
智能终端深度学习计算卸载决策技术研究
2022-03-09 02:10崔思静李宝荣潘碧莹
广东通信技术 2022年2期
[崔思静 李宝荣 潘碧莹]
1 引言
近年来,随着人工智能(AI)技术的不断演进,终端芯片制造厂商推出的中高端芯片都提供了深度神经网络(DNN)模型的加速计算能力,AI 应用程序逐渐被广泛落地于终端设备。尽管新一代智能终端的AI 处理单元能力越来越强大,但受限于设备自身有限的资源,AI 应用的计算强度、内存消耗和功耗备受关注。终端设备以及部分边缘设备对离线运行完整的DNN 模型推理,仍存在着严格的计算、内存和能耗成本限制。
通过DNN 模型计算卸载的方式,将全部或部分的模型计算任务卸载到其他设备(包括云设备、边缘设备或终端设备)上,是近年终端设备控制AI 资源成本的主要研究方向之一。以设备间协同推理计算的方式,能减轻原设备上计算、内存占用、存储、功率和所需数据速率的压力,同时减小推理延迟,提高AI 应用的服务质量(QoS)。
本文即针对智能终端设备的DNN 计算卸载决策展开研究,文中第2 节介绍DNN 计算卸载决策技术发展现状,第3 节针对智能终端特性对DNN 计算卸载系统管线进行进一步研究,同时提出一种适合智能终端AI 应用落地的模型潜在分割点搜索策略,并在第4 节进行系统仿真实验,最后在第5 节给出总结和展望。
2 计算卸载决策技术现状
计算卸载决策主要解决的是终端设备决定卸载什么、卸载多少以及如何卸载的问题[1]。在DNN 模型计算卸载决策中,根据设备的处理能力、资源占用情况和网络环境,将DNN 模型中计算密集、耗能密集的部分卸载到其他节点设备,而将隐私敏感和延迟敏感部分留在终端设备。由终端设备执行模型特定部分的推理计算,再将剩余计算和中间结果发送到其他节点,由接收到计算任务和结果的一个或多个节点完成剩余部分的模型推理计算,并最终将推理结果返回给原终端设备。
DNN 模型结构可被看作有向无环图(DAG)。基于DNN 模型的计算卸载决策,则需基于模型结构确定一组潜在的切割边(即分割点),根据如最低计算时延、最小计算能耗等优化目标,从该组分割点中择出最优的分割点和分割模式。根据所选分割点将DNN 模型计算分解成多份计算任务,保证本地计算任务所需资源低于本设备可用资源的上限,同时优化设备和各参与节点设备的计算、存储/内存、功率、通信资源的消耗。
如何确定模型内所有的潜在分割点,是DNN 模型计算卸载决策的关键之一。在研究领域,一种常见的方式是将DNN 模型内的每个神经网络层(如卷积层、池化层、全连接层等)视作DAG 的顶点,将层与层之间的每一条边作为潜在的分割点[2~4],以神经网络层为子任务单位,在设备之间分配计算任务。而针对资源受限的IoT 设备,则倾向于创建更细腻的计算任务颗粒度,通过模型并行技术,将卷积层和全连接层中的矩阵运算进一步分解为几个可并行的矩阵运算操作[5,6],以每个操作节点作为DAG 中的顶点,可形成一组更加细致的模型潜在分割点。
确定潜在分割点后,即须根据优化目标对每个可能的计算任务进行性能分析,以从中选择最优的分割点和分割模式。经典的方法如Neurosurgeon[2],对每个参与协同计算的设备,采用回归模型对不同种类的神经网络层进行计算时延或能耗的建模,以预测特定模型层在指定设备上所需要的时延或能量。另一方面,文献[3]认为设备软硬件对连续的模型层存在加速行为,将每个模型层独立出来做性能分析会存在一定偏差,应对给定模型中的所有神经网络层组合作分析。这对智能终端可适用的DNN 模型计算卸载决策技术来说有借鉴意义。
3 基于智能终端的DNN 模型计算卸载决策研究
3.1 DNN 计算卸载系统管线设计
在管线设计中,智能终端可参与的DNN 模型计算卸载可分为DNN模型准备和协同计算两个阶段,如图1所示。
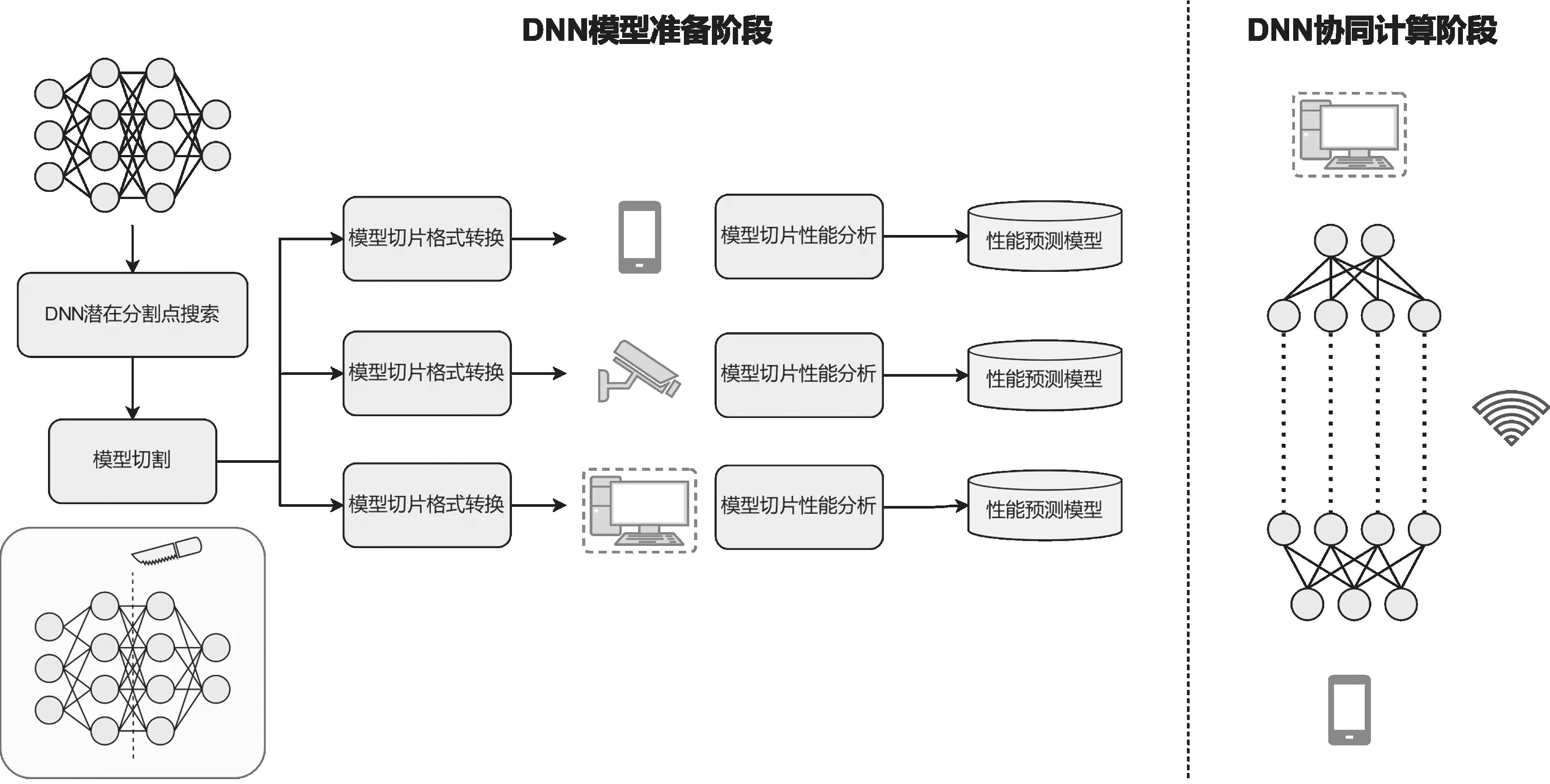
图1 智能终端可参与的DNN 计算卸载系统管线
3.1.1 DNN 模型准备阶段
对于智能终端DNN 模型计算卸载决策技术的研究,还需结合智能终端AI 技术栈的特性讨论。当前各大终端芯片厂商如苹果、华为海思、高通、联发科等已相继地在其终端产品上配备了NPU、AIP 和APU 等专用的AI 加速硬件单元芯片,并相应推出了芯片专用的AI 模型格式。这要求应用开发者在推出终端AI 应用前,须使用芯片厂商提供的模型转换工具,对已训练好的DNN 模型进行格式上的转换。由于涉及工序繁琐,耗时较长,为不影响计算任务的分配和生成,模型切割需在协同推理决策前完成,这意味着DNN 模型内所有潜在分割点须被提前定位。
在模型准备阶段,首先对给定的DNN 模型进行潜在分割点搜索,随后按照模型内所有潜在的分割点,对DNN 模型进行切割,并将切割后的模型(模型切片)转换成目标智能终端芯片专用的模型格式。在完成格式转换后,对各模型切片在设备上的执行性能进行分析。如何结合智能终端特性,找出DNN 模型内的潜在分割点,将在3.2节中展开。
3.1.2 DNN 协同计算阶段
结合协同计算中的数据链条考虑,终端作为最靠近用户的设备,其内数据通常都与用户信息紧密相关。在使用智能终端进行DNN 模型计算卸载时,应同时考虑到用户的隐私安全,在管线中的协同计算阶段引入相关保护机制。
DNN 模型计算推理阶段,主要可包括5 个功能模块,分别是启动和预处理、DNN 模型计算任务卸载决策、DNN 模型计算任务执行、消息收发和后处理模块。下面以协同计算场景中“任务发起方”“任务接收方”两类设备角色为例,描述各模块功能。
(1)启动和预处理模块:任务发起方在启动后,首先确定需进行计算卸载的DNN 模型信息,再调用DNN模型计算任务卸载决策模块。同时,任务发起放根据所用模型,对原始输入数据进行相应的预处理,以备后用。另一方面,任务接收方在启动后即注册监听任务请求。
(2)DNN 模型计算任务卸载决策模块:任务决策算法置入该模块中。以每个模型切片的计算为子任务,根据模型切片的性能分析结果,将各子任务组合并分配到合适的设备上以达到给定的优化目标,输出任务分配信息。
根据新时期人才培养的要求和目标,要求毕业时具有创新能力和工程实践能力的应用型高级人才培养目标和要求等,能够运用所学理论解决实际生产问题,因此,有效地实施案例教学法,可以将理论与生产实践相结合,使学生感到所学课程与自己毕业后所从事的工作是密切相关的,认识到在学校期间要学好专业课,从而激发学生的学习热情和积极性,除了学习基础理论知识,还要积极参与生产实践活动,在整个学习过程中,不断将理论与实践有机结合起来,通过实践和理论学习,从感性认识上升到理性认识,能够举一反三、融汇贯通和触类旁通,缩短理论教学与实际生产实践相脱离的差距,使学生在毕业后很快适应工作岗位的工作。
(3)DNN 模型计算任务执行模块:根据卸载决策模块输出的任务分配信息,模型计算任务执行模块确定需要在本地和远端执行的子任务(即模型切片),构建并执行本地的计算任务。对任务发起方而言,在确认本地任务后,以预处理输入数据作为输入,执行相应的模型切片计算。若无远端计算任务,任务发起方即调用后处理模块对计算结果进行解析,得到模型最终推理结果;若存在远端计算任务,则根据任务分配信息将计算结果发送至下一个设备,并调用消息收发模块监听最终结果的返回。对任务接收方来说,在确认本地任务后,即根据任务分配信息监听上一个设备传输的计算结果,以该结果为输入完成执行本地任务计算后,调用消息收发模块将计算所得发送至下一个设备。
(4)消息收发模块:主要负责计算结果、计算任务信息等消息的发送、监听和接收,根据协议组装或解析相关数据。同时,该模块中可置入数据隐私增强相关算法,如差分隐私[8]和多方安全计算[9]等,以保护数据中的隐私信息不被泄露。
(5)后处理模块:负责解析最终计算结果,得到DNN 模型的最终推理结果。以图像识别应用为例,后处理模块将计算结果进行标签解码,输出图像的标签作为识别结果。该模块仅位于任务发起方,其目的是使任务接收方对计算结果的用途不可知,从一定程度上保护用户的隐私。
3.2 DNN 模型潜在分割点搜索
如第2 节所述,DNN 模型计算卸载中的子任务单位通常为神经网络层,或对神经网络层内的运算做进一步分解,产生更小颗粒的子任务、更多的潜在的分割点。此类分割颗粒度对智能终端来说并不经济。一方面,越细化的模型分割意味着在模型准备过程中会产生越多的模型切片,模型格式的转换工作也随之成比例增加,这将使得整个模型生成的周期被延长。另一方面,设备软硬件对连续的神经网络层有加速的效果,而智能终端的AI 芯片对常用的神经网络层运算也设计了加速优化,若以一个神经网络层或网络层中一部分运算作为一个模型切片,将失去这些优化所带来的效益。
此外,潜在分割点数量的增加会增加协同计算阶段中DNN 模型计算任务卸载决策模块的压力,面对体量较大的DNN 模型,需要评估数百甚至上千个可能的分配策略,这对执行计算卸载决策的设备提出了较高的算力要求。对于需要终端侧决策的场景来说,这将成为一个可能的计算瓶颈。
综合考量,为尽可能缩短终端AI 模型生成周期、保证DNN 模型计算速度,同时使计算卸载决策更加轻量,在模型准备阶段需在神经网络层的基础上进一步缩小潜在分割点的范围,放大子任务颗粒度,减少子任务的组合可能。
本文提出一种潜在分割点预判策略,从优化计算卸载过程中可能的时延开销的角度出发,对DNN 模型内以各神经网络层为单位的子任务做进一步组合,如表1 所示。除了模型计算时延,计算卸载的时延开销还包括数据传输时延,该时延与其所传输的数据量呈正比。当分割点逐步向模型深层移动时,本地终端上需要计算的神经网络层将增加,其计算时间也将随之单调递增。而中间数据的传输时间未必会随着计算层数的增加而递增,如卷积层的输出结果常保持输入和输出数据的大小一致,而池化层则有数据降维的作用。因此,可遵循计算顺序,以输出数据量递减为原则,筛选潜在分割点,生成以模型块为单位的子任务,每个模型块中可包含一到多个连续的神经网络层,在本地计算时间递增的情况下,保持通信工作量是递减的。

表1 DNN 模型潜在分割点搜索伪代码表
4 系统实验
4.1 DNN 模型分割
实验中使用的DNN 模型为VGG16[10]。如图2 所示,基于3.2 节的DNN 模型潜在分割点预判测策略,相比于将每个神经网络层连接视作潜在的分割点,本方案显著减少了潜在分割点的数量,使模型准备阶段中的模型切割和格式转换工作得到简化。如表2 所示,VGG16 最终被分割成7 份模型切片,即7 个子任务,可有效缩小卸载决策的搜索空间,从一定程度上可加速决策过程,节省端侧资源。

图2 VGG16 各神经网络层输出数据量及 所提出搜索策略所得模型潜在分割点图

表2 基于策略所得潜在分割点划分的子任务
4.2 仿真实验结果
仿真实验建立在“终端-边缘”参与的DNN 协同推理场景上。由Rasperry Pi 4b(RPi)作为任务发起设备,与边缘设备PC 协作完成基于ImageNet[16]图像识别的VGG16 模型计算任务,并利用Docker 容器[12]创建相关软件堆栈。详细的设备信息参如表3 所示。仿真系统使用Python3 及TensorFlow 机器学习框架[11]。设备通信基于无线LAN,采用protobuf 和gRPC[13]进行数据传输。

表3 仿真设备信息
系统管线中的DNN 模型计算任务卸载决策模块设置于RPi 终端侧,以设备间协作完成推理运算的总耗时最小为优化目标。推理过程的时延具体包括模型切片在各设备上的计算时延,以及中间结果的传输时延。在“设备A-设备B”协同场景下,假设模型M 已被分割为N 个子任务{Mslice1,Mslice2,…,MsliceN},则需找到一个最优卸载点k,1 ≤k≤N,使
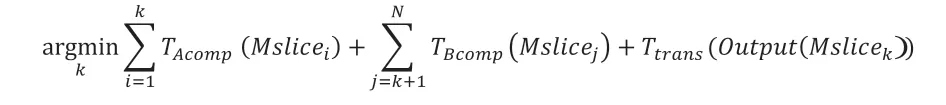
其中,TAcomp(Mslicei)为子任务Mslicei在设备A上运行时预计所需计算时延,TBcomp(Mslicej)为子任务Mslicej在设备B 上运行时预计所需计算时延。Output(Mslicek)为子任务Mslicek输出的中间结果,Ttrans(Output(Mslicek))则是该结果从A 传输至B 时预计所需时延。得到最优卸载点k后,子任务集合{Mslicek+1,…,MsliceN}组成设备A 的计算任务,{Mslice1,…,Mslicek}则为设备B计算任务。
实验中子任务计算时延通过统计历史计算时延获得。在不同的网络带宽下,系统基于不同的卸载点预测得到不同的模型协同推理耗时如图3 至图6 所示。由图3 可见,RPi 本地计算从block6 子任务上开始出现明显的瓶颈,这是由于block6 和block7 主要为全连接层的计算,它涉及大量参数加载,RPi 自身内存无法满足其需求,会使用芯片外存储作为交换内存,致使执行性能大受影响。RPi 最终的卸载决策结果如表4 所示。

表4 各带宽下DNN 计算卸载决策后各设备计算任务分配情况
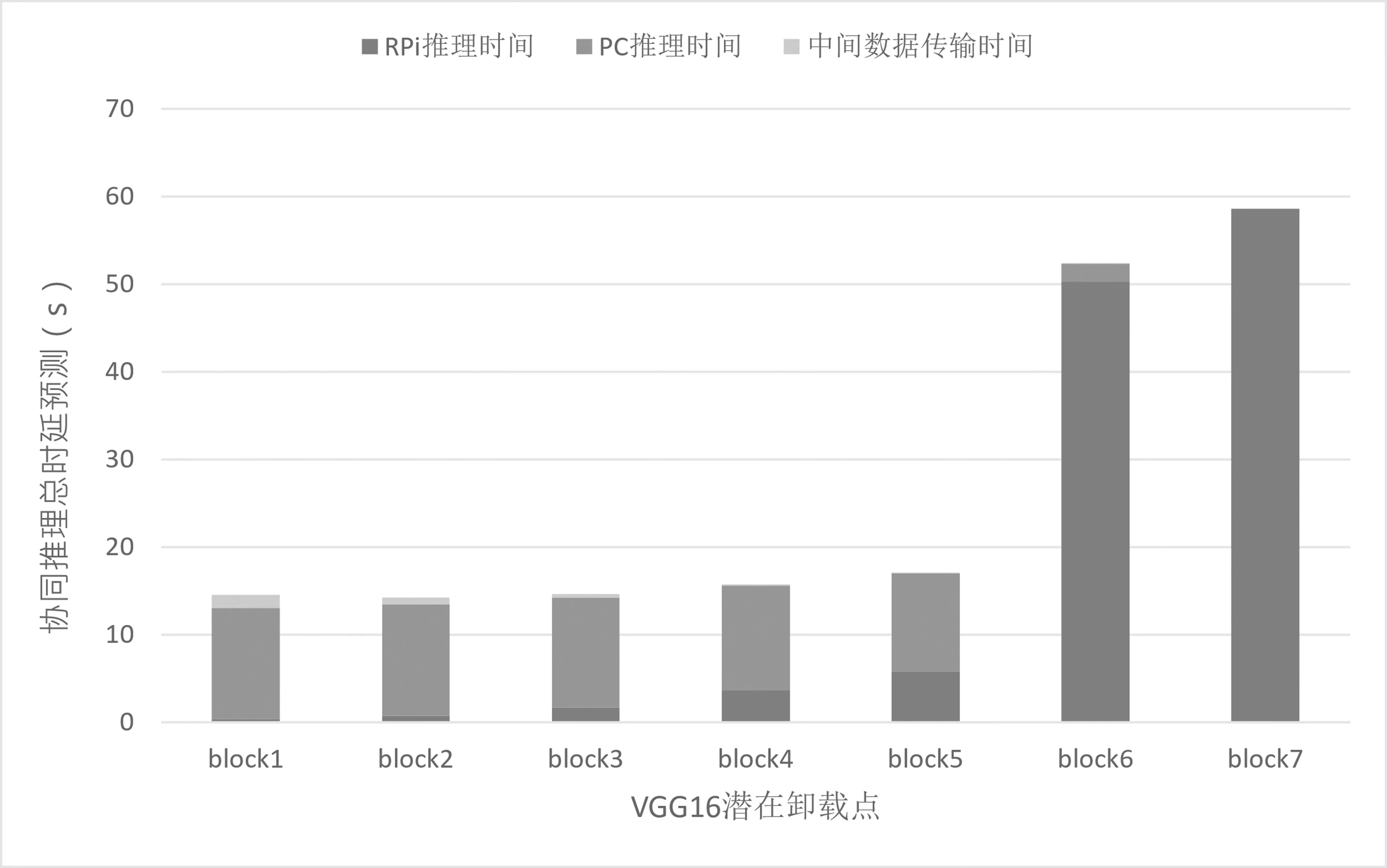
图3 带宽17.5 Mbit/s 下基于VGG16 模型内各潜在卸载点预测所得协同推理总时延
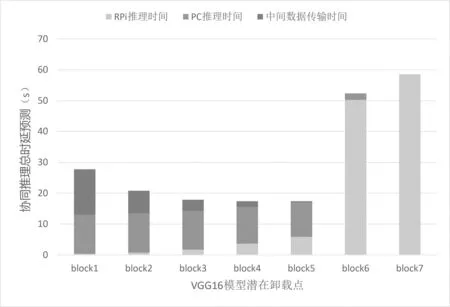
图4 带宽1.75 Mbit/s 下基于VGG16 模型内 各潜在卸载点预测所得协同推理总时延

图5 带宽175 kbit/s 下基于VGG16 模型内 各潜在卸载点预测所得协同推理总时延
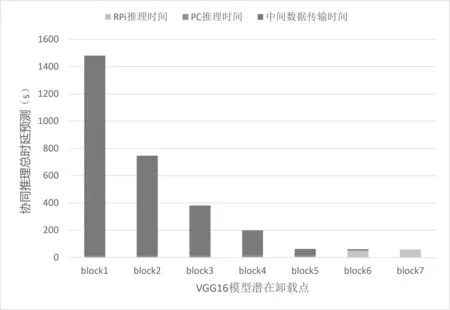
图6 带宽17.5 kbit/s 下基于VGG16 模型内 各潜在卸载点预测所得协同推理总时延
基于所得计算卸载决策,端边协同系统最终实际能达到的加速效果通过完整模型推理在RPi 上所耗时延与端边协同推理所耗时延之间的比值反映。如图7 所示,端边协同计算的速度对比纯RPi 终端侧计算提速超过4 倍,当带宽达到17.5 Mbit/s 时,加速可提至5 倍。
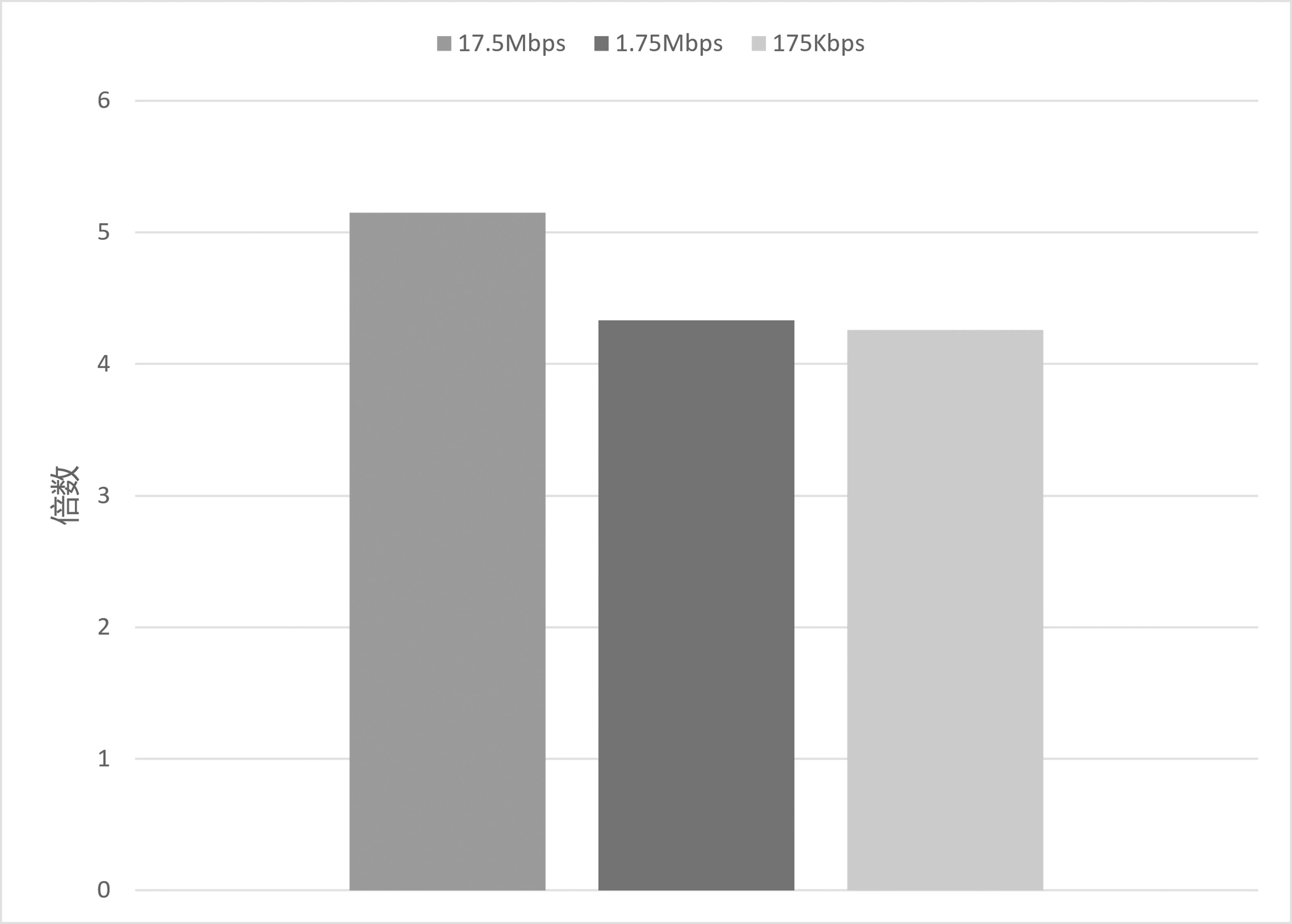
图7 各带宽下VGG16 模型端边协同实际推理的加速效果
5 总结与展望
本文围绕智能终端特性对DNN 模型计算卸载决策技术的研究,主要包括DNN 模型潜在分割点搜索和DNN计算卸载系统管线设计。DNN 模型潜在分割点搜索策略中,遵循计算顺序,以减少协同计算的通信开销为原则,对模型内的潜在分割点进行预判,从而生成以模型块为单位的子任务,缩小后续决策优化的搜索空间,同时保证DNN 模型计算速度。通过放大子任务颗粒度的方式,可提高AI 模型在终端的部署效率,同时使计算卸载决策更加轻量。系统管线设计中将智能终端可参与的DNN 模型计算卸载可分为模型准备和协同计算两个阶段,并在设计中融入对用户隐私安全的考量。通过对该系统进行端边AI 协同计算场景的仿真,可知该模式能有效节省单终端计算资源,加速终端AI 应用的计算速度。
随着5G 技术和物联网的发展,未来将有更多设备参与到协同计算场景中,为此我们将对决策算法进行优化,使其能在多设备间做出高效的任务卸载决策。此外,应用与容器技术的结合,也将提高AI 应用在端侧上的部署效率,使AI 应用可以更轻量、更高效、更便捷、更广泛地落地于终端,促进终端的智能化升级。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
现代装饰(2020年8期)2020-08-24
通信电源技术(2020年8期)2020-07-21
花火B(2019年3期)2019-04-27
电子制作(2019年23期)2019-02-23
电子制作(2018年23期)2018-12-26
宇航计测技术(2018年3期)2018-09-08
现代商贸工业(2017年23期)2017-09-13
销售与市场·渠道版(2017年2期)2017-03-09
物联网技术(2015年8期)2015-09-14
