
基于机器学习的火山岩岩性智能识别及预测
2022-03-10 07:20邹正银王志章蒋庆平常天全王伟方
特种油气藏 2022年1期
刘 凯,邹正银,王志章,蒋庆平,常天全,王伟方,杨 笑,3
(1.中国石油新疆油田分公司,新疆 克拉玛依 834000;2.中国石油大学(北京)油气资源与探测国家重点实验室,北京 102249;3.中国石油长庆油田分公司,陕西 西安 710018)
0 引 言
1957年,中国火山岩油气藏在准噶尔盆地首次被成功发现,截至目前,已在11个含油气盆地中发现火山岩油气藏[1]。准确识别火山岩岩性特征是研究火山岩油藏的重要基础,但火山岩岩性复杂,矿物成分多变,测井响应特征不明显,岩性识别难度极大。SANYAL等[2]利用声波时差、中子测井曲线的响应特征识别岩性;谭伏霖等[3-4]鉴于取心样本有限,采取样本扩充法识别火山岩岩性;由于单一测井曲线很难准确识别岩性,罗德江[5]根据逐步分析法和fisher判别方法进行识别;程国建等[6]将粒子群优化算法(PSO)与最小二乘支持向量机相结合进行识别;鞠武等[7]利用有序聚类分析方法识别;范存辉等[8]利用深度神经网络结合测井资料进行识别;牟丹、Li等[9-10]基于最小二乘支持向量机识别。该文综合利用准噶尔盆地金龙2井区的取心、薄片、成像资料解释的岩性样本标定测井资料,通过交会图开展岩性特征分析,判断岩性与电性相关关系,形成测井和岩性标签的样本库,并随机将样本库分为训练集(占70%)和测试集(占30%)2个部分。结合机器学习中的决策树、随机森林、梯度提升树和贝叶斯算法,利用同一训练集建立4种火山岩岩性识别模型,并利用同一测试集评价这4种模型的稳定性,优选算法模型,实现利用常规测井曲线识别火山岩岩性。
1 原理方法
1.1 决策树算法
决策树是对实例进行分类描述的树形结构,由结点和有向边组成,也是属性与值之间的一种映射关系。根据特征选择不同算法,主要包括ID3算法、C4.5算法和CATR算法[11]。ID3算法是在原始决策树算法的基础上实现的,其特点是在结点上选择特征时采用信息增益。C4.5算法是对ID3算法的改进,其利用信息增益率来进行特征属性的选择,避免了偏向多值的特征属性。CATR算法使用基尼系数代替信息增益,基尼系数代表了模型的不纯度,基尼系数越小,不纯度越低。
1.2 随机森林算法
随机森林算法属于集成学习的一种。随机森林算法分配给每棵树的样本从数据集中随机抽取,抽取完后放回数据集中[12]。每抽取一次数据,就建立一个决策树模型,最后所有的决策树就形成了一片森林,通过投票决策的方式,确定最终的预测结果。该算法在决策树算法的基础上,引入2个不同的随机条件,第1次随机条件是从数据集中随机地抽取训练数据集,每抽取一次形成一棵决策树;第2次随机条件是从抽取的训练集中的数据特征属性集合n中随机选取S(S≤n)个特征属性集合。这2个随机条件使得该算法相比决策树具有更好的效果[13]。
1.3 梯度提升树算法
梯度提升树算法是一种迭代的回归决策树算法,由多棵决策树组成,将所有决策树的结论累加起来就是最终的结论[14]。该算法主要用于分类和回归2个方面。在各结点分支时,选择最小化均方差来判断结点分支[15]。
1.4 贝叶斯算法
贝叶斯算法根据已知的数据学习计算出先验概率,再根据条件独立性假设计算条件概率,最后计算后验概率,对未知数据集进行预测。缺点是建立在样本属性独立性假设的基础上,如果样本属性有关联,其效果较差[16]。
2 研究区实际应用
2.1 火山岩岩性常规测井响应特征
不同类型的火山岩由于其化学成分、矿物成分、物性特征等存在差异,导致其测井响应特征存在一些变化[17-23]。研究区火山碎屑岩类主要有火山角砾岩、熔结角砾岩;熔岩类主要有玄武岩、安山岩、英安岩、流纹岩(图1)。火山岩越致密电阻率越高,熔岩类的电阻率高于火山碎屑岩类,熔岩中英安岩裂缝发育较少,电阻率很高,安山岩、流纹岩和玄武岩等由于裂缝和气孔的影响导致电阻率偏低。从基性到酸性火山岩,放射性增加,基性玄武岩自然伽马小于26 API,中性安山岩在45 API左右,酸性英安岩和流纹岩大于65 API。火山角砾岩和熔结角砾岩存在较大的原生孔隙,中子值约为20%左右,是该区主要储层;安山岩由于裂缝发育,中子值约为17%;玄武岩由于发育杏仁构造,中子值高达25%,流纹岩和英安岩致密,中子值约为10%。从基性到酸性火山岩,密度逐渐变小,玄武岩为2.70 g/cm3左右,安山岩为2.54 g/cm3左右,流纹岩密度最低,火山碎屑岩的密度低于熔岩。火山碎屑岩的声波时差略高于熔岩,火山角砾岩和熔结角砾岩声波时差在65 μs/m左右,英安岩声波时差约为57 μs/m,玄武岩、流纹岩和安山岩声波时差约为60 μs/m。利用成像测井静态图并结合周围岩石电阻率变化可区分沉积岩和火成岩[24-25];利用FMI动态图可以识别火山碎屑岩和具有流纹构造的流纹岩;利用动态图和常规测井曲线可以识别英安岩、安山岩和不具流纹构造的流纹岩。
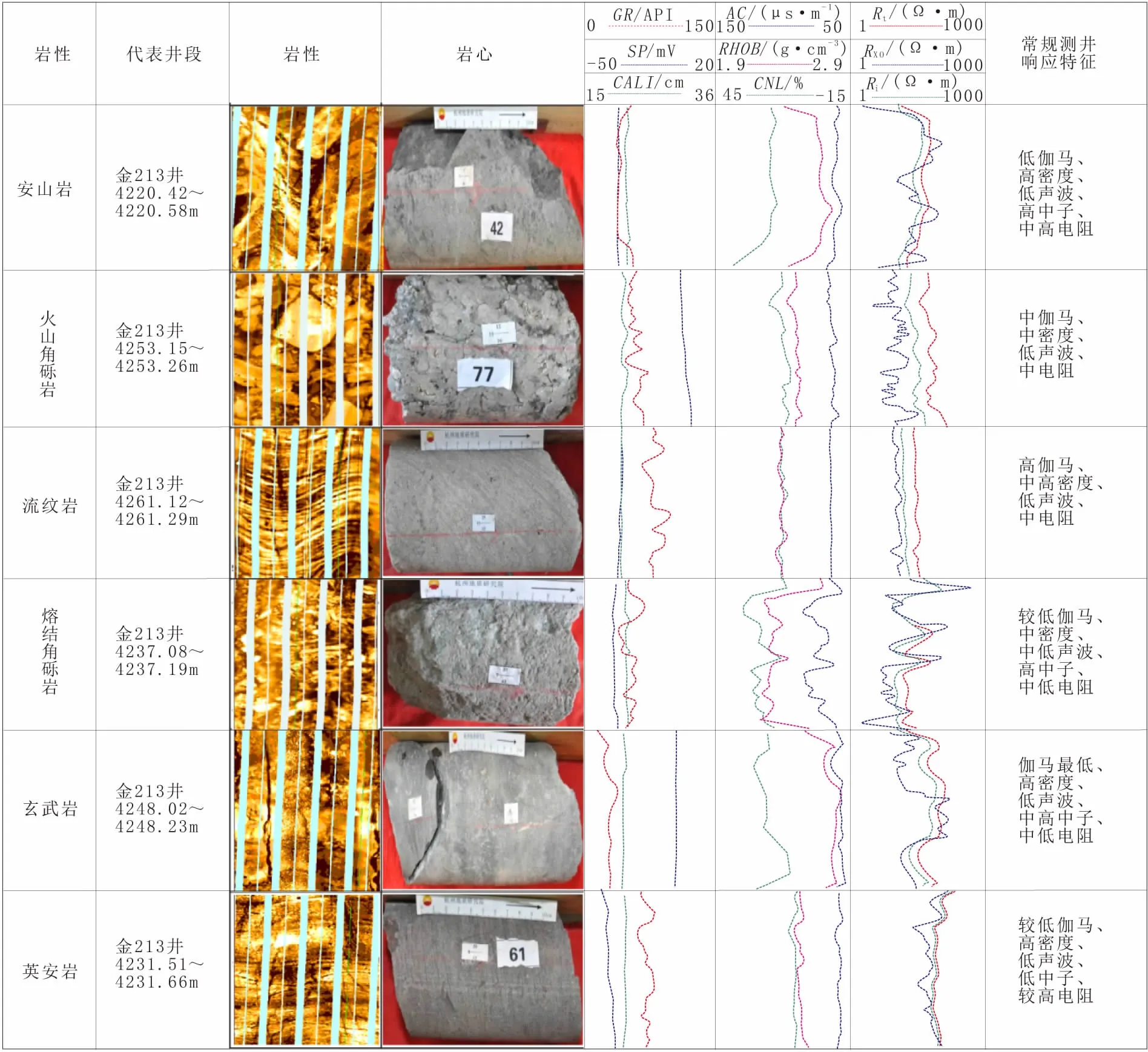
图1 火山岩测井响应特征
2.2 M-N交会图
以往的研究中,常采用密度与自然伽马等交会图分析不同岩性特征,提取敏感特征[26-32]。分析表明,此方法很难将各类岩性区分开。因此,应用中子、密度和声波3种孔隙度测井曲线,通过求解M、N值,进行交会图分析,旨在消除裂缝造成的孔隙度影响,更准确识别岩性(图2)。
(1)
(2)
式中:M为声波与密度交会图中流体点与骨架点连线的斜率,(μs·cm3)/(m·g);N为中子与密度交会图中流体点和骨架点连线的斜率,cm3/g;Δtf为声波时差测井的液体时差值,μs/m;Δt为声波时差测井值,μs/m;ρb为测井密度值,g/cm3;ρf为液体密度值,g/cm3;φNf为中子测井的液体值,%;φN为中子测井值,%。

图2 M-N交会图
2.3 机器学习岩性识别
利用机器学习建立岩性分类及预测模型,具体包括:样本库的建立、特征参数选择、测井特征数据的归一化、训练模型、评价模型以及岩性预测。
2.3.1 样本库建立
依据研究区5口井取心资料、测井数据和成像测井数据,分析测井数据与不同火山岩岩性的对应关系,生成样本空间。
2.3.2 特征参数选择
前文具体分析了不同火山岩岩性的测井响应特征,优选出岩性敏感的测井曲线,同时,根据2个新的特征值,即M和N,最终确定岩性敏感特征参数为:GR、N、Ri、M、CNL、DT、Rt、DEN,其占用的权重比依次为0.22、0.18、0.16、0.13、0.11、0.08、0.07、0.05。
2.3.3 测井数据归一化
由于岩性数据测量仪器不同,数值上会存在一定的系统偏差,因此,对测井数据需进行归一化处理。数据归一化处理可以消除量纲影响,降低不同测井仪器测量绝对值误差导致的影响,利于后期建立的模型对全区井段都能有很好的预测效果。因此,将选取的8种特征全部归一化到[0,1]中。对于GR、DT、DEN、CNL、M、N采用线性变量归一化处理,即:
(3)
式中:Y为测井曲线归一化结果;X为某一深度的某测井曲线值;Xmin为同一测井曲线的最小值;Xmax为同一测井曲线的最大值。
对于电阻Rt、Ri,采用先取对数,再归一化,即:
(4)
为准确获得特征参数最大值和最小值,避免一些极端值参与运算,干扰主体数据的归一化,采用累积概率曲线一次求导(斜率)的方法来获取特征的最大和最小值。
2.3.4 训练模型
在机器学习模型的训练过程中,为了使模型具有更好地泛化能力,需将数据集分割为训练集与测试集。根据准噶尔盆地金龙2区块的岩心数据,建立各类岩性样本库。各类岩性样本点总数为4 744个,将样本数据随机切分为训练集和测试集,其中,训练集占70%,数量为3 320个岩性样本点,测试集占30%,数量为1 424个岩性样本点。训练集用于训练模型,测试集用于检验模型的泛化能力。4种机器学习算法的主要参数为:①min-sample-split,为分裂一个内部节点(非叶节点)所需的最小样本数;②min-samples-leaf,为每个叶节点所包含的最小样本数;③learning-rate为每个学习器的学习率,即权重的缩减系数或步长,取值范围为[0,1];④n-estimators为弱学习器的最大迭代次数,或者是最大的弱学习器的个数,一般选择在[0.5,0.8]。
2.3.5 模型评价
为了更好地确定火山岩岩性识别模型的预测精度和泛化能力,利用精确率、召回率、ROC曲线确定分类模型的准确性和泛化能力。
精确率是被判定为正类样本数中实际为正类的比例:
(5)
召回率是覆盖面的度量,类似于灵敏度,度量有多少个正类样本数被判定为正类:
(6)
式中:P为精确率,%;recall为召回率,%;TP为正类判定为正类的样本数,个;FP为负类判定为正类的样本数,个;FN为正类判定为负类的样本数,个。
通过对各类算法在训练集与测试集的精确率与召回率的比较可知,随机森林算法具有更好的泛化能力。
ROC曲线是反应模型敏感性与特异性连续变量的综合指标。其横坐标FPR为预测为正但实际为负的样本占所有负例样本的比例;纵坐标TPR为预测为正且实际为正的样本占所有正例样本的比例。(0,0)代表所有样本全部被判定为负类,(1,1)代表所有样本被判定为正类,(0,1)代表最完美分类。图3为不同算法的ROC曲线,随机森林算法和梯度提升树算法的性能较好,能很好地向(0,1)点靠近,其次是决策树算法,而贝叶斯算法较差。AUC值为ROC曲线下与坐标轴围城的面积,是衡量算法优劣的一种性能指标,AUC越接近1,则算法真实性越高。随机森林算法和梯度提升树算法效果较好,每种岩性的AUC值都接近于1。
3 预测效果分析
根据前文建立的模型对未知井段进行预测,为验证预测的准确性,采用未参与建模的取心井进行预测验证。选取JIN204、JIN214井为盲井进行验证。其中,JIN204有3段取心,如图4a所示,自上而下分别为安山岩、流纹岩、凝灰岩与火山角砾岩互层。在第2段流纹岩处,4种算法都取得了准确的预测效果;第1段安山岩处,除梯度提升树算法外都进行了准确的预测;第3段凝灰岩与火山角砾岩的互层,只有随机森林算法取得了很好的效果。JIN214井是全区取心厚度较大的井,主要为火山角砾岩与安山岩岩心,如图4b所示,4种算法都能取得很好的预测结果。但在4 100~4 120 m处,安山岩与火山角砾岩叠置发育的部位,随机森林算法预测效果更好。通过对4种算法的模型评价与优选表明,随机森林算法较好。

图4 典型井岩性预测结果
4 结 论
(1) 结合取心、薄片、成像、实验分析数据确定岩性,并根据测井响应特征分析标定测井曲线对应的岩性,形成测井曲线和岩性对应样本库,为后续机器学习训练预测奠定基础。
(2) 根据建立的样本库数据,对数据进行归一化处理,利用机器学习中的决策树、随机森林、梯度提升树和贝叶斯算法,采用交叉验证和网格搜索优选每个模型的最优参数,建立4种机器学习模型,并对这4种不同模型评价优选,选出最优的随机森林算法模型。
(3) 利用优选出的随机森林模型,对该研究区45口井岩性智能解释,通过对取心井段的统计验证,结果与井段取心的符合率高。
猜你喜欢
西南石油大学学报(自然科学版)(2021年3期)2021-07-16
复杂油气藏(2021年1期)2021-05-27
宝藏(2021年4期)2021-05-27
空间科学学报(2020年1期)2021-01-14
矿产勘查(2020年5期)2020-12-19
建材发展导向(2019年5期)2019-09-09
电子制作(2018年16期)2018-09-26
湖北农业科学(2017年16期)2017-09-14
中国水运(2017年1期)2017-02-27
电子制作(2017年24期)2017-02-02
