
基于随机森林的锂电池电极缺陷粗细分类法
2022-03-03 12:33邬依林倪君仪黄晓红
广东技术师范大学学报 2022年6期
林 强,邬依林,倪君仪,黄晓红,何 方
(1.中国移动通信集团广东有限公司 广州分公司,广东 广州 510308;2.广东第二师范学院 计算机学院,广东 广州 510300;3.华南理工大学 自动化科学与工程学院,广东 广州 5106403;4.广东轻工职业技术学院 教务部,广东 广州 510300)
0 引言
目前,锂电池以其能量密度高、寿命长、体积小、无污染等优点在电动汽车等领域越来越受到关注[1-2].众所周知,特斯拉一直致力于新能源汽车[3]的研究,但自其交付市场以来,电动汽车的自燃频繁发生,给人们的生活带来了巨大的安全风险.虽然不能说这些令人遗憾的特斯拉汽车事故一定与电池系统有关,但锂电池给人类生活带来方便性背后的安全隐患也值得关注[4-5].除了锂电池内部结构等原因外,生产过程中产生的电极表面缺陷也会造成一定的安全隐患.因此,锂电池的缺陷检测显得尤为重要.值得注意的是,高效准确的缺陷分类可以反过来极大地促进缺陷检测.
现如今,许多研究人员的研究重心放在锂电池缺陷的检测上,并提出了一些比较成功的方法[6-7],然而,对其进行缺陷分类的研究还很少.在大多数工作场所,缺陷分类主要依靠人工完成,这是不可靠的.因此,应用机器学习技术对锂电池电极表面的缺陷进行自动分类,可以显著提高产品的质量和生产效率.
基于先进的机器视觉技术,自动缺陷分类(ADC)在精度和效率方面具有优势.S.Cheon和H.Lee 等人提出了一种结合CNN 和K-NN的ADC 方法,该方法可以提取有效的特征用于晶圆表面缺陷分类[8].Y.Deng 等人提出了一种用于PCB 的ADC 系统[9].T.Su,等人讨论了ADC 广泛应用的另一个例子,利用小波变换和反向传播神经网络组成的ADC 系统对织物疵点进行分类[10].如上所述,对锂电池电极表面缺陷进行分类的相关研究相对较少.我们发现G.Lanza 等人使用单点分析法可以自动检测锂电池电极表面缺陷[6],然而,他们的工作表明,只对两种缺陷进行检测分类,意味着他们的研究方法还有一定的改进空间.因为在实际工业生产过程中,锂电池表面缺陷常见的有六种类型:亮点、漏金属、气泡、黑点、脱碳和条纹.
针对锂电池电极表面缺陷分类研究不足的现状,重点研究其分类问题.使用[7]中的缺陷检测方法后,可以对缺陷进行定位,得到如图1(d)所示的缺陷图.在这里,我们将这六种类型的缺陷按其反射光或吸收光的能力分为亮缺陷和暗缺陷,如图2 所示.其中,亮点、漏金属、气泡为亮缺陷,黑点、条痕、脱碳为暗缺陷.可以看出,缺陷的灰度值与背景区域的灰度值相差不大,而不同类别的一些缺陷非常相似,如黑点和气泡.因此,准确地对这六种类型的缺陷进行分类具有一定的挑战性.

图1 缺陷定位过程

图2 六种类型缺陷样本
1 缺陷分类算法
我们主要致力于缺陷图像的分类研究.图3 为本文方法的主要框架.该算法分为两部分:粗分类和细分类.其中,Gabor 滤波器组在细分类时主要用于提取缺陷特征,而随机森林作为核心分类器,贯穿于粗分类和细分类过程.下面将对本文提出的算法进行详细的介绍.

图3 所提算法的主要框架
1.1 预处理
综合考虑清晰度和耗时两个因素,图像统一调整为200*200 大小.由于后续的粗分类过程是基于图像的灰度值,所以进行了简单的归一化处理.归一化方法如下:
其中,I(i,j)是原始图像在(i,j)处的灰度值,f(i,j)是归一化之后的图像在(i,j)处的灰度值,gmax和gmin分别是原始图像中最大和最小的灰度值.
1.2 粗分类
由于属于不同类别的一些缺陷有一定的相似性,为了提高分类的准确性,我们在粗分类时的初衷是直接将这些缺陷图像分为亮缺陷和暗缺陷两个大类.但从实验结果可以清楚地看出,漏金属和亮点具有与其他四类比较迥异的特征,所以这两个类别首先被分开.粗分类过程也因此被分为两个部分.
1.2.1 粗分类第一步:将亮点、漏金属与其余四类分离
为了从其他类别中分离出亮点和漏金属,我们使用最小二乘法拟合缺陷图像中指定区域的像素变化曲线.主要步骤如下:
步骤1:在图像20-180 行范围内,依次对中间三列每三行计算平均值,得到如图4 所示的一维向量;

图4 利用指定区域像素分布构造一维向量的方法
步骤2:用最小二乘法对上一步得到的数据进行拟合,在笛卡尔坐标下得到一条直线.同时计算曲线最高点和最低点到直线的垂直距离α和β,如图5 所示;
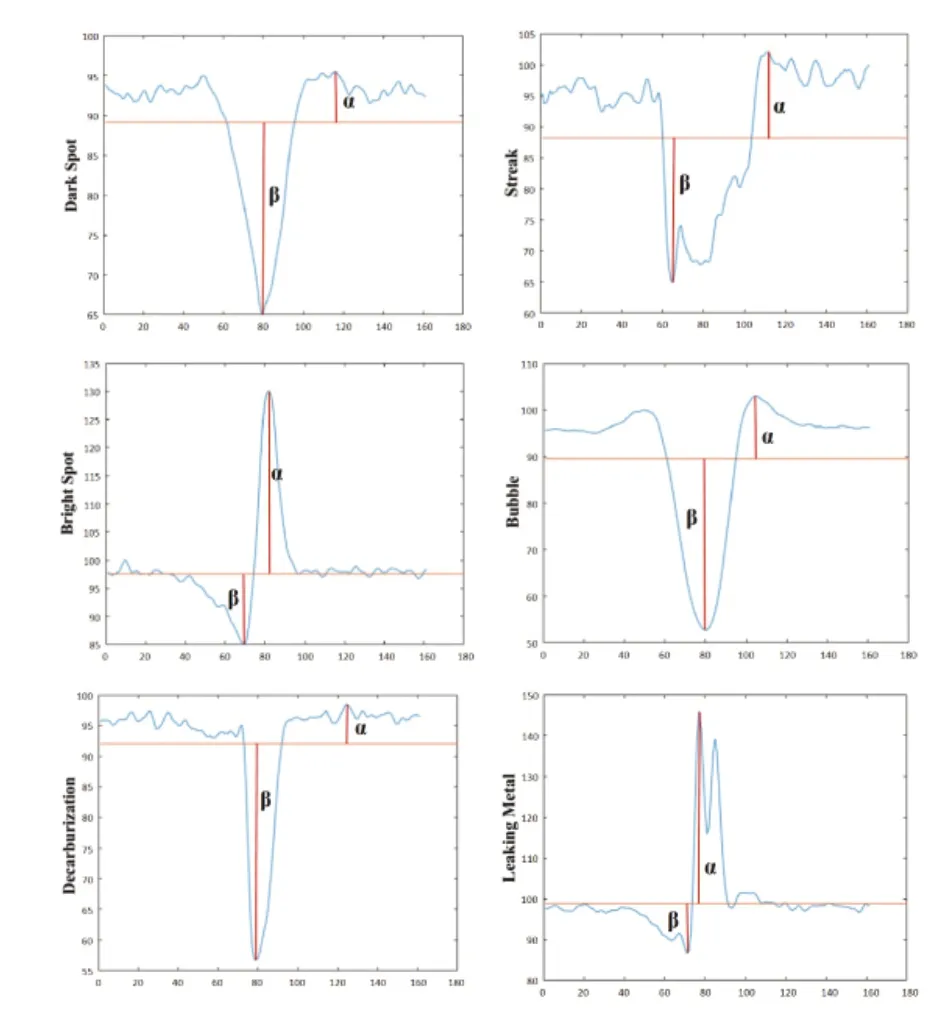
图5 由向量表示的特定区域的灰度值变化
步骤3:计算α 和β 的差值Δ :
其中,Δ 大于阈值T 时,对应的缺陷为亮点和漏金属.当小于阈值T 时,对应的缺陷是其余四种类型的缺陷.T 的值根据下式自适应求得:
其中MLM,MBS,MDSMDE,MST,MBB分别表示漏金属、亮点、黑点、脱碳、条痕和气泡这六类缺陷数据集的平均Δ,min()⋅ 表示最小值算子,Avg()⋅ 表示平均值算子.MM 为黑点、脱碳等四类缺陷数据集差值Δ 的平均值.
该方法可以初步判断测试图像是否属于亮点和漏金属两类.图4 清楚地显示了这部分的处理过程,图5 则直观地展示了亮点和漏金属与其他四类缺陷的区别.
1.2.2 粗分类第二步:将气泡与其他三类亮缺陷分离
环形掩模在这部分起到了至关重要的作用,因为这种形状的掩模可以更好的提取到将气泡缺陷与其他类别缺陷分离的特征,所以很好的满足我们这里的要求.以下是此部分的具体步骤.
步骤1:根据气泡缺陷的形状得到环形掩膜Mr,环形掩膜的内径r1、r2 的定义见Algorithm 1;

步骤2:在Mr 的帮助下,每个图像可以被分为三个区域:环内区域(AIR),环上区域(AAR)以及环外区域(AOR).对环上区域和环外区域两个区域进行特征提取;
步骤3:等角度分割Mr,可以得到两个模板T1 和T2.他们将AAR 和AOR 各自分为s 个 小连通域,实 验证明,当s 的值取36 的时候,可以得到最好的结果.模板T1 和T2 如图6 所示;
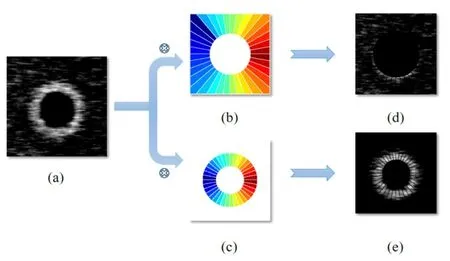
图6 使用模板T 1 和T2 分别将AAR 和AOR 划分成s 个连通域的过程
步骤4:计算每个小连通域RAi和ROi,(i=1,2,…,s)中灰度值的均值和方差,同时,分别计算灰度值为0 的像素所占比例的P1i和P2i,最终,得到一个具有良好区分度的特征:
M11,…s,M21,…s分别表示的是环上和环外的灰度值均值,S11,…s,S21,…s表示的是方差,
步骤5:利用随机森林分类器对上一步得到的特征进行分类,可以准确的将气泡与其他三张暗缺陷分离.
1.3 细分类
在将图像粗略划分为亮缺陷和暗缺陷之后,在各自的两大类缺陷中进行更详细的划分,就可以达到将缺陷图像划分为六类的原始目的.如上述步骤所述,气泡已经被分离,因此,在亮缺陷的类别中,只需要分离漏金属和亮点.观察这六种缺陷的结构,可以发现不同类型的缺陷在方向和尺度上存在差异,在特征提取过程中考虑这些因素,可以得到类间区分度高的特征.参考各种特征提取方法,我们发现Gabor 滤波器非常适合这种场景.因此,这里选择Gabor滤波器进行特征提取.随机森林[15]由于每棵树独立、同时生成,容易做成并行化方法,所以运行速度快;其采用了集成算法,本身精度比大多单个算法要好,所以准确率也高;同时两个随机性的引入(样本随机,特征随机)使得模型不容易陷于过拟合.为了使算法不至于过于复杂,本文使用随机森林分类器进行细分类.细分类的主要框架如图7 所示.
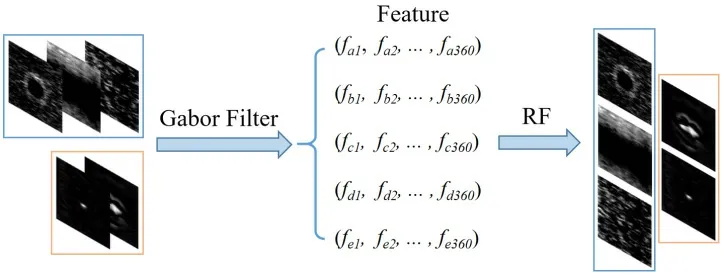
图7 细分类主要框架
2 性能评估实验
我们进行了几个实验来评估所提方法的性能.采用三种对比方法与我们提出的方法进行比较以证明其有效性.每组实验都是在真实数据集上进行的,所有方法都将训练样本和测试样本随机交叉重复10 次.然后报告他们的平均分类准确率,以便进行公平比较.
2.1 数据集
数据集来源于实际生产过程.正如引言中所述,锂电池电极表面缺陷被分为六种类型.在数据集中,一共有2158 副缺陷图像,其中有1165 副属于亮缺陷,亮点、漏金属和气泡各自有283、377 和505 副.至于暗缺陷,一共有993副,其中黑点有215 副,脱碳有602 副,而条痕只有176 副.在实验中,我们分别选取每个类别的20%,15%,10%以及5%作为测试集样本,剩下的则作为训练集样本.
2.2 对比方法
(1)判别弹性网络正则化线性回归(DENLR)[11]:该方法通过引入弹性网络正则化和扩大回归目标的边界,学习一个紧凑的判别回归模型.为了提高回归结果的辨别能力,引入技术将严格的0 -1 回归目标转化成可分离可判别回归的目标,将不同类别的回归目标向相反的方向移动,从而扩大不同类别之间的距离,获得了更具有判别力的回归目标.
(2)边缘弹性网络正则化线性回归(MENLR)[11]:与DENLR 相似,它也是一种基于弹性网络正则化的模型.该模型通过将回归目标的边缘约束嵌入到弹性网络正则化框架中来学习边缘回归模型,使学习目标易于区分.
(3)SVM+[12-13]:利用SVM 作 为分类器 进行分类,可以将不同类别的缺陷分离开.本文结合所提出的粗细分类法对其进行了优化,参考所提出方法,同样先进行粗分类,进一步利用Gabor 滤波器进行特征提取,最后再利用SVM进行分类,可以得到更高的分类效果.
对比方法(1)和(2)在原论文[11]中所使用的其中一个Extended YaleB[14]数据库样本数量为2414 张图像,对比方法(3)在原论文[13]中所使用的数据集样本数量为1440 张图像,因此在本文小样本缺陷分类算法对比中(2158 副缺陷图像)足够训练出合适的学习参数进行分类,从而与本文算法进行对比.
2.3 实验结果
所提出的粗细分类法在亮缺陷和暗缺陷这两个大类中各自会得到一个分类准确率,为了与其他几种方法进行更合理的对比,下式被用来将两个分类结果结合起来,以得到最终的分类精度:
Nb和Nd是测试集中亮缺陷和暗缺陷的数量,Pb和Pd分别是其对应的分类准确率,P是根据所提方法最终得到的分类准确率.
表1 显示了不同方法最终的分类精度.粗体部分说明对应算法在每个数据集中的平均精度(Mean)最高.斜体部分表示最小的标准差(Std),值越小,说明算法的鲁棒性越好.
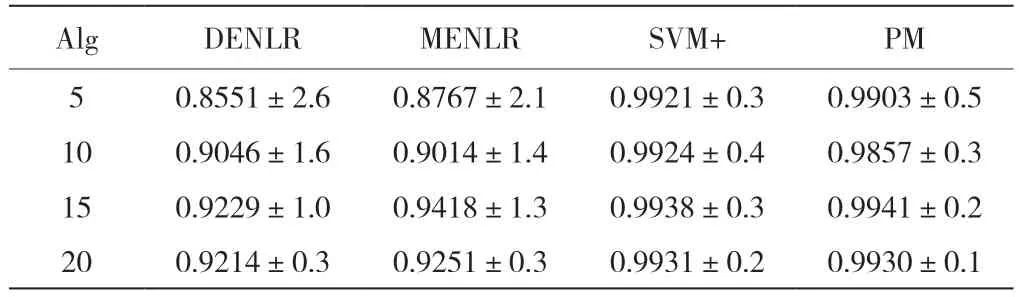
表1 不同方法在测试集图像数量不同情况下的分类精度(十次实验平均值±标准差%)
根据实验结果可以看出,所提算法PM 中提出的先对缺陷粗分类为亮缺陷和暗缺陷极大的提升了缺陷分类的准确率,而基于SVM 进行优化后的算法分类准确率与PM 非常相近,甚至还略优于PM 算法,至于为什么PM 更胜一筹,表2可以给出答案.考虑到实际工厂的生产环境不仅对分类精度,还对分类速度也有极高的要求,我们可以看到,在这个数据集中,与PM 相比,SVM+算法会消耗的大量时间.因此,其在分类精度上的微小优势几乎可以忽略不计.此外,显而易见的是PM 的鲁棒性更好.
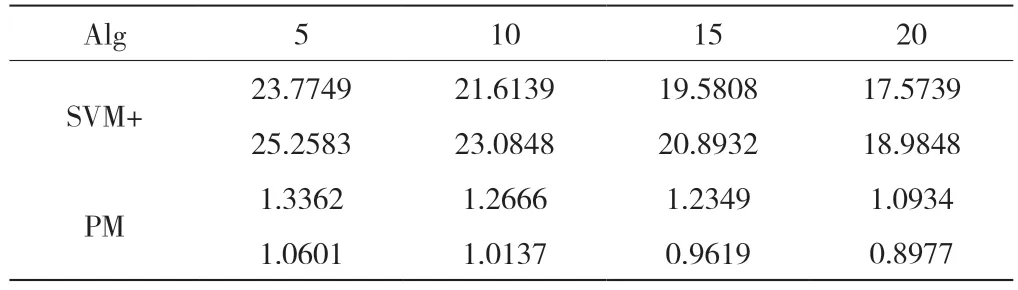
表2 两种算法消耗的时长(秒)
3 结论
我们提出了一种对锂电池电极表面缺陷进行分类的方法.根据指定区域的灰度值分布,从六种缺陷类型中分离出属于亮缺陷类别的亮点和漏金属.并通过引入环形掩模元素,我们将两种容易混淆的缺陷黑点和气泡进行了分类.因此,我们成功地将所有缺陷分为两大类:亮缺陷和暗缺陷.另外,利用Gabor 滤波器提取缺陷特征,并利用随机森林分类器对提取的缺陷特征进行分类.实验结果表明,与其他算法相比较,我们所提出的算法在精度和速度结合上取得了较好的结果.但不可否认的是,我们提出的算法有一定的局限性,粗分类方法对待分类的缺陷图像有一定的限制.在未来,我们希望进一步提高算法的普适性.
猜你喜欢
新潮电子(2021年7期)2021-08-14
建材发展导向(2021年13期)2021-07-28
儿童故事画报·发现号趣味百科(2019年9期)2019-02-02
电子制作(2018年23期)2018-12-26
民族古籍研究(2018年1期)2018-05-21
科技知识动漫(2017年4期)2017-04-15
新校长(2016年8期)2016-01-10
百科探秘·航空航天(2015年3期)2015-12-01
浙江大学学报(工学版)(2015年1期)2015-03-01
中国中医药现代远程教育(2014年16期)2014-03-01
