
基于灰色熵权法的大数据质量评估
2022-02-21 10:42王杨琛林佳能苏志勇
微型电脑应用 2022年1期
王杨琛, 林佳能, 苏志勇
(国网信通亿力科技有限责任公司,福建,福州 350000)
0 引言
随着泛在电力物联网和坚强电网的提出与发展,促进了电力大数据技术的发展,电力大数据具有数据量大,价值密度低的特点,需要挖掘其潜在价值,为系统的状态评估和故障诊断等业务提供高效可靠的服务[1-2]。电力大数据的质量影响着电力系统的智能化水平,所以对其建立评估模型,从而提高数据的集成和挖掘水平,意义重大[3]。
目前,针对电力数据质量评估的研究并不多见,文献[4]建立了电力大数据质量评估指标体系,采用MapReduce并行化K-means算法对数据进行预处理,然后采用熵权法求取属性权重,采用灰色算法判断数据质量等级。文献[5]为了提升电网调度系统数据质量,采用公共信息模型对不同系统的数据进行校验,并采用改进的多源数据提取优质数据,提高了数据的使用价值和数据质量,保证了调度系统安全可靠运行。文献[6]提出了一种基于Spark的并行K-means算法对电力系统的不良数据进行辨识,以提高状态估计的准确率。文献[7]通过对电网的异常数据进行识别,提高了调度数据中心的数据质量[7]。文献[8]提出了不确定感知数据的自动检测和修复方法,修正不良数据,提高电缆采集的数据质量和系统安全性。文献[9]提出了一种分布式数据质量管理方法,基于Hadoop框架,剔除缺陷数据,并储存在服务器上,提高数据利用价值。文献[10]建立了数据质量管理中心,从技术和管理两个方面入手,形成数据质量管理体系,保障了数据的准确性科学性。文献[11]为了提高电力企业的数据质量,建立了数据质量评价指标体系,采用熵权法和层次分析法建立数据质量评价模型,能够对电力数据进行准确可靠的评价。
虽然已经存在部分针对电力数据质量评估的研究,但是在泛在物联网背景下,如何针对大数据环境下的电力数据质量提升的研究还未发现。本文为了改善大数据环境下的电力数据质量,提出了采用灰色熵权法的大数据质量评估研究。
1 电力系统大数据平台及评价指标
1.1 数据质量评估架构
数据质量评估包括数据质量需求,评估业务规则,评估方法,对数据进行等级划分后,即可进行进一步的措施以提高数据质量。基于Hadoop平台下的数据质量评价架构如图1所示。
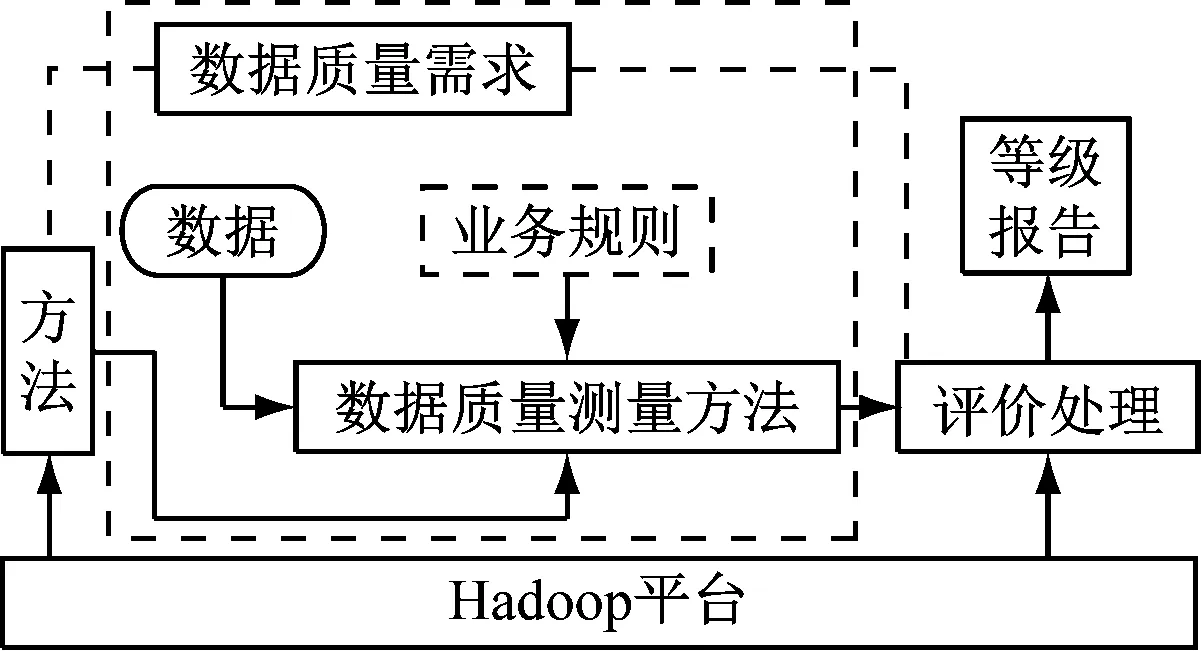
图1 大数据环境下数据质量评估架构
1.2 MapReduce并行化K-means
经典的K-means算法:样本表示为X={x1,x2,…,xn},当样本被分成k(k≤n)类的时候,记作si(i=1,2,…,k)[12]。在n个样本中去k个聚类中心z1,z2,…,zk。如式(1),
(1)
其中,Ni是si包含样本数量。
剩余的样本则根据样本与聚类中心的距离判断归属于哪一类,如式(2),
(2)
根据距离最小原则,将剩余的样本进行聚类划分,迭代循环该过程直到测量函数收敛。测量函数[13]表示为式(3),
(3)
其中,J是所有样本的均方差之和。
K-means算法在解决数据挖掘问题上具有收敛速度快,聚类精度高的优点,但是在处理电力大数据问题时,由于数据质量分布不均匀,会增加挖掘难度,而且海量数据的计算量会给计算带来巨大挑战,所以本文提出了基于MapReduce并行化K-means的求解方法[14]。
设样本集为D={d1,d2,…,dn},di表示第i个样本。当被分类为k的时候,聚类中心si(i=1,2,…,k)表示为式(4),
(4)
求取剩余样本的分类归属按照距离最小原则确定归属类别。循环迭代计算,直到量测函数收敛。如式(5),
(5)
MapReduce并行化K-means算法的过程可以表示为:① Map过程中求取样本与聚类中心的距离,按照距离最小的原则对其分类。② Reduce过程中求取各类样本的平均值作为新的聚类中心。③ 循环迭代,直到量测函数收敛。该过程提高了K-means算法的大数据处理能力。
1.3 电力大数据评价指标体系
针对电力大数据的特征,建立了评价指标体系,如表1所示。

表1 电力系统数据质量评价指标体系
2 基于灰色熵权的数据质量评估
2.1 熵权法确定指标权重
通常认为,某个指标的信息熵越小,则该信息熵在综合评价中的作用越大,所占的权重也应越大[15]。设n类,m个指标形成n×m阶评价矩阵G=(gij)n×m,(i=1,2,…,n,j=1,2,…,m)。其中,gij指的是第i类第j个指标的评价结果。指标数据标准化处理后有H=(hij)n×m。第j个指标的熵按式(6)计算,
(6)
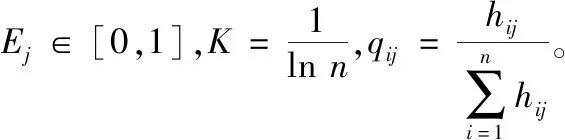
定义第j个指标的熵权如式(7),
(7)
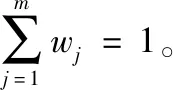
2.2 基于灰色评估法的质量评估
根据模糊数据的方法,将数据质量分成优、良、合格、偏差、劣5个等级。数据质量评语集V={优,良,合格,偏差,劣}。p个评审人员对指标打分,打分范围为[0,10]。则灰色判断矩阵表示如式(8),
(8)
其中,xij是第j个评审人员对指标Bi的评分。
灰色评价的核心是评价等级和白化权函数。当采用5级评价类别的时候,灰类k的白化权函数fk(k∈{1,2,3,4,5})表示如式(9),
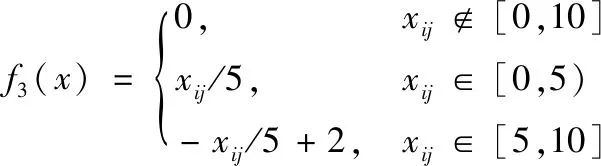
(9)
评价指标关于灰类k的评价系数如式(10),
(10)
则灰色权向量如式(11),
(11)
则向量矩阵Y记作式(12),
(12)
2.3 数据质量的灰色熵权评估方法
在采用MapReduce并行化K-means算法及灰色熵权法对电力系统数据质量进行评估的时候,评估流程如图2所示。
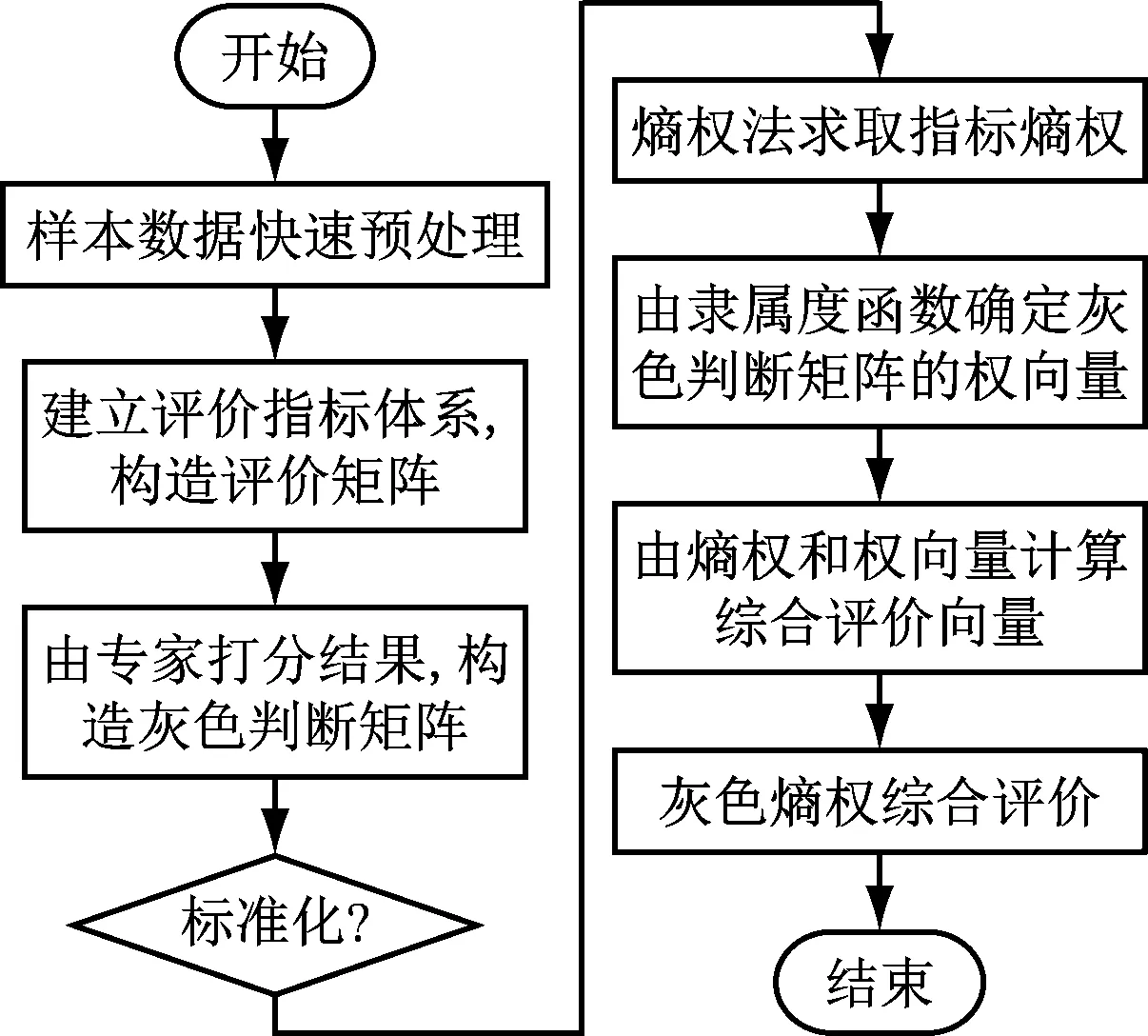
图2 评估方法流程图
如图2所示的评估流程如下。
(1)采用MapReduce并行化K-means算法进行数据预处理。将数据分成k类,从而实现大数据集分成若干个小数据集。小数据集里面的样本相似度较高。
(2)建立评价指标体系,构造评价矩阵。
(3)根据评审专家评分值,构造灰色判断矩阵X。
(4)采用熵权法确定指标权重W。
(5)求取灰色判断矩阵的权向量矩阵Y。
(6)根据W和Y,用式(13)求取综合评价向量Z。
Z=W·Y
(13)
(7)根据最大隶属度标准对数据质量进行等级划分,实现数据质量评价。
3 算例仿真
3.1 实验设置
以天津电力公司采集的电力数据作为实验对比用数据。数据采集为15 min/次,每天24 h,共2年的电力信息。包括了用电负荷、用户信息、地理位置等。
Hadoop平台包括HDFS和MapReduce 2部分,6台PC机,1台用于NameNode,剩余的作为DataNode服务。
首先,采用MapReduce并行化K-means算法对居民用电数据进行聚类分析。3类所占百分比如图3所示。
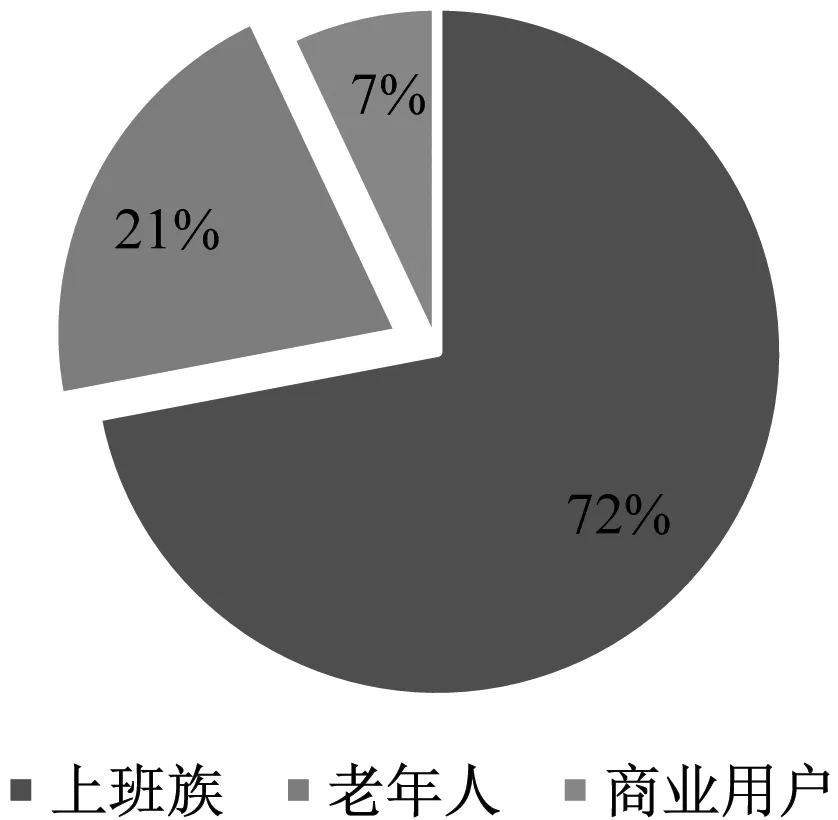
图3 各类用户所占百分比
求取每类用户各个时刻的用电均值,如图4所示。图4中通过对各个时间段的用电量,可以判断3类用电人群分别为上班族、老年人和商业用户。
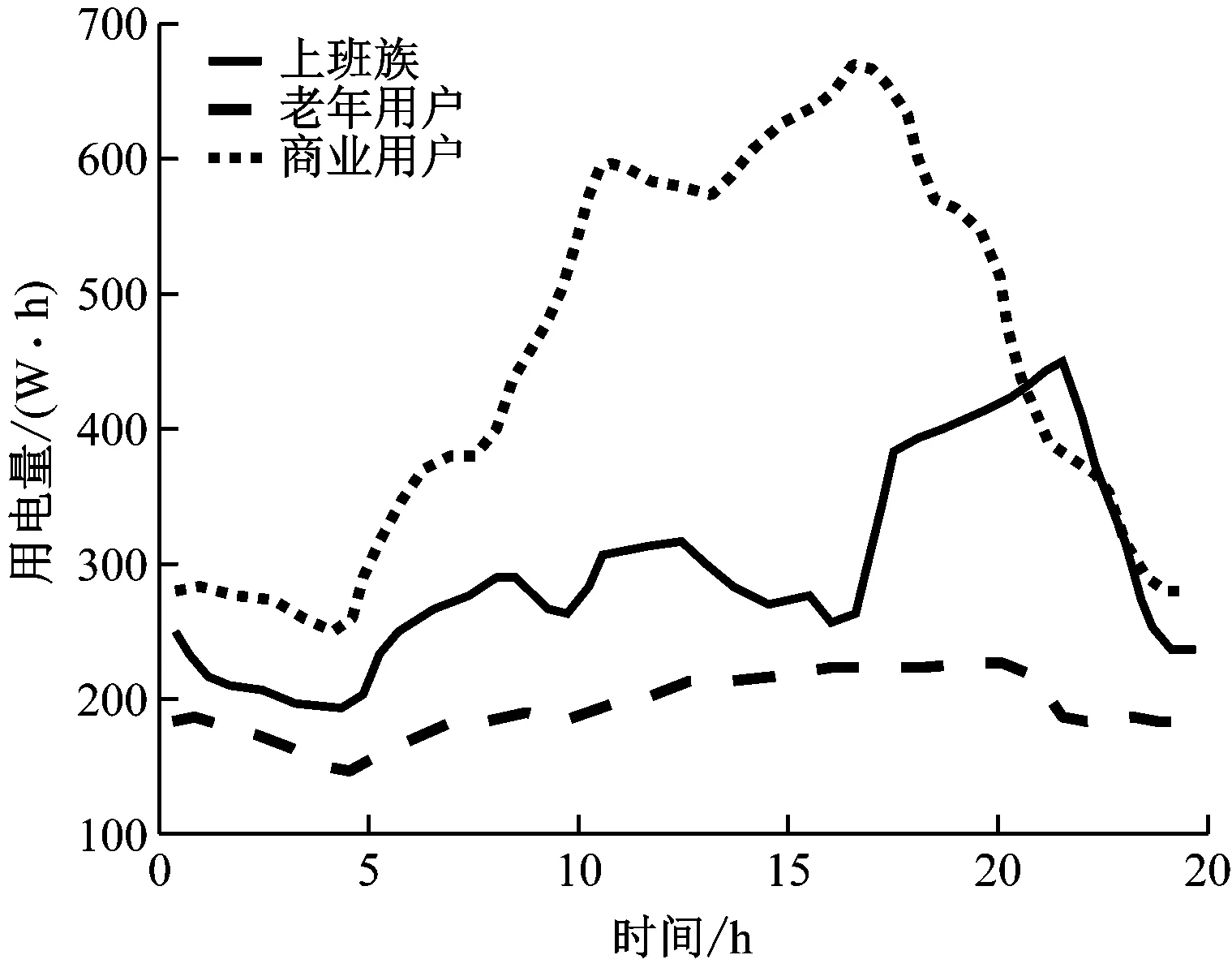
图4 用电负荷分析结果
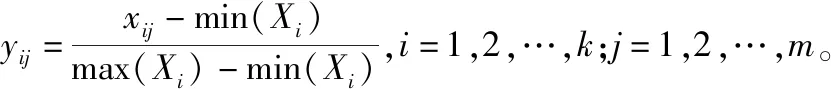
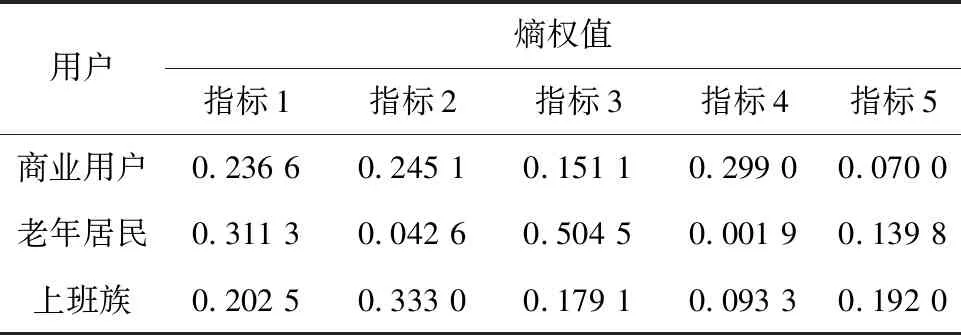
表2 指标熵权值
3.2 灰色熵权综合评价
选择10名专家对电力系统数据质量进行评价,评价结果如表3所示。
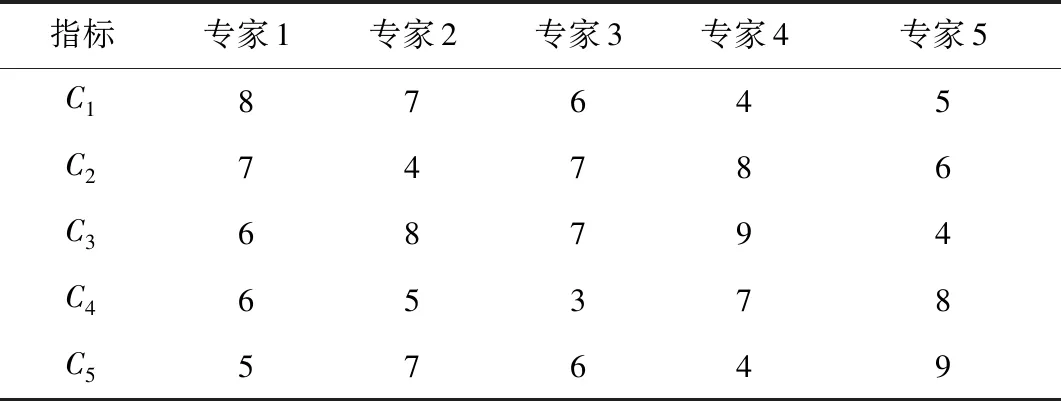
表3 电力系统数据质量评价结果
求取5个指标的灰类系数建立灰色权矩阵Y,如表4所示。
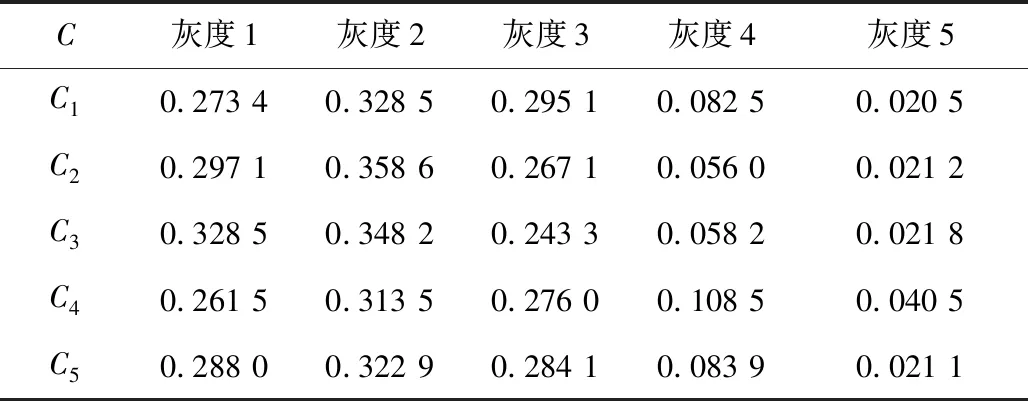
表4 指标灰色评价结果
综合主观评价和客观评价结果,求取综合评价值如式(14)—式(16)。
Z1=(0.285 2,0.333 8,0.274 3,0.079 9,0.026 8)
(14)
Z2=(0.304 5,0.338 7,0.266 6,0.069 1,0.021 2)
(15)
Z3=(0.293,0.339 3,0.273,0.071 8,0.022 8)
(16)
按照最大隶属度的方法,3类用户的最大隶属度为0.333 8,0.338 7,0.339 3。
通过以上分析可知,所采集的电力系统的数据处于良好水平。
4 总结
在泛在电力物联网背景下,采集的数据信息越来越庞大,为了对电力系统采集的大数据进行质量评估,建立了MapReduce并行化K-means算法的分类方法,将电力大数据分解成小数据集分析,提出了电力大数据评价指标体系,采用熵权法确定指标权重,采用灰色评估方法得到最终评分。算例仿真,验证了所提方法可以准确评估电力系统数据的质量。
猜你喜欢
导航定位学报(2022年4期)2022-08-15
选煤技术(2022年2期)2022-06-06
客联(2021年3期)2021-09-10
小学生学习指导(低年级)(2020年3期)2020-06-02
领导决策信息(2018年16期)2018-09-27
Coco薇(2017年2期)2017-04-25
Coco薇(2017年2期)2017-04-25
数学学习与研究(2017年3期)2017-03-09
为了孩子(3~7岁)(2016年8期)2016-05-14
西南学林(2011年0期)2011-11-12
