
面向网络社交媒体的少样本新冠谣言检测
2022-03-10 01:25陆恒杨范晨悠吴小俊
中文信息学报 2022年1期
陆恒杨,范晨悠,吴小俊
(1. 江南大学 江苏省模式识别与计算智能工程实验室,江苏 无锡 214122; 2. 南京大学 计算机软件新技术国家重点实验室,江苏 南京 210023; 3. 深圳市人工智能与机器人研究院,广东 深圳 518129)
0 引言
新型冠状病毒肺炎(COVID-19,以下简称新冠)在全球范围内持续爆发,已成为一场全球性的流行病,造成的损失遍及民生、经济等多个领域。其中,与新冠相关的谣言也造成了大量负面影响,尤其在当下发达的网络环境下,在社交媒体上发布的谣言会在短时间内大范围传播,造成公共资源的极大浪费,对社会产生恶劣的影响。例如,推特上有关“5G基站会传播新冠”的谣言,就曾引起部分英国网友纵火烧基站的激进行为。因此,高效、准确地开展新冠谣言检测对于政府和个人都具有重要的意义,对积极、正面的舆情引导也具有重要价值。
谣言是指未经证实或蓄意编撰的内容,常见于社交媒体。由于社交媒体上的数据不间断产生,近年来采用机器学习和人工智能技术进行谣言检测成为了热门的研究方向。一类常见的研究分支将谣言检测建模为二分类问题,预测文本样例的真实性。相关研究经历了从早期的手工构建文本特征到近期的基于深度学习的自动特征表示方法[1-4],到结合社交媒体的传播特性,也有一部分工作结合社交账号间的互动、转发评论等信息传播开展谣言检测研究。[5]
现有的谣言检测任务,通常假定各类已知事件有充足的有标签数据用于建模和训练,并且在测试阶段,需要检测的谣言也与训练所用的事件有关。然而,在新冠这一突发事件爆发之前,社交媒体从未出现过有关这一事件的信息,导致在初期可供训练的数据极其稀少,对现有谣言检测模型带来了巨大的挑战。在少样本场景下开展新冠谣言检测研究,成为亟待解决的研究问题,具有重要的理论研究意义和社会应用价值。
少样本学习作为一种热门的机器学习方法,近几年得到了飞速发展[6-9],为新冠谣言检测任务提供了新的研究范式。少样本学习可以训练一个有效的机器学习模型,该模型可通过极少量的有标签数据来快速学习新的任务,使其能够在该任务上预测识别其他大量的无标签数据,尤其适用于新冠这类突发事件的谣言检测。少样本学习的基本思路可类比人类的认知过程,仅通过对少量或者单个样例的学习,实现对这一类物体或者概念的识别。例如,只需要见过几句范例,人类就可以熟练使用陌生的词汇。针对社交媒体上有关突发事件的谣言,同样可以采用这一思想,通过学习少量具有标签的谣言样例,就可以实现这一类突发新事件的谣言检测,从而在早期及时遏制谣言的传播。
本文关注少样本谣言检测这一重要且被长期忽视的研究问题,聚焦少样本场景下社交媒体中的新冠谣言检测问题,以新浪微博这一中国社交媒体平台作为数据来源开展研究。新浪微博上的谣言通常围绕不同的事件产生、传播,已有工作一般将已发生的事件作为研究对象,这类事件通常用充分的有标签数据进行模型训练,因此当出现新冠这类突发事件时,现有模型缺乏新事件相关的训练数据,无法进行有效预测。本文提出一种基于少样本学习的谣言检测模型(few-shot learning based rumor detection model,FRUDE),通过元学习方法构造具备学习能力的谣言检测模型,对突发事件相关的微博进行有效的谣言预测,并依托新冠这一突发事件,进行有效性和应用性验证。
本文的主要贡献包括以下三个方面:
(1) 提出了“少样本谣言检测”这一非常重要但被忽视的研究问题。该问题聚焦如何通过极少量的谣言和非谣言样例,迅速检测有关全新的、无先例突发事件的谣言信息。
(2) 收集了一种来自新浪微博的谣言数据集,包含11个与新冠无关、3个与新冠有关的事件,共3 840条中文数据。该数据集有助于少样本谣言检测问题的进一步发展。
(3) 提出了一种结合字符级BERT预训练编码和双层双向GRU上下文编码的特征表示方法,并通过设计基于元学习的少样本学习方法实现突发事件少样本谣言的有效检测,在中文新冠谣言数据集以及英文PHEME公共数据集上均取得了优于主流谣言检测模型的效果。
1 相关工作
本文研究内容同时涉及谣言检测和少样本学习,并使用预训练向量作为文本输入,相关研究工作分别综述如下:
1.1 谣言检测
根据谣言数据的不同特点,SemEval-2017论坛将谣言检测分为两类子任务: 谣言立场分类(rumor stance classification),以及谣言真实性预测(rumor veracity prediction)[10]。其中,谣言立场分类任务面向树形结构的数据集,其一般结构为一条源文本以及不同用户对该条文本的回复,分类目标为四分类任务,将每条文本分为支持(support)、反对(deny)、质疑(query)以及评论(comment),简称SDQC任务[11]。谣言真实性预测任务面向单条文本的数据集,分类目标为二分类任务,可结合辅助信息预测输入的谣言数据为真和假,也可以将该任务建模为三分类问题,即真、假和无法验证[12]。
根据谣言检测的不同研究思路,早期工作通常基于不同类型的手工特征通过监督学习构建分类器。例如,从文本、用户简介中抽取出特征,使用支持向量机和决策树等分类器对推特的可信度进行预测[13-15]、基于情感词典抽取情感和语义特征,进行谣言检测等[16]。这类方法高度依赖特征工程方面的经验,对数据集的结构和特点要求较高,通用性一般。深度学习强大的特征表示能力则推动了谣言检测的发展,例如,基于深度循环神经网络(RNN)、卷积神经网络(CNN)、图卷积神经网络(GCN)等设计的谣言检测模型打破了手工构造特征的限制,能够从文本中自动抽取出深层语义信息,通用性更强[4,17-19]。还有一类工作结合社交媒体的传播特性、多模态特性等开展谣言检测,例如,通过优化传播图构建新闻可信度预测模型、基于异构用户表示和建模方法找出可区分谣言的传播模式、融合图像、图像内嵌文本以及文本内容开展谣言检测等[20-22]。
1.2 少样本学习
少样本学习(few-shot learning)是一种基于极少量有标签数据进行模型训练的机器学习方法,被广泛应用于解决未在训练数据中出现过的新任务[6-7,23-24]。针对一个新任务,只需给定极少量的有标签数据,少样本模型就可以对该任务的无标签数据进行有效预测。例如,在1-shot分类任务中,测试集中每一个新观察到的类,只有一个有标签数据,导致传统基于数据驱动的监督学习难以应用在少样本学习情景中。近期,许多研究将深度学习模型应用到少样本学习中。其中,元学习(meta-learning)成为一种主流方法[6,25]。元学习旨在学习一种模型,该模型可以提取已有训练任务中可迁移的知识, 使得该知识可用于学习新的任务。其基本机理是,通过从少量有标签数据中提取可迁移的知识,模型能够快速适应全新的任务,从而正确预测标签。主流的元学习方法可以分为两个大类: 基于优化方法的(optimization-based) 元学习和基于度量学习(metric-based)的元学习。
模型无关元学习方法(MAML)是一种有代表性的基于优化的元学习方法[6],提出了利用梯度下降使模型可以自适应地学习如何在新任务上得到最佳性能。该方法通过一次梯度下降使模型参数调整为任务相关,再利用一次梯度下降,使得在该任务上的损失信号可以回传给模型来调整参数。Meta-SGD方法扩展了MAML,可以自适应地学习梯度下降的步长[25]。元迁移学习MTL提出了一种避免在少量任务数据上过拟合的方法[24],进一步改善了基于优化的元学习方法。
基于度量学习的元学习方法旨在学习一个好的特征空间,使得标签相同的数据之间距离更短,而标签不同的数据之间距离更长[8-9,26-27]。例如,MatchingNet提出在1-shot少样本学习中,使用余弦距离来衡量支持数据和查询数据间的相似度,从而使神经网络的特征提取器更好地区分不同标签的数据[8]。Prototypical网络进一步推广MatchingNet到K-shot少样本学习,通过求类内支持数据的特征均值,对每一个类别构建一个原型特征,实现使用多个支持数据的相似度计算[9]。
1.3 预训练词向量
预训练词向量模型(word embeddings)的快速发展进一步推动了文本信息处理的研究,例如Word2Vec和GloVe模型的出现,极大地提升了各类自然语言处理任务的性能[28-29]。早期词向量模型的不足之处在于不同上下文中的同一个单词仅有单一的向量表示,无法有效处理单词多义性问题,因此后续的ELMo模型及BERT模型充分引入了单词上下文信息,通过预训练得到能有效反映单词上下文的预训练词向量,进一步提升各类下游任务的性能[30-31]。其中BERT模型为近来主流的预训练模型,采用多层双向Transformer获取更丰富的上下文信息,得到具有更强语义表示能力的预训练词向量,并与各类循环神经网络模型等相结合,用于文本分类、情感分析等场景,展示出更显著的效果。
本文提出的基于少样本学习的新冠谣言检测方法,将谣言检测建模为二分类问题,判断每条微博是否为谣言,结合模型无关元学习方法构建具有良好适应性的突发事件谣言预测模型。不仅解决了新冠这类突发事件可训练数据稀少的问题,也提供了开展谣言检测的新研究范式,扩展了该研究任务可适用的场景。
2 新浪微博中的新冠谣言检测方法
本节主要介绍少样本谣言检测的问题定义、面向社交媒体中少样本新冠谣言检测任务的数据集构建以及基于少样本学习的谣言检测模型构建方法。
2.1 问题定义
本文将新冠谣言检测任务建模为少样本二分类机器学习任务,记为N-taskK-shotQ-query,N代表少样本学习的任务数(将检测某个事件中的微博为谣言、为非谣言记为两个任务)、K代表每一个任务抽样的支持样例(即训练数据)数、Q代表每一个任务抽样的查询样例(即测试数据)数。记需要检测的事件数为E,均包含谣言和非谣言两类数据,则有N=E×2,该任务如定义1所示。
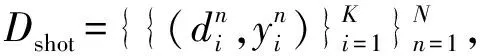
在新冠谣言检测场景下,有关新冠的突发事件出现后,可获取少量由平台判断的谣言数据,作为支持样例用于训练,从而得到能够有效预测查询集的少样本新冠谣言检测模型。2.2节中结合本文使用的新冠谣言数据集对定义1进行了具体的解释。
2.2 新浪微博新冠谣言数据集构建
参考微博谣言检测数据集常用的构造方法[3,32-33],本文使用网络爬虫从“微博社区管理中心”(1)https://service.account.weibo.com/获取由官方判定的不实信息,作为谣言数据的来源,并通过事件关键词爬取指定事件的谣言微博;指定事件相应的非谣言数据同样通过使用该事件的关键词进行爬取,并遵循已有工作的一般做法,验证爬取的微博未被平台标注为“不实信息”,图1为微博判定的谣言示例。

图1 新浪微博官方判定的谣言示例
本文共选取14个来自新浪微博的事件用于实验,其中3个事件均与新冠有关。由于数据集中存在大量重复或者转发的微博,为避免重复微博对模型造成过拟合,本文采用文本去重常用的汉明距离进行重复性文本的过滤,当多条微博之间的汉明距离小于设定的阈值,则过滤重复微博。根据不同阈值设置得到去重后的微博数量如图2所示。
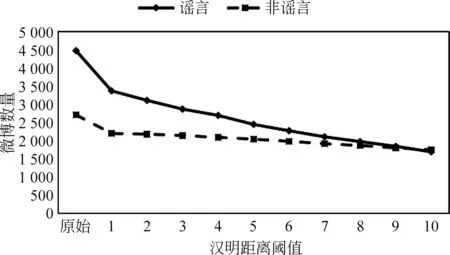
图2 设置不同汉明距离阈值去重后微博数量统计
汉明距离阈值过小,则无法有效过滤重复的微博,汉明距离阈值过大,则会误删非重复性的微博,根据图2的统计信息,本文选用汉明距离阈值为8构建新冠谣言数据集,通过该去重操作,数据集相关的统计情况如表1所示。
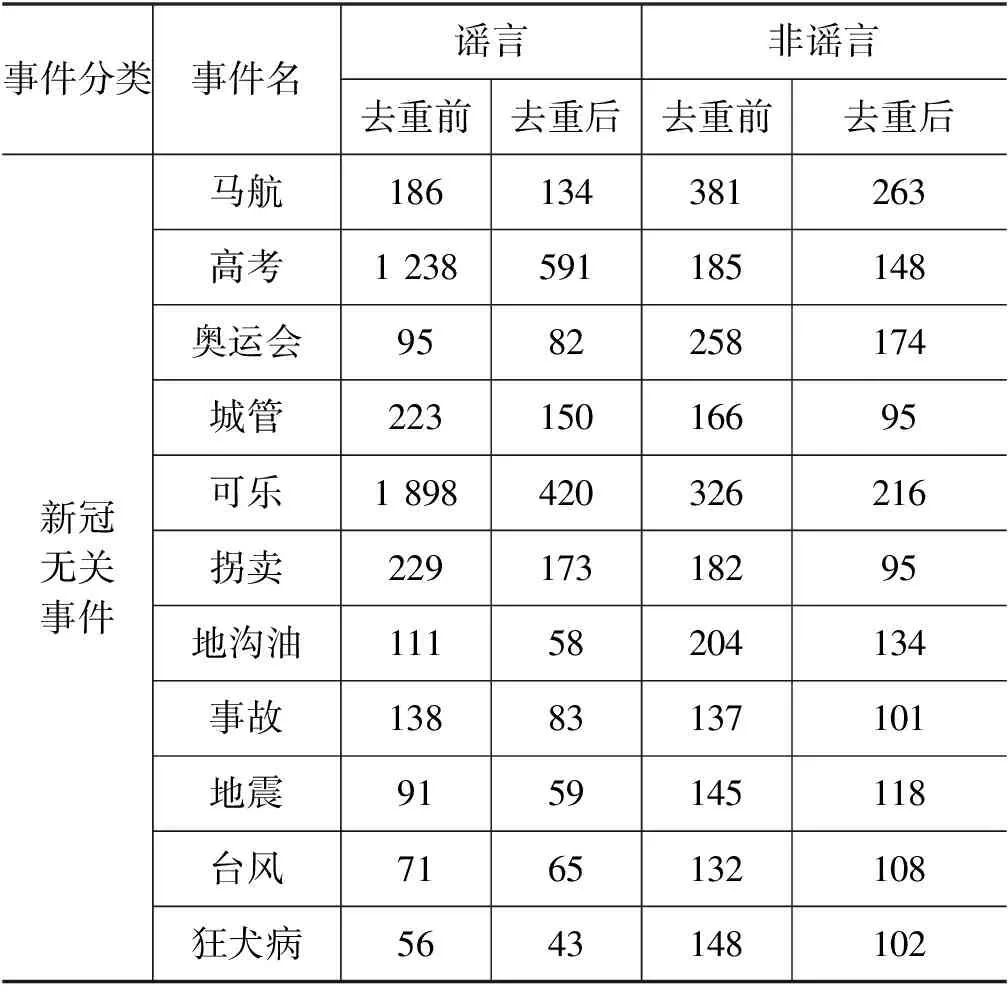
表1 新冠谣言数据集事件信息统计
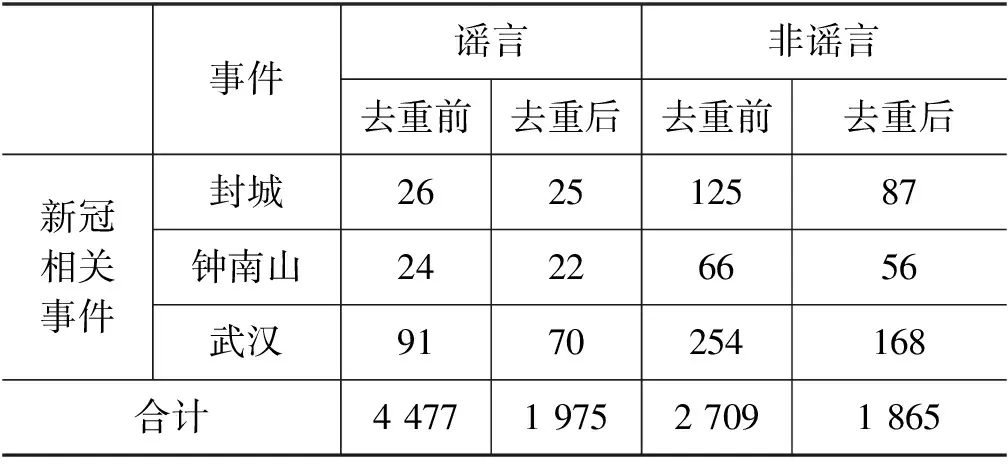
续表
该数据集包含3个与新冠相关的突发事件,11个与新冠无关的历史事件,各个事件的详细描述如下所示:
马航: 该事件为微博上有关马航MH370航班失事的讨论;
高考: 该事件为高考期间在微博上发布的有关准考证丢失、高考招生录用等高考相关信息;
奥运会: 该事件为微博上发布的有关奥运会新闻及讨论;
城管: 该事件为微博上有关城管执法的新闻及讨论;
可乐: 该事件为微博上发布的有关可口可乐食品添加剂的信息;
拐卖: 该事件为发布在微博上的儿童拐卖信息及寻人信息;
地沟油: 该事件主要为微博上关于地沟油这一食品安全问题的相关新闻和信息;
事故: 该事件主要涵盖了微博上发布的各类事故,主要包括交通事故等;
地震: 该事件主要为微博上有关地震灾害的报道与讨论;
台风: 该事件主要为微博上有关台风灾害的报道与讨论;
狂犬病: 该事件主要为微博上发布的有关狂犬病及其致死情况的信息和报道;
封城: 该事件为新冠肺炎爆发初期,微博上发布的有关各地封城政策的信息;
钟南山: 该事件为新冠疫情出现后微博上有关抗疫专家钟南山的相关新闻和讨论;
武汉: 该事件为新冠肺炎爆发后微博上有关武汉的新闻与信息。
通过采用少样本学习策略使用历史数据训练谣言检测模型,从而能够在新冠这一突发事件出现时,得到具备学习能力的、在新事件上具备较好预测能力的新模型。结合定义1,本文将该数据集上的新冠谣言检测任务建模为6-task 5-shot 9-query,即每次从3个有关新冠的事件中分别采样5条有标签的谣言和非谣言数据用于训练,各个事件随机采样9条未用于训练的无标签谣言和非谣言数据用于测试,则每个任务(如检测“封城”事件的谣言是一个任务)均由14条数据构成。
2.3 基于少样本学习的谣言检测模型
本节主要介绍FRUDE模型的设计思想和模型细节,FRUDE模型主要由三部分构成: 首先通过预训练BERT模型获取文本字符级词向量嵌入层[31],然后将其输入多层双向GRU进行上下文特征抽取,最后通过少样本元学习模型实现任务适应和新谣言的检测,模型总体框架如图3所示。
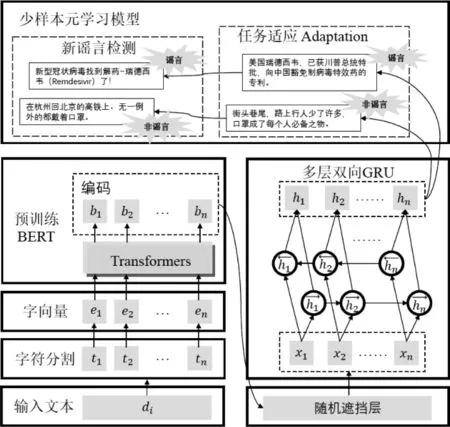
图3 FRUDE模型总体框架
2.3.1 文本字符级特征提取
预训练BERT模型在训练过程中使用了海量语料,具有较好的适用性,能够有效提升自然语言处理任务的性能[34]。本文提出的FRUDE模型首先按字符粒度对输入文本di进行分割,然后使用预训练BERT模型得到di中每个字符的编码向量[b1,b2,…],作为下一步文本上下文特征编码的输入。
为避免在训练中产生过拟合现象,FRUDE模型在进行上下文编码前加入了随机遮挡层,记随机遮挡概率为r,该层共支持三种策略:
策略1: 随机选中遮挡概率为r的字符,并置选中字符的编码向量所有维度为0。
策略2: 随机选中遮挡概率为r的字符编码向量维度,并置所有字符编码向量内选中的向量维度为0。
策略3: 随机选中遮挡概率为r的字符和编码向量维度,并将选中字符及被选中的向量维度置为0。
2.3.2 少样本模型的多层双向GRU编码器
为获取丰富的上下文信息,FRUDE模型采用带门结构的循环神经网络(GRU)对输入文本进行编码[35],其定义如式(1)~式(3)所示。
将上述过程简化为ht=GRU(xt,ht-1), 其中,ht和ht-1分别为本轮和上一轮的隐式状态;xt为序列当前的输入,表示第t个字符的BERT编码向量。按照时间展开并简化为h=GRU(x,h0),h表示h1:T,x表示x1:T,T代表句子的长度,h0为初始隐式状态,通常为零向量。
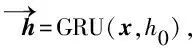
2.3.3 基于元学习的少样本学习方法
本节主要介绍基于元学习的少样本谣言检测方法。该方法旨在构造一个具备快速学习和适应新任务能力的谣言检测模型,适用于在仅有极少量有标签样例的情况下,判断与该事件相关的微博是否为谣言,可应用于新冠这类突发事件的谣言检测任务。
在机器学习领域,针对少样本任务的元学习理论和方法快速发展。其核心思想是从训练数据中抽样大量不同的任务组合,使模型学习到数据中可以迁移的知识来满足不同的任务。其中目前最先进的方法通过梯度下降方法找到一组最优的预训练模型参数[6,23],使得该模型仅需通过几个样例就可以快速适应新的未知任务,并通过迁移预训练中得到的知识,得到较准确的结果。
对于谣言检测任务来说,元学习框架可以帮助模型理解不同语境、事件的谣言和非谣言,学习到通用的区别谣言与非谣言的可迁移知识,例如谣言往往具有的夸大的语气和大量出现的感叹词等。因此元学习模型具备了在全新的事件上对文本样例进行谣言检测的能力,其训练流程如图4所示。
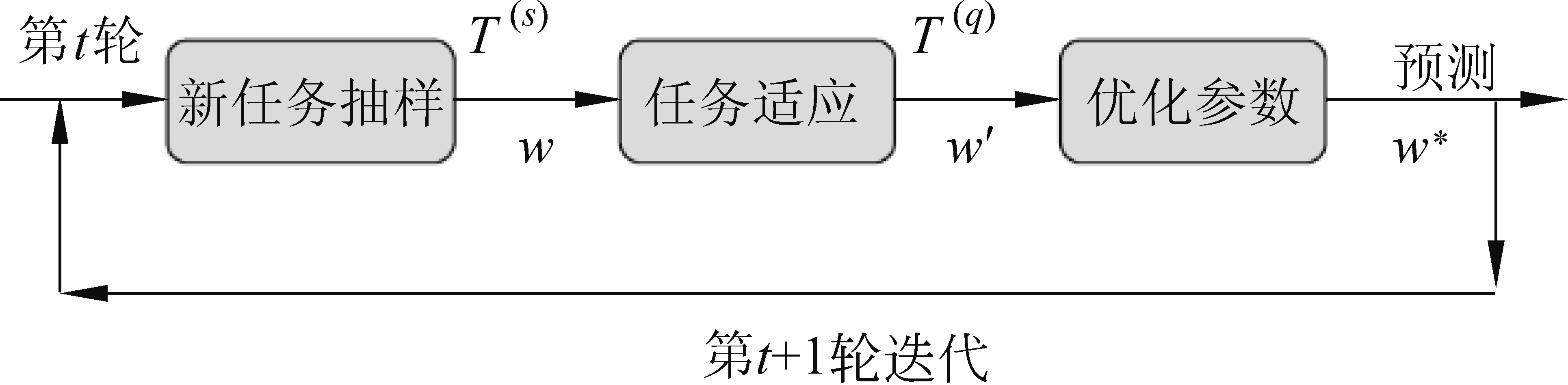
图4 元学习训练流程
元学习的训练任务是最小化训练损失函数。对于谣言检测来说,给定一个batch的少样本任务B={T1,…,TB},训练目标是减少分类交叉熵L。总的损失函数L,如式(5)所示。
(5)
其中,模型参数w是2.3.2节定义的多层双向GRU网络。通过多次迭代,可获得最优化的模型w*。结合2.1节定义的N-taskK-shotQ-query少样本任务,本节提出以下元学习训练步骤。
步骤 1: 抽样从训练数据中抽取|B|个少样本学习任务|T|,每一个任务包括了E个不同的事件,每一个事件分别抽样选取K个谣言和非谣言文本来训练模型,以适应这E个事件,记为支持集合T(s)。同时分别抽样Q个谣言和非谣言文本用于模型优化, 记为查询集合T(q)。因此一个任务中包含了N×(K+Q) 条文本数据(其中N=E×2)。
步骤 2: 新事件适应为了让模型适应新事件,更好地学习新事件中的语义信息,在这一步骤使用梯度下降法(SGD)在少样本支持数据集T(s)上更新模型参数,其步骤如式(6)所示。
w′=w-α∇wLT(s)(w)
(6)
其中,α是适应步骤的学习速率,把w′记为事件适应的模型参数。可利用w′来对查询数据集中的文本数据进行谣言检测,并更新模型参数。
步骤3: 模型优化该步骤是衡量事件适应模型w′在新事件上的表现。在训练阶段,查询数据集T(q)包含了该事件上是否为谣言的真实标签,可使用这些标签,通过SGD来更新原始模型参数w,如式(7)所示。
(7)
其中,γ是学习速率。优化原始模型参数w需要通过中间变量w′,而w′也是关于w的函数,这就导致上述计算过程需要求解关于w的Hessian矩阵,这无疑导致巨大的计算量。本文选择忽略二阶导数来直接估计w的梯度,相关研究显示该方法对最终的模型性能影响很小,却能大幅度减少计算量[6,23]。
在模型测试阶段,可直接使用事件适应模型w′判别该事件中查询文本是谣言的概率,即使用一个全连接层加上Sigmoid函数σ将隐状态转化输出为谣言的概率p=σ(Wh+b)。
3 实验与分析
本节使用本文提出的少样本谣言检测模型开展实验与分析,分别在新浪微博数据集和推特PHEME数据集上开展对比实验。
3.1 数据集
为了展示模型在新冠谣言检测上的效果,本文使用基于新浪微博采集的数据集进行实验。同时,为了体现模型的通用性,本文也选取谣言检测任务中常用的公共数据集开展实验,两个数据集的描述如下:
新冠谣言数据集针对少样本学习任务,该数据集由11个与新冠无关的事件以及3个与新冠有关的事件构成,每个事件均包含多条谣言及非谣言微博,其中11个事件作为训练集和验证集训练模型,3个新冠相关事件作为测试集验证少样本新冠谣言检测效果,整个数据集由3 840条中文谣言和非谣言构成。不失一般性地,11个与新冠无关的事件被随机划分为三个数据子集,每个子集分为训练集和验证集,分别命名为split 0、split 1和split 2。
PHEME谣言数据集该公共数据集包含来自推特的谣言和非谣言数据,共包含5个事件[36]。为了验证少样本学习效果,本文将5个事件中最新发生的2个事件作为测试集,将剩余3个作为训练集和验证集训练模型,本文使用文献中预处理后的数据集开展实验[37],整个数据集共有2 305条英文谣言和非谣言。其中用于训练的数据同样划分为三个数据子集,分别为split 0、split 1和split 2。
3.2 基线模型
本文使用如下三种基线模型开展对比实验,以展示FRUDE模型在少样本场景下的有效性:
DT-EMB在早期决策树算法常被用于谣言检测任务中[15],该基线模型以决策树为基分类器,每条样例使用由预训练BERT模型编码后得到的词嵌入均值作为该样例的特征向量。
SEQ-CNN近年来,CNN常被用于深度谣言检测模型中[4],该基线模型以卷积神经网络为基分类器,每条样例的输入与本文提出的模型一致,即由预训练BERT模型编码后得到的词嵌入序列。
SEQ-GRU近年来,RNN常被用于深度谣言检测模型中[3,17],该基线模型以双向门循环神经网络为分类器,每条样例的输入与本文提出的模型一致,即由预训练BERT模型编码后得到的词嵌入序列。
由于本文提出的模型基于少样本场景提出,为了进行公平比较,针对传统机器学习方法DT-EMB,在训练集中加入少量采样的新事件数据训练模型,采样数量与FRUDE模型保持一致;针对深度学习方法SEQ-CNN和SEQ-GRU,使用训练集训练模型,采样少量的新事件数据进行模型微调后再进行测试,采样的新事件数量同样与FRUDE模型保持一致。其中各模型在采样时使用的随机采样种子相同,这不仅能保证数据的一致性,并且保证从新事件数据中采样出的少样本训练数据不出现在测试集中。
3.3 实验及参数设置
针对中文新冠谣言和英文PHEME公共数据集,本节分别使用由HuggingFace(2)https://s3.amazonaws.com/models.huggingface.co提供的中、英文BERT预训练模型及对应词表获取输入文本的字符向量,针对中文数据,使用BERT-base-Chinese预训练模型,其词汇表大小为21 128;针对英文数据,使用BERT-base-uncased预训练模型,其词汇表大小为20 644,预训练向量维数均为768。同时,结合两个数据集的特点,新冠谣言数据集输入文本长度统一截取为100,PHEME公共数据集输入文本长度统一截取为32;由于新冠谣言数据集中有3个与新冠相关的事件作为测试集,由2.1节定义1中有关任务的定义可知,可将新冠谣言数据集建模为6-task,同理,PHEME公共数据集中有两个事件作为测试集,因此该数据集可建模为4-task,本文实验统一以5-shot 9-query的设置开展比较实验,因此新冠谣言数据集的少样本学习任务为6-task 5-shot 9-query,PHEME谣言数据集的少样本学习任务为4-task 5-shot 9-query,即每个任务仅采样5条有标签数据进行训练。在元学习阶段,设置学习率α=0.001。在将字符向量输入GRU模型前,本节比较了2.3.1节提出的三种随机遮挡策略,图5是新冠谣言数据集上的实验结果。

图5 使用不同随机遮挡策略在新冠谣言数据集上的准确率对比
观察图5可知,无遮挡策略在三个实验数据子集中的准确率最低,可见在对输入文本进行字符向量编码后,需要随机遮挡后再开展下一步的上下文特征编码。其中遮挡策略1得到的效果最佳,因此在本节实验中,FRUDE模型的随机遮挡层使用策略1,针对随机遮挡概率这一参数,本文同样通过实验方式确定,不同遮挡概率下FRUDE模型的性能如图6所示,可以观察到,当遮盖概率为30%时,模型取得最佳效果,因此在本实验中,遮挡概率设置为30%。此外,双向GRU模型的隐藏层数设置为2,隐藏层维数设置为128。
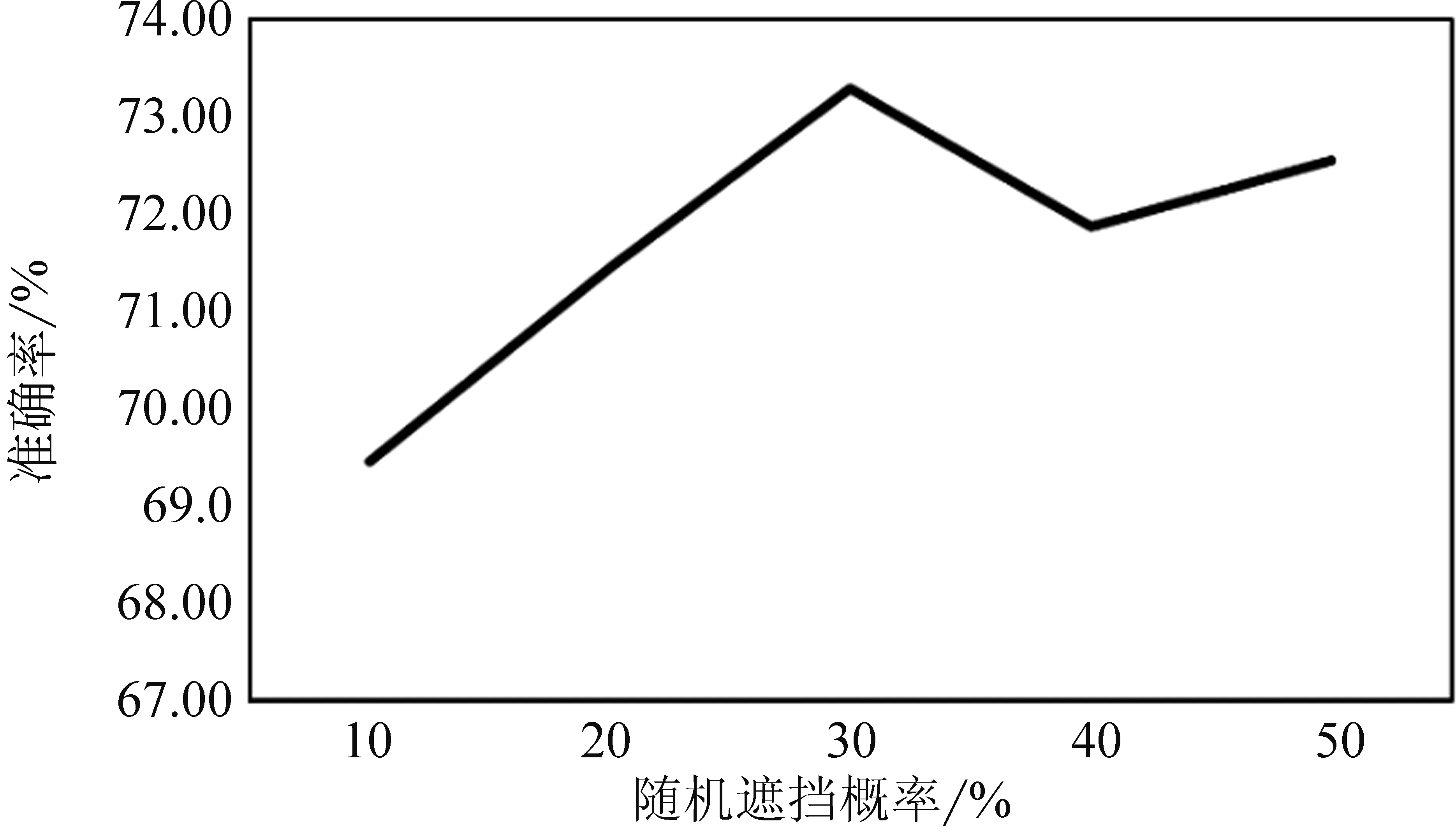
图6 使用随机遮挡策略1时不同遮挡概率对新冠谣言数据集谣言检测准确率的影响
3.4 谣言检测实验
本实验使用分类准确率(accuracy)进行模型效果评估,准确率越高,代表谣言检测效果越好。为了不失一般性,分别在三个数据子集上开展谣言检测的二分类实验,其中每个数据子集的结果均为200次少样本学习的准确率均值。
观察表2、表3的实验结果可知: 仅采用传统机器学习方法(如DT-EMB),在少样本场景下谣言检测的性能非常差,对于二分类问题的准确率在56%左右,仅比随机猜测的策略略好;使用深度神经网络的方法(SEQ-CNN和SEQ-RNN)由于采用微调的策略,可以在历史数据训练好的模型上,通过使用少量有标签的新样例数据进行模型微调,从而得到对于新事件有一定适用性的预测模型,这说明通过预训练+微调的方法可以在一定程度上提高模型性能;本文提出的FRUDE模型,采用了基于元学习的少样本学习方法,能够通过梯度下降的方式将历史事件学习到的信息迁移到新事件的预测模型中,在谣言检测的准确率上,FRUDE模型高出预训练+微调方法3%~6%,这说明本文提出的基于元学习的方法,在训练数据仅存在极少量有标签样例的场景下,具有更加显著的优势。
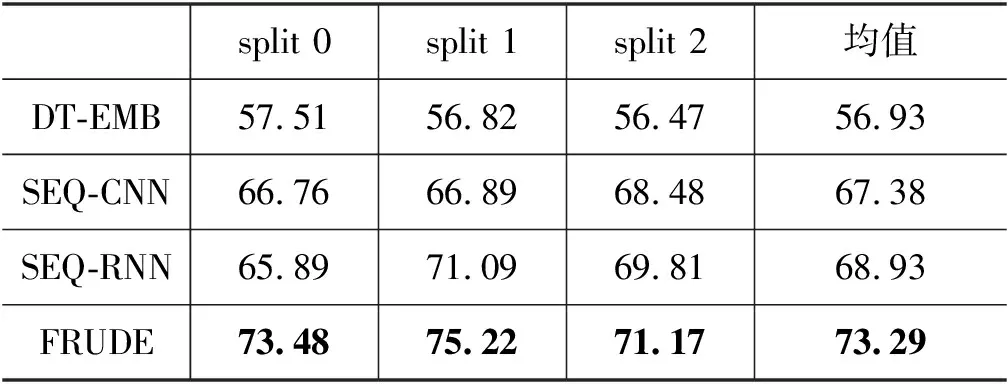
表2 新冠谣言数据集谣言检测准确率 (单位: %)
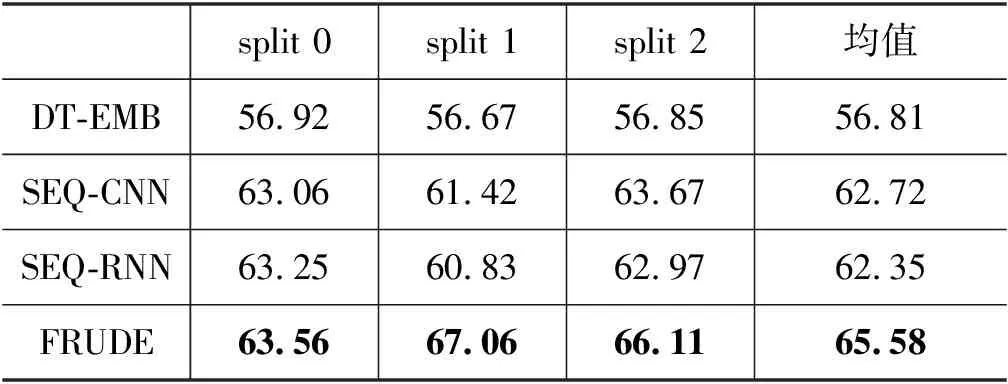
表3 PHEME公共数据集谣言检测准确率 (单位: %)
本文同时开展了不同shot数量下FRUDE模型在新冠谣言检测任务上的性能实验,分别设置为6-task 1-shot 9-query以及6-task 3-shot 9-query,实验结果如表4所示。
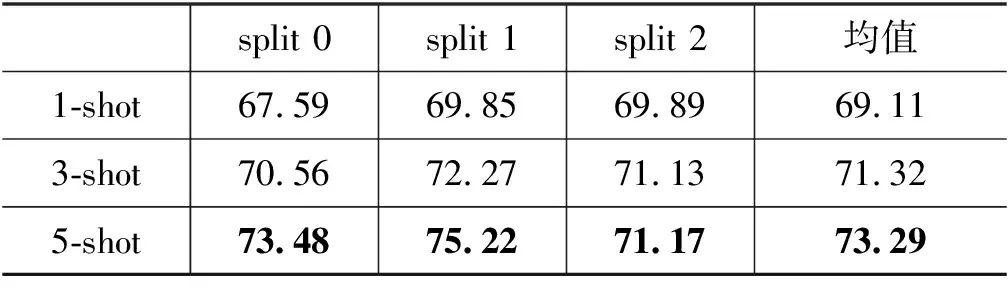
表4 不同shot数设置下FRUDE模型在新冠谣言数据 集上开展谣言检测的准确率 (单位: %)
观察表4的实验结果可知: 参与任务适应的少样本数据量对于FRUDE模型的性能有直接的影响,分别使用1-shot、3-shot以及5-shot得到的新冠谣言检测结果呈递增趋势,表明少量增加样本数量能够有效提升FRUDE模型的预测效果;此外,对比观察表4中1-shot设定下的实验结果以及表2中三个基线模型的结果,表2中三个基线模型分别在训练过程中使用了5-shot样本参与模型训练,而表4中仅使用1-shot样本的FRUDE模型已得到高于所有基线方法的准确率,展示出FRUDE模型在少样本学习中的有效性,也说明针对新冠这一少样本突发事件,其谣言检测任务需要在现有方法基础上引入少样本学习的必要性和重要性。
4 总结
本文提出了一种基于少样本学习的新冠谣言检测模型。现有工作一般需要充足的有标签数据进行模型训练,对于新冠这类突发事件,在谣言产生初期相关数据极少,已有方法的适用性存在局限性。因此本文结合当前主流的深度神经网络建模方法,使用基于元学习的少样本机器学习方法,提出适用于突发事件的新浪微博谣言检测模型。实验结果表明,该模型在本文提出的新冠谣言数据集以及公共的PHEME谣言数据集上,在少样本谣言检测任务中准确率均得到了显著提升,本文提出的FRUDE模型可行有效。
猜你喜欢
环球时报(2022-04-13)2022-04-13
今日农业(2021年2期)2021-11-27
今日农业(2021年1期)2021-03-19
中学生数理化·高一版(2021年2期)2021-03-19
科学大众(2020年12期)2020-08-13
新世纪智能(英语备考)(2020年5期)2020-08-11
恋爱婚姻家庭·养生版(2020年3期)2020-04-13
领导决策信息(2018年16期)2018-09-27
民生周刊(2017年22期)2017-12-12
新高考·高一数学(2016年10期)2017-07-06
