷日益突出,这加速了将TL方法应用在RL中的进程。
PR作为一种可以迁移RL训练结果的TL方法,通过重用过去的经验知识来加速新任务的学习,很大程度上解决了上述RL面临的问题。
为了便于说明和理解,将MDP等同于领域、任务或环境等概念。
PR的雏形源于文献[17],其所提出的方法基于行为迁移(behavior transfer,BT),通过将学习到的值函数从一个任务转移到另一个相似的任务来加速学习。将给定的任务1的初始策略定义为
(,,,,,)⟹
(5)
此策略从开始。则使用作为与任务1相似的任务2的初始策略,来学习任务2的最优策略:
(,,,,,π)⟹
(6)
这种方法需要对值函数进行转换,存在一定的局限性,但是对后续PR方法的发展起到很大的启发作用。
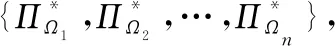
(7)
式中:,分别表示最大episode数、每个episode中的最大步数;,表示第个episode中第步智能体接收的瞬时奖励。
PR过程中,智能体与环境的交互过程如图2所示,其中红色虚线圆圈中的MDP元素可能会在源和目标任务之间发生变化。

图2 智能体与环境交互过程Fig.2 Process of interaction between agent and environment
2 任务间映射的方法
在介绍PR的方法之前,首先需要明确:PR效果的好坏很大程度上决定于源任务和目标任务之间的相似性。然而拥有完全相同的状态空间和动作空间的任务过于理想化,因而研究如何准确地进行源任务和目标任务之间的映射也是PR中的热门方向。
早期工作中,文献[19]假设目标任务中的动作和状态在源任务种存在唯一对应的关系,如图3所示。其中,分别是状态和动作上的映射函数,是源任务向目标任务映射值的函数。在此基础上,文献[20]将手动设置的专家建议作为一种离线知识在源任务和目标任务之间传递,这个专家建议依据值的大小给动作进行排名,以便智能体在目标任务中选择更好的动作。然而以上两种映射方法最大的问题在于默认了目标任务中的状态和动作的映射在源任务中是唯一的,这显然是不切实际的。同时,这种映射需要人工去完成,不具有通用性。因此,文献[21-23]的工作是研究如何让智能体自动学习映射函数,将状态表示分为特定于智能体和特定于任务,文献[21]和文献[22]在上学习映射函数并用该映射来设计即时奖励。该方法的好处是从上映射的状态空间可以同时用于具有不同动作空间但共享相似的状态空间的智能体上。
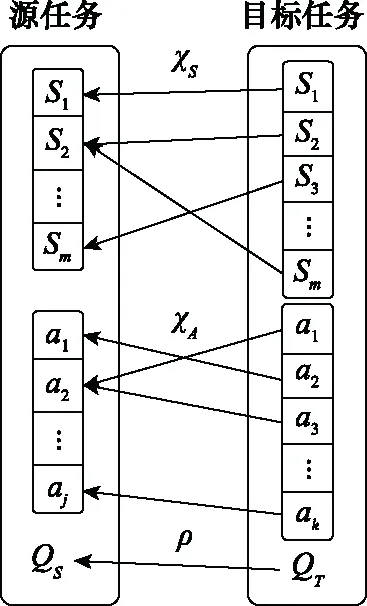
图3 源和目标任务间的映射Fig.3 Mapping between source and target tasks

总而言之,当前任务间映射的工作都基于源和目标任务之间存在一对一的映射这种假设。所映射的内容包括状态、函数或转移函数。这些映射的知识除了能够直接应用在目标任务上,还能够作为额外奖励或最小化的损失函数,以这种形式来引导智能体在目标任务中的学习。表1总结了主要的任务间映射方法。

表1 任务间映射方法总结
3 PR的分类
本文从是否基于策略结构的角度将目前存在的PR方法分为策略重构、奖励设计、问题转换和相似性度量等方面。但是在部分RL问题中,解决方案往往结合了多种PR方法,以取得更好的效果。下面将分别从这几个方面系统地介绍和分析PR方法。
3.1 策略重构类
在改变策略结构的前提下,根据改变策略结构方法的不同,PR方法又可分为外部协助、概率探索和策略蒸馏/整合等方面。
3.1.1 外部协助
在完成重用过去的策略这项工作时,只要在可接受的范围内,外部协助往往能够在促进学习目标任务方面表现出不错的效果。该外部协助可能来自不同的源头,具有不同的质量,可能来自人类专家、专家演示以及近似最优或次优的专家策略等。总的来说,这些外部协助都是依靠人类来完成的。大部分这种结合外部协助的PR方法都是针对特定的目标域而言,即源任务和目标任务是相同的。当然也有针对不同目标域的工作,如文献[31]在针对转移函数不同的任务时,通过偏差修正的方法来使智能体尽量不偏离专家策略,以此来保证重用的有效性。
文献[32]提出了一种利用人力为每个状态都绑定一个策略来构成一个称为“提示”的二元组〈π,〉的空间提示PR方法。这相当于为每个状态都打上标签,当智能体处于某个状态时,就使用对应的策略,这样能够保证每个提示可以解决一个任务。显然,当状态空间过大时,为每个状态都指定一个策略是不现实的。作者考虑到这点,将绑定了策略的状态作为参考状态(reference state,RS),用一个变量reach来估计策略在其参考状态周围的表现。将reach与每个提示联系起来,综合考虑当前状态(current state,CS)与参考状态之间的距离和策略的表现来相应地增加reach的值,再依据reach的大小来选择提示,该文中用曼哈顿距离作为度量reach的标准:
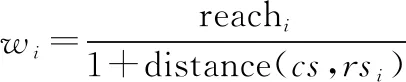
(8)
在状态空间定义的其他度量均可。
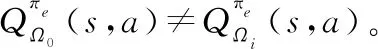
专家演示是一种通过利用提供的演示进行有效的探索来帮助智能体学习的方法。就目前来说,专家演示在利用外部协助的PR方法上应用得最为广泛,发展得也最为迅速。其主要原因是这种方式直接简便、效果显著。根据何时将演示用于知识迁移,该类方法可以分为离线方法、在线方法和在线离线相结合。离线方法是在应用专家演示之前对RL中的元素进行预训练,如值函数()和策略。Kurenkov 等人提出了在智能体学习的过程中重用专家演示这种离线知识,使其快速实现高性能的方法。文献[36]使用预训练后的值函数加速了DDPG算法的学习过程,并在理论上论证了他们方法的可行性。Silver等人在著名的AlphaGo项目中用预先训练的策略选择动作,来帮助其击败人类顶级围棋选手。不同于文献[36],文献[37]用演示来初始化值函数或策略,Schaal等人[38]的工作则用演示来初始化任务的动态模型。这些方法虽然在一定程度上加快了收敛,但是这一切都是建立在人类能够提供准确的经验的基础上,也就是说这些专家演示本身未必最优,并且预训练的过程可能漫长和繁杂,从总的学习过程来看,该方法并没有在学习时间上有较大的缩减。对于在线学习方法,则是抛弃了预训练的过程,将专家演示直接用于RL阶段,使智能体的行为偏向于有利的探索。然而当不能保证演示的质量的时候,学习的效果可能不尽如人意。文献[40]利用RL提供的理论保证,通过专家演示和奖励设计的过程来加速学习。这种方法的优势在于利用人类的输入的同时不会对演示的最优性做出错误的假设。除此之外,该方法需要的演示更少,对演示的次优具有更强的鲁棒性。除此之外,现在的很多研究都是将离线预培训和在线学习的方法结合起来,如Nair等人的工作建立在DDPG框架和事后经验回放(hindsight experience buffer,HEB)上,用DDPG框架来从演示中学习。该方法还通过利用行为克隆损失(behavior cloning loss,BCL)解决了演示次优的问题,对具有较高值的演示动作进行损失惩罚:
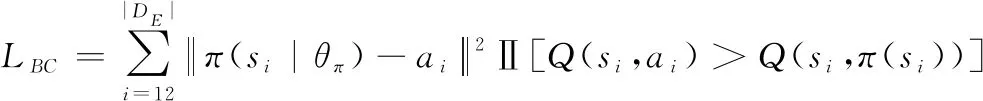
(9)
式中:Ⅱ[·]表示值损失的惩罚值;||是专家演示的模。
利用专家演示来加速学习面临着一些挑战,第一个是不完美的演示。这虽然是意料之中的情况,但是这种对环境有偏差的演示会对最终的学习效果造成一定的影响。目前针对不完美演示的解决方法包括改变目标函数。例如,文献[42]所提出的hinge-loss函数,允许少数违反(,())-max∈()(,)≥1性质的情况的发生。第二个挑战是过拟合。这个问题是由人类能够提供的专家演示总是有限的而导致的。因为在这些有限数量的演示当中,可能没有包含对目标域中出现的所有状态的指导。目前解决这种问题的方案包括使用熵正则化目标来鼓励智能体的探索。一般来说,专家演示可以通过离线预训练和在线学习来更好地初始化目标任务的学习以及实现有效的探索。但是如何使用次优、有限的专家演示加速学习,会是PR方法中的一个重要研究方向。
312 概率探索
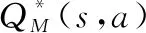
鉴于以上两个缺陷,Fernández 等人提出了一种在重用策略库的过程中同时增加探索的动作选择策略π-reuse,该策略库包含过去任务的策略。他们在学习的过程中逐渐降低重用过去策略的概率,相应的在增大的那部分概率中使用-greedy探索策略去探索目标任务,公式化表达如下:

(10)
式中:,分别表示过去的策略和正在学的新策略。这种方法能保证智能体在学习最优目标策略的时候能够充分探索,避免收敛到次优策略。同时还使用一个参数封装探索策略的所有参数,然后用该值来衡量所重用策略的有用性,再依此判断是否要将该策略放入策略库中。作者定义了最有用的重用策略。

=argmax(),=1,2,…,
(11)
这种方法为PR中的概率探索方法的后续相关研究提供了思路。但这种方法有一个限制,就是要经常性地评估,即每个专家策略对目标任务的期望回报。改进前的算法时间复杂度为(log),改进后为(),这无疑增加了算法的复杂度。另外,虽然允许单个目标状态在任务之间是不同的,但是要求,和都不变,这种限制过于苛刻。文献[46]克服了这种严格的限制,通过状态映射和动作映射::→和:→,将转换为可以在目标任务中执行的新策略:
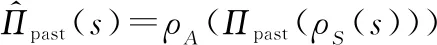
(12)
但是这种任务映射一方面需要人工定义,当状态空间和动作空间过大时,人工的耗费难以接受;另一方面,这种任务映射不具有通用性。比如说,对于3个任务=〈,,,,〉,=〈,,,,〉和=〈,,,,〉,,是任务1,2之间的映射组,则其只适用于任务1,2之间,将其用于任务1,3或者任务2,3就行不通。
李学俊等人将上述提到的概率探索方法应用到RoboCup 2D Keepaway的高层抢球动作决策中,通过将4v3任务的策略迁移到5v4任务的学习中,缩短了训练的时间,并且相较于普通的RL方法能够更快地收敛到令人满意的策略。
文献[48]提出了一种建立随机抽象策略来概括过去知识的方法。这种方法将源任务之前所有的解决方案归纳为单个抽象策略,该策略以抽象后的状态和动作的关系∑=∪∪表示,然后在新任务的学习过程中使用,以便让智能体在学习的早期就能表现出较好的效果。除此之外,文献[48]还提出了一种基于PR的Q学习(PR Q-learning,PRQL)算法的通用框架,允许学习者通过协调利用过去的经验、随机探索和利用在新任务学习过程中获得的新知识来表现出更适当的表现。
Narayan等人提出了一种通过使用类似-greedy的方法有概率地构建任务子空间并探索子空间生成子策略的方法。这种方法在一定程度上既保证了最后学出来的目标策略的最优性,又加速了学习的过程。当然,这种方法中不仅仅包括概率探索,还包括策略整合,这些将在后文中进行说明。
上述的探索策略都属于非定向探索,这种探索方法的特点是局部的,随机选择动作,比如说ε-greedy。相比之下,定向探索使用了全局信息来系统地确定要尝试的动作。文献[50]通过任务间映射结合可证明有效的延迟Q学习(delayed Q-learning,DQL)算法分析动作值的迁移,表达式如下:

(13)
式中:是任务间映射函数;是领域。该算法使用定向探索策略“不确定行为优先探索(optimism in the face of uncertainty,OFU)”在目标任务中学习更快,同时可以避免最优性的损失,即“正迁移”。但该方法有一个缺陷是:如果不解决两个任务,就没有通用的方法来获得任务之间适合的任务间映射。OFU定向探索策略的工作示意图如图4所示。
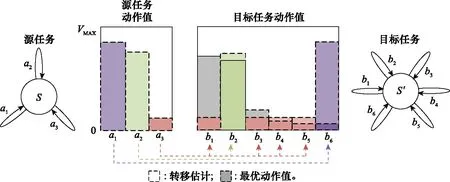
图4 OFU定向策略工作示意图Fig.4 Work diagram of OFU directional policy
3.1.3 策略蒸馏/整合
对于重用策略,研究人员首先想到的就是直接重用源策略(值),但是这种方法的弊端在前文中已经说明了:容易导致负迁移。为了剔除源策略中不适用于目标任务的部分,文献[43]只使用在相似问题中学到的策略的一部分,并在学习中保持策略的这部分不变。这种方法虽然提高了学习的速度,但是牺牲了策略的最优性。
假设有一系列状态空间和动作空间相同,转移函数和奖励函数不同的任务。这类任务的特点是变化的范围是未知和无穷的,可以利用学习策略中的共同结构来加速目标策略的学习。文献[54]提出了一种利用神经网络拟合一个概率模型的采样轨迹去学习策略空间结构的增量学习框架(incremental learning of policy space structure, ILPSS)。该轨迹用成功(“+”)或失败(“-”) 来标记是否到达目标状态,在后续的学习中只重用成功的轨迹。并将学习到的策略片段分配给概率模型当作一个“选项”,在之后的任务中用来生成更多的采样轨迹,具体流程如图5所示。
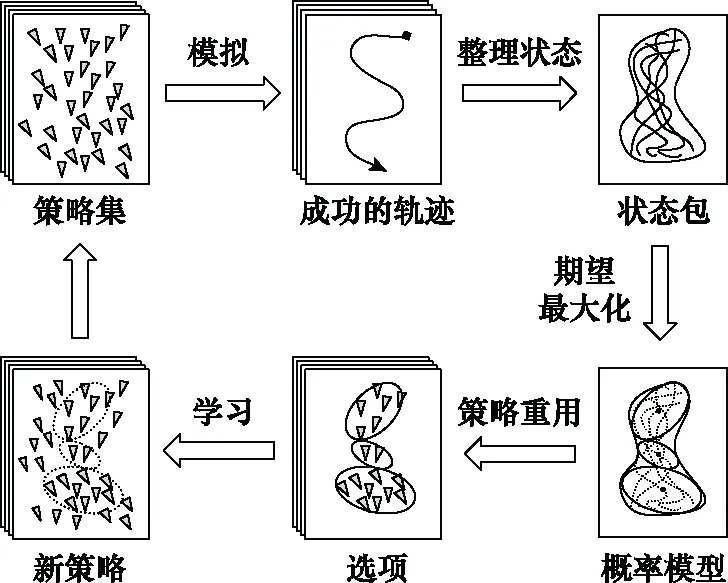
图5 ILPSS工作流程图Fig.5 Work flow chart of ILPSS
Rusu等人提出了一种根据专家网络和学生网络值的误差来确定值的回归目标函数,来使学生网络逼近专家网络的多任务PR方法,如图6所示,可以将多个任务最优策略整合到单个策略中,通过重用整合后的单个策略来达到加速学习的目的。但是当任务的参数规模和状态空间庞大的时候,需要消耗大量的计算去训练多任务策略网络。Yin等人提出了一种使用特定任务的高层次卷积特征作为多任务策略网络输入的策略蒸馏框架,并利用一个称作“分层优先经验重放”的采样框架有选择性地从每个任务的经验回放池选择经验放到神经网络上学习。文献[57]提出了一种在一组相关源任务上训练单个策略网络并将其重用在新任务中的“Actor-Mimic”方法。这种方法虽然能够加速新任务的学习,但是必须要在源任务和新任务之间具有一定相似性的情况下才能实现,因为任务间的相似性度量方法直接影响着PR的效果。另外,上面所提到的几种策略蒸馏方法都有一个共同的问题:同时训练多项任务会对单个任务的表现产生负面影响。这种负面影响可能来自其他任务的梯度,在极端情况下,一个任务甚至可能支配其他的任务。为了抵消这种负面的影响,Teh等人让每个源任务单独训练并将单个任务中获得的知识蒸馏到共享策略中,然后再由共享策略提取出共同的结构重用到其他的任务中,如图7所示。学习过程就是最大化一个联合目标函数的过程,其中联合目标函数为
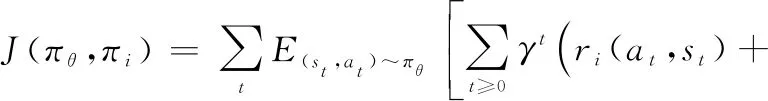
(14)
式中:是共享策略,是单个源策略;和是熵正则化因子。这种方法虽然消除了多任务训练对单任务训练所产生的影响,但是其在将单个任务中的知识蒸馏到共享策略中以及将共享策略中提取出的共同结构重用到其他任务的过程中增加了计算量。
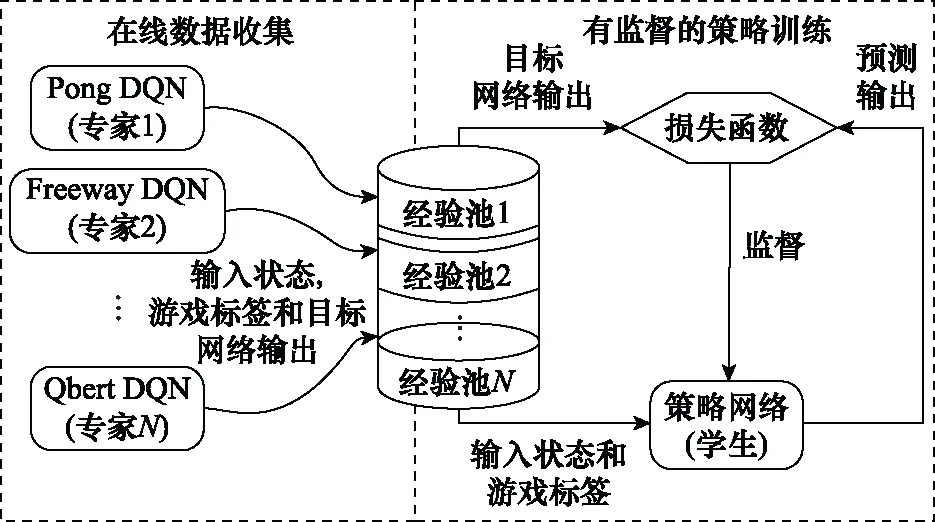
图6 多任务策略蒸馏Fig.6 Multi-task policy distillation
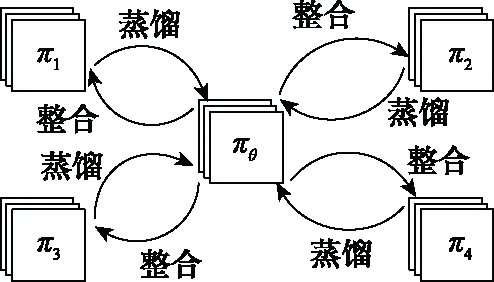
图7 共享策略工作过程Fig.7 Working process of shared policy
国内学者在这方面也有类似的研究。常田等人提出了随机集成策略迁移(stochastic ensemble policy transfer, SEPT)方法。该方法取消了在源策略库中每次选择一个策略的方式,取而代之的是利用终止概率计算出源策略的概率权重,再依据概率权重从策略库中集成出专家策略。最后通过策略蒸馏的方式将专家策略迁移到目标任务上去。这种方法避免了估计源策略在目标任务上的性能的不可靠性和度量目标任务间的相似性时所带来的误差。
文献[48]则换了一种思路,使用贝叶斯变更点检测算法寻找环境发生变化的位置,以此变更点为起点向后扩展步构造一个子空间并将其视为子任务。然后将在子任务探索得到的子策略与源策略整合为一个完整策略去解决目标任务。为了解决只在子任务中探索而造成的次优问题,使用了类似-greedy的方法,即在目标任务中探索的时候以一定的概率强制建立子空间(不管此处是否为变更点),这样目标任务中的其他状态也能够被探索到,因而最后学出来的策略是最优的。无论是重用完整的源策略还是部分源策略,抑或是将多个源策略蒸馏、整合为一个最优的源策略,这些从策略结构出发的方法都面临着一个共同的问题:源任务和目标任务之间需要具有极高的相似性。即使通过借助外部的帮助,或者增加概率去探索目标任务的未知领域来减缓收敛到次优策略的情况,但这些方法自身也存在着协助有限、次优或者增加探索而导致的学习时间过长等问题。如何使策略重构得更加契合目标任务是此类PR方法的核心问题。表2总结分析了具有代表性的策略重构类的PR方法。

表2 策略重构类方法总结
3.2 奖励设计类
奖励设计是另一种通过定义策略之间的相似性或从源策略去定义目标任务策略的方式去加速RL速度的方法。智能体除了学习环境反馈中的奖励外,还额外学习一个包含了先验知识的奖励设计函数:××→来生成辅助奖励,给予智能体在有益状态时以更高的奖励来加速收敛。奖励函数的改变将导致任务的改变:
=(,,,,)→=(,,,,)
(15)
式中:=+。智能体将在新的MDP中学习目标策略。
文献[61]提出了用定义在状态空间上的势函数的差值作为奖励设计函数的方法基于势函数的奖励设计(potential based reward shaping,PBRS):
(,,′)=(′)-()
(16)
在此基础上,文献[62]提出了将其扩展到基于势函数的状态-动作对建议(potential based state-action advice,PBA)的方法:
(,,′,′)=(′,′)-(,)
(17)
这个方法的一个限制是需要遵循策略来学习,如式(17)所示,′是通过遵循策略转换到下一个状态′时要执行的动作。上述的方法都是基于静态的势函数,文献[63]提出了一种将状态和时间结合起来的基于动态势函数(dynamic potential based,DPB)的方法:
(,,′,′)=(′,′)-(,)
(18)
证明了这种动态方法依然保证了策略的不变性:
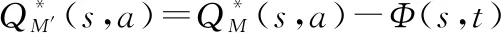
(19)
式中:是当前时间。在此基础上,Harutyunyan等人又提出了一种能将任何先验知识作为额外奖励加入基于动态势函数的建议(dynamic potential based advice,DPBA)的方法。基本原理是:给定来自先验知识的任意额外奖励函数,其必须满足以下条件才可作为额外奖励添加到原始即时函数上:
(′,′)-(,)=(,)=(,)
(20)
如果是动态的,则其贝尔曼方程是:
(,)=(,)+(′,′)
(21)
由此可知奖励设计函数(,)是(,)的否定:
(,)=(′,′)-(,)=-(,)
(22)
故可以将的否定作为奖励函数来训练额外的状态-动作值函数和策略,的更新方式如下:
(,)←(,)+()
(23)
因此,动态奖励设计函数为
(,)=+1(′,′)-(,)
(24)
DPBA方法最大的优点在于提供了一个能将任意先验知识作为额外奖励的框架,这大大提高了奖励设计类方法在PR上的通用性。
文献[65]提出了一种使用奖励设计迁移策略(policy transfer using reward shaping,PTS):在使用映射函数,完成了源任务和目标任务之间状态和动作映射工作的基础上,利用奖励设计将专家策略从源任务重用在目标任务上,那么额外的奖励正好是被映射的状态和动作被源任务的专家策略采取的概率(((),()))。另一项工作则利用神经网络训练鉴别器去区分样本是来自专家策略还是目标策略,而鉴别器的损失被用来设计奖励函数以鼓励智能体去模仿专家策略。这种方法涉及到PR方法的两个方面:奖励设计和外部协助。文献[67]所做的工作中的其中一项是通过定义一个设计奖励函数强度的参数来针对不同的目标任务调整奖励函数的大小。Zheng等人提出用外在奖励优化内在奖励并使用内外奖励的和去更新策略的方法:学习策略梯度的内在奖励(learning intrinsic rewards for policy gradient,LIRPG),基于该算法的智能体学习过程的抽象表示如图8所示。此方法的优点在于该算法适用于大部分的RL算法。
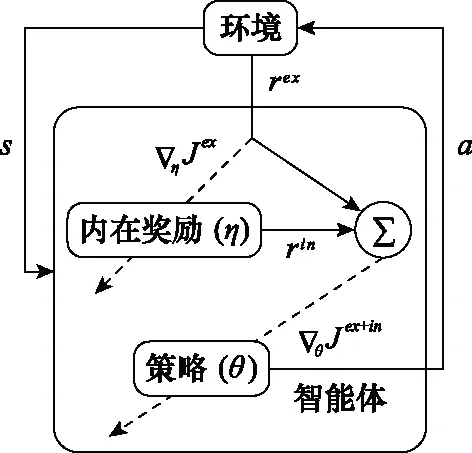
图8 LIRPG智能体学习过程的抽象表示Fig.8 Abstract representation of learning process of LIRPG agent
以上所述的工作都属于利用外在的知识来设计奖励函数,Marom等人转换了思路,考虑了额外的奖励源于自身的情况,提出了信念奖励设计(belief reward shaping,BRS)的概念,利用贝叶斯奖励设计框架来产生随着经验衰减的来自Critic网络自身的势值。
总的说来,奖励设计方法从基于状态和状态-动作值的静态势函数,到加入时间变化过程的动态势函数,再到能将任意先验知识作为辅助奖励添加到原始奖励函数的框架,奖励设计方法已被应用到实际上生活中的诸多场景,如训练机器人、口语对话系统等。如今,将奖励设计应用在PR的方法还不是很成熟,主要的问题在于构造的奖励函数并不能够完美契合目标任务,从而导致智能体在学习目标策略的过程中采取一些投机取巧方式的情况发生,或者收敛到次优策略。表3对比分析了奖励设计类的PR方法。

表3 奖励设计类方法总结
3.3 问题转换类
PR的核心问题是源策略的选择问题,智能体能否以最快的速度寻找到目标任务的最优策略一定程度上取决于所选择的源策略契合目标任务的程度。因此,关于PR的有些工作聚焦于将源策略的选择问题转化为其他较易解决的问题。
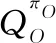
(25)
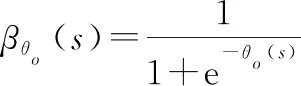
(26)
由于该方法只学习了源策略的选项间策略,容易导致次优问题,为了避免这个问题,用原始策略来扩展源策略库,然而这种方法需要手动添加原始策略,在很大程度上限制了其通用性,不能用于解决连续动作空间问题。为了解决文献[73]中存在的问题,文献[74]提出了一种由Agent模块和Option模块两个主要模块组成的策略迁移框架(policy transfer framework,PTF),如图9所示。其中,Agent模块用于在Option模块的指导下学习目标策略,Option模块用于学习选择对Agent有用的源策略。同时利用一个加权因子(,)控制从源策略中重用策略的程度,其中(,)定义为
(,)=()(1-(,|))
(27)
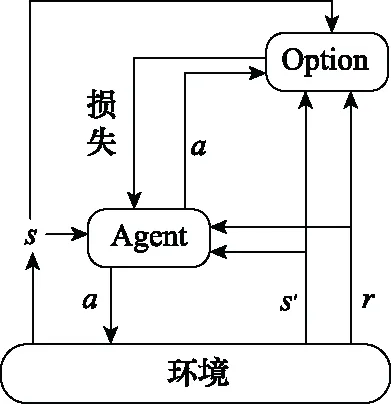
图9 PTFFig.9 PTF
这个框架能够与大多数RL算法结合,在离散和连续动作空间中都能应用。然而,相较之前的方法,这种方法新增了两个网络用于控制Agent何时选择源策略以及重用程度,这必然会增加算法的复杂度和计算量。
Yang等人提出了一种基于多智能体选项的策略迁移框架(multiagent option-based policy transfer, MAOPT)来提高多智能体选项的效率。该框架通过将多智能体策略迁移建模为选项学习问题来学习为每个智能体提供建议以及何时终止建议。该方法在离散和连续状态空间问题上都表现良好。
问题转化类的方法旨在将难以解决的源策略选择问题转化为其他易解决或相对熟悉的领域问题。但这种问题转换的前提是存在适合的转换模型,不准确的转换反而会导致次优问题的出现。
3.4 相似性度量类
目前已经有很多关于PR的工作,但是大多数方法都依赖于源任务和目标任务极度相似的假设。然而这种假设在实践过程中并不一定能够满足。如果源任务和目标任务无关,PR将会导致学习速度变慢,乃至在目标任务中的表现很差。因此,定义源任务和目标任务之间的相似性来选择最优的源策略是必要的。现有的工作中,度量源和目标任务的MDP之间相似性的方法居多,也有度量策略之间相似性的方法。
Fernández等人利用距离度量两个源任务最优策略的相似性来选择重用最有用的源策略,定义和证明了此种度量方法。

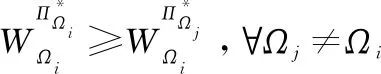
(28)
因而用距离度量来定义策略在策略中的作用为
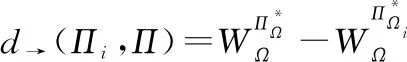
(29)
由于该方法需要比较应用两个策略后的结果来判断哪个策略更适合用来重用,计算量较大,不适用于大规模的PR场景。
相较于度量策略相似性的工作,更多的工作集中在度量任务MDP之间的相似性。在早期的工作中,文献[76-78]使用了一种交互模拟形式的度量方法,该方法将MDP之间的差异进行了量化。然而这个工作需要手动定义任务之间的度量,并且只适用于离散状态空间以及需要巨大的计算量。文献[19]提出的方法是半自动的,要求人类用户为算法定义相关的源任务和目标任务之间的关系,再用算法来比较源和目标任务之间的相似性。显然,为了实现完全自主的PR方法,智能体必须能够选择与目标任务相关的源任务以及学习源和目标任务之间的关系,如任务间映射。Taylor和Ammar等人将工作聚焦于如何使智能体选择与目标任务相关的源任务。而这正是重用先验知识成功与否的关键。
朱斐等人针对不稳定环境下的RL问题,提出了一种基于公式集的策略搜索算法。该方法用MDP分布表示不稳定的环境,利用自模拟度量构造的MDP分布之间的距离度量公式作为标准,并结合小公式集的构造方法,将求解的策略在不同的MDP分布之间进行迁移。从理论上证明了迁移之后的策略的最优性边界。这种方法为在不稳定环境下的RL问题中进行PR提供了思路,但是该算法中MDP分布之间的距离计算公式并不适用于庞大的状态空间和连续状态空间的问题。
文献[81]提出了一种从通过智能体与环境交互收集的样本中估计源和目标任务之间相似性的度量方法,该方法能够捕获和聚类具有多重差异的多维数据集之间的动态相似性,包括不同的奖励函数和转移函数。此方法的基本原理是:首先使用受限玻尔兹曼机(restricted Boltzmann machine,RBM)模型对源任务中收集的数据进行建模,产生一组能够描述源MDP的相关的和信息性的特征。然后在目标任务上测试这些特征,以此评估MDP的相似性。这种方法实现了智能体自主学习度量源和目标任务之间相似性并依此选择合适的源策略进行PR的工作。但是这种方法一个最主要的缺陷是可能会导致经验过拟合的问题,即在给定特定MDP参数的情况下效果良好,而在使用其他参数或在不同的MDP上时效果难以达到预期。
Wang等人将工作的重点放在了多任务迁移上,提出了一种称为“启发式自适应PR”的框架。这种框架通过快速选择最合适的策略及其有用的部分,来促进存储在策略库中的源策略的有效重用。同时,通过使用KL散度衡量策略之间的差异来筛选策略,保证了策略的质量,并完成策略库的重建。该方法有效避免了重用源策略中不相关的部分而导致的负迁移,并在每个回合中将策略库中的“不良策略”移除以保证策略库的健壮性和有效性。美中不足的是,该方法并不适用于连续动作空间问题。
Song等人的工作主要是提出了两个度量有限个MDP之间距离的方法。第一个方法是Hausdorff度量方法,用于利用Hausdorff矩阵度量不同任务状态集之间的距离。具体定义如下。
给定两个MDP:=〈,,,,〉和=〈,,,,〉,其Hausdorff距离为
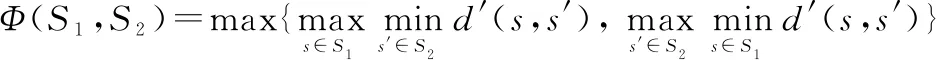
(30)
式中:′为两个状态之间的距离。这种方法存在错误度量的问题:如果相似的多维数据集中至少存在一个异常值,可能会被错误地视为不相似的数据集。因此又提出了第二个方法:Kantorovich度量方法,该方法利用Kantorovich矩阵度量概率分布之间的距离。具体定义如下。
给定两个MDP:=〈,,,,〉和=〈,,,,〉,其Kantorovich距离为
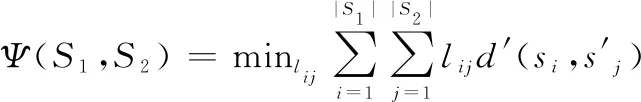
(31)
使用这种方法时,即使存在异常值,对总数据集的影响也不大。与此工作类似,文献[48]同样是计算概率分布之间的距离,它基于Jensen-Shannon距离(Jensen-Shannon distance,JSD)定义了一个轻量级的度量来计算共享相同状态-动作的问题中的任务相似性。JSD定义为Jensen-Shannon散度的平方根:
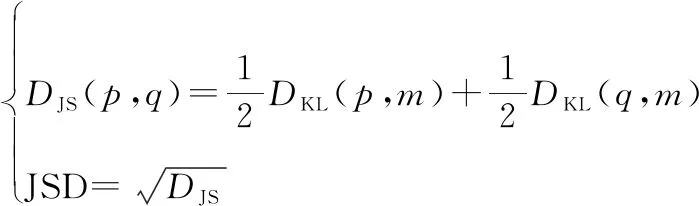
(32)
式中:是KL散度;和是源任务和目标任务中相应状态-动作对的分布;=(+)2。
相似性度量类方法的目标只有一个:为目标任务选择最好的源策略进行重用。现有的方法五花八门,没有统一的度量标准,该方向未来的工作可能会着力于寻找一个统一的度量标准。表4总结了目前的相似性度量类方法。
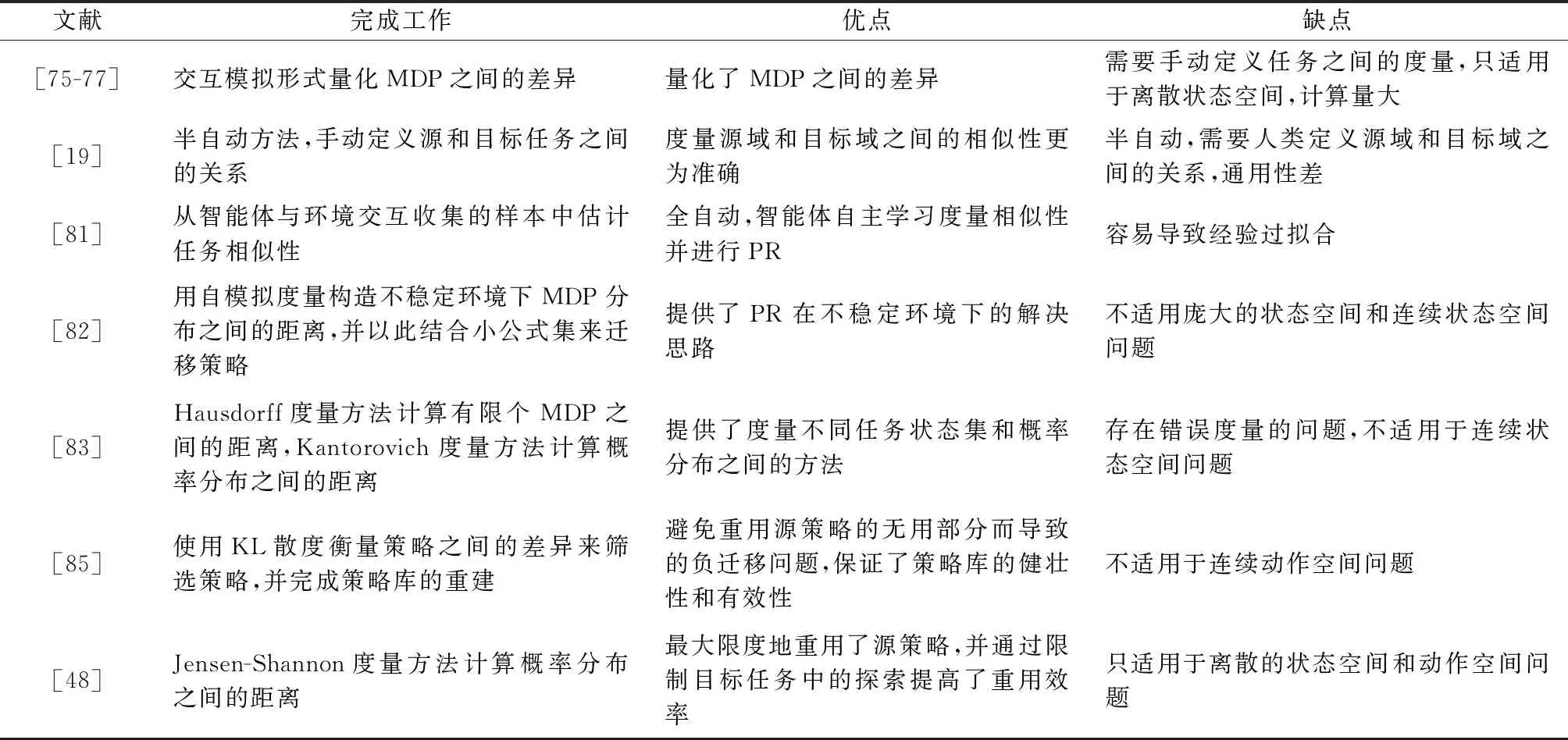
表4 相似性度量类方法总结
以上分析的几类方法,有效地加速了RL算法的收敛,但在一定程度上也提升了算法的复杂度和计算量。为方便了解和对比,分析、对比了这几类方法的优缺点,如表5所示。

表5 PR方法对比
4 DRL中的PR
近些年随着DL的飞速发展,DL和RL相结合的方法DRL在一定程度上解决了以前传统RL方法难以解决的问题。适用于传统RL算法的PR方法,在更换了RL框架的情况下,依然适用。在上面介绍的各类PR方法中,某些方法不仅适用于传统RL框架,同样适用于DRL框架。
文献[39]将专家演示这类依靠外部协助的PR方法应用在最经典的DRL算法DQN上,称为学习演示的深度Q学习。另一项基于DQN算法的工作是文献[65],其工作与奖励设计技术关系密切,基于一组专家演示来构建势函数,并且状态-动作对的势值由给定状态-动作对和专家经验之间的最高相似性来度量,这种额外奖励鼓励智能体做出类似专家的动作。文献[55-56]提出的策略蒸馏方法同样是基于DQN算法框架的。其中文献[55]的工作是利用专家网络和学生网络值的误差来使得学生网络逼近专家网络从而进行多任务PR。而文献[56]的工作则是将特定任务的高层次卷积特征作为多任务策略网络的输入,再有选择地采样每个任务的经验放到神经网络上学习。
PR方法不仅仅应用到基于值函数框架的DRL中,也适用于基于策略梯度框架的DRL。文献[89]基于信任域策略优化(trust region policy optimization,TRPO)算法框架,提出了一种结合生成对抗网络(generative adversarial networks,GAN)和奖励设计函数-log(1-(,))的算法生成对抗模仿学习(generative adversarial imitation learning,GAIL)。该算法可以利用GAN的对抗训练直接显示地得到策略,更加高效。Kang等人提出的学习演示的策略优化(policy optimization from demonstration,POfD)算法扩展了GAIL,该算法基于TRPO和PPO,将GAN中的鉴别器奖励与环境奖励结合,训练智能体去获得最大化累积的环境奖励:
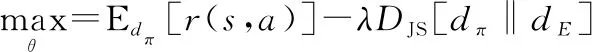
(33)
式中:和分别是当前策略和专家策略的占用度量,是由策略导出的状态-动作分布。
以上算法,无论是GAIL还是POfD,都属于on-policy的RL框架。文献[68]提出的学习演示的DDPG(DDPG from demonstrations,DDPGfD)算法则是off-policy的RL框架,该算法基于DDPG,指导智能体从专家演示中学习策略。另一项基于DDPG框架的工作是文献[40],与DDPGfD的不同在于智能体的功能通过行为克隆损失得到加强,鼓励其模仿所提供的演示行为。文献[58]提出的方法基于A3C框架,同时利用策略蒸馏提取多个教师策略网络中的经验并转移到学习策略网络以实现多任务PR。Schmitt等人做的工作与文献[58]类似,使用教师和学生策略网络之间的交叉熵来设计奖励,并设计了一个动态衰减系数来减轻奖励增加所带来的负面影响,从而使学生策略在迭代优化一定次数后能够独立于教师策略。
飞速发展的DRL算法已经能够面对高维的状态或动作空间的问题,但是面对相似问题需要从头学习的问题依然需要依靠PR方法来解决。表6总结了主流的应用了PR方法的DRL框架。

表6 PR方法中的DRL框架总结
5 多智能体场景
相对于单智能体而言,多智能体环境是非稳态的,多智能体RL(multi-agent RL,MARL)遵循随机博弈(stochastic game,SG)过程。对于MDP而言,其转移函数不仅与当前状态、当前动作以及下一个状态′有关,还与时间有关,因此更加复杂,更具有挑战性。
在多智能体环境中,传统的RL算法或多智能体算法没有过多关注对方的策略,仅仅只是聚焦于对手的行为,这类方法的弊端在于容易被对手的行为所误导,但是根据对手的策略来行动能够避免此问题。然而在多智能体环境中,对手的策略多且杂,如何快速地根据对手策略制定自己的策略正是MARL-PR算法所要解决的问题。文献[95]提出的贝叶斯PR(Bayesian PR,BPR),可以根据对手的策略来指定自己的策略,提出了一个当智能体面对未知任务时使用策略蒸馏来选择最优策略的框架。该框架使用了一个信念模型(),以奖励为标准来衡量当前的任务和过去已经解决的任务之间的相似程度,最优策略就是信念模型下期望奖励最大的策略。然而该信念模型存在光靠奖励难以准确区分对手的问题,文献[96]提出了一种方法深度BPR:用参数为的神经网络去近似对手的策略的修正信念模型,配合引入的对手模型同时去检测对手以达到精确检测的目的。如果检测发现对手用的是之前未用过的策略,则开始学习新策略并在学习完成后放入策略库。文献[97]提出的算法Bayes-Pepper结合了两个框架Pepper和BPR,该算法先从多智能体算法中获得随机的动作策略,然后计算可能的对手的信念,并随着交互的进行而更新,从而使智能体可以针对对手快速选择适当的策略。文献[99]将BPR扩展到对抗性设置,特别是扩展到从一种固定策略转换为另一种静态策略的对手。当Agent检测当前策略不是最优时,该扩展功能可以在线学习新模型。
然而以上方法都假定对手在一组平稳策略中随机改变其策略,在实践中,对手可以通过采用更高级的推理策略来表现出更复杂的行为,此时这些方法就难以打败这些复杂的对手。文献[100]提出一种贝叶斯心理策略理论(Bayesian theory of mind on policy, Bayes-ToMoP)方法,不仅能快速准确地检测到非平稳对手,而且还能检测到更复杂的对手,并据此计算出最佳对策。
相较于单智能体DRL算法,多智能体算法更加切合现实环境和需求。面对不稳定的环境,单智能体算法难以收敛,也不能通过改变智能体本身的策略去适应不稳定的动态环境。多智能体算法的提出在一定程度上缓解了这些问题。然而,随着智能体数量的增加,多智能体算法的联结动作空间大小爆炸性增长,而这带来的是庞大的计算量。除此之外,多智能体系统中各个智能体的任务存在差异,但彼此之间又存在耦合,相互影响,奖励设计比较困难,而这直接影响了学习到的策略的好坏。而且探索问题也是多智能体算法急需解决的问题之一。多智能体环境中,各智能体需要同时考虑自己对环境的探索和应对同伴策略变化进行的探索,而且各智能体的探索都可能影响同伴的策略,这使得学习的过程复杂且缓慢。PR方法的加入部分缓解了这些问题,但是现有的方法还不够成熟。接下来可以研究更加通用的PR方法,通过重用相似环境的源策略来更快地发现对手策略,加速探索过程和降低计算损耗。
6 应用
机器人学习领域一直是RL的重要研究方向,但一直存在实验代价过大的问题,比如机器人学习在复杂的山路进行作业的时候,经常存在损坏的风险。而在相似的地况进行作业时,从头学习不仅效率低,而且损耗大。文献[101]提出让不同机器人之间共享学习到的策略来进行协同训练的PR方法很大程度上缓解了这个问题。其方法是在DQN框架下实现多个机器人智能体之间的策略迁移,通过在一个经验池中共享演示和异步执行策略的更新。文献[102]则把注意力集中在机器人面临未知任务时的学习方法上,通过在所选的多个源任务上训练一个通用策略结合专家策略来让机器人更快地适应目标任务。
除了机器人领域,游戏也是PR广泛应用的领域。最典型的游戏应用就是AlphaGo。这是一款围棋游戏,先利用专家演示离线训练智能体,再通过学习用蒙特卡罗树搜索法来选择最优策略。在星际争霸这款实时战略游戏中也使用了PR。除此之外,OpenAI训练了一个击败了人类职业玩家的Dota2游戏智能体,其中也用到了PR的方法。文献[31]将PR应用在Minecraft上,文献[51-52]则在Atari上应用了PR方法。另外,在导航游戏和山地车游戏上也有应用。在这些通用平台上的应用且有不错的效果,足以说明PR的有效性。表7总结了常见的PR方法的应用场景。

表7 PR方法应用总结
7 总结及展望
本综述从是否基于策略重构的角度将目前RL中存在的PR方法进行分类并介绍。除此之外,还总结了在结构不同的任务之间的映射方法以及应用了PR的领域。本文提供了一个关于RL中PR方法的新的分类思路,希望能够为做此方面研究的人提供一点帮助。
依据现在RL中的PR研究进程,基于模型的PR方法会是未来的一个发展趋势。基于模型的方法能够结合大多数的RL算法,实现策略重构、奖励设计等方法的自动化,大大提高PR的效率和通用性。除此之外,任务的相似性度量方法现阶段良莠不齐,设计和制定一套通用高效的度量标准对于PR的发展也起到了至关重要的作用。另外,虽然PR能够较好地解决RL收敛速度慢、资源消耗大以及复用性的问题,但也提升了算法的复杂度和计算,如何在解决传统RL问题的基础上避免算法复杂度和计算的提高也是PR方法迫切需要解决的问题。最后,目前PR在多智能体内的研究进展缓慢,其主要原因在于多智能体场景的复杂性。然而多智能体场景更加贴近现实,优质的多智能体PR方法能够在很大程度上提高工业制造的效率。鉴于这个原因,相信多智能体PR会是未来的一大研究热点。
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24 01:14:34
速读·下旬(2021年11期)2021-10-12 01:10:43
中学生数理化·中考版(2021年3期)2021-07-22 07:41:30
新世纪智能(数学备考)(2020年9期)2021-01-04 00:25:12
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28 08:43:52
大东方(2019年12期)2019-10-20 13:12:49
小学生作文(低年级适用)(2019年5期)2019-07-26 00:45:10
读友·少年文学(清雅版)(2018年12期)2018-04-04 05:16:40
科学与财富(2017年22期)2017-09-10 13:20:02
商情(2017年1期)2017-03-22 16:56:36
