
基于稠残U-net神经网络在定位CT图像上自动分割甲状腺的研究
2022-02-23 01:46袁美芳杨毅赵彪文晓博易三莉
北京生物医学工程 2022年1期
袁美芳 杨毅 赵彪 文晓博 易三莉
0 引言
放射治疗是肿瘤治疗的主要手段之一,乳腺癌和鼻咽癌患者行放疗时会对甲状腺造成一定的辐射损伤,导致患者的甲状腺功能减退(简称甲减),出现畏寒、乏力和反应迟钝等症状,严重者可能诱发甲状腺疾病甚至危及生命[1]。研究显示,鼻咽癌患者或乳腺癌患者行放疗后5~10年甲减的发生率为20%~52%,且随着随访年限的增加,甲减的发生率会随之增加[2-3]。放疗中甲减的发生与许多因素有关,其中一个因素是甲状腺所受的辐射剂量。一项鼻咽癌放疗研究中发现,甲状腺所受辐射剂量>30 Gy和<30 Gy的两组患者甲减发生率有明显区别,且辐射剂量每增加1 Gy,甲减发生的风险会增加1.02倍[4]。另一个因素是甲状腺自身的体积,甲状腺体积小的患者甲减发生率相对较高、甲状腺体积大的患者甲减发生率相对偏低。一项头颈肿瘤放疗研究发现,甲状腺体积每增加1 cm3患者发生甲减的概率会降低0.93倍[5]。为此放疗医师通过甲状腺的剂量体积参数(Vx)评估放疗后甲减的风险,而评价指标Vx主要依赖于甲状腺所受辐射剂量和医师勾画的甲状腺体积。在实际临床工作中,仍是放疗医师手动勾画甲状腺,费时费力且勾画差异较大,此情况将造成放疗医师对甲状腺的受照剂量评估产生偏差,导致放射性甲减的发生率增加。因此,在临床上实现甲状腺的精准自动分割具有重要的实际意义。
甲状腺在放疗定位CT图像上的主要特点是:(1) 体积较小,CT图像层数较少;(2) 解剖结构特殊,紧邻气管血管边界不清;(3) 个体差异较大,因此在定位CT上实现甲状腺的自动分割难度较大、报道较少。近年来,基于深度学习的语义分割逐步应用于医学图像分割中[6-8]。2015年,Ronneberger等[9]提出的U-net网络是一种结构简单、参数较少、适用于小数据集的神经网络;2016年,He等[10]提出的ResNet残差网络,优势在于残差块的使用不仅加深了网络深度,同时缓解了梯度消失问题;2017年,Huang 等[11]提出的DenseNet 网络,优势在于稠密块的使用不仅增加了特征图的数量,同时大大提高了特征信息的复用率。本文汲取上述三种网络各自的优势并结合放疗定位CT甲状腺的特点,在U-net中引入残差机制和稠密连接机制建立一种稠残U-net,期望能在定位CT上对实现对甲状腺的精准自动分割,解决放疗中手动勾画甲状腺的现状。
1 研究方法
1.1 实验数据获取
本实验数据来自2014年6月~2019 年4月在云南省肿瘤医院放射治疗科行放疗的鼻咽癌和乳腺癌患者76例,均取仰卧位,在模拟定位大孔径CT(Somatom Sensation Open,24排、Φ85 cm)行平扫扫描,平扫后的DICOM数据传输至放射治疗计划系统并导出,获得原始定位CT影像数据。
由3位不同的医学影像专家(均具有15年以上高级职称的主任医师)使用3D slicer软件制作标签,逐层对标签进行质量评估并提出修改建议,直至所有标签均达RTOG勾画标准,此时获得甲状腺的标准标签图。1号患者的第5层原始定位CT图像及其对应的标准标签图如图1所示,标签图作为神经网络的训练数据和预测结果的比较基准。
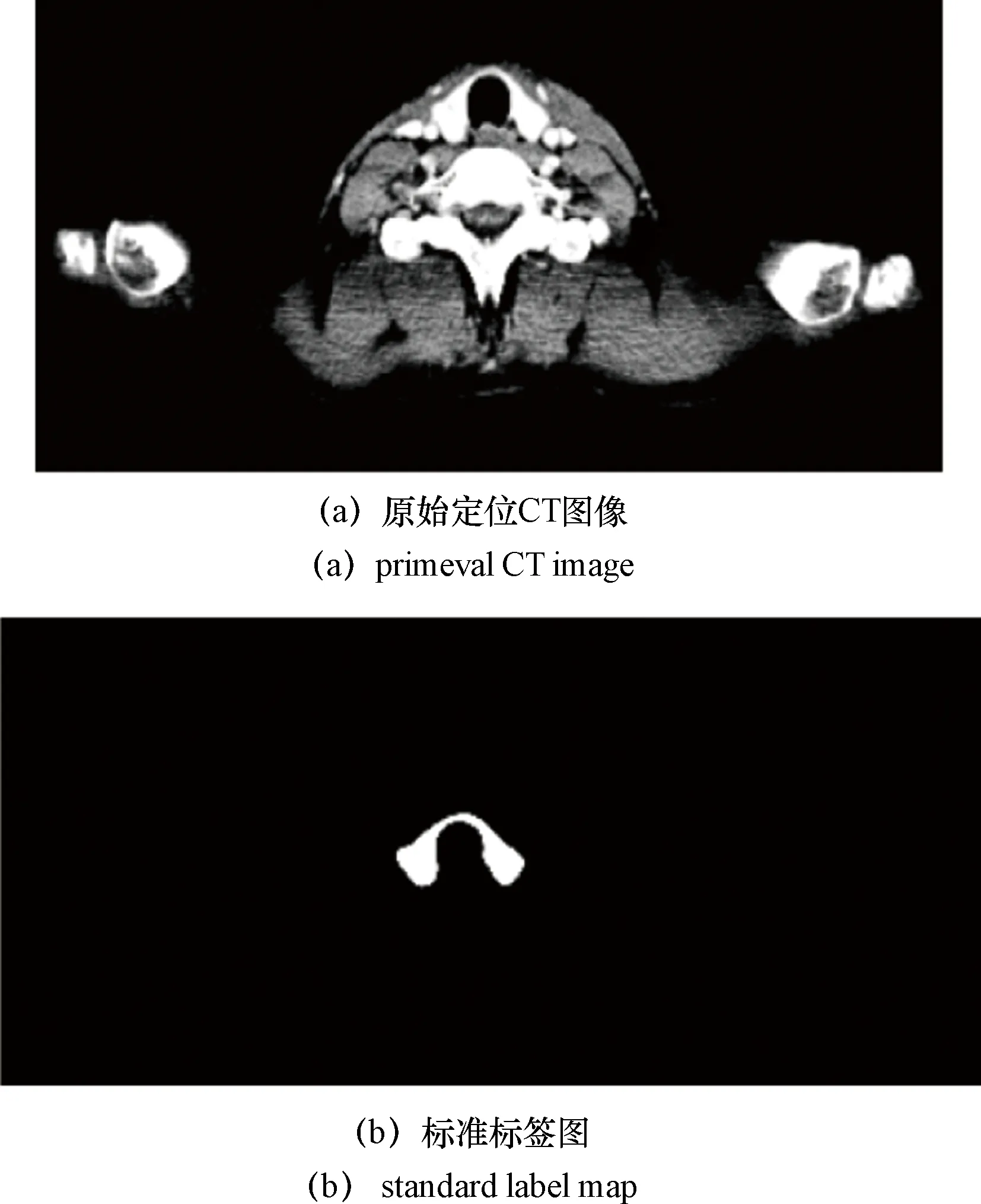
图1 1号患者第5层原始定位CT图像及其对应的标准标签图Figure 1 The primeval CT image of the fifth layer of patient 1 and the corresponding standard label map
本实验的数据集共有76例患者,1 064张原始甲状腺切片。将其随机分为训练集、验证集和测试集,其中训练集58例(821张原始甲状腺切片),验证集9例(120张原始甲状腺切片),测试集9例(123张原始甲状腺切片),分配比例接近8∶1∶1。由于训练集样本较小,为增加神经网络的泛化能力和鲁棒性,本研究通过旋转、平移和缩放等操作进行据扩充,扩充后训练集有2 157张。
1.2 方法
1.2.1 残差块
残差块的结构原理如图2所示,由图可知,残差块包括权重层的输出F(x)和等映射的输出x,等映射操作直接将输入x连接到权重层输出,二者相加得到残差块的输出。数学表达如公式(1)所示:
H(x)=F(x)+x
(1)

图2 残差块结构原理Figure 2 Schematic of residual block structure
1.2.2 稠密连接
稠密连接是指每个层均会与前面所有层在通道维度上连接在一起,作为下一层的输入,见图3。
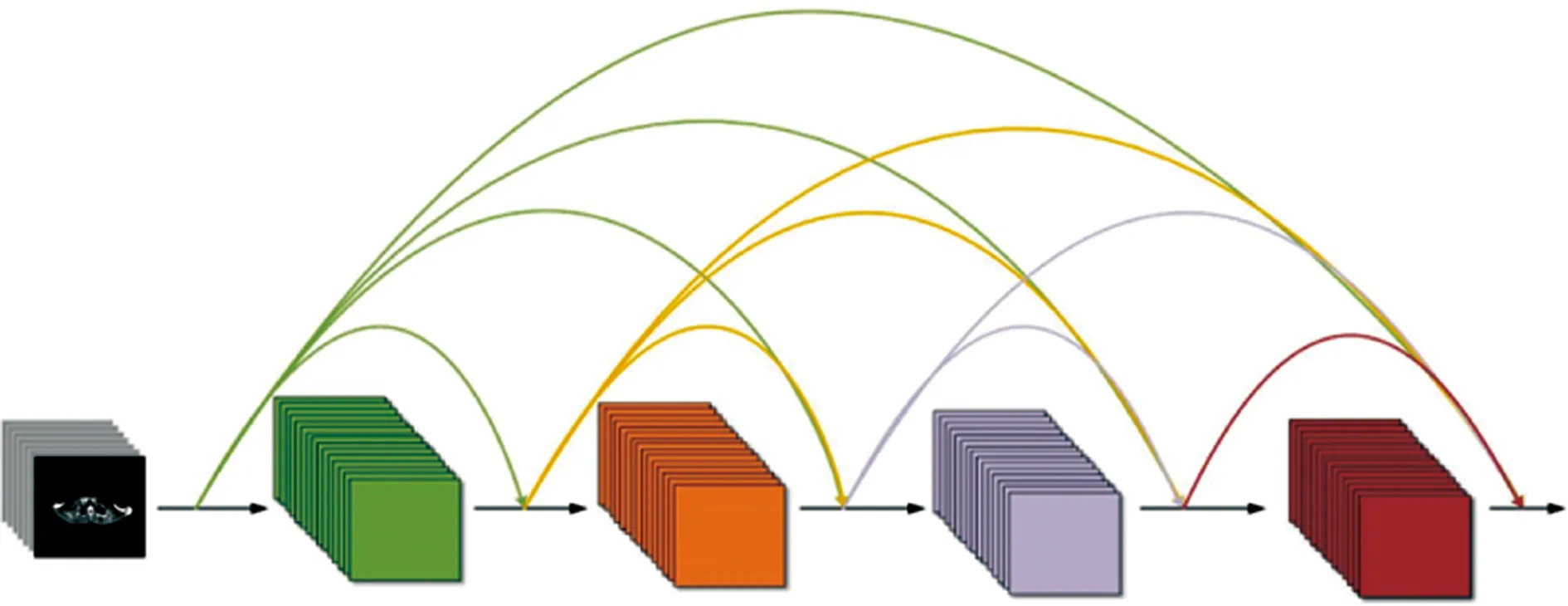
图3 稠密连接方式示意图Figure 3 Schematic diagram of dense connection
假设此神经网络有L层,则此神经网络共有L(L+1)/2个连接,且在第L层的输出为x1=Ht([x0,x1,…,xt-1]),Ht(·)代表是非线性转化复合函数,包括归一化-激活函数-池化-卷积的组合操作。
1.2.3 稠残U-net网络结构
本文在传统U-net中引入残差块机制和稠密连接机制,称为稠残U-net。稠残U-net的结构由下采样、上采样以及跳跃连接3部分组成。左边称为下采样,由4个残差块组成且使用了稠密连接方式,即通过1个Conv-BN互相连接所有残差块层,1个残差块包括2个3×3Conv+BN+ReLU和1个3×3Conv+BN,1次残差块运算包括主线运算和“捷径”运算,主线运算用2个Conv-BN-ReLu提取CT图像的特征信息,同时“捷径”运算用1个Conv-BN将CT图像的输入信息映射到主线路线的输出上,求和共同得到残差块的输出。下采样的作用是提取CT图像中甲状腺像素的位置信息。
右边称为上采样,用4个残差块进行组成,由于稠密连接方式会导致GPU内存占用过高,因硬件条件有限,在上采样过程中并没有使用稠密连接。上采样作用是提取CT图像中甲状腺像素的类别信息。此外,在上采样中增加了1个2×2的反卷积,作用是对特征图像进行尺寸大小的恢复。
中间的跳跃连接(skip connection,SC)进行复制裁剪操作,作用是将编码和解码中获得的特征信息进行融合。网络的输出层(1个Conv-BN和Sigmoid 函数)将CT图像中概率值大于 0.5的像素识别为甲状腺,即分割出定位CT图像中的甲状腺。
1.2.4 损失函数和评价指标
(1)Dice相似性系数和Dice损失函数。Dice相似性系数的数学表达式为:
(2)
式中:Xi代表标准图像的元素个数;Yi代表神经网络预测图像的元素个数;(Xj+Yj)为标准图像和预测图像之间的共同元素个数。Dice相似性系数的取值范围是[0,1],数值越大说明神经网络预测效果越好。
Dice损失函数由Dice系数演变而来,数学表达式为:
(3)
Dice损失函数把神经网络的预测结果作为损失值直接监督网络学习,且表达式中的交并比计算充分利用了图像中前景特征区域的元素,忽略大量的背景元素,能有效解决正负样本不均衡问题,使神经网络收敛速度更快。
(2)杰卡德相似系数(Jaccard similarity coefficient,Jaccard) 。Jaccard系数越接近于1表示神经网络预测效果越好,数学表达式为:
(4)
(3)豪斯多夫距离(Hausdorff,HD)。HD反映两个集合之间的距离关系,数值越小表示神经网络预测效果越好,HD的数学表达式为:
H(X,Y)=max{h(X,Y),h(Y,X)}
(5)
(4) 箱形图。箱形图是一种用最小值、最大值、第一四分位数、第三四分位数、中位数来分析数据的方法,箱形图能反映数据的异常值、尾重和偏态等情况。
1.2.5 训练环境
训练稠残U-net的实验环境为Windows 10和Tensorflow 2.0,编程语言为Python 3.7.1,CPU为Intel I7-8500H@2.20 GHz,内存条为16 GB DDR4 RAM,显卡为Nvidia GeForce GTX 1060。
1.2.6 稠残U-net的训练
76例原始数据在输入之前,首先使用Matlab2019a软件将数据格式由DICOM转换为PNG格式,并去除非甲状腺层面的CT切片,此时必须确保定位CT切片和标签图一一对应;然后对76例数据集进行图像预处理,包括归一化、Hu值转换、窗口化操作和直方图均衡化操作;最后,由于数据为2D定位CT图像,如果由计算机直接加载图片并传递给神经网络则会非常耗时和耗内存,因此将图片存为H5文件,以H5文件格式输入。
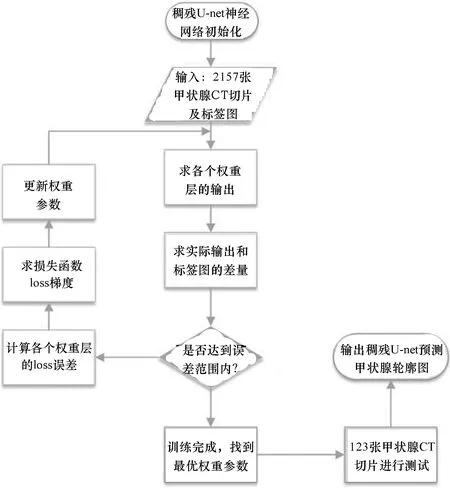
图4 稠残U-net训练流程Figure 4 The training flow of dense-residual U-net
稠残U-net训练的整体流程如图4所示,首先使用TensorFlow 自带的Xavier进行初始化操作;然后将训练集输入到稠残U-net中,对稠残U-net进行训练直到得到一组最优权重并得到学习曲线图;最后,使用训练完成的稠残U-net在测试集上进行测试,得到稠残U-net预测结果。其中,实验训练过程的基本参数设置如下:输入的甲状腺定位CT图像大小为512×512×1,采用步长为 1(Step=1)和大小为3×3的卷积核(3×3 Convs)进行特征提取,采用2×2的最大池化层(2×2 Maxpooling)进行特征压缩,激活函数为Relu和Sigmoid 函数,最终输出512×512×1的预测图。超参数设置为:训练的 Batch size 设定为2,采用Adam 算法对目标函数进行优化,整个训练迭代80个Epoch,学习率设为0.000 1。实验中主要调整的参数是学习率和Batch size,学习率影响神经网络的收敛状态,Batch size则影响神经网络的泛化性能,二者决定稠残U-net权重参数的更新,是训练过程中非常重要的参数。在预实验中,Batch size为1、2、4,学习率为0.000 1和0.000 01,最终当Batch size为2且学习率为0.000 1时,稠残U-net在训练过程中性能表现最好。
2 实验结果
2.1 稠残U-net学习曲线
稠残U-net学习曲线如图5所示,曲线在0~10个Epoch下降坡度较陡峭,之后逐渐平稳下降,最终曲线在0.05附近收敛,表示完成训练。
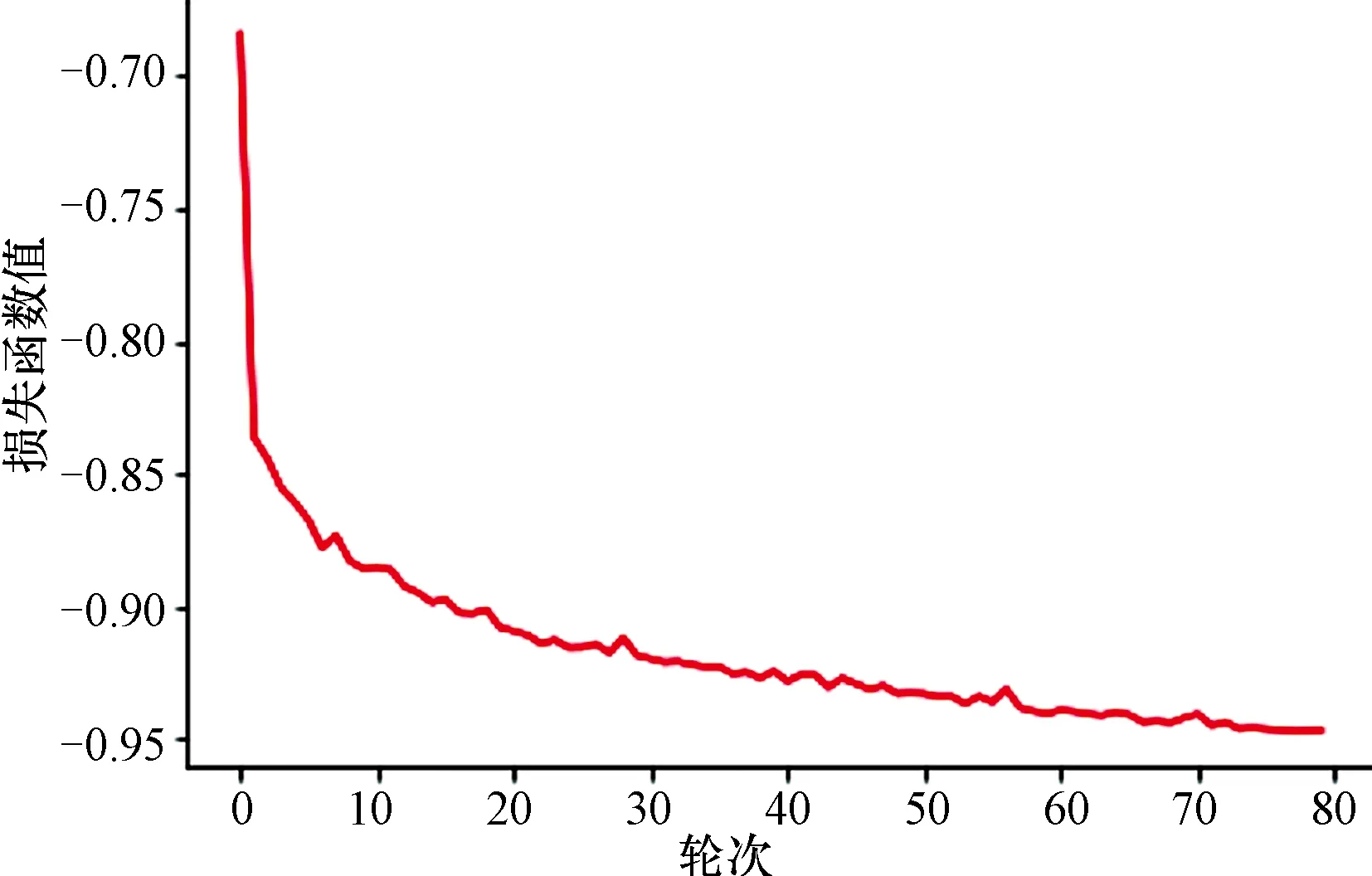
图5 稠残U-net学习曲线Figure 5 The learning curve of dense-residual U-net
2.2 评价指标比较
稠残U-net各评价指标(n=123):测试集Dice系数为0.86±0.09,Jaccard为0.78±0.12,HD为2.52±0.61。
2.3 稠残U-net神经网络预测图
训练完成后的稠残U-net在测试集上预测的甲状腺轮廓图如图6所示,其中a0、a1是原始甲状腺定位CT切片,b0、b1是专家勾画的甲状腺标准图,c0、c1是稠残U-net神经网络预测甲状腺轮廓结果。

图6 稠残U-net神经网络在测试集上预测甲状腺轮廓图Figure 6 Prediction of thyroid based on dense-residual U-net on test set
2.4 箱形图
稠残U-net的箱形图如图7所示,箱形图中的小黑点表异常值,小方框中的横线代表中位数。在Dice箱形图中,稠残U-net有较高的均值和中位值,而且异常值偏离中位值的程度较小;在Jaccard箱形图中,稠残U-net的中位值为0.8左右且异常值很少,预测结果较为稳定,HD箱形图异常值最少。
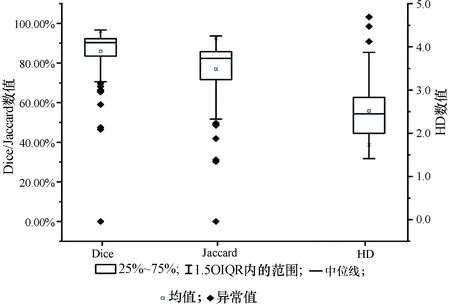
图7 稠残U-net在测试集上的箱形图Figure 7 The box diagram of dense-residual U-net on test set
3 讨论
本课题组前期研究[12]提出基于传统U-net分割甲状腺,Dice值为0.78±0.16,在甲状腺与周围血管紧邻的地方存在较为明显的过分割和欠分割现象;本文基于稠残U-net分割甲状腺,Dice值为0.86±0.09,预测的甲状腺轮廓与专家勾画的标准甲状腺几乎完全重合,在甲状腺狭窄的峡部及与气管、血管相邻难以辨别的位置,预测的甲状腺边界均较为准确。相比前期提出的传统U-net,稠残U-net的优势表现在引入了残差块和稠密机制,残差块不仅加深了网络结构,而且相邻前一层的特征能传递到下一层,避免了局部特征丢失;而稠密连接能将前面所有层的特征信息都往下传递,提高了特征利用率并减小了传递过程中特征的丢失,从而大大提高分割性能。
此外,近年来有部分学者利用深度学习的方法来自动分割甲状腺,如门阔等[13]提出深度反卷积神经网络,其分割甲状腺的Dice值和HD值分别为0.78±0.03和4.9±1.7;杨鑫等[14]提出引入自适应机制的AU-net网络,其分割甲状腺的Dice值和HD值分别为0.83±0.03和4.5±1.3;本文提出稠残U-net,分割甲状腺的Dice值和HD值分别0.86±0.09和2.52±0.61。相比上述文献报道,本研究提出的神经网络分割甲状腺的Dice值和HD值最佳,说明本研究提出的神经网络性能最好,可能是本研究残差块和稠密连接的使用让神经网络获取更丰富的关于甲状腺的特征信息,使得X∩Y增大。
本文结果中Dice箱形图和Jaccard箱形图中均有一个值为0的异常点,是稠残U-net神经网络均未预测出测试集中第123层的甲状腺轮廓,如图8所示。原因可能是类似此层甲状腺的样本较少,也可能是二维神经网络缺失了甲状腺的空间信息,而人工勾画此层时,结合了上下层的空间信息进行确定的,因此在具有硬件条件的情况下,应尝试3D神经网络以获得三维空间信息。本课题组下一步研究的新思路是将使用3D神经网络进行其他器官或病灶的预测。

图8 稠残U-net在测试集第123层的预测结果Figure 8 The prediction results of dense-residual U-net on 123 layer in test set
4 结论
本文提出的稠残U-net能在定位CT图像上较为准确地预测甲状腺轮廓,表明将来基于卷积神经网络进行医学图像分割时可以引入残差机制和稠密连接机制以提高其分割性能。
猜你喜欢
心理学报(2022年9期)2022-09-06
舰船科学技术(2022年11期)2022-07-15
成都信息工程大学学报(2022年2期)2022-06-14
中国教育信息化·高教职教(2022年4期)2022-05-13
心理学报(2022年4期)2022-04-12
煤气与热力(2022年2期)2022-03-09
北京大学学报(自然科学版)(2022年1期)2022-02-21
现代仪器与医疗(2021年6期)2022-01-18
东坡赤壁诗词(2019年1期)2019-04-30
软件(2017年6期)2017-09-23
