
基于改进残差网络的田间葡萄霜霉病病害程度分级模型
2022-02-21 08:20:42何东健毛燕茹赵艳茹
农业机械学报 2022年1期
何东健 王 鹏 牛 童 毛燕茹 赵艳茹
(1.西北农林科技大学机械与电子工程学院, 陕西杨凌 712100; 2.农业农村部农业物联网重点实验室, 陕西杨凌 712100;3.陕西省农业信息感知与智能服务重点实验室, 陕西杨凌 712100)
0 引言
葡萄产业是我国重要的果品产业之一,近年来,受气候变化等因素影响,葡萄病害频发。特别是葡萄霜霉病的发病率明显上升,对葡萄产量和品质构成严重威胁,给果农造成了巨大经济损失[1]。对葡萄病害严重程度进行分级,有利于果农精准施药、提高防治效果,降低病害带来的经济损失。目前,国内规模化葡萄园需要依靠人工跟踪果园葡萄霜霉病发展态势,导致果园病害跟踪管理存在滞后性。因此,实现实时准确的葡萄霜霉病严重程度分级,对葡萄病害科学管理和防治、培育抗病品种等都具有重要意义[2]。
随着计算机视觉技术的发展,机器学习[3-5]和深度学习[6-9]方法近年来已被广泛应用到遥感图像识别[10]和农业[11-14]等领域,特别是在作物病害识别方面取得了很好的成果[15-17],为葡萄病害严重度等级划分提供了新的解决方案。为了实现自动识别葡萄叶片病害,朱林等[18]在葡萄叶片病斑区域提取了基于灰度共生矩阵的4种纹理特征和颜色特征,用人工神经网络进行分类,结果表明HS组合特征具有最佳识别效果。ZHU等[19]首先采用小波变换对葡萄叶片图像去噪,利用形态学算法改善病害形状并利用Prewitt算子提取病变区域边缘,提出基于BP神经网络识别5种葡萄叶片病害。刘洋等[20]在其自建的6种葡萄病害数据集上利用移动端设备部署MobileNet网络进行识别,获得87.5%的平均识别准确率。ADEEL等[21]提出了一个自动分割和识别葡萄叶片病害的系统,利用M-class SVM对最终的约简特征进行分类,该方法平均分割正确率为90%,分类正确率达到92%以上。上述研究在病害识别方面取得了很好的成果,但是由于采用人工提取病害特征,难以高效完成有效特征的提取。
人工提取有效特征效率低下,而卷积神经网络能够避免这类复杂操作[22]。文献[23-27]在模型的轻量化、特征提取能力的增强、识别准确率的提高等方面都有了很大改善,但是所用数据集图像差异大、有效特征易提取,针对病害表征相似度较高的病斑特征提取能力有限,模型适应性不强。
不同程度葡萄霜霉病图像病斑表征相似度高且背景复杂不易区分,为了准确识别发病程度,提高模型的泛化性能,本文在ResNet-50的基础上,通过修改残差块的主分支和捷径分支结构以增强网络特征提取能力和保留重要信息的维度变化,并在多个不同的增强数据集上验证本文构建模型的有效性。
1 病害图像采集与供试样本生成
1.1 图像采集
2020年7—10月,于陕西省杨凌区西北农林科技大学葡萄种植基地,分别采集了霜霉病前期、中期、后期以及健康叶片图像,图像采集设备为小米9手机,分辨率为3 000像素×3 000像素。所采集图像由葡萄病害专家根据发病时间以及叶片病斑面积进行了严重度等级划分,共4 470幅,其中霜霉病前期1 190幅,中期1 090幅,后期1 180幅,健康叶片图像1 010幅,建立了一个葡萄霜霉病图像数据集。图1为不同霜霉病发病程度图像示例。
1.2 图像预处理及增容
在实际应用中,葡萄叶片通常生长在复杂环境背景中,同时由于存在天气、获取图像时的拍摄角度、设备噪声等因素影响,病害的准确分级面临诸多问题。田间环境存在背景多变、遮挡、阴影等情况,且获取图像易受光照、雾霾等因素干扰,同时葡萄叶片生长位置、叶片形状也会影响图像分级效果。如图1部分示例所示,无论是在几何特征、轮廓信息等方面均存在较大差异。
为模拟上述影响,使得本文数据集尽可能地符合田间复杂环境下的应用,对原始图像进行高斯模糊、对比度增强30%/减弱30%、亮度增强20%/减弱20%、锐度增强50%/减弱50%以模拟不同天气情况(图2)。分别旋转图像90°、180°、270°和水平翻转、垂直翻转,以模拟拍摄角度变化(图3)。对原始图像加入高斯噪声和椒盐噪声,以模拟图像采集时的设备噪声(图4)。综合以上3种方法得到增强后的数据集数据量是原来的14倍。将输入模型数据集的图像尺寸统一调整为224像素×224像素,并按照7∶2∶1划分为训练集、验证集、测试集。

图2 模拟不同天气的数据增强效果Fig.2 Data enhancement effects for simulating different weathers

图3 模拟不同拍摄角度的数据增强效果Fig.3 Data enhancement effects for simulating different shooting angles

图4 模拟设备噪声的数据增强效果Fig.4 Data enhancement effects of analog equipment noise
2 病害程度识别模型
2.1 葡萄霜霉病特征与深度学习模型选择
本文数据集包含3种不同发病程度的霜霉病以及健康叶片图像,不同程度的霜霉病病斑的纹理、颜色、图像中葡萄叶片面积占比等表征信息具有很高的相似性,区分难度大,会导致模型识别不同程度病害时准确率降低;同时由于不同病害等级叶片背景复杂无规律性,也会影响模型的特征提取过程,浅层网络的特征提取能力无法满足病斑特征的提取,模型泛化能力弱。深层卷积神经网络能够很好地提取图像浅层、深层的不同特征信息,复杂背景下的提取能力有了较大提升。深度卷积神经网络在特征提取能力上优于浅层网络,但随着网络深度加深,模型会出现梯度消失或梯度爆炸现象,同时易导致模型退化。残差块从结构上看主要包括两部分,即捷径连接和恒等映射,捷径分支使得残差成为可能,保证了网络深度增加的同时模型不退化,恒等映射使得网络能够更深,获得更强的特征提取能力。依靠残差块堆叠搭建的深层残差网络在表征相似度高的不同图像时仍然能达到很好的效果。为了使模型训练过程更快收敛且保证较高的识别准确率,本文在ResNet-50深度残差网络[28]基础上,修改模型残差块主分支结构与捷径分支结构,进一步提高网络特征提取能力,提取图像中的叶片病斑信息,构建模型实现葡萄霜霉病的等级划分。
2.2 模型改进与结构设计
本文采用的ResNet-50整体结构如图5所示。首先利用7×7卷积层和3×3最大池化下采样对输入图像进行一次常规特征提取操作,减小特征尺寸,然后通过Stage2中的Conv2、Conv3、Conv4与Conv5残差体提取更高层特征信息,最后将提取到的高维特征输入到Stage3全连接层进行分类输出。

图5 模型总体结构图Fig.5 Overall structure of model
残差块有2种结构,如图6所示,其主分支输出特征矩阵与捷径分支输出特征矩阵具有相同形状,两者堆叠构成了残差主体。

图6 不同结构的残差块Fig.6 Residual blocks of different structures
在图6a中,捷径分支被用于改变特征维度,这一操作起到了避免模型退化的作用,为了保持输出特征矩阵与主分支输出一致,采用一个1×1卷积操作,能够较好地实现跨通道的特征整合,但是直接用步长为2的1×1卷积层将上层特征图尺寸减半,无重点的特征图减半操作弱化了图像纹理、角点等部分重要特征,造成特征图存在一定程度失真,导致后续残差层结构能提取到的有效特征减少。输入特征在ID Block中残差块主分支中流动时,为了减少计算量先采用1×1卷积降维操作后再提取特征,然后将提取到的特征信息升维。如图6b所示,这种瓶颈结构虽然提高了计算速度,但也在一定程度上限制了主分支的特征提取能力,仅修改主分支和ResNet-50原始模型相比准确率能够提升3.11个百分点,模型泛化能力更优,说明单个3×3卷积层的特征提取性能不足。原始模型的全连接层不能直接用于本文数据集,需要对其重新设计。针对以上问题,本文对ResNet-50进行如下改进:
(1)对Conv3、Conv4、Conv5的Base Block捷径分支进行改进。原始结构如图7a所示,在原始1×1卷积层前插入3×3最大池化层,步长为2,实现保留重要信息的降维,经过1×1卷积层特征整合后通过批归一化操作(BN)与主分支输出相加,图7b为改进后的捷径分支结构。
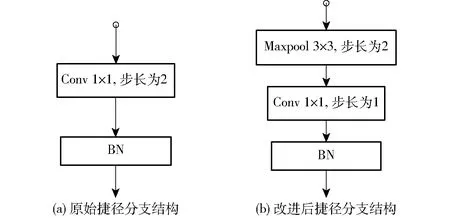
图7 改进前后捷径分支结构Fig.7 Shortcut branch structure before and after improvement
(2)改进ID Block中残差块的主分支结构。ID Block中残差块的主分支结构如图8a所示,在卷积过程中第1层卷积层仅对输入特征进行降维。为了强化残差结构主分支性能,使其能够高效地用于本文数据的特征提取,将其中的第1层1×1卷积降维替换为3×3卷积降维且步长为1,卷积核个数不变,在降维的同时提取大部分重要特征,改进后ID Block中残差块主分支结构如图8b所示。

图8 改进前后主分支结构Fig.8 Main branch structure before and after improvement
(3)设计新的全连接层。设计的新的全连接层如图9所示,用全局均值池化和3层节点个数分别为1 024、512和4的全连接层网络代替原模型全连接层结构,并加入Dropout层避免模型过拟合,提升模型泛化能力,使其能够针对本问题达到更好的效果。

图9 新的全连接层Fig.9 New fully connected layer
3 试验与结果分析
3.1 试验测试平台
试验平台为Intel Xeon Gold 5217 CPU,3 GHz处理器,系统内存251.4 GB。测试软件环境为Ubuntu 18.04.5 LTS,64位操作系统。分类网络模型由Python3.7基于TensorFlow2.1深度学习框架、GPU (Nvidia TESLA V100) 双卡模式训练实现。
3.2 试验设计
为了尽可能提升BN的优化效果,本试验将所有模型的输入批尺寸统一设置为32,图像尺寸设置为224像素×224像素,在保证训练速度的同时也能最大化BN操作的效果。
为了探明动量因子、学习率、Dropout比率、数据增强方式对改进后模型识别准确率的影响,在原始数据集上测试不同模型。试验设计如下:
(1)超参数(动量因子m、学习率α)对识别准确率的影响试验。设置了0.30、0.60、0.90共3个动量梯度,进行预试验,根据预试验的结果,再进一步改变m,找到适合本文模型的最佳动量因子;在最优动量基础上分别测试学习率为0.01、0.001、0.000 1,确定模型最优超参数。
(2)不同模型识别性能对比试验。首先优化AlexNet、GoogLeNet、VGG-16以及ResNet-34、ResNet-101模型的最优超参数,自动选择超参数算法往往需要更高的计算成本,因此各模型优化调参均采用手动调整的方式。将优化后的上述模型与改进后的模型在原始数据集上进行对比,分别测试准确率。
(3)数据增强方式对模型识别准确率的影响试验。在4种不同的增强数据集上对改进后模型进行训练和测试,以探明数据增强方式对识别准确率的影响;在综合各种增强数据集上将改进后的模型与ResNet-50进行对比,评估改进残差网络模型的性能提升效果。
(4)残差结构修改方式对模型识别准确率的影响试验。为评估仅修改残差块捷径分支和仅修改残差块主分支对模型识别准确率的影响,分别对两种修改后的模型进行训练并测试,最后与两种方法并用的模型进行对比。
3.3 结果与分析
3.3.1动量因子对识别准确率的影响
预试验结果显示,在m=0.60时模型精度最高,根据这一结果,设计了m为0.50、0.55、0.60、0.65、0.70的动量梯度并在原始数据集上进行试验;在动量因子为0.60的基础上测试了不同学习率对模型准确率的影响,根据收敛速度和准确率优选出学习率α为0.001的模型,测试结果如表1所示。

表1 不同动量因子下改进ResNet-50模型的准确率Tab.1 Model accuracy of improved ResNet-50 under different momentum factors %
不同动量因子的模型训练过程如图10所示。动量因子较小时模型收敛过程较平缓,但收敛速度慢且训练难以得到最优值,而过大的动量因子则使得模型训练过程容易出现振荡,不利于模型精度的提高。在测试集中,m=0.60时模型识别准确率为95.17%,高于其它动量参数模型。

图10 不同动量因子下模型性能随迭代周期的变化曲线Fig.10 Variation of model performance with iteration times under different momentum factors
3.3.2不同模型的识别性能
不同模型在原始数据集的训练集、验证集和测试集上的识别准确率如表2所示。
从表2可以看出,AlexNet网络在训练过程中采用分组卷积,其不同特征图分别计算后融合,导致卷积核只与某部分特征图进行卷积,模型泛化能力不强;本文数据集相似度较高,GoogLeNet网络对多尺度特征的适应性优势未能充分体现,识别准确率不高;VGG-16参数量大,初始数据集不足以训练VGG-16,网络难以优化;残差网络能很好地解决网络深度增加导致的梯度消失和模型退化的问题,ResNet-34以较少的参数量获得了较高的准确率,但还存在提升空间;更深层的ResNet-50模型识别效果有了明显的提升;而ResNet-101网络过深,训练时间长,在ResNet-50模型基础上识别准确率并未有显著提升,计算成本过高,不利于实际应用。残差网络模型能够较好地适应本文数据集相似度高的特点,改进后的ResNet-50模型识别准确率为95.17%,高于原始模型。

表2 不同模型识别准确率对比Tab.2 Comparison of recognition accuracy of different models %
3.3.3数据增强方式对改进模型识别性能的影响
为提高模型泛化能力,分别用4种不同的数据增强方式进行训练并测试,表3中数据集A、B、C、D分别为模拟不同天气、不同拍摄角度、不同设备以及综合各种增强方法得到的数据集,不同增强方式所生成数据集的4个时期数据量统计如表3所示。
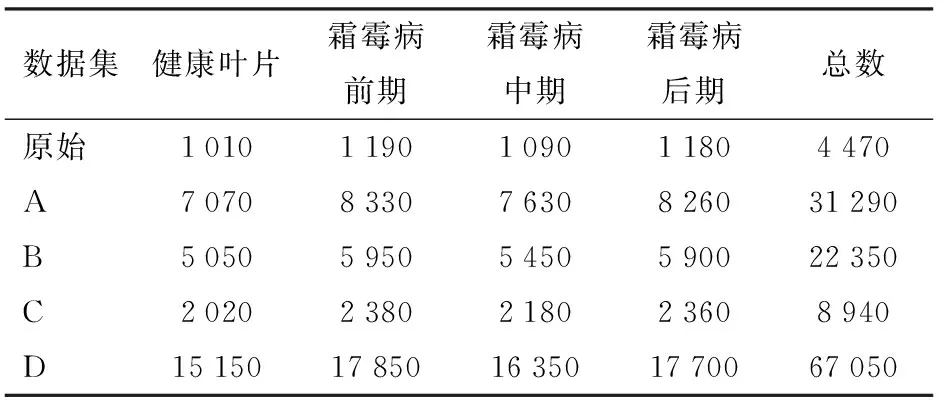
表3 数据增强后样本量分布Tab.3 Sample number distribution after data enhancement 幅
图11为改进后残差网络在综合数据集上的训练过程,模型收敛速度快,训练准确率达100%。

图11 改进模型性能随迭代周期的变化曲线Fig.11 Performance of improved model varied with number of iterations
改进ResNet-50模型与ResNet-50模型在不同数据集上的识别准确率对比如表4所示。可以看出,与ResNet-50相比,改进ResNet-50在数据集D上识别准确率最高,测试效果最好。

表4 改进模型与原模型的识别效果对比Tab.4 Recognition effect comparison between improved model and original model %
由表4可知,在原始数据集上,改进后模型较原始模型在测试集的识别准确率提升了2.31个百分点;不同数据增强方法均能提高模型的泛化性能,使用改进残差结构的模型识别准确率最高达到了99.92%。由于捷径分支池化层的加入和主分支的结构调整,参数量有一定的增加,模型训练耗时接近原始残差网络模型的1.3倍,但本文方法极大增强了模型特征提取能力和适应性,能够在复杂背景下准确判别病害等级,具有更高的实用价值。
3.3.4残差结构修改方式对模型识别准确率的影响
首先维持主分支不变,仅修改残差结构Conv3、Conv4、Conv5的Base Block捷径分支;然后维持捷径分支不变,修改ID Block中残差块的主分支结构;在数据集D上分别训练模型并进行测试,结果如表5所示。

表5 不同修改方式的残差结构识别效果Tab.5 Residual structure recognition effect of different modification methods %
与原始模型相比,两种修改方法在识别准确率上均有一定提升。仅修改捷径分支时,能够在实现降低特征维度的同时保留大量上层信息,基于这一上层信息,下层主分支在进行下一轮特征提取时能有更好的表现。仅修改主分支时,模型特征提取的能力得到增强,卷积层的性能得到较大提升。两分支同时修改后,进一步减少了流动过程中的信息损失,准确率得到进一步提升,残差结构主分支与捷径分支相互促进,模型效果达到最优。
模型残差结构改进前后的特征提取过程如图12所示,图12a中Block1、Block2、Block3分别为原始网络结构中图像经过第1、2、3个残差体后输出的特征图;图12b中各图分别为改进后网络第1、2、3个残差体提取到的特征。残差结构改进前后网络在浅层提取到的特征差异不大,但改进后残差结构提取深层抽象特征的能力比改进前更强。

图12 改进前后残差结构特征提取可视化Fig.12 Visualizations of feature extraction of improved residual structure
4 结论
(1)为了提高自然条件下葡萄霜霉病病害程度分级准确率,从插入池化层、优化主分支结构和设计新的全连接层等方面对残差网络模型ResNet-50进行改进,原始数据集测试结果表明,动量因子m为0.60、学习率α为0.001时改进ResNet-50模型具有最好的识别效果。改进后的残差块增强了网络的特征提取能力,在优化超参数的基础上,相较于原始模型识别准确率提升了2.31个百分点。
(2)不同数据增强方式对提高模型识别准确率均有一定贡献,且不同的残差结构改进方式均能提高模型识别准确率。数据集D上改进ResNet-50模型的识别准确率高于原始模型4.68个百分点,达到99.92%,表明本文方法可实现复杂环境下葡萄霜霉病的自动准确识别。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
学生天地(2019年28期)2019-08-25 08:50:54
自动化学报(2019年6期)2019-07-23 01:18:32
电子制作(2018年19期)2018-11-14 02:37:08
数学物理学报(2018年1期)2018-03-26 08:16:36
自动化学报(2017年11期)2017-04-04 02:52:58
河南科技(2015年8期)2015-03-11 16:23:52
噪声与振动控制(2015年4期)2015-01-01 07:08:21
山西大同大学学报(自然科学版)(2014年3期)2014-01-23 01:56:30
