
基于多层BP 神经网络的无参考视频质量客观评价
2022-03-10 11:04:42姚军财黄陈蓉
自动化学报 2022年2期
姚军财 申 静 黄陈蓉
视频技术的发展和应用改变了人们传统的生活、工作和学习等方式.由此,视频质量成为一个不可回避的重点话题.实时、有效和便捷的视频质量评价(Video quality assessment,VQA)方法,是保障视频有效通信的前提[1-2].
视频质量主要受到来自视频内容、编解码、传输环境和人类感知4 个大的方面因素的影响[1-5].视频的压缩编码给视频带来模糊、块效应等损伤[5];视频传输中的缓冲延时、卡顿、误码等问题造成视频图像模糊、播放停顿等情况,均会影响网络视频质量,使得用户体验质量下降[2];对于视频内容,相同的外在环境但不同的视频内容给人的感知效果也有较大的不同,视频内容同样是影响视频质量的重要因素[3];人类是视频质量的最后接受者和评价者,视频质量评价结果需要符合人类视觉特性[4-6].由此,在VQA 中需要考虑上述4 个大的方面的影响.
VQA 一般分为3 类:全参考(Full-reference,FR)、部分参考(Reduced-reference,RR)和无参考(No-reference,NR)视频质量评价[1].截止目前,现有的大多数VQA 模型均是FR和RR,其典型的有PSNR (Peak signal-to-noise ratio)、VSNR (Visual signal-to-noise ratio)[7]、SSIM (Structural similarity index)[8]、VQM (Video quality model)[9]、STMAD (Spatiotemporal most apparent distortion algorithm)[10]、MOVIE (Motion-based video integrity evaluation)[11]模型等.对于NR-VQA,其不需要任何来源,该方法进一步分为两类[12]:1) NR-P(NR 视觉感知)类型,其用于完全解码的视频质量的评价;2) NR-B (NR 编码)类型,其使用从比特流中提取的信息来评价视频质量.另外,神经网络方法在VQA 模型回归方面具有较大的优势,能够较大地提高构建模型的精度[13],且由于NR-VQA不需要源视频,其在视频传输中具有重要的实际应用价值,因而,结合神经网络的无参考视频质量评价方法成为视频通信的热门研究课题.近些年报道相关领域的研究成果主要有VQAUCA (NR VQA using codec analysis)[14]、V-CORNIA (Video codebook representation for NR image assessment)[15]、C-VQA (NR VQA method in the compressed domain)[16]、NR-DCT (Discrete cosine transformbased NR VQA model)[17]、V-BLIINDS (Blind VQA algorithm)[18]、NVSM (NR VQM using natural video statistical model)[19]、3D-DCT (NRVQA metric based on 3D discrete cosine transform domain)[20]和COME (NR VQA method based on convolutional NN and multiregression)[21]等NR-VQA 模型,但其目前仍存在较多问题,主要有:
1)失真特征提取数量问题:在视频通信中,可能会产生多种类型的视频失真,在构建NR-VQA模型中,虽然提取更多的视频失真特征可以提高其评估精度,但同时也增加了其复杂度[12,19,22].因此,构建NR-VQA 模型时应尽量提取少量但有效的失真特征,但这个度非常难把握;
2) 视频内容及其视觉感知问题:现有的NRVQA 模型通常只关注于传输造成的视频失真,很少考虑视频内容及其视觉感知效果对视频质量的影响[3,14].因此,其主客观评价结果一致性较差,需要结合二者提高精度;
3) HVS 特性问题:在VQA 中引入合适有效的HVS (Human visual system)感知特性能够显著性提高VQA 评价精度.但是,如果使用从比特流中提取的失真特征来构建NR-VQA 模型时,则很难有效地在模型中引入HVS 特性[3-4].因此,目前一般将VQA-B 度量和VQA-P 度量相结合,构建综合的NR-VQA 模型,从而提高了模型的精度;
4)模型的复杂性问题:在视频通信中,VQA 需要实时进行,其要求模型尽可能简单但有效.然而,VQA 模型往往引入了部分HVS 特性,并且依赖于更多的视频失真特性,同时,采用了机器学习方法,因此,现有的NR-VQA 模型往往非常复杂[17-22].因此,在构建模型时,需要对这些特征和方法进行适当的选择,并对相应的参数进行优化;
5)泛化性问题:在NR-VQA 中,其方法往往使用机器学习工具获得视频质量评价分数,然而,机器学习需要训练样本;目前,其常见方法是使用视频数据库中的部分样本进行训练,而其余部分进行测试,其实验结果表明,如此方式,VQA 模型精度较高;然而,当测试其他数据库中的视频时,其模型精度则显著下降[15-22].实验表明,基于机器学习方法的VQA 模型的泛化性能往往较差.因此,有必要对VQA 模型进行优化,提高泛化性能.
6) 模型精度问题:对于基于机器学习方法的NR-VQA,往往选取的样本素材、测试和训练样本的比例、不同测试数据库样本等对评价模型的精度有较大的影响[16-19].因此,在模型构建时需要从样本的多个方面来考虑,以提高精度.
基于此,在本研究中,针对上述影响视频质量的4 个大的方面,结合多层BP 神经网络研究了无参考视频质量评价方法,并与现有模型进行对比分析,研究了其精度、复杂性和泛化性能.
1 视频特征描述
NR-VQA 在视频传输中具有重要的实际应用价值.在视频通信中,通过提取视频本身特征和传输引起的质量因素,结合HVS 特性,能够很好地预测终端视频的质量;并且在视频质量预测过程中,采用机器学习的方法能够获得更高的评价精度,如采用神经网络的方法.结合机器学习方法,需要提取影响视频质量的有效特征.通过VQA 的主观实验研究和前人的研究结果表明[1-5],目前,影响视频质量主要是上述的4 个大的方面,经过反复试验和研究,其可更进一步细化到11 个具体的视频特征,即为图像局部对比度、灰度梯度分布、模糊度、亮度和色度的视觉感知、运动矢量、场景切换、比特率(BitRate,BR)、初始时延、单次中断时延时长、多次中断平均时延时长、中断频率,其说明如下.
在视频的时域和空域描述方法中,视频可以看成是一帧一帧的图像信息与帧间的时域信息相结合而成[1,9],即在本研究中,采用帧图像描述空域信息,采用运动矢量和场景切换两个方面来描述时域信息.
人眼对视频空域信息的感知,即是感知其每帧图像.依据HVS 特性,人眼对图像的感知主要是获取图像的灰度和色度信息,并分辨其清晰程度,同时其感知效果受局部对比度和人眼敏感程度的影响.由此,采用局部对比度、灰度梯度分布、模糊度、及亮度和色度的视觉感知共4 个特征来表征每帧图像的内容,即人眼感知到的图像是该4 个特征的综合结果.
在传输过程中,影响视频质量的主要因素有:压缩编码、信道传输条件及其视觉感知.对于压缩编码,主要表现为视频压缩编码后的码率BR;信道条件对传输视频质量影响最大的是时延(在TCP协议下不考虑丢包),其包括初始时延、中间单次中断时延、中断频率、中断平均时长.
对于上述的11 个特征,采用表1 中的参数进行定量描述.
2 视频特征参数计算
表1 中的各参数值的计算或获得方法如下.
1)图像局部对比度
采用图像中每一点与周围最近的8 个点的对比度的平均值作为该点受局部环境影响的对比度,然后乘以对应中心的归一化亮度值,再对所有点求平均,其值可以表明人眼在该对比度下的亮度的敏感结果.记帧图像为I,其局部对比度计算表达式为:
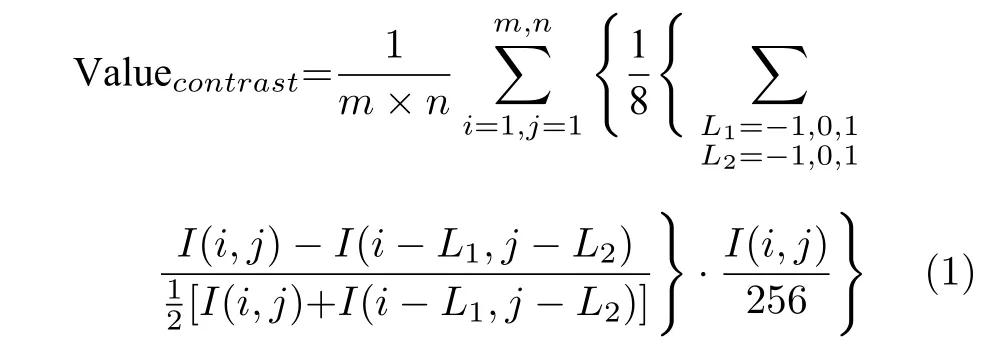
其中,m、n表示图像像素的行和列的数目.找出所有帧图像中该参数值的最大值,同时对所有帧图像求平均,以其平均值和最大值作为定量描述该视频内容空域信息的特征之一.表1 中的其他特征参数的最大值和平均值的计算方法均与该方法一致.
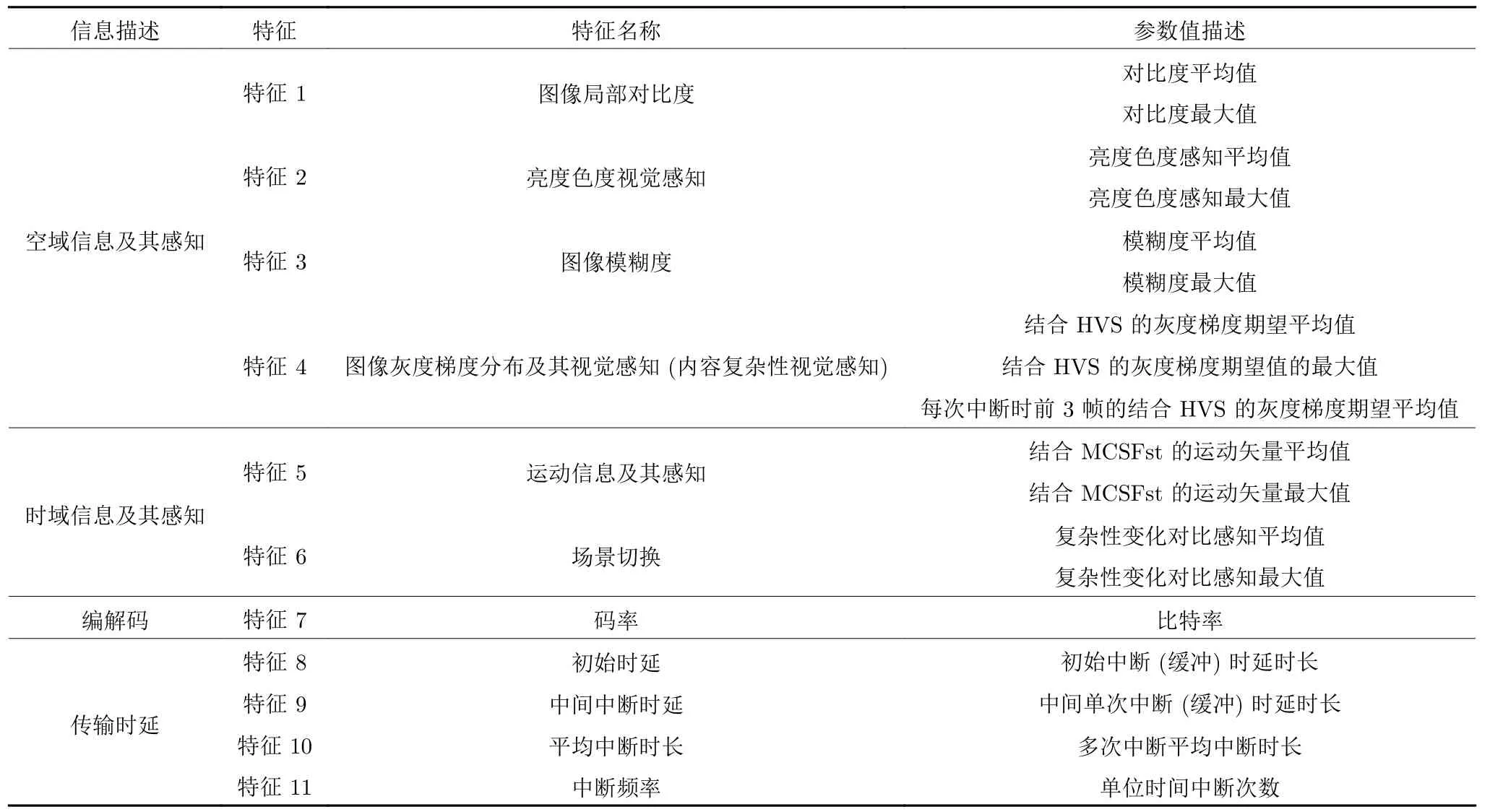
表1 所提视频特征及其参数描述Table 1 Video features and description of their parameters
2)亮度和色度视觉感知
图像亮度和色度的感知主要表现为对其强度大小的感知,且受空间位置的影响,不同空间位置,人眼的敏感程度不同.则依据Nadenau[23]和Barten[24]分别提出的人眼觉察静止目标时的亮度和色度对比敏感度函数CSF (Contrast sensitivity function),计算图像上每一点像素所在位置人眼的敏感值,并归一化;再将敏感值乘以相应像素点的灰度值,且归一化;然后按像素点个数求平均,其平均值为人眼对图像亮度和色度的感知结果;最后对所有帧图像求平均,得出的结果和其最大值作为描述该视频内容空域信息的第2 个特征,其计算式为:
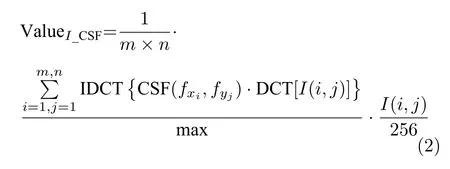
3)图像的模糊度
采用文献[25]中提出的改进的点锐度算法函数EAV (Entity attribute value)来计算,其表达式为:
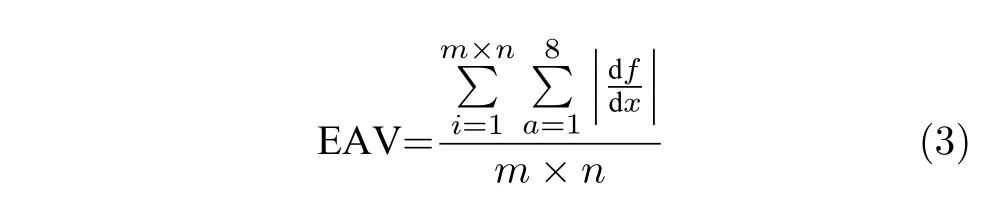
式(3)中,m、n为图像像素的行和列,dx表示距离增量(即像素间隔),df表示灰度变化幅值.同上理,得到其平均值和最大值,其结果作为描述该视频内容空域信息的第3 个特征.
4)图像的灰度梯度分布及其视觉感知
无论是亮度图还是色度图,其对人眼的刺激仍然是其强度的感知效果.其强度值在存储和显示中一般采用256 级的灰度值来描述.同时灰度的变化快慢对人眼的刺激也影响人眼对图像亮度和色度的感知.基于此,需要计算图像的灰度和梯度分布.为了更好地说明其分布情况,采用灰度梯度共生矩阵来描述图像的灰度梯度分布概率情况.再利用期望值的普遍计算方法,将各梯度值乘以灰度梯度共生矩阵中对应的值,其结果作为图像的灰度梯度期望值.该值亦作为描述图像内容的一个特征,其能够较好地反映图像内容的复杂性,记为Valuec(Valuecomplexity),其计算如表达式(4).
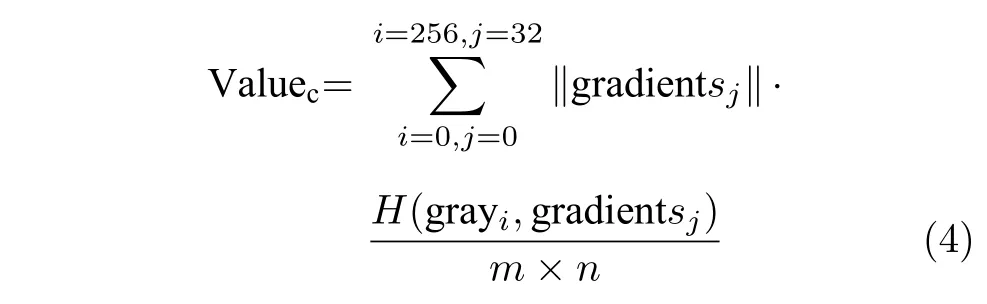
式中,图像的梯度被量化为32 级.
人眼对不同内容复杂性的图像敏感程度明显不同.结合人眼对图像内容复杂程度的敏感效果,通过反复主观实验和定性分析,人眼对图像内容复杂程度的感知结果可用灰度梯度期望值与人眼敏感程度值的乘积来定量描述,记为结合HVS 的灰度梯度期望值,其计算如式(5).
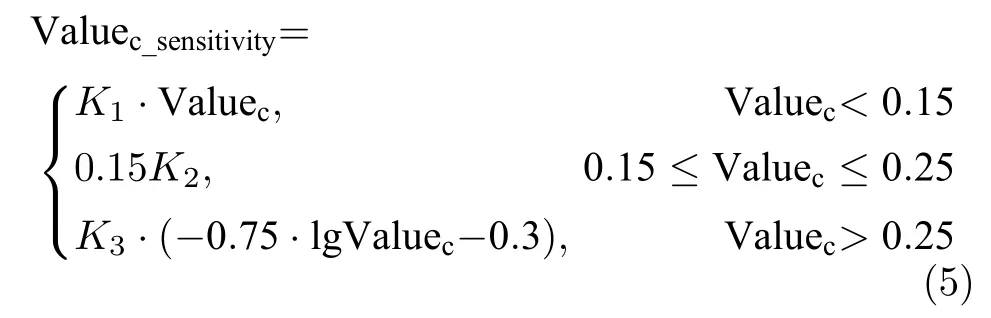
其中K1、K2和K3为参数,可通过主观实验测量数据拟合得出.式(5)计算值越大,表明人眼对该图像的复杂性越敏感,感知图像效果越好.同上方法,得到所有帧图像中该值的最大值和平均值.对于视频中的中断,中断时间内,人眼感知到的均是中断瞬间前的一帧图像,为了表明其效果,计算每次中断时前3 帧的结合HVS 的灰度梯度期望平均值,则该值、所有帧图像的最大值和平均值共同作为描述该视频内容空域信息的第4 个特征.
5)运动矢量及其视觉感知
采用全搜索算法匹配获得每一个子块的运动矢量.结合人眼对运动目标的敏感特性,将运动矢量乘以敏感阈值,其结果定量描述为人眼感知视频时域信息的两个特征之一.其计算方法为:
a) 采用Kelly[26]提出的运动目标感知敏感函数MCSFst:
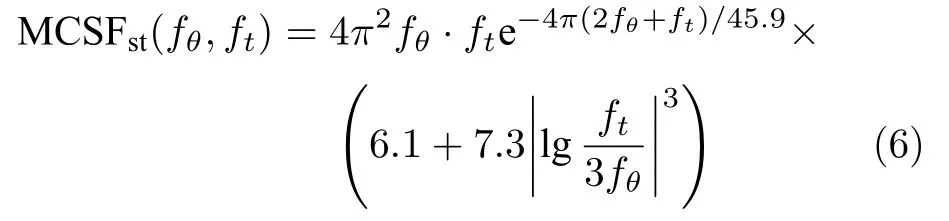
其中:MCSFst定量表征HVS 感知运动目标(即光栅)时的敏感阈值,fθ、ft为角频率和时间频率[26].该式可以计算得出模拟观看视频时,人眼感知视频任一像素点对应的运动矢量的敏感阈值.
b) 将式(6)计算的敏感阈值乘以该点的运动矢量,并按像素点数求平均,该值即定量描述为感知视频两帧间时域信息的一个特征值;将所有两帧间的计算结果对总帧数N求平均,其计算如式(7).其平均值和最大值为人眼感知视频时域信息的特征之一.
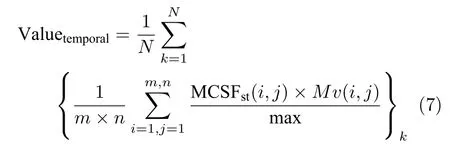
6)视频内场景切换
视频中往往存在较多的场景切换,而且是快速的,如此给用户带来非常负面的评价,但是客观评价分数往往变化不大,致使主客观评价分数明显不一致.为了克服该影响,引入场景切换来描述时域信息,即采用亮度、色度和纹理(期望值)的对比差异来反映场景的切换,其计算方法为:首先分别计算当前帧与之前30 帧各自的灰度梯度期望值;再基于物理中对比度的定义,分别计算当前帧与之前30 帧的灰度梯度期望值的对比度,其定义表述如式(8),并计算其平均值,则该值用来反映当前帧场景与之前30 帧场景的切换快慢;最后按视频帧数求其平均值.
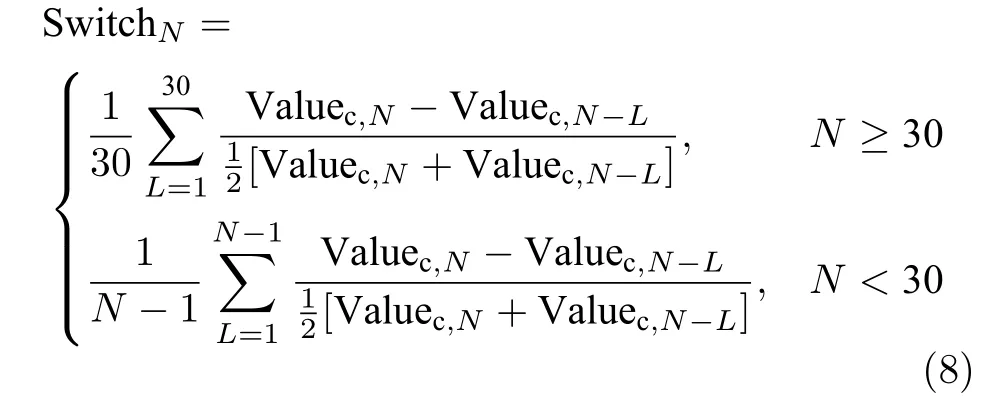
7)码率(BR)
码率能够较好地描述视频传输中的连接速度、传输速度、信道容量、最大吞吐量和数字带宽容量.不同的BR,最直接的表现为在终端播放出不同质量的视频,对于目前广泛采用的H.264 技术,其质量主要表现为模糊和块效应.在视频传输中,可以直接提取传输视频的BR.在仿真实验中,为了更好地阐述BR 对VQA 分数的影响,将参考视频经H.264进行压缩,其压缩后的视频的BR 分别取50 至10 000 的范围,从而来探讨BR 对视频质量的影响.
8)时延
在视频传输中,当传输1 个segment 的往返时间RTT (Round trip time)大于2 s 时,播放该segment必定发生卡顿,其卡顿带来的时延大小为(RTT-2) s;而在传输视频码流时,RTT 可以通过发送和接受ACK 的时间戳来计算得到,即两个时间点的时间差即可求出RTT;则在视频码流传输时,可以预测每一个segment 在即将播放时是否出现时延、出现时延的位置、时延长短等相关信息.基于此,结合视频质量评价的需要,视频传输可能影响其质量的时延特征量为:初始时延、中间单次中断时延、中断频率(次数)和平均中断时长,其值可从视频传输时直接获得.
3 视频质量客观评价方法
3.1 建立的视频数据集
为了获得性能优异的VQA 模型和结果,需要采用大量的样本对BP 神经网络进行训练.为此,采用开源视频库LIVE[27]中的10 个源视频和VIPSL[28]中的8 个源视频作为参考视频,分别对其进行不同BR 的压缩编码和不同方式的时延处理,得到两个数据集,分别记其为LIVEour和VIPSLour,共1 658 个失真视频.并采用21 位观察者,通过主观实验,得到其失真视频的主观质量评价分数(Mean opinion score,MOS).同时,计算出每个失真视频的空域信息及其感知特征和时域信息及其感知特征的参数值(即表1 中的特征1~ 特征6 的参数值),且提取码率和时延参数值(即表1 中的特征7~ 特征11 的参数值),共18 个参数值;以所有视频的每个参数值作为1 列,组成一个18 维的视频特征参数矩阵;由于各个特征参数值范围不同、物理意义不同,再对其进行归一化处理,归一化处理的方式即为每列的原始值除以该列的最大值.则以此方法得到失真视频特征参数矩阵及其主观质量评价分数MOS,如此,则每一 “视频特征参数矩阵加上MOS 分数”即为一个样本,从而构建训练样本.实验中,以此两个数据库中的视频特征参数矩阵作为神经网络的输入,主观质量评价分数MOS 值作为其输出,对所提VQA 模型进行训练和测试实验.其中,考虑到主观实验中个体的差异带给MOS 分数的偏差,采用所有观测者的质量评价分数的平均MOS 值作为神经网络的输出;另外,通过神经网络回归模型得出预测视频质量的分数,其对应为0~1 之间的结果,为了与不同模型的对比,可将其映射至0~ 100 之间,以其作为视频的客观质量分数.由于失真视频来源于不同的数据库,其特征差异较大,完全能够满足11 个特征量较大范围的取值.
3.2 基于多层BP 神经网络的VQA 方法基本框架
多层BP 神经网络对数据的回归在精度上具有较大的优势,其是一种多层的前馈神经网络.所提的基于多层BP 神经网络的VQA 方法(BP-VQA)主要分为3 步:第一步特征提取,第二步对设计的多层BP 神经网络进行训练,第三步采用训练好的VQA 模型对失真视频进行质量评价测试.其基本思路为:依据提出的方案和BP 神经网络的特征,采用上述描述的11 个特征的18 个参数值作为输入,主观MOS 作为输出,采用构建的LIVEour和VIPSLour 两个数据集中的样本数据来进行训练;通过大量训练,得到所需的多层BP 神经网络;再用训练好的神经网络评价其余部分的失真视频,预测出客观质量评价分数,并与其主观质量评价分数做相关性分析,计算其参数PLCC (Pearson linear correlation coefficient)、SROCC (Spearman rank order correlation coefficient)、OR (Outlier ratio)和RMSE (Root mean squared error),从而检验基于多层BP 神经网络的VQA 模型的评价性能.其构建的基本框架如图1.

图1 基于多层BP 神经网络的无参考视频质量客观评价方法流程图Fig.1 Flow chart of no reference video quality objective evaluation method based on multilayer BP neural network
3.3 多层BP 神经网络设置
对于多层BP 神经网络设置问题,需要综合模型精度、复杂性和泛化性能3 个方面来考虑.隐含层数越多、节点数越多、精度越高,但耗时越长,泛化性能越差,则需要合理选取隐含层数和节点数.文中采用理论分析与实验效果验证相结合的方法,不断优化选择,通过研究,设置的多层BP 神经网络如图2.
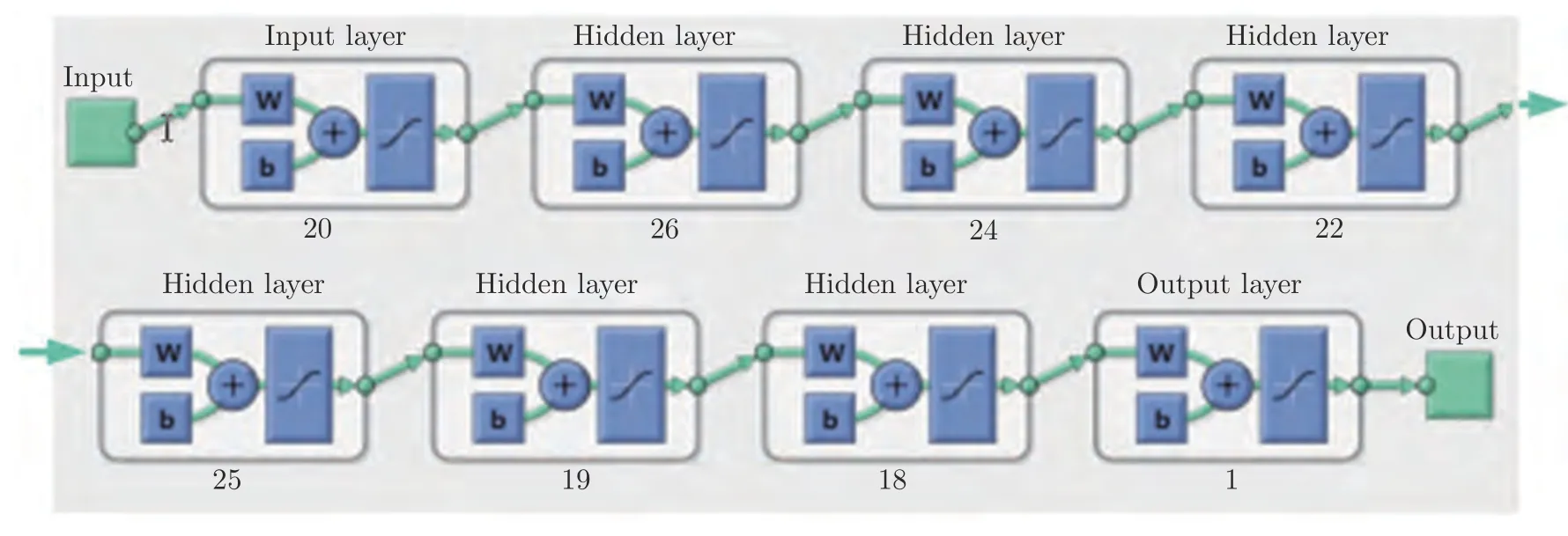
图2 设置的多层BP 神经网络结构图Fig.2 Designed multilayer BP neural network structure
对BP 神经网络的隐含层数目和每一层的节点数,设计方法如下:理论上,对于每一隐含层的节点数,依据式(9)[29]初步估计其值范围[a,b],再对范围中每个值进行实验,结合实验实际效果得出其最优值,同时兼顾模型复杂性,并且通过增加隐含层节点数来抵消因减小隐含层数目而带来的误差,从而尽量减少隐含层的数目.

式中,m为当前隐含层节点数,n为前一层或输入节点数目,l为后一层或输出节点数目.通过式(9)计算和结合其实际效果,得出各层节点数目依次为26、24、22、25、19和18.
仿真中,BP 神经网络的训练参数设置为:学习率(Learning rate) 为0.01,误差目标期望值为0.001,迭代次数epochs 为500,显示间隔次数为25.
4 实验及结果
按照以上设计的VQA 方法,对构建的视频数据集进行仿真实验.实验中,训练和测试样本共1 658组数据.实验中,为了使选取的数据具有更好的随机性,在训练和测试之前,将所有组的数据按组进行乱序,即选取训练和测试样本时,其是置乱后任意选取的一定比例的数据作为训练和测试样本.
在BP-VQA 模型设计中,训练样本集及其来源、测试样本集及其来源、训练样本和测试样本比例等均对模型的精度有较大的影响.则实验采用以下3 种方式进行:1)采用同一数据库中的样本进行训练和测试,2)采用两个数据库中的样本交叉训练和测试,3)采用不同比例的样本训练和测试.依据此3 种方式仿真,其实验结果分别如下.
1)同一数据库中的样本进行训练和测试
分别采用LIVEour和VIPSLour 数据库中各自80 %的数据作为训练样本,剩余20 %的数据作为测试样本进行测试,得到其质量客观分数,然后结合数据库中的主观分数,计算其主客观评价分数之间的相关性参数值PLCC、SROCC、OR和RMSE,同时得到主客观评价分数之间的散点图,以及预测值与原始值之间的比较图.其结果如表2、图3和图4.

图3 LIVEour 数据库中(80 %训练,20 %测试)实验结果Fig.3 Experimental results in LIVEour database (80 % training,20 % testing)
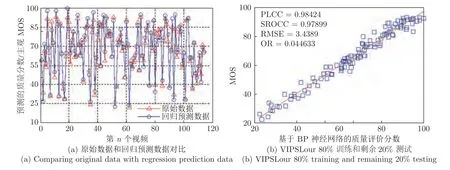
图4 VIPSLour 数据库中(80 %训练,20 %测试)实验结果Fig.4 Experimental results in VIPSLour database (80 % training,20 % testing)

表2 计算的4 个相关性参数值Table 2 Calculated results of four correlation parameters
上述实验结果表明,采用同一数据库中的样本进行训练并测试时,所提VQA 模型精度非常高.
2)两个数据库中的样本交叉训练和测试
实验采用两种方式进行:a) 采用LIVEour 中100 %的数据作为训练,任意选取VIPSLour 中20 %数据作为测试;b) 采用VIPSLour 中100 %的数据作为训练,任意选取LIVEour 中20 %数据作为测试.从而得到客观VQA 分数.结合主观MOS值,得出其主客观分数一致性分析结果,即4 个相关性参数值、散点图和预测值与原始值之间的比较图,结果如图5、图6和表3.
图5、图6和表3 的结果表明,该方式得出的散点图和比较图的相关性效果明显差于采用相同数据库作为训练和测试时的效果,相应的4 个相关性参数值与之相比,也明显偏小;但相对于目前现有的常用VQA 模型和基于传统方法构建的VQA 模型来说,所提模型的PLCC和SROCC 值均明显高于0.8,其精度明显高于传统方法.

表3 计算的4 个相关性参数值Table 3 Calculated results of four correlation parameters
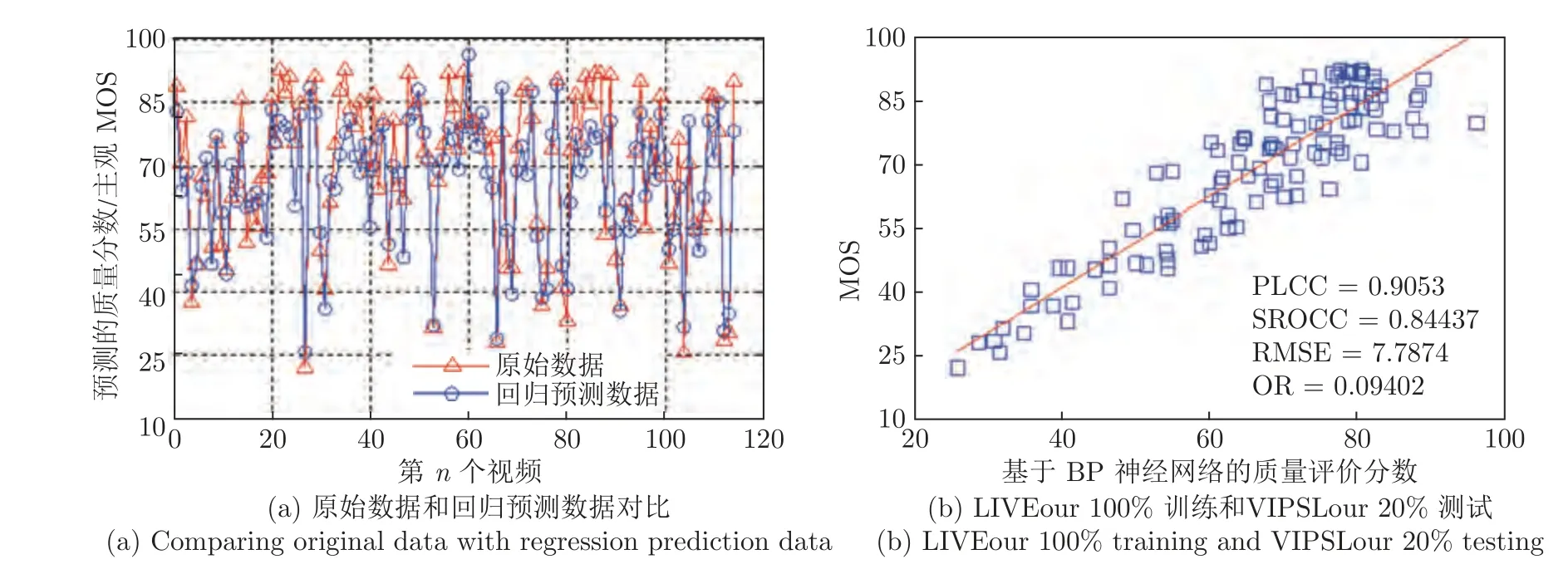
图5 LIVEour 100 %训练和VIPSLour 20 %测试的实验结果Fig.5 Experimental results from training by 100 % samples in LIVEour and testing 20 % samples in VIPSLour
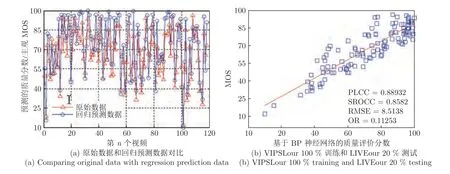
图6 VIPSLour 中训练(100 %样本) LIVEour 中测试(20 %样本)的实验结果Fig.6 Experimental results from training by 100 % samples in VIPSLour database and testing 20 % samples in LIVEour database
3)采用不同比例的样本训练和测试a) 同一数据库中不同比例的样本训练和测试分别在LIVEour和VIPSLour 各自数据库中,依次采用90 %、70 %、50 %、30 %的数据作为训练,其对应剩余10 %、30 %、50 %、70 %的数据作为测试来进行实验.并做主客观分数一致性分析和计算其相关性参数,其结果如表4.
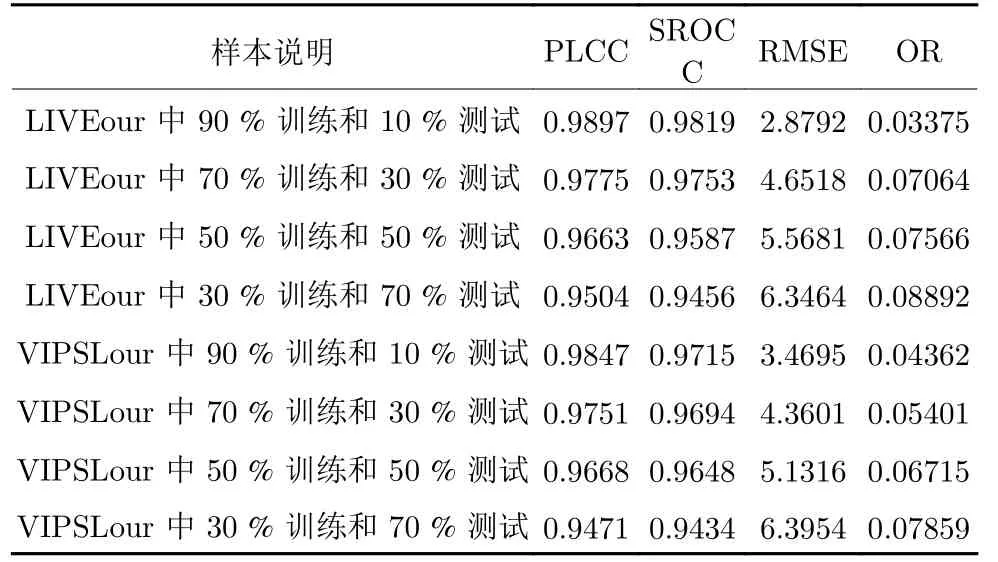
表4 计算的4 个相关性参数值Table 4 Calculated results of four correlation parameters
b) 不同数据库中不同比例的样本训练和测试
在LIVEour 中分别选取80 %和50 %数据作为训练和对应在VIPSLour 中选取20 %和50 %作为测试,以及在VIPSLour 中分别选取80 %和50 %数据作为训练和对应在LIVEour 中选取20 %和50 %作为测试来进行实验.并做主客观分数一致性分析和计算其相关性参数,其结果如表5.
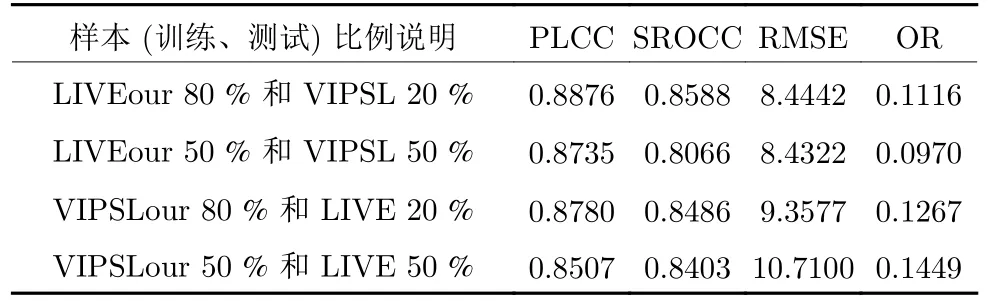
表5 计算的4 个相关性参数值Table 5 Calculated results of four correlation parameters
表4和表5 中相关性数值表明:1)对于所提的BP-VQA 模型,当在相同数据库中选择样本训练和测试时,即使在30 %的数据训练下,其精度仍能达到PLCC 为0.9471,而且当训练样本为90 %时,其评价精度能够实现达到PLCC 为0.9897,其结果表明所提模型精度非常高,而且是在两个不同类型的视频数据库中得出的结果;2)对于两个数据库中交叉选择训练和测试样本时,其模型仍然表现为精度较高,在训练样本为50 %时其能够达到0.8507,表明该模型具有较高的泛化性能.
分析上述3 种情况的实验结果,可以得出:1)在同一数据库中,不论训练和测试样本比例如何,所提模型的精度均较高,即使在30 %的训练样本下,其PLCC 值也能达到0.9471;2)对于同一数据库中不同比例的训练和测试样本的实验结果,训练样本占比越大,测试时,PLCC 值越大,所提模型的精度越高,说明训练和测试样本比例对模型精度影响较大,分析其原因,主要在于,当训练样本不足时,训练样本不足以囊括测试样本中所有有效视频特征,以致训练得出的模型对部分测试样本不能有效地预测,部分预测值与主观评价分数存在差异;3)对于交叉数据库中不同比例的训练和测试样本的实验结果,所提模型的精度PLCC 值也能均在0.8507 以上,表明所提VQA 模型具有较高的精度和泛化性能;4)对比现有的基于传统数学建模构建的VQA模型,如PSNR、VSNR、SSIM、VQM、ST-MAD和MOVIE,无论是其精度、还是其泛化性能,均得到了较大的提升.
5 讨论
对于视频质量评价模型,评估其性能的要点主要为:1)精度,2)泛化性能,3)模型复杂性.基于此,从此3 个方面来分析所提VQA 模型的性能.
5.1 VQA 模型精度对比分析
在视频质量评价中,评估VQA 模型精度优劣的方法是分析主客观质量分数之间的一致性,其一般采用PLCC和SROCC 值来描述VQA 模型的精度.为了说明所提模型的精度,将其与现有的VQA模型作以下对比:1)与基于机器学习的VQA 模型的精度对比,2)与基于传统数学建模方法的NR-VQA模型的精度对比,3)与全参考VQA 模型的精度对比,其对比结果如下.
1)与基于机器学习的VQA 模型的精度对比
将所提模型与近些年提出的6 种基于机器学习的VQA 模型进行精度对比,其6 种模型为:VQAUCA[14]、V-CORNIA[15]、NR-DCT[17]、V-BLIINDS[18]、3D-DCT[20]和COME[21],其实验仿真结果如图7.
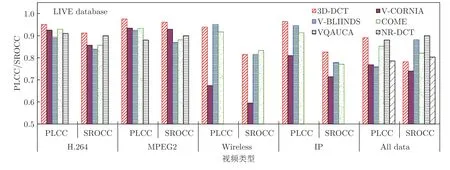
图7 采用现有6 种基于机器学习的VQA 模型评价结果的PLCC和SROCCFig.7 PLCC and SROCC of VQA results with 6 existing models based on machine learning
该对比的6 种模型的结果均为采用LIVE 数据库中150 个视频的实验结果;该150 个视频数据包括H.264、MPEG2、Wireless和IP4 个方面的失真,其对应的失真视频数据为40、40、40和30 组[21];其评价结果均为采用数据的80 %训练和20 %测试的实验结果.为了对比的公平性,选取本研究中同一数据库中的不同训练和测试样本比例下的实验结果与其对比,其结果如图8.
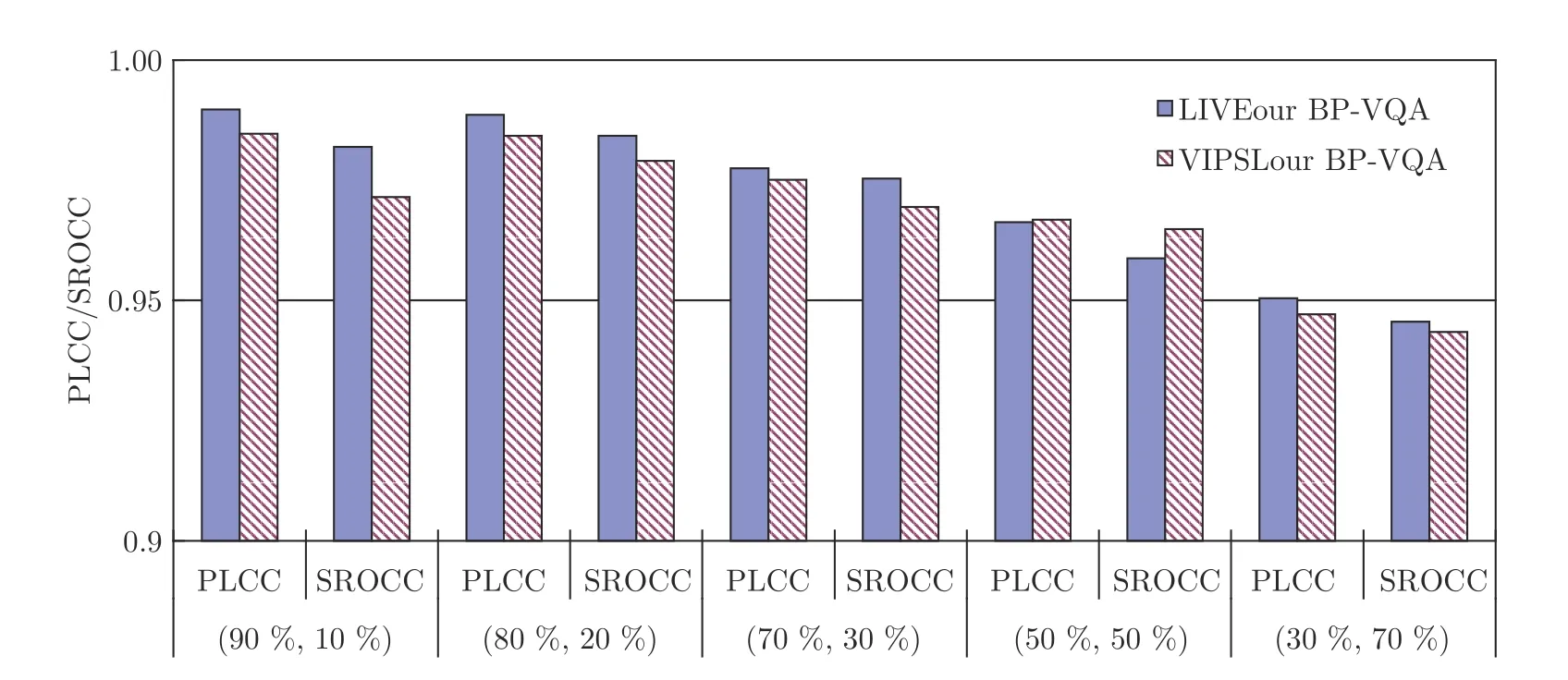
图8 不同训练和测试样本比例下采用所提BP-VQA 模型评价结果的PLCC和SROCCFig.8 PLCC and SROCC from applying the proposed BP-VQA model to evaluate video quality under different training and test sample ratios
从图7和图8 的对比结果可以看出,在相近的训练和测试样本比例下,本文所提的BP-VQA 模型的PLCC、SROCC 值均高于现有的6 种VQA模型的值,其幅度为PLCC 平均高13.96 %;则从精度对比上,所提模型优于此6 种VQA 模型.分析其原因,主要因为:a) VQA 模型在考虑影响视频质量因素的全面性上存在较大差异,6 种前人所提模型只考虑了4 大影响视频质量因素(即视频内容、编解码失真、传输失真和视觉特性)中的部分特征,即,VQAUCA[14]主要是针对H.264/AVC 失真视频、通过帧内预测的量化分析而提出的一种基于编解码分析的NR-VQA 模型,V-CORNIA[15]是一种基于码本表达的NR-VQA 模型,NR-DCT[17]是一种基于DCT和6 个传输失真特征而构建的VQA模型,V-BLIINDS[18]是一种基于视频场景特征统计和感知特征的VQA 模型,3D-DCT[20]是一种基于三维DCT 域的时空自然视频失真统计特征的NRVQA 模型,COME[21]是一种基于视频空域和时域失真特征的VQA 模型;而所提模型不仅考虑了视频内容特征、编解码和视觉特性,还考虑了传输中的时延失真特征;则相对于此6 种VQA 模型,所提模型考虑影响视频质量的因素更为全面;b) 采用的机器学习方法不同,6 种现有模型中,VQAUCA、VCORNIA、V-BLIINDS和3D-DCT 均是采用SVM 进行视频质量预测、NR-DCT 是采用多层神经网络,COME 是采用卷积神经网络提取视频失真特征和采用多元回归预测视频质量分数;对于SVM、神经网络和多元回归方法而言,在相同条件下,神经网络方法效果优于SVM和多元回归方法;而本文所提模型采用了多层BP 神经网络,所以其效果优于此6 种现有VQA 模型.
2)与基于传统数学建模方法的NR-VQA 模型的精度对比
将所提模型与现有的3 种基于传统数学建模构建的无参考VQA 模型的精度进行对比,3 个模型为C-VQA[16],NVSM[19]和BRVPVC[30].为了对比的公平性,所提BP-VQA 模型的结果均采用同一数据库中50 %训练和50 %测试的实验结果,其对比结果如表6.
从表6 中的对比结果可以看出,所提BP-VQA模型的精度明显高于基于传统数学建模方法构建的VQA 模型的精度.
3)与全参考VQA 模型的精度对比
目前,在VQA 的研究和实际应用中,主要仍是采用传统的全参考质量评价方法,如PSNR、SSIM[8]和MOVIE[11]等.为此,将所提BP-VQA 模型与6种经典的全参考视频质量评价模型(即PSNR、VSNR[7]、SSIM[8]、VQM[9]、ST-MAD[10]和MOVIE[11])的精度进行对比,其结果如图9.其中,所提模型均是采用50 %训练和50 %测试的结果.
通过图9 的精度对比,可以发现,所提模型的精度均明显高于基于传统数学建模方法构建的全参考VQA 模型的精度,而且其高出幅度最小为10.67 %.
综合分析表6和图9 的结果,可以得出,相对于传统方法构建的无论是NR-VQA 模型,还是FRVQA 模型,采用多层BP 神经网络构建的VQA模型,其精度明显得到了较大的提升.表明采用机器学习方法构建VQA 模型在提高精度上具有较大的优势.

图9 所提BP-VQA 模型与6 种现有FR-VQA 模型的精度对比Fig.9 Accuracy comparison between the proposed BP-VQA model and six existing FR-VQA models

表6 所提BP-VQA 模型与3 种NR-VQA 模型的精度对比Table 6 Accuracy comparison between the proposed BP-VQA model and three existing NR-VQA models
5.2 模型复杂性分析
对于VQA 模型复杂性,一般采用评价视频质量时算法的运算时间来描述,其运算时间越短,模型的复杂性越低.基于此,将所提BP-VQA 模型与现有10 种VQA 模型的复杂性进行对比,其10 种模型为:PSNR、VSNR[7]、MS-SSIM[8]、VQM[9]、STMAD[10]、MOVIE[11]、V-CORNIA[15]、V-BLIINDS[18]、COME[21]和BRVPVC[30].实验采用MATLAB-2014a 编程语言,在64 位操作系统的DELL Core i7 笔记本上进行仿真,其处理器为Intel(R) Core(TM)i7-8550U CPU @1.80 GHz 1.99 GHz.为了对比的需要,采用每种模型平均评价10 帧图像时算法运行的耗时来比较,其结果如图10.
从图10 中模型复杂性对比的结果上看,所提BP-VQA 模型的复杂性处于11 种方法中的中等水平.比PSNR和SSIM 模型的复杂性高,但低于VQM、MOVIE和ST-MAD.
对比分析图10 的实验结果,结合每种VQA 模型的特点和计算公式,其复杂性主要存在于3 个过程中:1)视频特征提取,2)模型训练,3)视频质量评价.分析每一过程,模型复杂性的原因主要为:1)除了PSNR、SSIM、VSNR和COME 外,其余模型均需要提取大量的视频特征,并对其进行计算,该过程耗时基本上占据了整个模型运算耗时的90 %,其是模型复杂的主要原因;2)对于基于机器学习的VQA 模型,一般需要对模型进行训练,其耗时同样比较长,而且,为了使得所提模型的精度更高、模型更具有泛化性能,一般需要采用大量的样本对其训练,致使其耗时很长;3) 在设计基于机器学习的VQA 模型时,为了提高精度,对于每一隐含层,尽量增加隐含层的数目和每一层的节点数目,致使模型评价视频时耗时更长,而且不仅耗时长,其模型的泛化性能会明显下降;4)对于采用训练好的模型对视频质量的评价的耗时,一般时间非常短,基本上不影响模型的复杂性;5)对于所提模型,其复杂性主要在视频特征提取上占时较多,在其特征提取中,其提取了11 个特征,共18 个参数,所以耗时稍长;但综合精度和复杂性,其实际应用效果更好.
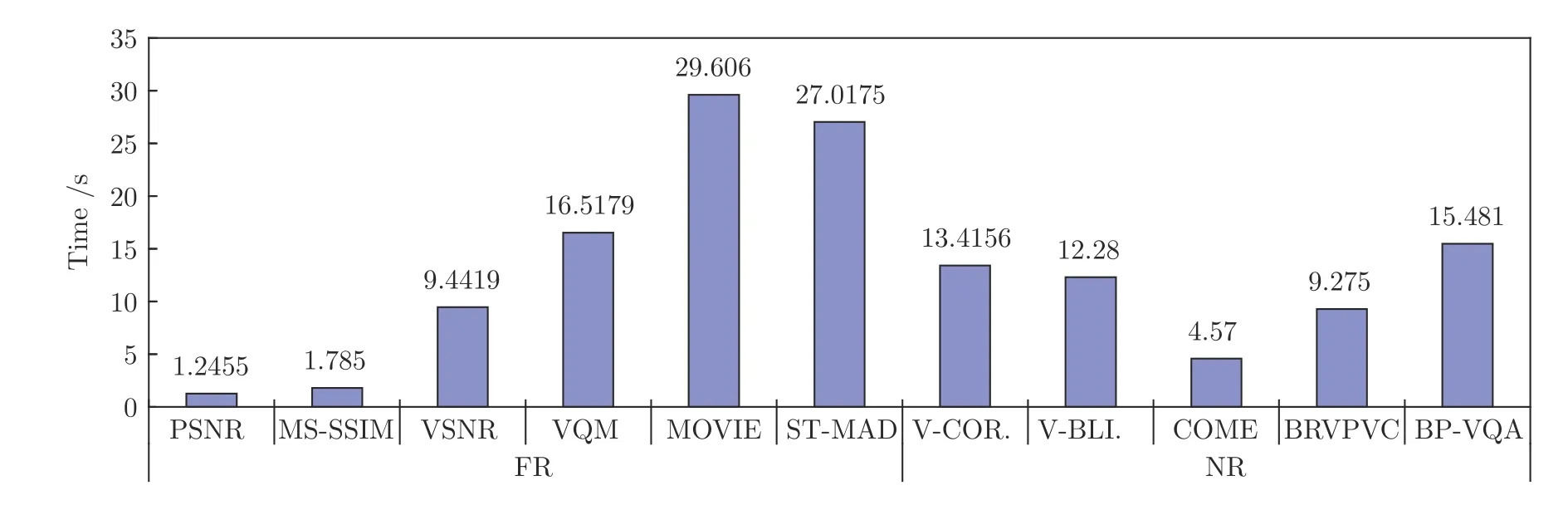
图10 所提模型与10 种现有VQA 模型的运算耗时对比Fig.10 Comparisons of the computational time between the proposed model and 10 existing VQA models
5.3 泛化性能分析
为了说明所提BP-VQA 模型的泛化性能,将其与8 种现有VQA 模型的泛化性能进行比较,其8 种方法为:VQM、ST-MAD、MOVIE、3D-DCT、VQAUCA、V-BLIINDS、NR-SVR (NR-VQA used support vector regression)[31]和NR-MLP (NRVQA used multilayer perceptron for nonlinear mapping)[31],8 种模型的结果分别来自于LIVE、VQEG、IRCCyN、CSIQ[32]、EPFL-PoliMI[1]、IVP[33]和Lisbon[34]数据库中失真视频仿真的实验结果.为了说明模型泛化性能的优劣程度,采用实验结果的PLCC和SROCC 大小来比较,其对比结果如图11.

图11 所提模型与8 种现有模型的泛化性能对比Fig.11 Comparison of generalization performance between the proposed model and 8 existing models
从图11 中可以直观地得到:1)在不同的数据库中,除了VQM 在EPFL-PoliMI 数据库中的结果稍好外,所提模型的评价结果的PLCC和SROCC值明显高于8 种现有模型的评价结果的PLCC和SROCC 值,表明其泛化性能好于该8 种模型;2) 8 种模型中,3D-DCT、NR-SVR、NR-MLP、VQAUCA、V-BLIINDS 同样是基于机器学习的VQA 模型,从图11 中的结果可以看出,无论是在同一数据库中训练和测试,还是在不同数据库中训练和测试,所提模型的测试结果即PLCC、SROCC 值基本上都高于该5 种模型的测试结果,表明,在结合机器学习的VQA 模型中,所提模型具有更高的泛化性能;3)本文所提模型在交叉数据库中进行了实验,对于训练和测试样本采用不同数据库的做法,在其他几种方法中基本没有相关报道,而且,在此情况下,所提模型的评价结果的PLCC和SROCC 值均超过了0.8.这也表明本文所提VQA 模型具有更好的泛化性能;4)所提模型在不同数据库和交叉数据库中实验时,其评价结果的PLCC和SROCC 值均比较平稳,而其他8 种模型,在不同数据库中,均表现出评价结果的不稳定性;且本文的模型的精度均超过了0.8,这也表明,本文所提模型具有更好的泛化性能.
分析所提模型泛化性能较优的原因,主要为:1)对于结合多层BP 神经网络的VQA 来说,一般为了其模型的精度要求,尽量增加隐含层数和每一层的节点数;的确,二者增加了,模型精度能得到提高,以致往往采用深度学习的方法进行,甚至让隐含层增加到20 层以上,每一层的节点达到30 个以上;但是在精度提高的同时,模型的复杂性也极大地增加了,而且泛化性能也明显下降;对于所提模型,通过实验验证和理论分析相结合,刚好精度达到极大时,选取其合适的层数和节点数目,并且如果再增加层数和节点数,对模型精度的提高非常有限,所以所选的隐含层数和节点数是最少的,则此时,相对来说,层数和节点数对泛化性能的影响最小;同时也说明,在结合机器学习的VQA 研究中,应尽量减少隐含层数和节点数.2)对于结合机器学习的VQA 评价中,往往为了提高精度,提取较多的影响因子,并且每个影响因子采用多个参数来描述,但是,不同的视频,其特征均有较大的差异,则需要选择更多的特征,由此反而限定了待测视频,没有考虑其他视频的特征,以致在评价其他数据库中的视频时,其PLCC和SROCC 值均明显下降,表现出较差的泛化性能;而对于文中所提模型,基本上考虑了VQA 中影响视频质量的4 个大的方面因素,并且只采用了11 个特征进行描述,相对来说特征相对较少,所以对泛化性能的影响也较小.而相对于NR-SVR、NR-MLP、VQAUCA、V-BLIINDS4 种模型来说,其提取的特征均较多,甚至特征参量达到36 个之多,其不仅严重影响了VQA 模型的泛化性能,而且其复杂性也比较高.所以,通过对比分析表明,所提模型的泛化性能优于该8 种VQA 模型.
6 结论
结合多层BP 神经网络,针对视频的4 个主要影响因素,即编解码影响、传输条件、视频内容和HVS 特性,研究了无参考视频质量评价方法,构建了VQA 模型.在研究中,首先采用图像的亮度和色度及其视觉感知、图像的灰度梯度期望值、图像的模糊程度、局部对比度、运动矢量及其视觉感知、场景切换特征、比特率、初始时延、单次中断时延、中断频率和多次中断平均时长共11 个特征来描述4个主要影响视频质量的因素,并提取相关的特征参数;再以其作为输入节点,采用多层BP 神经网络,通过建立的两个视频数据库中的大量视频样本对其进行训练学习,构建VQA 模型;最后,将所提模型应用于构建的视频数据库中,对失真视频进行评价仿真实验,且与14 种现有的视频质量评价模型进行对比分析,研究其精度、复杂性和泛化性能.实验结果表明:本文所提模型的精度明显高于其他14种模型的精度,其精度最低高出幅度为4.34 %;且其泛化性能优于它们,同时其复杂性处于该15 种模型中的中间水平.综合分析所提模型的精度、泛化性能和复杂性表明,所提模型是一种较好的基于机器学习的视频质量评价模型.
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
电子制作(2019年19期)2019-11-23 08:42:00
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
电子制作(2018年11期)2018-08-04 03:25:38
数学学习与研究(2017年3期)2017-03-09 18:12:42
测绘科学与工程(2016年5期)2016-04-17 06:51:15
重型机械(2016年1期)2016-03-01 03:42:04
中国老区建设(2016年1期)2016-02-28 09:32:00
大连工业大学学报(2015年4期)2015-12-11 04:06:52
海军航空大学学报(2015年4期)2015-02-27 13:45:47
