
融合多源时空数据的冬小麦产量预测模型研究
2022-02-21 08:20:32王来刚郑国清程永政
农业机械学报 2022年1期
王来刚 郑国清 郭 燕 贺 佳 程永政
(1.河南省农业科学院农业经济与信息研究所, 郑州 450002; 2.农作物种植监测与预警河南省工程实验室, 郑州 450002)
0 引言
及时准确掌握区域农作物产量信息,能够为粮食生产宏观调控、经济政策制定和农作物保险提供决策支持,对服务国家粮食安全战略具有重要意义。小麦是我国粮食作物之一,也是我国重要的口粮作物,对粮食安全和居民生活都具有重要意义。
冬小麦产量形成是一个复杂的过程,中间涉及非常多的生理生化过程,气象条件、土壤条件、地理环境、物候信息等都是其产量估算需要考虑的因素,产量可看成是一段时期内多个影响因子相互叠加的结果。遥感技术在农业中已广泛应用,可以从遥感数据中提取出各种相关信息用于产量预测。特别是植被指数,如归一化差异植被指数(Normalized difference vegetation index, NDVI),已被广泛使用[1-3]。其他指数如增强植被指数(Enhanced vegetation index,EVI)[4]、作物水分胁迫指数[5]、绿色植被指数、土壤调节植被指数[6]等,也被用于作物产量预测。气象数据(如降水量、空气温度等)[7-9]和土壤条件数据(如土壤含水率和温度)[10],在产量预测中经常被用作作物生长环境指标。日光诱导叶绿素荧光遥感数据(SIF)为植物进行光吸收后叶绿素a 释放出的微弱电磁辐射信号[11],与光合速率紧密耦合。近年来,SIF数据日益增多,为作物估产提供了一条新的有效途径[12-14]。基于遥感数据的作物产量预测模型主要有2种:作物模拟模型和经验统计模型。尽管作物模拟模型精确地模拟了作物生长的物理过程,但需要精细的土壤和气象数据,这阻碍了它们的大规模应用。相比之下,经验统计模型简单,需要较少的输入数据,因此被广泛用作基于过程的模型的常见替代方案。上述相关研究多集中在利用植被指数和气象数据预测作物产量,将SIF数据作为产量预测因子的研究相对较少。
随机森林回归模型是一种基于机器学习的统计方法,它能处理高维度的数据并且估算结果具有较高的准确率。杨北萍等[15]将气象数据和遥感数据作为输入变量,基于随机森林回归方法预测了水稻产量。王鹏新等[16]通过随机森林回归算法获取玉米主要生育时期各个特征变量的权重,构建了加权特征变量与玉米单产间的回归模型。程千等[17]采用偏最小二乘回归、支持向量机回归和随机森林回归3种机器学习算法进行冬小麦产量估测,其中随机森林回归模型估测精度最高。本文以河南省为研究区域,拟通过探索分析多年小麦生长季的遥感数据、气象数据、土壤含水率数据、地形数据与小麦单产的相关性,利用随机森林回归模型融合多源时空数据构建冬小麦产量预测模型,以期提高大尺度冬小麦产量预测精度。
1 材料与方法
1.1 研究区域概况
本文将河南省作为研究区域。河南省位于我国中部的黄河中下游地区,地处我国第二阶梯向第三阶梯的过渡地带,北、西、南三面的太行山、伏牛山、桐柏山、大别山沿省界呈半环形分布;中、东部为黄淮海冲积平原;西南部为南阳盆地。全省耕地面积8.110 3×106hm2,占中国总耕地面积的6.24%,是我国小麦的最适生态区,小麦是河南省最主要的粮食作物,全省小麦播种面积、总产量均居全国首位。
1.2 数据获取与处理
研究需要的数据包括2005—2019年河南省小麦生长季的遥感数据、气象数据、土壤含水率数据、数字高程和小麦单产数据,所有数据利用小麦种植空间分布数据进行掩膜,并叠加河南省县级行政边界,经栅格均值计算,得各县区的变量均值。
1.2.1遥感数据
卫星遥感参数分别选择增强型植被指数(EVI)和日光诱导叶绿素荧光(SIF)来反映小麦长势和光合作用。EVI是一个广泛用于监测作物长势和预测产量的植被指数[18],与NDVI相比,EVI对较高的冠层叶面积指数敏感,受大气气溶胶影响较小。本文使用了美国国家航空航天局(NASA)MODIS EVI 产品(MOD13A1, Collection 6),该产品的空间分辨率为500 m,时间分辨率为16 d。近年来,随着技术的发展,SIF遥感数据不断增多、空间分辨率不断提高,使得利用 SIF 遥感数据直接预测作物产量成为可能[19-20]。SIF数据是从全球空间连续日光诱导叶绿素荧光数据集产品(CSIF)获得(DOI:10.6084/m9.figshare.6387494),其时间分辨率为4 d和全球空间分辨率为0.05°。应用最大值合成技术生成冬小麦生长季(10月至次年5月)月时间尺度的EVI和SIF。
1.2.2气象数据
从Terra Climate数据集获得小麦整个生育期每月的降水量、最高温度、最低温度数据作为影响产量形成的特征变量。这些数据集对1958—2019年间的全球地表具有高空间分辨率(约4 km),可用于区域作物产量预测[21-22]。
1.2.3土壤含水率数据
土壤含水率数据来自国家青藏高原科学数据中心的中国土壤水分数据集(DOI: 10.5281/zenodo.4738556),时间分辨率为月,空间分辨率为0.05°。
1.2.4数字高程数据
来源于美国国家航空航天局(NASA)ASTERG-DEM,栅格尺寸为30 m×30 m。
1.2.5冬小麦单产数据
河南省县级冬小麦单产数据来源于《河南省统计年鉴》,2005—2019年间具有有效小麦单产数据的县市105个。
1.3 研究方法
1.3.1随机森林回归模型
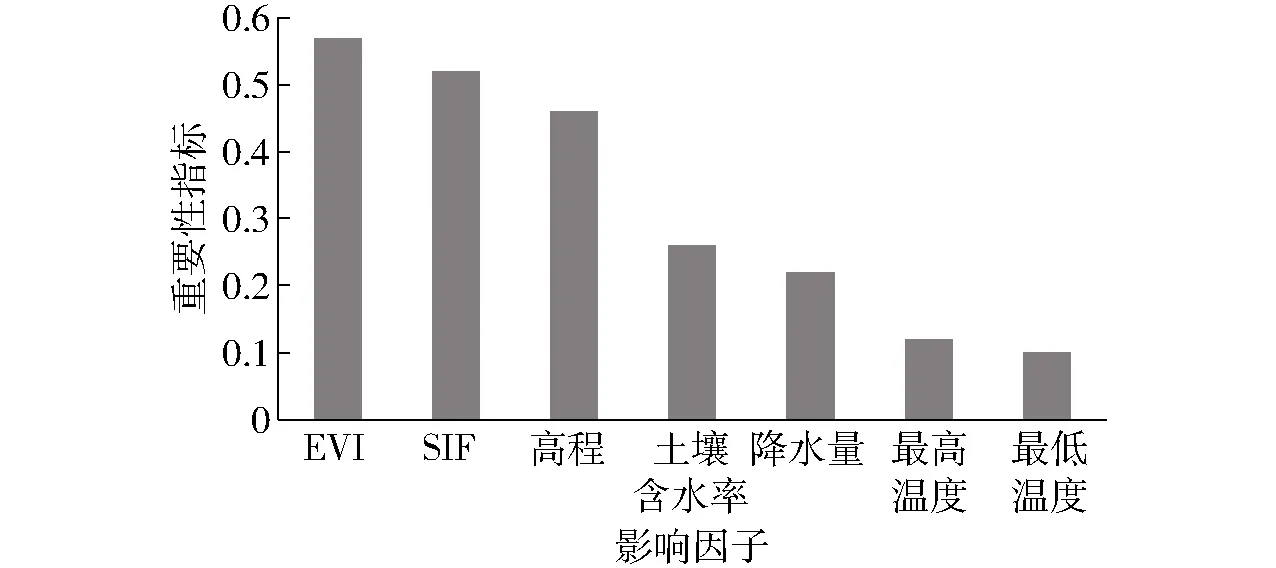
随机森林是由多棵分类回归树(Classification and regression tree,CART)构成的组合分类模型[23]。该研究将各年份各县市的小麦产量因子特征变量数据和产量数据进行集成,共同构成随机森林的样本数据集,通过自助法(Bootstrap)从原始样本集采样得到构建N棵树所需的N个子集,每次未被抽到的数据称为袋外数据(Out-of-bag,OOB),用来进行内部误差估计和变量重要性评价;生成每棵树时,从规模为M的特征变量集中随机选择m个变量(m 图1 基于随机森林算法的冬小麦产量预测流程图Fig.1 Flow chart of winter wheat yield prediction based on random forest algorithm 1.3.2特征变量重要性评价 随机森林算法是众多决策树并行式集成学习的方法,除了可对数据集进行分类和回归外,还可以进行变量重要性分析、奇异值检测等[24],能够解释若干自变量对因变量的作用。通过模型内部重要性评价结果,分析不同影响因子对小麦产量的影响程度。这种方法是直接分析评价每种特征变量对模型预测准确率的影响,基本思想是重新排列特征变量的顺序,观测模型准确率的降低程度。对于不重要的特征变量,这种方法对模型准确率的影响很小,但是对于重要特征变量却会极大降低模型的准确率。具体过程为: (1)对于随机森林中的每一棵决策树,使用相应的袋外数据(OOB)来计算它的袋外数据误差,记为eOOB1。 (2)随机地对OOB数据所有样本的特征变量加入噪声干扰,随机改变样本在特征变量处的值,再次计算它的袋外数据误差,记为eOOB2。 (3)假设随机森林中有Ntree棵树,则特征变量的重要性指标为∑(eOOB2-eOOB1)/Ntree。之所以可以用这个表达式作为相应特征的重要性度量值,是因为:若给某个特征随机加入噪声之后,袋外的准确率大幅度降低,则说明这个特征对于样本的分类结果影响很大,即重要程度比较高。 1.3.3模型精度评价 采用决定系数(Coefficient of determination,R2)、均方根误差(Root mean square error,RMSE)和相对误差(Relative error,RE)3个指标评价模型精度。其中R2评价预测模型拟合能力,RMSE和RE评价预测值和实测值离散程度。 为研究特征变量与小麦产量之间的关系,分别从时间和空间上进行了各特征变量数据与产量之间相关性分析,见图2,箱线图是特征变量与产量相关性的时间模式,相关性的空间模式基于具有最高相关系数的月份,即方框图中的红点。在时间相关性模式上,遥感参数EVI和SIF与产量都呈正相关,其中4月相关性达到最高峰,相关系数可达0.7左右,随后由于小麦冠层衰老和籽粒形成而开始下降,使得遥感参数与产量之间的相关性降低。与遥感参数不同,土壤含水率与产量之间的最大相关系数出现时期并不突出,主要在10月和次年3、4月相关性比较大,但整体相关性低于遥感参数。气象变量中,各生长阶段降水量和最低温度与小麦气象波动产量为正相关,降水量与产量之间的相关性最大的月份与土壤含水率基本相同,最低温度与产量相关性最大的月份为3月。3月小麦主要处于拔节-孕穗阶段,最低温度是影响小麦产量的重要因素。最高温度与产量主要呈负相关性,但相关系数较小。 图2 特征变量与冬小麦产量的时空相关性Fig.2 Spatiotemporal correlations between characteristic variable and wheat yield 选择特征变量与小麦产量相关性最高的月份,分析特征变量与小麦产量相关性的空间分布特征。遥感参数EVI和SIF在豫北平原和豫东平原与产量相关性较高,相关系数最高达0.8。豫西豫南山地丘陵地区和部分种植模式混杂的县区相关性较低,相关系数大部分在0~0.2之间,这些差异可能是由于豫西、豫南山地丘陵地区地块破碎,EVI和SIF混合像元较多,遥感参数难以真实反映小麦长势情况。土壤含水率与产量相关性在空间分布上,无明显特征。降水量在灌溉条件较差的丘陵地区与产量相关性较高,豫北地区相关性略低,可能由于豫北地区灌溉条件较好,小麦生长对降水量依赖性不高。最高温度在全省与小麦产量主要呈负相关,在山地丘陵地区相关性较高。最低温度在豫北地区相关性较高,豫北地区冬小麦易遭受晚霜冻害,最低温度是影响产量的一项重要制约因素。 冬小麦特征变量可以分为动态特征变量(遥感和气象变量等)和静态特征变量(高程)。利用2005—2019年的冬小麦特征动态变量数据与产量分别进行随机森林的OOB重要性分析,按照模型准确率降低的程度对特征变量由大到小排序(表1)。4月EVI和SIF、2月降水量排名位居前3位。开花期是冬小麦体内新陈代谢最旺盛的生长时期, 正是小麦产量形成的关键时期。河南省冬小麦的开花期主要集中在4月,EVI和SIF与冬小麦叶面积指数、生物量等苗情指标具有较强的相关性,因此在各特征变量中重要性更高,重要性指标在0.4左右。2月是河南省冬小麦返青期,是促进苗情转化升级的关键时期,降水量是一个重要的影响因素。重要性指标第4~6位分别为10月土壤含水率、4月最低温度和2月EVI。10月是冬小麦播种出苗时期,土壤墒情是出苗品质的关键因子。4月初小麦处于孕穗期,很容易受到低温冻害,特别是豫北地区。2月EVI代表了小麦生长前期的总体苗情,也是影响产量的重要因子。 表1 动态特征变量重要性指标Tab.1 Importance of dynamic feature variables 对EVI、SIF、土壤含水率、降水量、最高温度、最低温度和高程7大类特征变量进行基于随机森林的袋外OOB重要性分析(图3)。结果表明,EVI、SIF和高程对小麦产量的重要性远大于其他因素,重要性指标均超过0.45,说明除了遥感参数外,地形对产量的影响也非常大。其次是土壤含水率和降水量,说明含水率是影响小麦产量的重要环境因子。最后是最高温度和最低温度,重要性指标只有0.10左右。综上,描述作物生长状况EVI和SIF对产量预测的贡献大于描述作物生长环境的气象和土壤因子。 图3 影响因子重要性统计图Fig.3 Importance of impact factors 为了深入研究不同时间段的冬小麦单产预测精度,并结合单产预测实际工作需求,分别输入10月—次年2月、10月—次年3月、10月—次年4月、10月—次年5月的特征变量,对小麦产量进行随机森林建模,结果见图4。由图4可知,基于小麦整个生长阶段10月—次年5月和10月—次年4月特征变量的估产精度较高,R2分别为0.85和0.84,RMSE均最小,2个时间段模型预测精度基本相同。河南省冬小麦抽穗期和开花期主要集中在4月,开花期是冬小麦体内新陈代谢最旺盛的生长时期,正是小麦产量形成的关键时期,温度和降水量与小麦产量密切相关[25]。仅有小麦生长前期的10月—次年2月和10月—次年3月特征变量的估产精度相对偏低,RMSE均大于900 kg/hm2。因此,4月底或5月初是冬小麦产量预测的最佳时间。 图4 不同时间段模型预测结果对比Fig.4 Comparisons of prediction results of different periods 输入冬小麦各生长阶段的EVI、SIF、土壤含水率、气象要素和高程等全部变量,以小麦产量为目标变量构建随机森林模型,预测2018、2019年河南省各县冬小麦产量,图5为冬小麦产量预测相对误差与数字高程叠加空间分布情况。整体上,2年模型预测相对误差空间分布基本相似,产量预测相对误差均在20%以内,平原地区模型预测相对误差大部分在10%以内,而豫西和豫南丘陵山地模型预测相对误差高于平原地区,这可能由于丘陵山地区域地块破碎,而模型输入数据EVI、SIF等数据空间分辨率较低,混合像元现象比较严重,很难准确反映小麦实际长势情况。另外,信阳地区和开封部分县小麦种植地块零星破碎,预测精度也相对偏低。2年数据对比可以看出,2019年预测相对误差低于2018年,特别在豫北地区,2018年预测相对误差明显较大。这可能由于2018年4月初河南豫北地区发生一次较重的晚霜冻害,不同小麦品种抗冻害能力差别较大,产量损失程度更是不一致,而该预测模型无品种特征变量。 图5 河南省冬小麦产量预测相对误差空间分布Fig.5 Relative error spatial distributions of winter wheat yield prediction in Henan Province 研究表明,SIF与小麦产量呈正相关,这一结果得到了已有研究的支持[26-27]。研究区内,SIF和EVI与小麦产量的相关性相近,EVI对绿叶结构、叶绿素含量和生物量的变化比较敏感,而SIF有着直接指示植被光合作用的巨大潜力,2种数据可能共同反映一些与地上作物生物量相关的信息。本文研究的小麦产量预测模型输入变量重点考虑了气象条件、植被生长状态、地形地貌等,但在实际生产过程中小麦产量会受到多种环境因素的影响,以及各种人为因素造成的产量波动,这些都会影响最终的预测精度。气象条件中虽然用到了最高温度和最低温度等特征变量,但显然预测模型对灾害信息反应不敏感,在对2018年冬小麦产量预测中,受到晚霜冻害的区域小麦预测精度偏低。根据实际调查,小麦冻害除了与最低温度有关之外,与品种、种植密度和土壤特性都有明显的相关性。因此,未来的研究中可以增加灾害分布图层作为输入变量,从而提高模型预测精度。 随机森林算法在预测产量上具有很大的潜力,但并不意味着该算法一定是预测产量的最优算法,后期研究将对比深度神经网络、卷积神经网络等深度学习算法在作物预测产量的优缺点,解决算法对于极端天气等突发事件的适应性[28-29]。这项研究受到了一些不确定性的困扰,其中一个问题是SIF和EVI的低信噪比和粗糙的时空分辨率[30-31],可能无法真实反映小麦长势空间特征的细节。特别是在山地丘陵地块破碎的地区,产量预测精度都有不同程度下降。因此,如果要提高遥感数据在作物产量预测中的作用,时空连续高分辨率数据是非常重要的。随着卫星遥感技术发展,将实现具有更高空间和时间分辨率的EVI和SIF。例如,欧空局设计的FLEX(Fluorescence explorer),提供全球尺度上的植被叶绿素荧光测量卫星数据,目前其空间分辨率设定为300 m×300 m,轨道幅宽为150 km,非常有利于小尺度精准化的作物估产研究[32]。 (1)以遥感数据、气象数据、土壤含水率数据和地形数据为特征变量,分析了2005—2019年小麦产量与特征变量的相关性时空特征,基于随机森林算法对特征变量进行了重要性分析,并建立了不同时间段的小麦产量预测模型。 (2)SIF是指示植被光合变化的有效探针,与小麦产量呈高度正相关,在小麦产量预测特征变量重要性分析中,与EVI起着同等重要作用,是小麦产量预测的一项重要因子。 (3)在7大类特征变量中,EVI、SIF和高程对小麦产量的重要性远大于其他因素,重要性指标都超过0.45,其次是土壤含水率和降水量,最后是最高温度和最低温度。高程为静态特征变量,在空间有差异,年度间无变化。 (4)基于随机森林算法以小麦生长阶段10月—次年5月和10月—次年4月为特征变量构建的产量预测模型精度较高,R2分别为0.85和0.84,RMSE分别为821.55、832.01 kg/hm2。在产量预测误差空间分布特征上,全省相对误差均在20%以内,平原地区模型预测相对误差大部分在10%以内,而豫西和豫南丘陵山地模型预测相对误差高于平原地区。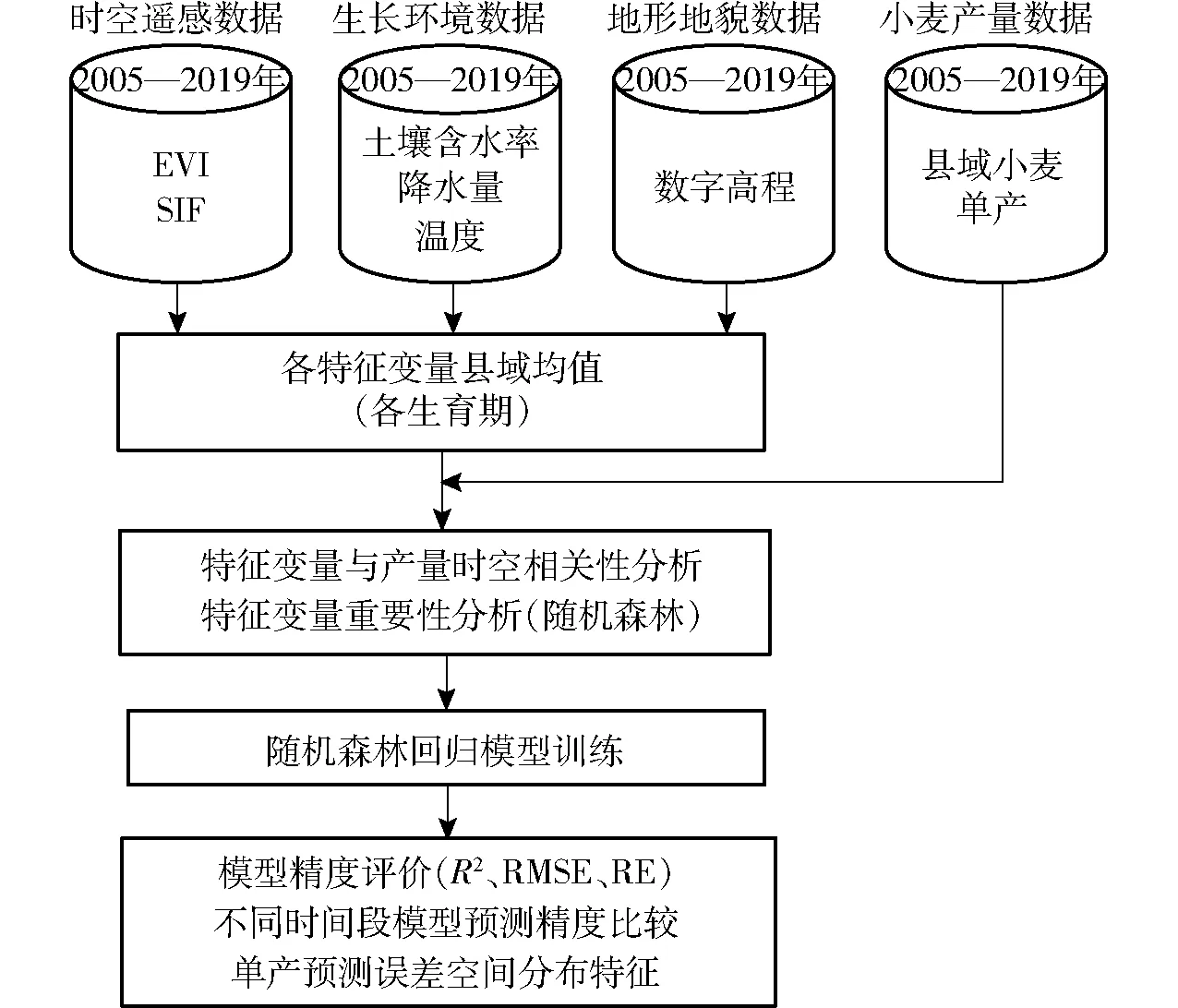
2 结果与分析
2.1 特征变量与冬小麦产量时空相关性分析

2.2 特征变量重要性分析

2.3 不同时间段模型预测精度比较

2.4 单产预测误差空间分布特征

3 讨论
4 结论
猜你喜欢
今日农业(2022年16期)2022-11-09 23:18:44
林业机械与木工设备(2022年5期)2022-05-27 09:28:56
金桥(2021年10期)2021-11-05 07:23:28
今日农业(2021年13期)2021-08-14 01:38:00
中国粉体技术(2021年1期)2021-01-04 02:19:18
作文小学中年级(2020年4期)2020-06-11 12:47:08
长江科学院院报(2018年12期)2018-12-19 09:52:02
植物保护(2017年1期)2017-02-13 06:44:34
电子制作(2016年1期)2016-11-07 08:42:56
中学生(2015年4期)2015-08-31 02:53:50
