
一种知识图谱增强的在线课程推荐方法
2022-02-25 06:43孙玉虹丁长青刘利聪
软件导刊 2022年1期
陈 欣,孙玉虹,丁长青,刘利聪
(山东科技大学计算机科学与工程学院,山东 青岛 266590)
0 引言
随着“互联网+教育”模式的推广和人工智能、大数据、云计算等技术的发展,在线教育作为教育信息化的重要手段,为学习者提供了便捷的学习平台,使学习者不受时间、空间限制,根据自身学习兴趣需求,获取丰富的学习资源[1]。为此,全国高校在MOOC、学堂在线等主流教育平台上推出了大量文本、音频、视频等形式的学习资源。对于全日制学习者而言,可将课程资源作为学习的补充,课后查缺补漏,夯实基础;而对于终身或成人教育学习者,在线课程学习是一种最常用的方式,为他们提供了大量的学习资源。但教育平台提供的学习资源繁多,学习方向多元化,存在一定的弊端:①在线教育平台没有与正规高等教育学校相同的培养计划,无法系统、渐进地组织课程,无法为学习者提供有效的学习指导,从而造成信息过载,课程完成率较低;②对于那些终身或成人教育的学习者而言,很难找到与自身水平匹配的课程资源;③课程之间存在重复内容,对学习者会产生一定困扰。因此,为了实现在线课程价值最大化,必须研究课程有效推荐的解决方案。
随着互联网技术快速发展,推荐系统已广泛应用于电影、书籍、社交和购物平台,有效解决了信息过载问题。为了降低学生查找课程的困难,通过分析学生在MOOC 平台上的相关历史数据,推荐系统可在众多课程资源中向学生精确推荐所需课程。现有课程推荐方法通常为协同过滤(CF)方法[2],结合学生课程交互历史和共同偏好进行推荐。但CF 将推荐任务视为有监督学习问题,将学生每次课程交互假设为具有附带信息的独立实例,忽略了实例与课程间的关系,未能从学生集体行为中提取协作信号,存在数据稀疏性和冷启动问题。
为了解决上述问题,研究者考虑将辅助信息融合到协同过滤中,提升推荐效果。在各类辅助信息中,知识图谱由一条条知识组成,包含了丰富的事实和联系,如图1 所示。知识图谱有利于增强课程推荐性能,例如在学习《零基础学Java 语言》之前,要先学习计算机入门课程《C 语言程序设计入门》。由于学生A 的历史学习记录中有《C 语言程序设计入门》,推荐算法会根据课程知识图谱的联系,向学生A 推荐《零基础学Java 语言》。受此启发,本文考虑将知识图谱增强推荐方法应用于课程推荐领域来提升推荐效果。
本文首先将推荐问题形式化;然后爬取MOOC 平台课程属性,并根据本科教学大纲总结课程的先修关系构建课程知识图谱;最后基于卷积神经网络,提出融合知识图谱的深度卷积神经网络(Course Knowledge Graph Convolutional Networks,KGCN-CR),并与协同过滤算法进行性能对比。
1 相关工作
课程推荐策略主要利用CF 方法考虑学生课程的历史交互,基于潜在的相似兴趣推荐学生共同偏好,例如矩阵分解方法SVD++[3]、因子分解方法LibFM[4]。CF 在实际推荐场景中有效性和通用性较高,但无法建模辅助信息,例如课程属性、学生配置文件和上下文。因此,在学生和课程交互矩阵极为稀疏的情况下,推荐效果极差。为了解决该问题,本文引入神经网络方法,将学生id 与课程id 转换为通用特征向量,输入监督学习模型中预测得分。例如基于神经网络的协同过滤推荐NCF[5],基于Inception 结构的神经网络协同过滤方法NCF-i 模型[6],神经因子分解机NFM[7],Wide&Deep 模型[8],这些方法为推荐系统提供了强大的性能,但都将每个学生的课程交互建模为独立的数据实例,未能考虑它们之间的关系,无法从学生集体行为中提取基于课程属性的协作信号。
知识图谱作为一种语义网络,拥有极强的表达能力和建模灵活性,可对现实世界中的实体、概念、属性及它们之间的关系进行建模[9]。知识图谱的概念于2012 年5 月17日由谷歌公司提出并发布了知识图谱课程,宣布将以此为基础构建下一代智能化搜索引擎,其中关键技术包括从互联网网页中抽取实体、实体属性信息以及实体关系[10]。最近,研究人员提出了NELL、DBpedia、谷歌知识图谱和Microsoft Satori,这些知识图谱已成功应用于军事[11]、文本分类[12]等诸多领域。
利用知识图谱的推荐系统现已应用于电影、书籍、音乐、新闻等领域。协同知识库嵌入(CKE)[13]将协同过滤(CF)模块与项目的知识嵌入、文本嵌入和图像嵌入结合在统一的贝叶斯框架中。经过实例验证,CKE 更适用于知识图补全和链接预测,推荐效果较差。深度知识感知网络(DKN)[14]将实体和词嵌入作为不同的通道,使用卷积神经网络(CNN)将它们组合进行新闻推荐。但在使用DKN 之前需要进行实体嵌入,导致DKN 缺乏端到端的训练方式。此外,DKN 除了文本信息外,它几乎无法包含其它层面的信息。RippleNet[15]是类似内存网络模型,通过该模型可传播用户在KG 中的潜在偏好,并探索用户的层次兴趣,但RippleNet 的关系处理能力较差。MKR[16]是多任务特征学习模型,通过知识图谱嵌入任务辅助增强推荐,但在嵌入任务中,未能体现关系的重要性,限制了推荐的性能。

Fig.1 Recommended examples of computer courses图1 计算机课程推荐示例
2 研究思路与方法
首先制定知识图谱用于推荐问题;然后阐述课程知识图谱构建方法;最后提出融合课程知识图谱的卷积神经网络(KGCN-CR)。
2.1 问题形式化
课程推荐问题简化而言就是将课程推荐给学生。在课程推荐场景中,有一组M 个学生为U={u1,u2,…,uM},一组N个课程为V={v1,v2,…,vN}。根据学生隐式反馈构造交互矩阵Y={yuv|u∈U,v∈V},若学生u与课程v进行了交互,则yuv= 1,否则yuv= 0。具体表达式如式(1)所示。

G表示课程知识图谱,课程知识图谱G是由大量的实体-关系-实体三元组(h,r,t)构成,其中h∈ε,r∈R,t∈ε分别表示知识图谱中的头实体、关系和尾实体,ε和R分别表示知识图谱中的实体集合和关系集合。
课程推荐问题目的是给定交互矩阵Y和知识图谱G,预测学生u是否对之前没有交互过的课程v存在潜在兴趣。模型目标是学习预测评分=F(u,v;Θ)。其中,表示学生u点击课程v的可能性,Θ表示函数F的模型参数。
2.2 面向在线课程的知识图谱构建
本文采用自底向上的构建方法,从MOOC 平台中爬取计算机类、音乐类与舞蹈类的课程属性。所爬取的数据具有一定的数据结构,并将此类知识要素进行归纳,抽象为概念,构建知识图谱。构建方法如图2 所示。

Fig.2 Constructing method of curriculum knowledge graph图2 课程知识图谱构造方法
首先获取结构化数据,得到初始的知识表示。由于在构建知识图谱时,相同名称的实体可能存在歧义,通常采用实体消歧技术在理解上下文后对实体进行准确地识别和描述,得到了一系列三元组。
(1)知识获取。从MOOC 平台中计算机类、音乐类与舞蹈类课程中爬取课程数据。如表1 所示,课程数据由所有课程数据进行实体识别、实体分类以及关系抽取所得到的结构化数据。其中,实体识别主要识别课程名称、教师名、学校名等;实体分类将识别后的实体按类别分类;关系抽取主要抽取两个或多个实体之间的某种联系。

Table1 Course data fragment表1 课程数据片段
(2)三元组获取。针对MOOC 平台具体的实际应用场景,本文抽取的课程实体包括课程名称、学校名称、教师名称、类别名称等。关系包括所属学校(属于同一个学校)、授课老师(属于同一个老师)和所属类别(属于同一个专业类别)。根据知识抽取以及实体链接技术构建知识图谱的三元组形式。此外,在计算机类课程中,可利用知识图谱对课程进行进阶描述,根据计算机课程教学大纲与新增先修课程关系能更好掌握学生需求(见图3)。
2.3 推荐算法
本文提出的KGCN-CR 模型可实现面向学生的课程推荐,利用该模型捕获知识图谱中实体之间的高阶连接,将课程实体表示及其邻域节点(绿色节点)相聚合,形成下一次迭代(深蓝色节点)。KGCN-CR 模型框架如图4 所示。
在KGCN-CR 的一阶连接中,用N(v)表示学生u直接连接v的实体集,rei,ej表示实体ei和ej之间的关系。模型用函数g:ℝd× ℝd→ℝ 计算用户对关系的兴趣度,如式(2)所示。

其中,u∈ℝd,r∈ℝd为学生u与关系r的向量表示,d是向量维度。
为了表征课程的邻近结构,本文将邻域的线性组合表示如式(3)所示。


其中,e是实体e的向量表示,在计算实体的邻域表示时,作为个性化过滤器捕获学生的学习兴趣[17]。
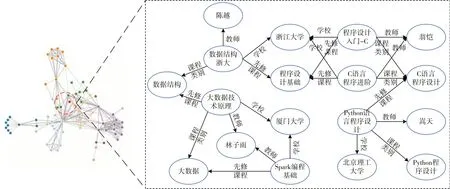
Fig.3 Examples of knowledge graphs for computer courses图3 计算机课程知识图谱示例

Fig.4 KGCN-CR model framework图4 KGCN-CR 模型框架
最后,将实体表示及邻域表示聚合到单个向量中,将两个向量相加,进行非线性变换,计算公式如式(5)所示。

实体最终表示为自身表示及邻域表示,为了保持计算高效,为每个实体采用固定大小的邻域。最后,将一阶表示扩展到多阶,以便更深入地探索用户偏好。
为了提高计算效率,在训练期间使用非负采样策略,完整的损失函数如下:

其中,J是交叉熵损失函数,P是负采样分布,Tu是学生u的负采样数,在本文中服从均匀分布,最后一项是防止过度拟合的L2 正则化项,λ是平衡参数。
3 实验对比与分析
本文选择的数据集MOOC-Music 是MOOC 平台中音乐、舞蹈类别的学习数据。MOOC-Music 包含109 门课程信息和15 914 位学生对109 门课程的评分。由于多数学生只选择一门课程进行学习,造成音乐课程学生课程交互数据十分稀疏,系统难以进行推荐。数据集MOOC-Computer是MOOC 平台中计算机类别的交互数据。MOOC-Computer 包含297 门课程信息和113 630 位学生对297 门课程的评分,本文为了减少交互矩阵的稀疏性,在MOOC-Computer中筛选交互次数大于4 的9 022 位学生。表2 显示了数据集的基本统计信息。

Table 2 Basic statistics of the data set表2 数据集基本统计信息
本文提出的课程推荐方法将与以下模型进行比较。
(1)SVD[3]将高维学生课程评分矩阵分解为低维学生特征向量矩阵、课程特征矩阵及奇异值的对角矩阵。生成学生特征向量矩阵与课程特征向量矩阵后,模型参数根据已有打分数据进行更新,然后SVD 将更新的学生课程评分矩阵作为模型输入。
(2)LibFM[4]是基于特征的分解模型,将学生和课程的原始特征作为LibFM 的输入。其中,维度为{1,1,8},训练次数为50。
(3)Wide&Deep[8]结合了线性和非线性通道的深度推荐模型。Wide&Deep 的输入与LibFM 中的相同,学生、课程维度为64,使用维度分别为100 和50 的两层深度渠道以及广度渠道。
(4)RippleNet[16]是类似于内存网络的方法,可以在知识图上传播学生的偏好。超参数设置为d= 8,H= 2,λ1=10-6,λ2= 0.01,η= 0.02。
本文选择ROC 曲线下面积(AUC)、准确率(ACC)、精确率(Presicion)、召回率(Recall)作为性能评价指标,衡量各算法的性能优劣,如式(7)-式(9)所示。在固定训练集的情况下,模型ACC、Presicion、Recall 和F1 计算越高,表明推荐模型更高效。

其中,TP(True Positive)表示真阳性,即课程样本被正确推荐给学习者的数量;TN(True Negative)表示真阴性,即不属于推荐课程的样本没有推荐给学生的课程数量;FP(False Positive)表示假阳性,即不属于正确推荐课程的样本被错误推荐给学生的数量;FN(False Negative)表示假阴性,即属于推荐课程的样本没有推荐给学生的课程数量。
在KGCN-CR 模型中设置K= 1,fRS作为内积,λ2=10-6,其他超参数L= 1,d= 8,t= 3,λ1= 0.5 由验证集通过优化AUC 确定,建立学生课程评分矩阵。本文矩阵为稀疏矩阵,其中正实例为学生对课程交互(评分)的实例,而负实例则从学生没有交互过的实例中进行采样。训练集、验证集与测试集的比例为6∶2∶2,每个实验重复四次,计算平均性能。评估方法为点击率预测(CTR),将训练后的模型应用于测试集中的每个交互实例,并输出预测的点击概率。最后,使用AUC 和ACC 评估预测效果。
本文所提方法的CTR 预测和top-K 推荐结果如图5-图7 和表3 所示。实验结果表明,在课程推荐中加入知识图谱模型RippleNet、KGCN-CR 的实验效果要优于SVD、LibFM、Wide&Deep,即使在学生课程交互及其稀疏的情况下仍能表现出良好的性能。SVD、LibFM 协同过滤方法由于无法建模辅助信息,在学生和课程交互矩阵极为稀疏的条件下,推荐效果较差。Wide&Deep 本质上是一种神经网络方法,在性能上要优于SVD、LibFM,但Wide&Deep 将每个学生课程交互建模为独立的数据实例,没有考虑它们之间的关系,未能从学生集体行为中提取基于课程属性的协作信号,故推荐效果略差于加入知识图谱的模型。RippleNet 在所有模型中表现最佳,特别是在MOOC-Computer 数据集下推荐准确率要优于KGCN-CR。这表明在学生课程交互较为密集的情况下,RippleNet 可精确捕获学生兴趣,同时证明了知识图谱的有效性。但在MOOC-Music 数据集中RippleNet 表现比KGCN-CR 差,所以KGCN-CR 更适用于稀疏场景。总体而言,在MOOC-Computer 数据集上的模型方法推荐性能优于MOOC-Music,但在MOOC-Music 数据集上运用知识图谱性能优于MOOC-Computer,说明运用知识图谱的推荐算法模型能够较好解决稀疏场景造成的问题。

Fig.5 Accuracy prediction results recommended by top-K图5 top-K 推荐的精确率预测结果

Fig.6 Recall prediction results recommended by top-K图6 top-K 推荐的召回率预测结果

Fig.7 F1 prediction results recommended by top-K图7 top-K 推荐的F1 预测结果

Table 3 Curriculum click-through rate prediction probability表3 课程点击率预测概率
4 总结
本文将知识图谱应用于课程推荐领域,建立课程知识图谱捕获不同类型实体之间丰富的语义信息,并纳入表示学习过程中。提出了融合课程知识图谱的卷积神经网络KGCN-LV,通过聚集邻域信息,获取学生个性化潜在兴趣。通过在数据集MOOC-Music 及MOOC-Computer 上的实验可见,KGCN-CR 始终优于基准线,表明融合知识图谱的课程推荐方法优于传统课程CF 推荐方法,能够准确实现课程资源推荐。
当然,KGCN-CR 也存在一些不足,由于数据限制,在推荐过程中只利用评分表示学生的兴趣。接下来将结合学生评分、学习时间、个人爱好等多指标表示学生的兴趣,建立学生端知识图谱,提供更高效的课程推荐服务。
猜你喜欢
少先队活动(2020年12期)2021-01-14
中国外汇(2019年18期)2019-11-25
哲学评论(2017年1期)2017-07-31
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
