
基于社交媒体数据的北京市游客与居民签到差异研究
2022-02-23 08:42:08屈树学,董琪,秦嘉徽,刘雨思,张晶
地理与地理信息科学 2022年1期
屈 树 学,董 琪,秦 嘉 徽,刘 雨 思,张 晶
(首都师范大学地球空间信息科学与技术国际化示范学院,首都师范大学三维信息获取与应用教育部重点实验室/城市环境过程与数字模拟国家重点实验室培育基地/水资源安全北京实验室,北京 100048)
0 引言
北京市“十四五”规划纲要提出要将北京市建设成弘扬中华优秀传统文化和高品质宜居之城[1],两个目标的受众群体分别为游客和居民两类人群。城市游客和居民的主客关系影响城市的经济和文化发展,明晰二者的耦合关系有助于实现游客与居民的互利互惠[2]。基于位置服务(Location Based Service,LBS)的海量地理大数据(如社交媒体、手机信令、共享单车等)为探究城市空间分异格局提供了新方式[3-5],其在城市空间分异的应用研究主要有“人”和“地”两种途径[6]。学者们往往从“地”的角度探讨固定场所的属性趋同与分异(如功能分区[7]、空间交互作用[8]等),而把人产生的海量地理大数据看作一个整体,分配到研究单元中,但这种方式会忽略人作为城市主体其异质性造成的城市分异现象。从“人”的角度出发,识别相对均质的人群并分析、比较特定人群的活动特征,正作为研究城市空间分异的新方式受到越来越多的关注。近年来,旅游地理研究者尝试通过社交媒体等地理大数据提取游客和居民的活动特征进行人群识别,并进行目的地挖掘[9,10]、文本主题挖掘[11]等探索。例如:Hasnat等基于用户签到坐标提取5个特征进行游客与居民分类训练[12];Yang等基于用户签到坐标、签到时间间隔等特征利用K-means聚类算法识别游客[13]。但与调查问卷等传统数据相比,社交媒体数据提供的信息更“薄”[14],从中难以提取到满足人群识别差异的适量特征,从而影响识别精度;同时,多数研究仅对单一人群进行识别与分析[15-18],或从签到空间分布和签到主题方面分析游客与居民的差异[13,19],较少考虑这两种人群签到地空间差异和类型分异。
“微博”+“旅游”正成为当代年轻人的主流出行模式[20],微博用户在签到地的真实态度与情感能反映用户对签到地的关注度。因此,本文基于微博签到数据,通过扩充数据源获取用户更多的签到信息,以此提取人群差异特征进行游客和居民识别;通过局部莫兰指数方法提取并比较游客和居民的显著性签到聚集区域,通过层次聚类等方法对签到聚集区进行类型划分和差异比较,以期从宏观角度挖掘游客与居民的空间分异格局,为旅游资源配置优化、北京特色文化宣传、游客与居民出行推荐等提供服务,以及为建设高品质宜居城市和打造中华优秀传统文化典范之城提供决策支持。
1 研究区与数据
本文研究区为北京市主城区(东城区、西城区、海淀区、朝阳区、丰台区和石景山区),面积1 384.34 km2,为保证研究区域的连续性,未包含朝阳区首都机场区域。城六区是首都“四个中心”功能的主承载区、国际一流和谐宜居之都建设的重要区域,也是疏解非首都功能的关键区域[21],探究城六区的城市空间分异对北京市的规划与建设有重要意义。
本文以2016年4月15日至10月20日北京市六环内1 577 273条微博签到数据(无签到地址和POI类型属性)为基础,提取研究范围内的用户ID,借助微博开放平台API接口,获取每位用户2016年全年的个人签到数据作为扩充数据集(有签到地址属性),依托高德API接口,基于签到地址进行地理编码和POI类型编码(采用高德一级分类,共23类)。最终,将基础数据与扩充数据依据用户ID匹配,作为本研究数据源(表1),共获取到26 205位用户1 416 666条有效微博数据,其中含经纬度属性数据555 638条,含签到地址和POI类型属性数据235 717条。

表1 数据源示例Table 1 Samples of data sources
2 研究方法
本研究技术流程(图1)为:1)对原微博签到数据进行扩充、清洗与融合等预处理,之后基于分类算法对游客与居民进行识别;2)基于局部莫兰指数方法提取签到聚集区;3)基于签到点的POI类型对签到聚集区进行聚类;4)比较游客与居民两类人群签到聚集区的差异及相似性。

图1 研究框架Fig.1 Research framework
2.1 游客与居民人群分类
本研究中,游客为到某地短期游玩的人,对当地了解不深;居民为长期居住在某地的常驻者,对当地较为了解。本文借助机器学习[22]中的特征工程[23]及分类算法对游客与居民进行识别,流程(图2)包括:1)特征选择。游客和居民在研究区内外的停留时长、签到次数、签到频率及访问次数均有差异,本文借助扩充后的微博签到数据源,将用户的签到行为特征分为时间特征、空间特征和签到比率特征3类(表2),然后根据稳定性选择方法选取合适特征并带入分类器进行训练。稳定性选择[24]方法将二次抽样和选择算法相结合,通过循环选择不同的数据子集和特征子集并计算得分以寻找最佳特征,重要特征得分接近1,无用特征得分接近0。2)特征训练与建模。经过特征选择选出合适特征后,选取分类效果最好的集成分类器进行特征训练并建立分类模型,据此将数据分为游客签到数据和居民签到数据两类。
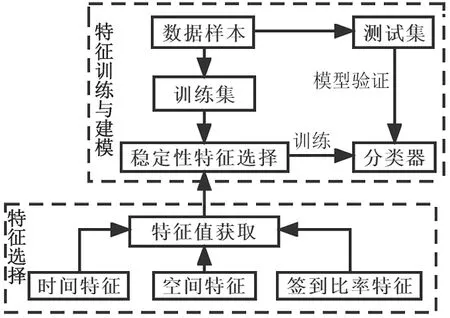
图2 游客与居民识别技术路线Fig.2 Technical route for identifying tourists and residents

表2 微博签到特征Table 2 Features of microblogging check-in
2.2 签到聚集区域提取
局部莫兰指数(Anselin Local Moran′sI)(式(1))常用于识别具有统计显著性低值、高值以及异常值的空间聚集区域[25,26]。本文通过规则格网划分研究区,将每个格网内用户签到点数量作为统计值,利用该方法分别提取游客和居民的签到聚集区域。
(1)
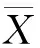
2.3 研究单元聚类
2.3.1 词频—逆文档频率(Term Frequency-Inverse Document Frequency,TF-IDF) TF-IDF是一种文本词汇重要性统计方法[27],其考虑到某些重要且特殊的词在文档中出现的频次不高,通过加权处理提高该词汇权重,以更好地表征此文档的特征,计算公式见式(2)。本文利用该方法提取研究单元特征,研究单元内每个签到点的POI类型构成一条词汇,一个研究单元构成一篇文档,经过TF-IDF处理后可得每个研究单元的特征向量。
(2)
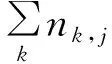
2.3.2 层次聚类及聚类指标评价 层次聚类依据各聚类要素间的距离(相似度)创建一棵有层次的嵌套聚类树。本文利用层次聚类法进行研究单元聚类,在获取研究单元的签到POI类型特征后,通过自下向上的凝聚方法构建聚类树进行类别划分[28,29]。首先将每个聚类要素当作一个簇,然后计算任意两簇间距离,距离指标采用余弦相似度度量[29],为克服离群点,簇间距离采用(类)平均距离;将最近的两个簇合并、迭代处理,直到合并完所有簇。在聚类完成后,应用轮廓系数(SC)[30]、戴维森堡丁指数(DBI)[31]、Calinski-Harabasz(CH)[32]值3个指标进行聚类结果评价。SC值越大,说明聚类效果越好;DBI越小,表明簇内距离越小、簇间距离越大,聚类效果越好;CH值越大,代表簇自身越紧密,簇间越分散,聚类效果更优。
3 人群分类和签到聚集区结果与评价
3.1 人群分类结果与评价
在进行人群分类前,首先依据用户签到特征将2 000名用户类型的人工标注数据构成数据集,并选取75%样本作为训练集,剩余25%作为测试集,随后进行特征选择并采用10次10折交叉验证法进行分类训练与评估。由稳定性特征选择结果(图3)可知,多数特征得分接近1,说明依据经验提取的游客与居民差异特征较合理。剔除较低得分特征(“京外签到频率”),最终选取“注册地(是否为北京)”“京内最大停留时长”“京外最大停留时长”“京内重访次数”“京外最大停留时长地区重访次数”“京外签到数量”“京内签到数量”“京内签到频率”“京外签到数量/京内签到数量”9个特征带入分类器进行训练。
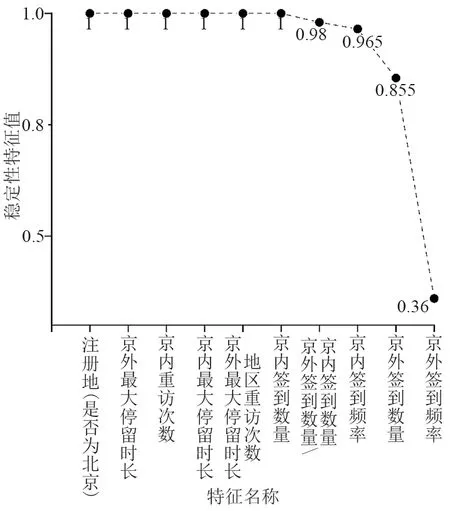
图3 特征重要性评估Fig.3 Assessment of feature importance
为获取较好的分类结果,选取准确度(Accuracy)、精确度(Precision)、召回率(Recall)和F1值4个指标对分类结果进行评估;同时选取K邻近(KNN)、决策树(DT)、支持向量机(SVM)、随机森林(RF)、AdaBoost 5个分类器对分类结果进行横向比较(图4),发现AdaBoost集成分类器综合分类效果最佳,故将其作为最终分类器对游客与居民进行分类。如图5所示,总计识别出游客4 187名,居民22 018名,带有经纬度的签到数据中游客18 803条,居民232 492条。将本文的分类方法与前人方法进行比较(表3),结果显示本文方法各个评价指标的数值均有提升。

图4 不同分类器分类结果比较Fig.4 Comparison of classification results for different classifiers

图5 2016年北京市城六区游客与居民签到分布Fig.5 Check-in distribution of tourists and residents in six core districts of Beijing in 2016

表3 不同分类方法结果比较Table 3 Comparison of classification results of different methods
3.2 签到聚集区提取结果与评价
利用规则格网进行研究区划分并提取签到聚集区,分别选取100 m、250 m、500 m及1 000 m格网进行试验。提取结果显示,1 000 m格网下的聚集区分布较宽泛,而100 m和250 m格网下结果较离散,500 m格网下结果理想,且研究表明,500 m是人类日常活动较频繁的范围[33],因此本文选用500 m格网作为局部莫兰指数的计算单元,空间关系则采用适合面状要素的一阶邻接面进行签到聚集区提取(图6)。

图6 游客与居民签到聚集区识别结果Fig.6 Identification results of check-in gathering areas for tourists and residents
总体看,游客和居民的签到多集中在五环以内,以故宫为中心,整体呈现出中心高、外围低的空间格局。东、西城区更靠近中心,签到量高;石景山区远离中心,关注度较少;海淀区和朝阳区的签到环东、西城区分布,离中心越远签到量越低。丰台区尽管在地理位置上邻接东、西城区,但并未获得微博用户的高关注。游客在天安门、后海、三里屯周围形成3个明显的高密集签到区,签到密度由中心向外围逐渐降低;居民除以上高密集签到区外,签到聚集区更加分散,在海淀区各大高校范围内存在显著的聚集区。
4 签到聚集区差异性和相似性分析
4.1 差异性分析
得到游客与居民签到聚集区后,利用签到点的POI类型划分签到聚集区类型,以挖掘游客与居民签到聚集区的类型差异。将每个研究单元的签到POI类型经过TF-IDF向量化与L1正则化处理后进行层次聚类(图7),可以看出游客与居民均在11类时聚类效果最佳,故将最终聚类数设为11。

图7 游客与居民聚类结果评价Fig.7 Evaluation of clustering results of tourists and residents
完成聚类后,统计游客和居民签到聚集区类型内各POI类型的占比情况,两类人群只在18种POI类型上存在签到行为(图8),进而对各聚集区类型相似度进行比较(图9)。总体看,游客与居民在1-8类型上相似性很高,均由单一类型主导;9-11类型为混合类型,在9、10类型游客偏向住宿服务,居民偏向商务住宅,第11类型主要为政府机构及社会团体,游客地名地址信息签到较多,居民则为商务住宅。进一步对比两类人群聚集区各类型占比(图10),发现二者均在类型4签到较多,该类型以地名地址信息为主,且以“三里屯”“王府井”“五道口”等热点地名为代表;二者在1、2、3、5、7、10类型上签到量差异明显,在餐饮服务、风景名胜及体育休闲服务主导的聚集区类型上游客明显多于居民,在科教文化服务及商务住宅主导的聚集区类型上居民显著多于游客。

图8 游客与居民签到聚集区类型内各POI类型占比Fig.8 Proportion of POI types in the different types of check-in gathering areas for tourists and residents
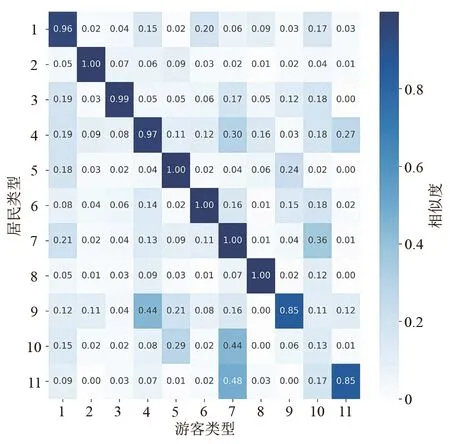
图9 游客与居民签到聚集区类型相似度评价Fig.9 Similarity evaluation of types of check-in gathering areas between tourists and residents
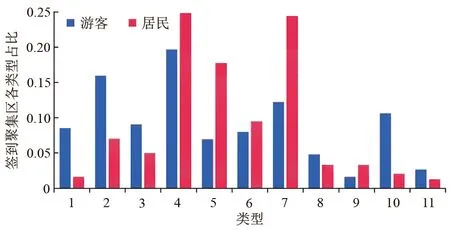
图10 游客与居民签到聚集区各类型占比Fig.10 Proportion of different types of check-in gathering areas for tourists and residents
由游客与居民签到聚集区各类型的空间分布(图11)并结合图8可以看出,人群异质性造成签到聚集区的空间差异及签到类型分异。游客签到聚集区类型特征及分布较明显,环故宫签到类型丰富且密集,外围签到聚集区类型单一且离散。其中,以餐饮服务为主导的类型区相对集中在三环内,周围多为购物服务类型;圆明园、奥林匹克森林公园、798艺术区、法华寺等风景名胜区分布离散且多与科教文化服务类型相邻;此外,还有以北京西站、北京南站、北京站等为代表的交通设施服务类型和以中国传媒大学为代表的科教文化服务类型等离散性聚集区类型。居民签到聚集区类型呈显著的地区特征,其中,海淀区以科教文化服务类型为主,朝阳区以商务住宅类型为主,东、西城区主要是餐饮、购物及风景名胜等服务类型。同时发现,对于游客与居民,北京西站与北京南站均为相对独立的聚集区,用户热衷签到的地区与这两个火车站都有一定的距离,火车站孤立现象也从侧面反映了其周边服务不均衡问题。
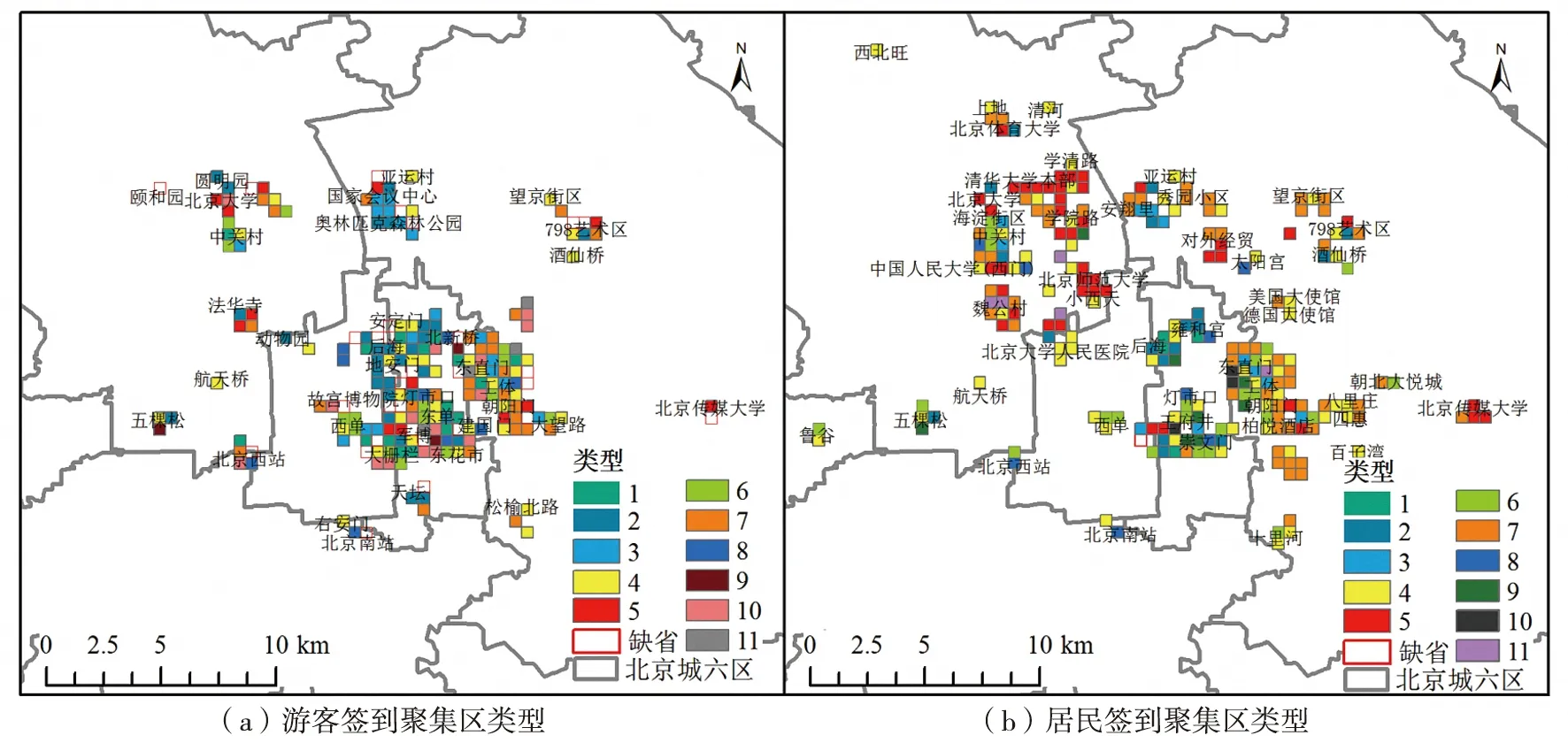
图11 游客与居民签到聚集区类型分布Fig.11 Distribution of different types of check-in gathering areas for tourists and residents
4.2 相似性分析
对游客与居民签到聚集区的POI类型利用TF-IDF向量化并计算余弦距离,得到游客与居民共同签到聚集区的相似性计算结果(图12),取值范围为[0,1],采用自然断裂法将其分为7个等级,值越大表明该地区两类人群的签到类型越相似。从图12可知,两类人群在具有特定类型的场所签到相似性很高,如北京西站、北京南站等火车站,北京大学、中国传媒大学等科教文化服务场所,国家体育场、798艺术区、五棵松等风景名胜区。

图12 游客与居民签到聚集区内POI类型相似性度量Fig.12 Similarity measurement of POI types in check-in gathering areas for tourists and residents
本文以“三里屯”“中关村”“水立方”“亮马桥”“天安门东”5类典型地区为例,通过签到类型云图(图略)说明游客与居民两类人群在相同聚集区内签到类型差异。其中,三里屯地区游客主要集中于购物、体育休闲、餐饮及住宿服务,签到类型具体且与旅游关系密切;居民则在购物及地名地址信息类型签到较多,“三里屯”这一地名地址信息类型代表较宽泛,且多为用户自主选择,这也代表了居民对该地区较为熟悉。中关村地区游客与居民签到类型差异显著,对游客主要提供科教文化与商务住宅类型的服务,对居民则主要为生活与购物类型的服务。水立方附近地区对游客主要提供体育休闲、生活及住宿类型的服务,但该地区的“盘古大观”“IBM”等商务住宅类型吸引了较多的居民签到。亮马桥地区附近众多酒店为游客提供了住宿服务,周边大使馆为其工作人员提供了商务及住宅服务,尽管该地区签到差异显著,但其服务功能具有互补性。中关村和水立方两地在旅游旺季是否会产生游客和居民的签到“冲突”值得关注。此外,在天安门以东区域,游客多为餐饮及住宿活动,不太关注居民常去的“菖蒲河公园”,而这可以为旅游推荐提供参考。
由此可见,人群异质性导致相同地区提供的服务类型也会产生差异,利用大数据进行人群异质性研究不仅可以挖掘地区间的类型相似性,还可探索地区内部提供的不同服务类型,从而为找寻游客和居民这两类人群的“平衡点”提供帮助。
5 结论与展望
本文应用社交媒体数据,筛选出具有代表性的人群差异特征进行游客与居民识别,其准确性、召回率等分类结果评价指标较前人方法均有显著提升,为人群分类研究提供了参考。将签到数据与签到地的POI类型结合,以用户的签到数量作为研究单元内各个POI类型的权重进行聚类,为小尺度、细粒度研究单元的类型划分提供借鉴,并从签到地类型角度定量分析对比了北京市游客与居民的签到差异,主要表现在以下方面:1)从签到聚集区的空间分布看,游客比居民签到更集中,但二者的签到聚集区都呈现出以故宫为中心,北高南低、东高西低的分布格局。2)从签到类型看,游客签到聚集区集中在故宫周边以及圆明园、奥体中心等知名景点;居民签到较分散,但高校签到量突出,体现了社交媒体使用偏向年轻化的特点。3)游客和居民在火车站、高校等单一的土地利用类型区域签到相似度较高,同时存在“三里屯”“中关村”等相似度较低的地区,一方面体现这些地区为混合土地利用类型,另一方面揭示了由人群异质性产生的地区类型偏好差异。通过研究这些差异不仅可以发掘一些潜在的景区进行旅游推荐,而且可以为游客与居民之间的“主客关系”研究提供参考。
微博这一社交媒体数据提供了空间分异研究的宏观视野,但代表的人群存在有偏性,所揭示的空间分异代表人群多为青年,且学生占比较大。今后可以考虑专门针对学生群体并结合感兴趣区等数据进行区域研究,此外,社交媒体数据蕴涵的丰富文本内容也是以后研究的重点。
猜你喜欢
中小企业管理与科技·下旬刊(2022年3期)2022-06-16 00:56:55
科普童话·神秘大侦探(2022年11期)2022-05-30 03:21:35
恋爱婚姻家庭(2020年27期)2020-10-09 04:16:18
百花洲(2018年1期)2018-02-07 16:34:52
电子测试(2017年15期)2017-12-18 07:19:27
瞭望东方周刊(2017年45期)2017-12-08 21:37:48
中央民族大学学报(自然科学版)(2017年4期)2017-06-11 07:17:44
智能系统学报(2015年4期)2015-12-27 09:38:39
中国卫生统计(2015年4期)2015-03-09 12:57:10
电子设计工程(2015年6期)2015-02-27 12:04:53
